Dependendo da qualidade e complexidade dos dados, os cientistas de dados gastam entre 45 e 80% de seu tempo em tarefas de preparação de dados. Isso implica que a preparação e a limpeza de dados tiram um tempo valioso do trabalho real de ciência de dados. Depois que um modelo de aprendizado de máquina (ML) é treinado com dados preparados e pronto para implantação, os cientistas de dados geralmente precisam reescrever as transformações de dados usadas para preparar dados para inferência de ML. Isso pode aumentar o tempo necessário para implantar um modelo útil que possa inferir e pontuar os dados de sua forma bruta.
Na Parte 1 desta série, demonstramos como o Data Wrangler permite um preparação de dados unificados e treinamento de modelo com experiência Piloto automático do Amazon SageMaker em apenas alguns cliques. Nesta segunda e última parte desta série, focamos em um recurso que inclui e reutiliza Gerenciador de dados do Amazon SageMaker transformações, como imputadores de valor ausente, codificadores ordinais ou one-hot e muito mais, juntamente com os modelos de piloto automático para inferência de ML. Esse recurso permite o pré-processamento automático dos dados brutos com a reutilização das transformações do recurso Data Wrangler no momento da inferência, reduzindo ainda mais o tempo necessário para implantar um modelo treinado em produção.
Visão geral da solução
O Data Wrangler reduz o tempo para agregar e preparar dados para ML de semanas para minutos, e o Autopilot cria, treina e ajusta automaticamente os melhores modelos de ML com base em seus dados. Com o Autopilot, você ainda mantém total controle e visibilidade de seus dados e modelo. Ambos os serviços foram desenvolvidos especificamente para tornar os profissionais de ML mais produtivos e acelerar o tempo de retorno.
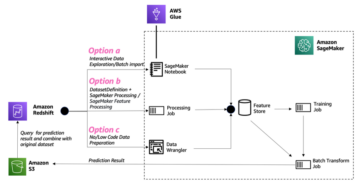
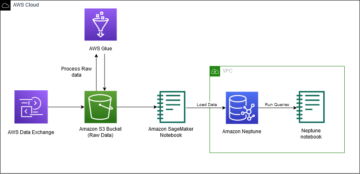
O diagrama a seguir ilustra nossa arquitetura de solução.
Pré-requisitos
Como este post é o segundo de uma série de duas partes, certifique-se de ter lido e implementado com sucesso Parte 1 antes de continuar.
Exportar e treinar o modelo
Na Parte 1, após a preparação de dados para ML, discutimos como você pode usar a experiência integrada no Data Wrangler para analisar conjuntos de dados e criar facilmente modelos de ML de alta qualidade no Autopilot.
Desta vez, usamos a integração do Autopilot mais uma vez para treinar um modelo em relação ao mesmo conjunto de dados de treinamento, mas em vez de realizar inferência em massa, realizamos inferência em tempo real em relação a um Amazon Sage Maker endpoint de inferência que é criado automaticamente para nós.
Além da conveniência fornecida pela implantação automática de endpoint, demonstramos como você também pode implantar com todas as transformações de recursos do Data Wrangler como um pipeline de inferência serial do SageMaker. Isso permite o pré-processamento automático dos dados brutos com a reutilização de transformações de recursos do Data Wrangler no momento da inferência.
Observe que, atualmente, esse recurso só tem suporte para fluxos do Data Wrangler que não usam transformações de junção, agrupamento por, concatenar e séries temporais.
Podemos usar a nova integração do Data Wrangler com o Autopilot para treinar diretamente um modelo da interface do usuário do fluxo de dados do Data Wrangler.
- Escolha o sinal de mais ao lado do Valores de escala nó e escolha Modelo de trem.
- Escolha Localização do Amazon S3, especifique o Serviço de armazenamento simples da Amazon (Amazon S3) local onde o SageMaker exporta seus dados.
Se for apresentado com um caminho de bucket raiz por padrão, o Data Wrangler cria um subdiretório de exportação exclusivo nele — você não precisa modificar esse caminho raiz padrão, a menos que queira. O Autopilot usa esse local para treinar um modelo automaticamente, economizando tempo de ter que definir o local de saída do fluxo do Data Wrangler e, em seguida, definir o local de entrada dos dados de treinamento do Autopilot. Isso torna a experiência mais perfeita. - Escolha Exportar e treinar para exportar os dados transformados para o Amazon S3.

