Introdução
No campo em rápida evolução da ciência de dados, a demanda por profissionais qualificados e versados em aprendizagem profunda está em alta. À medida que as organizações compreendem o poder da inteligência artificial para obter insights de vastos conjuntos de dados, os cientistas de dados equipados com experiência em aprendizagem profunda tornaram-se ativos inestimáveis. Quer você seja um cientista de dados experiente em busca de avançar em sua carreira ou um candidato a emprego entrando na área, preparar-se para entrevistas é essencial. Para ajudá-lo a navegar pelo intrincado cenário das entrevistas de aprendizagem profunda, compilamos uma lista abrangente dos “30 principais Aprendizagem profunda Perguntas de entrevista para cientistas de dados.”
Iniciantes
Q1. O que é um neurônio em uma rede neural?
R. Em uma rede neural, um neurônio é a unidade fundamental de processamento de informações. Pense nisso como uma pequena célula cerebral trabalhando junto com inúmeras outras para resolver problemas complexos.
Veja como funciona:
entradas: Imagine um neurônio com múltiplas ramificações, como dendritos, se estendendo. Estas são as entradas, recebendo sinais de outros neurônios ou dados brutos do mundo exterior. Cada entrada possui um peso, determinando sua influência na saída do neurônio.
Tratamento: Uma função de ativação combina e transforma as entradas ponderadas dentro do neurônio. Esta função atua como um gatekeeper, decidindo o quanto o neurônio “dispara” com base na soma de suas entradas. Diferentes funções de ativação têm propriedades diferentes, afetando a sensibilidade do neurônio às suas entradas e quais informações ele pode processar.
saída: Se o sinal processado ultrapassar um determinado limite, o neurônio “dispara” e envia um sinal de saída ao longo de seu axônio. Outros neurônios podem receber esse sinal de saída como entrada, criando uma reação em cadeia de processamento de informações em toda a rede.
Q2. Quais são os diferentes tipos de dados usados no aprendizado profundo?
R. O mundo diversificado do aprendizado profundo prospera com vários dados, cada um trazendo desafios e vantagens! Aqui está uma visão geral de alguns dos tipos mais comuns:
- Dados numéricos: Contínuo: Pense em leituras de temperatura, preços de ações ou alturas onde os valores fluem suavemente ao longo de uma faixa.
- Discreto: abrange dados como número de irmãos, classificações de filmes ou tamanhos de sapatos com valores distintos e separados.
- Dados de texto: Artigos, resenhas, postagens em mídias sociais e até livros oferecem um tesouro de informações textuais para tarefas como análise de sentimentos, tradução de idiomas e resumo de textos.
- Imagens: Desde fotografias e exames médicos até imagens de satélite e obras de arte, os dados visuais desempenham um papel crucial em tarefas de visão computacional, como detecção de objetos, classificação de imagens e reconhecimento facial.
- Dados de Áudio: Os modelos de aprendizagem profunda podem analisar música, gravações de fala e efeitos sonoros para classificação de gênero musical, reconhecimento de fala e detecção de anomalias em fluxos de áudio.
- Dados de série temporal: Leituras de sensores, transações financeiras, tráfego de sites e até dados meteorológicos formam sequências de pontos de dados ao longo do tempo. O aprendizado profundo pode extrair padrões significativos dessas sequências para previsão, detecção de anomalias e análise de tendências.
- Dados multimodais: Às vezes, a chave está na combinação de diferentes tipos de dados. Imagine analisar avaliações em vídeo de restaurantes, onde você aproveitaria informações audiovisuais para análise de sentimentos e compreensão do conteúdo.
Q3. O que são épocas e lotes no treinamento de aprendizado profundo?
R. Épocas e lotes são como engrenagens e pistões do treinamento de aprendizado profundo – eles trabalham juntos para conduzir o modelo a um melhor desempenho. Veja como eles se encaixam no processo de treinamento:
Época:
- Imagine uma maratona completa de leitura do seu livro favorito. No aprendizado profundo, uma época é como ler todo o conjunto de dados de treinamento uma vez. O modelo vê cada ponto de dados e ajusta seus parâmetros internos (pesos) com base no que aprende.
- Durante uma época, o modelo calcula o erro de cada ponto de dados (diferença entre suas previsões e os valores reais) e os propaga retroativamente para atualizar seus pesos.
- A conclusão de várias épocas permite que o modelo refine sua compreensão dos dados e melhore sua precisão.
Fornada:
- Imagine ler seu livro capítulo por capítulo, em vez de ler tudo de uma vez. No aprendizado profundo, um lote é um subconjunto menor de dados de treinamento usados para atualizar os pesos do modelo durante uma época.
- O treinamento com lotes é mais rápido e eficiente do que usar todo o conjunto de dados simultaneamente, especialmente para grandes conjuntos de dados. Também permite que o modelo aprenda com mais frequência diferentes aspectos dos dados.
- O tamanho do lote (número de pontos de dados) é um hiperparâmetro que você pode ajustar para otimizar o desempenho do seu modelo. Lotes menores podem levar mais tempo para treinar, mas podem ajudar a evitar overfitting, enquanto lotes maiores podem treinar mais rápido, mas estão sujeitos a overfitting.
Q4. Qual é a diferença entre aprendizagem supervisionada e não supervisionada em aprendizagem profunda?
A. Aprendizagem Supervisionada envolve treinar um modelo com dados rotulados, onde são fornecidas entradas e saídas corretas correspondentes. Você pode usá-lo para tarefas preditivas, como classificação e regressão, e requer grandes dados rotulados.
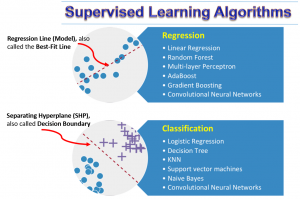
Aprendizagem não supervisionada funciona com dados não rotulados, o que significa que apenas entradas sem saídas especificadas são fornecidas. Tem como objetivo identificar padrões ou estruturas nos dados e é usado para agrupamento, associação e redução de dimensionalidade. Não são necessários dados rotulados, mas encontrar padrões precisos pode ser mais desafiador.
A principal diferença está nos dados utilizados (rotulados versus não rotulados) e no objetivo (predição versus descoberta de padrões).
Q5. Explique a diferença entre funções de ativação como ReLU e sigmóide. Quando você escolheria um em vez do outro?
A. A principal diferença entre as funções de ativação ReLU e Sigmóide está em sua formulação matemática e na maneira como transformam os sinais de entrada.
ReLU (Unidade Linear Retificada): Definido como f(x) = máx(0, x), ReLU gera a entrada se for positiva ou zero caso contrário. É amplamente utilizado em aprendizado profundo devido à sua eficiência computacional e capacidade de reduzir o problema do gradiente evanescente, comum em redes profundas. ReLU costuma ser a escolha padrão para camadas ocultas em vários tipos de redes neurais.
Sigmóide: Definido como f(x) = 1 / (1 + exp(-x)), a função Sigmóide mapeia qualquer entrada para um valor entre 0 e 1. Essa característica a torna adequada para camadas de saída em tarefas de classificação binária, onde a saída é interpretada como uma probabilidade.
Quando escolher um em vez do outro?
- Usar ReLU: Para uso geral em camadas ocultas devido à sua eficiência e eficácia em evitar o problema do desaparecimento do gradiente. É adequado para a maioria dos tipos de redes neurais, incluindo modelos de aprendizagem profunda.
- Use Sigmóide: Na camada de saída para tarefas de classificação binária, interprete a saída como uma probabilidade. É menos preferido em camadas ocultas devido à sua suscetibilidade ao problema do gradiente evanescente, especialmente em redes profundas.”
Q6. Descreva o processo de retropropagação em uma rede neural. Por que é importante para o aprendizado?
A. Backpropagation é um algoritmo fundamental usado para treinar redes neurais. Consiste em duas fases principais: o passe para frente e o passe para trás.
Passar para a frente: Nesta fase, os dados de entrada são passados pela rede camada por camada, da camada de entrada para a camada de saída. Em cada camada, a função de ativação processa as entradas para produzir saídas, que então se tornam entradas para a próxima camada. O resultado final calcula a perda, medindo a diferença entre a previsão da rede e os valores alvo.
Passe para trás: é aqui que a retropropagação entra em ação. O objetivo é minimizar a perda ajustando os pesos e vieses da rede. Começando na camada de saída, a rede propaga a perda para trás. Usando a regra da cadeia de cálculo, calculamos o gradiente de perda relativo a cada peso e viés. Isso nos diz o quanto uma pequena mudança em cada peso e tendência afetaria a perda.
Atualizando os Pesos e Vieses: com esses gradientes, ajustamos os pesos e as tendências na direção que reduz a perda, normalmente usando um algoritmo de otimização como Gradient Descent.
