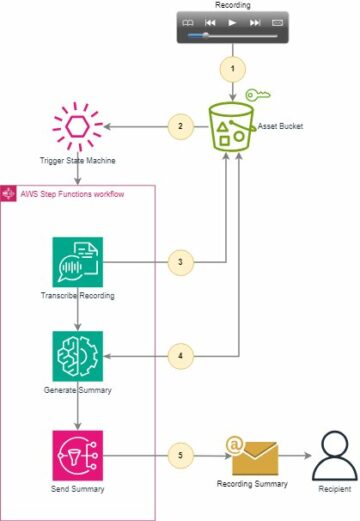
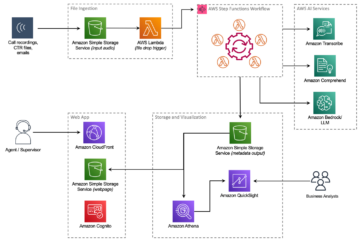
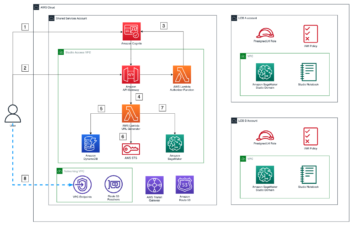
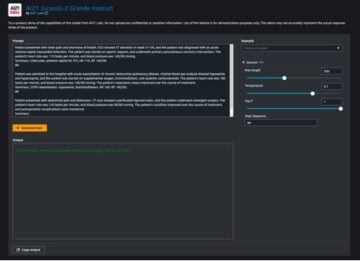
Amazon Sage Maker oferece um conjunto de algoritmos integrados, modelos pré-treinados e modelos de solução pré-criados para ajudar cientistas de dados e profissionais de machine learning (ML) a começar a treinar e implantar modelos de ML rapidamente. Você pode usar esses algoritmos e modelos para aprendizado supervisionado e não supervisionado. Eles podem processar vários tipos de dados de entrada, incluindo tabular, imagem e texto.
A partir de hoje, o SageMaker fornece quatro novos algoritmos de modelagem de dados tabulares integrados: LightGBM, CatBoost, AutoGluon-Tabular e TabTransformer. Você pode usar esses algoritmos populares e de última geração para tarefas de classificação tabular e de regressão. Estão disponíveis através do algoritmos integrados no console do SageMaker, bem como através do JumpStart do Amazon SageMaker IU dentro Estúdio Amazon SageMaker.
A seguir está a lista dos quatro novos algoritmos integrados, com links para sua documentação, notebooks de exemplo e fonte.
| Documentação | Notebooks de exemplo | fonte |
| Algoritmo LightGBM | Regressão, Classificação | Light GBM |
| Algoritmo CatBoost | Regressão, Classificação | Cat Boost |
| Algoritmo AutoGluon-Tabular | Regressão, Classificação | AutoGluon-Tabular |
| Algoritmo TabTransformer | Regressão, Classificação | TabTransformador |
Nas seções a seguir, fornecemos uma breve descrição técnica de cada algoritmo e exemplos de como treinar um modelo por meio do SageMaker SDK ou do SageMaker Jumpstart.
Light GBM
Light GBM é uma implementação de código aberto popular e eficiente do algoritmo Gradient Boosting Decision Tree (GBDT). GBDT é um algoritmo de aprendizado supervisionado que tenta prever com precisão uma variável alvo combinando um conjunto de estimativas de um conjunto de modelos mais simples e mais fracos. LightGBM usa técnicas adicionais para melhorar significativamente a eficiência e escalabilidade do GBDT convencional.
Cat Boost
Cat Boost é uma implementação de código aberto popular e de alto desempenho do algoritmo GBDT. Dois avanços algorítmicos críticos são introduzidos no CatBoost: a implementação de reforço ordenado, uma alternativa orientada por permutação ao algoritmo clássico e um algoritmo inovador para processar recursos categóricos. Ambas as técnicas foram criadas para combater uma mudança de previsão causada por um tipo especial de vazamento de alvo presente em todas as implementações atualmente existentes de algoritmos de aumento de gradiente.
