Amazon Comprehend este un serviciu de procesare a limbajului natural (NLP) care utilizează învățarea automată (ML) pentru a descoperi informații din text. Fiind un serviciu complet gestionat, Amazon Comprehend nu necesită experiență ML și poate scala la volume mari de date. Amazon Comprehend oferă mai multe API-uri pentru a integra cu ușurință NLP în aplicațiile dvs. Puteți apela pur și simplu API-urile din aplicația dvs. și furnizați locația documentului sursă sau a textului. API-urile produc entități, fraze cheie, sentiment, clasificare a documentelor și limba într-un format ușor de utilizat pentru aplicația sau afacerea dvs.
API-urile de analiză a sentimentelor furnizate de Amazon Comprehend ajută companiile să determine sentimentul unui document. Puteți evalua sentimentul general al unui document ca fiind pozitiv, negativ, neutru sau mixt. Cu toate acestea, pentru a obține gradul de înțelegere a sentimentului asociat cu anumite produse sau mărci, companiile au fost nevoite să utilizeze soluții cum ar fi fragmentarea textului în blocuri logice și deducerea sentimentului exprimat față de un anumit produs.
Pentru a simplifica acest proces, începând de astăzi, Amazon Comprehend lansează Sentiment vizat caracteristică pentru analiza sentimentelor. Aceasta oferă capacitatea de a identifica grupuri de mențiuni (grupuri de coreferință) care corespund unei singure entități sau atribute din lumea reală, de a furniza sentimentul asociat cu fiecare mențiune de entitate și de a oferi clasificarea entității din lumea reală pe baza unui listă predeterminată de entități.
Această postare oferă o privire de ansamblu asupra modului în care puteți începe cu sentimentul vizat de Amazon Comprehend, demonstrează ce puteți face cu rezultatul și trece prin trei cazuri de utilizare a sentimentelor vizate obișnuite.
Prezentare generală a soluțiilor
Următorul este un exemplu de sentiment țintit:

„Spa” este entitatea principală, identificată ca tip facility, și este menționat încă de două ori, denumit pronume „it”. API-ul Targeted Sentiment oferă sentimentul față de fiecare entitate. Sentimentul pozitiv este verde, negativ este roșu și neutru este albastru. De asemenea, putem determina cum se schimbă sentimentul față de spa pe parcursul propoziției. Ne aprofundăm în API mai târziu în postare.
Această capacitate deschide mai multe capacități diferite pentru companii. Echipele de marketing pot urmări sentimentele populare față de mărcile lor în rețelele sociale de-a lungul timpului. Comercianții de comerț electronic pot înțelege ce atribute specifice ale produselor lor au fost cel mai bine și cel mai prost primite de clienți. Operatorii de call center pot folosi funcția pentru a extrage transcrierile pentru probleme de escaladare și pentru a monitoriza experiența clienților. Restaurantele, hotelurile și alte organizații din industria ospitalității pot folosi serviciul pentru a transforma categorii ample de evaluări în descrieri bogate ale experiențelor bune și rele ale clienților.
Cazuri de utilizare a sentimentelor vizate
API-ul Targeted Sentiment din Amazon Comprehend preia date text, cum ar fi postările pe rețelele sociale, recenziile aplicațiilor și transcripțiile centrului de apeluri. Apoi analizează intrarea folosind puterea algoritmilor NLP pentru a extrage automat sentimentul la nivel de entitate. Un entitate este o referire textuală la numele unic al unui obiect din lumea reală, cum ar fi oameni, locuri și articole comerciale, pe lângă referințe precise la măsuri precum datele și cantitățile. Pentru o listă completă a entităților acceptate, consultați Entități sentimentale vizate.
Folosim API-ul Targeted Sentiment pentru a activa următoarele cazuri de utilizare:
- O afacere poate identifica părți ale experienței angajat/client care sunt plăcute și părți care pot fi îmbunătățite.
- Centrele de contact și echipele de asistență pentru clienți pot analiza transcripțiile la apel sau jurnalele de chat pentru a identifica eficiența instruirii agenților și detaliile conversației, cum ar fi reacțiile specifice ale unui client și frazele sau cuvintele care au fost folosite pentru a illicita acel răspuns.
- Proprietarii de produse și dezvoltatorii UI/UX pot identifica caracteristicile produsului lor de care se bucură utilizatorii și părțile care necesită îmbunătățiri. Acest lucru poate sprijini discuțiile despre foile de parcurs și prioritizările produselor.
Următoarea diagramă ilustrează procesul de sentiment vizat:

În această postare, demonstrăm acest proces folosind următoarele trei exemple de recenzii:
- Eșantionul 1: evaluarea afacerii și a produsului – „Îmi place foarte mult cât de groasă este jacheta. Port un sacou mare pentru ca am umerii lati si asta am comandat si se potriveste perfect acolo. Aproape că simt că iese din piept în jos. M-am gândit să folosesc șirurile din partea de jos a jachetei pentru a o ajuta să o închid și să o aduc înăuntru, dar acestea nu funcționează. Jacheta se simte foarte voluminoasă.”
- Exemplul 2: transcrierea centrului de contact – „Bună ziua, există un blocaj de fraudă pe cardul meu de credit, îl puteți elimina pentru mine. Cardul meu de credit continuă să fie semnalat pentru fraudă. Este destul de enervant, de fiecare dată când merg să-l folosesc, tot fiu refuzat. Voi anula cardul dacă acest lucru se întâmplă din nou.”
- Eșantionul 3: Sondaj de feedback de la angajator – „Mă bucur că managementul îmbunătățește echipa. Dar instructorul nu a trecut bine peste elementele de bază. Managementul ar trebui să depună mai multă diligență cu privire la nivelul de calificare al fiecăruia pentru sesiunile viitoare.”
Pregătiți datele
Pentru a începe, descărcați fișierele de exemplu care conțin textul exemplu folosind Interfața liniei de comandă AWS (AWS CLI) rulând următoarele comenzi:
Creați o Serviciul Amazon de stocare simplă (Amazon S3), dezarhivați folderul și încărcați folderul care conține cele trei fișiere eșantion. Asigurați-vă că utilizați aceeași regiune pe tot parcursul.

Acum puteți accesa cele trei fișiere text eșantion din compartimentul S3.

Creați un loc de muncă în Amazon Comprehend
După ce încărcați fișierele în compartimentul S3, parcurgeți următorii pași:
- În consola Amazon Comprehend, alegeți Joburi de analiză în panoul de navigare.

- Alege Creați loc de muncă.

- Pentru Nume si Prenume, introduceți un nume pentru jobul dvs.
- Pentru Tipul analizei, alege Sentiment țintit.
- În Date de intrare, introduceți locația Amazon S3 a ts-sample-date dosar.
- Pentru formatul de intrare, alege Un document pe dosar.
Puteți modifica această configurație dacă datele dvs. sunt într-un singur fișier delimitat de linii.

- În Locația de ieșire, introduceți locația Amazon S3 în care doriți să salvați rezultatul lucrării.
- În Permisii de acces, Pentru Rolul IAM, alegeți unul existent Gestionarea identității și accesului AWS (IAM) sau creați unul care are permisiuni pentru compartimentul S3.
- Lăsați celelalte opțiuni ca implicite și alegeți Creați loc de muncă.

După ce începeți jobul, vă puteți revizui detaliile jobului. Durata totală de rulare a jobului depinde de dimensiunea datelor de intrare.

- Când lucrarea este finalizată, sub producție, alegeți legătura către locația datelor de ieșire.