Q7. Quais são os diferentes tipos de algoritmos de otimização usados no aprendizado profundo? Qual é o melhor para treinar redes neurais convolucionais (CNN)?
R. No aprendizado profundo, vários algoritmos de otimização são comumente usados, cada um com pontos fortes e aplicações. Aqui está uma visão geral de alguns dos mais populares:
- Gradiente descendente: Este é o algoritmo de otimização fundamental, onde os parâmetros do modelo são atualizados na direção do gradiente negativo da função de perda. É mais teórico porque usa todo o conjunto de dados para calcular gradientes e raramente é usado na prática devido à ineficiência computacional.
- Descida Gradiente Estocástica (SGD): uma variante do gradiente descendente, o SGD atualiza os parâmetros do modelo usando apenas uma única amostra ou um pequeno lote de amostras. Isto introduz ruído nas atualizações dos parâmetros, o que pode ajudar a escapar dos mínimos locais, mas também pode levar à instabilidade na convergência.
- Descida gradiente de minilote: Equilibra entre versões em lote e estocásticas, atualizando parâmetros com um subconjunto de dados de treinamento em cada etapa. É mais eficiente que a descida gradiente em lote e menos barulhenta que o SGD.
- Ímpeto: uma extensão do SGD que acelera o algoritmo de descida de gradiente considerando os gradientes anteriores para suavizar as atualizações. Ajuda a evitar oscilações e acelera a convergência.
- Adagrado: Adapta a taxa de aprendizado aos parâmetros, realizando atualizações maiores para parâmetros pouco frequentes e atualizações menores para parâmetros frequentes. É adequado para dados esparsos, mas sua taxa de aprendizado continuamente decrescente pode ser uma desvantagem.
- RMSprop: aborda a diminuição das taxas de aprendizagem do Adagrad usando uma média móvel de gradientes quadrados para normalizar o gradiente. Isso permite uma taxa de aprendizagem adaptativa.
- Adam (estimativa de momento adaptativo): Combina elementos de RMSprop e Momentum, calculando taxas de aprendizagem adaptativas para cada parâmetro. Adam é conhecido por sua eficácia e é um otimizador amplamente utilizado em várias aplicações de aprendizado profundo.
Melhor para redes neurais convolucionais (CNNs):

- Para treinar CNNs, Adam é frequentemente considerada a melhor escolha devido à sua robustez e eficácia em uma ampla gama de tarefas. É particularmente útil para grandes conjuntos de dados e arquiteturas de redes neurais complexas.
- O Mercado Pago não havia executado campanhas de Performance anteriormente nessas plataformas. Alcançar uma campanha de sucesso exigiria SGD com impulso também é uma escolha popular, especialmente nos casos em que se deseja um controle refinado sobre o processo de aprendizagem, como no treinamento de redes profundas ou redes com uma estrutura complexa.
A escolha do otimizador pode depender da tarefa específica, do tamanho e natureza dos dados e da arquitetura da CNN. Testes empíricos e ajuste de hiperparâmetros costumam ser essenciais para determinar o melhor otimizador para um caso de uso específico.
Q8. Quais são as vantagens e desvantagens de usar o abandono em modelos de aprendizagem profunda?
A. O abandono é uma técnica de regularização amplamente utilizada em modelos de aprendizagem profunda. Aqui estão suas vantagens e desvantagens:
Vantagens:
- Evita overfitting: O dropout reduz o overfitting ao desativar aleatoriamente um subconjunto de neurônios durante o treinamento. Isso força a rede a aprender representações redundantes e a não depender de nenhum neurônio único, tornando o modelo mais robusto.
- Generalização do modelo: Ao simular um grande número de arquiteturas de rede por meio da desativação aleatória de neurônios, o dropout ajuda a melhorar as capacidades de generalização do modelo.
- Simples mas eficaz: O dropout é simples de implementar e muitas vezes melhora significativamente o desempenho do modelo, especialmente em redes complexas propensas a overfitting.
- Efeito Conjunto: Cada iteração de treinamento com abandono pode ser vista como o treinamento de um modelo diferente. No momento do teste, é como calcular a média das previsões de todos esses modelos, semelhante a um método conjunto.
Desvantagens :
- Maior tempo de treinamento: Como o abandono envolve o treinamento de um subconjunto diferente de neurônios em cada iteração, pode aumentar o tempo necessário para treinar o modelo de maneira eficaz.
- Capacidade reduzida do modelo: A capacidade efetiva da rede é reduzida pela queda aleatória de neurônios durante o treinamento. Embora isso ajude a prevenir o sobreajuste, também pode limitar a capacidade do modelo de aprender padrões complexos se não for gerenciado adequadamente.
- Ajuste de hiperparâmetros: a taxa de abandono é um hiperparâmetro adicional a ser ajustado. Uma taxa inadequada pode levar a um underfitting (muito alto) ou overfitting (muito baixo).
- Variação de desempenho: A aleatoriedade introduzida pelo abandono pode levar a variações no desempenho do modelo e nem sempre pode ser benéfica, dependendo da complexidade da tarefa e da quantidade de dados de treinamento.
- Nem sempre é necessário: Em alguns casos, especialmente com conjuntos de dados pequenos ou modelos mais simples, o abandono pode não ser necessário e prejudicar o desempenho.
Q9. Explique o conceito de overfitting e underfitting no aprendizado profundo. Como você pode evitá-los?
Overfitting e underfitting são problemas comuns no aprendizado profundo, relacionados ao quão bem um modelo aprende e generaliza para novos dados.
Overfitting:
- Definição: o overfitting ocorre quando um modelo aprende muito bem os dados de treinamento, incluindo seu ruído e valores discrepantes. Ele se ajusta ao padrão subjacente e às flutuações aleatórias nos dados de treinamento.
- Características: Esse modelo tem um bom desempenho em dados de treinamento, mas um desempenho ruim em dados não vistos (dados de teste) porque memorizou os dados de treinamento em vez de aprender a generalizar.
- Prevenção:
- Regularização: Técnicas como regularização L1 e L2 penalizam a função de perda por desencorajar modelos complexos.
- Cair fora: define aleatoriamente uma fração de unidades de entrada como 0 em cada atualização durante o treinamento, o que ajuda a evitar a dependência de qualquer nó individual.
- Aumento de dados: aumenta a diversidade dos dados de treinamento adicionando versões ligeiramente modificadas de dados existentes ou dados sintéticos recém-criados.
- Validação cruzada: usa várias divisões dos dados para validar o desempenho do modelo.
- Parada Antecipada: interrompe o treinamento quando o desempenho do modelo para de melhorar em um conjunto de dados de validação.
Subajuste:
- Definição: o underfitting ocorre quando um modelo é muito simples para aprender o padrão subjacente nos dados, resultando em treinamento e desempenho insatisfatórios dos dados de teste.
- Características: isso ocorre quando o modelo não tem capacidade suficiente (camadas ou nós insuficientes) ou não é treinado o suficiente.
Prevenção:
- Aumentando a complexidade do modelo: Adicionar mais camadas ou nós à rede neural pode fornecer mais capacidade de aprendizagem.
- Treinando por mais tempo: permitindo mais períodos de treinamento até que o desempenho do modelo melhore.
- Engenharia de recursos: melhorar os recursos de entrada pode ajudar o modelo a aprender melhor.
- Reduzindo a Regularização: se a regularização for muito forte, o modelo poderá não se ajustar bem, mesmo nos dados de treinamento.
Q10. Quais são os diferentes tipos de técnicas de regularização usadas no aprendizado profundo?
A. Os diferentes tipos de técnicas de regularização utilizadas são as seguintes:
- Regularização L1 (Laço): Adiciona o valor absoluto dos pesos à função de perda. Isso pode levar a modelos esparsos onde alguns pesos se tornam zero, realizando efetivamente a seleção de recursos.
- Regularização L2 (Ridge): Adiciona o quadrado dos pesos à função de perda. Penaliza mais os pesos grandes do que os menores, incentivando o modelo a desenvolver pesos menores, levando a um modelo mais distribuído e generalizado.
- Regularização de Rede Elástica: Combina a regularização L1 e L2, adicionando valores absolutos e quadrados de pesos à função de perda. Ele equilibra a seleção de recursos (L1) e pequenos pesos (L2).
- Cair fora: Defina aleatoriamente uma fração das unidades de entrada como 0 em cada atualização durante o tempo de treinamento. Isso evita que a rede se torne muito dependente de qualquer recurso e promove a robustez dos recursos.
- Parada Antecipada: Parando o processo de treinamento antes do modelo sobreajuste. O treinamento é monitorado usando um conjunto de validação, e o treinamento é interrompido quando o desempenho no conjunto de validação começa a diminuir.