AutoGluon-Tabular
AutoGluon-Tabular é um projeto de AutoML de código aberto desenvolvido e mantido pela Amazon que executa processamento avançado de dados, aprendizado profundo e conjunto de pilha de várias camadas. Ele reconhece automaticamente o tipo de dados em cada coluna para um pré-processamento robusto de dados, incluindo manipulação especial de campos de texto. O AutoGluon se adapta a vários modelos, desde árvores otimizadas prontas para uso até modelos de rede neural personalizados. Esses modelos são agrupados de uma maneira inovadora: os modelos são empilhados em várias camadas e treinados em camadas que garantem que os dados brutos possam ser traduzidos em previsões de alta qualidade dentro de uma determinada restrição de tempo. O ajuste excessivo é mitigado ao longo desse processo, dividindo os dados de várias maneiras com um rastreamento cuidadoso de exemplos fora da dobra. O AutoGluon é otimizado para desempenho e seu uso imediato alcançou várias posições entre os 3 e os 10 melhores em competições de ciência de dados.
TabTransformador
TabTransformador é uma nova arquitetura de modelagem de dados tabulares profundos para aprendizado supervisionado. O TabTransformer é construído sobre Transformers baseados em autoatenção. As camadas do Transformer transformam as incorporações de recursos categóricos em incorporações contextuais robustas para obter maior precisão de previsão. Além disso, as incorporações contextuais aprendidas com o TabTransformer são altamente robustas contra recursos de dados ausentes e ruidosos e fornecem melhor interpretabilidade. Este modelo é produto de recentes Ciência da Amazônia pesquisa (papel e oficial no blog aqui) e foi amplamente adotado pela comunidade ML, com várias implementações de terceiros (Keras, AutoGlúon,) e recursos de mídia social, como os tweets, em direção à ciência de dados, médio e Kaggle.
Benefícios dos algoritmos integrados do SageMaker
Ao selecionar um algoritmo para seu tipo específico de problema e dados, usar um algoritmo integrado do SageMaker é a opção mais fácil, pois isso traz os seguintes benefícios principais:
- Os algoritmos integrados não requerem codificação para iniciar os experimentos. As únicas entradas que você precisa fornecer são os dados, hiperparâmetros e recursos de computação. Isso permite que você execute experimentos mais rapidamente, com menos sobrecarga para rastrear resultados e alterações de código.
- Os algoritmos integrados vêm com paralelização em várias instâncias de computação e suporte a GPU pronto para uso para todos os algoritmos aplicáveis (alguns algoritmos podem não ser incluídos devido a limitações inerentes). Se você tiver muitos dados para treinar seu modelo, a maioria dos algoritmos integrados pode ser dimensionada facilmente para atender à demanda. Mesmo se você já tiver um modelo pré-treinado, ainda pode ser mais fácil usar seu corolário no SageMaker e inserir os hiperparâmetros que você já conhece, em vez de portá-lo e escrever um script de treinamento você mesmo.
- Você é o proprietário dos artefatos de modelo resultantes. Você pode pegar esse modelo e implantá-lo no SageMaker para vários padrões de inferência diferentes (confira todos os tipos de implantação disponíveis) e dimensionamento e gerenciamento fáceis de endpoints, ou você pode implantá-lo onde mais precisar.
Vamos agora ver como treinar um desses algoritmos integrados.
Treine um algoritmo integrado usando o SDK do SageMaker
Para treinar um modelo selecionado, precisamos obter o URI desse modelo, bem como o do script de treinamento e a imagem do contêiner usada para treinamento. Felizmente, essas três entradas dependem apenas do nome do modelo, versão (para uma lista dos modelos disponíveis, consulte Tabela de modelos disponíveis do JumpStart) e o tipo de instância em que você deseja treinar. Isso é demonstrado no trecho de código a seguir:
A train_model_id muda para lightgbm-regression-model se estamos lidando com um problema de regressão. Os IDs de todos os outros modelos apresentados neste post estão listados na tabela a seguir.
| Modelo | Tipo de Problema | ID do modelo |
| Light GBM | Classificação | lightgbm-classification-model |
| . | Regressão | lightgbm-regression-model |
| Cat Boost | Classificação | catboost-classification-model |
| . | Regressão | catboost-regression-model |
| AutoGluon-Tabular | Classificação | autogluon-classification-ensemble |
| . | Regressão | autogluon-regression-ensemble |
| TabTransformador | Classificação | pytorch-tabtransformerclassification-model |
| . | Regressão | pytorch-tabtransformerregression-model |
Em seguida, definimos onde nossa entrada está Serviço de armazenamento simples da Amazon (Amazônia S3). Estamos usando um conjunto de dados de amostra público para este exemplo. Também definimos para onde queremos que nossa saída vá e recuperamos a lista padrão de hiperparâmetros necessários para treinar o modelo selecionado. Você pode alterar o valor deles ao seu gosto.
