Amazon RedshiftML permite que analistas de dados, desenvolvedores e cientistas de dados treinem modelos de aprendizado de máquina (ML) usando SQL. Nas postagens anteriores, demonstramos como você pode usar o recurso de treinamento automático de modelo do Redshift ML para treinar classificação e regressão modelos. Redshift ML permite criar um modelo usando SQL e especificar seu algoritmo, como XGBoost. Você pode usar o Redshift ML para automatizar a preparação de dados, o pré-processamento e a seleção do seu tipo de problema (para obter mais informações, consulte Crie, treine e implante modelos de aprendizado de máquina no Amazon Redshift usando SQL com o Amazon Redshift ML). Você também pode trazer um modelo previamente treinado em Amazon Sage Maker para dentro Amazon RedShift via Redshift ML para inferência local. Para inferência local em modelos criados no SageMaker, o tipo de modelo ML deve ser compatível com Redshift ML. No entanto, inferência remota está disponível para tipos de modelo que não estão disponíveis nativamente no Redshift ML.
Com o tempo, os modelos de ML envelhecem e, mesmo que nada drástico aconteça, pequenas mudanças se acumulam. Os motivos comuns pelos quais os modelos de ML precisam ser treinados novamente ou auditados incluem:
- Desvio de dados – Como seus dados mudaram ao longo do tempo, a precisão da previsão dos seus modelos de ML pode começar a diminuir em comparação com a precisão exibida durante os testes
- Desvio de conceito – O algoritmo de ML que foi usado inicialmente pode precisar ser alterado devido a diferentes ambientes de negócios e outras necessidades em mudança
Talvez seja necessário atualizar o modelo regularmente, automatizar o processo e reavaliar a precisão aprimorada do seu modelo. No momento em que este livro foi escrito, o Amazon Redshift não era compatível com versionamento de modelos de ML. Nesta postagem, mostramos como você pode usar a funcionalidade traga seu próprio modelo (BYOM) do Redshift ML para implementar o controle de versão de modelos Redshift ML.
Usamos inferência local para implementar o versionamento de modelos como parte da operacionalização de modelos de ML. Presumimos que você tenha um bom entendimento dos seus dados e do tipo de problema mais aplicável ao seu caso de uso, e que tenha criado e implantado modelos em produção.
Visão geral da solução
Nesta postagem, usamos o Redshift ML para construir um modelo de regressão que prevê o número de pessoas que podem usar o serviço de compartilhamento de bicicletas da cidade de Toronto a qualquer hora do dia. O modelo leva em conta vários aspectos, incluindo feriados e condições climáticas, e como precisamos prever um resultado numérico, utilizamos um modelo de regressão. Usamos o desvio de dados como motivo para treinar novamente o modelo e usamos o controle de versão do modelo como parte da solução.
Depois que um modelo é validado e usado regularmente para executar previsões, você pode criar versões dos modelos, o que exige que você treine novamente o modelo usando um conjunto de treinamento atualizado e possivelmente um algoritmo diferente. O versionamento serve a dois propósitos principais:
- Você pode consultar versões anteriores de um modelo para fins de solução de problemas ou auditoria. Isso permite garantir que seu modelo ainda mantenha alta precisão antes de mudar para uma versão de modelo mais recente.
- Você pode continuar executando consultas de inferência na versão atual de um modelo durante o processo de treinamento do modelo da nova versão.
No momento em que este artigo foi escrito, o Redshift ML não tinha recursos de controle de versão nativos, mas você ainda pode obter controle de versão implementando algumas técnicas SQL simples usando o recurso BYOM. O BYOM foi introduzido para oferecer suporte a modelos SageMaker pré-treinados para executar consultas de inferência no Amazon Redshift. Neste post, usamos a mesma técnica BYOM para criar uma versão de um modelo existente construído usando Redshift ML.
A figura a seguir ilustra esse fluxo de trabalho.
