Acest articol a fost publicat ca parte a Blogathon Data Science
Introducere

Rețelele neuronale convoluționale, numite și ConvNets, au fost introduse pentru prima dată în anii 1980 de către Yann LeCun, un cercetător în domeniul informaticii care a lucrat în fundal. LeCun a construit pe opera lui Kunihiko Fukushima, un om de știință japonez, o rețea de bază pentru recunoașterea imaginii.
Vechea versiune a CNN, numită LeNet (după LeCun), poate vedea cifre scrise de mână. CNN vă ajută să găsiți coduri PIN din poștă. Dar, în ciuda expertizei lor, ConvNets a rămas aproape de viziunea computerizată și de inteligența artificială, deoarece se confruntau cu o problemă majoră: nu puteau scala mult. CNN necesită multe date și integrează resurse pentru a funcționa bine pentru imagini mari.
La acea vreme, această metodă se aplica numai imaginilor cu rezoluție mică. Pytorch este o bibliotecă care poate face operații de învățare profundă. Putem folosi acest lucru pentru a realiza rețele neuronale convoluționale. Rețelele neuronale convoluționale conțin multe straturi de neuroni artificiali. Neuronii sintetici, simulări complexe ale omologilor biologici, sunt funcții matematice care calculează masa ponderată a intrărilor multiple și activarea valorii produsului.

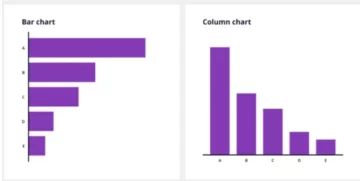
Imaginea de mai sus ne arată un model CNN care preia o imagine asemănătoare cifrei de 2 și ne dă rezultatul a ceea ce cifră a fost afișată în imagine ca număr. Vom discuta în detaliu cum obținem acest lucru în acest articol.
CIFAR-10 este un set de date care are o colecție de imagini din 10 clase diferite. Acest set de date este utilizat pe scară largă în scopuri de cercetare pentru a testa diferite modele de învățare automată și în special pentru probleme de vedere computerizată. În acest articol, vom încerca să construim un model de rețea neuronală folosind Pytorch și să-l testăm pe setul de date CIFAR-10 pentru a verifica ce precizie poate fi obținută.
Importul bibliotecii PyTorch
import numpy ca np import panda ca pd
import torch import torch.nn.funcțional ca F din torchvision import seturi de date, transformă din torță import nn import matplotlib.pyplot ca plt import numpy ca np import seaborn ca sns #de tqdm.notebook import tqdm din tqdm import tqdm
În acest pas, importăm bibliotecile necesare. Putem vedea că folosim NumPy pentru operații numerice și panda pentru operații de cadre de date. Biblioteca cu lanterne este utilizată pentru a importa Pytorch.
Pytorch are o componentă nn care este utilizată pentru abstractizarea operațiilor și funcțiilor de învățare automată. Aceasta este importată ca F. Biblioteca torchvision este utilizată astfel încât să putem importa setul de date CIFAR-10. Această bibliotecă are multe seturi de date de imagine și este utilizată pe scară largă pentru cercetare. Transformările pot fi importate astfel încât să putem redimensiona imaginea la dimensiune egală pentru toate imaginile. Tqdm este utilizat astfel încât să putem urmări progresul în timpul antrenamentului și este utilizat pentru vizualizare.
Citiți setul de date solicitat
trainData = pd.read_csv ('cifar-10 / trainLabels.csv') trainData.head ()
Odată ce am citit setul de date, putem vedea diverse etichete precum broasca, camionul, cerbul, automobilul etc.
Analizarea datelor cu PyTorch
print ("Număr de puncte:", trainData.shape [0]) print ("Număr de caracteristici:", trainData.shape [1]) print ("Caracteristici:", trainData.columns.values) print ("Număr de Valori unice ") pentru col in trainData: print (col,": ", len (trainData [col] .unique ())) plt.figure (figsize = (12,8))
ieșire:
Număr de puncte: 50000 Număr de caracteristici: 2 Caracteristici: [„id” „etichetă”] Număr de valori unice id: 50000 etichetă: 10
În acest pas, analizăm setul de date și vedem că datele trenului nostru au în jur de 50000 de rânduri cu codul lor și eticheta asociată. Există un total de 10 clase ca în numele CIFAR-10.