Quando a exportação for bem-sucedida, você será redirecionado para o Criar um experimento de piloto automático página, com o Dados de entrada Local do S3 já preenchido para você (foi preenchido a partir dos resultados da página anterior). - Escolha Nome do experimento, insira um nome (ou mantenha o nome padrão).
- Escolha Target, escolha Resultado como a coluna que você deseja prever.
- Escolha Próximo: Método de treinamento.

Conforme detalhado no post O Amazon SageMaker Autopilot é até oito vezes mais rápido com o novo modo de treinamento ensemble desenvolvido com AutoGluon, você pode permitir que o Autopilot selecione o modo de treinamento automaticamente com base no tamanho do conjunto de dados ou selecione o modo de treinamento manualmente para otimização de conjunto ou de hiperparâmetro (HPO).
Os detalhes de cada opção são os seguintes:
- Auto – O Autopilot escolhe automaticamente o modo ensembling ou HPO com base no tamanho do seu conjunto de dados. Se seu conjunto de dados for maior que 100 MB, o Autopilot escolherá HPO; caso contrário, ele escolhe o conjunto.
- Montagem – O piloto automático usa o AutoGlúon técnica de ensembling para treinar vários modelos de base e combina suas previsões usando o empilhamento de modelos em um modelo preditivo ideal.
- Otimização de hiperparâmetros – O Autopilot encontra a melhor versão de um modelo ajustando hiperparâmetros usando a técnica de otimização Bayesiana e executando trabalhos de treinamento em seu conjunto de dados. O HPO seleciona os algoritmos mais relevantes para seu conjunto de dados e escolhe o melhor intervalo de hiperparâmetros para ajustar os modelos. Para nosso exemplo, deixamos a seleção padrão de Auto.
- Escolha Próximo: Implantação e configurações avançadas para continuar.

- No Implantação e configurações avançadas página, selecione uma opção de implantação.
É importante entender as opções de implantação com mais detalhes; o que escolhermos afetará se as transformações que fizemos anteriormente no Data Wrangler serão incluídas no pipeline de inferência:- Implante automaticamente o melhor modelo com transformações do Data Wrangler – Com esta opção de implantação, quando você prepara dados no Data Wrangler e treina um modelo invocando o Autopilot, o modelo treinado é implantado junto com todas as transformações de recursos do Data Wrangler como um Pipeline de inferência serial do SageMaker. Isso permite o pré-processamento automático dos dados brutos com a reutilização de transformações de recursos do Data Wrangler no momento da inferência. Observe que o endpoint de inferência espera que o formato de seus dados esteja no mesmo formato de quando foi importado para o fluxo do Data Wrangler.
- Implante automaticamente o melhor modelo sem transformações do Data Wrangler – Essa opção implanta um endpoint em tempo real que não usa transformações do Data Wrangler. Nesse caso, você precisa aplicar as transformações definidas em seu fluxo do Data Wrangler aos seus dados antes da inferência.
- Não implante automaticamente o melhor modelo – Você deve usar esta opção quando não quiser criar um endpoint de inferência. É útil se você deseja gerar o melhor modelo para uso posterior, como inferência em massa executada localmente. (Esta é a opção de implantação que selecionamos na Parte 1 da série.) Observe que quando você seleciona esta opção, o modelo criado (a partir do melhor candidato do Autopilot por meio do SDK do SageMaker) inclui as transformações do recurso Data Wrangler como um pipeline de inferência serial do SageMaker.
Para esta postagem, usamos o Implante automaticamente o melhor modelo com transformações do Data Wrangler opção.
- Escolha Opção de implantação, selecione Implante automaticamente o melhor modelo com transformações do Data Wrangler.
- Deixe as outras configurações como padrão.
- Escolha Próximo: Revisar e criar para continuar.
No Revise e crie página, vemos um resumo das configurações escolhidas para nosso experimento de piloto automático. - Escolha Criar experimento para iniciar o processo de criação do modelo.