- Normalização em lote: Normaliza a saída de uma camada de ativação anterior subtraindo a média do lote e dividindo pelo desvio padrão do lote. Isso ajuda a reduzir mudanças internas de covariáveis e às vezes atua como um regularizador.
- Aumento de dados: Envolve aumentar o tamanho e a diversidade do conjunto de dados de treinamento, aplicando várias transformações aos dados existentes. Isso ajuda o modelo a generalizar melhor para dados novos e invisíveis.
- Injeção de Ruído: Adicionar ruído às entradas ou pesos durante o treinamento pode melhorar a robustez e reduzir o overfitting. Isto força o modelo a aprender a generalizar bem, mesmo em pequenas perturbações.
- Reduzindo a complexidade do modelo: Simplificar a arquitetura do modelo reduzindo o número de camadas ou neurônios em cada camada pode evitar o sobreajuste, especialmente quando os dados são limitados.
- Restrição de peso: Imposição de restrições à magnitude dos pesos durante a otimização, como forçar os pesos a terem uma norma menor que um valor especificado.
Q11. Como você avalia o desempenho de um modelo de aprendizado profundo? Quais são algumas métricas comuns usadas?
A. Para avaliar o desempenho de um modelo de aprendizagem profunda, usamos diversas métricas que dependem do tipo de problema (por exemplo, classificação, regressão):
Para Classificação:
- Precisão: Proporção de observações previstas corretamente em relação ao total de observações.
- Precisão e Recuperação: A precisão é a proporção de observações positivas previstas corretamente em relação ao total de positivas previstas, enquanto a recuperação é a proporção de observações positivas previstas corretamente em relação a todas as observações na aula real.
- Pontuação F1: Média harmônica de precisão e recall.
- ROC-AUC: Área sob a curva Receiver Operating Characteristic, medindo a capacidade do modelo de distinguir entre classes.
- Matriz de Confusão: uma tabela usada para descrever o desempenho de um modelo de classificação.
Para regressão:
- Erro médio quadrático (MSE): Média dos quadrados dos erros ou desvios (diferença entre valores previstos e reais).
- Erro quadrático médio (RMSE): Raiz quadrada de MSE.
- Erro Médio Absoluto (MAE): Diferenças médias absolutas entre valores previstos e reais.
- R-quadrado: Proporção da variância na variável dependente que é previsível a partir das variáveis independentes.
Q12. Quais são algumas das considerações éticas ao usar modelos de aprendizagem profunda?
R. As considerações éticas na utilização de modelos de aprendizagem profunda incluem a garantia da privacidade dos dados, a prevenção de preconceitos e discriminação nas previsões dos modelos, a transparência na forma como os modelos tomam decisões e a responsabilização pelos resultados produzidos por estes modelos. Também é importante considerar o impacto ambiental do treinamento de grandes modelos e o potencial uso indevido da tecnologia de IA.
Q13. Compare e contraste TensorFlow e PyTorch.
A. Estaremos considerando os parâmetros abaixo:
- Tipo de Gráfico: o TensorFlow usa gráficos estáticos, enquanto o PyTorch usa gráficos dinâmicos.
- Fácil de usar: PyTorch é frequentemente considerado mais amigável e fácil para prototipagem.
- desenvolvimento: o TensorFlow está mais estabelecido para ambientes de produção.
- Comunidade e Suporte: ambos têm forte suporte da comunidade, mas o TensorFlow historicamente teve uma base de usuários maior.
- Performance: ambos evoluem continuamente e podem depender do caso de uso específico.
Q14. Como funcionam as redes neurais recorrentes (RNNs)? Explique as diferenças entre LSTMs e GRUs.
A. Redes Neurais Recorrentes (RNNs) são um tipo de rede neural projetada para processar dados sequenciais. Eles são particularmente eficazes para tarefas em que o contexto de pontos de dados anteriores é essencial para a compreensão do ponto de dados atual, como na modelagem de linguagem ou na análise de séries temporais.
Como funcionam os RNNs?
- Processamento Sequencial: RNNs processam sequências de dados mantendo uma 'memória' (estado oculto) de entradas anteriores. Atualizarseu estado oculto em cada etapa da sequência à medida que a rede processa cada elemento de entrada.
- Pesos Compartilhados: Um RNN aplica os mesmos pesos a cada etapa da sequência de entrada, permitindo que a rede generalize em diferentes posições da sequência.
- Desafios: RNNs tradicionais muitas vezes lutam com dependências de longo prazo devido a problemas como desaparecimento ou explosão de gradientes.
Arquiteturas RNN avançadas como Long Short-Term Memory (LSTMs) e Gated Recurrent Units (GRUs) precisarão enfrentar esses desafios.
Diferenças entre LSTMs e GRUs:
- Complexidade: LSTMs são mais complexos com três portas, enquanto GRUs são mais simples com duas portas.
- Controle de memória: LSTMs têm mais controle sobre a memória com células separadas e estados ocultos, enquanto GRUs têm um único estado mesclado.
- Contagem de parâmetros: LSTMs têm mais parâmetros devido à sua complexidade, levando potencialmente a tempos de treinamento mais longos em comparação com GRUs.
Q15. Descreva a arquitetura de uma CNN típica usada para reconhecimento de imagens. Quais são as diferentes camadas e suas funções?
A. Uma Rede Neural Convolucional (CNN) típica usada para reconhecimento de imagem consiste em várias camadas, cada uma com sua função específica. Aqui está uma visão geral da arquitetura e das funções das diferentes camadas:
- Camada de entrada:
- Esta camada contém os valores brutos de pixel da imagem.
- Camada Convolucional:
- O alicerce central de uma CNN.
- Aplica um conjunto de filtros que podem ser aprendidos à entrada.
- Cada filtro ativa certos recursos da entrada (como bordas e texturas).
- As operações convolucionais ajudam a rede a se concentrar nas regiões locais e a aprender hierarquias espaciais de recursos.
- Camada de ativação (geralmente ReLU):
- Segue cada camada convolucional.
- Introduz propriedades não lineares ao sistema, permitindo que a rede aprenda recursos mais complexos.
- ReLU (Rectified Linear Unit) é a função de ativação mais comum, transformando todos os valores negativos de pixel em 0.
- Camada de pooling (subamostragem):
- Segue a função de ativação.
- Reduz o tamanho espacial do volume de entrada (largura, altura) para a próxima camada convolucional.
- Ajuda a diminuir a carga computacional, o uso de memória e o número de parâmetros.
- O pooling máximo (obtendo o valor máximo em uma determinada janela) é comum.
- Camada Totalmente Conectada (FC):
- Os neurônios em uma camada totalmente conectada têm conexões com todas as ativações da camada anterior.
- Essas camadas são normalmente colocadas perto do final das arquiteturas CNN.
- Eles são usados para calcular as pontuações das turmas, resultando no tamanho do volume de [1x1xN], onde N é o número de turmas.
- Camada de Saída:
- A camada final totalmente conectada.
- Produz as probabilidades finais para cada classe.
- Eliminar Camadas (opcional):
- Às vezes, é usado entre camadas totalmente conectadas.
- Ajude a evitar o overfitting eliminando aleatoriamente (ou seja, definindo como zero) um conjunto de ativações.
- Camadas de normalização em lote (opcional):
- Pode ser adicionado após camadas convolucionais ou totalmente conectadas.
- Normalize a saída da camada anterior para estabilizar e acelerar o treinamento.
- Ativação Softmax ou Sigmóide (na camada de saída):
- Softmax é usado para classificação multiclasse, convertendo os resultados em pontuações de probabilidade.
- Sigmoid é usado para classificação binária.
Essa arquitetura pode variar com base em requisitos específicos e avanços na área. Existem muitas variações e inovações na prática, como diferentes tipos de operações convolucionais, funções de ativação avançadas e técnicas de pooling mais sofisticadas.
Q16. Explique o conceito de mecanismo de atenção na aprendizagem profunda. Como é usado em modelos como Transformers?
A. O mecanismo de atenção calcula um conjunto de pontuações de atenção, geralmente chamadas de pesos de atenção, para cada elemento na sequência de entrada. Essas pontuações determinam quanta atenção ou ênfase o modelo deve dar a cada elemento ao fazer previsões. No caso da tradução automática, por exemplo, o mecanismo de atenção permite que o modelo alinhe as palavras do idioma de origem com as palavras correspondentes no idioma de destino.
O mecanismo de atenção nos Transformers normalmente envolve três componentes principais: Consulta, Chave e Valor. Esses componentes são usados para calcular pontuações de atenção e gerar uma soma ponderada de valores, fornecendo um vetor de contexto para cada posição na sequência.
