Imagem gerada usando Difusão Estável
O mundo da IA mudou drasticamente em direção à modelagem generativa nos últimos anos, tanto em Visão Computacional quanto em Processamento de Linguagem Natural. Dalle-2 e Midjourney chamaram a atenção das pessoas, levando-as a reconhecer o trabalho excepcional realizado no campo da IA generativa.
A maioria das imagens geradas por IA atualmente produzidas dependem de modelos de difusão como base. O objetivo deste artigo é esclarecer alguns dos conceitos que envolvem a difusão estável e oferecer uma compreensão fundamental da metodologia empregada.
Este fluxograma mostra a versão simplificada de uma arquitetura de difusão estável. Vamos analisá-lo peça por peça para construir uma melhor compreensão do funcionamento interno. Vamos detalhar o processo de treinamento para melhor compreensão, com a inferência tendo apenas algumas mudanças sutis.
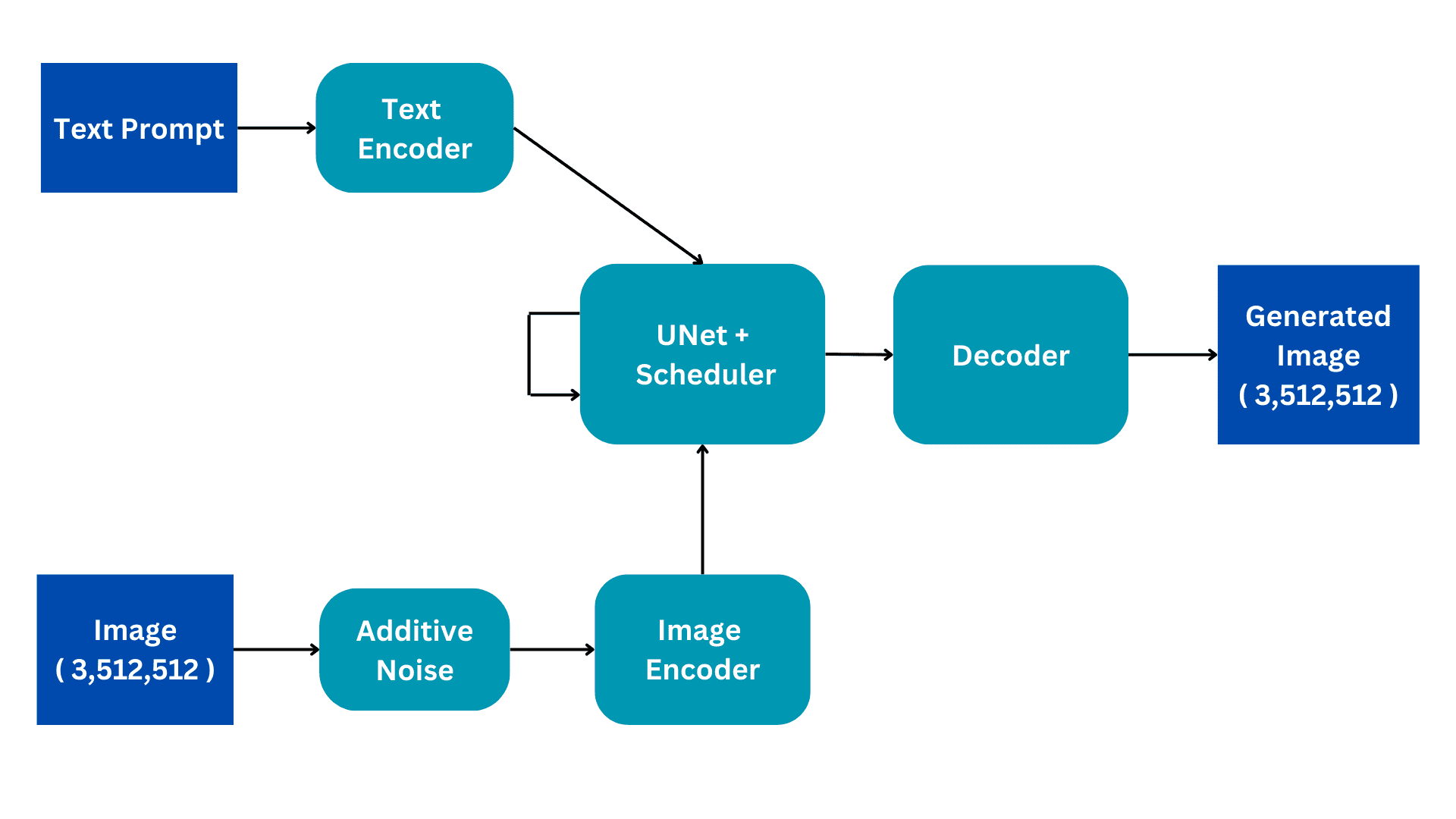
Imagem do autor
entradas
Os modelos de difusão estável são treinados em conjuntos de dados de legendas de imagens em que cada imagem tem uma legenda ou prompt associado que descreve a imagem. Existem, portanto, duas entradas para o modelo; um prompt textual em linguagem natural e uma imagem de tamanho (3,512,512) com 3 canais de cores e dimensões de tamanho 512.