Aici puteți găsi un fișier de ieșire comprimat.
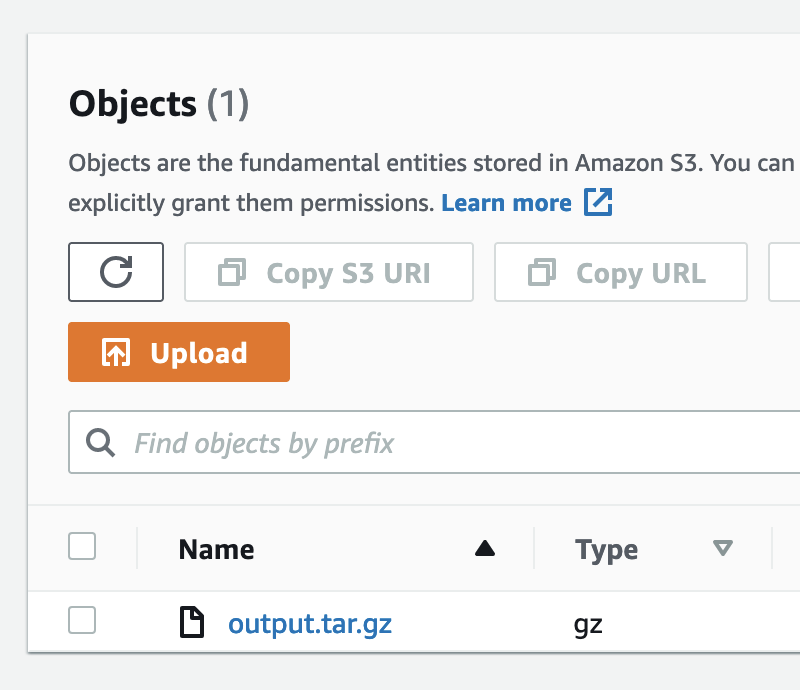
- Descărcați și decomprimați fișierul.
Acum puteți inspecta fișierele de ieșire pentru fiecare exemplu de text. Deschideți fișierele în editorul de text preferat pentru a examina structura răspunsului API. Descriem acest lucru mai detaliat în secțiunea următoare.

Structura de răspuns API
API-ul Targeted Sentiment oferă o modalitate simplă de a consuma rezultatul joburilor dvs. Oferă o grupare logică a entităților (grupuri de entități) detectate, împreună cu sentimentul pentru fiecare entitate. Următoarele sunt câteva definiții ale câmpurilor care sunt în răspuns:
- entități – Părțile semnificative ale documentului. De exemplu,
Person,Place,Date,Food, SauTaste. - Mențiuni – Referințele sau mențiunile entității din document. Acestea pot fi pronume sau substantive comune precum „el”, „el”, „carte” și așa mai departe. Acestea sunt organizate în ordinea locației (offset) în document.
- DescriptiveMentionIndex – Indexul în
Mentionscare oferă cea mai bună descriere a grupului de entități. De exemplu, „ABC Hotel” în loc de „hotel”, „it” sau alte mențiuni substantive comune. - GroupScore – Încrederea că toate entitățile menționate în grup sunt legate de aceeași entitate (cum ar fi „eu”, „eu” și „eu însumi” referindu-se la o singură persoană).
- Text – Textul din documentul care descrie entitatea
- Tip – O descriere a ceea ce descrie entitatea.
- Scor – Încrederea modelului că aceasta este o entitate relevantă.
- Menționați Sentimentul – Sentimentul real găsit pentru mențiune.
- Sentiment – Valoarea șirului de
positive,neutral,negative, Saumixed. - SentimentScore – Încrederea modelului pentru fiecare sentiment posibil.
- BeginOffset – Deplasarea în textul documentului unde începe mențiunea.
- EndOffset – Deplasarea în textul documentului unde se termină mențiunea.
Pentru a demonstra acest lucru vizual, să luăm rezultatul celui de-al treilea caz de utilizare, sondajul de feedback al angajatorului, și să trecem prin grupurile de entități care reprezintă angajatul care completează sondajul, conducerea și instructorul.