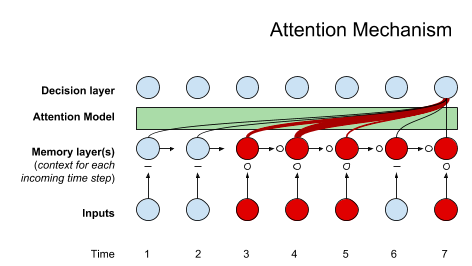
Ao incorporar mecanismos de atenção, modelos como Transformers apresentam desempenho aprimorado na captura de dependências de longo alcance e na compreensão das relações contextuais dentro das sequências. Isso os torna particularmente eficazes para tarefas de processamento de linguagem natural, incluindo tradução automática, resumo de texto e compreensão de linguagem. No geral, os mecanismos de atenção contribuem significativamente para o sucesso dos modelos Transformer em diversas aplicações de aprendizagem profunda.
Q17. Como o aprendizado profundo pode ser usado para tarefas de processamento de linguagem natural (PNL), como tradução automática e geração de texto?
R. O aprendizado profundo é fundamental no avanço das tarefas de processamento de linguagem natural (PNL), oferecendo abordagens sofisticadas de tradução automática e geração de texto. Deixe-me explicar como o aprendizado profundo é aplicado em cada um destes domínios:
- Maquina de tradução: Os modelos de aprendizagem profunda, especialmente as arquiteturas sequência a sequência, revolucionaram a tradução automática. Esses modelos, muitas vezes baseados em redes neurais recorrentes (RNNs) ou arquiteturas de transformadores, aprendem a compreender o contexto de uma frase em um idioma e geram uma tradução coerente em outro. Os mecanismos de atenção dentro desses modelos permitem que eles se concentrem em partes específicas da sequência de entrada, facilitando uma tradução precisa.
- Geração de Texto: Para tarefas como geração de texto, são empregados modelos de aprendizagem profunda, especialmente modelos generativos como LSTMs ou Transformers. Esses modelos são treinados em grandes corpora de texto para aprender padrões e dependências nos dados. Durante a geração, o modelo pode produzir texto novo e contextualmente relevante por meio de amostragem da distribuição aprendida de palavras. Isso é amplamente utilizado em chatbots, criação de conteúdo e aplicativos de escrita criativa.
Em ambos os casos, o poder da aprendizagem profunda reside na sua capacidade de aprender automaticamente representações hierárquicas e padrões intrincados a partir de grandes quantidades de dados. Isso permite que os modelos capturem nuances na linguagem, compreendam a semântica e gerem resultados contextualmente apropriados. A adaptabilidade e escalabilidade da aprendizagem profunda tornam-na uma pedra angular na evolução da PNL, fornecendo soluções eficazes para tarefas relacionadas com a linguagem em vários domínios.
Q18. O que são Redes Adversariais Generativas (GANs)? Explique o processo de treinamento e possíveis aplicações.
R. Redes Adversariais Generativas (GANs) são uma classe de algoritmos de inteligência artificial introduzida por Ian Goodfellow e seus colegas em 2014. GANs consistem em duas redes neurais, um gerador e um discriminador, envolvidos em um processo de treinamento adversário.
Processo de Treinamento: O processo de treinamento envolve um vaivém contínuo entre o gerador e o discriminador. O gerador refina sua saída com base no feedback do discriminador, que, por sua vez, se adapta para diferenciar melhor entre dados reais e gerados. Esse ciclo adversário continua até que o gerador produza resultados realistas e de alta qualidade.
- Gerador: O gerador visa criar dados realistas a partir de ruído aleatório ou de um espaço latente, como imagens. Seu objetivo principal é produzir dados indistinguíveis de exemplos reais no conjunto de treinamento.
- Discriminador: O discriminador avalia os dados gerados e reais e visa distinguir entre os dois. Atua essencialmente como juiz, determinando a autenticidade das amostras geradas.
Aplicações potenciais: As Redes Adversariais Generativas demonstraram um sucesso notável em vários domínios, tornando-as ferramentas versáteis e poderosas para tarefas que envolvem geração, transformação e aprimoramento de dados.
- Síntese de Imagens: GANs se destacam na geração de imagens realistas e de alta resolução. Eles têm sido usados para criar arte, gerar rostos e até imaginar cenas que não existem.
- Transferência de estilo: Os GANs podem transferir estilos artísticos de uma imagem para outra, permitindo transformações criativas de imagens.
- Super-Resolução: GANs são empregados para melhorar a resolução de imagens, tornando-as valiosas em aplicações como imagens médicas.
- Detecção de anomalia: GANs podem aprender os padrões normais nos dados e detectar anomalias, tornando-os úteis para detecção de fraudes e segurança cibernética.
- Aumento de dados: GANs podem gerar dados de treinamento adicionais, auxiliando em cenários onde a coleta de grandes conjuntos de dados é desafiadora.
Q19. Como a explicabilidade e a interpretabilidade podem ser melhoradas em modelos de aprendizagem profunda?
R. Melhorar a explicabilidade e a interpretabilidade dos modelos de aprendizagem profunda é crucial para construir confiança e compreender os seus processos de tomada de decisão. Aqui estão várias estratégias para conseguir isso:
- Simplificando Arquiteturas: A simplificação das arquiteturas de modelos, optando por arquiteturas mais simples, facilita um melhor entendimento. Evitar estruturas excessivamente complexas pode facilitar o rastreamento do fluxo de informações na rede.
- Utilizando modelos explicáveis: A escolha de modelos inerentemente interpretáveis para tarefas específicas, como árvores de decisão ou modelos lineares, aumenta a transparência. Esses modelos fornecem insights claros sobre como os recursos de entrada contribuem para as previsões.
- Incorporando Mecanismos de Atenção: Os mecanismos de atenção destacam partes relevantes das sequências de entrada, permitindo aos usuários ver em quais elementos o modelo se concentra durante as previsões. Isto é particularmente benéfico para tarefas baseadas em sequência, como processamento de linguagem natural.
- Propagação de relevância em camadas: Técnicas como a propagação de relevância em camadas alocam pontuações de relevância para cada neurônio ou recurso, ajudando a compreender a contribuição de componentes individuais para a previsão final.
- Explicações agnósticas de modelo interpretável local (LIME): LIME gera aproximações locais do comportamento do modelo, fornecendo insights sobre como o modelo toma decisões para instâncias específicas. Isso ajuda a compreender as previsões caso a caso.
- Mapas de Atenção e Grad-CAM: A visualização de mapas de atenção e mapas de ativação de classe baseados em gradiente (Grad-CAM) destacam regiões em imagens de entrada que influenciam significativamente as previsões do modelo, melhorando a interpretabilidade para tarefas baseadas em imagens.
- Garantindo a comunicação da importância do recurso: Comunicar a importância e o impacto dos recursos de entrada nas previsões ajuda os usuários a compreender a lógica de decisão do modelo.
- Ferramentas de visualização interativa: O desenvolvimento de ferramentas interativas que permitem aos usuários explorar e visualizar previsões de modelos, importância de recursos e caminhos de decisão aprimora a interpretabilidade geral.
Q20. Quais são os desafios da implantação de modelos de aprendizagem profunda em ambientes de produção?
R. A implantação de modelos de aprendizagem profunda na produção traz desafios únicos que exigem consideração cuidadosa e soluções estratégicas:
- AMPLIAR: Garantir que o modelo implantado possa lidar com o aumento da demanda e da carga de trabalho é crucial. Podem surgir desafios de escalabilidade devido a padrões de tráfego variados, diversas entradas de usuários e distribuições de dados em evolução.
- Requisitos de hardware: Os modelos de aprendizagem profunda muitas vezes exigem recursos computacionais substanciais, incluindo GPUs ou TPUs. Alinhar a infraestrutura de hardware com os requisitos do modelo e otimizar a utilização de recursos pode ser um desafio.
- Desempenho em tempo real: Alcançar desempenho em tempo real, especialmente para aplicações que exigem respostas de baixa latência, representa um desafio significativo. Otimizar a velocidade de inferência do modelo e ao mesmo tempo manter a precisão é um equilíbrio delicado.
- Privacidade e segurança de dados: O tratamento de dados confidenciais em ambientes de produção requer medidas de segurança robustas. Garantir a conformidade com os regulamentos de privacidade de dados e implementar técnicas de criptografia são aspectos críticos da implantação.
- Monitoramento e Manutenção Contínuos: Os modelos implantados precisam de monitoramento contínuo para detectar desvios nas distribuições de dados, degradação do desempenho ou outros problemas. Manter a eficácia do modelo ao longo do tempo e atualizá-lo com novos dados é um desafio constante.
- Controle de versão e governança de modelo: Gerenciar diferentes versões de modelos, rastrear alterações e garantir a consistência entre ambientes exigem práticas eficazes de controle de versão e governança. Isto é vital para manter a reprodutibilidade e a rastreabilidade.
