Introducere
În lumea rapidă de astăzi a livrării de alimente locale, asigurarea satisfacției clienților este esențială pentru companii. Jucători majori precum Zomato și Swiggy domină această industrie. Clienții se așteaptă la alimente proaspete; dacă primesc articole stricate, ei apreciază un voucher de rambursare sau de reducere. Cu toate acestea, determinarea manuală a prospețimii alimentelor este greoaie pentru clienți și personalul companiei. O soluție este automatizarea acestui proces folosind modele Deep Learning. Aceste modele pot prezice prospețimea alimentelor, permițând numai plângerilor semnalate să fie revizuite de către angajați pentru validarea finală. Dacă modelul confirmă prospețimea alimentelor, poate respinge automat reclamația. În acest articol vom construi un detector de calitate a alimentelor folosind Deep Learning.
Deep Learning, un subset al inteligenței artificiale, oferă o utilitate semnificativă în acest context. Mai exact, CNN-urile (Rețelele neuronale convoluționale) pot fi folosite pentru a antrena modele folosind imagini alimentare pentru a le discerne prospețimea. Precizia modelului nostru depinde în întregime de calitatea setului de date. În mod ideal, încorporarea imaginilor reale de mâncare din plângerile utilizatorilor chatbot în aplicațiile hiperlocale de livrare a alimentelor ar îmbunătăți considerabil acuratețea. Cu toate acestea, neavând acces la astfel de date, ne bazăm pe un set de date utilizat pe scară largă, cunoscut sub numele de „Setul de date Fresh and Rotten Classification”, accesibil pe Kaggle. Pentru a explora codul complet de deep-learning, faceți clic pe butonul „Copiați și editați” furnizat aici.
obiective de invatare
- Aflați importanța calității alimentelor în satisfacția clienților și creșterea afacerii.
- Descoperiți cât de profundă ajută învățarea la construirea detectorului de calitate a alimentelor.
- Dobândiți experiență practică printr-o implementare pas cu pas a acestui model.
- Înțelegeți provocările și soluțiile implicate în implementarea acestuia.
Acest articol a fost publicat ca parte a Blogathonul științei datelor.
Cuprins
Înțelegerea utilizării Deep Learning în Detectorul de calitate a alimentelor
Invatare profunda, un subset al Inteligenta Artificiala, folosește în primul rând seturi de date spațiale pentru a construi modele. Rețelele neuronale din cadrul Deep Learning sunt utilizate pentru a antrena aceste modele, mimând funcționalitatea creierului uman.
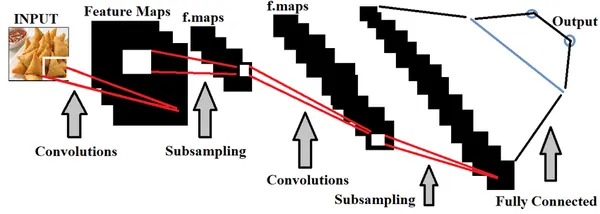
În contextul detectării calității alimentelor, formarea modelelor de învățare profundă cu seturi extinse de imagini alimentare este esențială pentru a distinge cu precizie alimentele de calitate bună și de proastă calitate. Putem să facem reglarea hiperparametrului pe baza datelor care sunt alimentate, pentru a face modelul mai precis.
Importanța calității alimentelor în livrarea hiperlocală
Integrarea acestei funcții în livrarea de alimente hiperlocală oferă mai multe beneficii. Modelul evită părtinirea față de anumiți clienți și prezice cu acuratețe, reducând astfel timpul de soluționare a reclamațiilor. În plus, putem folosi această funcție în timpul procesului de ambalare a comenzii pentru a inspecta calitatea alimentelor înainte de livrare, asigurându-ne că clienții primesc în mod constant alimente proaspete.

