Esta série de três partes demonstra como usar redes neurais gráficas (GNNs) e Amazon Netuno para gerar recomendações de filmes usando o IMDb e Box Office Mojo Filmes/TV/OTT pacote de dados licenciáveis, que fornece uma ampla variedade de metadados de entretenimento, incluindo mais de 1 bilhão de classificações de usuários; créditos para mais de 11 milhões de membros do elenco e da equipe; 9 milhões de títulos de filmes, TV e entretenimento; e dados de relatórios de bilheteria global de mais de 60 países. Muitos clientes de mídia e entretenimento da AWS licenciam dados IMDb por meio de Troca de dados da AWS para melhorar a descoberta de conteúdo e aumentar o envolvimento e a retenção do cliente.
In Parte 1, discutimos as aplicações de GNNs e como transformar e preparar nossos dados IMDb para consulta. Nesta postagem, discutimos o processo de uso do Neptune para gerar incorporações usadas para conduzir nossa pesquisa fora do catálogo na Parte 3 . Nós também passamos por cima Amazon Netuno ML, o recurso de aprendizado de máquina (ML) do Neptune e o código que usamos em nosso processo de desenvolvimento. Na Parte 3, mostramos como aplicar nossas incorporações de gráfico de conhecimento a um caso de uso de pesquisa fora do catálogo.
Visão geral da solução
Grandes conjuntos de dados conectados geralmente contêm informações valiosas que podem ser difíceis de extrair usando consultas baseadas apenas na intuição humana. As técnicas de ML podem ajudar a encontrar correlações ocultas em gráficos com bilhões de relacionamentos. Essas correlações podem ser úteis para recomendar produtos, prever o valor do crédito, identificar fraudes e muitos outros casos de uso.
O Neptune ML torna possível construir e treinar modelos úteis de ML em grandes gráficos em horas, em vez de semanas. Para conseguir isso, o Neptune ML usa a tecnologia GNN desenvolvida por Amazon Sage Maker e os votos de Biblioteca de gráficos profundos (DGL) (qual é de código aberto). GNNs são um campo emergente na inteligência artificial (por exemplo, veja Uma pesquisa abrangente sobre redes neurais gráficas). Para obter um tutorial prático sobre como usar GNNs com o DGL, consulte Aprendendo redes neurais gráficas com Deep Graph Library.
Neste post, mostramos como usar o Neptune em nosso pipeline para gerar embeddings.
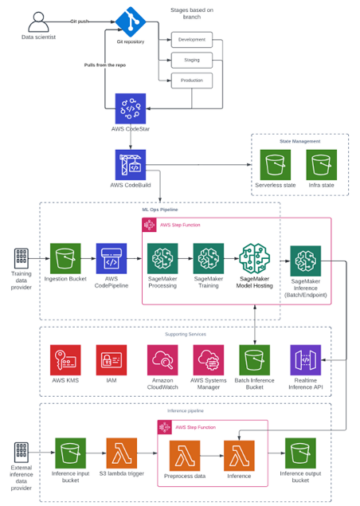
O diagrama a seguir descreve o fluxo geral de dados IMDb desde o download até a geração de incorporação.
