Această postare pe blog este scrisă împreună cu Chaoyang He și Salman Avestimehr de la FedML.
Analiza datelor din lumea reală a sănătății și științelor vieții (HCLS) ridică mai multe provocări practice, cum ar fi silozurile de date distribuite, lipsa datelor suficiente la un singur site pentru evenimente rare, liniile directoare de reglementare care interzic partajarea datelor, cerințele de infrastructură și costurile suportate pentru crearea. un depozit de date centralizat. Deoarece se află într-un domeniu foarte reglementat, partenerii și clienții HCLS caută mecanisme de păstrare a confidențialității pentru a gestiona și analiza date la scară largă, distribuite și sensibile.
Pentru a atenua aceste provocări, propunem un cadru de învățare federalizat (FL), bazat pe FedML open-source pe AWS, care permite analizarea datelor sensibile HCLS. Aceasta implică antrenarea unui model global de învățare automată (ML) din date de sănătate distribuite deținute local în diferite site-uri. Nu necesită mutarea sau partajarea datelor între site-uri sau cu un server centralizat în timpul procesului de formare a modelului.
Implementarea unui cadru FL pe cloud are mai multe provocări. Automatizarea infrastructurii client-server pentru a suporta mai multe conturi sau cloud-uri private virtuale (VPC-uri) necesită peering-ul VPC și o comunicare eficientă între VPC-uri și instanțe. Într-o sarcină de lucru de producție, este nevoie de o conductă de implementare stabilă pentru a adăuga și elimina fără probleme clienți și pentru a le actualiza configurațiile fără prea multe cheltuieli. În plus, într-o configurație eterogenă, clienții pot avea cerințe diferite pentru calcul, rețea și stocare. În această arhitectură descentralizată, erorile de înregistrare și depanare între clienți pot fi dificile. În cele din urmă, determinarea abordării optime pentru agregarea parametrilor modelului, menținerea performanței modelului, asigurarea confidențialității datelor și îmbunătățirea eficienței comunicării este o sarcină grea. În această postare, abordăm aceste provocări oferind un șablon de operațiuni de învățare federate (FLOps) care găzduiește o soluție HCLS. Soluția este agnostică pentru cazurile de utilizare, ceea ce înseamnă că o puteți adapta pentru cazurile dvs. de utilizare schimbând modelul și datele.
În această serie în două părți, demonstrăm cum puteți implementa un cadru FL bazat pe cloud pe AWS. În prima postare, am descris concepte FL și cadrul FedML. În această a doua parte, prezentăm o dovadă a conceptului în domeniul sănătății și al științelor vieții dintr-un set de date din lumea reală eICU. Acest set de date cuprinde o bază de date de îngrijiri critice multicentre, colectată de la peste 200 de spitale, ceea ce o face ideală pentru a testa experimentele noastre FL.
Caz de utilizare HCLS
În scopul demonstrației, am construit un model FL pe un set de date disponibil public pentru a gestiona pacienții în stare critică. Noi am folosit Baza de date de cercetare colaborativă eICU, o bază de date multi-centre de unități de terapie intensivă (ICU), care cuprinde 200,859 de întâlniri de unități de pacienți pentru 139,367 de pacienți unici. Ei au fost internați într-una dintre cele 335 de unități din 208 spitale situate în SUA în perioada 2014-2015. Datorită eterogenității subiacente și naturii distribuite a datelor, oferă un exemplu ideal în lumea reală pentru a testa acest cadru FL. Setul de date include măsurători de laborator, semne vitale, informații despre planul de îngrijire, medicamente, istoricul pacientului, diagnostic de admitere, diagnostice marcate în timp dintr-o listă structurată de probleme și tratamente alese în mod similar. Este disponibil ca un set de fișiere CSV, care pot fi încărcate în orice sistem de baze de date relaționale. Tabelele sunt de-identificate pentru a îndeplini cerințele de reglementare Actul SUA privind portabilitatea și responsabilitatea asigurărilor de sănătate (HIPAA). Datele pot fi accesate printr-un depozit PhysioNet, iar detaliile procesului de acces la date pot fi găsite aici [1].
Datele eICU sunt ideale pentru dezvoltarea algoritmilor ML, instrumente de sprijinire a deciziilor și pentru avansarea cercetării clinice. Pentru analiza de referință, am luat în considerare sarcina de a prezice mortalitatea în spital a pacienților [2]. Am definit-o ca o sarcină de clasificare binară, în care fiecare eșantion de date se întinde pe o fereastră de 1 oră. Pentru a crea o cohortă pentru această sarcină, am selectat pacienți cu un statut de externare în fișa pacientului și o durată de ședere de cel puțin 48 de ore, deoarece ne concentrăm pe predicția mortalității în primele 24 și 48 de ore. Acest lucru a creat o cohortă de 30,680 de pacienți care conținea 1,164,966 de înregistrări. Am adoptat preprocesarea datelor specifice domeniului și metode descrise în [3] pentru predicția mortalității. Acest lucru a dus la un set de date agregat care cuprinde mai multe coloane per pacient per înregistrare, așa cum se arată în figura următoare. Următorul tabel oferă o înregistrare a pacientului într-o interfață în stil tabelar cu timpul în coloane (5 intervale peste 48 de ore) și observațiile semnelor vitale pe rânduri. Fiecare rând reprezintă o variabilă fiziologică, iar fiecare coloană reprezintă valoarea acesteia înregistrată pe o fereastră de timp de 48 de ore pentru un pacient.
| Parametrul fiziologic | Chart_Time_0 | Chart_Time_1 | Chart_Time_2 | Chart_Time_3 | Chart_Time_4 |
| Glasgow Coma Score Ochi | 4 | 4 | 4 | 4 | 4 |
| FiO2 | 15 | 15 | 15 | 15 | 15 |
| Glasgow Coma Score Ochi | 15 | 15 | 15 | 15 | 15 |
| Ritmul cardiac | 101 | 100 | 98 | 99 | 94 |
| TA invazivă diastolică | 73 | 68 | 60 | 64 | 61 |
| TA invazivă sistolică | 124 | 122 | 111 | 105 | 116 |
| Tensiunea arterială medie (mmHg) | 77 | 77 | 77 | 77 | 77 |
| Glasgow Coma Score Motor | 6 | 6 | 6 | 6 | 6 |
| 02 Saturație | 97 | 97 | 97 | 97 | 97 |
| Viteza respiratorie | 19 | 19 | 19 | 19 | 19 |
| Temperatura (C) | 36 | 36 | 36 | 36 | 36 |
| Glasgow Coma Score verbal | 5 | 5 | 5 | 5 | 5 |
| înălțimea admiterii | 162 | 162 | 162 | 162 | 162 |
| greutate de admitere | 96 | 96 | 96 | 96 | 96 |
| vârstă | 72 | 72 | 72 | 72 | 72 |
| apacheadmissiondx | 143 | 143 | 143 | 143 | 143 |
| etnie | 3 | 3 | 3 | 3 | 3 |
| sex | 1 | 1 | 1 | 1 | 1 |
| glucoză | 128 | 128 | 128 | 128 | 128 |
| spitaladmitoffset | -436 | -436 | -436 | -436 | -436 |
| starea de externare din spital | 0 | 0 | 0 | 0 | 0 |
| itemoffset | -6 | -1 | 0 | 1 | 2 |
| pH | 7 | 7 | 7 | 7 | 7 |
| pacientunitstayid | 2918620 | 2918620 | 2918620 | 2918620 | 2918620 |
| unitdischargeoffset | 1466 | 1466 | 1466 | 1466 | 1466 |
| starea de descărcare a unității | 0 | 0 | 0 | 0 | 0 |
Am folosit atât caracteristici numerice, cât și categoriale și am grupat toate înregistrările fiecărui pacient pentru a le aplatiza într-o serie de timp cu o singură înregistrare. Cele șapte caracteristici categoriale (diagnostic de admitere, etnie, gen, Glasgow Coma Score Total, Glasgow Coma Score Eyes, Glasgow Coma Score Motor și Glasgow Coma Score Verbal au fost convertite în vectori de codificare one-hot) au conținut 429 de valori unice și au fost convertite într-una singură. -inglobarile la cald. Pentru a preveni scurgerea datelor pe serverele nodurilor de antrenament, am împărțit datele după ID-urile spitalului și am păstrat toate înregistrările unui spital pe un singur nod.
