Aceasta este o postare comună scrisă în comun de AWS și Voxel51. Voxel51 este compania din spatele FiftyOne, setul de instrumente open-source pentru construirea de seturi de date și modele de viziune computerizată de înaltă calitate.
O companie de vânzare cu amănuntul creează o aplicație mobilă pentru a ajuta clienții să cumpere haine. Pentru a crea această aplicație, au nevoie de un set de date de înaltă calitate care să conțină imagini de îmbrăcăminte, etichetate cu diferite categorii. În această postare, arătăm cum să reutilizați un set de date existent prin curățarea datelor, preprocesare și pre-etichetare cu un model de clasificare zero-shot în Cincizeci si unu, și ajustarea acestor etichete cu Amazon SageMaker Ground Adevăr.
Puteți folosi Ground Truth și FiftyOne pentru a vă accelera proiectul de etichetare a datelor. Vă ilustrăm cum să folosiți fără probleme cele două aplicații împreună pentru a crea seturi de date etichetate de înaltă calitate. Pentru cazul nostru de utilizare exemplu, lucrăm cu Set de date Fashion200K, lansat la ICCV 2017.
Prezentare generală a soluțiilor
Ground Truth este un serviciu de etichetare a datelor complet autoservit și gestionat, care dă putere oamenilor de știință ai datelor, inginerilor de învățare automată (ML) și cercetătorilor să construiască seturi de date de înaltă calitate. Cincizeci si unu by voxel51 este un set de instrumente open-source pentru curatarea, vizualizarea și evaluarea seturilor de date de viziune computerizată, astfel încât să puteți antrena și analiza modele mai bune prin accelerarea cazurilor de utilizare.
În următoarele secțiuni, demonstrăm cum să faceți următoarele:
- Vizualizați setul de date în FiftyOne
- Curățați setul de date cu filtrare și deduplicare a imaginii în FiftyOne
- Preetichetați datele curățate cu clasificarea zero-shot în FiftyOne
- Etichetați setul de date mai mic cu Ground Truth
- Injectați rezultatele etichetate din Ground Truth în FiftyOne și examinați rezultatele etichetate în FiftyOne
Prezentare generală a cazului de utilizare
Să presupunem că dețineți o companie de retail și doriți să construiți o aplicație mobilă pentru a oferi recomandări personalizate pentru a ajuta utilizatorii să decidă ce să poarte. Utilizatorii dvs. potențiali caută o aplicație care să le spună ce articole vestimentare din dulapul lor funcționează bine împreună. Vedeți o oportunitate aici: dacă puteți identifica ținute bune, puteți folosi aceasta pentru a recomanda articole vestimentare noi care completează îmbrăcămintea pe care o deține deja un client.
Vrei să faci lucrurile cât mai ușor posibil pentru utilizatorul final. În mod ideal, cineva care folosește aplicația dvs. trebuie doar să facă poze cu hainele din garderoba, iar modelele dvs. ML își fac magia în culise. Puteți antrena un model de uz general sau puteți ajusta un model la stilul unic al fiecărui utilizator cu o anumită formă de feedback.
În primul rând, totuși, trebuie să identificați ce tip de îmbrăcăminte captează utilizatorul. Este o cămașă? O pereche de pantaloni? Sau altceva? La urma urmei, probabil că nu vrei să recomanzi o ținută care are mai multe rochii sau mai multe pălării.
Pentru a face față acestei provocări inițiale, doriți să generați un set de date de antrenament format din imagini ale diferitelor articole de îmbrăcăminte cu diverse modele și stiluri. Pentru a crea prototipuri cu un buget limitat, doriți să porniți folosind un set de date existent.
Pentru a ilustra și a vă ghida prin procesul din această postare, folosim setul de date Fashion200K lansat la ICCV 2017. Este un set de date consacrat și bine citat, dar nu este potrivit direct pentru cazul dvs. de utilizare.
Deși articolele de îmbrăcăminte sunt etichetate cu categorii (și subcategorii) și conțin o varietate de etichete utile care sunt extrase din descrierile originale ale produselor, datele nu sunt etichetate sistematic cu informații despre model sau stil. Scopul dvs. este să transformați acest set de date existent într-un set de date robust de antrenament pentru modelele dvs. de clasificare a îmbrăcămintei. Trebuie să curățați datele, mărind schema de etichetare cu etichete de stil. Și vrei să faci asta rapid și cu cât mai puține cheltuieli.
