Introducere
Cele mai mici pătrate obișnuite este o tehnică de optimizare. OLS este aceeași tehnică care este folosită de clasa scikit-learn LinearRegression și de funcția numpy.polyfit() din culise. Înainte de a trece la detaliile tehnicii OLS, ar merita să parcurgem articolul pe care l-am scris rolul tehnicilor de optimizare în învățarea automată și învățarea profundă. În același articol, am explicat pe scurt motivul și contextul existenței tehnicii OLS (Secțiunea 6). Acest articol este în continuare în continuarea aceluiași articol, iar cititorii sunt de așteptat să fie familiarizați cu același articol.

Sursa: Pixbay
Obiective de invatare:
În acest articol, veți
- Aflați ce este MOL și înțelegeți ecuația sa matematică
- Obțineți o privire de ansamblu asupra OLS sub formă de scaler și dezavantajele sale
- Înțelegeți OLS folosind un exemplu în timp real
Cuprins
- Care sunt problemele de optimizare?
- De ce avem nevoie de OLS?
- Înțelegerea matematicii din spatele algoritmului OLS
- Soluție OLS în formă Scaler
- OLS în acțiune folosind un exemplu real
- Probleme cu forma Scaler a soluției OLS
- Concluzie
Care sunt problemele de optimizare?
Problemele de optimizare sunt probleme matematice care presupun găsirea celei mai bune soluții dintr-un set de soluții posibile. Aceste probleme sunt de obicei formulate ca probleme de maximizare sau minimizare, unde scopul este fie de a maximiza, fie de a minimiza o anumită funcție obiectivă. Funcția obiectiv este o expresie matematică care descrie cantitatea de optimizat, iar un set de constrângeri definește setul de soluții posibile.
Problemele de optimizare apar în diverse domenii, inclusiv inginerie, finanțe, economie și cercetare operațională. Acestea sunt folosite pentru a modela și rezolva probleme precum alocarea resurselor, programarea și optimizarea portofoliului. Optimizarea este o componentă crucială a multor algoritmi de învățare automată. În învățarea automată, optimizarea este utilizată pentru a găsi cel mai bun set de parametri pentru un model care minimizează diferența dintre predicțiile modelului și valorile adevărate. Optimizarea este un domeniu activ de cercetare în domeniul învățării automate, noi algoritmi de optimizare fiind dezvoltați pentru a îmbunătăți viteza și acuratețea modelelor de învățare automată.
Câteva exemple de unde este utilizată optimizarea în învățarea automată includ:
- În învăţarea supravegheată, optimizarea este utilizată pentru a găsi parametrii unui model care minimizează diferența dintre predicțiile modelului și valorile adevărate pentru un set de date de antrenament dat. De exemplu, regresia liniară și regresia logistică folosesc optimizarea pentru a găsi cele mai bune valori ale coeficienților modelului. În plus, unele modele precum arbori de decizie, păduri aleatorii și modele de creștere a gradientului sunt construite prin adăugarea iterativă de noi modele la ansamblu și optimizează parametrii noilor modele care minimizează eroarea datelor de antrenament.
- În învățarea nesupravegheată, optimizarea ajută la găsirea celei mai bune configurații de clustere sau maparea datelor care reprezintă cel mai bine structura de bază a datelor. În clustering, optimizarea este utilizată pentru a găsi cea mai bună configurație a clusterelor din date. De exemplu, algoritmul K-Means folosește o tehnică de optimizare numită algoritmul Lloyd, care reatribuie iterativ punctele de date la cel mai apropiat centroid al clusterului și actualizează centroizii clusterului pe baza punctelor nou alocate. În mod similar, alți algoritmi de clustering, cum ar fi clusteringul ierarhic, clustering-ul bazat pe densitate și modelele de amestec Gaussian folosesc, de asemenea, tehnici de optimizare pentru a găsi cea mai bună soluție de clustering. În reducerea dimensionalității, optimizarea găsește cea mai bună mapare a datelor dintr-un spațiu de dimensiuni înalte la unul de dimensiuni inferioare. De exemplu, Analiza componentelor principale (PCA) folosește descompunerea valorii singulare (SVD), o tehnică de optimizare, pentru a găsi cea mai bună combinație liniară a variabilelor originale care explică cea mai mare variație a datelor. În plus, alte tehnici de reducere a dimensionalității, cum ar fi Analiza discriminantă liniară (LDA) și încorporarea învecinată stocastică t-distribuită (t-SNE) folosesc, de asemenea, tehnici de optimizare pentru a găsi cea mai bună reprezentare a datelor într-un spațiu de dimensiuni inferioare.
- În învățarea profundă, optimizarea este utilizată pentru a găsi cel mai bun set de parametri pentru rețelele neuronale, care se face de obicei folosind algoritmi de optimizare bazați pe gradient, cum ar fi coborârea gradientului stocastic (SGD) sau Adam/Adagrad/RMSProp etc.
