Ultima actualizare: ianuarie 2021.
Acest blog este o prezentare cuprinzătoare a utilizării OCR cu orice instrument RPA pentru automatizarea fluxurilor de lucru ale documentelor. Explorăm modul în care cele mai recente tehnologii OCR bazate pe învățarea automată nu necesită reguli sau configurarea șablonului.

RPA-urile sau automatizarea proceselor robotizate sunt instrumente software care vizează eliminarea sarcinilor repetitive de afaceri. Mai mulți CIO se îndreaptă către ei pentru a reduce costurile și pentru a-i ajuta pe angajați să se concentreze pe munca de afaceri cu valoare mai mare. Exemplele includ răspunsul la comentarii de pe site-uri web sau procesarea comenzilor clienților. Sarcinile ceva mai complexe includ manipularea documentelor precum forme scrise de mână și facturi – these typically need to be moved from one legacy system to the other – say your email client to your SAP ERP system where you need to extract data. Aceasta este partea problematică.
Most OCR tools that capture data from these documents are template based (say Abbyy Flexicapture) and don’t scale well on semi-structured documents. There are newer generation machine learning based solutions that typically provide API
integrări care pot captura perechi cheie-valoare din documente – sistemele de întreprindere sunt de obicei vechi și nu sunt deschise pentru a fi integrate cu API-uri externe. Pe de altă parte, RPA-urile sunt construite pentru a gestiona aceste fluxuri de lucru vechi ale sistemului, cum ar fi ingerarea documentelor din foldere și introducerea rezultatelor în ERP-uri sau CRM-uri.
Pe măsură ce Robotic Process Automation (RPA) și ML evoluează către hiper-automatizare, putem folosi roboții software împreună cu ML pentru a gestiona sarcini complexe, cum ar fi clasificarea documentelor, extragerea și recunoașterea optică a caracterelor. Într-un studiu recent, s-a spus că, prin automatizarea a doar 29% din funcții pentru o sarcină folosind RPA-uri, numai departamentele financiare economisesc mai mult de 25,000 de ore de reluare cauzate de erori umane la costul de 878,000 USD pe an pentru o organizație cu 40 personalul de contabilitate a timpului [1]. În acest blog, vom învăța despre utilizarea OCR-urilor cu RPA și vom cerceta în detaliu fluxurile de lucru pentru înțelegerea documentelor. Mai jos sunt cuprinsul.
Definiții și prezentare generală
RPA, in general, is a technology that helps automate administrative tasks via software-hardware bots. These bots take advantage of user interfaces; to capture the data and manipulate applications as humans do. For example, an RPA can look at a series of tasks taken in a GUI, say moving cursors, connect to APIs, copy-pastes the data, and formulates the same sequence of actions in an RPA wireframe that translates to code. Further, these tasks can be performed without human intervention in the future. Optical Character Recognition (OCR) is a crucial feature of any functional robotic process automation (RPA) solution. This technology is used to read and extract text from different sources like images or pdfs into a digital format without manually capturing it.
Pe de altă parte, înțelegerea documentelor este termenul folosit pentru a descrie automat citirea, interpretarea și acționarea asupra datelor documentului. Cel mai important în acest proces este ca robotii software însuși îndeplinesc toate sarcinile. Acești roboți profită de puterea inteligenței artificiale și a învățării automate pentru a înțelege documentele ca asistenți digitali. În acest fel, putem spune că înțelegerea documentelor apare la intersecția procesării documentelor, AI și RPA.