Obținerea setului de validare folosind PyTorch
din torch.utils.data import random_split val_size = 5000 train_size = len (set de date) - val_size train_ds, val_ds = random_split (set de date, [train_size, val_size]) len (train_ds), len (val_ds)
Acest pas este același cu pasul de formare, dar vrem să împărțim datele în seturi de tren și validare.
(45000, 5000)
din torch.utils.data.dataloader import DataLoader batch_size = 64 train_dl = DataLoader (train_ds, batch_size, shuffle = True, num_workers = 4, pin_memory = True) val_dl = DataLoader (val_ds, batch_size, num_workers = 4, pin_mem
Torch.utils au un încărcător de date care ne poate ajuta să încărcăm datele necesare ocolind diferiți parametri, cum ar fi numărul lucrătorului sau dimensiunea lotului.
Definirea funcțiilor necesare
@ torch.no_grad () precizie def (ieșiri, etichete): _, preds = torch.max (ieșiri, dim = 1) return torch.tensor (torch.sum (preds == etichete) .item () / len (preds )) clasă ImageClassificationBase (nn.Module): def training_step (self, batch): imagini, etichete = batch out = self (imagini) # Generare predicții pierdere = F.cross_entropy (out, etichete) # Calculează pierderea accu = exactitate (out) ; # Calculați returnarea preciziei {'Loss': loss.detach (), 'Accuracy': acc} def validation_epoch_end (self, outputs): batch_losses = [x ['Loss'] pentru x în ieșiri] epoch_loss = torch.lack (batch_losses ) .mean () # Combinați pierderile batch_accs = [x ['Precizie'] pentru x în ieșiri] epoch_acc = torch.stack (batch_accs) .mean () # Combinați acuratețea returnează {'Pierderea': epoch_loss.item (), ' Precizie ': epoch_acc.item ()} def epoch_end (sine, epocă, rezultat): pr int ("Epoch:", epoch + 1) print (f'Train Accuracy: {result ["train_accuracy"] * 100: .2f}% Validation Precision: {result ["Accuracy"] * 100: .2f}% ' ) print (f'Toss Loss: {result ["train_loss"] :. 4f} Validation Loss: {result ["Loss"] :. 4f} ')
După cum putem vedea aici, am folosit implementarea de clasă a ImageClassification și este nevoie de un parametru care este nn.Module. În cadrul acestei clase, putem implementa diferite funcții sau pași diferiți, cum ar fi instruirea, validarea etc. Funcțiile de aici sunt implementări simple de python.
Pasul de instruire ia imagini și etichete în loturi. folosim entropia încrucișată pentru funcția de pierdere și calculăm pierderea și returnăm pierderea. Acest lucru este similar cu pasul de validare așa cum putem vedea în funcție. Sfârșiturile epocii combină pierderile și acuratețea și, în cele din urmă, imprimăm acuratețea și pierderile.
Implementarea modulului de rețea neuronală convoluțională
clasa Cifar10CnnModel (ImageClassificationBase): def __init __ (self): super () .__ init __ () self.network = nn.Sequential (nn.Conv2d (3, 32, kernel_size = 3, padding = 1), nn.ReLU (), nn.Conv2d (32, 64, kernel_size = 3, stride = 1, padding = 1), nn.ReLU (), nn.MaxPool2d (2, 2), # ieșire: 64 x 16 x 16 nn.BatchNorm2d (64) , nn.Conv2d (64, 128, kernel_size = 3, stride = 1, padding = 1), nn.ReLU (), nn.Conv2d (128, 128, kernel_size = 3, stride = 1, padding = 1), nn .ReLU (), nn.MaxPool2d (2, 2), # ieșire: 128 x 8 x 8 nn.BatchNorm2d (128), nn.Conv2d (128, 256, kernel_size = 3, stride = 1, padding = 1), nn.ReLU (), nn.Conv2d (256, 256, kernel_size = 3, stride = 1, padding = 1), nn.ReLU (), nn.MaxPool2d (2, 2), # ieșire: 256 x 4 x 4 nn.BatchNorm2d (256), nn.Flatten (), nn.Linear (256 * 4 * 4, 1024), nn.ReLU (), nn.Linear (1024, 512), nn.ReLU (), nn.Linear (512, 10)) def forward (self, xb): returnează self.network (xb)
Aceasta este cea mai importantă parte a implementării rețelei neuronale. Pe tot parcursul, folosim modulul nn pe care l-am importat de pe torță. După cum putem vedea în prima linie, Conv2d este un modul care ajută la implementarea unei rețele neuronale convoluționale. Primul parametru 3 aici reprezintă faptul că imaginea este colorată și în format RGB. Dacă ar fi fost o imagine în tonuri de gri, am fi optat pentru 1.