Dezvoltarea unui detector de calitate a alimentelor
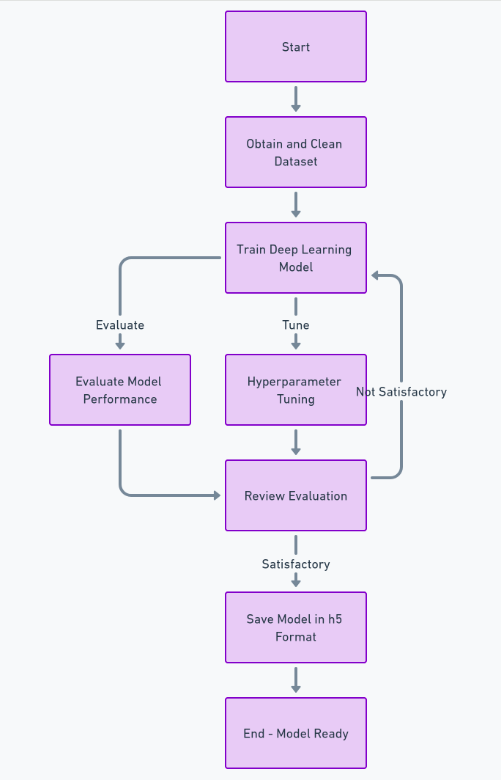
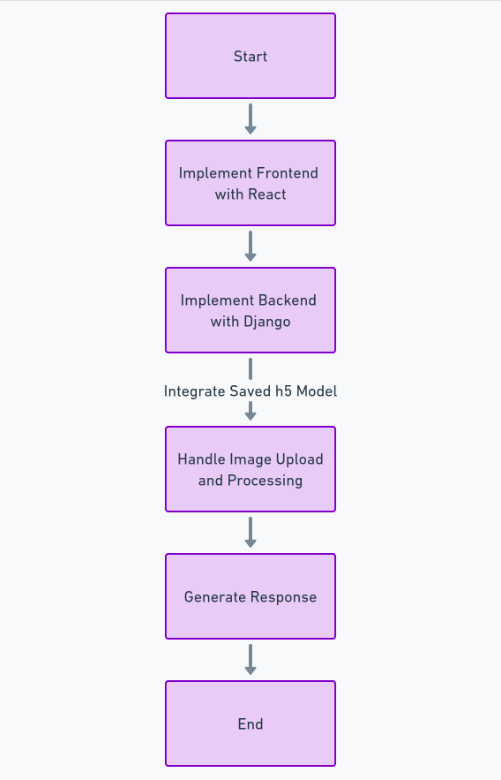
Pentru a construi complet această caracteristică, trebuie să urmăm o mulțime de pași, cum ar fi obținerea și curățarea setului de date, antrenarea modelului de învățare profundă, evaluarea performanței și reglarea hiperparametrului și, în sfârșit, salvarea modelului în h5 format. După aceasta, putem implementa frontend-ul folosind Reacţiona, iar backend-ul folosind cadrul Python django. Vom folosi Django pentru a gestiona încărcarea imaginilor și a o procesa.
Despre setul de date
Înainte de a aprofunda preprocesarea datelor și construirea modelelor, este esențial să înțelegeți setul de date. După cum am discutat mai devreme, vom folosi un set de date de la Kaggle numit Clasificarea alimentelor proaspete și putrede. Acest set de date este împărțit în două categorii principale numite Tren și Test care sunt utilizate în scopuri de instruire și, respectiv, de testare. Sub folderul trenului, avem 9 subdirectoare cu fructe proaspete și legume proaspete și 9 subdirectoare cu fructe și legume putrede.
Caracteristicile cheie ale setului de date
- Varietate de imagini: Acest set de date conține o mulțime de imagini cu alimente cu multe variații în ceea ce privește unghiul, fundalul și condițiile de iluminare. Acest lucru ajută modelul să nu fie părtinitor și să fie mai precis.
- Imagini de înaltă calitate: Acest set de date are imagini de foarte bună calitate capturate de diverse camere profesionale.
Încărcarea și pregătirea datelor
În această secțiune, vom încărca mai întâi imaginile folosind „tensorflow.keras.preprocesare.imagine.load_img' și vizualizați imaginile folosind biblioteca matplotlib. Preprocesarea acestor imagini pentru formarea modelului este foarte importantă. Aceasta presupune curățarea și organizarea imaginilor pentru a le face potrivite pentru model.