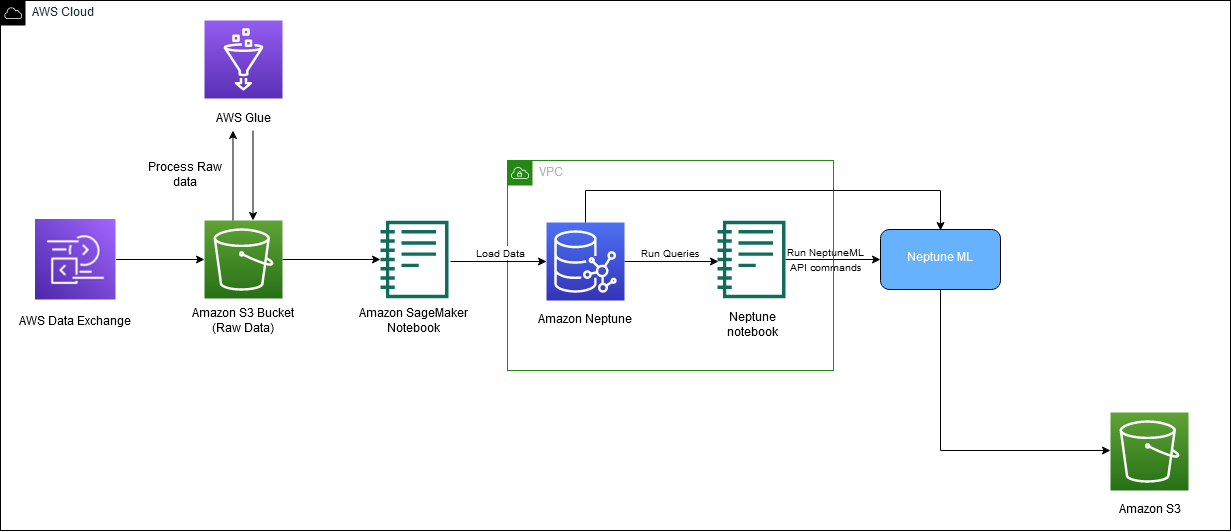
Utilizamos os seguintes serviços da AWS para implementar a solução:
Nesta postagem, orientamos você pelas seguintes etapas de alto nível:
- Configurar variáveis de ambiente
- Crie um trabalho de exportação.
- Crie um trabalho de processamento de dados.
- Envie um trabalho de treinamento.
- Baixar incorporações.
Código para comandos Neptune ML
Usamos os seguintes comandos como parte da implementação desta solução:
Usamos neptune_ml export para verificar o status ou iniciar um processo de exportação do Neptune ML e neptune_ml training para iniciar e verificar o status de um trabalho de treinamento do modelo Neptune ML.
Para obter mais informações sobre esses e outros comandos, consulte Usando as mágicas da bancada de trabalho Neptune em seus notebooks.
Pré-requisitos
Para acompanhar este post, você deve ter o seguinte:
- An Conta da AWS
- Familiaridade com SageMaker, Amazon S3 e AWS CloudFormation
- Dados do gráfico carregados no cluster Neptune (consulte Parte 1 para mais informações)
Configurar variáveis de ambiente
Antes de começarmos, você precisará configurar seu ambiente definindo as seguintes variáveis: s3_bucket_uri e processed_folder. s3_bucket_uri é o nome do bucket usado na Parte 1 e processed_folder é o local do Amazon S3 para a saída do trabalho de exportação.
Criar um trabalho de exportação
Na Parte 1, criamos um notebook SageMaker e um serviço de exportação para exportar nossos dados do cluster de banco de dados Neptune para o Amazon S3 no formato necessário.
Agora que nossos dados foram carregados e o serviço de exportação criado, precisamos criar um trabalho de exportação e iniciá-lo. Para fazer isso, usamos NeptuneExportApiUri e crie parâmetros para o trabalho de exportação. No código a seguir, usamos as variáveis expo e export_params. Conjunto expo para o seu NeptuneExportApiUri valor, que você pode encontrar no Saídas guia da pilha do CloudFormation. Para export_params, usamos o endpoint de seu cluster Neptune e fornecemos o valor para outputS3path, que é o local do Amazon S3 para a saída do trabalho de exportação.
Para enviar o trabalho de exportação, use o seguinte comando:
Para verificar o status do trabalho de exportação, use o seguinte comando:
Após a conclusão do trabalho, defina o processed_folder variável para fornecer a localização do Amazon S3 dos resultados processados:
Criar um trabalho de processamento de dados
Agora que a exportação está concluída, criamos um trabalho de processamento de dados para preparar os dados para o processo de treinamento do Neptune ML. Isso pode ser feito de algumas maneiras diferentes. Para esta etapa, você pode alterar o job_name e modelType variáveis, mas todos os outros parâmetros devem permanecer os mesmos. A parte principal deste código é o modelType parâmetro, que podem ser modelos de grafos heterogêneos (heterogeneous) ou gráficos de conhecimento (kge).
