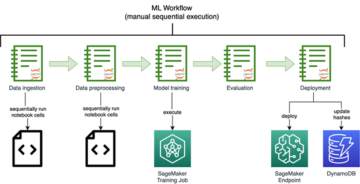
Pilot automat cu Amazon SageMaker vă ajută să finalizați un flux de lucru de învățare automată (ML) end-to-end prin automatizarea pașilor de inginerie a caracteristicilor, instruire, reglare și implementare a unui model ML pentru inferență. Oferiți lui SageMaker Autopilot un set de date tabelar și un atribut țintă de estimat. Apoi, SageMaker Autopilot explorează automat datele dvs., antrenează, acordă, clasifică și găsește cel mai bun model. În cele din urmă, puteți implementa acest model în producție pentru deducere cu un singur clic.
Ce mai e nou?
Funcția recent lansată, Rapoarte de calitate a modelului SageMaker Autopilot, raportează acum valorile modelului dvs. pentru a oferi o vizibilitate mai bună asupra performanței modelului dvs. pentru probleme de regresie și clasificare. Puteți folosi aceste valori pentru a aduna mai multe informații despre cel mai bun model din clasamentul modelului.
Aceste metrici și rapoarte care sunt disponibile într-o nouă filă „Performanță” sub „Detalii model” a celui mai bun model includ matrice de confuzie, o zonă sub curba caracteristicii de funcționare a receptorului (AUC-ROC) și o zonă sub curba de precizie-rechemare. (AUC-PR). Aceste valori vă ajută să înțelegeți false pozitive/false negative (FP/FN), compromisuri între adevăratele pozitive (TP) și false pozitive (FP), precum și compromisurile dintre precizie și reamintire pentru a evalua cele mai bune caracteristici de performanță a modelului.
Rularea experimentului SageMaker Autopilot
Setul de date
Noi folosim Setul de date de marketing bancar al UCI pentru a demonstra rapoartele de calitate a modelului SageMaker Autopilot. Aceste date conțin atribute ale clientului, cum ar fi vârsta, tipul locului de muncă, starea civilă și altele pe care le vom folosi pentru a estima dacă clientul va deschide un cont la bancă. Setul de date se referă la acest cont ca depozit la termen. Acest lucru face cazul nostru o problemă de clasificare binară - predicția va fi fie „da” fie „nu”. SageMaker Autopilot va genera mai multe modele în numele nostru pentru a anticipa cel mai bine clienții potențiali. Apoi, vom examina raportul de calitate a modelului pentru pilotul automat SageMaker cel mai bun model.
Cerințe preliminare
Pentru a iniția un experiment SageMaker Autopilot, trebuie mai întâi să vă plasați datele într-un Serviciul Amazon de stocare simplă (Amazon S3) găleată. Specificați găleata și prefixul pe care doriți să le utilizați pentru antrenament. Asigurați-vă că găleata se află în aceeași regiune cu experimentul SageMaker Autopilot. De asemenea, trebuie să vă asigurați că rolul Identity and Access Management (IAM) Autopilot are permisiuni pentru a accesa datele în Amazon S3.
Crearea experimentului
Aveți mai multe opțiuni pentru a crea un experiment SageMaker Autopilot în SageMaker Studio. Prin deschiderea unui nou lansator, este posibil să puteți accesa direct SageMaker Autopilot. Dacă nu, atunci puteți selecta pictograma de resurse SageMaker din partea stângă. În continuare, puteți selecta Experimente și încercări din meniul drop-down.