- Interoperabilidade: A integração de modelos de aprendizagem profunda com sistemas de software, bancos de dados ou APIs existentes pode ser um desafio. É essencial garantir a interoperabilidade perfeita com outros componentes no ambiente de produção.
- Explicabilidade e Interpretabilidade: Abordar a natureza de caixa negra dos modelos de aprendizagem profunda é crucial para ganhar a confiança das partes interessadas. O desenvolvimento de métodos para explicar e interpretar decisões de modelos em cenários do mundo real é um desafio constante.
- Colaboração entre equipes: A colaboração eficaz entre cientistas de dados, engenheiros de machine learning e equipes de DevOps é essencial. Preencher a lacuna entre pesquisa e produção requer comunicação clara e compreensão das prioridades de cada equipe.
- Otimização de Custos: Gerenciar os custos associados à implantação e manutenção de modelos de aprendizagem profunda envolve otimizar o uso de recursos, considerar despesas com serviços de nuvem e garantir a relação custo-benefício ao longo do ciclo de vida do modelo.
Q21. Explique o conceito de aprendizagem por transferência na aprendizagem profunda. Como pode Você usar para melhorar o desempenho do modelo com dados limitados?
A. No aprendizado profundo, transferir aprendizado aproveita um modelo pré-treinado, inicialmente desenvolvido para uma tarefa, como ponto de partida para uma tarefa diferente, mas relacionada. Esta abordagem mostra-se particularmente benéfica quando se lida com dados rotulados limitados.
Aqui está um resumo de como funciona a aprendizagem por transferência e sua aplicação para melhorar o desempenho do modelo com dados limitados:
- Modelo pré-treinado: Uma rede neural profunda é pré-treinada em um grande conjunto de dados para uma tarefa específica, como classificação de imagens ou processamento de linguagem natural. O modelo aprende representações e recursos significativos do extenso conjunto de dados.
- Transferir para nova tarefa: Em vez de treinar um novo modelo do zero para uma tarefa alvo com dados limitados, o modelo pré-treinado é utilizado. O conhecimento adquirido durante a formação inicial é transferido para a nova tarefa, formando uma base sólida.
- Afinação: O modelo pré-treinado é ajustado no conjunto de dados limitado relevante para a nova tarefa. O ajuste fino envolve ajustar os pesos do modelo para se adaptar às características e nuances específicas da tarefa alvo.
- Extração de recursos: Em alguns casos, os recursos aprendidos pelo modelo pré-treinado podem ser usados diretamente como representações para a nova tarefa. Isto é conseguido removendo as camadas finais do modelo e conectando as camadas restantes a novas camadas específicas da tarefa.
- Benefícios para dados limitados: A aprendizagem por transferência mitiga o desafio dos dados rotulados limitados, aproveitando o conhecimento capturado pelo modelo pré-treinado. O modelo começa com uma melhor compreensão dos padrões e características gerais, exigindo menos dados para se adaptar às especificidades da nova tarefa.
- Adaptação de Domínio: A aprendizagem por transferência é eficaz em cenários onde as tarefas de origem e de destino compartilham características comuns. Facilita a adaptação de domínio, permitindo que modelos treinados em um domínio tenham um bom desempenho em domínios relacionados com o mínimo de dados rotulados.
- Aplicações: A aprendizagem por transferência encontra aplicações em vários domínios, incluindo reconhecimento de imagem, processamento de linguagem natural e análise de áudio. Por exemplo, um modelo pré-treinado em um grande conjunto de dados de imagens pode ser ajustado para tarefas específicas de reconhecimento de objetos com imagens rotuladas limitadas.
Q22. Como funciona a normalização em lote no aprendizado profundo? Quais são seus benefícios?
A normalização de lote (BatchNorm) é uma técnica de aprendizado profundo que aborda mudanças internas de covariáveis, normalizando a entrada de cada camada dentro de um minilote. Aqui está um resumo de como o BatchNorm funciona e seus benefícios associados:
Normalização dentro do minilote: Para cada minilote durante o treinamento, BatchNorm normaliza a entrada para uma camada subtraindo a média e dividindo pelo desvio padrão do minilote. Isso garante que a entrada para a camada subsequente tenha uma distribuição consistente, evitando que o modelo enfrente mudanças internas de covariáveis.
Parâmetros que podem ser aprendidos: BatchNorm introduz parâmetros que podem ser aprendidos (gama e beta) para cada recurso, permitindo que o modelo dimensione e altere os valores normalizados de forma adaptativa. Essa flexibilidade permite que o modelo mantenha sua expressividade mesmo após a normalização.
Integração na Formação: BatchNorm normalmente é aplicado após a função de ativação em uma camada. O processo de normalização está integrado na fase de treinamento, tornando-o parte integrante do processo de otimização.
Benefícios:
Convergência de treinamento acelerada: BatchNorm acelera o processo de treinamento, reduzindo mudanças internas de covariáveis, levando a gradientes mais estáveis e convergência mais rápida durante a otimização.
Mitigação de gradientes que desaparecem e explodem: BatchNorm ajuda a mitigar problemas relacionados a gradientes que desaparecem ou explodem, mantendo escalas de ativação consistentes em toda a rede.
Sensibilidade reduzida à inicialização: A técnica reduz a sensibilidade das redes neurais profundas à inicialização de peso, facilitando a escolha dos parâmetros iniciais que levam a uma convergência bem-sucedida.
Efeito de regularização: BatchNorm atua como uma forma de regularização adicionando ruído às ativações dentro de um minilote, reduzindo a necessidade de outras técnicas de regularização, como abandono em alguns casos.
Aplicabilidade entre arquiteturas:
BatchNorm é amplamente aplicável e benéfico em várias arquiteturas de aprendizagem profunda, incluindo redes neurais convolucionais (CNNs) e redes neurais recorrentes (RNNs), melhorando suas propriedades de estabilidade e convergência.
Q23. Discuta a importância do aumento de dados no aprendizado profundo. Quais são algumas técnicas comuns?
O aumento de dados é uma estratégia crucial no aprendizado profundo que envolve aumentar artificialmente a diversidade de um conjunto de dados de treinamento, aplicando várias transformações aos dados existentes. Aqui está uma exploração da importância do aumento de dados e algumas técnicas comuns:
Importância do aumento de dados:
- Maior Robustez: O aumento de dados aprimora a capacidade de generalização de um modelo, expondo-o a uma gama mais ampla de variações nos dados de treinamento, tornando-o mais robusto para diversas entradas.
- Mitigação do sobreajuste: aumentar o conjunto de dados ajuda a prevenir o sobreajuste, à medida que o modelo aprende a reconhecer padrões independentemente das variações, reduzindo sua sensibilidade ao ruído nos dados de treinamento.
- Generalização aprimorada: ao simular variações do mundo real, o aumento de dados ajuda na criação de modelos que generalizam bem para dados invisíveis, melhorando o desempenho geral em diversas entradas.
Técnicas comuns de aumento de dados:
- Rotação de imagem: girar imagens em vários ângulos simula diferentes pontos de vista, melhorando a capacidade do modelo de reconhecer objetos de diferentes orientações.
- Inversão horizontal e vertical: o espelhamento de imagens horizontal ou verticalmente introduz variações, especialmente benéficas para tarefas onde a orientação do objeto não afeta a classificação.
- Zoom e corte: ampliar ou cortar imagens aleatoriamente ajuda o modelo a lidar com variações nas escalas e posições dos objetos na entrada.
- Ajustes de brilho e contraste: A alteração dos níveis de brilho e contraste imita as mudanças nas condições de iluminação, tornando o modelo mais robusto às variações de iluminação.
- Tremulação de cores: a introdução de alterações aleatórias nos valores de cores nas imagens amplia a paleta de cores vista pelo modelo, melhorando sua capacidade de lidar com diversas distribuições de cores.
- Transformações geométricas: a aplicação de transformações geométricas, como transformações afins, ajuda o modelo a se adaptar às mudanças espaciais nos dados de entrada.
- Adicionando Ruído: A introdução de ruído aleatório nos dados de entrada contribui para a resiliência do modelo contra variações e ruído em cenários do mundo real.
- Aumento de texto: para tarefas de processamento de linguagem natural, técnicas como substituição, inserção ou exclusão de palavras simulam variações nos dados de texto.
Técnicas Específicas de Tarefas:
- Aumento de áudio: Para dados de áudio, técnicas como mudança de tom, alongamento de tempo e adição de ruído de fundo melhoram a robustez do modelo no tratamento de diferentes condições de áudio.
- Aumento de dados 3D: em tarefas que envolvem dados 3D, técnicas como rotação, translação e dimensionamento podem se estender a três dimensões.
Avançado
Q24. Explique o conceito de aprendizagem profunda bayesiana. Como pode ser usado para melhorar a estimativa da incerteza nos modelos?
