Quando OpenAI lançou a terceira geração de seu modelo de aprendizado de máquina (ML) especializado em geração de texto em julho de 2020, eu sabia que algo estava diferente. Este modelo atingiu um nervo como nenhum outro que veio antes dele. De repente, ouvi amigos e colegas, que podem estar interessados em tecnologia, mas geralmente não se importam muito com os avanços mais recentes no espaço de IA/ML, falando sobre isso. Até o Guardian escreveu um artigo sobre isso. Ou, para ser mais preciso, o modelo escreveu o artigo e o Guardian o editou e publicou. Não havia como negar - GPT-3 foi um divisor de águas.
Depois que o modelo foi lançado, as pessoas imediatamente começaram a criar possíveis aplicações para ele. Dentro de semanas, muitas demos impressionantes foram criadas, que podem ser encontradas no Site GPT-3. Um aplicativo em particular que me chamou a atenção foi resumo de texto - a capacidade de um computador de ler um determinado texto e resumir seu conteúdo. É uma das tarefas mais difíceis para um computador porque combina dois campos dentro do campo do processamento de linguagem natural (PLN): compreensão de leitura e geração de texto. É por isso que fiquei tão impressionado com as demonstrações do GPT-3 para resumo de texto.
Você pode experimentá-los no Abraçando o site Face Spaces. O meu preferido no momento é um Formulário on line que gera resumos de artigos de notícias com apenas a URL do artigo como entrada.
Nesta série de duas partes, proponho um guia prático para organizações para que você possa avaliar a qualidade dos modelos de sumarização de texto para seu domínio.
Visão geral do tutorial
Muitas organizações com as quais trabalho (caridades, empresas, ONGs) têm grandes quantidades de textos que precisam ler e resumir – relatórios financeiros ou artigos de notícias, trabalhos de pesquisa científica, pedidos de patentes, contratos legais e muito mais. Naturalmente, essas organizações estão interessadas em automatizar essas tarefas com a tecnologia PNL. Para demonstrar a arte do possível, costumo usar as demonstrações de resumo de texto, que quase nunca deixam de impressionar.
Mas e agora?
O desafio para essas organizações é que elas querem avaliar modelos de resumo de texto com base em resumos para muitos, muitos documentos – não um de cada vez. Eles não querem contratar um estagiário cujo único trabalho é abrir o aplicativo, colar em um documento, apertar o botão Resumir botão, aguarde a saída, avalie se o resumo é bom e faça tudo de novo para milhares de documentos.
Eu escrevi este tutorial pensando no meu passado de quatro semanas atrás – é o tutorial que eu gostaria de ter na época quando comecei esta jornada. Nesse sentido, o público-alvo deste tutorial é alguém que está familiarizado com IA/ML e já usou modelos do Transformer antes, mas está no início de sua jornada de sumarização de texto e quer se aprofundar nela. Por ter sido escrito por um “iniciante” e para iniciantes, quero enfatizar o fato de que este tutorial é a guia prático – não que o guia prático. Por favor, trate-o como se Caixa EP George tinha dito:
![]()
Em termos de quanto conhecimento técnico é necessário neste tutorial: ele envolve alguma codificação em Python, mas na maioria das vezes usamos o código para chamar APIs, portanto, nenhum conhecimento de codificação profundo também é necessário. É útil estar familiarizado com certos conceitos de ML, como o que significa trem e implantar um modelo, os conceitos de treinamento, validação e conjuntos de dados de teste, e assim por diante. Também tendo mexido com o Biblioteca de transformadores antes pode ser útil, porque usamos essa biblioteca extensivamente ao longo deste tutorial. Também incluo links úteis para leitura adicional desses conceitos.
Como este tutorial foi escrito por um iniciante, não espero que especialistas em PNL e praticantes avançados de aprendizado profundo obtenham muito deste tutorial. Pelo menos não de uma perspectiva técnica – você ainda pode gostar da leitura, então, por favor, não saia ainda! Mas você terá que ser paciente com relação às minhas simplificações – tentei viver pelo conceito de tornar tudo neste tutorial o mais simples possível, mas não mais simples.
