O NLP multi-rótulo refere-se à tarefa de atribuir vários rótulos a uma determinada entrada de texto, em vez de apenas um rótulo. Em tarefas tradicionais de NLP, como classificação de texto ou análise de sentimento, cada entrada geralmente recebe um único rótulo com base em seu conteúdo. No entanto, em muitos cenários do mundo real, um trecho de texto pode pertencer a várias categorias ou expressar vários sentimentos simultaneamente.
O NLP multi-rótulo é importante porque nos permite capturar informações mais sutis e complexas de dados de texto. Por exemplo, no domínio da análise de feedback do cliente, uma avaliação do cliente pode expressar sentimentos positivos e negativos ao mesmo tempo, ou pode abordar vários aspectos de um produto ou serviço. Ao atribuir vários rótulos a essas entradas, podemos obter uma compreensão mais abrangente do feedback do cliente e tomar ações mais direcionadas para atender às suas preocupações.
Este artigo investiga um caso notável de uso da PNL multi-rótulos pela Provectus.
Background:
Um cliente nos abordou com um pedido para ajudá-lo automatizar a rotulagem de documentos de um determinado tipo. À primeira vista, a tarefa parecia simples e fácil de resolver. No entanto, enquanto trabalhávamos no caso, encontramos um conjunto de dados com anotações inconsistentes. Embora nosso cliente tenha enfrentado desafios com números de classe variados e mudanças em sua equipe de revisão ao longo do tempo, eles investiram esforços significativos na criação de um conjunto de dados diversificado com uma variedade de anotações. Embora existissem alguns desequilíbrios e incertezas nos rótulos, esse conjunto de dados forneceu uma oportunidade valiosa para análise e exploração adicional.
Vamos dar uma olhada mais de perto no conjunto de dados, explorar as métricas e nossa abordagem e recapitular como o Provectus resolveu o problema da classificação de texto com vários rótulos.
O conjunto de dados possui 14,354 observações, com 124 classes únicas (rótulos). Nossa tarefa é atribuir uma ou várias classes a cada observação.
A Tabela 1 fornece estatísticas descritivas para o conjunto de dados.
Em média, temos cerca de duas aulas por observação, com uma média de 261 textos diferentes descrevendo uma única aula.

Tabela 1: Estatística do conjunto de dados
Na Figura 1, vemos a distribuição das classes no gráfico superior, e temos um determinado número de rótulos HEAD com maior frequência de ocorrência no conjunto de dados. Observe também que a maioria das aulas tem baixa frequência de ocorrência.
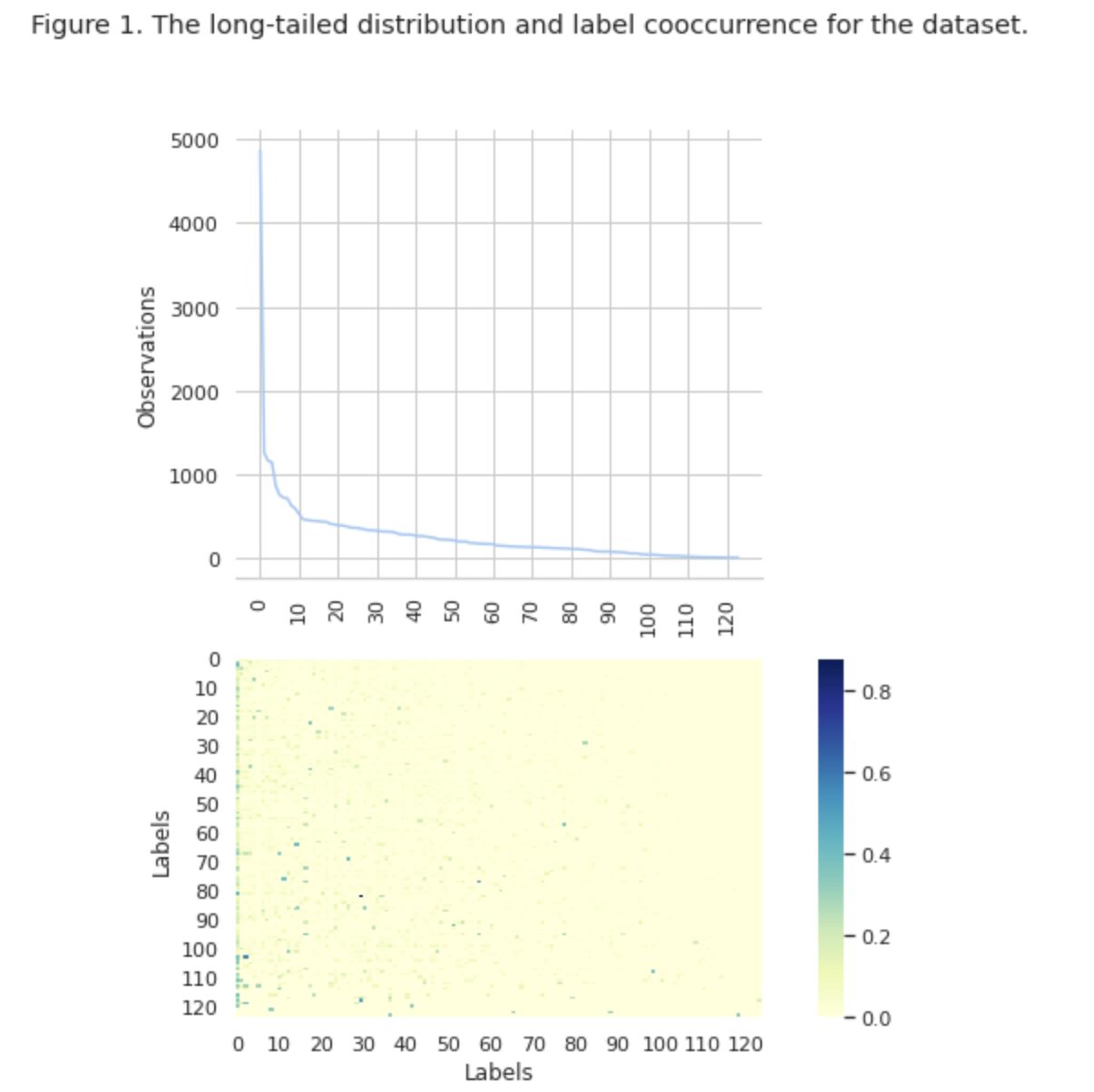
No gráfico inferior, vemos que há sobreposição frequente entre as classes que são melhor representadas no conjunto de dados e as classes com baixa significância.
