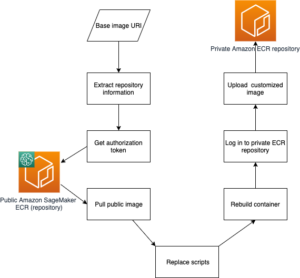
Na visão computacional, a segmentação semântica é a tarefa de classificar cada pixel em uma imagem com uma classe de um conjunto conhecido de rótulos, de modo que os pixels com o mesmo rótulo compartilhem certas características. Gera uma máscara de segmentação das imagens de entrada. Por exemplo, as imagens a seguir mostram uma máscara de segmentação do cat rótulo.
 |
 |
Em Novembro de 2018, Amazon Sage Maker anunciou o lançamento do algoritmo de segmentação semântica SageMaker. Com esse algoritmo, você pode treinar seus modelos com um conjunto de dados público ou seu próprio conjunto de dados. Conjuntos de dados de segmentação de imagens populares incluem o conjunto de dados Common Objects in Context (COCO) e PASCAL Visual Object Classes (PASCAL VOC), mas as classes de seus rótulos são limitadas e você pode querer treinar um modelo em objetos de destino que não estão incluídos no conjuntos de dados públicos. Neste caso, você pode usar Verdade no solo do Amazon SageMaker para rotular seu próprio conjunto de dados.
Neste post, demonstro as seguintes soluções:
- Usando o Ground Truth para rotular um conjunto de dados de segmentação semântica
- Transformando os resultados do Ground Truth para o formato de entrada necessário para o algoritmo de segmentação semântica integrado do SageMaker
- Usando o algoritmo de segmentação semântica para treinar um modelo e realizar inferência
Rotulagem de dados de segmentação semântica
Para construir um modelo de aprendizado de máquina para segmentação semântica, precisamos rotular um conjunto de dados no nível de pixel. O Ground Truth oferece a opção de usar anotadores humanos por meio de Amazon Mechanical Turk, fornecedores terceirizados ou sua própria força de trabalho privada. Para saber mais sobre a força de trabalho, consulte Criar e gerenciar forças de trabalho. Se você não quiser gerenciar a força de trabalho de rotulagem por conta própria, Amazon SageMaker Ground Truth Plus é outra ótima opção como um novo serviço de rotulagem de dados pronto para uso que permite criar conjuntos de dados de treinamento de alta qualidade rapidamente e reduz os custos em até 40%. Para esta postagem, mostro como rotular manualmente o conjunto de dados com o recurso de segmentação automática do Ground Truth e rotulagem de crowdsource com uma força de trabalho Mechanical Turk.
Rotulagem manual com Ground Truth
Em dezembro de 2019, o Ground Truth adicionou um recurso de segmentação automática à interface do usuário de rotulagem de segmentação semântica para aumentar a taxa de transferência de rotulagem e melhorar a precisão. Para obter mais informações, consulte Objetos de segmentação automática ao executar rotulagem de segmentação semântica com o Amazon SageMaker Ground Truth. Com este novo recurso, você pode acelerar seu processo de rotulagem em tarefas de segmentação. Em vez de desenhar um polígono bem ajustado ou usar a ferramenta pincel para capturar um objeto em uma imagem, você desenha apenas quatro pontos: nos pontos superior, inferior, esquerdo e direito do objeto. O Ground Truth usa esses quatro pontos como entrada e usa o algoritmo Deep Extreme Cut (DEXTR) para produzir uma máscara bem ajustada ao redor do objeto. Para um tutorial usando o Ground Truth para rotulagem de segmentação semântica de imagem, consulte Segmentação Semântica de Imagem. Veja a seguir um exemplo de como a ferramenta de segmentação automática gera uma máscara de segmentação automaticamente depois que você escolhe os quatro pontos extremos de um objeto.