De ce avem nevoie de OLS?
cele mai mici pătrate obișnuite Algoritmul (OLS) este o metodă de estimare a parametrilor unui model de regresie liniară. Algoritmul MOL își propune să găsească valorile parametrilor modelului de regresie liniară (adică, coeficienții) care minimizează suma reziduurilor pătrate. Reziduurile sunt diferențele dintre valorile observate ale variabilei dependente și valorile prezise ale variabilei dependente date fiind variabilele independente. Este important de remarcat că algoritmul OLS presupune că erorile sunt distribuite în mod normal cu medie zero și varianță constantă și că nu există multicoliniaritate (corelație mare) între variabilele independente. Alte metode, cum ar fi cele mai mici pătrate generalizate sau cele mai mici pătrate ponderate, ar trebui utilizate în cazurile în care aceste ipoteze nu sunt îndeplinite.
Înțelegerea matematicii din spatele algoritmului OLS
Pentru a explica algoritmul OLS, permiteți-mi să iau cel mai simplu exemplu posibil. Luați în considerare următoarele 3 puncte de date:
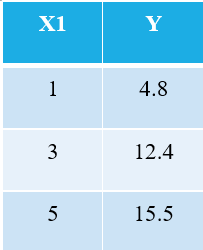
Toți cei familiarizați cu învățarea automată vor recunoaște imediat că ne referim la X1 ca variabilă independentă (numită și „DESCRIERE”Sau „Atribute”), iar Y este variabila dependentă (numită și ca "Ţintă" or "Rezultat"). Prin urmare, sarcina generală a oricărei mașini este să găsească relația dintre X1 și Y. Această relație este de fapt "învățat" de către mașina din DATE. Prin urmare, numim termenul Machine Learning. Noi, oamenii, învățăm din experiențele noastre. În mod similar, aceeași experiență este introdusă în mașină ca date.
Acum, să presupunem că vrem să găsim linia cea mai potrivită prin cele 3 puncte de date de mai sus. Următorul diagramă arată aceste 3 puncte de date în cercuri albastre. De asemenea, este afișată linia roșie (cu pătrate), pe care o pretindem drept „linia cea mai potrivită” prin aceste 3 puncte de date. De asemenea, am arătat o linie „potrivită” (linia galbenă) pentru comparație.
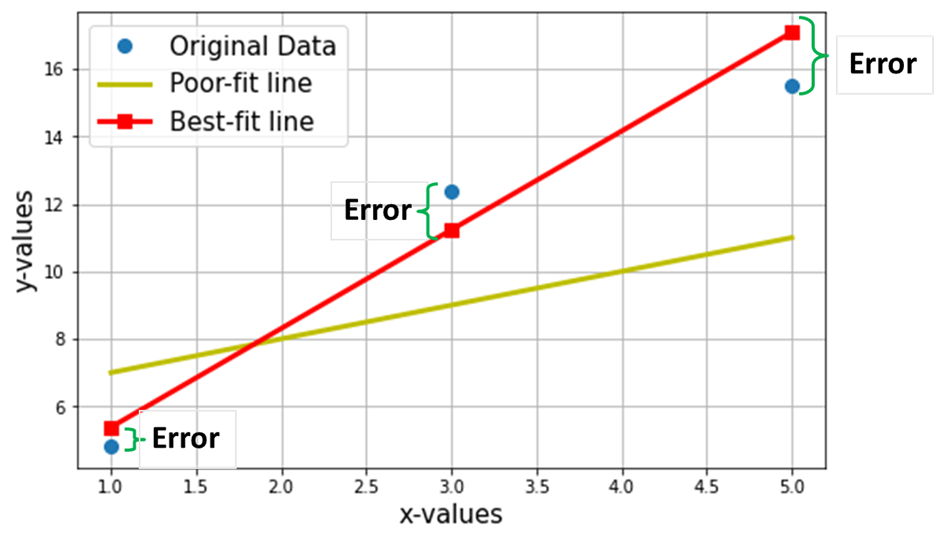
Obiectivul net este de a găsi ecuația lui Cea mai potrivită linie dreaptă (prin aceste 3 puncte de date menționate în tabelul de mai sus).

Este ecuația liniei celei mai potrivite (linia roșie în graficul de mai sus), unde w1 = panta dreptei; w0 = interceptarea liniei.
În învățarea automată, această potrivire cea mai bună se numește Liniar Regres (LR), și w0 și w1 sunt, de asemenea, numite greutățile modelului sau coeficienții modelului.
Pătratele roșii din graficul de mai sus reprezintă valorile prezise din modelul de regresie liniară (Y^). Desigur, valorile prezise NU sunt aceleași cu valorile reale ale lui Y (cercuri albastre). Diferența verticală reprezintă eroarea în predicție dată de (vezi imaginea de mai jos) pentru orice i-lea punct de date.
![]()
Acum susțin că această linie de cea mai bună potrivire va avea eroarea minimă pentru predicție (dintre toate liniile aleatoare infinite „poor-fit” posibile). Această eroare totală în toate punctele de date este exprimată ca Funcția de eroare medie pătratică (MSE)., care va fi minim pentru linia cea mai potrivită.