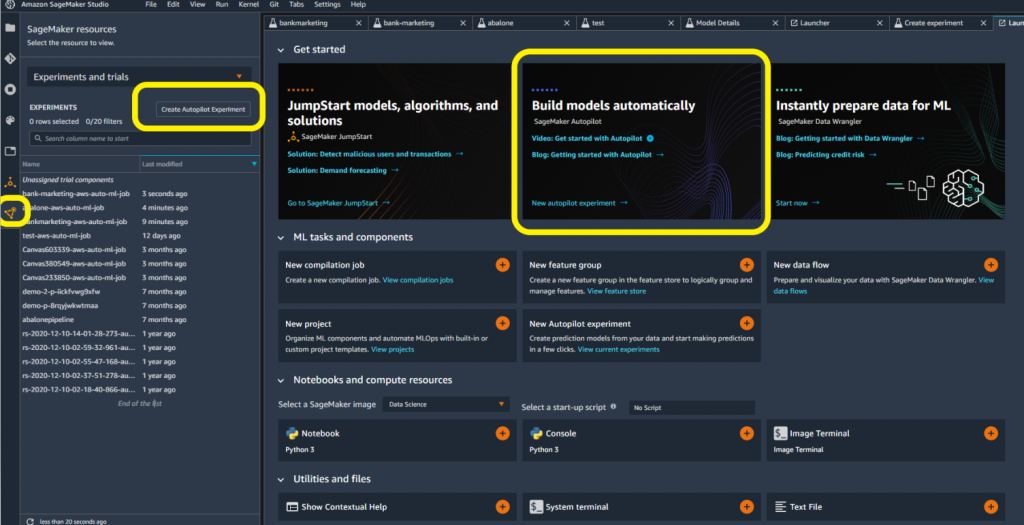
- Dați un nume experimentului dvs.
- Conectați-vă la sursa de date selectând compartimentul Amazon S3 și numele fișierului.
- Alegeți locația datelor de ieșire în Amazon S3.
- Selectați coloana țintă pentru setul dvs. de date. În acest caz, vizam coloana „y” pentru a indica da/nu.
- Opțional, furnizați un nume de punct final dacă doriți ca SageMaker Autopilot să implementeze automat un punct final model.
- Lăsați toate celelalte setări avansate ca implicite și selectați Creați experiment.

După finalizarea experimentului, puteți vedea rezultatele în SageMaker Studio. SageMaker Autopilot va prezenta cel mai bun model dintre diferitele modele pe care le antrenează. Puteți vizualiza detalii și rezultate pentru diferite încercări, dar vom folosi cel mai bun model pentru a demonstra utilizarea Rapoartelor de calitate a modelului.
- Selectați modelul și faceți clic dreapta pentru Deschideți în detaliile modelului.
- În detaliile modelului, selectați Performanţă fila. Aceasta arată valorile modelului prin vizualizări și diagrame.
- În Performanţă, Selectați Descărcați rapoarte de performanță ca PDF.


Interpretarea raportului de calitate al modelului SageMaker Autopilot
Raportul de calitate a modelului rezumă jobul SageMaker Autopilot și detaliile modelului. Ne vom concentra pe formatul PDF al raportului, dar puteți accesa rezultatele și ca JSON. Deoarece SageMaker Autopilot a determinat setul nostru de date ca o problemă de clasificare binară, SageMaker Autopilot și-a propus să maximizeze Valoarea calității F1 pentru a găsi cel mai bun model. SageMaker Autopilot alege acest lucru în mod implicit. Cu toate acestea, există flexibilitate pentru a alege alte valori obiective, cum ar fi acuratețea și AUC. Scorul F1 al modelului nostru este 0.61. Pentru a interpreta un scor F1, vă ajută să înțelegeți mai întâi o matrice de confuzie, care este explicată de Raportul de calitate a modelului din PDF-ul rezultat.
Matricea confuziei
O matrice de confuzie ajută la vizualizarea performanței modelului prin compararea diferitelor clase și etichete. Experimentul SageMaker Autopilot a creat o matrice de confuzie care arată etichetele reale ca rânduri și etichetele predicate ca coloane în Raportul de calitate a modelului. Caseta din stânga sus arată clienții care nu au deschis un cont la bancă, care au fost prezis corect ca „nu” de către model. Acestea sunt negative adevărate (TN). Caseta din dreapta jos arată clienții care au deschis un cont la bancă, care au fost prezis corect ca „da” de către model. Acestea sunt adevărate pozitive (PT).