Estrutura deste tutorial
Esta série se estende por quatro seções divididas em dois posts, nos quais passamos por diferentes etapas de um projeto de sumarização de texto. No primeiro post (seção 1), começamos apresentando uma métrica para tarefas de sumarização de texto – uma medida de desempenho que nos permite avaliar se um resumo é bom ou ruim. Também apresentamos o conjunto de dados que queremos resumir e criamos uma linha de base usando um modelo sem ML – usamos uma heurística simples para gerar um resumo de um determinado texto. A criação dessa linha de base é uma etapa de vital importância em qualquer projeto de ML, pois nos permite quantificar quanto progresso fazemos usando a IA daqui para frente. Isso nos permite responder à pergunta “Vale realmente a pena investir em tecnologia de IA?”
No segundo post, usamos um modelo que já foi pré-treinado para gerar resumos (seção 2). Isso é possível com uma abordagem moderna em ML chamada transferir aprendizado. É outra etapa útil porque basicamente pegamos um modelo de prateleira e o testamos em nosso conjunto de dados. Isso nos permite criar outra linha de base, o que nos ajuda a ver o que acontece quando realmente treinamos o modelo em nosso conjunto de dados. A abordagem é chamada resumo de tiro zero, porque o modelo teve exposição zero ao nosso conjunto de dados.
Depois disso, é hora de usar um modelo pré-treinado e treiná-lo em nosso próprio conjunto de dados (seção 3). Isso também é chamado afinação. Ele permite que o modelo aprenda com os padrões e idiossincrasias de nossos dados e se adapte lentamente a eles. Depois de treinarmos o modelo, nós o usamos para criar resumos (seção 4).
Para resumir:
- 1 parte:
- Seção 1: use um modelo sem ML para estabelecer uma linha de base
- Parte 2:
- Seção 2: gerar resumos com um modelo de tiro zero
- Seção 3: treinar um modelo de sumarização
- Seção 4: Avalie o modelo treinado
Todo o código para este tutorial está disponível no seguinte GitHub repo.
O que teremos alcançado ao final deste tutorial?
Ao final deste tutorial, nós não vai tem um modelo de sumarização de texto que pode ser usado em produção. Não teremos nem um Bom estado, com sinais de uso modelo de resumo (insira emoji de grito aqui)!
O que teremos é um ponto de partida para a próxima fase do projeto, que é a fase de experimentação. É aí que entra a “ciência” na ciência de dados, porque agora se trata de experimentar diferentes modelos e configurações diferentes para entender se um modelo de sumarização suficientemente bom pode ser treinado com os dados de treinamento disponíveis.
E, para ser completamente transparente, há uma boa chance de que a conclusão seja que a tecnologia ainda não está madura e que o projeto não será implementado. E você precisa preparar os stakeholders do seu negócio para essa possibilidade. Mas isso é assunto para outro post.
Seção 1: use um modelo sem ML para estabelecer uma linha de base
Esta é a primeira seção do nosso tutorial sobre como configurar um projeto de sumarização de texto. Nesta seção, estabelecemos uma linha de base usando um modelo muito simples, sem realmente usar ML. Este é um passo muito importante em qualquer projeto de ML, pois nos permite entender quanto valor o ML agrega ao longo do tempo do projeto e se vale a pena investir nele.
O código para o tutorial pode ser encontrado no seguinte GitHub repo.
Dados, dados, dados
Todo projeto de ML começa com dados! Se possível, devemos sempre usar dados relacionados ao que queremos alcançar com um projeto de sumarização de texto. Por exemplo, se nosso objetivo é resumir os pedidos de patentes, também devemos usar os pedidos de patentes para treinar o modelo. Uma grande ressalva para um projeto de ML é que os dados de treinamento geralmente precisam ser rotulados. No contexto da sumarização de texto, isso significa que precisamos fornecer o texto a ser resumido, bem como o resumo (o rótulo). Somente fornecendo ambos, o modelo pode aprender como é um bom resumo.
Neste tutorial, usamos um conjunto de dados disponível publicamente, mas as etapas e o código permanecem exatamente os mesmos se usarmos um conjunto de dados personalizado ou privado. E, novamente, se você tiver um objetivo em mente para seu modelo de resumo de texto e tiver dados correspondentes, use seus dados para tirar o máximo proveito disso.