Por fim, instanciamos um SageMaker Estimator com todas as entradas recuperadas e inicie o trabalho de treinamento com .fit, passando nosso URI do conjunto de dados de treinamento. o entry_point script fornecido é nomeado transfer_learning.py (o mesmo para outras tarefas e algoritmos), e o canal de dados de entrada passado para .fit deve ser nomeado training.
Observe que você pode treinar algoritmos integrados com SageMaker ajuste automático do modelo para selecionar os hiperparâmetros ideais e melhorar ainda mais o desempenho do modelo.
Treine um algoritmo integrado usando o SageMaker JumpStart
Você também pode treinar qualquer um desses algoritmos integrados com apenas alguns cliques por meio da interface do usuário do SageMaker JumpStart. JumpStart é um recurso do SageMaker que permite treinar e implantar algoritmos integrados e modelos pré-treinados de várias estruturas de ML e hubs de modelos por meio de uma interface gráfica. Ele também permite que você implante soluções de ML completas que unem modelos de ML e vários outros serviços da AWS para resolver um caso de uso direcionado.
Para mais informações, consulte Execute a classificação de texto com o Amazon SageMaker JumpStart usando os modelos TensorFlow Hub e Hugging Face.
Conclusão
Neste post, anunciamos o lançamento de quatro novos e poderosos algoritmos integrados para ML em conjuntos de dados tabulares agora disponíveis no SageMaker. Fornecemos uma descrição técnica do que são esses algoritmos, bem como um exemplo de trabalho de treinamento para LightGBM usando o SDK do SageMaker.
Traga seu próprio conjunto de dados e experimente esses novos algoritmos no SageMaker e confira os notebooks de amostra para usar algoritmos integrados disponíveis em GitHub.
Sobre os autores
![]() Dr.Xin Huang é um cientista aplicado para algoritmos integrados Amazon SageMaker JumpStart e Amazon SageMaker. Ele se concentra no desenvolvimento de algoritmos de aprendizado de máquina escaláveis. Seus interesses de pesquisa estão na área de processamento de linguagem natural, aprendizado profundo explicável em dados tabulares e análise robusta de agrupamento não paramétrico de espaço-tempo. Ele publicou muitos artigos em conferências ACL, ICDM, KDD e Royal Statistical Society: Series A journal.
Dr.Xin Huang é um cientista aplicado para algoritmos integrados Amazon SageMaker JumpStart e Amazon SageMaker. Ele se concentra no desenvolvimento de algoritmos de aprendizado de máquina escaláveis. Seus interesses de pesquisa estão na área de processamento de linguagem natural, aprendizado profundo explicável em dados tabulares e análise robusta de agrupamento não paramétrico de espaço-tempo. Ele publicou muitos artigos em conferências ACL, ICDM, KDD e Royal Statistical Society: Series A journal.
![]() Dr. é um cientista aplicado sênior com algoritmos integrados Amazon SageMaker JumpStart e Amazon SageMaker e ajuda a desenvolver algoritmos de aprendizado de máquina. Ele é um pesquisador ativo em aprendizado de máquina e inferência estatística e publicou muitos artigos nas conferências NeurIPS, ICML, ICLR, JMLR, ACL e EMNLP.
Dr. é um cientista aplicado sênior com algoritmos integrados Amazon SageMaker JumpStart e Amazon SageMaker e ajuda a desenvolver algoritmos de aprendizado de máquina. Ele é um pesquisador ativo em aprendizado de máquina e inferência estatística e publicou muitos artigos nas conferências NeurIPS, ICML, ICLR, JMLR, ACL e EMNLP.
 João moura é arquiteto de soluções especialista em IA/ML na Amazon Web Services. Ele se concentra principalmente em casos de uso de PNL e em ajudar os clientes a otimizar o treinamento e a implantação de modelos de Deep Learning. Ele também é um defensor ativo de soluções de ML de baixo código e hardware especializado em ML.