Descărcați datele local
Mai întâi, descărcați fișierul zip women.tar și folderul etichete (cu toate subfolderele sale) urmând instrucțiunile furnizate în Setul de date Fashion200K depozit GitHub. După ce le-ați dezarhivat pe amândouă, creați un director părinte fashion200k și mutați etichetele și folderele femei în acesta. Din fericire, aceste imagini au fost deja decupate în casetele de delimitare de detecție a obiectelor, așa că ne putem concentra pe clasificare, mai degrabă decât să ne îngrijorăm cu privire la detectarea obiectelor.
În ciuda numelui „200K” din numele său, directorul de femei pe care l-am extras conține 338,339 de imagini. Pentru a genera setul de date oficial Fashion200K, autorii setului de date au accesat cu crawlere mai mult de 300,000 de produse online, iar numai produsele cu descrieri care conțin mai mult de patru cuvinte au făcut diferența. Pentru scopurile noastre, unde descrierea produsului nu este esențială, putem folosi toate imaginile accesate cu crawlere.
Să ne uităm la modul în care sunt organizate aceste date: în dosarul femei, imaginile sunt aranjate după tipul de articol de nivel superior (fuste, topuri, pantaloni, jachete și rochii) și subcategoria tip articol (bluze, tricouri, mâneci lungi). vârfuri).
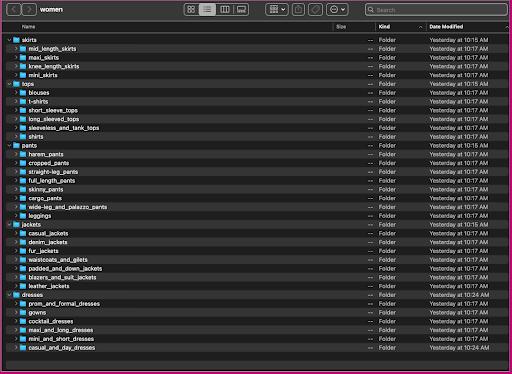
În directoarele subcategorii, există un subdirector pentru fiecare listă de produse. Fiecare dintre acestea conține un număr variabil de imagini. Subcategoria cropped_pants, de exemplu, conține următoarele liste de produse și imagini asociate.

Dosarul etichete conține un fișier text pentru fiecare tip de articol de nivel superior, atât pentru secțiunile de tren, cât și pentru cele de testare. În fiecare dintre aceste fișiere text există o linie separată pentru fiecare imagine, specificând calea relativă a fișierului, un scor și etichete din descrierea produsului.

Deoarece reutilizam setul de date, combinăm toate imaginile de tren și de testare. Le folosim pentru a genera un set de date de înaltă calitate, specific aplicației. După ce încheiem acest proces, putem împărți aleatoriu setul de date rezultat în noi secțiuni de tren și de testare.
Injectați, vizualizați și gestionați un set de date în FiftyOne
Dacă nu ați făcut deja acest lucru, instalați FiftyOne cu sursă deschisă folosind pip:
O bună practică este să faceți acest lucru într-un nou mediu virtual (venv sau conda). Apoi importați modulele relevante. Importați biblioteca de bază, fiftyone, FiftyOne Brain, care are încorporate metode ML, FiftyOne Zoo, din care vom încărca un model care va genera etichete zero-shot pentru noi și ViewField, care ne permite să filtram eficient datele din setul nostru de date:
De asemenea, doriți să importați modulele glob și os Python, ceea ce ne va ajuta să lucrăm cu căi și potrivirea modelelor asupra conținutului directorului:
Acum suntem gata să încărcăm setul de date în FiftyOne. În primul rând, creăm un set de date numit fashion200k și îl facem persistent, ceea ce ne permite să salvăm rezultatele operațiilor intensive din punct de vedere computațional, așa că trebuie să calculăm cantitățile respective o singură dată.
Acum putem itera toate directoarele de subcategorii, adăugând toate imaginile din directoarele de produse. Adăugăm o etichetă de clasificare FiftyOne la fiecare eșantion cu numele câmpului tip_articol, populat de categoria de articol de nivel superior a imaginii. De asemenea, adăugăm informații despre categorii și subcategorii ca etichete:
În acest moment, ne putem vizualiza setul de date în aplicația FiftyOne lansând o sesiune:

De asemenea, putem tipări un rezumat al setului de date în Python rulând print(dataset):
Putem adăuga și etichetele din labels director la mostrele din setul nostru de date:
Privind datele, câteva lucruri devin clare:
- Unele imagini sunt destul de granulate, cu rezoluție scăzută. Acest lucru se datorează probabil că aceste imagini au fost generate prin tăierea imaginilor inițiale în casetele de delimitare de detecție a obiectelor.