Cum pot învăța roboții să înțeleagă documentele cu OCR și ML
Înainte de a ne aprofunda mai întâi în înțelegerea documentelor, să vorbim despre rolul roboților pentru înțelegerea documentelor. Acești ajutoare complet invizibili ne fac viața mult mai confortabilă. Spre deosebire de filme și seriale, acești roboți nu sunt dispozitive fizice sau programe de inteligență artificială care stau la un desktop și apasă butoane pentru a îndeplini sarcini. Ne putem gândi la aceștia ca asistenți digitali care sunt instruiți să proceseze documente prin citirea și utilizarea aplicațiilor așa cum facem noi. Din punct de vedere funcțional, roboții sunt buni la îmbunătățirea performanței și eficienței unui proces. Cu toate acestea, fiind un software de sine stătător, nu pot evalua procesul și nu pot lua decizii cognitive. Cu toate acestea, dacă învățarea automată este integrată cu succes, robotica va deveni mai dinamică și mai adaptabilă. De exemplu, roboții utilizați pentru procesarea documentelor, gestionarea datelor și alte funcții din front și middle office vor efectua acțiuni mai inteligente, cum ar fi eliminarea intrărilor duplicate sau rezolvarea excepțiilor de sistem necunoscute în acest proces. În plus, roboții sunt instruiți să citească, să extragă, să interpreteze și să acționeze pe baza datelor din documente folosind inteligența artificială (AI).
Cum pot companiile să integreze OCR inteligent cu RPA pentru a îmbunătăți fluxurile de lucru
Extragerea datelor din document este o componentă crucială pentru înțelegerea documentului. În această secțiune, vom discuta despre cum putem integra OCR cu RPA sau invers. În primul rând, știam cu toții că există diferite tipuri de documente în ceea ce privește șabloanele, stilul, formatarea și, uneori, limbajul. Prin urmare, nu ne putem baza pe o tehnică OCR simplă pentru a extrage datele din aceste documente. Pentru a rezolva această problemă, vom folosi atât abordări bazate pe reguli, cât și abordări bazate pe model în OCR pentru a gestiona datele din diferite structuri de documente. Acum vom vedea cum companiile care fac OCR pot integra RPA-uri în sistemul lor existent în funcție de tipul de documente.
Documente structurate: În acest tip de documente, machetele și șabloanele sunt de obicei fixe și aproape consistente. De exemplu, luați în considerare o organizație care face KYC cu acte de identitate emise de guvern, cum ar fi un pașaport sau permis de conducere. Toate aceste documente vor fi identice și vor avea aceleași câmpuri cu Numărul de identitate, Numele persoanei, Vârsta și câteva altele la aceleași poziții. Dar doar detaliile variază. Pot exista puține constrângeri, cum ar fi depășirea tabelului sau datele neînregistrate.
De obicei, abordarea recomandată utilizează un șablon sau un motor bazat pe reguli pentru a extrage informațiile pentru documentele structurate. Acestea pot include expresii regulate sau simpla mapare a poziției și OCR. Prin urmare, pentru a integra roboți software pentru a automatiza extragerea informațiilor, putem fie să folosim șabloane preexistente, fie să creăm reguli pentru datele noastre structurate. Există un dezavantaj în utilizarea abordării bazate pe reguli, deoarece se bazează pe părți fixe, chiar și modificări minore în structura formularului pot duce la defectarea regulilor.
Documente semistructurate: These documents have the same information but are arranged in different positions. For example, consider facturi containing 8-12 identical fields. In a few facturi, the merchant address can be located at the top, and in others, it can be found at the bottom. Typically these rule-based approaches do not give high accuracies; hence we bring in machine learning and deep learning models into the picture for information extraction using OCR. Alternatively, in some cases, we can use hybrid models involving both rules and ML models. A few popular pre-trained models are FastRCNN, Attention OCR, Graph Convolutions for information extraction in documents. However, again these models have few drawbacks; hence we measure the algorithm performance using metrics like accuracy or confidence score. Because the model is learning patterns, rather than operating off concrete rules, it may make mistakes initially right after corrections. However, the solution to these drawbacks – the more samples the ML model processes, the more patterns it learns to ensure accuracy.