Mudamos o processo de divisão do conjunto de dados em conjuntos train/val/test. Em vez de usar um método tradicional, empregamos estratificação iterativa para fornecer uma distribuição bem equilibrada de evidências de relações de rótulo. Para isso, utilizamos Scikit Multi-aprender
from skmultilearn.model_selection import iterative_train_test_split mlb = MultiLabelBinarizer() def balanced_split(df, mlb, test_size=0.5): ind = np.expand_dims(np.arange(len(df)), axis=1) mlb.fit_transform(df["tag"]) labels = mlb.transform(df["tag"]) ind_train, _, ind_test, _ = iterative_train_test_split( ind, labels, test_size ) return df.iloc[ind_train[:, 0]], df.iloc[ind_test[:, 0]] df_train, df_tmp = balanced_split(df, test_size=0.4)
df_val, df_test = balanced_split(df_tmp, test_size=0.5)
Obtivemos a seguinte distribuição:
- O conjunto de dados de treinamento contém 60% dos dados e abrange todos os 124 rótulos
- O conjunto de dados de validação contém 20% dos dados e abrange todos os 124 rótulos
- O conjunto de dados de teste contém 20% dos dados e abrange todos os 124 rótulos
A classificação multi-rótulo é um tipo de algoritmo de aprendizado de máquina supervisionado que nos permite atribuir vários rótulos a uma única amostra de dados. Ela difere da classificação binária, na qual o modelo prevê apenas duas categorias, e da classificação multiclasse, na qual o modelo prevê apenas uma de várias classes para uma amostra.
Métricas de avaliação para desempenho de classificação multirrótulo são inerentemente diferentes daquelas usadas na classificação multiclasse (ou binária) devido às diferenças inerentes do problema de classificação. Informações mais detalhadas podem ser encontradas na Wikipédia.
Selecionamos as métricas mais adequadas para nós:
- Precisão mede a proporção de previsões positivas verdadeiras entre as previsões positivas totais feitas pelo modelo.
- Recordar mede a proporção de previsões positivas verdadeiras entre todas as amostras positivas reais.
- Pontuação F1 é a média harmônica de precisão e recuperação, que ajuda a restaurar o equilíbrio entre os dois.
- Perda de Hamming é a fração de rótulos que são previstos incorretamente
Nós também rastreamos o número de rótulos previstos no conjunto { definido como contagem para rótulos, para os quais alcançamos uma pontuação F1 > 0}.
A classificação multi-rótulo é um tipo de problema de aprendizado supervisionado em que uma única instância ou exemplo pode ser associado a vários rótulos ou classificações, em oposição à classificação tradicional de rótulo único, em que cada instância é associada apenas a um único rótulo de classe.
Para resolver problemas de classificação multirrótulo, existem duas categorias principais de técnicas:
- Métodos de transformação de problemas
- Métodos de adaptação de algoritmo
Os métodos de transformação de problemas nos permitem transformar tarefas de classificação de vários rótulos em várias tarefas de classificação de rótulo único. Por exemplo, a abordagem de linha de base Binary Relevance (BR) trata cada rótulo como um problema de classificação binária separado. Neste caso, o problema multirrótulo é transformado em problemas múltiplos de rótulo único.
Os métodos de adaptação de algoritmo modificam os próprios algoritmos para lidar com dados multi-rótulo nativamente, sem transformar a tarefa em várias tarefas de classificação de rótulo único. Um exemplo dessa abordagem é o modelo BERT, que é um modelo de linguagem baseado em transformador pré-treinado que pode ser ajustado para várias tarefas de NLP, incluindo classificação de texto com vários rótulos. O BERT foi projetado para lidar diretamente com dados de vários rótulos, sem a necessidade de transformação do problema.
No contexto do uso do BERT para classificação de texto com vários rótulos, a abordagem padrão é usar a perda de entropia cruzada binária (BCE) como a função de perda. A perda de BCE é uma função de perda comumente usada para problemas de classificação binária e pode ser facilmente estendida para lidar com problemas de classificação de vários rótulos, calculando a perda para cada rótulo independentemente e, em seguida, somando as perdas. Nesse caso, a função de perda BCE mede o erro entre as probabilidades previstas e os rótulos verdadeiros, onde as probabilidades previstas são obtidas da camada de ativação sigmoide final no modelo BERT.
Agora, vamos dar uma olhada mais de perto na Figura 2 abaixo.