- Unele haine sunt purtate de o persoană, iar altele sunt fotografiate pe cont propriu. Aceste detalii sunt încapsulate de
viewpointproprietate. - Multe dintre imaginile aceluiași produs sunt foarte asemănătoare, așa că cel puțin inițial, includerea mai multor imagini pe produs poate să nu adauge prea multă putere de predicție. În cea mai mare parte, prima imagine a fiecărui produs (se termină în
_0.jpeg) este cel mai curat.
Inițial, ar putea dori să ne antrenăm modelul de clasificare a stilului de îmbrăcăminte pe un subset controlat al acestor imagini. În acest scop, folosim imagini de înaltă rezoluție ale produselor noastre și ne limităm vizualizarea la un eșantion reprezentativ per produs.
În primul rând, filtrăm imaginile cu rezoluție scăzută. Noi folosim compute_metadata() metodă de a calcula și stoca lățimea și înălțimea imaginii, în pixeli, pentru fiecare imagine din setul de date. Apoi folosim FiftyOne ViewField pentru a filtra imaginile pe baza valorilor minime permise pentru lățimea și înălțimea. Vezi următorul cod:

Acest subset de înaltă rezoluție are puțin sub 200,000 de mostre.
Din această vizualizare, putem crea o nouă vizualizare în setul nostru de date care să conțină un singur eșantion reprezentativ (cel mult) pentru fiecare produs. Noi folosim ViewField încă o dată, potrivirea modelului pentru căile de fișiere care se termină cu _0.jpeg:
Să vedem o ordine aleatorie a imaginilor din acest subset:

Eliminați imaginile redundante din setul de date
Această vizualizare conține 66,297 de imagini sau puțin peste 19% din setul de date original. Când ne uităm la vedere, totuși, vedem că există multe produse foarte asemănătoare. Păstrarea tuturor acestor copii nu va face decât să adauge costuri pentru formarea noastră de etichetare și model, fără a îmbunătăți semnificativ performanța. În schimb, să scăpăm de aproape duplicatele pentru a crea un set de date mai mic, care încă are același punct.
Deoarece aceste imagini nu sunt duplicate exacte, nu putem verifica egalitatea pixelilor. Din fericire, putem folosi FiftyOne Brain pentru a ne ajuta să ne curățăm setul de date. În special, vom calcula o încorporare pentru fiecare imagine - un vector de dimensiuni inferioare reprezentând imaginea - și apoi vom căuta imagini ai căror vectori de încorporare sunt aproape unul de celălalt. Cu cât vectorii sunt mai apropiați, cu atât imaginile sunt mai asemănătoare.
Folosim un model CLIP pentru a genera un vector de încorporare cu 512 dimensiuni pentru fiecare imagine și pentru a stoca aceste înglobări în câmpurile încorporate pe mostrele din setul nostru de date:
Apoi calculăm apropierea dintre înglobări, folosind asemănarea cosinusului, și afirmă că oricare doi vectori a căror similitudine este mai mare decât un anumit prag este probabil să fie aproape duplicate. Scorurile de similaritate cosinus se află în intervalul [0, 1] și, privind datele, un scor de prag de prag=0.5 pare să fie aproximativ corect. Din nou, acest lucru nu trebuie să fie perfect. Câteva imagini aproape duplicate nu ar putea să ne distrugă puterea de predicție, iar aruncarea câtorva imagini neduplicate nu are un impact semnificativ asupra performanței modelului.
Putem vizualiza presupusele duplicate pentru a verifica dacă sunt într-adevăr redundante:

Când suntem mulțumiți de rezultat și credem că aceste imagini sunt într-adevăr aproape duplicate, putem alege câte o probă din fiecare set de mostre similare pe care să le păstrăm și să le ignorăm pe celelalte:
Acum această vizualizare are 3,729 de imagini. Prin curățarea datelor și identificarea unui subset de înaltă calitate al setului de date Fashion200K, FiftyOne ne permite să ne limităm concentrarea de la peste 300,000 de imagini la puțin sub 4,000, reprezentând o reducere cu 98%. Folosirea înglobărilor pentru a elimina imagini aproape duplicate a redus numărul total de imagini luate în considerare cu mai mult de 90%, cu un efect redus, sau chiar deloc, asupra oricăror modele care urmează să fie instruite pe aceste date.