Colțul din stânga jos arată numărul de false negative (FN). Modelul a prezis că clientul nu va deschide un cont, dar clientul a făcut-o. Colțul din dreapta sus arată numărul de fals pozitive (FP). Modelul a prezis că clientul va deschide un cont, dar clientul a făcut-o nu chiar asa fac.
Valori ale raportului de calitate al modelului
Raportul de calitate al modelului explică cum se calculează rata fals pozitive (FPR) si rata pozitivă adevărată (TPR).
Rata de reamintire sau fals pozitiv (FPR) măsoară proporția de negative reale care au fost prezise în mod fals ca deschiderea unui cont (pozitive). Intervalul este de la 0 la 1, iar o valoare mai mică indică o precizie predictivă mai bună.

Rețineți că FPR este, de asemenea, exprimat ca 1-Specificitate, unde Specificitatea sau Rata negativă adevărată (TNR) este proporția de TN identificate corect ca nedeschizând un cont (negative).

Rechemare/Sensibilitate/Rata pozitivă adevărată (TPR) măsoară fracția de pozitive reale care au fost prezise ca deschiderea unui cont. Intervalul este, de asemenea, de la 0 la 1, iar o valoare mai mare indică o precizie predictivă mai bună. Acest lucru este cunoscut și sub numele de Recall/Sensitivity. Această măsură exprimă capacitatea de a găsi toate instanțele relevante dintr-un set de date.
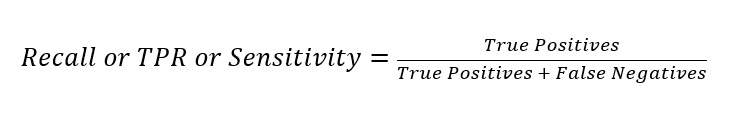
Precizie măsoară fracția de pozitive reale care au fost prezise ca pozitive din toate cele prezise ca pozitive. Intervalul este de la 0 la 1, iar o valoare mai mare indică o precizie mai bună. Precizia exprimă proporția de puncte de date despre care modelul nostru spune că sunt relevante și care au fost de fapt relevante. Precizia este o măsură bună de luat în considerare, mai ales atunci când costurile FP sunt mari – de exemplu, cu detectarea spam-ului prin e-mail.

Modelul nostru prezintă o precizie de 0.53 și o rechemare de 0.72.
Scorul F1 demonstrează metrica noastră țintă, care este media armonică a preciziei și a reamintirii. Deoarece setul nostru de date este dezechilibrat în favoarea multor predicții „nu”, F1 ia în considerare atât FP, cât și FN pentru a acorda aceeași pondere preciziei și reamintirii.
Raportul explică modul de interpretare a acestor valori. Acest lucru vă poate ajuta dacă nu sunteți familiarizat cu acești termeni. În exemplul nostru, precizia și amintirea sunt valori importante pentru o problemă de clasificare binară, deoarece sunt folosite pentru a calcula scorul F1. Raportul explică că un scor F1 poate varia între 0 și 1. Cea mai bună performanță posibilă va nota 1, în timp ce 0 va indica cel mai rău. Amintiți-vă că scorul F1 al modelului nostru este 0.61.

Scorul Fβ este media armonică ponderată a preciziei și a reamintirii. În plus, scorul F1 este același cu Fβ cu β=1. Raportul oferă scorul Fβ al clasificatorului, unde β ia 0.5, 1 și 2.

Tabelul de valori
În funcție de problemă, este posibil să descoperiți că SageMaker Autopilot maximizează o altă măsurătoare, cum ar fi acuratețea, pentru o problemă de clasificare cu mai multe clase. Indiferent de tipul de problemă, Rapoartele de calitate a modelului produc un tabel care rezumă valorile modelului dvs. disponibile atât în linie, cât și în raportul PDF. Puteți afla mai multe despre tabelul metric în documentaţie.