Documente nestructurate: RPA, today is unable to manage unstructured data directly, hence requiring robots first to extract and create structured data using OCR. Unlike structured and semi-structured documents, unstructured data doesn’t have a few key-values pairs. For example, in a few facturi, we see a merchant address somewhere without any key name; similarly, we observe the same for other fields like date, invoice ID. For ML models to accurately process these, the robots need to learn how to translate written text into actionable data, like an email, phone number, address, etc. The model then will learn that 7- or 10-digit number patterns should be extracted as phone numbers and huge text containing five-digit codes and different nouns as text. To make these models more accurate, we can also use techniques from Natural Language Processing (NLP) like Named Entity Recognition and Word Embedding.
În general, pentru înțelegerea documentelor, este mai întâi esențial să înțelegeți datele și apoi să implementați OCR cu RPA-uri. Apoi, mai degrabă decât să mapam un proces pas cu pas, putem învăța un robot să „facă așa cum fac eu”, înregistrând procesul așa cum se întâmplă cu capabilități OCR puternice, așa cum am discutat mai sus, prin integrarea regulilor și a algoritmilor de învățare automată. Robotul software urmărește clicurile și acțiunile dvs. pe ecran și apoi le transformă într-un flux de lucru editabil. Dacă lucrați în întregime în programe locale, este atât de mult pe care ar trebui să știți.
Provocări OCR cu care se confruntă dezvoltatorii RPA
Am văzut cum putem integra OCRR cu RPA-uri pentru diferite documente, dar există câteva cazuri de provocări în care roboții trebuie să se descurce bine. Să le discutăm acum!
- Date slabe sau inconsecvente: Datele joacă un rol crucial în înțelegerea documentelor. În cele mai multe cazuri, documentele sunt scanate folosind camere unde există șansa de a pierde formatarea documentului în timpul scanării textului (adică, aldine, cursive și subliniere nu sunt întotdeauna recunoscute). Uneori, OCR poate extrage text în mod greșit, ceea ce duce la erori de ortografie, întreruperi neregulate de paragraf, ceea ce reduce performanța generală a roboților. Prin urmare, gestionarea tuturor valorilor lipsă și capturarea datelor cu o precizie mai mare este vitală pentru a obține o precizie mai mare pentru OCR.
- Orientare incorectă a paginii în documente: Orientarea paginii și asimetria este, de asemenea, una dintre problemele comune care duc la corectarea incorectă a textului OCR. Acest lucru se întâmplă de obicei atunci când documentele sunt scanate incorect în timpul fazei de colectare a datelor. Pentru a depăși acest lucru, va trebui să declarăm roboților câteva funcții, cum ar fi potrivirea automată pe pagină, filtrarea automată, astfel încât să poată permite creșterea calității documentului scanat și primirea datelor corecte la ieșire.
- Probleme de integrare: Nu toate instrumentele RPA funcționează bine în mediile desktop la distanță – ele provoacă blocări și probleme critice în automatizare. În plus, dezvoltatorul RPA trebuie să știe care soluție OCR va fi cea mai bună pentru un caz specific. De asemenea, pentru a lucra cu instrumente de automatizare specifice, dezvoltatorul RPA trebuie să aleagă doar tehnologia OCR limitată creată de Microsoft, Google. Prin urmare, integrarea algoritmilor și modelelor noastre personalizate este uneori o provocare.
- Tot textul este text amestecat: Pentru cazurile de utilizare din viața reală, textul capturat de un OCR generic este amestecat și nu are informații semnificative pe care roboții le pot folosi pentru a efectua operațiuni semnificative. Dezvoltatorii RPA au nevoie de suport puternic ML pentru a putea crea aplicații utile.
Flux de lucru pentru înțelegerea documentelor
În secțiunile anterioare, am văzut cum roboții ajută la realizarea OCR pentru diferite tipuri de documente. Dar OCR este doar o tehnică care convertește imagini sau alte fișiere în text. Acum, în această secțiune, ne vom uita la fluxul de lucru Înțelegerea documentelor chiar de la începutul culegerii documentelor până la salvarea lor în sfârșit de informații semnificative în formatul dorit.