Înainte de a pre-eticheta acest subset, putem înțelege mai bine datele prin vizualizarea înglobărilor pe care le-am calculat deja. Putem folosi sistemul încorporat al FiftyOne Brain compute_visualization(), care utilizează tehnica de aproximare uniformă a varietății (UMAP) pentru a proiecta vectorii de încorporare de 512 dimensionale în spațiul bidimensional, astfel încât să îi putem vizualiza:
Deschidem un nou Panoul de încorporare în aplicația FiftyOne și colorare după tipul de articol și putem vedea că aceste înglobări codifică aproximativ o noțiune de tip de articol (printre altele!).

Acum suntem gata să pre-etichetăm aceste date.
Inspectând aceste imagini extrem de unice, de înaltă rezoluție, putem genera o listă inițială decentă de stiluri de utilizat ca clase în clasificarea noastră pre-etichetare zero-shot. Scopul nostru în pre-etichetarea acestor imagini nu este neapărat să etichetăm corect fiecare imagine. Mai degrabă, scopul nostru este de a oferi un bun punct de plecare pentru adnotatorii umani, astfel încât să putem reduce timpul și costurile de etichetare.
Apoi putem instanția un model de clasificare zero-shot pentru această aplicație. Folosim un model CLIP, care este un model de uz general antrenat atât pe imagini, cât și pe limbaj natural. Instanțiem un model CLIP cu mesajul text „Îmbrăcăminte în stil”, astfel încât, având în vedere o imagine, modelul va scoate clasa pentru care „Îmbrăcăminte în stil [clasa]” este cea mai potrivită. CLIP nu este instruit cu privire la retail sau date specifice modei, așa că acest lucru nu va fi perfect, dar vă poate economisi costurile de etichetare și adnotare.
Apoi aplicăm acest model subsetului nostru redus și stocăm rezultatele într-un article_style camp:
Lansând aplicația FiftyOne încă o dată, putem vizualiza imaginile cu aceste etichete de stil prezise. Sortăm după gradul de încredere al predicțiilor, astfel încât să vedem mai întâi cele mai sigure predicții de stil:

Putem vedea că cele mai înalte predicții de încredere par să fie pentru stilurile „tricou”, „animal print”, „buline” și „literare”. Acest lucru are sens, deoarece aceste stiluri sunt relativ distincte. De asemenea, se pare că, în cea mai mare parte, etichetele de stil prezise sunt corecte.
De asemenea, ne putem uita la predicțiile stilului cu cea mai scăzută încredere:

Pentru unele dintre aceste imagini, categoria de stil adecvată se află în lista furnizată, iar articolul de îmbrăcăminte este etichetat incorect. Prima imagine din grilă, de exemplu, ar trebui să fie în mod clar „camuflaj” și nu „chevron”. În alte cazuri, însă, produsele nu se încadrează perfect în categoriile de stil. Rochia din a doua imagine din al doilea rând, de exemplu, nu este tocmai „în dungi”, dar având în vedere aceleași opțiuni de etichetare, un adnotator uman ar fi putut fi, de asemenea, în conflict. Pe măsură ce ne construim setul de date, trebuie să decidem dacă să eliminăm cazuri de margine ca acestea, să adăugăm noi categorii de stil sau să mărim setul de date.
Exportați setul de date final din FiftyOne
Exportați setul de date final cu următorul cod:
Putem exporta un set de date mai mic, de exemplu, 16 imagini, în folder 200kFashionDatasetExportResult-16Images. Creăm un job de ajustare Ground Truth folosindu-l:
Încărcați setul de date revizuit, convertiți formatul etichetei în Ground Truth, încărcați în Amazon S3 și creați un fișier manifest pentru jobul de ajustare
Putem converti etichetele din setul de date pentru a se potrivi cu schema manifest de ieșire dintr-o lucrare de delimitare Ground Truth și încărcați imaginile într-un Serviciul Amazon de stocare simplă (Amazon S3) găleată pentru a lansa a Lucrare de ajustare a Adevărului la sol:
Încărcați fișierul manifest pe Amazon S3 cu următorul cod:
Creați etichete cu stil corectat cu Ground Truth
Pentru a vă adnota datele cu etichete de stil folosind Ground Truth, parcurgeți pașii necesari pentru a începe o lucrare de etichetare a casetei de delimitare urmând procedura prezentată în Începeți cu Ground Truth ghid cu setul de date în același bucket S3.