import os
import matplotlib.pyplot as plt
from tensorflow.keras.preprocessing.image import load_img
def visualize_sample_images(dataset_dir, categories):
n = len(categories)
fig, axs = plt.subplots(1, n, figsize=(20, 5))
for i, category in enumerate(categories):
folder = os.path.join(dataset_dir, category)
image_file = os.listdir(folder)[0]
img_path = os.path.join(folder, image_file)
img = load_img(img_path)
axs[i].imshow(img)
axs[i].set_title(category)
plt.tight_layout()
plt.show()
dataset_base_dir = '/kaggle/input/fresh-and-stale-classification/dataset'
train_dir = os.path.join(dataset_base_dir, 'Train')
categories = ['freshapples', 'rottenapples', 'freshbanana', 'rottenbanana']
visualize_sample_images(train_dir, categories)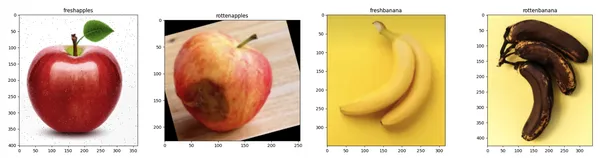
Acum să încărcăm imaginile de antrenament și testare în variabile. Vom redimensiona toate imaginile la aceeași înălțime și lățime de 180.
from tensorflow.keras.preprocessing.image import ImageDataGenerator
batch_size = 32
img_height = 180
img_width = 180
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest',
validation_split=0.2)
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(img_height, img_width),
batch_size=batch_size,
class_mode='binary',
subset='training')
validation_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(img_height, img_width),
batch_size=batch_size,
class_mode='binary',
subset='validation')
Construirea modelului
Acum să construim modelul de învățare profundă folosind algoritmul secvențial din „tensorflow.keras”. Vom adăuga 3 straturi de convoluție și un optimizator Adam. Înainte să ne oprim asupra părții practice, să înțelegem mai întâi care sunt termenii "Model secvenţial„“Adam Optimizer', și 'Stratul de convoluție' Rău.
Model secvenţial
Modelul secvenţial cuprinde un teanc de straturi, oferind o structură fundamentală în Keras. Este ideal pentru scenariile în care rețeaua dumneavoastră neuronală are un singur tensor de intrare și un singur tensor de ieșire. Adăugați straturi în ordinea secvențială de execuție, făcându-l potrivit pentru construirea de modele simple cu straturi stivuite. Această simplitate face ca modelul secvenţial să fie extrem de util şi mai uşor de implementat.
Adam Optimizer
Abrevierea lui Adam este „Adaptive Moment Estimation”. Acesta servește ca o alternativă a algoritmului de optimizare la coborârea gradientului stocastic, actualizând ponderile rețelei în mod iterativ. Adam Optimizer este benefic deoarece menține o rată de învățare (LR) pentru fiecare greutate a rețelei, ceea ce este avantajos în gestionarea zgomotului în date.
Strat convoluțional (Conv2D)
Este componenta principală a rețelelor neuronale convoluționale (CNN). Este folosit în principal pentru procesarea seturi de date spațiale, cum ar fi imagini. Acest strat aplică o funcție sau o operație de convoluție la intrare și apoi transmite rezultatul la stratul următor.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
model = Sequential([
Conv2D(32, (3, 3), activation='relu', input_shape=(img_height, img_width, 3)),
MaxPooling2D(2, 2),
Conv2D(64, (3, 3), activation='relu'),
MaxPooling2D(2, 2),
Conv2D(128, (3, 3), activation='relu'),
MaxPooling2D(2, 2),
Flatten(),
Dense(512, activation='relu'),
Dropout(0.5),
Dense(1, activation='sigmoid')
])
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
epochs = 10
history = model.fit(
train_generator,
steps_per_epoch=train_generator.samples // batch_size,
epochs=epochs,
validation_data=validation_generator,
validation_steps=validation_generator.samples // batch_size)
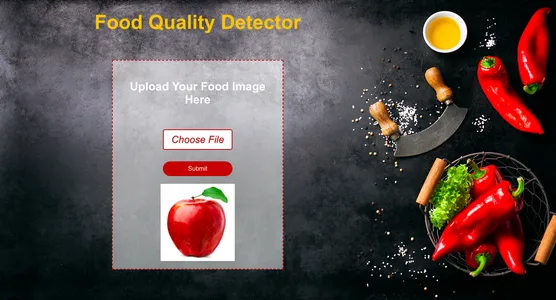
Testarea detectorului de calitate a alimentelor
Acum să testăm modelul dându-i o nouă imagine a alimentelor și să vedem cât de exact se poate clasifica în alimente proaspete și putrede.