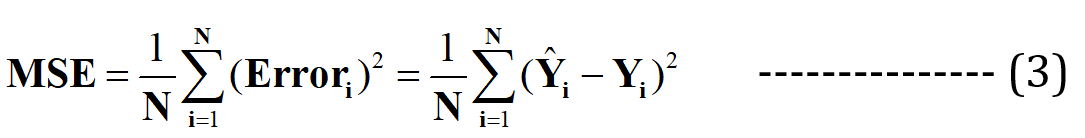
N = Nr. total. de puncte de date din setul de date (în cazul actual, este 3)
Minimizarea sau maximizarea oricărei cantități este denumită matematic a Problema de optimizare, și, prin urmare, soluția (punctul în care există minimum/maxim) se referă la valorile optime ale variabilelor.

linear Regression este un exemplu de optimizare neconstrânsă, dat de:
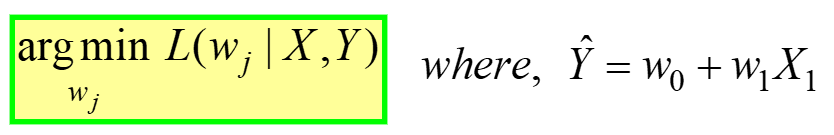 ---- (4)
---- (4)
Acesta este citit ca „Găsiți greutăți optime (wj) pentru care MSE Funcția de pierdere (dată în ecuația 3 de mai sus) are valoarea minima, pentru o DATE X, Y dateMatei 22:21 (consultați primul tabel de la începutul articolului). L(wj) reprezintă Pierderea MSE, o funcție a greutăților modelului, nu X sau Y. Amintiți-vă, X & Y sunt DATELE dvs. și ar trebui să fie CONSTANTE! Indicele „j” reprezintă al j-lea coeficient/greutate al modelului.
La înlocuirea cu Y^ = w0 +w1X1 in eq. 3 de mai sus, finala Funcția de pierdere MSE (L) arata ca:
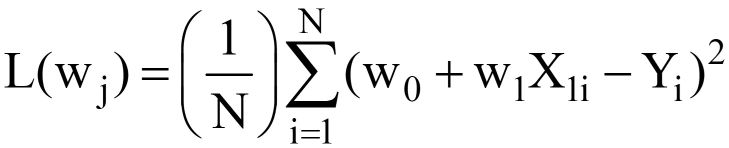 ---- (5)
---- (5)
În mod clar, L este o funcție a greutăților modelului (w0 & w1), ale căror valori optime trebuie să le găsim la minimizarea L. Valorile optime sunt reprezentate prin (*) în figura de mai jos.
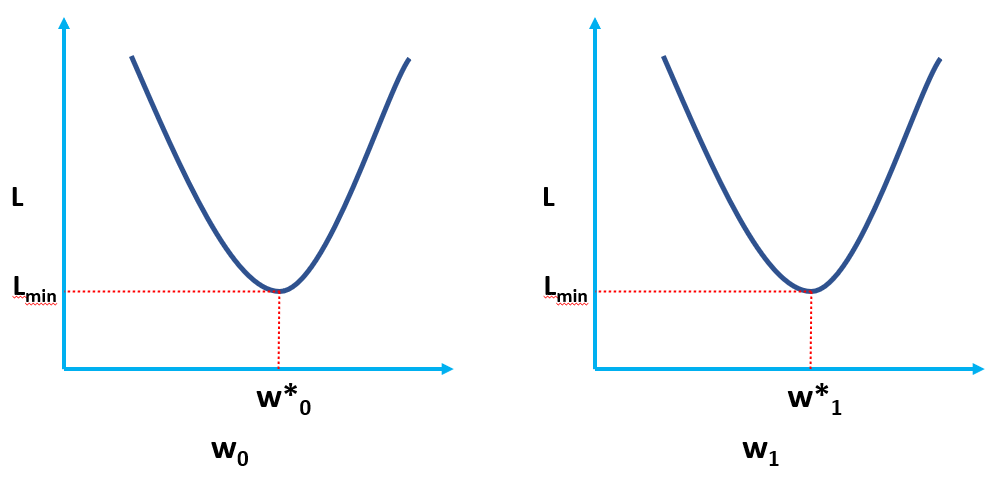
Soluție OLS sub formă de scalator
Echivalentul 5 de mai sus reprezintă funcția OLS Loss în forma scaler (unde putem vedea însumarea erorilor pentru fiecare punct de date. Algoritmul OLS este o soluție analitică la problema de optimizare prezentată în ec. 4. Această soluție analitică constă din următorii pași:
Pasul 1:

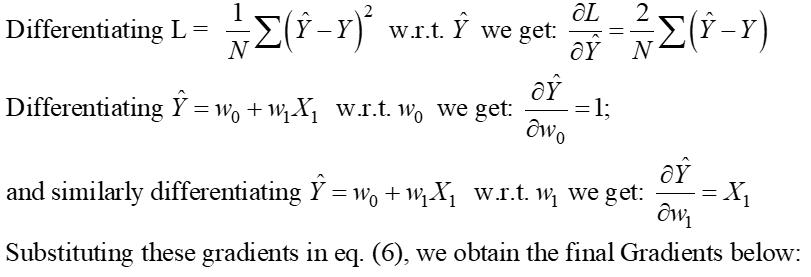

Pasul 2: Echivalați acești gradienți cu zero și rezolvați pentru valorile optime ale coeficienților modelului wj.