Prezentare generală a soluțiilor
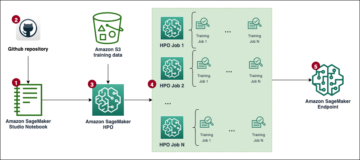
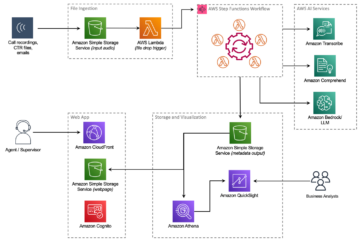
Următoarea diagramă arată arhitectura implementării FedML pe mai multe conturi pe AWS. Acesta include doi clienți (participantul A și participantul B) și un agregator model.
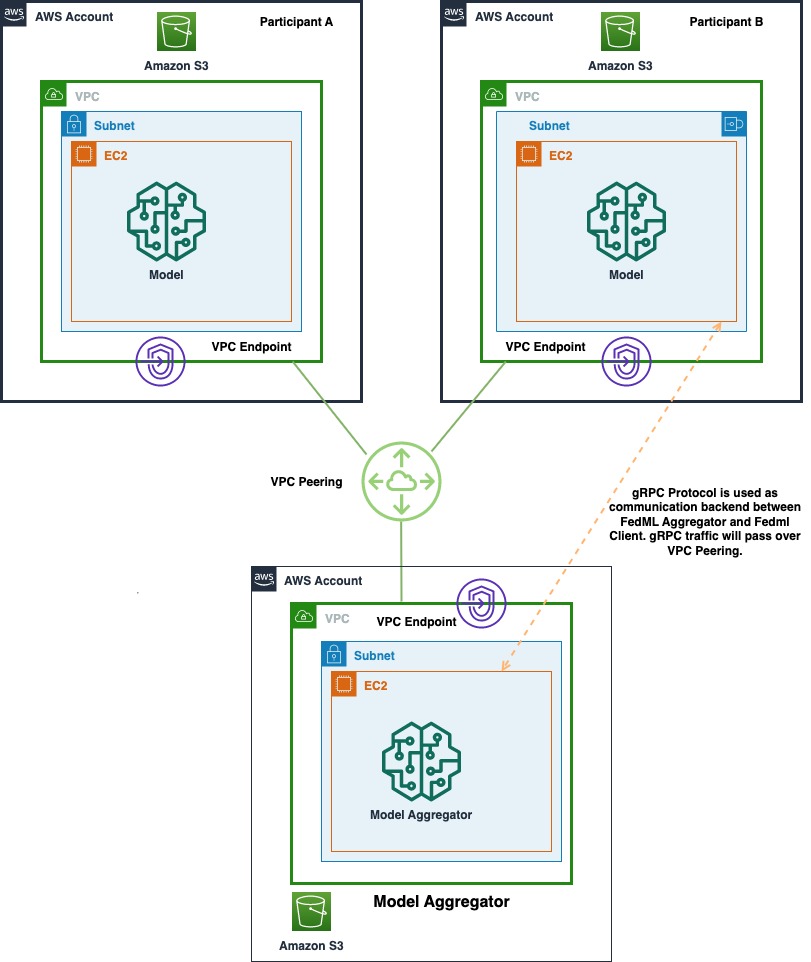
Arhitectura este formată din trei separate Cloud Elastic de calcul Amazon (Amazon EC2) instanțe care rulează în propriul cont AWS. Fiecare dintre primele două instanțe este deținută de un client, iar a treia instanță este deținută de agregatorul de modele. Conturile sunt conectate prin peering VPC pentru a permite schimbul de modele și ponderi ML între clienți și agregator. gRPC este folosit ca backend de comunicare pentru comunicarea dintre agregatorul de modele și clienți. Am testat o singură configurație de calcul distribuită bazată pe cont, cu un server și două noduri client. Fiecare dintre aceste instanțe a fost creată folosind o AMI personalizată Amazon EC2 cu dependențe FedML instalate conform Ghid de instalare FedML.ai.
Configurați peeringul VPC
După ce lansați cele trei instanțe în conturile lor AWS respective, stabiliți interogare VPC între conturi prin Cloud virtual virtual Amazon (Amazon VPC). Pentru a configura o conexiune de peering VPC, creați mai întâi o solicitare de conectare cu un alt VPC. Puteți solicita o conexiune de peering VPC cu un alt VPC din contul dvs. sau cu un VPC într-un alt cont AWS. Pentru a activa solicitarea, proprietarul VPC-ului trebuie să accepte solicitarea. În scopul acestei demonstrații, am configurat conexiunea de peering între VPC-uri din conturi diferite, dar în aceeași regiune. Pentru alte configurații de peering VPC, consultați Creați o conexiune de peering VPC.
Înainte de a începe, asigurați-vă că aveți numărul de cont AWS și ID-ul VPC al VPC-ului cu care să vă consultați.
Solicitați o conexiune de peering VPC
Pentru a crea conexiunea de peering VPC, parcurgeți următorii pași:
- Pe consola Amazon VPC, în panoul de navigare, alegeți Conexiuni peering.
- Alege Creați o conexiune de peering.
- Pentru Eticheta cu numele conexiunii de interogare, puteți, opțional, să vă denumiți conexiunea de peering VPC. Procedând astfel, se creează o etichetă cu o cheie a numelui și a unei valori pe care le specificați. Această etichetă este vizibilă numai pentru tine; proprietarul VPC-ului peer își poate crea propriile etichete pentru conexiunea de peering VPC.
- Pentru VPC (solicitant), alegeți VPC-ul din contul dvs. pentru a crea conexiunea de peering.
- Pentru Cont, alege Alt cont.
- Pentru Cont ID, introduceți ID-ul contului AWS al proprietarului VPC-ului acceptator.