- Pe consola SageMaker, creați o lucrare de etichetare Ground Truth.
- Seteaza Introduceți locația setului de date să fie manifestul pe care l-am creat în etapele precedente.

- Specificați o cale S3 pentru Locația setului de date de ieșire.
- Pentru Rolul IAM, alege Introduceți un rol IAM personalizat ARN, apoi introduceți rolul ARN.

- Pentru Categoria de sarcini, alege Imagine și selectați Casetă de încadrare.
- Alege Pagina Următoare →.
- În Muncitorii secțiunea, alegeți tipul de forță de muncă pe care doriți să o utilizați.
Puteți selecta o forță de muncă prin intermediul Amazon Mechanical Turk, furnizori terți sau forța de muncă privată. Pentru mai multe detalii despre opțiunile pentru forța de muncă, consultați Creați și gestionați forța de muncă. - Extinde Opțiuni de afișare a etichetelor existente și selectați Doresc să afișez etichetele existente din setul de date pentru acest job.
- Pentru Atribut de etichetă nume, alegeți numele din manifest care corespunde etichetelor pe care doriți să le afișați pentru ajustare.
Veți vedea numai numele atributelor de etichetă pentru etichetele care se potrivesc cu tipul de activitate pe care l-ați selectat la pașii anteriori. - Introduceți manual etichetele pentru Instrument de etichetare a casetei de delimitare.
 Etichetele trebuie să conțină aceleași etichete utilizate în setul de date public. Puteți adăuga etichete noi. Următoarea captură de ecran arată cum puteți alege lucrătorii și configura instrumentul pentru munca dvs. de etichetare.
Etichetele trebuie să conțină aceleași etichete utilizate în setul de date public. Puteți adăuga etichete noi. Următoarea captură de ecran arată cum puteți alege lucrătorii și configura instrumentul pentru munca dvs. de etichetare.
- Alege Anunţ pentru a previzualiza imaginea și adnotările originale.
Acum am creat un job de etichetare în Ground Truth. După ce munca noastră este finalizată, putem încărca datele etichetate nou generate în FiftyOne. Ground Truth produce date de ieșire într-un manifest de ieșire Ground Truth. Pentru mai multe detalii despre fișierul manifest de ieșire, consultați Ieșire lucrare cu casetă de delimitare. Următorul cod arată un exemplu al acestui format manifest de ieșire:
Examinați rezultatele etichetate din Ground Truth în FiftyOne
După ce lucrarea este finalizată, descărcați manifestul de ieșire al jobului de etichetare de pe Amazon S3.

Citiți fișierul manifest de ieșire:
Creați un set de date FiftyOne și convertiți liniile manifest în mostre din setul de date:
Acum puteți vedea date etichetate de înaltă calitate de la Ground Truth în FiftyOne.

Concluzie
În această postare, am arătat cum să construim seturi de date de înaltă calitate combinând puterea Cincizeci si unu by voxel51, un set de instrumente open-source care vă permite să gestionați, să urmăriți, să vizualizați și să vă gestionați setul de date și Ground Truth, un serviciu de etichetare a datelor care vă permite să etichetați eficient și precis seturile de date necesare pentru antrenarea sistemelor ML, oferind acces la mai multe -în șabloane de sarcini și acces la o forță de muncă diversă prin Mechanical Turk, furnizori terți sau propria forță de muncă privată.
Vă încurajăm să încercați această nouă funcționalitate instalând o instanță FiftyOne și folosind consola Ground Truth pentru a începe. Pentru a afla mai multe despre Ground Truth, consultați Date de etichetă, Întrebări frecvente privind etichetarea datelor Amazon SageMaker, Şi Blog de AWS Machine Learning.
Conectați-vă cu Învățare automată și comunitate AI dacă aveți întrebări sau feedback!
Alăturați-vă comunității FiftyOne!
Alăturați-vă miilor de ingineri și cercetători care folosesc deja FiftyOne pentru a rezolva unele dintre cele mai dificile probleme din viziunea computerizată astăzi!