Aceasta înseamnă practic că panta tangentei (interpretarea geometrică a gradienților) la funcția Pierdere la valorile optime (punctul în care L este minim) va fi zero, așa cum se arată în figurile de mai sus.

Din ecuațiile de mai sus, putem muta „2” de la LHS la RHS; RHS rămâne ca 0 (deoarece 0/2 este încă 0).


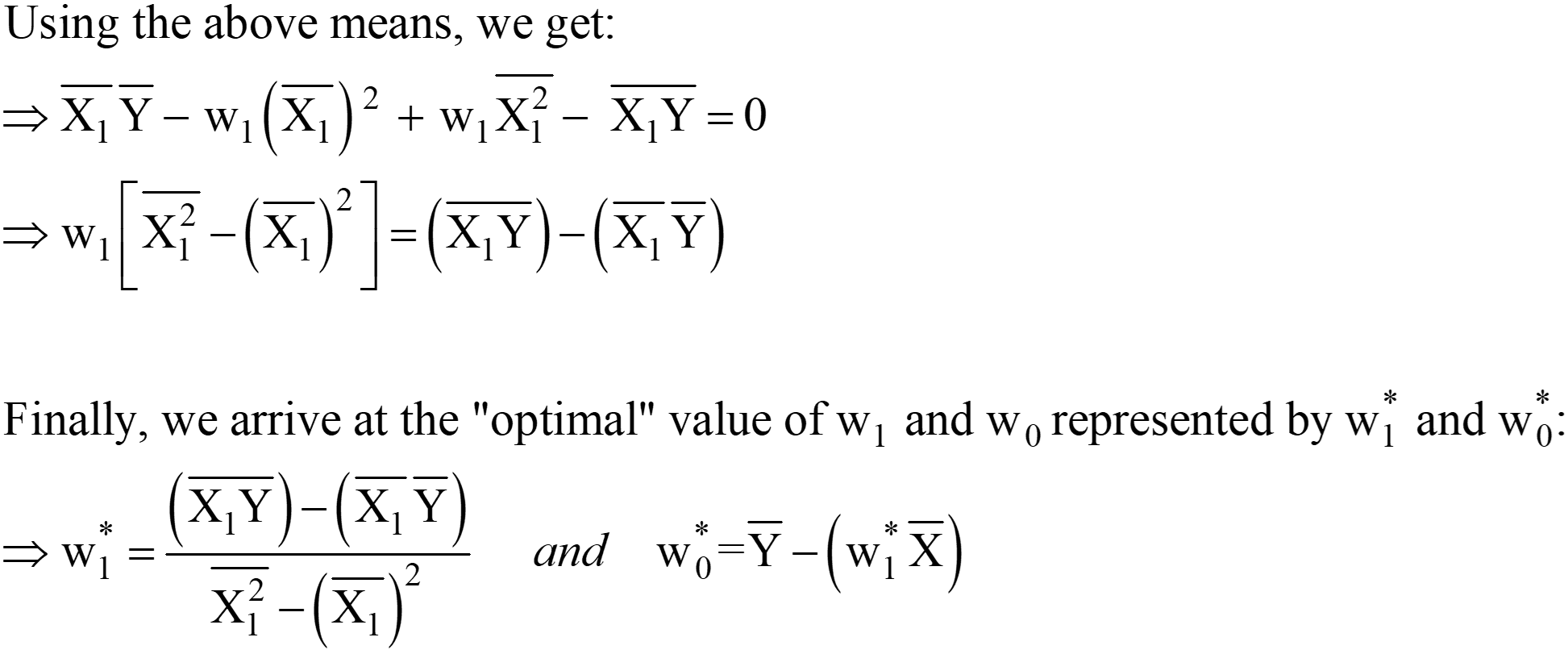
Aceste expresii pentru w1* și w0* sunt soluția finală OLS analitică în forma Scaler.
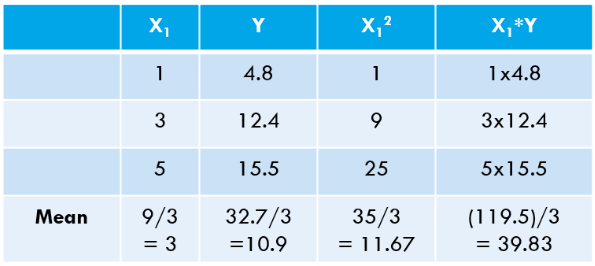
Pasul 3: Calculați mediile de mai sus și înlocuiți în expresia w1* și w0*.