- Pentru VPC (Acceptator), introduceți ID-ul VPC cu care să creați conexiunea de peering VPC.
- În caseta de dialog de confirmare, alegeți OK.
- Alege Creați o conexiune de peering.
Acceptați o conexiune de peering VPC
După cum sa menționat mai devreme, conexiunea de peering VPC trebuie să fie acceptată de proprietarul VPC-ului la care a fost trimisă cererea de conectare. Parcurgeți următorii pași pentru a accepta cererea de conectare de peering:
- Pe consola Amazon VPC, utilizați selectorul de regiune pentru a alege regiunea VPC-ului acceptator.
- În panoul de navigare, alegeți Conexiuni peering.
- Selectați conexiunea de peering VPC în așteptare (starea este
pending-acceptance), iar pe Acţiuni meniu, alegeți Acceptați cererea. - În caseta de dialog de confirmare, alegeți Da, Accept.
- În al doilea dialog de confirmare, alegeți Modifică-mi tabelele de rute acum pentru a merge direct la pagina tabelelor de rute sau alegeți Închide pentru a face asta mai târziu.
Actualizați tabelele de rute
Pentru a activa traficul IPv4 privat între instanțele din VPC-uri peered, adăugați o rută la tabelele de rute asociate cu subrețelele pentru ambele instanțe. Destinația rutei este blocul CIDR (sau porțiunea blocului CIDR) al VPC-ului peer, iar ținta este ID-ul conexiunii de peering VPC. Pentru mai multe informații, vezi Configurați tabele de rute.
Actualizați-vă grupurile de securitate pentru a face referire la grupuri VPC de la egal la egal
Actualizați regulile de intrare sau de ieșire pentru grupurile dvs. de securitate VPC pentru a face referire la grupurile de securitate din VPC-ul peered. Acest lucru permite traficului să circule între instanțele care sunt asociate cu grupul de securitate la care se face referire în VPC-ul peered. Pentru mai multe detalii despre configurarea grupurilor de securitate, consultați Actualizați-vă grupurile de securitate pentru a face referire la grupurile de securitate peer.
Configurați FedML
După ce rulați cele trei instanțe EC2, conectați-vă la fiecare dintre ele și efectuați următorii pași:
- Clonați Depozitul FedML.
- Furnizați date de topologie despre rețeaua dvs. în fișierul de configurare
grpc_ipconfig.csv.
Acest fișier poate fi găsit la FedML/fedml_experiments/distributed/fedavg în depozitul FedML. Fișierul include date despre server și clienți și maparea nodurilor lor desemnate, cum ar fi FL Server – Nodul 0, FL Client 1 – Nodul 1 și FL Client 2 – Nodul 2.
- Definiți fișierul de configurare de mapare GPU.
Acest fișier poate fi găsit la FedML/fedml_experiments/distributed/fedavg în depozitul FedML. Fișierul gpu_mapping.yaml constă în date de configurare pentru maparea serverului client la GPU-ul corespunzător, așa cum se arată în fragmentul următor.
După ce definiți aceste configurații, sunteți gata să rulați clienții. Rețineți că clienții trebuie să fie rulați înainte de a porni serverul. Înainte de a face asta, să setăm încărcătoarele de date pentru experimente.
Personalizați FedML pentru eICU
Pentru a personaliza depozitul FedML pentru setul de date eICU, faceți următoarele modificări la încărcătorul de date și date.
Date
Adăugați date în folderul de date prealocat, așa cum se arată în următoarea captură de ecran. Puteți plasa datele în orice folder la alegere, atâta timp cât calea este menționată în mod constant în scriptul de antrenament și are accesul activat. Pentru a urmări un scenariu HCLS din lumea reală, în care datele locale nu sunt partajate între site-uri, împărțiți și eșantionați datele, astfel încât să nu existe suprapunere a ID-urilor spitalelor între cei doi clienți. Acest lucru asigură că datele unui spital sunt găzduite pe propriul server. De asemenea, am aplicat aceeași constrângere pentru a împărți datele în seturi de tren/test în cadrul fiecărui client. Fiecare dintre seturile de tren/test de la clienți au avut un raport de 1:10 de etichete pozitive și negative, cu aproximativ 27,000 de eșantioane în curs de pregătire și 3,000 de mostre în testare. Tratăm dezechilibrul de date în antrenamentul modelului cu o funcție de pierdere ponderată.
Încărcător de date
Fiecare dintre clienții FedML încarcă datele și le convertește în tensori PyTorch pentru antrenament eficient pe GPU. Extindeți nomenclatura FedML existentă pentru a adăuga un folder pentru datele eICU în data_processing dosar.

Următorul fragment de cod încarcă datele din sursa de date. Preprocesează datele și returnează câte un articol prin intermediul __getitem__ Funcția.
Antrenarea modelelor ML cu un singur punct de date la un moment dat este plictisitoare și necesită timp. Instruirea modelului se face de obicei pe un lot de puncte de date la fiecare client. Pentru a implementa acest lucru, încărcătorul de date din data_loader.py scriptul convertește tablourile NumPy în tensori Torch, așa cum se arată în următorul fragment de cod. Rețineți că FedML oferă dataset.py și data_loader.py scripturi pentru date structurate și nestructurate pe care le puteți utiliza pentru modificări specifice datelor, ca în orice proiect PyTorch.
Importați încărcătorul de date în scriptul de antrenament
După ce creați încărcătorul de date, importați-l în codul FedML pentru formarea modelului ML. Ca orice alt set de date (de exemplu, CIFAR-10 și CIFAR-100), încărcați datele eICU în main_fedavg.py script în cale FedML/fedml_experiments/distributed/fedavg/. Aici, am folosit media federalizată (fedavg) funcţia de agregare. Puteți urma o metodă similară pentru a configura main fișier pentru orice altă funcție de agregare.
Apelăm funcția de încărcare a datelor pentru datele eICU cu următorul cod:
Definiți modelul
FedML acceptă câțiva algoritmi de învățare profundă ieșiți din fabricație pentru diferite tipuri de date, cum ar fi date tabelare, text, imagini, grafice și Internet of Things (IoT). Încărcați modelul specific pentru eICU cu dimensiunile de intrare și de ieșire definite pe baza setului de date. Pentru dezvoltarea acestei dovezi de concept, am folosit un model de regresie logistică pentru a antrena și a prezice rata mortalității pacienților cu configurații implicite. Următorul fragment de cod arată actualizările pe care le-am făcut la main_fedavg.py scenariu. Rețineți că puteți utiliza și modele personalizate PyTorch cu FedML și le puteți importa în main_fedavg.py script-ul.
Rulați și monitorizați instruirea FedML pe AWS
Următorul videoclip arată procesul de instruire în curs de inițializare la fiecare dintre clienți. După ce ambii clienți sunt listați pentru server, creați procesul de instruire a serverului care realizează agregarea federată a modelelor.
Pentru a configura serverul FL și clienții, parcurgeți următorii pași:
- Rulați Clientul 1 și Clientul 2.