A. O aprendizado profundo bayesiano integra princípios bayesianos em modelos de aprendizado profundo, tratando os pesos da rede como distribuições de probabilidade em vez de valores fixos. Isso permite uma melhor estimativa da incerteza nos modelos, fornecendo uma medida de confiança nas previsões. Ao capturar a incerteza associada aos parâmetros do modelo, a aprendizagem profunda bayesiana oferece previsões mais confiáveis e facilita a tomada de decisões em cenários onde a incerteza é crítica, como diagnósticos médicos ou sistemas autônomos.
Q25. O que são arquiteturas de redes neurais além de redes totalmente conectadas e CNNs? Discuta exemplos como redes de cápsulas ou redes neurais de grafos.
A. Arquiteturas como redes neurais de cápsulas e grafos (GNNs) vão além de redes totalmente conectadas e redes neurais convolucionais (CNNs). As redes cápsula visam superar as limitações na extração hierárquica de características das CNNs, melhorando as hierarquias espaciais no reconhecimento de imagens. As GNNs operam em dados estruturados em grafos, permitindo que modelos capturem dependências e relacionamentos entre elementos em domínios não euclidianos, como redes sociais ou estruturas moleculares.
Q26. Como você pode usar o aprendizado profundo para tarefas de aprendizado por reforço? Explique a conexão entre Q-learning e Deep Q-Networks.
R. O aprendizado profundo aprimora o aprendizado por reforço por meio de técnicas como Deep Q-Networks (DQN). Q-learning, um algoritmo de aprendizagem por reforço, pode estender com redes neurais profundas em DQN. Esta combinação permite a aproximação eficiente dos valores Q, representando a recompensa cumulativa esperada pela realização de uma ação num determinado estado. O DQN melhora o aprendizado em ambientes complexos, aproveitando redes neurais profundas para aproximar funções ideais de valor de ação, permitindo uma tomada de decisão mais eficaz em tarefas de aprendizagem por reforço.
Q27. Discuta as preocupações éticas em torno do preconceito nos modelos de aprendizagem profunda. Como podemos mitigar esses preconceitos?
R. As preocupações éticas na aprendizagem profunda surgem frequentemente de preconceitos de modelo, levando a resultados injustos ou discriminatórios. Mitigar preconceitos envolve:
- Dados diversos e representativos: garantir que os dados de treinamento representem dados demográficos diversos para evitar percepções distorcidas do modelo.
- Técnicas de detecção de preconceito: Auditar regularmente modelos em busca de preconceitos usando métricas e ferramentas de análise.
- IA Explicável (XAI): Implementação de modelos interpretáveis para compreender e retificar previsões tendenciosas.
- Quadros Éticos: Incorporar considerações éticas no desenvolvimento de modelos, guiados por estruturas éticas estabelecidas.
Q28. Quais são os últimos avanços na pesquisa de aprendizagem profunda? Quais são as potenciais aplicações futuras?
A. Os avanços recentes na aprendizagem profunda incluem:
- Modelos de transformadores: revolucionando o processamento de linguagem natural.
- Aprendizagem auto-supervisionada: Aprendizagem sem dados rotulados.
- Meta-Aprendizado: Permitir que modelos se adaptem rapidamente a novas tarefas.
- AI explicável (XAI): Melhorando a interpretabilidade do modelo.
As aplicações futuras podem incluir medicina personalizada, robótica avançada e colaboração aprimorada entre IA e humanos, moldando setores como saúde, robótica e educação.
Perguntas bônus
Q29. Compare o aprendizado profundo com abordagens de aprendizado de máquina, como Support Vector Machines (SVMs) ou árvores de decisão.
A. Aprendizagem profunda, Máquinas de vetor de suporte (SVMs) e árvores de decisão são abordagens distintas de aprendizado de máquina com características únicas:
Representação de Dados:
- Deep Learning: Aprende representações hierárquicas por meio de redes neurais, extraindo recursos automaticamente.
- SVMs: utiliza hiperplanos para separar dados em classes com base em vetores de recursos.
- Árvores de decisão: toma decisões por meio de uma estrutura semelhante a uma árvore de condições if-else com base em valores de recursos.
Lidando com a Complexidade:
- Aprendizado profundo: destaca-se no tratamento de tarefas complexas e grandes conjuntos de dados, capturando padrões intrincados.
- SVMs: Eficazes em espaços de grandes dimensões, adequados para tarefas com separação clara de margens.
- Árvores de decisão: adequadas para tarefas com limites de decisão não lineares e regras interpretáveis.
Treinamento e Interpretabilidade:
- Deep Learning: Requer grandes quantidades de dados rotulados para treinamento; modelos complexos podem não ter interpretabilidade.
- SVMs: Eficazes com conjuntos de dados de tamanho moderado; os limites de decisão podem ser interpretáveis.
- Árvores de decisão: adequadas para conjuntos de dados de tamanho pequeno a moderado; oferece regras de decisão interpretáveis.
Aplicações:
- Deep Learning: Amplamente utilizado em reconhecimento de imagens, processamento de linguagem natural e tarefas complexas de reconhecimento de padrões.
- SVMs: Aplicados em tarefas de classificação, especialmente em bioinformática e categorização de textos.
- Árvores de decisão: usadas em diagnósticos médicos, pontuação de crédito e sistemas de recomendação.
Q30. Como ce você usa aprendizagem profunda em saúde, finanças ou robótica?
A aprendizagem profunda tem aplicações transformadoras em vários campos:

Assistência médica:
- Imagens Médicas: O aprendizado profundo auxilia na análise de imagens para diagnosticar doenças, detectar anomalias em exames médicos e prever resultados de tratamentos.
- Descoberta de Medicamentos: Identifica potenciais candidatos a medicamentos através da análise de dados biológicos, acelerando o desenvolvimento de medicamentos.
- Apoio à decisão clínica: auxilia os profissionais de saúde no planejamento do tratamento e no atendimento ao paciente por meio de análises preditivas.

Financeira:
- Detecção de fraude: modelos de aprendizagem profunda podem detectar padrões incomuns em transações financeiras, melhorando a prevenção de fraudes.
- Negociação Algorítmica: Analisa tendências de mercado e faz previsões para estratégias de negociação otimizadas.
- Pontuação de crédito: melhora a precisão na avaliação da qualidade de crédito por meio da análise de diversas fontes de dados.

Robótica:
- Visão computacional: permite que robôs interpretem e respondam a informações visuais, melhorando a navegação e o reconhecimento de objetos.
- Reconhecimento de fala: Melhora a interação humano-robô por meio do processamento de linguagem natural.
- Veículos Autônomos: O deep learning contribui para a tomada de decisões em veículos autônomos, melhorando a segurança e a eficiência.
Nestes campos, a capacidade da aprendizagem profunda de processar dados complexos, reconhecer padrões e fazer previsões com base em grandes conjuntos de dados traz avanços significativos, impulsionando a inovação e a eficiência.
Conclusão
No mundo dinâmico da ciência de dados, manter-se à frente da curva é fundamental para garantir posições cobiçadas no setor. Navegar em uma entrevista de aprendizado profundo requer combinar conhecimento teórico, aplicação prática e pensamento crítico. As “30 principais perguntas da entrevista de aprendizado profundo para cientistas de dados” apresentadas aqui têm como objetivo equipá-lo com as ferramentas necessárias para lidar com entrevistas em vários níveis de dificuldade com confiança.
Lembre-se de que o processo de aprendizagem é inestimável à medida que você entra nas complexidades das redes neurais convolucionais, redes neurais recorrentes e outros conceitos de aprendizagem profunda. Ao dominar essas questões e desafios bônus, você não apenas aumenta suas chances de ser bem sucedido em entrevistas, mas também aprofunda sua compreensão dos fundamentos do aprendizado profundo.
Boa sorte com suas entrevistas! 🙂
Relacionado
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://www.analyticsvidhya.com/blog/2024/01/top-30-deep-learning-interview-questions-for-data-scientists/
- :tem
- :é
- :não
- :onde
- $UP
- 1
- 2014
- 225
- 30
- 300
- 3d
- a
- habilidade
- Sobre
- absoluto
- acelera
- acelerando
- responsabilidade
- precisão
- preciso
- Alcançar
- alcançado
- em
- Açao Social
- ativação
- ativações
- atos
- real
- Adam
- adaptar
- adaptabilidade
- adaptação
- adaptativo
- adapta
- adicionado
- acrescentando
- Adição
- Adicional
- endereços
- ajustar
- ajustando
- ajustes
- ajusta
- avançar
- avançado
- avanços
- Avançando
- vantagens
- adversarial
- afetar
- Depois de
- contra
- à frente
- AI
- SIDA
- visar
- visa
- algoritmo
- algoritmos
- alinhar
- alinhando
- Todos os Produtos
- distribuir
- permitir
- Permitindo
- permite
- juntamente
- ao lado de
- tb
- sempre
- quantidade
- quantidades
- an
- análise
- analítica
- analisar
- análises
- análise
- e
- detecção de anomalia
- Outro
- qualquer
- APIs
- relevante
- Aplicação
- aplicações
- aplicado
- aplica
- Aplicando
- abordagem
- se aproxima
- apropriado
- aproximado
- arquitetura
- SOMOS
- ÁREA
- surgir
- Arte
- artificial
- inteligência artificial
- artístico
- arte
- AS
- aspectos
- Avaliando
- Ativos
- ajuda
- associado
- Associação
- At
- por WhatsApp.