Cel mai bun clasificator constant – un clasificator care servește ca o linie de bază simplă pentru a compara cu alți clasificatori mai complexi – prezice întotdeauna o etichetă majoritară constantă furnizată de utilizator. În cazul nostru, un model „constant” ar prezice „nu”, deoarece aceasta este clasa cea mai frecventă și considerată a fi o etichetă negativă. Valorile pentru modelele de clasificatoare antrenate (cum ar fi f1, f2 sau recall) pot fi comparate cu cele pentru clasificatorul constant, adică, linia de bază. Acest lucru asigură că modelul antrenat are performanțe mai bune decât clasificatorul constant. Scorurile Fβ (f0_5, f1 și f2, unde β ia valorile de 0.5, 1 și, respectiv, 2) sunt media armonică ponderată a preciziei și a reamintirii. Aceasta atinge valoarea optimă la 1 și cea mai proastă valoare la 0.
În cazul nostru, cel mai bun clasificator constant prezice întotdeauna „nu”. Prin urmare, acuratețea este mare la 0.89, dar scorurile de reamintire, precizie și Fβ sunt 0. Dacă setul de date este perfect echilibrat acolo unde nu există o singură clasă majoritară sau minoritară, am fi văzut posibilități mult mai interesante pentru precizie, reamintire, și scorurile Fβ ale clasificatorului constant.
În plus, puteți vizualiza aceste rezultate în format JSON, așa cum se arată în exemplul următor. Puteți accesa atât fișierele PDF, cât și JSON prin interfața de utilizare, precum și Amazon SageMaker Python SDK folosind elementul S3OutputPath în OutputDataConfig structura în CreateAutoMLJob/DescrieAutoMLJob Răspuns API.
{ "version" : 0.0, "dataset" : { "item_count" : 9152, "evaluation_time" : "2022-03-16T20:49:18.661Z" }, "binary_classification_metrics" : { "confusion_matrix" : { "no" : { "no" : 7468, "yes" : 648 }, "yes" : { "no" : 295, "yes" : 741 } }, "recall" : { "value" : 0.7152509652509652, "standard_deviation" : 0.00439996600081394 }, "precision" : { "value" : 0.5334773218142549, "standard_deviation" : 0.007335840278445563 }, "accuracy" : { "value" : 0.8969624125874126, "standard_deviation" : 0.0011703516093899595 }, "recall_best_constant_classifier" : { "value" : 0.0, "standard_deviation" : 0.0 }, "precision_best_constant_classifier" : { "value" : 0.0, "standard_deviation" : 0.0 }, "accuracy_best_constant_classifier" : { "value" : 0.8868006993006993, "standard_deviation" : 0.0016707401772078998 }, "true_positive_rate" : { "value" : 0.7152509652509652, "standard_deviation" : 0.00439996600081394 }, "true_negative_rate" : { "value" : 0.9201577131591917, "standard_deviation" : 0.0010233756436643213 }, "false_positive_rate" : { "value" : 0.07984228684080828, "standard_deviation" : 0.0010233756436643403 }, "false_negative_rate" : { "value" : 0.2847490347490348, "standard_deviation" : 0.004399966000813983 },
………………….
ROC și AUC
În funcție de tipul de problemă, este posibil să aveți praguri diferite pentru ceea ce este acceptabil ca FPR. De exemplu, dacă încercați să preziceți dacă un client va deschide un cont, atunci ar putea fi mai acceptabil pentru companie să aibă o rată FP mai mare. Poate fi mai riscant să ratezi extinderea ofertelor către clienții cărora li sa prezis incorect „nu”, spre deosebire de a oferi clienților cărora li sa prezis incorect „da”. Modificarea acestor praguri pentru a produce diferite FPR necesită crearea de noi matrice de confuzie.