Pentru a rula un client, introduceți următoarea comandă cu ID-ul nodului corespunzător. De exemplu, pentru a rula Clientul 1 cu ID-ul nodului 1, rulați din linia de comandă:
- După ce ambele instanțe client sunt pornite, porniți instanța de server folosind aceeași comandă și ID-ul nodului corespunzător conform configurației dvs. din
grpc_ipconfig.csv file. Puteți vedea greutățile modelului transmise serverului de la instanțele client.
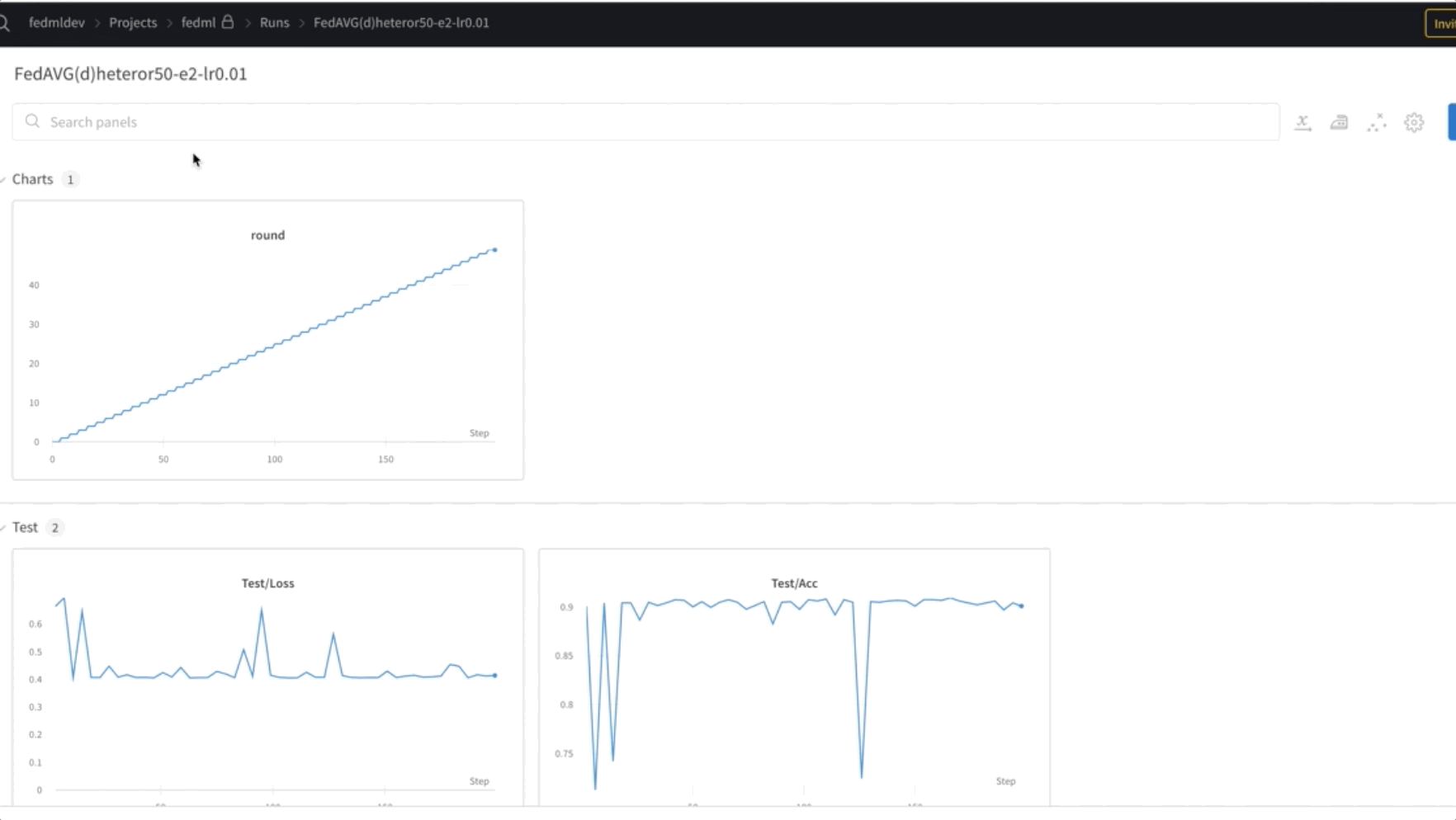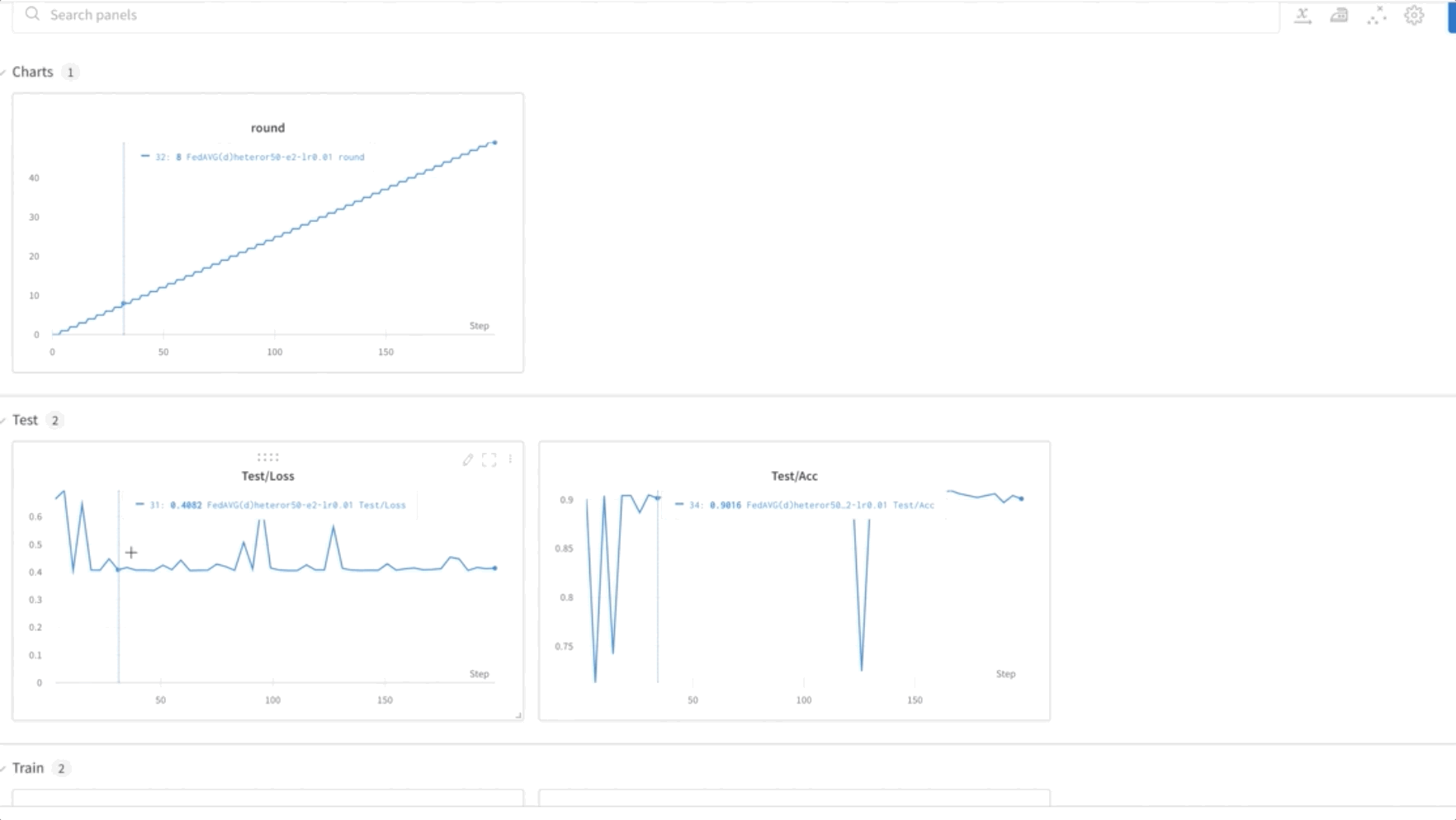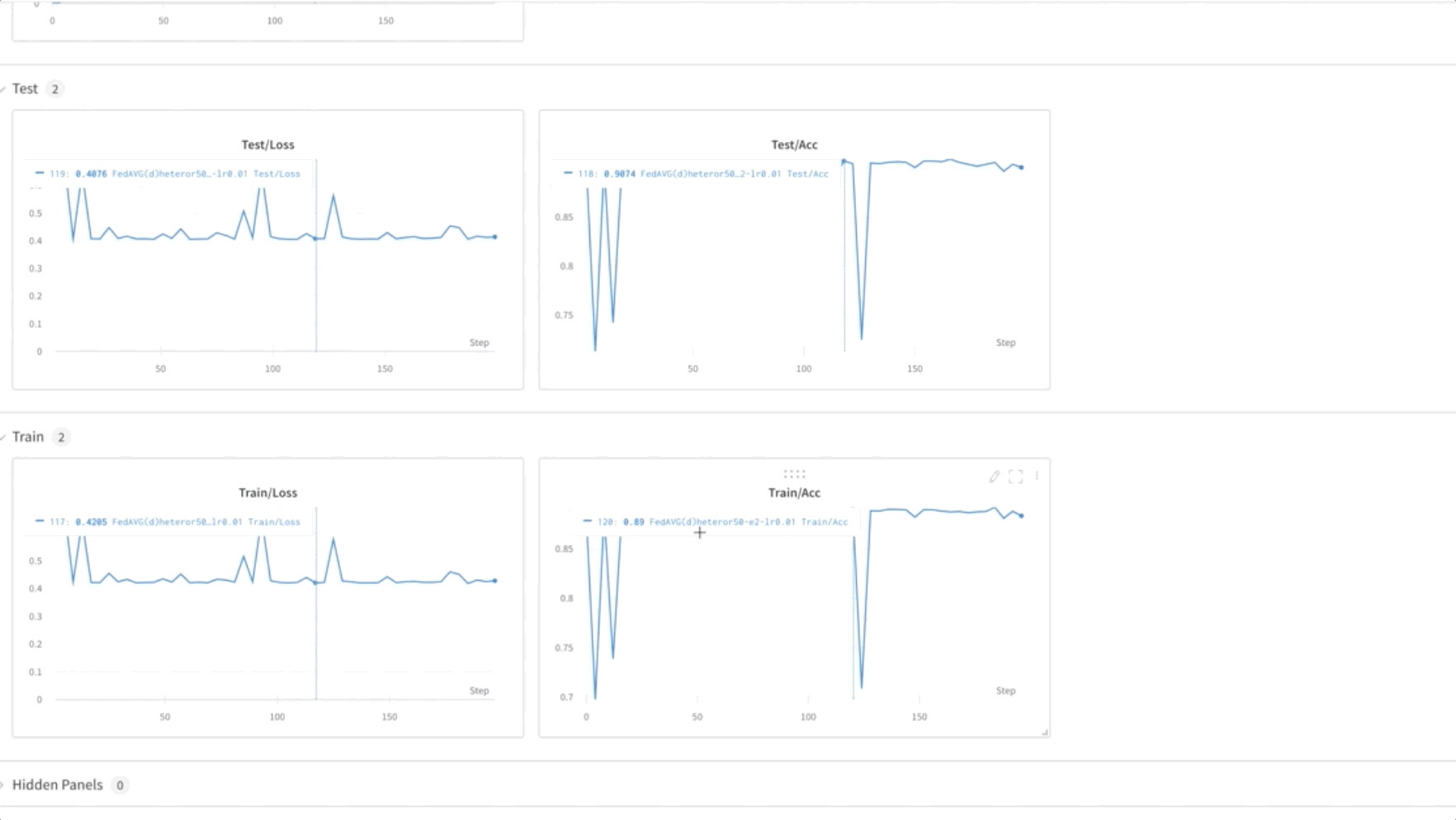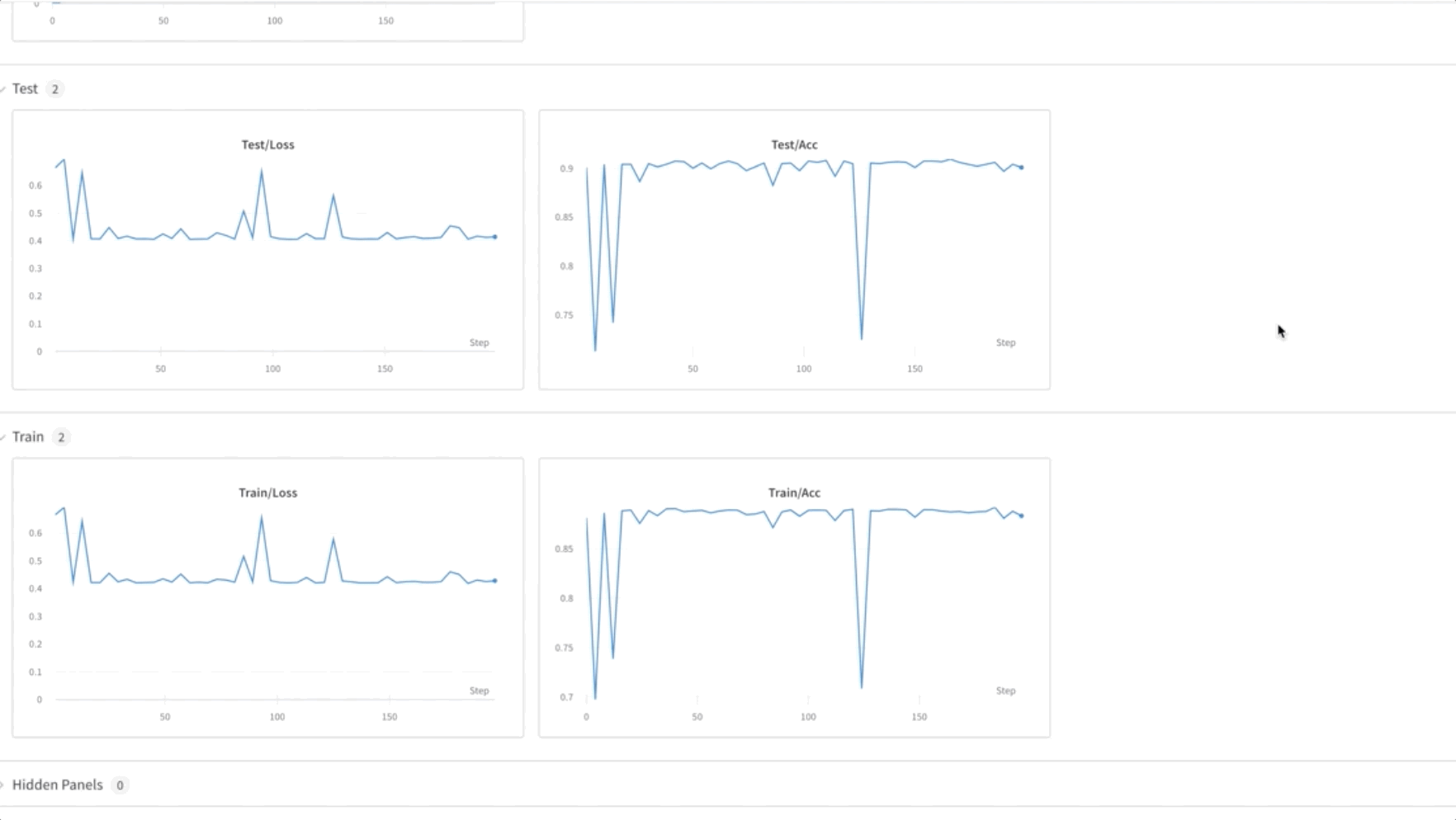
- Antrenăm model FL pentru 50 de epoci. După cum puteți vedea în videoclipul de mai jos, greutățile sunt transferate între nodurile 0, 1 și 2, indicând că antrenamentul progresează conform așteptărilor, într-o manieră federată.