Os dados que usamos são os conjunto de dados arXiv, que contém resumos de artigos do arXiv, bem como seus títulos. Para o nosso propósito, usamos o resumo como o texto que queremos resumir e o título como o resumo de referência. Todas as etapas de download e pré-processamento dos dados estão disponíveis nas seguintes caderno. Nós exigimos um Gerenciamento de acesso e identidade da AWS (IAM) que permite carregar dados de e para Serviço de armazenamento simples da Amazon (Amazon S3) para executar este notebook com sucesso. O conjunto de dados foi desenvolvido como parte do artigo Sobre o uso do ArXiv como um conjunto de dados e é licenciado sob o Creative Commons CC0 1.0 Dedicação de Domínio Público Universal.
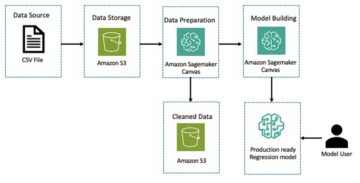
Os dados são divididos em três conjuntos de dados: dados de treinamento, validação e teste. Se você quiser usar seus próprios dados, verifique se esse também é o caso. O diagrama a seguir ilustra como usamos os diferentes conjuntos de dados.
![]()
Naturalmente, uma pergunta comum neste momento é: De quantos dados precisamos? Como você provavelmente já pode adivinhar, a resposta é: depende. Depende de quão especializado é o domínio (resumir pedidos de patente é bem diferente de resumir artigos de notícias), quão preciso o modelo precisa ser para ser útil, quanto deve custar o treinamento do modelo e assim por diante. Voltaremos a essa questão posteriormente, quando treinarmos o modelo, mas o resumo disso é que temos que testar diferentes tamanhos de conjuntos de dados quando estamos na fase de experimentação do projeto.
O que faz um bom modelo?
Em muitos projetos de ML, é bastante simples medir o desempenho de um modelo. Isso porque geralmente há pouca ambiguidade sobre se o resultado do modelo está correto. Os rótulos no conjunto de dados geralmente são binários (Verdadeiro/Falso, Sim/Não) ou categóricos. De qualquer forma, é fácil neste cenário comparar a saída do modelo com a etiqueta e marcá-la como correta ou incorreta.
Ao gerar texto, isso se torna mais desafiador. Os resumos (os rótulos) que fornecemos em nosso conjunto de dados são apenas uma maneira de resumir o texto. Mas há muitas possibilidades para resumir um determinado texto. Portanto, mesmo que o modelo não corresponda ao nosso rótulo 1:1, a saída ainda pode ser um resumo válido e útil. Então, como comparamos o resumo do modelo com o que fornecemos? A métrica mais usada na sumarização de texto para medir a qualidade de um modelo é a Pontuação ROUGE. Para entender a mecânica dessa métrica, consulte A melhor métrica de desempenho em PNL. Em resumo, a pontuação ROUGE mede a sobreposição de n-gramas (sequência contígua de n itens) entre o resumo do modelo (resumo do candidato) e o resumo de referência (o rótulo que fornecemos em nosso conjunto de dados). Mas, claro, esta não é uma medida perfeita. Para entender suas limitações, confira Para ROUGE ou não para ROUGE?
Então, como calculamos a pontuação ROUGE? Existem alguns pacotes Python por aí para calcular essa métrica. Para garantir a consistência, devemos usar o mesmo método em todo o nosso projeto. Como, em um ponto posterior deste tutorial, usaremos um script de treinamento da biblioteca Transformers em vez de escrever o nosso próprio, podemos apenas dar uma olhada no código fonte do script e copie o código que calcula a pontuação ROUGE:
Ao usar esse método para calcular a pontuação, garantimos que sempre comparamos maçãs com maçãs ao longo do projeto.