- Ingerați documentul dintr-un folder folosind Botul dvs.: Acesta este primul pas prin atingerea înțelegerii documentelor prin intermediul roboților. Aici, vom prelua documentul aflat fie pe o platformă cloud (folosind un API), fie de pe o mașină locală. În câteva cazuri, dacă documentele noastre sunt pe pagini web, putem automatiza scripturile de scraping prin roboți de unde pot prelua documente în timp util.
- Tipul documentului: After we fetch the data, it’s essential to understand the type of document and the format with which they are saved in our systems, as sometimes, we receive data from different sources in various file formats such as PDF, PNG, and JPG. Not just the file types, sometimes when the documents are scanned with phone cameras, a few challenging problems like image skewness, rotation, brightness, or low-resolution should also be handled. Thereby, we’ll have to make sure that bots classify these documents into the structured, semi-structured, or unstructured category, thus saving it in a generic format. The classification task is achieved by comparing the documents with templates and analyzing features like fonts, language, presence of key-value pairs, tables, etc.
- Extragerea datelor cu OCR: Bine, acum că roboții ne-au aranjat documentele într-un format generic și le-au clasificat, a sosit timpul să le digitalizăm folosind tehnica OCR. Cu aceasta, vom avea textul, locația lui în coordonate din imagini. Acest lucru ajută la standardizarea documentelor și datelor pentru etapele următoare. De asemenea, întâlnim câteva momente când software-ul OCR nu a putut distinge corect între caractere, cum ar fi „t” versus „i” sau „0” versus „O”. Erorile pe care doriți să le evitați folosind software-ul OCR pot deveni noi bătăi de cap atunci când tehnologia OCR nu este capabilă să analizeze nuanțele unui document pe baza calității sau a formei sale originale. Aici intervine învățarea automată, despre care vom discuta în pasul următor.
- Utilizarea ML/DL pentru Intelligent OCR folosind Bots: După ce datele sunt digitizate, software-ul OCR ar trebui să înțeleagă tipul de document cu care lucrează și ce este relevant. Dar software-ul tradițional OCR se poate lupta cu eforturile de clasificare a documentelor. Prin urmare, roboții software ar trebui antrenați cu abilități cognitive prin valorificarea tehnicilor de învățare automată și de învățare profundă pentru a face OCR-urile mai inteligente. Soluțiile OCR bazate pe ML pot identifica un tip de document și îl pot potrivi cu un tip de document cunoscut utilizat de afacerea dvs. De asemenea, pot analiza și înțelege blocuri de text din documente nestructurate. Odată ce soluția știe mai multe despre documentul în sine, poate începe să extragă informații relevante bazate pe intenție și semnificație.
- Extragerea și clasificarea mai bună a datelor: Extragerea datelor este nucleul înțelegerii documentelor. După cum sa discutat în secțiunea anterioară despre Integrarea RPA-urilor cu OCR în acest pas, optați pentru tehnica de extracție a datelor în funcție de tipul de document. Prin intermediul RPA-urilor, putem configura cu ușurință ce extractor să folosim, fie o tehnică OCR bazată pe reguli sau bazată pe ML sau un model hibrid. Pe baza valorilor de încredere și de performanță care sunt returnate după extragerea informațiilor, roboții software le vor salva în formatul dorit pentru analiză ulterioară. Mai jos este o imagine a modului în care putem configura extractoare și seta nivelul de încredere într-un instrument RPA de la UIPath.