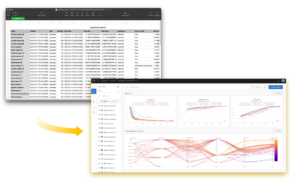
- În cele din urmă, monitorizați și urmăriți progresia antrenamentului modelului FL în diferite noduri din cluster folosind ponderi și părtiniri (wandb), așa cum se arată în următoarea captură de ecran. Vă rugăm să urmați pașii enumerați aici pentru a instala wandb și a configura monitorizarea pentru această soluție.
Următorul videoclip surprinde toți acești pași pentru a oferi o demonstrație completă a FL pe AWS folosind FedML:
Concluzie
În această postare, am arătat cum puteți implementa un cadru FL, bazat pe FedML open-source, pe AWS. Vă permite să antrenați un model ML pe date distribuite, fără a fi nevoie să îl partajați sau să îl mutați. Am creat o arhitectură cu mai multe conturi, în care, într-un scenariu real, spitalele sau organizațiile din domeniul sănătății se pot alătura ecosistemului pentru a beneficia de învățarea colaborativă, menținând în același timp guvernanța datelor. Am folosit setul de date eICU pentru mai multe spitale pentru a testa această implementare. Acest cadru poate fi aplicat și altor cazuri de utilizare și domenii. Vom continua să extindem această activitate prin automatizarea implementării prin infrastructură ca cod (folosind Formarea AWS Cloud), încorporând în continuare mecanisme de păstrare a vieții private și îmbunătățind interpretabilitatea și corectitudinea modelelor FL.
Vă rugăm să revizuiți prezentarea de la re:MARS 2022 axată pe „Învățare federată gestionată pe AWS: un studiu de caz pentru asistența medicală” pentru o prezentare detaliată a acestei soluții.
Referinţă
[1] Pollard, Tom J., et al. „Baza de date de cercetare colaborativă eICU, o bază de date multicentrică disponibilă gratuit pentru cercetarea în îngrijirea critică.” Date științifice 5.1 (2018): 1-13.
[2] Yin, X., Zhu, Y. și Hu, J., 2021. Un studiu cuprinzător al învățării federate care păstrează confidențialitatea: O taxonomie, revizuire și direcții viitoare. ACM Computing Surveys (CSUR), 54(6), pp.1-36.
[3] Sheikhalishahi, Seyedmostafa, Vevake Balaraman și Venet Osmani. „Evaluarea comparativă a modelelor de învățare automată pe setul de date multicentre de îngrijiri critice eICU.” Plus unu 15.7 (2020): e0235424.
Despre Autori
 Vidya Sagar Ravipati este Manager la Laboratorul Amazon ML Solutions, unde își folosește vasta experiență în sisteme distribuite pe scară largă și pasiunea sa pentru învățarea automată pentru a ajuta clienții AWS din diferite verticale ale industriei să-și accelereze adoptarea AI și cloud. Anterior, a fost inginer de învățare automată în servicii de conectivitate la Amazon, care a contribuit la construirea platformelor de personalizare și de întreținere predictivă.
Vidya Sagar Ravipati este Manager la Laboratorul Amazon ML Solutions, unde își folosește vasta experiență în sisteme distribuite pe scară largă și pasiunea sa pentru învățarea automată pentru a ajuta clienții AWS din diferite verticale ale industriei să-și accelereze adoptarea AI și cloud. Anterior, a fost inginer de învățare automată în servicii de conectivitate la Amazon, care a contribuit la construirea platformelor de personalizare și de întreținere predictivă.
 Olivia Choudhury, PhD, este Senior Partner Solutions Architect la AWS. Ea ajută partenerii din domeniul Sănătății și Științe ale Vieții să proiecteze, să dezvolte și să scaleze soluții de ultimă generație folosind AWS. Ea are experiență în genomică, analiză a asistenței medicale, învățarea federată și învățarea automată care păstrează confidențialitatea. În afara serviciului, joacă jocuri de societate, pictează peisaje și colecționează manga.
Olivia Choudhury, PhD, este Senior Partner Solutions Architect la AWS. Ea ajută partenerii din domeniul Sănătății și Științe ale Vieții să proiecteze, să dezvolte și să scaleze soluții de ultimă generație folosind AWS. Ea are experiență în genomică, analiză a asistenței medicale, învățarea federată și învățarea automată care păstrează confidențialitatea. În afara serviciului, joacă jocuri de societate, pictează peisaje și colecționează manga.
 Wajahat Aziz este arhitect principal de învățare automată și soluții HPC la AWS, unde se concentrează pe a ajuta clienții din domeniul sănătății și științelor vieții să utilizeze tehnologiile AWS pentru a dezvolta soluții ML și HPC de ultimă generație pentru o mare varietate de cazuri de utilizare, cum ar fi dezvoltarea de medicamente, Studii clinice și învățare automată pentru păstrarea confidențialității. În afara serviciului, lui Wajahat îi place să exploreze natura, drumețiile și lectura.