from tensorflow.keras.preprocessing import image
import numpy as np
def classify_image(image_path, model):
img = image.load_img(image_path, target_size=(img_height, img_width))
img_array = image.img_to_array(img)
img_array = np.expand_dims(img_array, axis=0)
img_array /= 255.0
predictions = model.predict(img_array)
if predictions[0] > 0.5:
print("Rotten")
else:
print("Fresh")
image_path = '/kaggle/input/fresh-and-stale-classification/dataset/Train/
rottenoranges/Screen Shot 2018-06-12 at 11.18.28 PM.png'
classify_image(image_path, model)
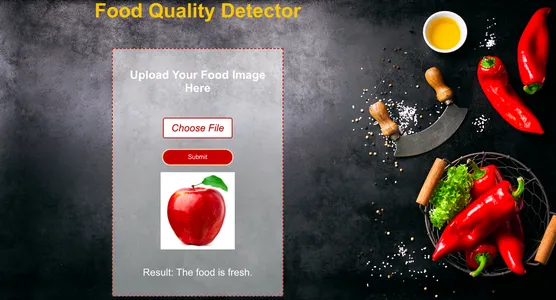
După cum putem vedea, modelul a prezis corect. Așa cum am dat rottenorange imagine ca intrare modelul a prezis-o corect putrezit.
Pentru codul frontend (React) și backend (Django), puteți vedea codul meu complet pe GitHub aici: Link
Concluzie
În concluzie, pentru a automatiza reclamațiile privind calitatea alimentelor în aplicațiile Hyperlocal Delivery, propunem construirea unui model de deep learning integrat cu o aplicație web. Cu toate acestea, din cauza datelor limitate de antrenament, este posibil ca modelul să nu detecteze cu acuratețe fiecare imagine alimentară. Această implementare servește ca un pas fundamental către o soluție mai mare. Accesul la imagini în timp real încărcate de utilizator în cadrul acestor aplicații ar îmbunătăți semnificativ acuratețea modelului nostru.
Intrebari cu cheie
- Calitatea alimentelor joacă un rol critic în atingerea satisfacției clienților pe piața hiperlocală de livrare a alimentelor.
- Puteți utiliza tehnologia Deep Learning pentru a pregăti un predictor precis al calității alimentelor.
- Ați dobândit experiență practică cu acest ghid pas cu pas pentru a crea aplicația web.
- Ați înțeles importanța calității setului de date pentru construirea unui model precis.
Media prezentată în acest articol nu este deținută de Analytics Vidhya și este utilizată la discreția Autorului.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- PlatoData.Network Vertical Generative Ai. Împuterniciți-vă. Accesați Aici.
- PlatoAiStream. Web3 Intelligence. Cunoștințe amplificate. Accesați Aici.
- PlatoESG. carbon, CleanTech, Energie, Mediu inconjurator, Solar, Managementul deșeurilor. Accesați Aici.
- PlatoHealth. Biotehnologie și Inteligență pentru studii clinice. Accesați Aici.
- Sursa: https://www.analyticsvidhya.com/blog/2024/03/food-quality-detector/
- :are
- :este
- :nu
- :Unde
- 1
- 10
- 11
- 127
- 180
- 2%
- 20
- 28
- 300
- 32
- 48
- 5
- 501
- 55
- 58
- 9
- a
- abreviere
- Despre Noi
- acces
- accesibil
- precizie
- precis
- precis
- realizarea
- Adam
- adăuga
- În plus,
- avantajos
- După
- SIDA
- Algoritmul
- TOATE
- Permiterea
- alternativă
- an
- Google Analytics
- Analize Vidhya
- și
- unghi
- aplicaţia
- se aplică
- aprecia
- Apps
- SUNT
- articol
- artificial
- inteligență artificială
- AS
- At
- automatizarea
- în mod automat
- Împiedică
- AXS
- Backend
- fundal
- Rău
- bazat
- BE
- înainte
- fiind
- benefică
- Beneficiile
- între
- părtinire
- părtinitor
- binar
- blogathon
- Creier
- construi
- Clădire
- afaceri
- buton
- by
- camere video
- CAN
- capturat
- categorii
- Categorii
- provocări
- chatbot
- clasificare
- Clasifica
- Curățenie
- clic
- cod
- Companii
- companie
- plângere
- plângeri
- Completă
- complet