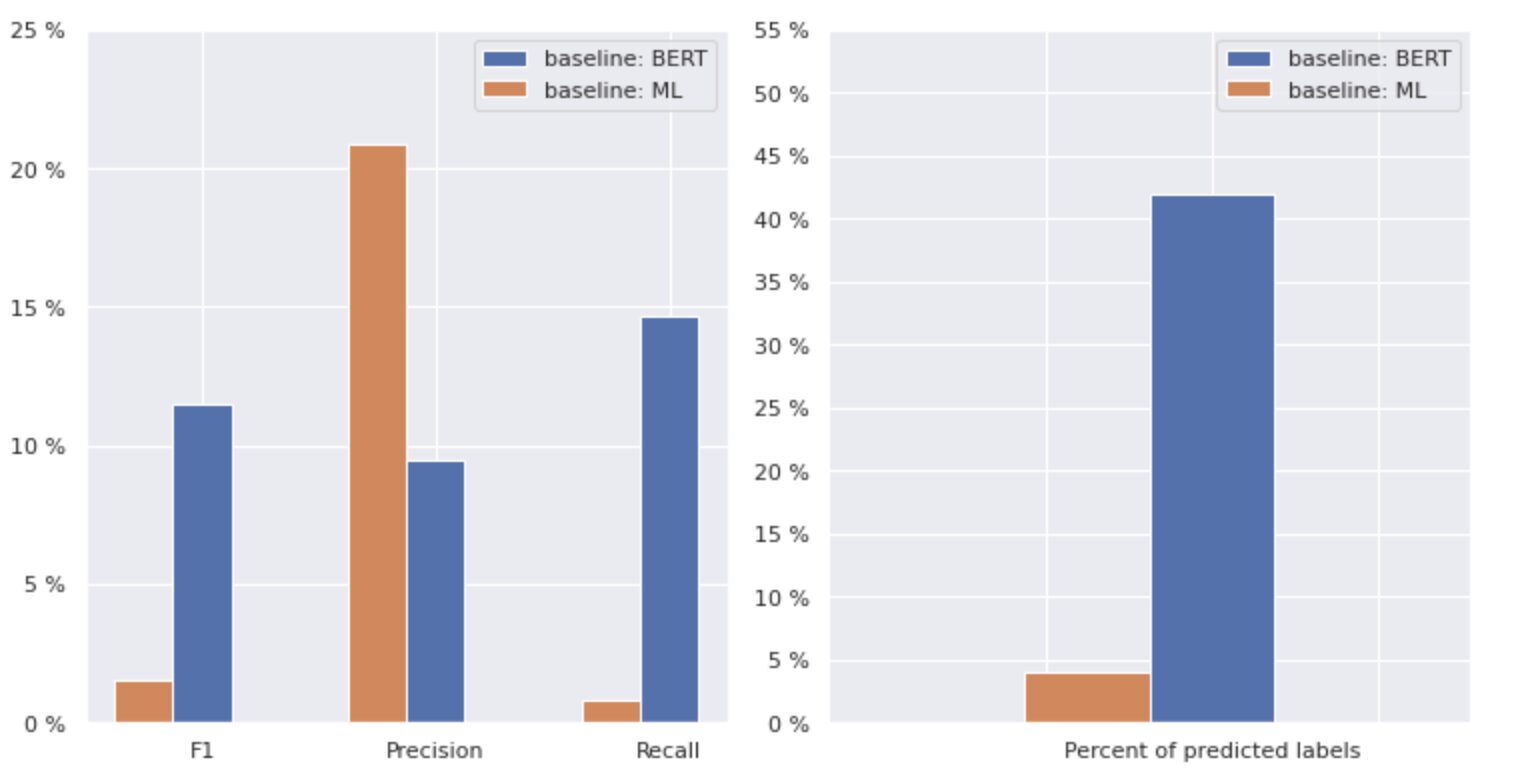
Figura 2. Métricas para modelos de linha de base
O gráfico à esquerda mostra uma comparação de métricas para uma “linha de base: BERT” e “linha de base: ML”. Assim, pode-se observar que para “baseline: BERT”, os escores F1 e Recall são aproximadamente 1.5 vezes maiores, enquanto a Precisão para “baseline: ML” é 2 vezes maior que a do modelo 1. Ao analisar a porcentagem geral de classes preditas mostradas à direita, vemos que “baseline: BERT” previu classes mais de 10 vezes do que “baseline: ML”.
Como o resultado máximo para a “linha de base: BERT” é inferior a 50% de todas as classes, os resultados são bastante desanimadores. Vamos descobrir como melhorar esses resultados.
Com base no excelente artigo “Métodos de balanceamento para classificação de texto multi-rótulo com distribuição de classe de cauda longa”, aprendemos que a perda balanceada de distribuição pode ser a abordagem mais adequada para nós.
Perda balanceada de distribuição
A perda balanceada de distribuição é uma técnica usada em problemas de classificação de texto com vários rótulos para resolver desequilíbrios na distribuição de classes. Nesses problemas, algumas classes têm uma frequência de ocorrência muito maior em comparação com outras, resultando em um viés do modelo em direção a essas classes mais frequentes.
Para resolver esse problema, a perda balanceada por distribuição visa equilibrar a contribuição de cada amostra na função de perda. Isso é obtido reponderando a perda de cada amostra com base no inverso de sua frequência de ocorrência no conjunto de dados. Ao fazer isso, aumenta-se a contribuição das turmas menos frequentes e diminui-se a contribuição das turmas mais frequentes, equilibrando assim a distribuição geral das turmas.
Essa técnica tem se mostrado eficaz em melhorar o desempenho de modelos em problemas de distribuição de classes de cauda longa. Ao reduzir o impacto das classes frequentes e aumentar o impacto das classes pouco frequentes, o modelo consegue capturar melhor os padrões nos dados e produzir previsões mais equilibradas.