O trabalho de exportação também inclui training-data-configuration.json. Use este arquivo para adicionar ou remover quaisquer nós ou bordas que você não deseja fornecer para treinamento (por exemplo, se você deseja prever o link entre dois nós, pode remover esse link neste arquivo de configuração). Para esta postagem do blog, usamos o arquivo de configuração original. Para informações adicionais, consulte Editando um arquivo de configuração de treinamento.
Crie seu trabalho de processamento de dados com o seguinte código:
Para verificar o status do trabalho de exportação, use o seguinte comando:
Enviar um trabalho de treinamento
Após a conclusão do trabalho de processamento, podemos começar nosso trabalho de treinamento, onde criamos nossos embeddings. Recomendamos um tipo de instância de ml.m5.24xlarge, mas você pode alterá-lo para atender às suas necessidades de computação. Veja o seguinte código:
Imprimimos a variável training_results para obter o ID do trabalho de treinamento. Use o seguinte comando para verificar o status do seu trabalho:
%neptune_ml training status --job-id {training_results['id']} --store-to training_status_results
Baixar incorporações
Após a conclusão do trabalho de treinamento, a última etapa é fazer o download das incorporações brutas. As etapas a seguir mostram como baixar embeddings criados usando KGE (você pode usar o mesmo processo para RGCN).
No código a seguir, usamos neptune_ml.get_mapping() e get_embeddings() para baixar o arquivo de mapeamento (mapping.info) e o arquivo raw embeddings (entity.npy). Em seguida, precisamos mapear as incorporações apropriadas para seus IDs correspondentes.
Para baixar RGCNs, siga o mesmo processo com um novo nome de trabalho de treinamento processando os dados com o parâmetro modelType definido como heterogeneous, treinando seu modelo com o parâmetro modelName definido como rgcn Vejo SUA PARTICIPAÇÃO FAZ A DIFERENÇA para mais detalhes. Feito isso, ligue para o get_mapping e get_embeddings funções para baixar seu novo mapeamento.info e entidade.npy arquivos. Depois de ter os arquivos de entidade e mapeamento, o processo para criar o arquivo CSV é idêntico.
Por fim, faça upload de suas incorporações para o local desejado do Amazon S3:
Certifique-se de lembrar este local S3, você precisará usá-lo na Parte 3.
limpar
Quando terminar de usar a solução, certifique-se de limpar todos os recursos para evitar cobranças contínuas.
Conclusão
Nesta postagem, discutimos como usar o Neptune ML para treinar incorporações GNN a partir de dados IMDb.
Algumas aplicações relacionadas de incorporações de gráfico de conhecimento são conceitos como pesquisa fora do catálogo, recomendações de conteúdo, publicidade direcionada, previsão de links ausentes, pesquisa geral e análise de coorte. A pesquisa fora do catálogo é o processo de pesquisa de conteúdo que não pertence a você e de localização ou recomendação de conteúdo que esteja em seu catálogo que seja o mais próximo possível do que o usuário pesquisou. Nós nos aprofundamos na pesquisa fora do catálogo na Parte 3.
Sobre os autores
 Mateus Rodes é um cientista de dados que trabalha no laboratório de soluções do Amazon ML. Ele é especialista na construção de pipelines de Machine Learning que envolvem conceitos como Processamento de Linguagem Natural e Visão Computacional.
Mateus Rodes é um cientista de dados que trabalha no laboratório de soluções do Amazon ML. Ele é especialista na construção de pipelines de Machine Learning que envolvem conceitos como Processamento de Linguagem Natural e Visão Computacional.