Esta função calcula várias pontuações ROUGE: rouge1, rouge2, rougeL e rougeLsum. A “soma” em rougeLsum refere-se ao fato de que essa métrica é calculada sobre um resumo inteiro, enquanto rougeL é calculado como a média sobre sentenças individuais. Então, qual pontuação ROUGE devemos usar para o nosso projeto? Novamente, temos que tentar diferentes abordagens na fase de experimentação. Vale o que vale, o papel original ROUGE afirma que “ROUGE-2 e ROUGE-L funcionaram bem em tarefas de resumo de documentos únicos”, enquanto “ROUGE-1 e ROUGE-L têm ótimo desempenho na avaliação de resumos curtos”.
Crie a linha de base
Em seguida, queremos criar a linha de base usando um modelo simples e sem ML. O que isso significa? No campo da sumarização de texto, muitos estudos usam uma abordagem muito simples: eles tomam o primeiro n frases do texto e declará-lo o resumo candidato. Eles então comparam o resumo candidato com o resumo de referência e calculam a pontuação ROUGE. Esta é uma abordagem simples, mas poderosa, que podemos implementar em algumas linhas de código (o código inteiro para esta parte está no seguinte caderno):
Usamos o conjunto de dados de teste para esta avaliação. Isso faz sentido porque depois de treinarmos o modelo, também usamos o mesmo conjunto de dados de teste para a avaliação final. Também tentamos números diferentes para n: começamos com apenas a primeira frase como resumo do candidato, depois as duas primeiras frases e, finalmente, as três primeiras frases.
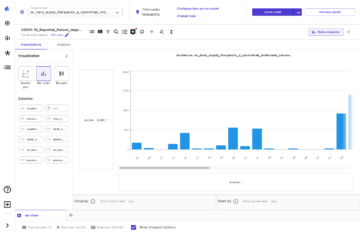
A captura de tela a seguir mostra os resultados do nosso primeiro modelo.
![]()
As pontuações do ROUGE são as mais altas, com apenas a primeira frase como resumo do candidato. Isso significa que tomar mais de uma frase torna o resumo muito detalhado e leva a uma pontuação mais baixa. Isso significa que usaremos as pontuações dos resumos de uma frase como nossa linha de base.
É importante notar que, para uma abordagem tão simples, esses números são realmente muito bons, especialmente para o rouge1 pontuação. Para contextualizar esses números, podemos nos referir a Modelos Pegasus, que mostra as pontuações de um modelo de última geração para diferentes conjuntos de dados.
Conclusão e o que vem a seguir
Na Parte 1 de nossa série, apresentamos o conjunto de dados que usamos em todo o projeto de resumo, bem como uma métrica para avaliar resumos. Em seguida, criamos a linha de base a seguir com um modelo simples e sem ML.
![]()
No próximo post, usamos um modelo de tiro zero – especificamente, um modelo que foi treinado especificamente para sumarização de texto em artigos de notícias públicas. No entanto, esse modelo não será treinado em nosso conjunto de dados (daí o nome “zero-shot”).
Deixo para você como lição de casa adivinhar como esse modelo de tiro zero se comportará em comparação com nossa linha de base muito simples. Por um lado, será um modelo muito mais sofisticado (na verdade, é uma rede neural). Por outro lado, é usado apenas para resumir artigos de notícias, portanto, pode ter problemas com os padrões inerentes ao conjunto de dados arXiv.
Sobre o autor
![]() Heiko Hotz é arquiteto de soluções sênior para IA e aprendizado de máquina e lidera a comunidade de processamento de linguagem natural (NLP) na AWS. Antes dessa função, ele foi o chefe de ciência de dados para o atendimento ao cliente da UE da Amazon. A Heiko ajuda nossos clientes a serem bem-sucedidos em sua jornada de IA/ML na AWS e trabalhou com organizações de vários setores, incluindo seguros, serviços financeiros, mídia e entretenimento, saúde, serviços públicos e manufatura. Em seu tempo livre, Heiko viaja o máximo possível.
Heiko Hotz é arquiteto de soluções sênior para IA e aprendizado de máquina e lidera a comunidade de processamento de linguagem natural (NLP) na AWS. Antes dessa função, ele foi o chefe de ciência de dados para o atendimento ao cliente da UE da Amazon. A Heiko ajuda nossos clientes a serem bem-sucedidos em sua jornada de IA/ML na AWS e trabalhou com organizações de vários setores, incluindo seguros, serviços financeiros, mídia e entretenimento, saúde, serviços públicos e manufatura. Em seu tempo livre, Heiko viaja o máximo possível.