João moura é arquiteto de soluções especialista em IA/ML na Amazon Web Services. Ele se concentra principalmente em casos de uso de PNL e em ajudar os clientes a otimizar o treinamento e a implantação de modelos de Deep Learning. Ele também é um defensor ativo de soluções de ML de baixo código e hardware especializado em ML.
- Coinsmart. A melhor troca de Bitcoin e criptografia da Europa.
- Platoblockchain. Inteligência Metaverso Web3. Conhecimento Ampliado. ACESSO LIVRE.
- CryptoHawk. Radar Altcoin. Teste grátis.
- Fonte: https://aws.amazon.com/blogs/machine-learning/new-built-in-amazon-sagemaker-algorithms-for-tabular-data-modeling-lightgbm-catboost-autogluon-tabular-and-tabtransformer/
- "
- 100
- a
- Alcançar
- alcançado
- em
- ativo
- Adicional
- avançado
- avanços
- contra
- algoritmo
- algorítmico
- algoritmos
- Todos os Produtos
- permite
- já
- alternativa
- Amazon
- Amazon Web Services
- análise
- anunciou
- relevante
- aplicado
- arquitetura
- ÁREA
- Automático
- automaticamente
- disponível
- AWS
- Porque
- Benefícios
- Melhor
- Impulsionado
- impulsionar
- Caixa
- construídas em
- cuidadoso
- casas
- causado
- alterar
- clássico
- classificação
- código
- Codificação
- Coluna
- como
- comunidade
- Competições
- Computar
- conferências
- cônsul
- Recipiente
- crio
- criado
- crítico
- Atualmente
- personalizadas
- Clientes
- dados,
- informática
- ciência de dados
- lidar
- decisão
- profundo
- Demanda
- demonstraram
- implantar
- Implantação
- desenvolvimento
- descrição
- desenvolver
- desenvolvido
- em desenvolvimento
- diferente
- Estivador
- cada
- facilmente
- eficiência
- eficiente
- Ponto final
- estimativas
- exemplo
- exemplos
- existente
- Rosto
- Característica
- Funcionalidades
- Campos
- focado
- concentra-se
- seguinte
- enquadramentos
- da
- mais distante
- Além disso
- GPU
- Manipulação
- Hardware
- altura
- ajudar
- ajuda
- ajuda
- SUA PARTICIPAÇÃO FAZ A DIFERENÇA
- alta qualidade
- superior
- altamente
- Como funciona o dobrador de carta de canal
- Como Negociar
- HTTPS
- Hub
- imagem
- implementação
- melhorar
- incluído
- Incluindo
- INFORMAÇÕES
- inerente
- inovadores
- entrada
- instância
- interesses
- Interface
- IT
- Trabalho
- revista
- Saber
- língua
- lançamento
- aprendido
- aprendizagem
- Links
- Lista
- Listado
- máquina
- aprendizado de máquina
- principal
- de grupos
- maneira
- Mídia
- média
- ML
- modelo
- modelos
- mais
- a maioria
- múltiplo
- natural
- rede
- Otimize
- otimizado
- Opção
- Outros
- próprio
- proprietário
- particular
- Passagem
- atuação
- Popular
- poderoso
- predizer
- predição
- Previsões
- presente
- Problema
- processo
- em processamento
- Produto
- projeto
- fornecer
- fornecido
- fornece
- público
- publicado
- rapidamente
- variando
- Cru
- reconhece
- região
- requerer
- pesquisa
- Recursos
- resultando
- Resultados
- Execute
- corrida
- mesmo
- AMPLIAR
- escalável
- Escala
- dimensionamento
- Ciência
- Cientista
- cientistas
- Sdk
- selecionado
- Série
- Série A
- Serviços
- conjunto
- vários
- mudança
- simples
- So
- Redes Sociais
- meios de comunicação social
- Sociedade
- solução
- Soluções
- RESOLVER
- alguns
- especial
- especialista
- pilha
- começo
- começado
- estado-da-arte
- estatístico
- Ainda
- armazenamento
- ajuda
- Target
- visadas
- tarefas
- Dados Técnicos:
- técnicas
- A
- De terceiros
- três
- Através da
- todo
- tempo
- hoje
- juntos
- Rastreamento
- Trem
- Training
- Transformar
- tipos
- ui
- único
- usar
- casos de uso
- valor
- vário
- versão
- maneiras
- web
- serviços web
- O Quê
- dentro
- investimentos