Rotulagem de crowdsourcing com uma força de trabalho Mechanical Turk
Se você tiver um grande conjunto de dados e não quiser rotular manualmente centenas ou milhares de imagens, poderá usar o Mechanical Turk, que fornece uma força de trabalho humana escalável sob demanda para concluir trabalhos que os humanos podem fazer melhor do que os computadores. O software Mechanical Turk formaliza ofertas de trabalho para milhares de trabalhadores dispostos a fazer um trabalho fragmentado conforme sua conveniência. O software também recupera o trabalho realizado e o compila para você, o solicitante, que paga aos trabalhadores pelo trabalho satisfatório (somente). Para começar com o Mechanical Turk, consulte Introdução ao Amazon Mechanical Turk.
Criar um trabalho de rotulagem
Veja a seguir um exemplo de um trabalho de rotulagem Mechanical Turk para um conjunto de dados de tartarugas marinhas. O conjunto de dados de tartarugas marinhas é da competição Kaggle Detecção de rosto de tartaruga marinha, e selecionei 300 imagens do conjunto de dados para fins de demonstração. Tartaruga marinha não é uma classe comum em conjuntos de dados públicos, portanto, pode representar uma situação que requer rotular um conjunto de dados massivo.
- No console SageMaker, escolha Trabalhos de rotulagem no painel de navegação.
- Escolha Criar trabalho de rotulagem.
- Digite um nome para o seu trabalho.
- Escolha Configuração de dados de entrada, selecione Configuração de dados automatizada.
Isso gera um manifesto de dados de entrada. - Escolha Localização do S3 para conjuntos de dados de entrada, insira o caminho para o conjunto de dados.

- Escolha Categoria da tarefa, escolha Imagem.
- Escolha Seleção de tarefas, selecione Segmentação semântica.

- Escolha Tipos de trabalhadores, selecione Amazon Mechanical Turk.
- Defina suas configurações para tempo limite da tarefa, tempo de expiração da tarefa e preço por tarefa.

- Adicione um marcador (para esta postagem,
sea turtle) e fornecer instruções de rotulagem. - Escolha Crie.

Depois de configurar o trabalho de rotulagem, você pode verificar o andamento da rotulagem no console do SageMaker. Quando estiver marcado como concluído, você poderá escolher o trabalho para verificar os resultados e usá-los para as próximas etapas.

Transformação do conjunto de dados
Depois de obter a saída do Ground Truth, você pode usar os algoritmos integrados do SageMaker para treinar um modelo nesse conjunto de dados. Primeiro, você precisa preparar o conjunto de dados rotulado como a interface de entrada solicitada para o algoritmo de segmentação semântica do SageMaker.
Canais de dados de entrada solicitados
A segmentação semântica do SageMaker espera que seu conjunto de dados de treinamento seja armazenado em Serviço de armazenamento simples da Amazon (Amazônia S3). Espera-se que o conjunto de dados no Amazon S3 seja apresentado em dois canais, um para train e um para validation, usando quatro diretórios, dois para imagens e dois para anotações. Espera-se que as anotações sejam imagens PNG não compactadas. O conjunto de dados também pode ter um mapa de rótulos que descreve como os mapeamentos de anotação são estabelecidos. Caso contrário, o algoritmo usa um padrão. Para inferência, um endpoint aceita imagens com um image/jpeg tipo de conteúdo. A seguir está a estrutura necessária dos canais de dados:
Cada imagem JPG nos diretórios de trem e validação tem uma imagem de rótulo PNG correspondente com o mesmo nome no train_annotation e validation_annotation diretórios. Essa convenção de nomenclatura ajuda o algoritmo a associar um rótulo à imagem correspondente durante o treinamento. O trem, train_annotation, validação e validation_annotation canais são obrigatórios. As anotações são imagens PNG de canal único. O formato funciona desde que os metadados (modos) na imagem ajudem o algoritmo a ler as imagens de anotação em um inteiro sem sinal de 8 bits de canal único.
Saída do trabalho de rotulagem do Ground Truth
As saídas geradas do trabalho de rotulagem do Ground Truth têm a seguinte estrutura de pastas:
As máscaras de segmentação são salvas em s3://turtle2022/labelturtles/annotations/consolidated-annotation/output. Cada imagem de anotação é um arquivo .png com o nome do índice da imagem de origem e a hora em que a rotulagem da imagem foi concluída. Por exemplo, a seguir estão a imagem de origem (Image_1.jpg) e sua máscara de segmentação gerada pela força de trabalho do Mechanical Turk (0_2022-02-10T17:41:04.724225.png). Observe que o índice da máscara é diferente do número no nome da imagem de origem.
 |
 |
O manifesto de saída do trabalho de rotulagem está no /manifests/output/output.manifest Arquivo. É um arquivo JSON e cada linha registra um mapeamento entre a imagem de origem e seu rótulo e outros metadados. A seguinte linha JSON registra um mapeamento entre a imagem de origem mostrada e sua anotação:
A imagem de origem é chamada Image_1.jpg e o nome da anotação é 0_2022-02-10T17:41: 04.724225.png. Para preparar os dados como os formatos de canal de dados necessários do algoritmo de segmentação semântica SageMaker, precisamos alterar o nome da anotação para que tenha o mesmo nome das imagens JPG de origem. E também precisamos dividir o conjunto de dados em train e validation diretórios para imagens de origem e as anotações.
Transforme a saída de um trabalho de rotulagem do Ground Truth para o formato de entrada solicitado
Para transformar a saída, conclua as etapas a seguir:
- Faça download de todos os arquivos do trabalho de rotulagem do Amazon S3 para um diretório local:
- Leia o arquivo de manifesto e altere os nomes da anotação para os mesmos nomes das imagens de origem:
- Divida os conjuntos de dados de trem e validação:
- Crie um diretório no formato necessário para os canais de dados do algoritmo de segmentação semântica:
- Mova as imagens de trem e validação e suas anotações para os diretórios criados.
- Para imagens, use o seguinte código:
- Para anotações, use o seguinte código:
- Carregue os conjuntos de dados de treinamento e validação e seus conjuntos de dados de anotação no Amazon S3:
Treinamento do modelo de segmentação semântica do SageMaker
Nesta seção, percorremos as etapas para treinar seu modelo de segmentação semântica.
Siga o notebook de exemplo e configure os canais de dados
Você pode seguir as instruções em O algoritmo de segmentação semântica já está disponível no Amazon SageMaker para implementar o algoritmo de segmentação semântica em seu conjunto de dados rotulado. Esta amostra caderno mostra um exemplo de ponta a ponta introduzindo o algoritmo. No notebook, você aprende como treinar e hospedar um modelo de segmentação semântica usando a rede totalmente convolucional (FCN) algoritmo usando o Conjunto de dados Pascal VOC para treinamento. Como não pretendo treinar um modelo do conjunto de dados Pascal VOC, ignorei a Etapa 3 (preparação de dados) neste notebook. Em vez disso, criei diretamente train_channel, train_annotation_channe, validation_channel e validation_annotation_channel usando os locais do S3 onde armazenei minhas imagens e anotações:
Ajuste hiperparâmetros para seu próprio conjunto de dados no estimador SageMaker
Eu segui o notebook e criei um objeto estimador do SageMaker (ss_estimator) para treinar meu algoritmo de segmentação. Uma coisa que precisamos personalizar para o novo conjunto de dados está em ss_estimator.set_hyperparameters: precisamos mudar num_classes=21 para num_classes=2 (turtle e background), e também mudei epochs=10 para epochs=30 porque 10 é apenas para fins de demonstração. Em seguida, usei a instância p3.2xlarge para treinamento de modelo definindo instance_type="ml.p3.2xlarge". O treinamento foi concluído em 8 minutos. Ao melhor MIOU (Mean Intersection over Union) de 0.846 é alcançado na época 11 com um pix_acc (a porcentagem de pixels em sua imagem que são classificados corretamente) de 0.925, o que é um resultado muito bom para esse pequeno conjunto de dados.
Resultados de inferência do modelo
Hospedei o modelo em uma instância ml.c5.xlarge de baixo custo:
Por fim, preparei um conjunto de teste de 10 imagens de tartaruga para ver o resultado da inferência do modelo de segmentação treinado:
As imagens a seguir mostram os resultados.