Despre Autori
Shalendra Chhabra este în prezent șeful de management al produselor pentru Amazon SageMaker Human-in-the-Loop (HIL) Services. Anterior, Shalendra a incubat și a condus Inteligența lingvistică și conversațională pentru întâlnirile Microsoft Teams, a fost EIR la Amazon Alexa Techstars Startup Accelerator, VP Product and Marketing la Discută.io, Head of Product and Marketing la Clipboard (achizitionat de Salesforce) si Lead Product Manager la Swype (achizitionat de Nuance). În total, Shalendra a contribuit la construirea, livrarea și comercializarea produselor care au afectat mai mult de un miliard de vieți.
Jacob Marks este inginer de învățare automată și evanghelist pentru dezvoltatori la Voxel51, unde ajută la aducerea transparenței și clarității datelor din lume. Înainte de a se alătura Voxel51, Jacob a fondat un startup pentru a ajuta muzicienii emergenti să se conecteze și să partajeze conținut creativ cu fanii. Înainte de asta, a lucrat la Google X, Samsung Research și Wolfram Research. Într-o viață trecută, Jacob a fost un fizician teoretician, și-a finalizat doctoratul la Stanford, unde a investigat fazele cuantice ale materiei. În timpul liber, lui Jacob îi place să urce, să alerge și să citească romane științifico-fantastice.
Jason Corso este co-fondator și CEO al Voxel51, unde conduce strategia pentru a contribui la aducerea transparenței și clarității datelor din lume prin software-ul flexibil de ultimă generație. De asemenea, este profesor de robotică, inginerie electrică și informatică la Universitatea din Michigan, unde se concentrează asupra problemelor de ultimă oră la intersecția dintre viziunea computerizată, limbajul natural și platformele fizice. În timpul liber, lui Jason îi place să petreacă timpul cu familia sa, să citească, să fie în natură, să joace jocuri de societate și tot felul de activități creative.
Brian Moore este co-fondator și CTO al Voxel51, unde conduce strategia și viziunea tehnică. El deține un doctorat în Inginerie Electrică de la Universitatea din Michigan, unde cercetarea sa s-a concentrat pe algoritmi eficienți pentru probleme de învățare automată la scară largă, cu un accent deosebit pe aplicațiile de viziune computerizată. În timpul liber, îi place badminton, golf, drumeții și joacă cu gemenii săi Yorkshire Terriers.
Zhuling Bai este inginer de dezvoltare software la Amazon Web Services. Ea lucrează la dezvoltarea de sisteme distribuite la scară largă pentru a rezolva problemele de învățare automată.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- PlatoAiStream. Web3 Data Intelligence. Cunoștințe amplificate. Accesați Aici.
- Mintând viitorul cu Adryenn Ashley. Accesați Aici.
- Cumpărați și vindeți acțiuni în companii PRE-IPO cu PREIPO®. Accesați Aici.
- Sursa: https://aws.amazon.com/blogs/machine-learning/create-high-quality-datasets-with-amazon-sagemaker-ground-truth-and-fiftyone/
- :are
- :este
- :nu
- :Unde
- $UP
- 000
- 1
- 10
- 11
- 110
- 13
- 14
- 20
- 200
- 2017
- 23
- 24
- 250
- 28
- 30
- 500
- 66
- 7
- 8
- 9
- a
- Despre Noi
- accelera
- accelerarea
- accelerator
- acces
- precis
- precis
- dobândite
- activităţi de
- adăuga
- adăugare
- adresa
- Ajustat
- Ajustare
- După
- din nou
- AI
- Alexa
- algoritmi
- TOATE
- permite
- singur
- deja
- de asemenea
- Amazon
- amazon alexa
- Amazon SageMaker
- Amazon SageMaker Ground Adevăr
- Amazon Web Services
- printre
- an
- analiza
- și
- animal
- Orice
- aplicaţia
- aplicație
- aplicatii
- Aplică