Să calculăm aceste valori pentru setul nostru de date:
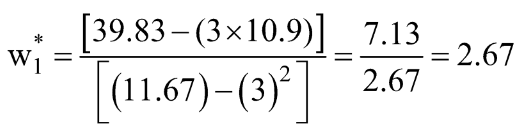
![]()
Să calculăm același lucru folosind codul Python:
[IEȘIRE]: Aceasta este ecuația liniei „Cel mai potrivită”: 2.675 x + 2.875
Puteți vedea valorile noastre „calculate manual” se potrivesc foarte strâns cu valorile pantei și interceptării obținute folosind NumPy (diferența mică se datorează erorilor de rotunjire din calculele noastre manuale). De asemenea, putem verifica că același OLS „rulează în spatele scenei” clasei LinearRegression din scikit-learn pachet, așa cum este demonstrat în codul de mai jos.
# importați clasa LinearRegression din pachetul scikit-learn din sklearn.linear_model import LinearRegression LR = LinearRegression() # creați o instanță a clasei LinearRegression # definiți-vă X și Y ca NumPy Arrays (vectori coloană) X = np.array([1,3,5) ,1,1]).reshape(-4.8,12.4,15.5) Y = np.array([1,1]).reshape(-0) LR.fit(X,Y) # calculați coeficienții modelului LR .intercepta_ # părtinirea sau termenul de interceptare (wXNUMX*)
[Ieșire]: matrice([2.875])
LR.coef_ # termenul pantei (w1*) [Ieșire]: matrice ([[2.675]])
OLS în acțiune folosind un exemplu real
Aici folosesc setul de date Boston House Pricing, unul dintre cele mai frecvent întâlnite seturi de date în timp ce învăț Data Science. Obiectivul este de a realiza o Model de regresie liniară pentru a prezice valoarea medie a prețurilor casei pe baza a 13 caracteristici/atribute menționate mai jos.
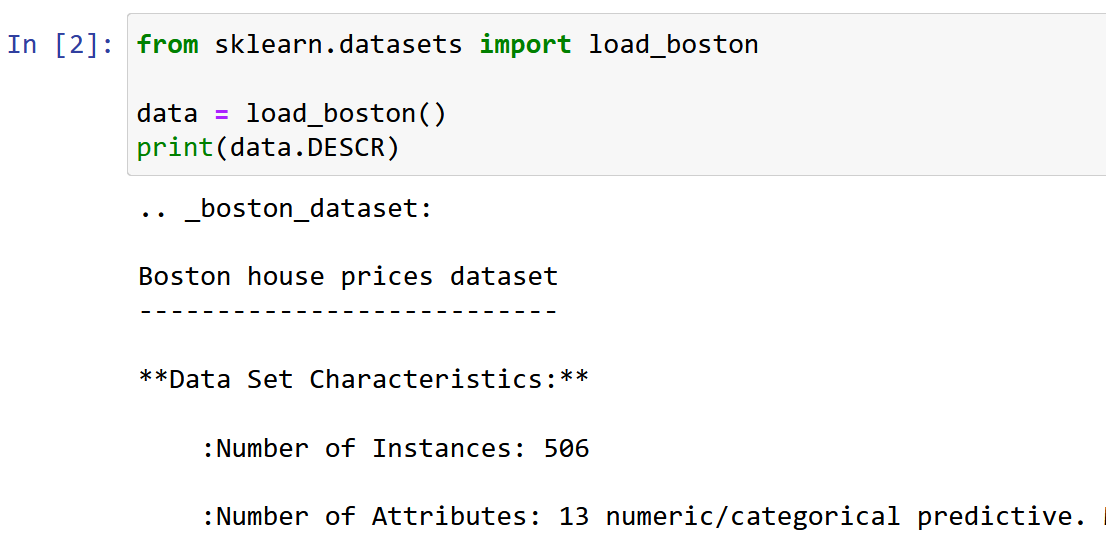
Importați și explorați setul de date.
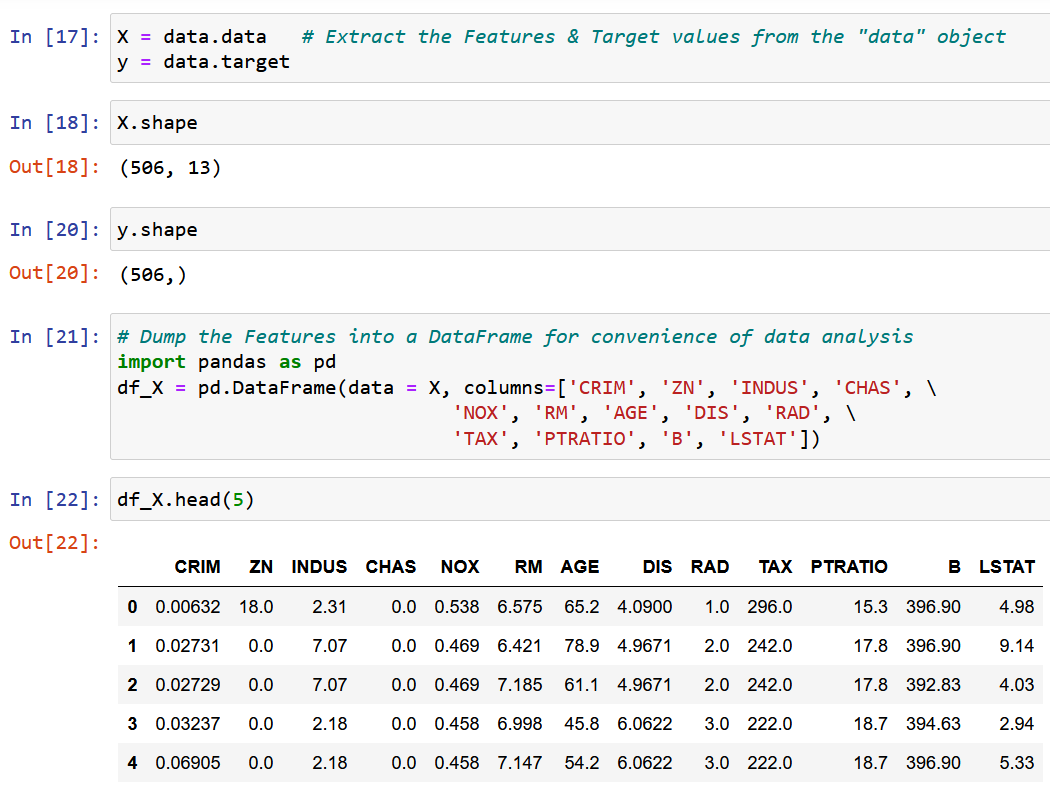
Vom extrage o singură caracteristică RM, dimensiunea medie a camerei în localitatea dată și o vom potrivi cu variabila țintă y (valoarea mediană a prețului casei).