Implementação da classe Resample
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np class ResampleLoss(nn.Module): def __init__( self, use_sigmoid=True, partial=False, loss_weight=1.0, reduction="mean", reweight_func=None, weight_norm=None, focal=dict(focal=True, alpha=0.5, gamma=2), map_param=dict(alpha=10.0, beta=0.2, gamma=0.1), CB_loss=dict(CB_beta=0.9, CB_mode="average_w"), logit_reg=dict(neg_scale=5.0, init_bias=0.1), class_freq=None, train_num=None, ): super(ResampleLoss, self).__init__() assert (use_sigmoid is True) or (partial is False) self.use_sigmoid = use_sigmoid self.partial = partial self.loss_weight = loss_weight self.reduction = reduction if self.use_sigmoid: if self.partial: self.cls_criterion = partial_cross_entropy else: self.cls_criterion = binary_cross_entropy else: self.cls_criterion = cross_entropy # reweighting function self.reweight_func = reweight_func # normalization (optional) self.weight_norm = weight_norm # focal loss params self.focal = focal["focal"] self.gamma = focal["gamma"] self.alpha = focal["alpha"] # mapping function params self.map_alpha = map_param["alpha"] self.map_beta = map_param["beta"] self.map_gamma = map_param["gamma"] # CB loss params (optional) self.CB_beta = CB_loss["CB_beta"] self.CB_mode = CB_loss["CB_mode"] self.class_freq = ( torch.from_numpy(np.asarray(class_freq)).float().cuda() ) self.num_classes = self.class_freq.shape[0] self.train_num = train_num # only used to be divided by class_freq # regularization params self.logit_reg = logit_reg self.neg_scale = ( logit_reg["neg_scale"] if "neg_scale" in logit_reg else 1.0 ) init_bias = ( logit_reg["init_bias"] if "init_bias" in logit_reg else 0.0 ) self.init_bias = ( -torch.log(self.train_num / self.class_freq - 1) * init_bias ) self.freq_inv = ( torch.ones(self.class_freq.shape).cuda() / self.class_freq ) self.propotion_inv = self.train_num / self.class_freq def forward( self, cls_score, label, weight=None, avg_factor=None, reduction_override=None, **kwargs ): assert reduction_override in (None, "none", "mean", "sum") reduction = ( reduction_override if reduction_override else self.reduction ) weight = self.reweight_functions(label) cls_score, weight = self.logit_reg_functions( label.float(), cls_score, weight ) if self.focal: logpt = self.cls_criterion( cls_score.clone(), label, weight=None, reduction="none", avg_factor=avg_factor, ) # pt is sigmoid(logit) for pos or sigmoid(-logit) for neg pt = torch.exp(-logpt) wtloss = self.cls_criterion( cls_score, label.float(), weight=weight, reduction="none" ) alpha_t = torch.where(label == 1, self.alpha, 1 - self.alpha) loss = alpha_t * ((1 - pt) ** self.gamma) * wtloss loss = reduce_loss(loss, reduction) else: loss = self.cls_criterion( cls_score, label.float(), weight, reduction=reduction ) loss = self.loss_weight * loss return loss def reweight_functions(self, label): if self.reweight_func is None: return None elif self.reweight_func in ["inv", "sqrt_inv"]: weight = self.RW_weight(label.float()) elif self.reweight_func in "rebalance": weight = self.rebalance_weight(label.float()) elif self.reweight_func in "CB": weight = self.CB_weight(label.float()) else: return None if self.weight_norm is not None: if "by_instance" in self.weight_norm: max_by_instance, _ = torch.max(weight, dim=-1, keepdim=True) weight = weight / max_by_instance elif "by_batch" in self.weight_norm: weight = weight / torch.max(weight) return weight def logit_reg_functions(self, labels, logits, weight=None): if not self.logit_reg: return logits, weight if "init_bias" in self.logit_reg: logits += self.init_bias if "neg_scale" in self.logit_reg: logits = logits * (1 - labels) * self.neg_scale + logits * labels if weight is not None: weight = ( weight / self.neg_scale * (1 - labels) + weight * labels ) return logits, weight def rebalance_weight(self, gt_labels): repeat_rate = torch.sum( gt_labels.float() * self.freq_inv, dim=1, keepdim=True ) pos_weight = ( self.freq_inv.clone().detach().unsqueeze(0) / repeat_rate ) # pos and neg are equally treated weight = ( torch.sigmoid(self.map_beta * (pos_weight - self.map_gamma)) + self.map_alpha ) return weight def CB_weight(self, gt_labels): if "by_class" in self.CB_mode: weight = ( torch.tensor((1 - self.CB_beta)).cuda() / (1 - torch.pow(self.CB_beta, self.class_freq)).cuda() ) elif "average_n" in self.CB_mode: avg_n = torch.sum( gt_labels * self.class_freq, dim=1, keepdim=True ) / torch.sum(gt_labels, dim=1, keepdim=True) weight = ( torch.tensor((1 - self.CB_beta)).cuda() / (1 - torch.pow(self.CB_beta, avg_n)).cuda() ) elif "average_w" in self.CB_mode: weight_ = ( torch.tensor((1 - self.CB_beta)).cuda() / (1 - torch.pow(self.CB_beta, self.class_freq)).cuda() ) weight = torch.sum( gt_labels * weight_, dim=1, keepdim=True ) / torch.sum(gt_labels, dim=1, keepdim=True) elif "min_n" in self.CB_mode: min_n, _ = torch.min( gt_labels * self.class_freq + (1 - gt_labels) * 100000, dim=1, keepdim=True, ) weight = ( torch.tensor((1 - self.CB_beta)).cuda() / (1 - torch.pow(self.CB_beta, min_n)).cuda() ) else: raise NameError return weight def RW_weight(self, gt_labels, by_class=True): if "sqrt" in self.reweight_func: weight = torch.sqrt(self.propotion_inv) else: weight = self.propotion_inv if not by_class: sum_ = torch.sum(weight * gt_labels, dim=1, keepdim=True) weight = sum_ / torch.sum(gt_labels, dim=1, keepdim=True) return weight def reduce_loss(loss, reduction): """Reduce loss as specified. Args: loss (Tensor): Elementwise loss tensor. reduction (str): Options are "none", "mean" and "sum". Return: Tensor: Reduced loss tensor. """ reduction_enum = F._Reduction.get_enum(reduction) # none: 0, elementwise_mean:1, sum: 2 if reduction_enum == 0: return loss elif reduction_enum == 1: return loss.mean() elif reduction_enum == 2: return loss.sum() def weight_reduce_loss(loss, weight=None, reduction="mean", avg_factor=None): """Apply element-wise weight and reduce loss. Args: loss (Tensor): Element-wise loss. weight (Tensor): Element-wise weights. reduction (str): Same as built-in losses of PyTorch. avg_factor (float): Avarage factor when computing the mean of losses. Returns: Tensor: Processed loss values. """ # if weight is specified, apply element-wise weight if weight is not None: loss = loss * weight # if avg_factor is not specified, just reduce the loss if avg_factor is None: loss = reduce_loss(loss, reduction) else: # if reduction is mean, then average the loss by avg_factor if reduction == "mean": loss = loss.sum() / avg_factor # if reduction is 'none', then do nothing, otherwise raise an error elif reduction != "none": raise ValueError( 'avg_factor can not be used with reduction="sum"' ) return loss def binary_cross_entropy( pred, label, weight=None, reduction="mean", avg_factor=None
): # weighted element-wise losses if weight is not None: weight = weight.float() loss = F.binary_cross_entropy_with_logits( pred, label.float(), weight, reduction="none" ) loss = weight_reduce_loss( loss, reduction=reduction, avg_factor=avg_factor ) return loss
Perda DB
loss_func = ResampleLoss( reweight_func="rebalance", loss_weight=1.0, focal=dict(focal=True, alpha=0.5, gamma=2), logit_reg=dict(init_bias=0.05, neg_scale=2.0), map_param=dict(alpha=0.1, beta=10.0, gamma=0.405), class_freq=class_freq, train_num=train_num,
) """
class_freq - list of frequencies for each class,
train_num - size of train dataset """
Ao investigar de perto o conjunto de dados, concluímos que o parâmetro
= 0.405.
Ajuste de limiar
Outra etapa de aprimoramento do nosso modelo foi o processo de tuning do threshold, tanto na etapa de treinamento, quanto nas etapas de validação e teste. Calculamos as dependências de métricas como pontuação f1, precisão e rechamada no nível do limite e selecionamos o limite com base na pontuação mais alta da métrica. Abaixo você pode ver a implementação da função deste processo.
Otimização da pontuação F1 ajustando o limite:
def optimise_f1_score(true_labels: np.ndarray, pred_labels: np.ndarray): best_med_th = 0.5 true_bools = [tl == 1 for tl in true_labels] micro_thresholds = (np.array(range(-45, 15)) / 100) + best_med_th f1_results, pre_results, recall_results = [], [], [] for th in micro_thresholds: pred_bools = [pl > th for pl in pred_labels] test_f1 = f1_score(true_bools, pred_bools, average="micro", zero_division=0) test_precision = precision_score( true_bools, pred_bools, average="micro", zero_division=0 ) test_recall = recall_score( true_bools, pred_bools, average="micro", zero_division=0 ) f1_results.append(test_f1) prec_results.append(test_precision) recall_results.append(test_recall) best_f1_idx = np.argmax(f1_results) return micro_thresholds[best_f1_idx]Avaliação e comparação com a linha de base
Essas abordagens nos permitiram treinar um novo modelo e obter o seguinte resultado, que é comparado com a linha de base: BERT na Figura 3 abaixo.

Figura 3. Métricas de comparação por linha de base e abordagem mais recente.
Ao comparar as métricas relevantes para a classificação, vemos um aumento significativo nas medidas de desempenho de quase 5 a 6 vezes:
A pontuação F1 aumentou de 12% → 55%, enquanto a precisão aumentou de 9% → 59% e a rechamada aumentou de 15% → 51%.
Com as mudanças mostradas no gráfico à direita na Figura 3, agora podemos prever 80% das classes.
Fatias de aulas
Dividimos nossos rótulos em quatro grupos: HEAD, MEDIUM, TAIL e ZERO. Cada grupo contém rótulos com uma quantidade semelhante de observações de dados de suporte.
Como visto na Figura 4, as distribuições dos grupos são distintas. A caixa rosa (HEAD) tem uma distribuição assimétrica negativa, a caixa do meio (MEDIUM) tem uma distribuição assimétrica positiva e a caixa verde (TAIL) parece ter uma distribuição normal.
Todos os grupos também têm outliers, que são pontos fora dos bigodes no box plot. O grupo HEAD tem um grande impacto em uma classe MAJOR.
Além disso, identificamos um grupo separado chamado “ZERO” que contém rótulos que o modelo não conseguiu aprender e não pode reconhecer devido ao número mínimo de ocorrências no conjunto de dados (menos de 3% de todas as observações).