Algoritmii de clasificare returnează valori continue cunoscute sub numele de probabilități de predicție. Aceste probabilități trebuie transformate într-o valoare binară (pentru clasificarea binară). În problemele de clasificare binară, un prag (sau un prag de decizie) este o valoare care dihotomizează probabilitățile într-o decizie binară simplă. Pentru probabilitățile proiectate normalizate în intervalul de la 0 la 1, pragul este setat implicit la 0.5.
Pentru modelele de clasificare binară, o măsură de evaluare utilă este aria de sub curba caracteristicii de funcționare a receptorului (ROC). Raportul de calitate a modelului include un grafic ROC cu rata TP ca axa y și FPR ca axa x. Zona sub caracteristica de funcționare a receptorului (AUC-ROC) reprezintă compromisul dintre TPR și FPR.
Creați o curbă ROC luând un predictor de clasificare binar, care utilizează o valoare de prag și atribuind etichete cu probabilități de predicție. Pe măsură ce variați pragul pentru un model, acoperiți de la cele două extreme. Când TPR și FPR sunt ambele 0, înseamnă că totul este etichetat „nu”, iar când atât TPR, cât și FPR sunt 1, înseamnă că totul este etichetat „da”.
Un predictor aleatoriu care etichetează „Da” jumătate din timp și „Nu” în cealaltă jumătate din timp ar avea un ROC care este o linie diagonală dreaptă (linie punctată roșie). Această linie taie pătratul unității în două triunghiuri de dimensiuni egale. Prin urmare, aria de sub curbă este 0.5. O valoare AUC-ROC de 0.5 ar însemna că predictorul dumneavoastră nu a fost mai bun la discriminarea între cele două clase decât să ghicească aleatoriu dacă un client ar deschide un cont sau nu. Cu cât valoarea AUC-ROC este mai aproape de 1.0, cu atât predicțiile sale sunt mai bune. O valoare sub 0.5 indică faptul că am putea face de fapt modelul nostru să producă predicții mai bune, inversând răspunsul pe care ni-l oferă. Pentru cel mai bun model al nostru, AUC este 0.93.

Curba de rechemare de precizie
Raportul de calitate a modelului a creat, de asemenea, o curbă de rechemare de precizie (PR) pentru a reprezenta în grafic precizia (axa y) și retragerea (axa x) pentru diferite praguri – la fel ca curba ROC. Curbele PR, adesea folosite în Recuperarea informațiilor, sunt o alternativă la curbele ROC pentru probleme de clasificare cu o declinare mare în distribuția clasei.
Pentru aceste seturi de date dezechilibrate de clasă, curbele PR devin utile în special atunci când clasa pozitivă minoritară este mai interesantă decât clasa negativă majoritară. Amintiți-vă că modelul nostru prezintă o precizie de 0.53 și o rechemare de 0.72. Mai mult, amintiți-vă că cel mai bun clasificator constant nu poate discrimina între „da” și „nu”. Ar prezice o clasă aleatoare sau o clasă constantă de fiecare dată.
Curba pentru un set de date echilibrat între „da” și „nu” ar fi o linie orizontală la 0.5 și, astfel, ar avea o zonă sub curba PR (AUPRC) ca 0.5. Pentru a crea PRC, trasăm diferite modele pe curbă la diferite praguri, în același mod ca și curba ROC. Pentru datele noastre, AUPRC este 0.61.