Ruído Aditivo
A imagem é convertida em ruído completo adicionando ruído gaussiano à imagem original. Isso é feito em etapas consecutivas, por exemplo, uma pequena quantidade de ruído é adicionada à imagem por 50 etapas consecutivas até que a imagem fique completamente ruidosa. O processo de difusão terá como objetivo remover esse ruído e reproduzir a imagem original. Como isso é feito será explicado mais adiante.
Codificador de imagem
O Image encoder funciona como um componente de um Variational AutoEncoder, convertendo a imagem em um 'espaço latente' e redimensionando-a para dimensões menores, como (4, 64, 64), enquanto também inclui uma dimensão de lote adicional. Esse processo reduz os requisitos computacionais e melhora o desempenho. Ao contrário dos modelos de difusão originais, o Stable Diffusion incorpora a etapa de codificação na dimensão latente, resultando em computação reduzida, bem como diminuição do tempo de treinamento e inferência.
Codificador de Texto
O prompt de linguagem natural é transformado em uma incorporação vetorizada pelo codificador de texto. Esse processo emprega um modelo Transformer Language, como modelos CLIP Text baseados em BERT ou GPT. Os modelos de codificador de texto aprimorados aprimoram significativamente a qualidade das imagens geradas. A saída resultante do codificador de texto consiste em uma matriz de vetores de incorporação de 768 dimensões para cada palavra. Para controlar o comprimento do prompt, um limite máximo de 77 é definido. Como resultado, o codificador de texto produz um tensor com dimensões de (77, 768).
UNet
Esta é a parte computacionalmente mais cara da arquitetura e o principal processamento de difusão ocorre aqui. Ele recebe codificação de texto e imagem latente ruidosa como entrada. Este módulo visa reproduzir a imagem original a partir da imagem ruidosa que recebe. Ele faz isso por meio de várias etapas de inferência que podem ser definidas como um hiperparâmetro. Normalmente, 50 etapas de inferência são suficientes.
Considere um cenário simples em que uma imagem de entrada sofre uma transformação em ruído pela introdução gradual de pequenas quantidades de ruído em 50 etapas consecutivas. Essa adição cumulativa de ruído eventualmente transforma a imagem original em ruído completo. O objetivo da UNet é reverter esse processo prevendo o ruído adicionado no passo de tempo anterior. Durante o processo de redução de ruído, a UNet começa prevendo o ruído adicionado no 50º timestep para o timestep inicial. Em seguida, subtrai esse ruído previsto da imagem de entrada e repete o processo. Em cada intervalo de tempo subsequente, a UNet prevê o ruído adicionado no intervalo de tempo anterior, restaurando gradualmente a imagem de entrada original do ruído completo. Ao longo desse processo, a UNet depende internamente do vetor de incorporação textual como fator condicionante.
A UNet gera um tensor de tamanho (4, 64, 64) que é passado para a parte do decodificador do Variational AutoEncoder.
Decoder
O decodificador reverte a conversão de representação latente feita pelo codificador. Ele pega uma representação latente e a converte de volta ao espaço da imagem. Portanto, ele gera uma imagem (3,512,512), do mesmo tamanho do espaço de entrada original. Durante o treinamento, visamos minimizar a perda entre a imagem original e a imagem gerada. Dado que, dado um prompt textual, podemos gerar uma imagem relacionada ao prompt a partir de uma imagem completamente ruidosa.
Durante a inferência, não temos imagem de entrada. Trabalhamos apenas no modo texto para imagem. Removemos a parte do ruído aditivo e, em vez disso, usamos um tensor gerado aleatoriamente do tamanho necessário. O resto da arquitetura permanece a mesma.
A UNet passou por treinamento para gerar uma imagem a partir de ruído completo, aproveitando a incorporação de prompt de texto. Essa entrada específica é usada durante o estágio de inferência, permitindo gerar com sucesso imagens sintéticas a partir do ruído. Esse conceito geral serve como a intuição fundamental por trás de todos os modelos de visão computacional generativa.