- auditivo
- auditoria
- autenticidade
- automaticamente
- Autônomo
- sistemas autônomos
- veículos autônomos
- média
- média
- evitar
- evitando
- fundo
- Equilíbrio
- saldos
- base
- baseado
- base
- Bayesiano
- BE
- Porque
- tornam-se
- tornando-se
- sido
- antes
- comportamento
- abaixo
- benéfico
- Benefícios
- MELHOR
- beta
- Melhor
- entre
- Pós
- viés
- tendencioso
- vieses
- Caixa preta
- Bloquear
- Bônus
- livro
- Livros
- ambos
- limites
- Cérebro
- ramos
- Break
- Breakdown
- ponte
- Trazendo
- Traz
- mais amplo
- Prédio
- mas a
- by
- calcular
- calcula
- chamado
- CAN
- candidatos
- capacidades
- Capacidade
- capturar
- capturados
- Capturar
- Cuidado
- Oportunidades
- cuidadoso
- casas
- casos
- célula
- certo
- cadeia
- desafiar
- desafios
- desafiante
- chances
- alterar
- Alterações
- Capítulo
- característica
- características
- chatbots
- escolha
- Escolha
- classe
- aulas
- classificação
- remover filtragem
- Na nuvem
- agrupamento
- CNN
- COERENTE
- colaboração
- colegas
- Coleta
- cor
- combinação
- combina
- combinando
- vem
- comum
- geralmente
- Comunicação
- comunidade
- comparar
- comparado
- compilado
- completar
- integrações
- complexidade
- compliance
- componentes
- compreender
- compreensivo
- computacional
- Computar
- computador
- Visão de Computador
- computação
- conceito
- conceitos
- concernente
- Preocupações
- condições
- confiança
- com confiança
- conectado
- Conexão de
- da conexão
- Coneções
- Considerar
- consideração
- Considerações
- considerado
- considerando
- consistente
- consiste
- restrições
- conteúdo
- Criação de conteúdo
- contexto
- contextual
- continua
- contínuo
- continuamente
- contraste
- contribuir
- contribui
- contribuição
- ao controle
- Convergência
- conversão
- rede neural convolucional
- núcleo
- pedra angular
- correta
- corretamente
- Correspondente
- custos
- poderia
- incontável
- cobiçado
- crio
- criado
- Criar
- criação
- Criatividade
- crédito
- credibilidade
- crítico
- crucial
- Atual
- curva
- Cíber segurança
- dados,
- Os pontos de dados
- privacidade de dados
- ciência de dados
- cientista de dados
- bases de dados
- conjuntos de dados
- desativando
- lidar
- Decidindo
- decisão
- Tomada de Decisão
- decisões
- diminuir
- decrescente
- profundo
- deep learning
- rede neural profunda
- redes neurais profundas
- Aprofundar
- Padrão
- definido
- Demanda
- Demografia
- depender
- dependências
- dependente
- Dependendo
- implantado
- Implantação
- desenvolvimento
- derivar
- descreve
- projetado
- desejado
- descobrir
- Detecção
- Determinar
- determinando
- desenvolver
- desenvolvido
- em desenvolvimento
- Desenvolvimento
- desvio
- DevOps
- diagnosticar
- diagnóstico
- diferença
- diferenças
- diferente
- diferenciar
- Dificuldade
- dimensões
- diminuindo
- direção
- diretamente
- descoberta
- Discriminação
- discutir
- doenças
- distinto
- distinguir
- distribuído
- distribuição
- distribuições
- diferente
- Diversidade
- do
- parece
- Não faz
- domínio
- domínios
- down
- distância
- condução
- Caindo
- droga
- Desenvolvimento de drogas
- dois
- durante
- dinâmico
- e
- cada
- mais fácil
- bordas
- Educação
- efeito
- Eficaz
- efetivamente
- eficácia
- efeitos
- eficiência
- eficiente
- elemento
- elementos
- ênfase
- empregada
- permitir
- permite
- permitindo
- engloba
- animador
- criptografia
- final
- contratado
- Engenheiros
- aumentar
- aprimorada
- aprimoramento
- Melhora
- aprimorando
- suficiente
- garante
- assegurando
- entrar
- Todo
- Meio Ambiente
- ambiental
- ambientes
- época
- épocas
- equipado
- erro
- erros
- escapar
- especialmente
- essencial
- essencialmente
- estabelecido
- Éter (ETH)
- considerações éticas
- avaliar
- Mesmo
- Cada
- evolução
- evolui
- evolução
- exemplo
- exemplos
- Excel
- apresentar
- existir
- existente
- esperado
- despesas
- experiência
- Explicação
- Explicação
- exploração
- explorar
- estender
- extensão
- extenso
- extrato
- Extração
- rostos
- Facial
- reconhecimento facial
- facilita
- facilitando
- mais rápido
- fc
- Característica
- Funcionalidades
- retornos
- campo
- Campos
- filtro
- filtros
- final
- financiar
- financeiro
- descoberta
- encontra
- caber
- fixado
- Flexibilidade
- fluxo
- flutuações
- Foco
- concentra-se
- segue
- Escolha
- Forças
- forçando
- formulário
- formulação
- para a frente
- Foundation
- Fundacional
- Fundações
- fração
- enquadramentos
- fraude
- detecção de fraude
- PREVENÇÃO DE FRAUDE
- freqüente
- freqüentemente
- da
- totalmente
- função
- funções
- fundamental
- futuro
- ganhou
- ganhando
- GANs
- lacuna
- fechado
- Portões
- engrenagens
- Geral
- gerar
- gerado
- gera
- gerando
- geração
- generativo
- redes adversárias geradoras
- gerador
- genre
- ter
- OFERTE
- dado
- Vislumbre
- Go
- meta
- governo
- GPUs
- gradientes
- gráfico
- redes neurais de grafos
- gráficos
- dirigido
- tinha
- manipular
- Manipulação
- acontece
- Hardware
- Ter
- saúde
- setor de saúde
- altura
- alturas
- ajudar
- ajuda
- ajuda
- SUA PARTICIPAÇÃO FAZ A DIFERENÇA
- oculto
- Alta
- alta qualidade
- de alta resolução
- Destaques
- dificultar
- sua
- historicamente
- detém
- Como funciona o dobrador de carta de canal
- HTTPS
- Ajuste de hiperparâmetros
- i
- identifica
- identificar
- if
- imagem
- análise de imagem
- Classificação de imagem
- Reconhecimento de Imagem
- imagens
- fotografia
- Imagiologia
- Impacto
- impactando
- executar
- implementação
- importância
- importante
- melhorar
- melhorado
- melhora
- melhorar
- in
- incluir
- Incluindo
- incorporando
- Crescimento
- aumentou
- Aumenta
- aumentando
- de treinadores em Entrevista Motivacional
- Individual
- indústrias
- indústria
- ineficiência
- influência
- INFORMAÇÕES
- Infraestrutura
- inerentemente
- do estado inicial,
- inicialmente
- Inovação
- e inovações
- entrada
- inputs
- dentro
- insights
- instabilidade
- instância
- instâncias
- em vez disso
- integral
- integrado
- Integra-se
- Inteligência
- interação
- interativo
- interno
- Interoperabilidade
- Entrevista
- Questões de entrevista
- Entrevistas
- para dentro
- complexidades
- intricado
- introduzido
- Introduz
- introduzindo
- inestimável
- envolve
- envolvendo
- questões
- IT
- iteração
- ESTÁ
- Trabalho
- jpg
- juiz
- Chave
- Conhecimento
- conhecido
- l2
- Falta
- paisagem
- língua
- grande
- Maior
- mais recente
- camada
- camadas
- conduzir
- principal
- APRENDER
- aprendido
- aprendizagem
- engenheiros de aprendizagem
- aprende
- menos
- deixar
- níveis
- Alavancagem
- aproveita as
- aproveitando
- encontra-se
- wifecycwe
- Iluminação
- como
- Lima
- LIMITE
- limitações
- Limitado
- Lista
- carregar
- local
- longo
- longo prazo
- mais
- procurando
- fora
- Baixo
- sorte
- máquina
- aprendizado de máquina
- maquina de tradução
- máquinas
- a Principal
- manutenção
- fazer
- FAZ
- Fazendo
- gerenciados
- muitos
- mapas
- Maratona
- Margem
- mercado
- Tendências de mercado
- Dominar
- matemático
- max-width
- máximo
- Posso..