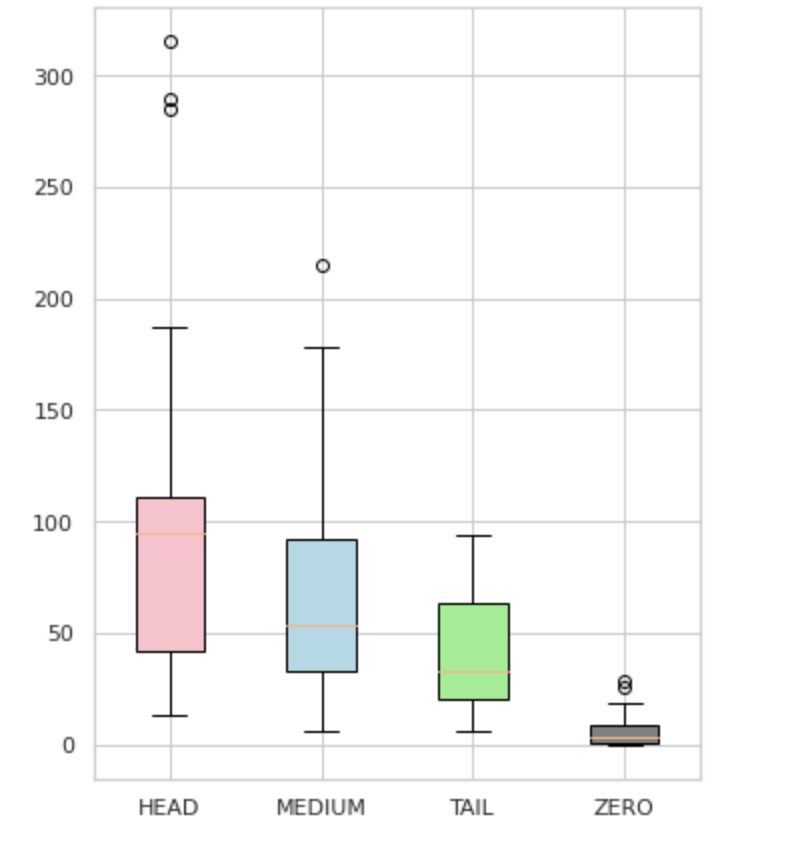
Figura 4. Contagens de rótulos vs. grupos
A Tabela 2 fornece informações sobre métricas por cada grupo de rótulos para o subconjunto de dados de teste.
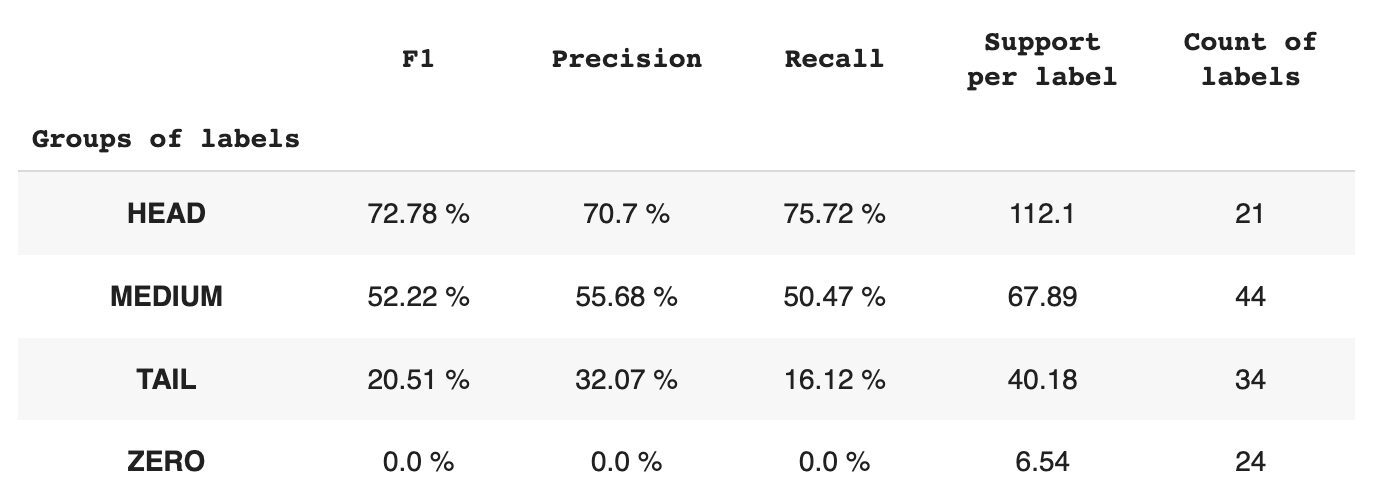
Tabela 2. Métricas por grupo.
- O grupo HEAD contém 21 rótulos com uma média de 112 observações de suporte por rótulo. Este grupo é impactado por outliers e, devido à sua alta representatividade no conjunto de dados, suas métricas são altas: F1 – 73%, Precision – 71%, Recall – 75%.
- O grupo MEDIUM é composto por 44 rótulos com um suporte médio de 67 observações, que é aproximadamente duas vezes menor que o grupo HEAD. Espera-se que as métricas para este grupo diminuam em 50%: F1 – 52%, Precisão – 56%, Recall – 51%.
- O grupo TAIL possui o maior número de classes, mas todas estão mal representadas no conjunto de dados, com média de 40 observações de suporte por rótulo. Como resultado, as métricas caem significativamente: F1 – 21%, Precisão – 32%, Recall – 16%.
- O grupo ZERO inclui classes que o modelo não consegue reconhecer, possivelmente devido à sua baixa ocorrência no conjunto de dados. Cada um dos 24 rótulos desse grupo tem uma média de 7 observações de suporte.
A Figura 5 visualiza as informações apresentadas na Tabela 2, fornecendo uma representação visual das métricas por grupo de rótulos.