Maomé Arham é um Engenheiro de Aprendizagem Profunda trabalhando em Visão Computacional e Processamento de Linguagem Natural. Ele trabalhou na implantação e otimizações de vários aplicativos generativos de IA que alcançaram os principais gráficos globais da Vyro.AI. Ele está interessado em construir e otimizar modelos de aprendizado de máquina para sistemas inteligentes e acredita na melhoria contínua.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Automotivo / EVs, Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- BlockOffsets. Modernizando a Propriedade de Compensação Ambiental. Acesse aqui.
- Fonte: https://www.kdnuggets.com/2023/06/stable-diffusion-basic-intuition-behind-generative-ai.html?utm_source=rss&utm_medium=rss&utm_campaign=stable-diffusion-basic-intuition-behind-generative-ai
- :tem
- :é
- :onde
- 50
- 77
- a
- realizado
- adicionado
- acrescentando
- Adição
- Adicional
- aditivo
- AI
- visar
- visa
- Todos os Produtos
- tb
- quantidade
- quantidades
- an
- e
- aplicações
- arquitetura
- SOMOS
- Ordem
- artigo
- AS
- associado
- At
- por WhatsApp.
- em caminho duplo
- basic
- BE
- atrás
- ser
- acredita
- Melhor
- entre
- ambos
- construir
- Prédio
- by
- CAN
- apanhados
- Alterações
- canais
- charts
- cor
- completar
- completamente
- componente
- computação
- computador
- Visão de Computador
- conceito
- conceitos
- consecutivo
- consiste
- ao controle
- Conversão
- convertido
- conversão
- Atualmente
- conjuntos de dados
- profundo
- deep learning
- desenvolvimento
- Distribuição
- Dimensão
- dimensões
- parece
- feito
- dramaticamente
- durante
- cada
- Elaborar
- embutindo
- empregada
- emprega
- permitindo
- engenheiro
- aumentar
- aprimorada
- Melhora
- eventualmente
- exemplo
- excepcional
- caro
- explicado
- fator
- poucos
- campo
- Escolha
- Foundation
- da
- funções
- fundamental
- mais distante
- Geral
- gerar
- gerado
- generativo
- IA generativa
- dado
- Global
- Go
- gradualmente
- Ter
- ter
- he
- SUA PARTICIPAÇÃO FAZ A DIFERENÇA
- Como funciona o dobrador de carta de canal
- HTTPS
- imagem
- imagens
- melhoria
- in
- Incluindo
- incorpora
- do estado inicial,
- entrada
- inputs
- em vez disso
- Inteligente
- interessado
- interno
- internamente
- para dentro
- introduzindo
- intuição
- IT
- jpg
- KDnuggetsGenericName
- língua
- principal
- aprendizagem
- Comprimento
- aproveitando
- LIMITE
- fora
- máquina
- aprendizado de máquina
- a Principal
- máximo
- Metodologia
- Meio da Jornada
- minimizar
- Moda
- modelo
- modelagem
- modelos
- módulo
- a maioria
- natural
- Linguagem Natural
- Processamento de linguagem natural
- não
- Ruído
- normalmente
- objetivo
- of
- oferecer
- on
- só
- otimizando
- or
- ordem
- original
- saída
- Acima de
- parte
- passou
- passado
- Pessoas
- atuação
- peça
- platão
- Inteligência de Dados Platão
- PlatãoData
- previsto
- prevendo
- Previsões
- anterior
- processo
- em processamento
- Produzido
- produz
- qualidade
- gerado aleatoriamente
- alcançado
- recebe
- reconhecer
- Reduzido
- reduz
- relacionado
- depender
- permanece
- remover
- representação
- requeridos
- Requisitos
- DESCANSO
- restauração
- resultar
- resultando
- reverso
- s
- mesmo
- cenário
- serve
- conjunto
- vários
- deslocado
- Shows
- de forma considerável
- simples
- simplificada
- Tamanho
- pequeno
- menor
- alguns
- Espaço
- específico
- estável
- Etapa
- Passo
- Passos
- subseqüente
- entraram com sucesso
- tal
- suficiente
- Em torno da
- sintético
- sistemas
- toma
- que
- A
- deles
- Eles
- então
- Lá.
- assim sendo
- isto
- Através da
- todo
- tempo
- para
- topo
- para
- treinado
- Training
- Transformação
- transformado
- transformador
- transformações
- dois
- sofre
- sofrido
- compreensão
- ao contrário
- até
- us
- usar
- usava
- utilização
- versão
- visão
- we
- BEM
- qual
- enquanto
- precisarão
- de
- Word
- Atividades:
- trabalhou
- trabalhar
- funcionamento
- mundo
- anos
- zefirnet