Să ne uităm mai întâi la toate mențiunile grupului de entități de coreferință asociate cu „Eu” (angajatul care scrie răspunsul) și locația mențiunii în text. DescriptiveMentionIndex reprezintă indici ai mențiunilor entității care descriu cel mai bine grupul de entități de coreferință (în acest caz I):
Următorul grup de entități furnizează toate mențiunile grupului de entități de coreferință asociat cu managementul, împreună cu locația acestuia în text. DescriptiveMentionIndex reprezintă indici ai mențiunilor entității care descriu cel mai bine grupul de entități de coreferință (în acest caz management). Ceva de observat în acest exemplu este schimbarea sentimentului către management. Puteți utiliza aceste date pentru a deduce ce părți ale acțiunilor conducerii au fost percepute ca pozitive și ce părți au fost percepute ca negative și, prin urmare, pot fi îmbunătățite.
Pentru a încheia, să observăm toate mențiunile instructorului și locația din text. DescriptiveMentionIndex reprezintă indici ai mențiunilor entității care descriu cel mai bine grupul de entități de coreferință (în acest caz instructor):
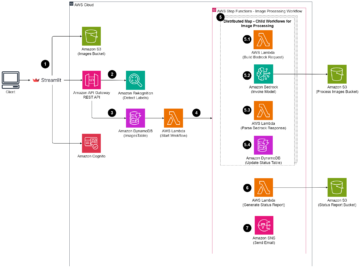
Arhitectura de referinta
Puteți aplica sentimente direcționate în multe scenarii și cazuri de utilizare pentru a genera valoare pentru afaceri, cum ar fi următoarele:
- Determinați eficacitatea campaniilor de marketing și a lansărilor de caracteristici prin detectarea entităților și mențiunilor care conțin cel mai bun feedback pozitiv sau negativ
- Ieșire de interogare pentru a determina ce entități și mențiuni se referă la o entitate corespunzătoare (pozitive, negative sau neutre)
- Analizați sentimentul de-a lungul ciclului de viață al interacțiunii cu clienții în centrele de contact pentru a demonstra eficacitatea schimbărilor procesului sau a instruirii
Următoarea diagramă ilustrează un proces de la capăt la capăt:

Concluzie
Înțelegerea interacțiunilor și feedback-ului pe care organizațiile le primesc de la clienți cu privire la produsele și serviciile lor rămâne crucială în dezvoltarea unor produse și experiențe mai bune pentru clienți. Ca atare, sunt necesare detalii mai detaliate pentru a deduce rezultate mai bune.
În această postare, am oferit câteva exemple despre cum utilizarea acestor detalii granulare poate ajuta organizațiile să îmbunătățească produsele, experiențele clienților și instruirea, stimulând și validând, de asemenea, atributele pozitive. Există multe cazuri de utilizare în industrii în care puteți experimenta și câștiga valoare din sentimentul vizat.
Vă încurajăm să încercați această nouă funcție cu cazurile dvs. de utilizare. Pentru mai multe informații și pentru a începe, consultați Sentiment vizat.
Despre Autori
 Raj Pathak este arhitect de soluții și consilier tehnic pentru clienții Fortune 50 și Mid-Size FSI (bancare, asigurări, piețe de capital) din Canada și Statele Unite. Raj este specializat în învățare automată cu aplicații în extragerea documentelor, transformarea centrului de contact și viziunea computerizată.
Raj Pathak este arhitect de soluții și consilier tehnic pentru clienții Fortune 50 și Mid-Size FSI (bancare, asigurări, piețe de capital) din Canada și Statele Unite. Raj este specializat în învățare automată cu aplicații în extragerea documentelor, transformarea centrului de contact și viziunea computerizată.
 Sanjeev Pulapaka este arhitect senior de soluții în echipa US Fed Civilian SA la Amazon Web Services (AWS). El lucrează îndeaproape cu clienții în construirea și arhitectura de soluții critice pentru misiune. Sanjeev are o experiență vastă în conducerea, arhitectura și implementarea de soluții tehnologice de mare impact care abordează diverse nevoi de afaceri în mai multe sectoare, inclusiv guvernele comerciale, federale, de stat și locale. Are o diplomă de licență în inginerie de la Institutul Indian de Tehnologie și un MBA de la Universitatea Notre Dame.
Sanjeev Pulapaka este arhitect senior de soluții în echipa US Fed Civilian SA la Amazon Web Services (AWS). El lucrează îndeaproape cu clienții în construirea și arhitectura de soluții critice pentru misiune. Sanjeev are o experiență vastă în conducerea, arhitectura și implementarea de soluții tehnologice de mare impact care abordează diverse nevoi de afaceri în mai multe sectoare, inclusiv guvernele comerciale, federale, de stat și locale. Are o diplomă de licență în inginerie de la Institutul Indian de Tehnologie și un MBA de la Universitatea Notre Dame.
- Coinsmart. Cel mai bun schimb de Bitcoin și Crypto din Europa.
- Platoblockchain. Web3 Metaverse Intelligence. Cunoștințe amplificate. ACCES LIBER.
- CryptoHawk. Radar Altcoin. Încercare gratuită.
- Sursa: https://aws.amazon.com/blogs/machine-learning/extract-granular-sentiment-in-text-with-amazon-comprehend-targeted-sentiment/
- "
- 100
- 11
- 7
- 9
- Despre Noi
- acces
- peste
- acțiuni
- adresa
- consilier
- algoritmi
- TOATE
- Amazon
- Amazon Web Services
- analiză
- api
- API-uri
- aplicație
- aplicatii
- AWS
- Bancar
- Noțiuni de bază
- CEL MAI BUN
- Bloca
- frontieră
- marci
- Clădire
- afaceri
- întreprinderi
- apel
- Campanii
- Poate obține
- Canada
- capacități
- capital
- Piețele de capital
- cazuri
- Schimbare
- clasificare
- comercial
- Comun
- încredere
- Configuraţie
- Consoleze
- consuma
- Conversație
- credit
- card de credit
- crucial
- experienta clientului
- Serviciu clienți
- clienţii care
- de date
- Date
- Mai adânc
- detaliu
- detectat
- Dezvoltatorii
- în curs de dezvoltare
- FĂCUT
- diferit
- diligență
- jos
- cu ușurință
- E-commerce
- editor
- încuraja
- se încheie
- Inginerie
- exemplu
- experienţă
- Experiențe
- experiment
- expertiză
- Caracteristică
- DESCRIERE
- fed-
- federal
- feedback-ul
- Domenii
- First
- În primul rând
- următor
- format
- găsit
- fraudă
- Complet
- viitor
- obtinerea
- merge
- bine
- guvernele
- Verde
- grup
- ajutor
- Cum
- HTTPS
- identifica
- Identitate
- îmbunătăţi
- Inclusiv
- index
- industrii
- industrie
- informații
- perspective
- asigurare
- integra
- interacţiune
- probleme de
- IT
- Loc de munca
- Locuri de munca
- Cheie
- limbă
- mare
- lansează
- lansare
- conducere
- învăţare
- Nivel
- Linie
- LINK
- Listă
- local
- locaţie
- maşină
- masina de învățare
- administrare
- Marketing
- pieţe
- Mass-media
- menționează
- comercianţi
- Misiune
- mixt
- ML
- model
- cele mai multe
- Natural
- Navigare
- compensa
- deschide
- deschide
- Opţiuni
- comandă
- organizație
- organizații
- Altele
- Proprietarii
- oameni
- Expresii
- Popular
- posibil
- postări
- putere
- primar
- proces
- Produs
- Produse
- furniza
- furnizează
- evaluări
- Reacții
- a primi
- reprezintă
- necesita
- necesar
- răspuns
- restaurante
- revizuiască
- Recenzii
- foaie de parcurs
- funcţionare
- Scară
- sectoare
- sentiment
- serviciu
- Servicii
- schimbare
- semnificativ
- simplu
- Mărimea
- So
- Social
- social media
- soluţii
- ceva
- specializată
- Începe
- început
- Stat
- Statele
- depozitare
- a sustine
- Suportat
- Sondaj de opinie
- echipă
- Tehnic
- Tehnologia
- Noțiuni de bază
- Sursa
- Prin
- de-a lungul
- timp
- astăzi
- urmări
- Pregătire
- Transformare
- ne
- înţelege
- unic
- Unit
- Statele Unite
- universitate
- utilizare
- utilizatorii
- valoare
- viziune
- web
- servicii web
- Ce
- cuvinte
- Apartamente
- fabrică
- scris