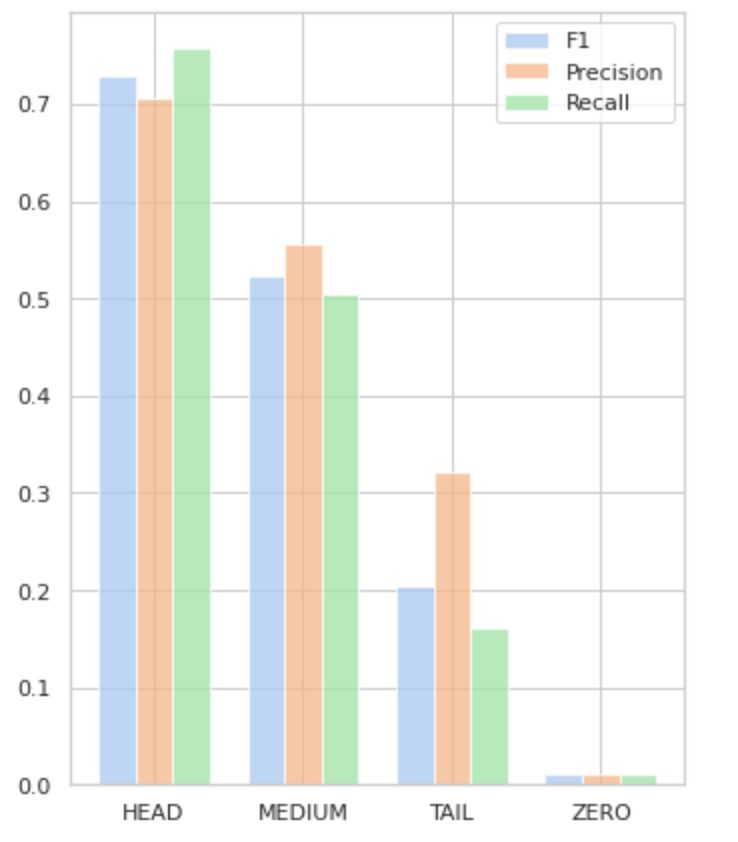
Figura 5. Métricas versus grupos de rótulos. Todos os valores ZERO = 0.
Neste artigo abrangente, demonstramos que uma tarefa aparentemente simples de classificação de texto com vários rótulos pode ser desafiadora quando métodos tradicionais são aplicados. Propusemos o uso de funções de perda de balanceamento de distribuição para lidar com a questão do desequilíbrio de classe.
Comparamos o desempenho de nossa abordagem proposta com o método clássico e o avaliamos usando métricas de negócios do mundo real. Os resultados demonstram que a utilização de funções de perda para resolver desequilíbrios de classes e co-ocorrências de rótulos oferece uma solução viável para a classificação de texto com vários rótulos.
O caso de uso proposto destaca a importância de considerar diferentes abordagens e técnicas ao lidar com a classificação de texto com vários rótulos e os benefícios potenciais das funções de perda de balanceamento de distribuição ao lidar com desequilíbrios de classe.
Se você está enfrentando um problema semelhante e está tentando simplificar as operações de processamento de documentos dentro de sua organização, entre em contato comigo ou com a equipe Provectus. Teremos o maior prazer em ajudá-lo a encontrar métodos mais eficientes para automatizar seus processos.
Oleksii Babych é Engenheiro de Machine Learning na Provectus. Com formação em física, ele possui excelentes habilidades analíticas e matemáticas e adquiriu uma experiência valiosa por meio de pesquisas científicas e apresentações em conferências internacionais, incluindo a SPIE Photonics West. A Oleksii é especializada na criação de soluções de IA/ML de ponta a ponta em grande escala para os setores de saúde e fintech. Ele está envolvido em cada estágio do ciclo de vida do desenvolvimento de ML, desde a identificação de problemas de negócios até a implantação e execução de modelos de ML de produção.
Rinat Akhmetov é o arquiteto de soluções de ML da Provectus. Com uma sólida formação prática em Machine Learning (especialmente em Visão Computacional), Rinat é um nerd, entusiasta de dados, engenheiro de software e workaholic cuja segunda maior paixão é a programação. Na Provectus, Rinat é responsável pelas fases de descoberta e prova de conceito e lidera a execução de projetos complexos de IA.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- Platoblockchain. Inteligência Metaverso Web3. Conhecimento Ampliado. Acesse aqui.