- adecvat
- SUNT
- amenajat
- articol
- bunuri
- AS
- asociate
- At
- Autorii
- departe
- AWS
- de bază
- bazat
- BE
- deoarece
- deveni
- fost
- înainte
- în spatele
- în spatele scenelor
- fiind
- Crede
- CEL MAI BUN
- Mai bine
- între
- Miliard
- bord
- Consiliul de Jocuri
- OS
- Bootstrap
- atât
- Cutie
- Dulapuri
- Creier
- Pauză
- aduce
- adus
- buget
- construi
- Clădire
- construit-in
- dar
- cumpăra
- by
- CAN
- capturarea
- caz
- cazuri
- categorii
- Categorii
- CEO
- contesta
- provocare
- verifica
- Alege
- claritate
- clasă
- clase
- clasificare
- Curățenie
- clar
- clar
- client
- Alpinism
- Închide
- mai aproape
- haine
- Îmbrăcăminte
- Co-fondator
- cod
- combina
- combinând
- companie
- Completa
- Completă
- completarea
- Calcula
- calculator
- Informatică
- Computer Vision
- Aplicații de viziune pe computer
- încredere
- încrezător
- Conectați
- considerare
- Constând
- Consoleze
- conține
- conţinut
- conținut
- controlată
- de conversaţie
- converti
- Nucleu
- corectat
- corect
- corespunde
- A costat
- Cheltuieli
- crea
- a creat
- Creator
- scrisori de acreditare
- CTO
- curator
- curatoriale
- În prezent
- personalizat
- client
- clienţii care
- Tăiat
- ultima generație
- de date
- seturi de date
- decide
- demonstra
- dril
- adâncime
- descriere
- detalii
- Detectare
- Dezvoltator
- în curs de dezvoltare
- Dezvoltare
- diferit
- direct
- directoare
- Afişa
- distinct
- distribuite
- sisteme distribuite
- diferit
- do
- Nu
- Câine
- face
- făcut
- Dont
- DOT
- jos
- Descarca
- duplicate
- e
- fiecare
- uşor
- Margine
- efect
- eficient
- eficient
- Inginerie Electrică
- Încorporarea
- șmirghel
- accent
- angajează
- imputerniceste
- încapsulată
- încuraja
- capăt
- inginer
- Inginerie
- inginerii
- Intrați
- Mediu inconjurator
- egalitate
- esenţial
- stabilit
- Eter (ETH)
- evaluarea
- evanghelist
- exact
- exemplu
- existent
- exporturile
- destul de
- familie
- fani
- feedback-ul
- puțini
- Ficţiune
- camp
- Domenii
- Fișier
- Fişiere
- filtru
- filtrare
- final
- First
- potrivi
- flexibil
- Concentra
- concentrat
- se concentrează
- următor
- Pentru
- formă
- format
- din fericire
- Fondat
- patru
- Gratuit
- din
- complet
- funcționalitate
- Jocuri
- scop general
- genera
- generată
- obține
- GitHub
- Da
- dat
- scop
- golf
- bine
- mai mare
- Grilă
- Teren
- grup
- ghida
- fericit
- Avea
- he
- cap
- înălțime
- ajutor
- a ajutat
- util
- ajută
- aici
- de înaltă calitate
- Rezoluție înaltă
- cea mai mare
- extrem de
- drumeții
- lui
- deține
- Cum
- Cum Pentru a
- Totuși
- HTML
- http
- HTTPS
- uman
- i
- IAM
- ID
- identifica
- identificarea
- ID-uri
- if
- imagine
- imagini
- Impactul
- import
- îmbunătățirea
- in
- În altele
- Inclusiv
- în mod incorect
- incubate
- informații
- inițială
- inițial
- instala
- Instalarea
- instanță
- in schimb
- instrucțiuni
- Inteligență
- intersecție
- în
- IT
- ESTE
- jerseu
- Loc de munca
- aderarea
- comun
- JSON
- doar
- A pastra
- păstrare
- Etichetă
- etichetarea
- etichete
- limbă
- pe scară largă
- lansa
- lansare
- conduce
- Conduce
- AFLAȚI
- învăţare
- cel mai puțin
- Led
- stânga
- Permite
- Bibliotecă
- Viaţă
- ca
- Probabil
- LIMITĂ
- Limitat
- Linie
- linii
- Listă
- listare
- înregistrări
- mic
- Locuiește
- încărca
- Uite
- cautati
- Lot
- Jos
- maşină
- masina de învățare
- făcut
- magie
- face
- FACE
- administra
- gestionate
- administrare
- manager
- multe
- Hartă
- Piață
- Marketing
- Meci
- potrivire
- material
- materie
- Mai..