6. Validare și împuternicire Insights: Modelele OCR și Machine Learning nu sunt sută la sută precise în ceea ce privește extragerea informațiilor, prin urmare adăugarea unui strat de intervenție umană cu ajutorul roboților poate rezolva problema. Modul în care funcționează această validare este că, ori de câte ori roboții se confruntă cu acuratețe scăzută și excepții, ea ridică imediat o notificare către centrul de acțiuni unde un angajat poate primi o solicitare de validare a datelor sau de a gestiona excepții și poate rezolva orice incertitudine în doar câteva clicuri. În plus, putem debloca potențialul inteligenței artificiale de a documenta datele în timp pentru a face predicții și de a identifica potențialele anomalii care pot indica fraudă, duplicare și alte erori.
Beneficiile integrării roboților cu Document Understanding
- Automatizarea procesului: Motivul cheie pentru integrarea boților pentru înțelegerea documentelor este automatizarea întregului proces de la început până la sfârșit. Tot ce trebuie să facem este să creăm un flux de lucru pentru ca roboții să învețe, să stea pe loc și să se relaxeze. În timpul procesului de validare, este posibil să fie nevoie să rezolvăm problemele care sunt notificate de roboți în cazul în care sunt identificate erori sau fraude.
- Boți cu învățare automată: În timpul procesului de automatizare, putem face roboții rezistenți la învățarea automată. Înseamnă că roboții pot afla, de asemenea, cum funcționează modelele de învățare automată și, prin urmare, pot îmbunătăți modelele pentru a obține o precizie și performanță mai ridicate pentru extragerea de text și informații a documentelor.
- Procesează o gamă largă de procesare a documentelor: Pentru sarcini generale, cum ar fi extragerea tabelelor și a informațiilor, va trebui să creăm diferite conducte de învățare profundă pentru diferite tipuri de documente. Acest lucru duce la construirea mai multor aplicații și la implementarea diferitelor modele pe diferite servere, ceea ce necesită mult efort și timp. Când roboții sunt în imagine pentru o gamă largă de documente, am putea avea doar o singură conductă în care roboții îi pot clasifica și apoi pot folosi modelul adecvat pentru diferite sarcini. De asemenea, putem integra diverse servicii prin intermediul API-urilor și putem comunica cu alte organizații în ceea ce privește preluarea datelor.
- Ușor de implementat: Pentru înțelegerea documentelor după crearea conductelor, procesul de implementare durează doar un minut. Putem avea fie exportate API-uri de către roboți după antrenament, fie putem construi o soluție RPA personalizată care poate fi utilizată în sistemele noastre locale. Acest tip de implementare poate optimiza, de asemenea, întreprinderile și poate reduce cheltuielile cu riscuri foarte minime.
Intră Nanonets
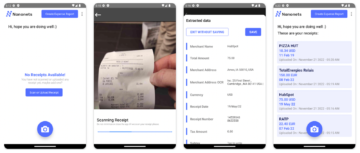
NanoNets is a Machine Learning platform that allows users to capture data from facturi, receipts, and other documents without any template setup. We have state of the art deep learning and computer vision algorithms running at the back that can handle any kind of document understanding tasks like OCR, table extraction, key-value pair extraction. They are usually exported as APIs or can be deployed on-premises based on different use cases. Here are a few examples,
- Invoice Model: Identify key fields from Facturi like Buyers Name, Invoice Id, Date, Amount etc.
- Model de chitanțe: identificați câmpurile cheie din chitanțe, cum ar fi numele vânzătorului, numărul, data, suma etc.
- Permis de conducere (SUA): Identificați câmpurile cheie, cum ar fi numărul de permis, data de expirare, data emiterii etc.
- CV-uri: extrageți experiență, educație, seturi de abilități, informații despre candidați etc.
To make these workflows faster and robust, we use UiPath, an RPA tool for seamless automation of your documents without any template. In the next section, we’ll go through how you can use UiPath Connect with Nanonets for document understanding. The 3 biggest players in the RPA market are UiPath, Automation Anywhere and Prisma albastră. This blog focuses on Uipath.
NanoNets cu UiPath
Am învățat să creăm un canal de înțelegere a documentelor în secțiunile noastre anterioare. Necesită cunoștințe de bază despre OCR, RPA și învățare automată, deoarece există abordări și algoritmi diferite pentru diferite sarcini în diferite puncte. De asemenea, trebuie să depunem mult efort pentru a construi rețele neuronale care să înțeleagă șabloanele noastre, să ne instruim și să le implementăm. Prin urmare, pentru a fi confortabil și pentru a automatiza totul, de la încărcarea documentelor, clasificarea lor, construirea OCR, integrarea modelelor ML, noi cei de la Nanonets lucrăm la Ui Path pentru a crea o conductă fără întreruperi pentru înțelegerea documentelor. Mai jos este o imagine a modului în care funcționează.