- Coinsmart. A melhor troca de Bitcoin e criptografia da Europa.
- Platoblockchain. Inteligência Metaverso Web3. Conhecimento Ampliado. ACESSO LIVRE.
- CryptoHawk. Radar Altcoin. Teste grátis.
- Fonte: https://aws.amazon.com/blogs/machine-learning/part-1-set-up-a-text-summarization-project-with-hugging-face-transformers/
- '
- "
- &
- 100
- 2020
- Sobre
- RESUMO
- Acesso
- preciso
- alcançado
- avançado
- avanços
- AI
- Todos os Produtos
- já
- Amazon
- Ambiguidade
- quantidades
- Outro
- APIs
- Aplicação
- aplicações
- abordagem
- por aí
- Arte
- artigo
- artigos
- público
- disponível
- média
- AWS
- Linha de Base
- Basicamente
- Começo
- ser
- negócio
- chamada
- Cuidado
- apanhados
- desafiar
- código
- Codificação
- comum
- comunidade
- Empresas
- comparado
- completamente
- Computar
- conceito
- contém
- conteúdo
- contratos
- Criar
- personalizadas
- Atendimento ao Cliente
- Clientes
- dados,
- ciência de dados
- mais profunda
- desenvolvido
- diferente
- INSTITUCIONAIS
- Não faz
- domínio
- Entretenimento
- especialmente
- estabelecer
- EU
- tudo
- exemplo
- esperar
- especialistas
- olho
- Rosto
- Campos
- Finalmente
- financeiro
- serviços financeiros
- Primeiro nome
- seguinte
- para a frente
- encontrado
- função
- mais distante
- jogo
- gerar
- geração
- meta
- vai
- Bom estado, com sinais de uso
- ótimo
- guardião
- guia
- ter
- cabeça
- saúde
- útil
- ajuda
- SUA PARTICIPAÇÃO FAZ A DIFERENÇA
- contratar
- Como funciona o dobrador de carta de canal
- HTTPS
- enorme
- Dados de identificação:
- executar
- implementado
- importante
- incluir
- Incluindo
- Individual
- indústrias
- com seguro
- introduzindo
- investir
- IT
- Trabalho
- Julho
- Chave
- Conhecimento
- Rótulos
- língua
- mais recente
- Leads
- APRENDER
- aprendizagem
- Deixar
- Legal
- Biblioteca
- Licenciado
- Links
- pequeno
- máquina
- aprendizado de máquina
- FAZ
- Fazendo
- fabrica
- marca
- Match
- a medida
- Mídia
- mente
- ML
- modelo
- modelos
- mais
- a maioria
- natural
- rede
- notícias
- caderno
- números
- aberto
- ordem
- organizações
- Outros
- Papel
- patente
- Pessoas
- atuação
- perspectiva
- fase
- ponto
- possibilidades
- possibilidade
- possível
- POSTAGENS
- potencial
- poderoso
- privado
- Produção
- projeto
- projetos
- oferece
- fornecer
- fornecendo
- público
- propósito
- qualidade
- questão
- alcance
- RE
- Leitura
- Relatórios
- requerer
- requeridos
- pesquisa
- Resultados
- Execute
- Dito
- Ciência
- sentido
- Série
- serviço
- Serviços
- conjunto
- contexto
- Baixo
- simples
- So
- Soluções
- Alguém
- algo
- sofisticado
- Espaço
- espaços
- especializado
- especializada
- especificamente
- divisão
- começo
- começado
- começa
- estado-da-arte
- Unidos
- armazenamento
- estresse
- caso
- bem sucedido
- entraram com sucesso
- Converse
- Target
- tarefas
- Dados Técnicos:
- Equipar
- teste
- milhares
- Através da
- todo
- tempo
- Título
- Training
- transparente
- tratar
- final
- compreender
- Universal
- us
- usar
- geralmente
- valor
- esperar
- O Quê
- se
- QUEM
- Wikipedia
- dentro
- sem
- Atividades:
- trabalhou
- Equivalente há
- escrita
- X
- zero