 Divya Bhargavi é cientista de dados e líder vertical de mídia e entretenimento no Amazon ML Solutions Lab, onde resolve problemas de negócios de alto valor para clientes da AWS usando Machine Learning. Ela trabalha com compreensão de imagem/vídeo, sistemas de recomendação de gráfico de conhecimento, casos de uso de publicidade preditiva.
Divya Bhargavi é cientista de dados e líder vertical de mídia e entretenimento no Amazon ML Solutions Lab, onde resolve problemas de negócios de alto valor para clientes da AWS usando Machine Learning. Ela trabalha com compreensão de imagem/vídeo, sistemas de recomendação de gráfico de conhecimento, casos de uso de publicidade preditiva.
 Gaurav Rele é cientista de dados no Amazon ML Solution Lab, onde trabalha com clientes da AWS em diferentes setores para acelerar o uso de aprendizado de máquina e serviços de nuvem da AWS para resolver seus desafios de negócios.
Gaurav Rele é cientista de dados no Amazon ML Solution Lab, onde trabalha com clientes da AWS em diferentes setores para acelerar o uso de aprendizado de máquina e serviços de nuvem da AWS para resolver seus desafios de negócios.
 Karan Sindwani é cientista de dados no Amazon ML Solutions Lab, onde cria e implanta modelos de aprendizado profundo. Ele é especialista na área de visão computacional. Nas horas vagas, gosta de fazer caminhadas.
Karan Sindwani é cientista de dados no Amazon ML Solutions Lab, onde cria e implanta modelos de aprendizado profundo. Ele é especialista na área de visão computacional. Nas horas vagas, gosta de fazer caminhadas.
 Soji Adeshina é um cientista aplicado na AWS, onde desenvolve modelos baseados em redes neurais de grafos para aprendizado de máquina em tarefas de grafos com aplicativos para fraude e abuso, grafos de conhecimento, sistemas de recomendação e ciências biológicas. Nas horas vagas gosta de ler e cozinhar.
Soji Adeshina é um cientista aplicado na AWS, onde desenvolve modelos baseados em redes neurais de grafos para aprendizado de máquina em tarefas de grafos com aplicativos para fraude e abuso, grafos de conhecimento, sistemas de recomendação e ciências biológicas. Nas horas vagas gosta de ler e cozinhar.
 Vidya Sagar Ravipati é gerente do Amazon ML Solutions Lab, onde aproveita sua vasta experiência em sistemas distribuídos de grande escala e sua paixão por aprendizado de máquina para ajudar os clientes da AWS em diferentes verticais do setor a acelerar a adoção de IA e nuvem.
Vidya Sagar Ravipati é gerente do Amazon ML Solutions Lab, onde aproveita sua vasta experiência em sistemas distribuídos de grande escala e sua paixão por aprendizado de máquina para ajudar os clientes da AWS em diferentes verticais do setor a acelerar a adoção de IA e nuvem.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- Platoblockchain. Inteligência Metaverso Web3. Conhecimento Ampliado. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/part-2-power-recommendations-and-search-using-an-imdb-knowledge-graph/
- 1
- 10
- 100
- 11
- 116
- 7
- 9
- a
- Sobre
- abuso
- acelerar
- em
- Adicional
- Informação adicional
- Adoção
- Publicidade
- Depois de
- AI
- Todos os Produtos
- sozinho
- Amazon
- Laboratório de soluções de ML da Amazon
- análise
- e
- aplicações
- aplicado
- Aplicar
- apropriado
- ÁREA
- artificial
- inteligência artificial
- AWS
- baseado
- entre
- bilhão
- bilhões
- Blog
- Caixa
- bilheteria
- construir
- Prédio
- Constrói
- negócio
- chamada
- casas
- casos
- catálogo
- desafios
- alterar
- acusações
- verificar
- Fechar
- Na nuvem
- adoção de nuvem
- serviços na nuvem
- Agrupar
- código
- grupo
- completar
- compreensivo
- computador
- Visão de Computador
- computação
- conceitos
- Conduzir
- Configuração
- conectado
- conteúdo
- Correspondente
- países
- crio
- criado
- crédito
- Créditos
- cliente
- O envolvimento do cliente é aprimorado em uma relação direta e personalizada.