Acum să analizăm fiecare dintre acestea și să aflăm cum putem integra Nanonets cu UiPath.
Pasul 1: Înscrieți-vă la UiPath și descărcați UiPath Studio
Pentru a crea un flux de lucru, mai întâi, va trebui să creăm un cont în UiPath. Dacă sunteți un utilizator existent, vă puteți conecta direct la contul dvs., redirecționând tabloul de bord UiPath. Apoi, va trebui să descărcați și să instalați UiPath Studio (Community Edition), care este gratuit.
Pasul 2: Descărcați componenta Nanonets
Apoi, pentru a configura dvs conducta de procesare a facturii, va trebui să descărcați conectorul Nanonets din linkul de mai jos.
-> NanoNets OCR – Componentă RPA
Mai jos este o captură de ecran a UiPath Marketplace și a componentei Nanonets. De asemenea, pentru a descărca acest lucru, asigurați-vă că v-ați conectat la UiPath dintr-un sistem de operare Windows.

Fișierele descărcate trebuie să conțină fișierele enumerate mai jos,
UiPath OCR Predict ├── Main.xaml
└── project.json
Pasul 3: Deschideți fișierul Main.xaml Componenta Nanonets
Pentru a verifica dacă Nanonets UiPath funcționează sau nu, puteți deschide fișierul Main.xml din componenta Nanonets descărcată folosind Ui Path Studio. Apoi, puteți vedea pipeline deja creat pentru dvs. pentru procesarea documentelor.

Pasul 4: Adunați ID-ul modelului, cheia API și punctul final API din APP Nanonets
Apoi, puteți utiliza oricare dintre modelele OCR instruite din Nanonets APP și puteți aduna ID-ul modelului, cheia API și punctul final. Mai jos sunt mai multe detalii pentru a le găsi rapid.
ID model: Conectați-vă la contul Nanonets și navigați la „Modelele mele”. Puteți antrena un model nou sau puteți copia ID-ul aplicației al unui model existent.

Punct final API: Puteți alege orice model existent și faceți clic pe Integrare pentru a găsi punctul final API. Mai jos este un exemplu despre cum arată punctele finale.
https://app.nanonets.com/api/v2/OCR/Model/XXXXXXX-4840-4c27-8940-d3add200779e/LabelUrls/

3. Cheie API: navigați la fila Cheie API și puteți copia orice cheie API existentă sau puteți crea una nouă.

Pasul 5: Adăugați o solicitare HTTP pentru a obține metoda și variabilele dvs. în calea UI
Acum, pentru a vă integra modelul de la Nanonets în calea UI, veți avea primul clic pe Solicitare HTTP și adăugați EndPoint, care poate fi găsit în navigarea din stânga sub secțiunea Intrare. Mai jos este o captură de ecran.

Mai târziu, adăugați toate variabilele pentru a stabili o conexiune de la studioul UiPath la API-ul Nanonets. Puteți găsi această secțiune în panoul de jos, la „Fila Variabile”. Mai jos este captura de ecran, va trebui să actualizați/copiați cheia API, punctul final și ID-ul modelului dvs. aici.

Pasul 6: Adăugați locația fișierului pentru predicții
În cele din urmă, puteți adăuga locația fișierului dvs. în fila Atribute, așa cum se arată în captura de ecran de mai jos, și puteți apăsa butonul de redare din navigația de sus pentru a vă prezice rezultatele.

Voila! Iată rezultatele noastre pentru documentul pe care l-am solicitat în captura de ecran de mai jos. Pentru a procesa mai mult, puteți pur și simplu să adăugați locațiile fișierelor și să apăsați butonul de rulare.

Pasul 7 - Împingeți Ieșirea în CSV / ERP
În cele din urmă, pentru a personaliza rezultatul nostru în formatul dorit, putem adăuga noi blocuri la conducta dvs. în fișierul Main.XML. De asemenea, putem introduce acest lucru în orice sisteme ERP existente prin fișiere offline sau apeluri API.