- component
- cuprinde
- concluzie
- Condiții
- consecvent
- construi
- construirea
- conține
- context
- corect
- critic
- crucial
- greoaie
- client
- Satisfactia clientului
- clienţii care
- de date
- seturi de date
- adânc
- învățare profundă
- Def
- livrare
- dens
- detecta
- Detectare
- determinarea
- în curs de dezvoltare
- discerne
- Reducere
- discreție
- discutat
- destitui
- Django
- do
- face
- domina
- două
- în timpul
- fiecare
- Mai devreme
- mai ușor
- altfel
- angajat
- de angajați
- angajează
- spori
- asigurare
- în întregime
- epoci
- esenţial
- Eter (ETH)
- evaluarea
- Fiecare
- execuție
- aștepta
- experienţă
- explora
- extensiv
- ritm rapid
- Caracteristică
- DESCRIERE
- fed-
- Smochin
- final
- În cele din urmă
- First
- fanionat
- urma
- alimente
- livrare de mancare
- Pentru
- fundamentale
- Cadru
- proaspăt
- din
- Frontend
- Fructe
- funcţie
- funcționalitate
- fundamental
- dobândită
- GitHub
- dat
- Oferirea
- merge
- bine
- foarte mult
- Creștere
- ghida
- manipula
- Manipularea
- hands-on
- Avea
- înălțime
- ajută
- aici
- Înalt
- extrem de
- balamale
- istorie
- Cum
- Totuși
- http
- HTTPS
- uman
- Reglarea hiperparametrului
- i
- ideal
- ideal
- if
- imagine
- imagini
- punerea în aplicare a
- implementarea
- import
- importanță
- important
- in
- care încorporează
- industrie
- intrare
- integrate
- Inteligență
- în
- implicat
- implică
- IT
- articole
- ESTE
- keras
- Cheie
- cunoscut
- lipsit
- mai mare
- strat
- straturi
- învăţare
- Bibliotecă
- Iluminat
- ca
- Limitat
- încărca
- încărcare
- local
- Lot
- Principal
- mai ales
- susține
- major
- face
- FACE
- Efectuarea
- manual
- Piață
- matplotlib
- max-width
- Mai..
- însemna
- Mass-media
- model
- Modele
- moment
- mai mult
- my
- Numit
- Nevoie
- reţea
- rețele
- neural
- rețele neuronale
- rețele neuronale
- Nou
- următor
- Zgomot
- NumPy
- obținerea
- of
- oferind
- promoții
- on
- ONE
- afară
- operaţie
- optimizare
- or
- comandă
- organizator
- OS
- al nostru
- producție
- deţinute
- parte
- trece
- cale
- performanță
- Plato
- Informații despre date Platon
- PlatoData
- jucători
- joacă
- pm
- Practic
- prezice
- a prezis
- Predictii
- Predictor
- prezice
- pregătire
- în primul rând
- proces
- prelucrare
- profesional
- propune
- prevăzut
- publicat
- scopuri
- calitate
- rată
- Reacţiona
- real
- în timp real
- într-adevăr
- a primi
- reducerea
- rambursa
- relu
- se bazează
- Rezoluţie
- rezultat
- revizuite
- Rol
- acelaşi
- satisfacție
- economisire
- scenarii
- Ştiinţă
- Secțiune
- vedea
- servește
- Seturi
- câteva
- shot
- indicat
- semnificativ
- semnificativ
- simplitate
- pur şi simplu
- singur
- soluţie
- soluţii
- spațial
- specific
- specific
- împărţi
- stivui
- stivuite
- Personal
- Pas
- paşi
- simplu
- structura
- astfel de
- potrivit
- Swiggy
- Tehnologia
- tensorflow
- termeni
- test
- Testarea
- acea
- lor
- apoi
- astfel
- Acestea
- ei
- acest
- Prin
- timp
- la
- azi
- față de
- Tren
- Pregătire
- de reglaj
- Două
- în
- înţelege
- înţelegere
- înțeles
- actualizarea
- utilizare
- utilizat
- util
- folosind
- utilitate
- folosi
- utilizate
- validare
- variabile
- diverse
- Legume
- foarte
- imagina
- a fost
- we
- web
- WebP
- greutate
- Ce
- care
- voi
- cu
- în
- lume
- ar
- tu
- Ta
- zephyrnet
- Zomato