Você é redirecionado para a página de descrição do trabalho do piloto automático. Os modelos aparecem no Modelos guia à medida que são gerados. Para confirmar que o processo foi concluído, vá para o Perfil de trabalho guia e procure um Completed valor para o Status campo.
Você pode voltar a esta página de descrição do trabalho do piloto automático a qualquer momento em Estúdio Amazon SageMaker:
- Escolha Experimentos e testes na Recursos do SageMaker menu suspenso.
- Selecione o nome do trabalho do Autopilot que você criou.
- Escolha (clique com o botão direito do mouse) a experiência e escolha Descrever trabalho do AutoML.
Veja o treinamento e a implantação
Quando o Autopilot concluir o experimento, podemos visualizar os resultados do treinamento e explorar o melhor modelo na página de descrição do trabalho do Autopilot.
Escolha (clique com o botão direito do mouse) o modelo rotulado Melhor modeloe escolha Abrir nos detalhes do modelo.

A Performance A guia exibe vários testes de medição de modelo, incluindo uma matriz de confusão, a área sob a curva de precisão/recordação (AUCPR) e a área sob a curva característica de operação do receptor (ROC). Eles ilustram o desempenho geral de validação do modelo, mas não nos dizem se o modelo generalizará bem. Ainda precisamos executar avaliações em dados de teste não vistos para ver com que precisão o modelo faz previsões (para este exemplo, prevemos se um indivíduo terá diabetes).
Execute a inferência em relação ao endpoint em tempo real
Crie um novo notebook SageMaker para realizar inferência em tempo real para avaliar o desempenho do modelo. Insira o seguinte código em um notebook para executar a inferência em tempo real para validação:
Depois de configurar o código para ser executado em seu notebook, você precisa configurar duas variáveis:
endpoint_namepayload_str
Configurar endpoint_name
endpoint_name representa o nome do endpoint de inferência em tempo real que a implantação criou automaticamente para nós. Antes de defini-lo, precisamos encontrar seu nome.
- Escolha Pontos finais na Recursos do SageMaker menu suspenso.
- Localize o nome do endpoint que tem o nome do trabalho do Autopilot que você criou com uma string aleatória anexada a ele.
- Escolha (clique com o botão direito do mouse) a experiência e escolha Descrever ponto final.

A Detalhes do terminal página aparece. - Realce o nome completo do terminal e pressione Ctrl + C para copiá-lo para a área de transferência.