Pentru orice ajutor, contactați-ne pe support@nanonets.com
Webinar

Alăturați-vă nouă pentru un webinar marțea viitoare pe OCR cu RPA, înregistrează-te aici.
Referinte
[2] Înțelegerea documentelor – Procesarea documentelor AI
[3] RPA OCR – automatizarea proceselor de creștere | GROZAV
[4] Cum să utilizați AI pentru a optimiza înțelegerea documentelor
[5] https://www.uipath.com/product/document-understanding
[6] Utilizarea NanoNets în UiPath Workflow pentru Factura OCR
Lecturi suplimentare
S-ar putea să fiți interesat de ultimele noastre postări pe:
Actualizați:
Added more reading material about the use and impact of OCR, RPA in document understanding.
Sursa: https://nanonets.com/blog/ocr-with-rpa-and-document-understanding-uipath/
- '
- &
- 000
- 2021
- 7
- Cont
- Contabilitate
- Acțiune
- Avantaj
- AI
- Algoritmul
- algoritmi
- TOATE
- analiză
- api
- API-uri
- aplicaţia
- aplicație
- aplicatii
- Artă
- inteligență artificială
- Inteligența artificială (AI)
- Inteligența artificială și învățarea în mașină
- Automatizare
- automatizare oriunde
- CEL MAI BUN
- Cea mai mare
- Blog
- Bot
- roboţii
- construi
- Clădire
- afaceri
- camere video
- cazuri
- Provoca
- cauzată
- recunoașterea personajelor
- clasificare
- Cloud
- Platforma Cloud
- cod
- cognitive
- Colectare
- comentarii
- Comun
- comunitate
- Companii
- component
- Computer Vision
- încredere
- conținut
- Corectarea
- Cheltuieli
- tablou de bord
- de date
- management de date
- afacere
- învățare profundă
- Dezvoltator
- Dezvoltatorii
- Dispozitive
- digital
- documente
- Ocolire
- conducere
- Educaţie
- eficiență
- de angajați
- Punct final
- Afacere
- etc
- extrageți datele
- extracţie
- Caracteristică
- DESCRIERE
- Domenii
- În cele din urmă
- finanţa
- First
- Concentra
- formă
- format
- fraudă
- Gratuit
- viitor
- Gartner
- General
- gif
- bine
- ghida
- Manipularea
- dureri de cap
- aici
- Înalt
- Cum
- Cum Pentru a
- HTTPS
- mare
- Oamenii
- Hibrid
- identifica
- imagine
- Impactul
- Crește
- info
- informații
- extragerea informațiilor
- Inteligență
- scop
- probleme de
- IT
- Cheie
- cunoştinţe
- KYC
- limbă
- Ultimele
- conduce
- conducere
- AFLAȚI
- învățat
- învăţare
- Nivel
- Pârghie
- Licență
- Limitat
- LINK
- local
- locaţie
- masina de învățare
- administrare
- Piață
- piaţă
- Meci
- măsura
- Comerciant
- Metrici
- Microsoft
- ML
- model
- Filme
- Limbajul natural
- Procesarea limbajului natural
- Navigare
- rețele
- neural
- rețele neuronale
- nlp
- notificare
- numere
- OCR
- deschide
- de operare
- sistem de operare
- Operațiuni
- recunoaștere optică a caracterelor
- comandă
- Altele
- Altele
- pașaport
- performanță
- imagine
- platformă
- Popular
- postări
- putere
- Precizie
- Predictii
- Automatizarea procesului
- Programe
- proiect
- calitate
- ridică
- gamă
- RE
- Citind
- reduce
- REZULTATE
- revizuiască
- robot
- Robotic Process Automation
- robotica
- roboţi
- Africa de Sud
- norme
- Alerga
- funcţionare
- sevă
- economisire
- Scară
- scanare
- răzuire
- Ecran
- fără sudură
- Vanzatorii
- serie
- Servicii
- set
- simplu
- So
- Software
- Roboți software
- soluţii
- REZOLVAREA
- petrece
- Începe
- Stat
- Studiu
- a sustine
- sistem
- sisteme
- extragerea mesei
- Tehnologii
- Tehnologia
- Viitorul
- timp
- top
- Pregătire
- ui
- UiPath
- Actualizează
- us
- Statele Unite ale Americii
- utilizare-cazuri
- utilizatorii
- valoare
- Impotriva
- viziune
- web
- webinar
- site-uri web
- OMS
- ferestre
- în
- Apartamente
- flux de lucru
- fabrică
- XML
- an
- youtube