32 este dimensiunea canalului de ieșire inițial și atunci când mergem pentru următorul strat conv2d am avea acest 32 ca canal de intrare și 64 ca canal de ieșire.
Al treilea parametru din prima linie se numește dimensiunea nucleului și ne ajută să avem grijă de filtrele utilizate. Operația de umplere este ultimul parametru.
Operația de convoluție este conectată la un strat de activare și Relu aici. După două straturi Conv2d, avem o operațiune de grupare maximă de dimensiunea 2 * 2. Valoarea care iese din aceasta este normalizată pentru stabilitate și pentru a evita deplasarea covariabilă internă. Aceste operații sunt repetate cu mai multe straturi pentru a adânci rețeaua și a reduce dimensiunea. În cele din urmă, aplatizăm stratul astfel încât să putem construi un strat liniar pentru a mapa valorile la 10 valori. Probabilitatea fiecărui neuron din acești 10 neuroni va determina la ce clasă aparține o anumită imagine pe baza probabilității maxime.
Antrenează modelul
@ torch.no_grad () def evaluate (model, data_loader): model.eval () outputs = [model.validation_step (batch) for batch in data_loader] return model.validation_epoch_end (outputs) def fit (model, train_loader, val_loader, epochs) = 10, learning_rate = 0.001): best_valid = None history = [] optimizer = torch.optim.Adam (model.parameters (), learning_rate, weight_decay = 0.0005) pentru epoch in range (epochs): # Training Phase model.train ( ) train_losses = [] train_accuracy = [] pentru lot în tqdm (train_loader): loss, accu = model.training_step (batch) train_losses.append (loss) train_accuracy.append (accu) loss.backward () optimizer.step () optimizer .zero_grad () # Validation phase result = evaluate (model, val_loader) result ['train_loss'] = torch.stack (train_losses) .mean (). item () result ['train_accuracy'] = torch.stack (train_accuracy). mean (). item () model.epoch_end (epoch, result) if (best_valid == None sau best_valid
history = fit (model, train_dl, val_dl)
Acesta este un pas de bază pentru a ne antrena modelul pentru a obține rezultatul necesar. funcția de potrivire aici se va potrivi cu trenul și datele Val cu modelul pe care l-am creat. Funcția de potrivire ia inițial o listă numită istoric care are grijă de datele de iterație ale fiecărei epoci. Rulăm o buclă for, astfel încât să putem itera în fiecare epocă. Pentru fiecare lot, ne asigurăm că afișăm progresul folosind tqdm. Denumim etapa de instruire pe care am implementat-o anterior și calculăm acuratețea și pierderea. Mergeți pentru propagarea înapoi și optimizatorul de rulare pe care l-am definit mai devreme. Odată ce facem acest lucru, ținem evidența listei noastre, iar funcțiile ne ajută să imprimăm detaliile și progresul.
Funcția de evaluare, pe de altă parte, folosește funcția de evaluare și, pentru fiecare pas, luăm lotul încărcat din încărcătorul de date și se calculează ieșirea. Valoarea este apoi trecută la sfârșitul perioadei de validare definite anterior și valoarea respectivă este returnată.