- Insira este valor (certifique-se de que está cotado) para
endpoint_nameno caderno de inferência.
Configurar payload_str
O notebook vem com uma string de carga útil padrão payload_str que você pode usar para testar seu endpoint, mas sinta-se à vontade para experimentar valores diferentes, como os do conjunto de dados de teste.
Para extrair valores do conjunto de dados de teste, siga as instruções em Parte 1 para exportar o conjunto de dados de teste para o Amazon S3. Em seguida, no console do Amazon S3, você pode baixá-lo e selecionar as linhas para usar o arquivo do Amazon S3.
Cada linha em seu conjunto de dados de teste tem nove colunas, com a última coluna sendo a outcome valor. Para este código de notebook, certifique-se de usar apenas uma única linha de dados (nunca um cabeçalho CSV) para payload_str. Certifique-se também de enviar apenas um payload_str com oito colunas, onde você removeu o valor do resultado.
Por exemplo, se seus arquivos de conjunto de dados de teste se parecem com o código a seguir e queremos realizar inferência em tempo real da primeira linha:
Montamos payload_str para 10,115,0,0,0,35.3,0.134,29. Observe como omitimos o outcome valor de 0 no fim.
Se por acaso o valor de destino do seu conjunto de dados não for o primeiro ou o último valor, basta remover o valor com a estrutura de vírgula intacta. Por exemplo, suponha que estamos prevendo a barra e nosso conjunto de dados se parece com o seguinte código:
Neste caso, definimos payload_str para 85,,20.
Quando o notebook é executado com o configurado corretamente payload_str e endpoint_name valores, você recebe uma resposta CSV de volta no formato de outcome (0 ou 1), confidence (0-1).
Limpando
Para garantir que você não incorra em cobranças relacionadas ao tutorial após concluir este tutorial, certifique-se de desligar o aplicativo Data Wrangler (https://docs.aws.amazon.com/sagemaker/latest/dg/data-wrangler-shut-down.html), bem como todas as instâncias de notebook usadas para realizar tarefas de inferência. Os endpoints de inferência criados por meio da implantação do Auto Pilot também devem ser excluídos para evitar cobranças adicionais.
Conclusão
Nesta postagem, demonstramos como integrar seu processamento de dados, apresentando engenharia e construção de modelo usando Data Wrangler e Autopilot. Com base na Parte 1 da série, destacamos como você pode treinar, ajustar e implantar facilmente um modelo em um endpoint de inferência em tempo real com o Autopilot diretamente da interface do usuário do Data Wrangler. Além da conveniência fornecida pela implantação automática de endpoint, demonstramos como você também pode implantar todas as transformações do recurso Data Wrangler como um pipeline de inferência serial do SageMaker, fornecendo pré-processamento automático dos dados brutos, com a reutilização das transformações do recurso Data Wrangler em o momento da inferência.
Soluções de baixo código e AutoML, como Data Wrangler e Autopilot, eliminam a necessidade de ter um conhecimento profundo de codificação para criar modelos de ML robustos. Comece a usar o Data Wrangler hoje para ver como é fácil criar modelos de ML usando o Autopilot.
Sobre os autores
 Geremy Cohen é Arquiteto de Soluções da AWS, onde ajuda os clientes a criar soluções de ponta baseadas em nuvem. Em seu tempo livre, ele gosta de caminhadas curtas na praia, explorando a área da baía com sua família, consertando coisas em casa, quebrando coisas em casa e fazendo churrasco.
Geremy Cohen é Arquiteto de Soluções da AWS, onde ajuda os clientes a criar soluções de ponta baseadas em nuvem. Em seu tempo livre, ele gosta de caminhadas curtas na praia, explorando a área da baía com sua família, consertando coisas em casa, quebrando coisas em casa e fazendo churrasco.
 Pradeep Reddy é Gerente de Produto Sênior na equipe SageMaker Low/No Code ML, que inclui SageMaker Autopilot, SageMaker Automatic Model Tuner. Fora do trabalho, Pradeep gosta de ler, correr e se divertir com computadores do tamanho da palma da mão, como raspberry pi e outras tecnologias de automação residencial.
Pradeep Reddy é Gerente de Produto Sênior na equipe SageMaker Low/No Code ML, que inclui SageMaker Autopilot, SageMaker Automatic Model Tuner. Fora do trabalho, Pradeep gosta de ler, correr e se divertir com computadores do tamanho da palma da mão, como raspberry pi e outras tecnologias de automação residencial.
 Dr. João Ele é engenheiro sênior de desenvolvimento de software da Amazon AI, onde se concentra em aprendizado de máquina e computação distribuída. Possui doutorado pela CMU.
Dr. João Ele é engenheiro sênior de desenvolvimento de software da Amazon AI, onde se concentra em aprendizado de máquina e computação distribuída. Possui doutorado pela CMU.
- AI
- arte ai
- gerador de arte ai
- ai robô
- Amazon Sage Maker
- Piloto automático do Amazon SageMaker
- Gerenciador de dados do Amazon SageMaker
- inteligência artificial
- certificação de inteligência artificial
- inteligência artificial em bancos
- robô de inteligência artificial
- robôs de inteligência artificial
- software de inteligência artificial
- Aprendizado de máquina da AWS
- blockchain
- conferência blockchain ai
- Coingenius
- inteligência artificial conversacional
- conferência de criptografia ai
- dall's
- deep learning
- google ai
- aprendizado de máquina
- platão
- platão ai
- Inteligência de Dados Platão
- Jogo de Platão
- PlatãoData
- jogo de platô
- escala ai
- sintaxe
- zefirnet