Ieșire raport de calitate model
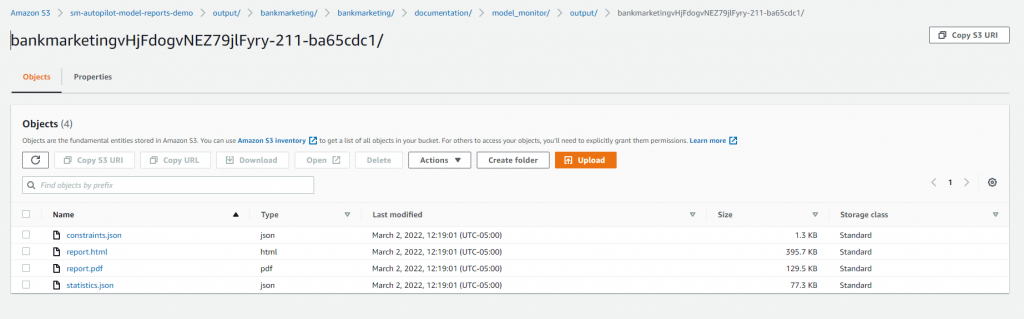
Puteți găsi Raportul de calitate a modelului în compartimentul Amazon S3 pe care l-ați specificat când ați desemnat calea de ieșire înainte de a rula experimentul SageMaker AutoPilot. Veți găsi rapoartele sub documentation/model_monitor/output/<autopilot model name>/ prefix salvat ca PDF.
Concluzie
Rapoartele de calitate a modelului SageMaker Autopilot vă ajută să vedeți și să partajați rapid rezultatele unui experiment SageMaker Autopilot. Puteți finaliza cu ușurință antrenamentul și reglarea modelului folosind SageMaker Autopilot, apoi faceți referire la rapoartele generate pentru a interpreta rezultatele. Indiferent dacă ajungeți să utilizați cel mai bun model SageMaker Autopilot sau un alt candidat, aceste rezultate pot fi un punct de plecare util pentru evaluarea unui job preliminar de pregătire și reglare a modelului. SageMaker Autopilot Model Quality Reports ajută la reducerea timpului necesar pentru scrierea codului și producerea de imagini pentru evaluarea și compararea performanței.
Puteți încorpora cu ușurință autoML în cazurile dvs. de afaceri astăzi, fără a fi nevoie să construiți o echipă de știință a datelor. SageMaker documentaţie oferă numeroase mostre pentru a vă ajuta să începeți.
Despre Autori
 Peter Chung este arhitect de soluții pentru AWS și este pasionat de a ajuta clienții să descopere informații din datele lor. El a construit soluții pentru a ajuta organizațiile să ia decizii bazate pe date, atât în sectorul public, cât și în cel privat. El deține toate certificările AWS, precum și două certificări GCP. Îi place cafeaua, să gătească, să rămână activ și să petreacă timpul cu familia.
Peter Chung este arhitect de soluții pentru AWS și este pasionat de a ajuta clienții să descopere informații din datele lor. El a construit soluții pentru a ajuta organizațiile să ia decizii bazate pe date, atât în sectorul public, cât și în cel privat. El deține toate certificările AWS, precum și două certificări GCP. Îi place cafeaua, să gătească, să rămână activ și să petreacă timpul cu familia.
 Arunprasath Shankar este un arhitect specializat în soluții de inteligență artificială și învățare automată (AI / ML) cu AWS, ajutând clienții globali să își scaleze soluțiile de AI în mod eficient și eficient în cloud. În timpul liber, lui Arun îi place să urmărească filme SF și să asculte muzică clasică.
Arunprasath Shankar este un arhitect specializat în soluții de inteligență artificială și învățare automată (AI / ML) cu AWS, ajutând clienții globali să își scaleze soluțiile de AI în mod eficient și eficient în cloud. În timpul liber, lui Arun îi place să urmărească filme SF și să asculte muzică clasică.
 Ali Takbiri este un arhitect de soluții specializat în AI/ML și ajută clienții folosind Machine Learning pentru a-și rezolva provocările de afaceri pe AWS Cloud.
Ali Takbiri este un arhitect de soluții specializat în AI/ML și ajută clienții folosind Machine Learning pentru a-și rezolva provocările de afaceri pe AWS Cloud.
 Pradeep Reddy este Senior Product Manager în echipa SageMaker Low/No Code ML, care include SageMaker Autopilot, SageMaker Automatic Model Tuner. În afara serviciului, lui Pradeep îi place să citească, să alerge și să se plimbe cu computere de dimensiunea palmei, cum ar fi raspberry pi și alte tehnologii de automatizare a locuinței.