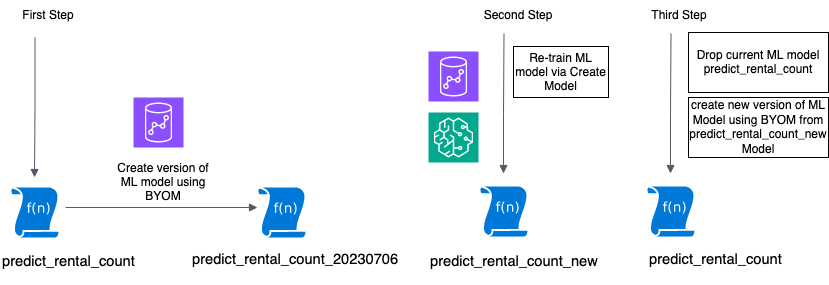
Nas seções a seguir, mostramos como criar uma versão a partir de um modelo existente e, em seguida, realizar um novo treinamento do modelo.
Pré-requisitos
Como pré-requisito para implementar o exemplo desta postagem, você precisa configurar um cluster redshift or Sem servidor Amazon Redshift ponto final. Para obter as etapas preliminares para começar e configurar seu ambiente, consulte Crie, treine e implante modelos de aprendizado de máquina no Amazon Redshift usando SQL com o Amazon Redshift ML.
Usamos o modelo de regressão criado no post Construir modelos de regressão com Amazon Redshift ML. Assumimos que ele já foi implantado e usamos este modelo para criar novas versões e treinar novamente o modelo.
Crie uma versão do modelo existente
O primeiro passo é criar uma versão do modelo existente (o que significa salvar as alterações de desenvolvimento do modelo) para que um histórico seja mantido e o modelo esteja disponível para comparação posterior.
O código a seguir é o formato genérico da sintaxe do comando CREATE MODEL; na próxima etapa, você obterá as informações necessárias para usar este comando para criar uma nova versão:
A seguir, coletamos e aplicamos os parâmetros de entrada ao código CREATE MODEL anterior ao modelo. Precisamos do nome do trabalho e dos tipos de dados dos valores de entrada e saída do modelo. Nós os coletamos executando o show model comando em nosso modelo existente. Execute o seguinte comando no Amazon Redshift Query Editor v2:

Observe os valores para Nome do trabalho do AutoML, Tipos de parâmetros de função, e as Coluna de Destino (trip_count) da saída do modelo. Usamos esses valores no comando CREATE MODEL para criar a versão.
A instrução CREATE MODEL a seguir cria uma versão do modelo atual usando os valores coletados de nosso show model comando. Anexamos a data (o formato de exemplo é AAAAMMDD) ao final do modelo e dos nomes das funções para rastrear quando esta nova versão foi criada.
Este comando pode levar alguns minutos para ser concluído. Quando terminar, execute o seguinte comando:

Podemos observar o seguinte na saída:
- Nome do trabalho do AutoML é igual à versão original do modelo
- Nome da Função mostra o novo nome, como esperado
- Tipo de inferência mostra
Local, que designa que isso é BYOM com inferência local
Você pode executar consultas de inferência usando ambas as versões do modelo para validar as saídas de inferência.
A captura de tela a seguir mostra a saída da inferência do modelo usando a versão original.

A captura de tela a seguir mostra a saída da inferência do modelo usando a cópia da versão.

Como você pode ver, as saídas de inferência são as mesmas.
Agora você aprendeu como criar uma versão de um modelo Redshift ML previamente treinado.
Treine novamente seu modelo Redshift ML
Depois de criar uma versão de um modelo existente, você poderá treinar novamente o modelo existente simplesmente criando um novo modelo.
Você pode criar e treinar um novo modelo usando o mesmo comando CREATE MODEL, mas usando diferentes parâmetros de entrada, conjuntos de dados ou tipos de problemas, conforme aplicável. Para esta postagem, treinaremos novamente o modelo em conjuntos de dados mais recentes. Nós anexamos _new ao nome do modelo para que seja semelhante ao modelo existente para fins de identificação.