Trasarea rezultatelor
În acest pas, vom vizualiza acuratețea față de fiecare epocă. Putem observa că pe măsură ce epoca crește, precizia sistemului crește și în mod similar pierderea scade. Linia roșie indică progresul datelor de antrenament și albastru pentru validare. Putem vedea că a existat o cantitate bună de supradaptare în rezultatele noastre, deoarece datele de instruire depășesc destul de mult rezultatul validării și în mod similar în caz de pierdere. După 10 epoci, datele trenului par să ocolească 90% precizia, dar are o pierdere de aproximativ 0.5. Datele testului sunt în jur de 81%, iar pierderile sunt de aproape 0.2.
def plot_accuracies (history): Validation_accuracies = [x ['Accuracy'] pentru x in history] Training_Accuracies = [x ['train_accuracy'] pentru x in history] plt.plot (Training_Accuracies, '-rx') plt.plot (Validation_accuracies , '-bx') plt.xlabel ('epocă') plt.ylabel ('acuratețe') plt.legend (['Formare', 'Validare']) plt.title ('Acuratețe vs. Nr. epoci') ; plot_accuracies (istoric)

def plot_losses (history): train_losses = [x.get ('train_loss') for x in history] val_losses = [x ['Loss'] for x in history] plt.plot (train_losses, '-bx') plt.plot (val_losses, '-rx') plt.xlabel ('epoch') plt.ylabel ('loss') plt.legend (['Training', 'Validare']) plt.title ('Pierdere vs. Nr. de epoci '); plot_losses (istoric)
test_dataset = ImageFolder (data_dir + '/ test', transform = ToTensor ()) test_loader = DeviceDataLoader (DataLoader (test_dataset, batch_size), device) result = evaluate (model_final, test_loader) print (f'Test Precizie: {result ["Accuracy") ] * 100: .2f}% ')
Precizia testului: 81.07%
Putem vedea că ajungem cu o precizie de 81.07%.
Concluzie:
Imagine: https: //unsplash.com/photos/5L0R8ZqPZHk
Despre mine: Sunt un student de cercetare interesat de domeniul învățării profunde și prelucrării limbajului natural și care urmăresc în prezent studii postuniversitare în inteligență artificială.
Image Source
- Image 1: https://becominghuman.ai/cifar-10-image-classification-fd2ace47c5e8
- Imagine 2: https://www.analyticsvidhya.com/blog/2021/05/convolutional-neural-networks-cnn/
Simțiți-vă liber să vă conectați cu mine pe:
- Linkedin: https://www.linkedin.com/in/siddharth-m-426a9614a/
- Github: https://github.com/Siddharth1698
Mediile prezentate în acest articol nu sunt deținute de Analytics Vidhya și sunt utilizate la discreția autorului.
Legate de
- "
- TOATE
- Google Analytics
- în jurul
- articol
- inteligență artificială
- construi
- apel
- pasă
- CNN
- venire
- component
- Informatică
- Computer Vision
- rețea neuronală convoluțională
- de date
- învățare profundă
- Cerb
- detaliu
- Cifră
- cifre
- se încheie
- etc
- DESCRIERE
- Filtre
- În cele din urmă
- First
- potrivi
- format
- Gratuit
- funcţie
- GitHub
- bine
- Alb-negru
- aici
- istorie
- Cum
- HTTPS
- imagine
- Recunoașterea imaginii
- Crește
- Inteligență
- IT
- etichete
- limbă
- mare
- învăţare
- Bibliotecă
- Linie
- Listă
- încărca
- masina de învățare
- major
- Hartă
- Mass-media
- model
- Limbajul natural
- Procesarea limbajului natural
- În apropiere
- reţea
- rețele
- neural
- rețele neuronale
- rețele neuronale
- Operațiuni
- Altele
- prezicere
- Predictii
- Produs
- Piton
- pirtorh
- reduce
- cercetare
- Resurse
- REZULTATE
- Alerga
- Scară
- Ştiinţă
- set
- schimbare
- simplu
- Mărimea
- So
- împărţi
- Stabilitate
- student
- sistem
- test
- timp
- lanternă
- urmări
- Pregătire
- camion
- us
- valoare
- viziune
- vizualizare
- OMS
- în
- Apartamente
- X