- mecanic
- Mass-media
- reuniuni
- meta
- Metadata
- metodă
- Metode
- Michigan
- Microsoft
- echipe de microsoft
- ar putea
- minim
- ML
- Mobil
- Aplicatie mobila
- model
- Modele
- Module
- mai mult
- cele mai multe
- muta
- mult
- multiplu
- muzicieni
- trebuie sa
- nume
- Numit
- nume
- Natural
- Limbajul natural
- Natură
- În apropiere
- în mod necesar
- necesar
- Nevoie
- nevoilor
- Nou
- vizibil
- noțiune
- acum
- Nuanță
- număr
- obiect
- Detectarea obiectelor
- obiecte
- of
- oficial
- on
- dată
- ONE
- on-line
- afară
- deschide
- open-source
- Operațiuni
- Oportunitate
- Opţiuni
- or
- Organizat
- original
- OS
- Altele
- Altele
- al nostru
- afară
- a subliniat
- producție
- peste
- propriu
- deține
- Pachete
- împerecheat
- parte
- special
- trecut
- cale
- Model
- modele
- Perfect
- performanță
- persoană
- Personalizat
- Etapele materiei
- fizic
- alege
- poze
- tartan
- Simplu
- Platforme
- Plato
- Informații despre date Platon
- PlatoData
- joc
- Punct
- populat
- posibil
- Post
- putere
- practică
- a prezis
- prezicere
- Predictii
- Anunţ
- precedent
- în prealabil
- anterior
- privat
- probabil
- probleme
- proces
- Produs
- management de produs
- manager de produs
- Produse
- Profesor
- proiect
- proprietate
- viitor
- prototip
- furniza
- prevăzut
- furnizarea
- public
- pumn
- scopuri
- Piton
- Cuantic
- Întrebări
- repede
- gamă
- mai degraba
- Citind
- gata
- recomanda
- Recomandări
- reduce
- Redus
- reducere
- relativ
- eliberat
- scoate
- reprezentant
- reprezentând
- necesar
- cercetare
- cercetători
- Rezoluţie
- restrânge
- rezultat
- rezultând
- REZULTATE
- cu amănuntul
- reveni
- revizuiască
- Scăpa
- dreapta
- robotica
- robust
- Rol
- aproximativ
- RÂND
- ruina
- funcţionare
- sagemaker
- Said
- Salesforce
- acelaşi
- Samsung
- Economisiți
- scene
- Ştiinţă
- Romane științifico-fantastice
- oamenii de stiinta
- scor
- perfect
- Al doilea
- Secțiune
- secțiuni
- vedea
- părea
- pare
- selectate
- sens
- distinct
- serviciu
- Servicii
- sesiune
- set
- Distribuie
- ea
- să
- Arăta
- Emisiuni
- DA
- asemănător
- simplu
- mai mici
- So
- Software
- de dezvoltare de software
- REZOLVAREA
- unele
- Cineva
- ceva
- Spaţiu
- petrece
- Cheltuire
- împărţi
- șpalturi
- stanford
- Începe
- început
- Pornire
- lansare
- accelerator de pornire
- de ultimă oră
- paşi
- Încă
- depozitare
- stoca
- Strategie
- stil
- REZUMAT
- Suportat
- sigur
- sisteme
- Lua
- Sarcină
- echipe
- Tehnic
- TechStars
- spune
- şabloane
- test
- decât
- acea
- lor
- Lor
- apoi
- teoretic
- Acolo.
- Acestea
- ei
- lucruri
- Crede
- terț
- acest
- mii
- prag
- Prin
- Aruncare
- timp
- la
- împreună
- instrument
- Toolkit
- top
- nivel superior
- Bluze
- Total
- atins
- urmări
- Tren
- dresat
- Pregătire
- Transforma
- Transparență
- adevărat
- Adevăr
- ÎNTORCĂ
- Două
- tip
- Tipuri
- în
- înţelege
- unic
- universitate
- Universitatea din Michigan
- Actualizează
- us
- utilizare
- carcasa de utilizare
- utilizat
- Utilizator
- utilizatorii
- folosind
- Valori
- varietate
- diverse
- furnizori
- verifica
- foarte
- de
- Vizualizare
- Virtual
- viziune
- imagina
- vrea
- a fost
- we
- web
- servicii web
- BINE
- au fost
- Ce
- cand
- dacă
- care
- Wikipedia
- voi
- cu
- în
- fără
- Femei
- cuvinte
- Apartamente
- a lucrat
- muncitorii
- Forta de munca
- fabrică
- lume
- face griji
- ar
- scrie
- X
- tu
- Ta
- zephyrnet
- Zip
- GRĂDINĂ ZOOLOGICĂ