No código a seguir, usamos o comando CREATE MODEL com um novo conjunto de dados disponível no training_data tabela:
Execute o seguinte comando para verificar o status do novo modelo:
Substitua o modelo Redshift ML existente pelo modelo retreinado
A última etapa é substituir o modelo existente pelo modelo retreinado. Fazemos isso eliminando a versão original do modelo e recriando um modelo usando a técnica BYOM.
Primeiro, verifique seu modelo retreinado para garantir que as pontuações MSE/RMSE permaneçam estáveis entre as execuções de treinamento do modelo. Para validar os modelos, você pode executar inferências por cada uma das funções do modelo no seu conjunto de dados e comparar os resultados. Usamos as consultas de inferência fornecidas em Construir modelos de regressão com Amazon Redshift ML.
Após a validação, você pode substituir seu modelo.
Comece coletando os detalhes do predict_rental_count_new modelo.

Note o Nome do trabalho do AutoML valor, o Tipos de parâmetros de função valores, e o Coluna de Destino nome na saída do modelo.
Substitua o modelo original eliminando o modelo original e, em seguida, criando o modelo com o modelo original e os nomes das funções para garantir que as referências existentes aos nomes do modelo e das funções funcionem:
A criação do modelo deverá ser concluída em alguns minutos. Você pode verificar o status do modelo executando o seguinte comando:
Quando o status do modelo é ready, a versão mais recente predict_rental_count do seu modelo existente está disponível para inferência e a versão original do modelo de ML predict_rental_count_20230706 está disponível para referência, se necessário.
Por favor, consulte isso Repositório GitHub para obter scripts de amostra para automatizar o controle de versão do modelo.
Conclusão
Nesta postagem, mostramos como você pode usar o recurso BYOM do Redshift ML para fazer o versionamento do modelo. Isso permite que você tenha um histórico de seus modelos para poder comparar as pontuações dos modelos ao longo do tempo, responder a solicitações de auditoria e executar inferências enquanto treina um novo modelo.
Para obter mais informações sobre a construção de modelos diferentes com Redshift ML, consulte Amazon RedshiftML.
Sobre os autores
 Rohit Bansal é um arquiteto de soluções especialista em análise na AWS. Ele é especializado no Amazon Redshift e trabalha com clientes para criar soluções analíticas de última geração usando outros serviços do AWS Analytics.
Rohit Bansal é um arquiteto de soluções especialista em análise na AWS. Ele é especializado no Amazon Redshift e trabalha com clientes para criar soluções analíticas de última geração usando outros serviços do AWS Analytics.
 Phil Bates é Arquiteto de Soluções Senior Analytics Specialist na AWS. Ele tem mais de 25 anos de experiência na implementação de soluções de armazenamento de dados em larga escala. Ele é apaixonado por ajudar os clientes em sua jornada na nuvem e usar o poder do ML em seu data warehouse.