Wajahat Aziz este arhitect principal de învățare automată și soluții HPC la AWS, unde se concentrează pe a ajuta clienții din domeniul sănătății și științelor vieții să utilizeze tehnologiile AWS pentru a dezvolta soluții ML și HPC de ultimă generație pentru o mare varietate de cazuri de utilizare, cum ar fi dezvoltarea de medicamente, Studii clinice și învățare automată pentru păstrarea confidențialității. În afara serviciului, lui Wajahat îi place să exploreze natura, drumețiile și lectura.
 Divya Bhargavi este Data Scientist și Media and Entertainment Vertical Lead la Laboratorul Amazon ML Solutions, unde rezolvă probleme de afaceri de mare valoare pentru clienții AWS folosind Machine Learning. Lucrează pe înțelegerea imaginilor/video, sistemelor de recomandare cu grafice de cunoștințe, cazuri de utilizare a publicității predictive.
Divya Bhargavi este Data Scientist și Media and Entertainment Vertical Lead la Laboratorul Amazon ML Solutions, unde rezolvă probleme de afaceri de mare valoare pentru clienții AWS folosind Machine Learning. Lucrează pe înțelegerea imaginilor/video, sistemelor de recomandare cu grafice de cunoștințe, cazuri de utilizare a publicității predictive.
 Ujjwal Ratan este lider pentru AI/ML și Data Science în Unitatea de afaceri AWS Healthcare și Life Science și este, de asemenea, arhitect principal de soluții AI/ML. De-a lungul anilor, Ujjwal a fost un lider de gândire în industria sănătății și științelor vieții, ajutând mai multe organizații Global Fortune 500 să-și atingă obiectivele de inovare prin adoptarea învățării automate. Munca sa care implică analiza imaginilor medicale, a textului clinic nestructurat și a genomicului a ajutat AWS să construiască produse și servicii care oferă diagnosticare și terapie extrem de personalizate și țintite precis. În timpul liber, îi place să asculte (și să cânte) muzică și să facă excursii neplanificate cu familia.
Ujjwal Ratan este lider pentru AI/ML și Data Science în Unitatea de afaceri AWS Healthcare și Life Science și este, de asemenea, arhitect principal de soluții AI/ML. De-a lungul anilor, Ujjwal a fost un lider de gândire în industria sănătății și științelor vieții, ajutând mai multe organizații Global Fortune 500 să-și atingă obiectivele de inovare prin adoptarea învățării automate. Munca sa care implică analiza imaginilor medicale, a textului clinic nestructurat și a genomicului a ajutat AWS să construiască produse și servicii care oferă diagnosticare și terapie extrem de personalizate și țintite precis. În timpul liber, îi place să asculte (și să cânte) muzică și să facă excursii neplanificate cu familia.
 Chaoyang El este co-fondator și CTO al FedML, Inc., un startup care funcționează pentru o comunitate de IA deschisă și colaborativă de oriunde, la orice scară. Cercetarea sa se concentrează pe algoritmi, sisteme și aplicații de învățare automată distribuite/federate. Și-a luat doctoratul. în Informatică de la Universitatea din California de Sud, Los Angeles, SUA.
Chaoyang El este co-fondator și CTO al FedML, Inc., un startup care funcționează pentru o comunitate de IA deschisă și colaborativă de oriunde, la orice scară. Cercetarea sa se concentrează pe algoritmi, sisteme și aplicații de învățare automată distribuite/federate. Și-a luat doctoratul. în Informatică de la Universitatea din California de Sud, Los Angeles, SUA.
 Salman Avestimehr este co-fondator și CEO al FedML, Inc., un startup care funcționează pentru o comunitate de IA deschisă și colaborativă de oriunde, la orice scară. Salman Avestimehr este un expert de renume mondial în învățarea federată, cu peste 20 de ani de conducere în cercetare și dezvoltare atât în mediul academic, cât și în industrie. El este profesor decan și directorul inaugural al USC-Amazon Center on Trustworthy Machine Learning de la Universitatea din California de Sud. El a fost, de asemenea, un bursier Amazon în Amazon. El este un câștigător al premiului prezidențial al Statelor Unite pentru contribuțiile sale profunde în tehnologia informației și un membru al IEEE.
Salman Avestimehr este co-fondator și CEO al FedML, Inc., un startup care funcționează pentru o comunitate de IA deschisă și colaborativă de oriunde, la orice scară. Salman Avestimehr este un expert de renume mondial în învățarea federată, cu peste 20 de ani de conducere în cercetare și dezvoltare atât în mediul academic, cât și în industrie. El este profesor decan și directorul inaugural al USC-Amazon Center on Trustworthy Machine Learning de la Universitatea din California de Sud. El a fost, de asemenea, un bursier Amazon în Amazon. El este un câștigător al premiului prezidențial al Statelor Unite pentru contribuțiile sale profunde în tehnologia informației și un membru al IEEE.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- Platoblockchain. Web3 Metaverse Intelligence. Cunoștințe amplificate. Accesați Aici.
- Sursa: https://aws.amazon.com/blogs/machine-learning/part-2-federated-learning-on-aws-with-fedml-health-analytics-without-sharing-sensitive-data/
- 000
- 1
- 10
- 100
- ani 20
- 2018
- 2020
- 2021
- 2022
- 28
- 7
- 9
- a
- Despre Noi
- mai sus
- Academie
- accelera
- Accept
- acces
- accesate
- Cont
- responsabilitate
- Conturi
- Obține
- peste
- act
- adapta
- adresa
- admise
- adoptată
- Adoptarea
- Adoptare
- Promovare
- După
- agregare
- Agregator
- AI
- AI / ML
- algoritmi
- TOATE
- permite
- Amazon
- Amazon EC2
- analiză
- Google Analytics
- analiza
- analiza
- și
- Angeles
- O alta
- oriunde
- aplicatii
- aplicat
- abordare
- adecvat
- arhitectură
- asociate
- automatizarea
- disponibil
- acordare
- AWS
- Backend
- fundal
- bazat
- deoarece
- înainte
- fiind
- de mai jos
- Benchmark
- beneficia
- între
- Bloca
- Blog
- bord
- Consiliul de Jocuri
- Cutie
- BP
- construi
- Clădire
- construit
- afaceri
- California
- apel
- capturi
- pasă
- caz
- studiu de caz
- cazuri
- Centru
- centralizat
- CEO
- provocări
- Modificări
- schimbarea
- alegere
- Alege
- ales
- clasă
- clasificare
- client
- clientii
- clinic
- studii clinice
- Cloud