- Clientes
- dados,
- informática
- cientista de dados
- conjuntos de dados
- profundo
- deep learning
- mais profunda
- implanta
- detalhes
- Desenvolvimento
- desenvolve
- dgl
- diferente
- descoberta
- discutir
- discutido
- distribuído
- Sistemas distribuídos
- não
- download
- ou
- emergente
- Ponto final
- COMPROMETIMENTO
- Entretenimento
- entidade
- Meio Ambiente
- Éter (ETH)
- exemplo
- vasta experiência
- exportar
- extrato
- Característica
- poucos
- campo
- Envie o
- Arquivos
- Encontre
- descoberta
- fluxo
- seguir
- seguinte
- formato
- fraude
- da
- cheio
- funções
- Geral
- gerar
- geração
- ter
- Global
- Go
- gráfico
- gráficos
- mãos em
- Queijos duros
- ajudar
- útil
- oculto
- de alto nível
- HORÁRIO
- Como funciona o dobrador de carta de canal
- Como Negociar
- HTML
- HTTPS
- humano
- idêntico
- identificar
- executar
- implementação
- melhorar
- in
- inclui
- Incluindo
- Crescimento
- índice
- indústria
- info
- INFORMAÇÕES
- instância
- em vez disso
- Inteligência
- envolver
- IT
- Trabalho
- json
- Chave
- Conhecimento
- laboratório
- língua
- grande
- em grande escala
- Sobrenome
- conduzir
- aprendizagem
- aproveita as
- Biblioteca
- Licença
- vida
- Ciências da Vida
- LINK
- Links
- localização
- máquina
- aprendizado de máquina
- a Principal
- FAZ
- Gerente
- muitos
- mapa,
- mapeamento
- Mídia
- média
- Membros
- metadados
- milhão
- desaparecido
- ML
- modelo
- modelos
- mais
- filme
- nome
- natural
- Processamento de linguagem natural
- você merece...
- Cria
- Netuno
- baseado em rede
- redes
- redes neurais
- Novo
- nós
- caderno
- Office
- contínuo
- original
- Outros
- global
- próprio
- pacote
- parâmetro
- parâmetros
- parte
- paixão
- oleoduto
- platão
- Inteligência de Dados Platão
- PlatãoData
- possível
- Publique
- poder
- alimentado
- predizer
- prevendo
- Preparar
- Impressão
- problemas
- processo
- em processamento
- Produtos
- Perfil
- fornecer
- fornece
- alcance
- avaliações
- Cru
- Leitura
- recomendar
- Recomendação
- recomendações
- recomendando
- relacionado
- Relacionamentos
- permanecem
- lembrar
- remover
- Relatórios
- requeridos
- Recursos
- Resultados
- retenção
- sábio
- mesmo
- CIÊNCIAS
- Cientista
- Pesquisar
- pesquisar
- Série
- serviço
- Serviços
- conjunto
- contexto
- rede de apoio social
- mostrar
- solução
- Soluções
- RESOLVER
- Resolve
- especializada
- pilha
- começo
- Status
- Passo
- Passos
- loja
- enviar
- tal
- terno
- Vistorias
- sistemas
- visadas
- tarefas
- técnicas
- Equipar
- A
- A área
- deles
- Através da
- tempo
- títulos
- para
- Trem
- Training
- Transformar
- verdadeiro
- tutorial
- tv
- compreensão
- usar
- caso de uso
- Utilizador
- Valioso
- valor
- Grande
- versão
- Verticais
- visão
- maneiras
- semanas
- O Quê
- qual
- Largo
- Ampla variedade
- precisarão
- trabalhar
- trabalho
- investimentos
- zefirnet