Phil Bates é Arquiteto de Soluções Senior Analytics Specialist na AWS. Ele tem mais de 25 anos de experiência na implementação de soluções de armazenamento de dados em larga escala. Ele é apaixonado por ajudar os clientes em sua jornada na nuvem e usar o poder do ML em seu data warehouse.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/big-data/implement-model-versioning-with-amazon-redshift-ml/
- :tem
- :é
- :não
- $UP
- 100
- 11
- 25
- 5000
- 7
- a
- Sobre
- Contas
- Acumular
- precisão
- Alcançar
- algoritmo
- permite
- já
- tb
- Amazon
- Amazon Web Services
- an
- Analistas
- analítica
- e
- qualquer
- relevante
- Aplicar
- SOMOS
- AS
- aspectos
- assumir
- At
- auditor
- auditadas
- automatizar
- Automático
- disponível
- AWS
- base
- BE
- Porque
- sido
- antes
- começar
- ser
- entre
- ambos
- trazer
- construir
- Prédio
- construído
- negócio
- mas a
- by
- CAN
- capacidades
- capacidade
- casas
- mudado
- Alterações
- mudança
- verificar
- Cidades
- Na nuvem
- código
- coletar
- Coleta
- Coluna
- comum
- comparar
- comparado
- comparação
- completar
- condições
- continuar
- crio
- criado
- cria
- Criar
- criação
- Atual
- Clientes
- dados,
- Preparação de dados
- data warehouse
- conjuntos de dados
- Data
- dia
- diminuir
- Padrão
- demonstraram
- implantar
- implantado
- detalhes
- desenvolvedores
- desenvolvimento
- diferente
- do
- Não faz
- Caindo
- dois
- durante
- cada
- editor
- permite
- final
- Ponto final
- garantir
- Meio Ambiente
- ambientes
- Éter (ETH)
- Mesmo
- exemplo
- exibido
- existente
- vasta experiência
- Característica
- poucos
- Figura
- Primeiro nome
- seguinte
- Escolha
- formato
- da
- função
- funcionalidade
- funções
- ter
- dado
- Bom estado, com sinais de uso
- Cresça:
- acontece
- Ter
- he
- ajuda
- Alta
- história
- férias
- hora
- Como funciona o dobrador de carta de canal
- Como Negociar
- Contudo
- HTML
- http
- HTTPS
- IAM
- identificação
- if
- ilustra
- executar
- implementação
- melhorado
- in
- incluir
- Incluindo
- INFORMAÇÕES
- inicialmente
- entrada
- para dentro
- introduzido
- IT
- Trabalho
- viagem
- jpg
- em grande escala
- Sobrenome
- mais tarde
- aprendido
- aprendizagem
- local
- máquina
- aprendizado de máquina
- a Principal
- fazer
- Posso..
- significa
- minutos
- ML
- modelo
- modelos
- mais
- a maioria
- devo
- nome
- nomes
- nativo
- você merece...
- necessário
- Cria
- Novo
- mais novo
- Próximo
- próxima geração
- nada
- agora
- número
- numérico
- objetivo
- observar
- of
- WOW!
- Velho
- on
- or
- original
- Outros
- A Nossa
- Resultado
- saída
- outputs
- Acima de
- próprio
- parâmetro
- parâmetros
- parte
- apaixonado
- Pessoas
- realizar
- platão
- Inteligência de Dados Platão
- PlatãoData
- possivelmente
- Publique
- POSTAGENS
- poder
- predizer
- predição
- Previsões
- Previsões
- preliminares
- preparação
- anterior
- anteriormente
- Prévio
- Problema
- processo
- Produção
- fornecido
- fins
- consultas
- razão
- razões
- referir
- referência
- referências
- regressão
- regular
- substituir
- pedidos
- exige
- Responder
- Resultados
- Retém
- reciclagem
- Retorna
- Execute
- corrida
- é executado
- sábio
- mesmo
- poupança
- cientistas
- pontuações
- Scripts
- seções
- Vejo
- doadores,
- senior
- serve
- serviço
- Serviços
- conjunto
- Configurações
- compartilhando
- rede de apoio social
- mostrar
- mostrou
- Shows
- semelhante
- simples
- simplesmente
- pequeno
- So
- solução
- Soluções
- especialista
- especializada
- SQL
- estável
- começado
- Declaração
- Status
- permanecendo
- Passo
- Passos
- Ainda
- tal
- ajuda
- Suportado
- certo
- sintaxe
- mesa
- Tire
- Target
- técnica
- técnicas
- do que
- que
- A
- as informações
- deles
- então
- Este
- isto
- Através da
- tempo
- para
- pista
- Trem
- treinado
- Training
- dois
- tipo
- tipos
- compreensão
- Atualizada
- usar
- caso de uso
- usava
- utilização
- VALIDAR
- validado
- validação
- valor
- Valores
- vário
- versão
- versões
- via
- Armazém
- foi
- we
- Clima
- web
- serviços web
- quando
- qual
- enquanto
- porque
- de
- dentro
- Atividades:
- de gestão de documentos
- trabalho
- escrita
- XGBoostName
- anos
- Você
- investimentos
- zefirnet