- adoptarea norului
- Grup
- Co-fondator
- cod
- Cohortă
- colaborativ
- colecte
- Coloană
- Coloane
- Comă
- Comunicare
- comunitate
- construirea comunității
- Completă
- cuprinzător
- Calcula
- calculator
- Informatică
- tehnica de calcul
- concept
- Concepte
- Configuraţie
- Conectați
- legat
- conexiune
- Suport conectare
- luate în considerare
- Consoleze
- continua
- contribuţii
- convertit
- Corespunzător
- A costat
- crea
- a creat
- creează
- Crearea
- critic
- CTO
- personalizat
- clienţii care
- personaliza
- de date
- accesul la date
- scurgeri de date
- puncte de date
- confidențialitatea datelor
- știința datelor
- om de știință de date
- schimbul de date
- Baza de date
- descentralizată
- decizie
- adânc
- învățare profundă
- Mod implicit
- demonstra
- implementa
- desfășurarea
- descris
- Amenajări
- destinație
- detaliat
- detalii
- determinarea
- dezvolta
- în curs de dezvoltare
- Dezvoltare
- Dialog
- diferit
- dificil
- Dimensiuni
- direct
- Director
- distribuite
- calcul distribuit
- sisteme distribuite
- distribuire
- Nu
- face
- domeniu
- domenii
- medicament
- dezvoltarea de droguri
- în timpul
- fiecare
- Mai devreme
- ecosistem
- eficiență
- eficient
- permite
- activat
- permite
- un capăt la altul
- inginer
- asigura
- asigură
- Intrați
- Divertisment
- epoci
- Erori
- stabili
- Eter (ETH)
- evenimente
- exemplu
- existent
- de aşteptat
- experienţă
- expert
- explora
- extinde
- Ochi
- cinste
- familie
- DESCRIERE
- membru
- Figura
- Fișier
- Fişiere
- În cele din urmă
- First
- debit
- Concentra
- concentrat
- se concentrează
- urma
- următor
- Avere
- găsit
- Cadru
- Gratuit
- din
- funcţie
- funcții
- mai mult
- În plus
- viitor
- Jocuri
- Gen
- genomica
- gif
- Caritate
- Go
- Goluri
- guvernare
- GPU
- grafic
- grafice
- grup
- Grupului
- orientări
- manipula
- Sănătate
- de asigurări de sănătate
- de asistență medicală
- Held
- ajutor
- a ajutat
- ajutor
- ajută
- aici
- extrem de
- drumeții
- istorie
- Spital
- spitale
- găzduit
- ORE
- Cum
- hpc
- HTML
- HTTPS
- ideal
- IEEE
- imagine
- Imaging
- dezechilibru
- punerea în aplicare a
- import
- îmbunătăţi
- îmbunătățirea
- in
- Inaugural
- Inc
- include
- care încorporează
- index
- industrie
- informații
- Infrastructură
- Inovaţie
- intrare
- instala
- instanță
- asigurare
- interfaţă
- Internet
- internetul Lucrurilor
- IoT
- IT
- alătura
- Cheie
- cunoştinţe
- etichete
- laborator
- lipsă
- pe scară largă
- lansa
- conduce
- lider
- Conducere
- învăţare
- Lungime
- Pârghie
- pîrghii
- efectului de pârghie
- Viaţă
- Știința vieții
- Life Sciences
- Linie
- Listă
- listat
- Ascultare
- încărca
- încărcător
- loturile
- local
- la nivel local
- situat
- Lung
- lor
- Los Angeles
- de pe
- maşină
- masina de învățare
- făcut
- menține
- întreținere
- face
- FACE
- administra
- manager
- manieră
- cartografiere
- martie
- mijloace
- măsurători
- Mass-media
- medical
- imagistica medicala
- Întâlni
- menționat
- metodă
- Metode
- MIT
- diminua
- ML
- Algoritmi ML
- model
- Modele
- monitor
- Monitorizarea
- mai mult
- Motor
- muta
- în mişcare
- multiplu
- Muzică
- nume
- Natură
- Navigare
- Nevoie
- necesar
- nevoilor
- negativ
- reţea
- nod
- noduri
- număr
- NumPy
- ONE
- deschide
- open-source
- Operațiuni
- optimă
- organizații
- Altele
- exterior
- propriu
- deţinute
- proprietar
- pâine
- parametrii
- parte
- partener
- parteneri
- Trecut
- pasiune
- cale
- pacient
- pacientes
- egal
- efectua
- performanță
- efectuează
- personalizare
- Personalizat
- conducte
- Loc
- plan
- Platforme
- Plato
- Informații despre date Platon
- PlatoData
- joc
- "vă rog"
- Punct
- puncte
- ridică
- pozitiv
- Post
- Practic
- tocmai
- prezice
- estimarea
- prezicere
- prezenta
- prezentare
- prezidenţial
- presiune
- împiedica
- în prealabil
- Principal
- intimitate
- privat
- Problemă
- probleme
- proces
- producere
- Produse
- Produse si Servicii
- Profesor
- progresează
- progresie
- interzice
- proiect
- dovadă
- dovada de concept
- propune
- furniza
- furnizează
- furnizarea
- public
- scop
- pirtorh
- C&D
- aleator
- RAR
- rată
- raport
- RE
- Citind
- gata
- lumea reală
- primit
- Recomandare
- record
- inregistrata
- înregistrări
- regiune
- regres
- reglementate
- autoritățile de reglementare
- scoate
- depozit
- reprezintă
- solicita
- necesita
- cerință
- Cerinţe
- Necesită
- cercetare
- respectiv
- reveni
- Returnează
- revizuiască
- drum
- aproximativ
- Traseul
- RÂND
- norme
- Alerga
- funcţionare
- acelaşi
- Scară
- Ştiinţă
- ȘTIINȚE
- Om de stiinta
- script-uri
- perfect
- Al doilea
- securitate
- Căuta
- selectate
- SELF
- senior
- sensibil
- serie
- Servicii
- set
- Seturi
- instalare
- configurarea
- Șapte
- câteva
- Distribuie
- comun
- partajarea
- indicat
- Emisiuni
- semna
- Semne
- asemănător
- asemănător
- singur
- teren
- Centre de cercetare
- So
- soluţie
- soluţii
- rezolvă
- Sursă
- Sudic
- se întinde
- specific
- împărţi
- stabil
- standard
- Începe
- început
- lansare
- de ultimă oră
- Statele
- Stare
- şedere
- paşi
- depozitare
- structurat
- date structurate și nestructurate
- Studiu
- stil
- subrețele
- astfel de
- suficient
- a sustine
- Sprijină
- Sondaj de opinie
- sistem
- sisteme
- tabel
- TAG
- luare
- Ţintă
- vizate
- Sarcină
- taxonomie
- Tehnologii
- Tehnologia
- șablon
- test
- lor
- terapeutică
- lucruri
- Al treilea
- gândit
- trei
- Prin
- de-a lungul
- timp
- Seria de timp
- consumă timp
- la
- instrument
- Unelte
- lanternă
- Torchvision
- Total
- urmări
- trafic
- Tren
- Pregătire
- transferat
- studii
- demn de încredere
- Tipuri
- tipic
- care stau la baza
- înţelegere
- unic
- unitate
- Unit
- Statele Unite
- de unităţi
- universitate
- Universitatea din California de Sud
- Actualizează
- actualizări
- us
- Statele Unite ale Americii
- utilizare
- carcasa de utilizare
- valoare
- Valori
- varietate
- diverse
- Fixă
- verticalele
- de
- Video
- Virtual
- vizibil
- vital
- walkthrough
- care
- în timp ce
- OMS
- larg
- voi
- în
- fără
- Apartamente
- fabrică
- de renume mondial
- X
- ani
- Ta
- zephyrnet