- me
- significar
- significado
- significativo
- a medida
- medidas
- medição
- mecanismo
- mecanismos
- Mídia
- médico
- imagiologia médica
- medicina
- Memória
- método
- métodos
- Métrica
- poder
- mínimo
- Minimiza
- espelhamento
- mau uso
- Mitigar
- mitigando
- modelo
- modelagem
- modelos
- modificada
- molecular
- momento
- Ímpeto
- monitorados
- monitoração
- mais
- mais eficiente
- a maioria
- filme
- em movimento
- média móvel
- muito
- múltiplo
- Música
- natural
- Linguagem Natural
- Processamento de linguagem natural
- Natureza
- Navegar
- navegação
- Navegação
- Perto
- necessário
- você merece...
- necessário
- negativo
- líquido
- rede
- redes
- Neural
- rede neural
- redes neurais
- Neurônios
- Novo
- recentemente
- Próximo
- PNL
- nó
- nós
- Ruído
- normal
- nuances
- número
- numérico
- objeto
- Detecção de Objetos
- objetivo
- objetos
- observações
- of
- oferecer
- oferecendo treinamento para distância
- Oferece
- frequentemente
- on
- uma vez
- ONE
- queridos
- contínuo
- só
- operar
- operando
- Operações
- ideal
- otimizar
- otimização
- otimizado
- otimizando
- optando
- or
- organizações
- Outros
- Outros
- de outra forma
- Fora
- resultados
- saída
- outputs
- lado de fora
- Acima de
- global
- Superar
- Visão geral
- palete
- parâmetro
- parâmetros
- parte
- particularmente
- peças
- passar
- passou
- passado
- vias
- paciente
- assistência ao paciente
- padrão
- padrões
- realizar
- atuação
- realização
- executa
- Personalizado
- fase
- fases
- fotografias
- Passo
- essencial
- pixels
- colocado
- planejamento
- platão
- Inteligência de Dados Platão
- PlatãoData
- Jogar
- desempenha
- ponto
- pontos
- piscina
- pobre
- Popular
- coloca
- posição
- abertas
- positivo
- POSTAGENS
- potencial
- potencialmente
- poder
- poderoso
- ferramentas poderosas
- Prática
- prática
- práticas
- Precisão
- Previsível
- previsto
- prevendo
- predição
- Previsões
- preditivo
- Análise Preditiva
- preferido
- preparação
- apresentado
- evitar
- impedindo
- Prevenção
- impede
- anterior
- Valores
- primário
- princípios
- política de privacidade
- probabilidade
- Problema
- problemas
- processo
- processado
- processos
- em processamento
- produzir
- Produzido
- produz
- Produção
- promove
- propagação
- devidamente
- Propriedades
- proporção
- prototipagem
- Prova
- fornecer
- fornecido
- fornecendo
- pytorch
- Frequentes
- rapidamente
- acaso
- aleatoriedade
- alcance
- rapidamente
- raramente
- Taxa
- Preços
- em vez
- avaliações
- relação
- raciocínio
- Cru
- dados não tratados
- chegando
- reação
- Leitura
- reais
- mundo real
- em tempo real
- realista
- receber
- receber
- recentemente
- reconhecimento
- reconhecer
- Recomendação
- retificado
- recorrente
- reduzir
- Reduzido
- reduz
- redução
- redução
- redundante
- refinar
- Independentemente
- regiões
- regressão
- regularmente
- regulamentos
- aprendizagem de reforço
- relacionado
- Relacionamentos
- relevância
- relevante
- confiável
- confiança
- depender
- remanescente
- notável
- removendo
- representante
- representando
- representa
- requerer
- requeridos
- Requisitos
- exige
- pesquisa
- resiliência
- Resolução
- recurso
- Recursos
- Responder
- respostas
- Restaurantes
- resultando
- reter
- Opinões
- revolucionou
- Revolucionando
- Recompensa
- robótica
- robôs
- uma conta de despesas robusta
- robustez
- Tipo
- papéis
- raiz
- Regra
- regras
- Segurança
- mesmo
- satélite
- imagens de satélite
- AMPLIAR
- Escala
- Escalas
- dimensionamento
- digitaliza
- cenários
- Cenas
- Ciência
- Cientista
- cientistas
- pontuações
- marcar
- arranhar
- desatado
- temperado
- setor
- assegurando
- segurança
- medidas de segurança
- Vejo
- visto
- vê
- doadores,
- semântica
- envia
- sensível
- Sensibilidade
- sentença
- sentimento
- separado
- Seqüência
- Série
- serviço
- conjunto
- Conjuntos
- contexto
- vários
- SGD
- formação
- Partilhar
- mudança
- MUDANÇA
- Turnos
- assistência técnica de curto e longo prazo
- rede de apoio social
- mostrada
- Signal
- sinais
- periodo
- de forma considerável
- simples
- mais simples
- simular
- Simula
- simultaneamente
- solteiro
- Tamanho
- tamanhos
- hábil
- pequeno
- menor
- Liso
- sem problemas
- Redes Sociais
- meios de comunicação social
- Publicações nas redes sociais
- redes sociais
- Software
- sólido
- Soluções
- RESOLVER
- alguns
- às vezes
- sofisticado
- Parecer
- fonte
- Fontes
- Espaço
- espaços
- Espacial
- específico
- especificidades
- especificada
- discurso
- Reconhecimento de Voz
- velocidade
- velocidades
- splits
- quadrado
- Quadrada
- quadrados
- Estabilidade
- estabilizar
- estável
- padrão
- Comece
- começa
- Estado
- Unidos
- estático
- permanecendo
- Passo
- estoque
- paragem
- Pára
- franco
- Estratégico
- estratégias
- Estratégia
- córregos
- pontos fortes
- mais forte,
- estrutura
- estruturas
- Lutar
- Lutando
- subseqüente
- substancial
- sucesso
- bem sucedido
- tal
- adequado
- soma
- aprendizagem supervisionada
- ajuda
- supera
- Em torno da
- suscetibilidade
- sintético
- dados sintéticos
- .
- sistemas
- mesa
- equipamento
- Tire
- tomar
- Target
- Tarefa
- tarefas
- equipes
- técnica
- técnicas
- Tecnologia
- conta
- fluxo tensor
- teste
- ensaio
- texto
- geração de texto
- textual
- do que
- que
- A
- A fonte
- deles
- Eles
- então
- teórico
- Este
- deles
- Pensar
- Pensando
- isto
- três
- limiar
- prospera
- Através da
- todo
- tempo
- Séries temporais
- vezes
- para
- juntos
- também
- ferramentas
- topo
- Total
- para
- traçar
- Rastreabilidade
- Rastreamento
- Trading
- Estratégias de negociação
- tradicional
- tráfego
- Trem
- treinado
- Training
- Transações
- transferência
- transferido
- Transformar
- Transformação
- transformações
- transformadora
- transformador
- transformadores
- transformações
- Tradução
- Transparência
- tratamento
- tratamento
- Árvores
- Trend
- análise de tendências
- Tendências
- Confiança
- afinação
- sintonização
- VIRAR
- Passando
- dois
- tipo
- tipos
- típico
- tipicamente
- Incerteza
- para
- subjacente
- compreender
- compreensão
- Injusto
- único
- unidade
- unidades
- aprendizado não supervisionado
- até
- incomum
- Atualizar
- Atualizada
- Atualizações
- atualização
- us
- Uso
- usar
- caso de uso
- usava
- útil
- Utilizador
- user-friendly
- usuários
- usos
- utilização
- geralmente
- utilização
- utilizado
- utiliza
- VALIDAR
- validação
- Valioso
- valor
- Valores
- variável
- variáveis
- Variante
- variações
- vário
- variar
- variando
- Grande
- Veículos
- versátil
- versão
- controle de versão
- versões
- vertical
- verticalmente
- Vídeo
- pontos de vista
- visão
- visual
- visualização
- visualizar
- vital
- volume
- vs
- Caminho..
- we
- Clima
- webp
- Site
- peso
- BEM
- O Quê
- O que é a
- quando
- enquanto que
- se
- qual
- enquanto
- porque
- Largo
- Ampla variedade
- largamente
- janela
- de
- dentro
- sem
- Word
- palavras
- Atividades:
- trabalhar juntos
- trabalhar
- trabalho
- mundo
- seria
- escrita
- X
- ainda
- Você
- investimentos
- zefirnet
- zero
- zoom