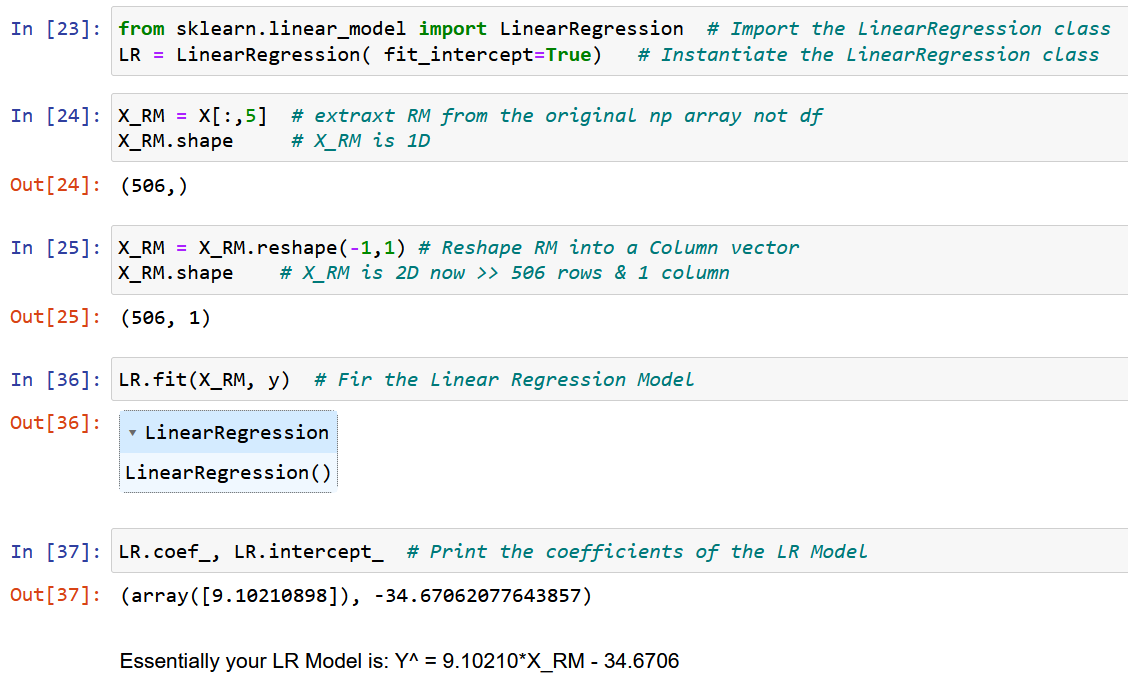
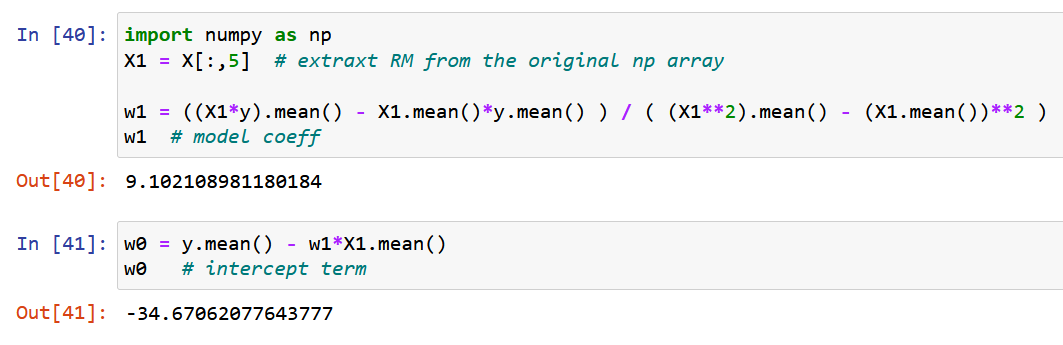
Acum, să folosim NumPy pur și să calculăm coeficienții modelului folosind expresiile derivate pentru valorile optime ale coeficienților modelului w0 și w1 de mai sus (sfârșitul pasului 2).