- Fonte: https://www.kdnuggets.com/2023/03/multilabel-nlp-analysis-class-imbalance-loss-function-approaches.html?utm_source=rss&utm_medium=rss&utm_campaign=multi-label-nlp-an-analysis-of-class-imbalance-and-loss-function-approaches
- :é
- 1
- 10
- 100
- 15%
- 67
- 7
- 9
- a
- Capaz
- Sobre
- Alcançar
- alcançado
- ações
- ativação
- adaptação
- endereço
- endereçando
- AI
- AI / ML
- visa
- algoritmo
- algoritmos
- Todos os Produtos
- permite
- alfa
- entre
- quantidade
- análise
- Análises
- análise
- e
- apareceu
- aplicado
- Aplicar
- abordagem
- se aproxima
- aproximadamente
- SOMOS
- artigo
- AS
- aspectos
- atribuído
- auxiliar
- associado
- At
- automatizando
- média
- fundo
- Equilíbrio
- baseado
- Linha de Base
- BE
- Porque
- abaixo
- Benefícios
- MELHOR
- beta
- Melhor
- entre
- viés
- O maior
- Inferior
- Caixa
- construídas em
- negócio
- by
- calculado
- CAN
- não podes
- capturar
- casas
- Categorias
- CB
- certo
- desafios
- desafiante
- Alterações
- carregar
- classe
- aulas
- clássico
- classificação
- cliente
- de perto
- mais próximo
- geralmente
- comparado
- comparando
- comparação
- integrações
- compreensivo
- computador
- Visão de Computador
- computação
- conceito
- Preocupações
- Concluído
- Conferência
- considerando
- Contacto
- contém
- conteúdo
- contexto
- contribuição
- cobre
- Criar
- cliente
- ciclo
- dados,
- lidar
- diminuir
- definido
- demonstrar
- demonstraram
- Implantação
- projetado
- detalhado
- Desenvolvimento
- diferenças
- diferente
- diretamente
- descoberta
- distinto
- distribuição
- distribuições
- diferente
- dividido
- documento
- INSTITUCIONAIS
- fazer
- domínio
- Cair
- cada
- facilmente
- Eficaz
- eficiente
- esforços
- permitir
- end-to-end
- engenheiro
- entusiasta
- igualmente
- erro
- especialmente
- Éter (ETH)
- avaliadas
- Cada
- evidência
- exemplo
- excelente
- execução
- esperado
- vasta experiência
- exploração
- explorar
- expresso
- f1
- enfrentou
- enfrentando
- retornos
- Figura
- final
- descoberta
- FinTech
- Primeiro nome
- Flutuador
- seguinte
- Escolha
- encontrado
- fração
- Frequência
- freqüente
- da
- função
- funcional
- funções
- mais distante
- Ganho
- dado
- Relance
- gráfico
- Verde
- Grupo
- Do grupo
- manipular
- feliz
- Ter
- cabeça
- saúde
- ajudar
- ajuda
- Alta
- superior
- mais
- destaques
- Como funciona o dobrador de carta de canal
- Como Negociar
- Contudo
- HTML
- http
- HTTPS
- identificado
- identificar
- desequilíbrio
- Impacto
- impactada
- implementação
- importar
- importância
- importante
- melhorar
- melhorar
- in
- inclui
- Incluindo
- incorretamente
- Crescimento
- aumentou
- aumentando
- independentemente
- indústrias
- INFORMAÇÕES
- inerente
- entrada
- instância
- em vez disso
- Internacionais
- investido
- envolvido
- emitem
- IT
- ESTÁ
- jpg
- apenas um
- KDnuggetsGenericName
- O rótulo
- marcação
- Rótulos
- língua
- em grande escala
- maior
- camada
- Leads
- APRENDER
- aprendido
- aprendizagem
- Nível
- vida
- Lista
- olhar
- fora
- perdas
- Baixo
- máquina
- aprendizado de máquina
- moldadas
- a Principal
- principal
- Maioria
- muitos
- mapeamento
- matemática
- máximo
- medidas
- média
- método
- métodos
- métrico
- Métrica
- mínimo
- ML
- MLB
- modelo
- modelos
- modificar
- módulo
- mais
- mais eficiente
- a maioria
- múltiplo
- Nomeado
- você merece...
- negativo
- negativamente
- Novo
- PNL
- normal
- notável
- número
- números
- numpy
- obter
- obtido
- of
- oferecer
- on
- ONE
- Oportunidade
- contrário
- Opções
- organização
- Outros
- de outra forma
- lado de fora
- marcante
- global
- parâmetro
- paixão
- padrões
- percentagem
- atuação
- Física
- peça
- platão
- Inteligência de Dados Platão
- PlatãoData
- por favor
- pontos
- PoS
- positivo
- potencial
- potencialmente
- Prática
- Precisão
- predizer
- previsto
- Previsões
- Previsões
- Apresentações
- apresentado
- Problema
- problemas
- processo
- processos
- em processamento
- produzir
- Produto
- Produção
- Programação
- projetos
- prova
- prova de conceito
- proposto
- fornecer
- fornecido
- fornece
- fornecendo
- pytorch
- aumentar
- alcance
- em vez
- mundo real
- reequilibrar
- recapitulação
- reconhecer
- reduzir
- Reduzido
- redução
- refere-se
- relações
- relevância
- relevante
- representação
- representado
- solicitar
- pesquisa
- resultar
- resultando
- Resultados
- retorno
- Retorna
- rever
- ROSE
- corrida
- s
- mesmo
- cenários
- Pesquisa científica
- Segundo
- busca
- selecionado
- AUTO
- sentimento
- separado
- serviço
- conjunto
- Conjuntos
- Shape
- mostrando
- Shows
- significado
- periodo
- de forma considerável
- semelhante
- simples
- simultaneamente
- solteiro
- Tamanho
- Habilidades
- So
- Software
- Engenheiro de Software
- sólido
- solução
- Soluções
- RESOLVER
- alguns
- especializada
- especificada
- Etapa
- Estágio
- padrão
- estatística
- Passo
- franco
- tal
- adequado
- aprendizagem supervisionada
- ajuda
- Apoiar
- mesa
- TAG
- Tire
- visadas
- Tarefa
- tarefas
- Profissionais
- técnicas
- teste
- ensaio
- Classificação de Texto
- que
- A
- as informações
- deles
- Eles
- si mesmos
- Este
- limiar
- Através da
- tempo
- vezes
- para
- topo
- tocha
- Total
- tocar
- para
- pista
- tradicional
- Trem
- Training
- Transformar
- Transformação
- transformado
- transformando
- trata
- verdadeiro
- tipicamente
- incertezas
- compreensão
- único
- us
- usar
- caso de uso
- Utilizando
- validação
- Valioso
- Valores
- vário
- viável
- visão
- vs
- peso
- Ocidente
- qual
- enquanto
- Wikipedia
- precisarão
- de
- dentro
- sem
- trabalhou
- investimentos
- zefirnet
- zero