Pradeep Reddy este Senior Product Manager în echipa SageMaker Low/No Code ML, care include SageMaker Autopilot, SageMaker Automatic Model Tuner. În afara serviciului, lui Pradeep îi place să citească, să alerge și să se plimbe cu computere de dimensiunea palmei, cum ar fi raspberry pi și alte tehnologii de automatizare a locuinței.
- Coinsmart. Cel mai bun schimb de Bitcoin și Crypto din Europa.
- Platoblockchain. Web3 Metaverse Intelligence. Cunoștințe amplificate. ACCES LIBER.
- CryptoHawk. Radar Altcoin. Încercare gratuită.
- Sursa: https://aws.amazon.com/blogs/machine-learning/automatically-generate-model-evaluation-metrics-using-sagemaker-autopilot-model-quality-reports/
- "
- 100
- 7
- Despre Noi
- acces
- Cont
- activ
- avansat
- AI
- algoritmi
- TOATE
- Amazon
- printre
- O alta
- api
- ZONĂ
- artificial
- inteligență artificială
- Inteligența artificială și învățarea în mașină
- atribute
- Automatizare
- disponibil
- AWS
- Bancă
- De bază
- deveni
- CEL MAI BUN
- frontieră
- Cutie
- construi
- Clădire
- afaceri
- cazuri
- provocări
- Alege
- clasă
- clase
- clasificare
- mai aproape
- Cloud
- cod
- Cafea
- Coloană
- comparație
- complex
- Calculatoare
- confuzie
- conține
- Cheltuieli
- ar putea
- a creat
- Crearea
- curba
- clienţii care
- de date
- știința datelor
- set de date
- demonstra
- implementa
- Implementarea
- Detectare
- FĂCUT
- diferit
- direct
- distribuire
- cu ușurință
- Punct final
- Inginerie
- mai ales
- tot
- exemplu
- experiment
- familie
- Caracteristică
- În cele din urmă
- descoperiri
- First
- Flexibilitate
- Concentra
- următor
- format
- genera
- Caritate
- bine
- având în
- ajutor
- util
- ajută
- Înalt
- superior
- deține
- Acasă
- Automatizare acasă
- Cum
- Cum Pentru a
- HTTPS
- ICON
- Identitate
- important
- include
- informații
- perspective
- Inteligență
- IT
- Loc de munca
- cunoscut
- etichete
- mare
- mai mare
- AFLAȚI
- învăţare
- Pârghie
- Linie
- Ascultare
- locaţie
- maşină
- masina de învățare
- Majoritate
- FACE
- administrare
- manager
- Marketing
- Matrice
- măsura
- Metrici
- minoritate
- ML
- model
- Modele
- mai mult
- cele mai multe
- Filme
- Muzică
- număr
- numeroși
- oferind
- promoții
- deschide
- de deschidere
- de operare
- Opţiuni
- organizații
- Altele
- pasionat
- performanță
- Punct
- pozitiv
- posibilităţile de
- posibil
- potenţial
- prezice
- prezicere
- Predictii
- prezenta
- privat
- Problemă
- probleme
- produce
- Produs
- producere
- furniza
- furnizează
- public
- calitate
- repede
- gamă
- Citind
- reduce
- raportează
- Rapoarte
- reprezintă
- Resurse
- răspuns
- REZULTATE
- funcţionare
- Scară
- Ştiinţă
- sectoare
- set
- Distribuie
- simplu
- So
- soluţii
- REZOLVAREA
- spam-
- Cheltuire
- pătrat
- început
- Stare
- depozitare
- studio
- Ţintă
- echipă
- tech
- Prin
- timp
- astăzi
- TPR
- Pregătire
- trenuri
- ui
- descoperi
- înţelege
- us
- utilizare
- valoare
- diverse
- Vizualizare
- vizibilitate
- dacă
- OMS
- fără
- Apartamente
- ar