Să reprezentăm în cele din urmă datele originale împreună cu linia cea mai potrivită, așa cum este prezentat mai jos.
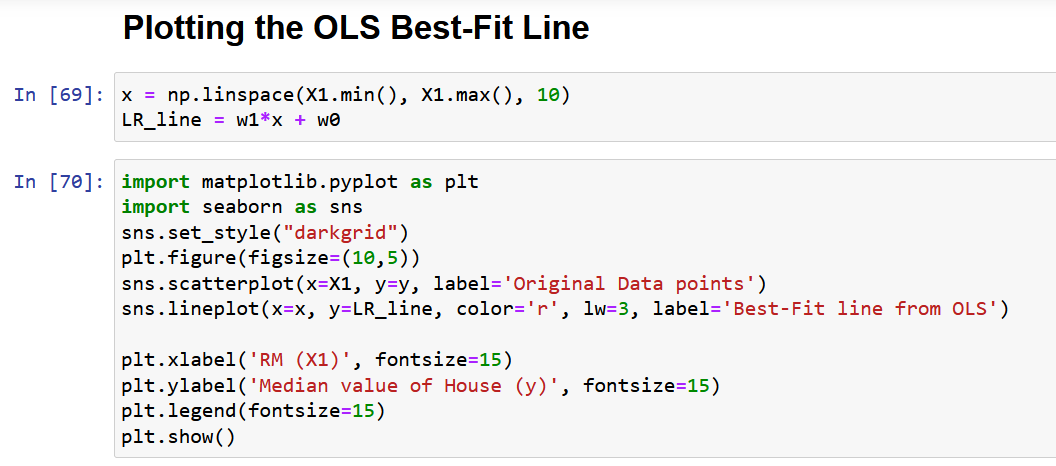

Probleme cu Formularul Scaler a Soluției OLS
În cele din urmă, permiteți-mi să discut principala problemă cu abordarea de mai sus, așa cum este descrisă în secțiunea 4. După cum puteți vedea din setul de date menționat mai sus, orice set de date din viața reală va avea mai multe caracteristici. Motivul principal pentru care am luat o singură caracteristică pentru demonstrarea metodei OLS în secțiunea de mai sus a fost că, pe măsură ce numărul de caracteristici crește, numărul de gradienți ar crește, deci și numărul de ecuații care trebuie rezolvate simultan!
Pentru a fi exact, pentru 13 caracteristici (setul de date Boston de mai sus), vom avea 13 coeficienți de model și un termen de interceptare, ceea ce aduce numărul total de variabile de optimizat la 14. Prin urmare, vom obține 14 gradienți (derivata parțială). a funcţiei de pierdere faţă de fiecare dintre aceste 14 variabile). În consecință, trebuie să rezolvăm 14 ecuații (după echivalarea acestor 14 derivate parțiale la zero, așa cum este descris în pasul 2). Ați realizat deja complexitatea soluției analitice cu doar 2 variabile. Sincer, am încercat să vă ofer cea mai elaborată explicație a MOL disponibilă pe internet și, totuși, nu este ușor să asimilați matematica.
Prin urmare, în cuvinte simple, soluția analitică de mai sus NU ESTE SCALABILĂ!
Soluția la această problemă este „Forma vectorizată a soluției OLS”, care va fi discutată în detaliu într-un articol de continuare (Partea 2 a acestui articol), cu secțiunile 7 și 8.
Concluzie
În concluzie, metoda MOL este un instrument puternic pentru estimarea parametrilor unui model de regresie liniară. Se bazează pe principiul minimizării sumei diferențelor pătrate dintre valorile prezise și cele reale.
Unele dintre concluziile cheie din articol sunt următoarele:
- Soluția OLS poate fi reprezentată sub formă de scaler, făcând-o ușor de implementat și interpretat.
- Articolul a discutat despre conceptul de probleme de optimizare și necesitatea MOL în analiza regresiei și a oferit o formulare matematică și un exemplu de MCO în acțiune.
- Articolul evidențiază, de asemenea, unele dintre limitările formei de scalare a soluției OLS, cum ar fi scalabilitatea și ipotezele de liniaritate și variație constantă. Sper să înveți ceva nou din acest articol.
Vă rog să-mi trimiteți un comentariu dacă simțiți că orice punct/ecuație din acest articol are nevoie de explicații sau dacă doriți să scriu despre orice alt algoritm de învățare automată atât de detaliat.
Legate de
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- Platoblockchain. Web3 Metaverse Intelligence. Cunoștințe amplificate. Accesați Aici.