As máscaras de segmentação das tartarugas marinhas parecem precisas e estou feliz com esse resultado treinado em um conjunto de dados de 300 imagens rotulado por trabalhadores da Mechanical Turk. Você também pode explorar outras redes disponíveis, como rede de análise de cena de pirâmide (PSP) or DeepLab-V3 no notebook de amostra com seu conjunto de dados.
limpar
Exclua o endpoint quando terminar com ele para evitar custos contínuos:
Conclusão
Neste post, mostrei como personalizar a rotulagem de dados de segmentação semântica e o treinamento de modelos usando o SageMaker. Primeiro, você pode configurar um trabalho de rotulagem com a ferramenta de segmentação automática ou usar uma força de trabalho Mechanical Turk (assim como outras opções). Se você tiver mais de 5,000 objetos, também poderá usar a rotulagem de dados automatizada. Em seguida, você transforma as saídas do seu trabalho de rotulagem do Ground Truth para os formatos de entrada necessários para o treinamento de segmentação semântica integrado do SageMaker. Depois disso, você pode usar uma instância de computação acelerada (como p2 ou p3) para treinar um modelo de segmentação semântica com o seguinte caderno e implemente o modelo em uma instância mais econômica (como ml.c5.xlarge). Por fim, você pode revisar os resultados da inferência em seu conjunto de dados de teste com algumas linhas de código.
Comece com a segmentação semântica do SageMaker rotulagem de dados e treinamento de modelo com seu conjunto de dados favorito!
Sobre o autor
 Kara Yang é um cientista de dados nos serviços profissionais da AWS. Ela é apaixonada por ajudar os clientes a atingir suas metas de negócios com os serviços de nuvem da AWS. Ela ajudou organizações a criar soluções de ML em vários setores, como manufatura, automotivo, sustentabilidade ambiental e aeroespacial.
Kara Yang é um cientista de dados nos serviços profissionais da AWS. Ela é apaixonada por ajudar os clientes a atingir suas metas de negócios com os serviços de nuvem da AWS. Ela ajudou organizações a criar soluções de ML em vários setores, como manufatura, automotivo, sustentabilidade ambiental e aeroespacial.
- Coinsmart. A melhor troca de Bitcoin e criptografia da Europa.
- Platoblockchain. Inteligência Metaverso Web3. Conhecimento Ampliado. ACESSO LIVRE.
- CryptoHawk. Radar Altcoin. Teste grátis.
- Fonte: https://aws.amazon.com/blogs/machine-learning/semantic-segmentation-data-labeling-and-model-training-using-amazon-sagemaker/
- '
- "
- 000
- 10
- 100
- 11
- 2019
- a
- Sobre
- acelerar
- acelerado
- preciso
- Alcançar
- alcançado
- em
- adicionado
- Indústria aeroespacial
- algoritmo
- algoritmos
- Todos os Produtos
- Amazon
- anunciou
- Outro
- por aí
- Jurídico
- Automatizado
- automaticamente
- automotivo
- disponível
- AWS
- fundo
- Porque
- MELHOR
- Melhor
- entre
- construir
- construídas em
- negócio
- capturar
- casas
- certo
- alterar
- canais
- Escolha
- classe
- aulas
- classificado
- Na nuvem
- serviços na nuvem
- código
- comum
- competição
- completar
- computador
- computadores
- computação
- confiança
- cônsul
- conteúdo
- facilidade
- Correspondente
- relação custo-benefício
- custos
- crio
- criado
- Clientes
- personalizar
- dados,
- cientista de dados
- profundo
- demonstrar
- implantar
- diferente
- diretamente
- desenho
- durante
- cada
- permite
- end-to-end
- Ponto final
- Entrar
- ambiental
- estabelecido
- exemplo
- Exceto
- esperado
- espera
- explorar
- extremo
- Rosto
- Característica
- Primeiro nome
- seguir
- seguinte
- formato
- da
- gerado
- Objetivos
- Bom estado, com sinais de uso
- cinza
- ótimo
- feliz
- ajudou
- ajuda
- ajuda
- alta qualidade
- hospedado
- Como funciona o dobrador de carta de canal
- Como Negociar
- HTTPS
- humano
- Humanos
- Centenas
- imagem
- imagens
- executar
- melhorar
- incluir
- incluído
- Crescimento
- índice
- indústrias
- INFORMAÇÕES
- entrada
- instância
- Interface
- interseção
- introduzindo
- IT
- Trabalho
- Empregos
- conhecido
- O rótulo
- marcação
- Rótulos
- grande
- lançamento
- APRENDER
- aprendizagem
- Nível
- Limitado
- Line
- linhas
- Lista
- local
- localização
- locais
- longo
- olhar
- máquina
- aprendizado de máquina
- gerencia
- obrigatório
- manualmente
- fabrica
- mapa,
- mapeamento
- máscara
- Máscaras
- maciço
- mecânico
- poder
- ML
- modelo
- modelos
- mais
- múltiplo
- nomes
- nomeando
- Navegação
- rede
- redes
- Próximo
- caderno
- número
- Oferece
- Opção
- Opções
- organizações
- Outros
- próprio
- apaixonado
- por cento
- realização
- pontos
- Polygon
- Popular
- Preparar
- bastante
- preço
- privado
- processo
- produzir
- profissional
- fornecer
- fornece
- público
- fins
- rapidamente
- RE
- registros
- representar
- requeridos
- exige
- Resultados
- rever
- mesmo
- escalável
- Cientista
- SEA
- segmentação
- selecionado
- serviço
- Serviços
- conjunto
- contexto
- Partilhar
- mostrar
- mostrando
- simples
- situação
- pequeno
- So
- Software
- Soluções
- divisão
- começado
- armazenamento
- Sustentabilidade
- Target
- tarefas
- Profissionais
- teste
- A
- A fonte
- coisa
- De terceiros
- milhares
- Através da
- Taxa de transferência
- tempo
- ferramenta
- Trem
- Training
- Transformar
- união
- usar
- validação
- fornecedores
- visão
- QUEM
- Atividades:
- trabalhadores
- Força de trabalho
- trabalho
- investimentos