- Sursa: https://www.analyticsvidhya.com/blog/2023/01/a-comprehensive-guide-to-ols-regression-part-1/
- 1
- 10
- 214
- 7
- a
- Despre Noi
- mai sus
- Absolut
- precizie
- peste
- Acțiune
- activ
- de fapt
- plus
- În plus,
- După
- isi propune
- Algoritmul
- algoritmi
- TOATE
- alocare
- deja
- printre
- analiză
- Analitic
- și
- abordare
- ZONĂ
- articol
- alocate
- disponibil
- in medie
- bazat
- Pe scurt
- înainte
- în spatele
- în spatele scenelor
- fiind
- de mai jos
- CEL MAI BUN
- între
- părtinire
- Albastru
- stimularea
- boston
- scurt
- Aduce
- construit
- apel
- denumit
- caz
- cazuri
- Centru
- sigur
- cerc
- pretinde
- clasă
- îndeaproape
- Grup
- clustering
- cod
- Coloană
- combinaţie
- comentariu
- în mod obișnuit
- comparație
- complexitate
- component
- cuprinzător
- Calcula
- concept
- concluzie
- Configuraţie
- prin urmare
- Lua în considerare
- constant
- constrângeri
- context
- continuare
- Corelație
- înscrie-te la cursul
- crea
- crucial
- Curent
- Întuneric
- de date
- puncte de date
- știința datelor
- seturi de date
- decizie
- adânc
- defineste
- demonstrat
- demonstrând
- Dependent/ă
- Instrumentele financiare derivate
- Derivat
- descris
- detaliu
- detalii
- dezvoltat
- diferenţă
- diferenţele
- discuta
- discutat
- distribuite
- Picătură
- fiecare
- Economie
- oricare
- Elaborat
- Inginerie
- ecuații
- eroare
- Erori
- etc
- Eter (ETH)
- exemplu
- exemple
- există
- de aşteptat
- experienţă
- Experiențe
- Explica
- a explicat
- explică
- explicație
- explora
- și-a exprimat
- expresii
- extrage
- familiar
- Caracteristică
- DESCRIERE
- fed-
- Domenii
- Figura
- cifre
- final
- În cele din urmă
- finanţa
- Găsi
- descoperire
- descoperiri
- First
- potrivi
- următor
- urmează
- formă
- din
- funcţie
- Da
- dat
- scop
- merge
- gradienți
- grup
- ghida
- ajută
- Înalt
- highlights-uri
- speranţă
- casă
- HTTPS
- Oamenii
- imagine
- imediat
- punerea în aplicare a
- import
- important
- îmbunătăţi
- in
- include
- Inclusiv
- Crește
- independent
- instanță
- Internet
- interpretare
- implica
- IT
- Cheie
- AFLAȚI
- învăţare
- LG
- limitări
- Linie
- linii
- Se pare
- de pe
- maşină
- masina de învățare
- Principal
- face
- Efectuarea
- multe
- cartografiere
- Meci
- matematic
- matematic
- matematică
- max-width
- Maximaliza
- mijloace
- menționat
- metodă
- Metode
- minimizarea
- minimizând
- minim
- amestec
- model
- Modele
- cele mai multe
- multiplu
- Nevoie
- nevoilor
- net
- rețele
- neural
- rețele neuronale
- Nou
- în mod normal
- număr
- NumPy
- obiectiv
- Obiectivele
- obținut
- ONE
- Operațiuni
- optimă
- optimizare
- Optimizați
- optimizate
- original
- Altele
- global
- Prezentare generală
- pachet
- parametrii
- parte
- Plato
- Informații despre date Platon
- PlatoData
- Punct
- puncte
- portofoliu
- posibil
- puternic
- prezice
- a prezis
- prezicere
- Predictii
- prezentat
- preţ
- Prețuri
- de stabilire a prețurilor
- Principal
- principiu
- Problemă
- probleme
- prevăzut
- Piton
- cantitate
- aleator
- Citeste
- cititori
- în timp real
- realizat
- motiv
- recunoaște
- Roșu
- menționat
- se referă
- regres
- relaţie
- rămășițe
- minte
- reprezenta
- reprezentare
- reprezentate
- reprezintă
- cercetare
- resursă
- Rol
- Cameră
- acelaşi
- scalabilitate
- scene
- Ştiinţă
- scikit-learn
- Secțiune
- secțiuni
- set
- SGD
- schimbare
- să
- indicat
- Emisiuni
- asemănător
- simplu
- singur
- singular
- Mărimea
- Pantă
- mic
- soluţie
- soluţii
- REZOLVAREA
- unele
- ceva
- Spaţiu
- viteză
- Squared
- pătrate
- Începe
- Pas
- paşi
- Încă
- drept
- structura
- astfel de
- a presupus
- tabel
- Lua
- Takeaways
- Ţintă
- Sarcină
- tehnici de
- Prin
- la
- instrument
- Total
- Pregătire
- Copaci
- adevărat
- tipic
- care stau la baza
- înţelege
- actualizări
- us
- utilizare
- valoare
- Valori
- diverse
- verifica
- vizibil
- Ce
- care
- în timp ce
- voi
- cuvinte
- merită
- ar
- scrie
- scris
- X
- Ta
- zephyrnet
- zero