Introducere
Am văzut câțiva termeni de lux pentru AI și învățarea profundă, cum ar fi modele pre-antrenate, învățarea prin transfer etc. Permiteți-mi să vă educ cu o tehnologie utilizată pe scară largă și una dintre cele mai importante și mai eficiente: transferul de învățare cu YOLOv5.
You Only Look Once, sau YOLO este una dintre cele mai utilizate metode de identificare a obiectelor bazate pe deep learning. Folosind un set de date personalizat, acest articol vă va arăta cum să antrenați una dintre cele mai recente variante ale sale, YOLOv5.
obiective de invatare
- Acest articol se va concentra în principal pe antrenarea modelului YOLOv5 cu privire la implementarea unui set de date personalizat.
- Vom vedea ce sunt modelele pre-antrenate și vom vedea ce înseamnă învățarea prin transfer.
- Vom înțelege ce este YOLOv5 și de ce folosim versiunea 5 a YOLO.
Deci, fără să pierdem timpul, să începem cu procesul
Cuprins
- Modele pregatite
- Transferul învățării
- Ce și de ce YOLOv5?
- Pași implicați în învățarea prin transfer
- Punerea în aplicare
- Câteva provocări pe care le puteți face față
- Concluzie
Modele pre-antrenate
S-ar putea să fi auzit că oamenii de știință din date folosesc pe scară largă termenul „model pre-antrenat”. După ce am explicat ce face un model/rețea de învățare profundă, voi explica termenul. Un model de învățare profundă este un model care conține diverse straturi stivuite împreună astfel încât să servească un scop solitar, cum ar fi clasificarea, detectarea etc. Rețelele de învățare profundă învață prin descoperirea structurilor complicate în datele care le sunt furnizate și salvând ponderile într-un fișier care sunt folosite ulterior pentru a îndeplini sarcini similare. Modelele preinstruite sunt deja modele de Deep Learning instruite. Ceea ce înseamnă este că sunt deja instruiți pe un set de date uriaș care conține milioane de imagini.
Iată cum TensorFlow site-ul web definește modele pre-instruite: Un model pre-antrenat este o rețea salvată care a fost antrenată anterior pe un set de date mare, de obicei pe o sarcină de clasificare a imaginilor la scară largă.
Unele extrem de optimizate și extraordinar de eficiente modele pre-antrenate sunt disponibile pe internet. Diferite modele sunt folosite pentru a îndeplini diferite sarcini. Unele dintre modelele pre-antrenate sunt VGG-16, VGG-19, YOLOv5, YOLOv3 și ResNet 50.
Ce model de utilizat depinde de sarcina pe care doriți să o efectuați. De exemplu, dacă vreau să efectuez un detectarea obiectelor sarcină, voi folosi modelul YOLOv5.
Transferul învățării
Transferul învățării este cea mai importantă tehnică care ușurează sarcina unui cercetător de date. Antrenarea unui model este o sarcină grea și consumatoare de timp; dacă un model este antrenat de la zero, de obicei nu dă rezultate foarte bune. Chiar dacă antrenăm un model similar cu un model pre-antrenat, acesta nu va funcționa la fel de eficient și poate dura săptămâni pentru ca un model să se antreneze. În schimb, putem folosi modelele pre-antrenate și folosim greutățile deja învățate, antrenându-le pe un set de date personalizat pentru a efectua o sarcină similară. Aceste modele sunt extrem de eficiente și rafinate în ceea ce privește arhitectura și performanța și și-au făcut drum spre vârf, performând mai bine în diferite concursuri. Aceste modele sunt antrenate pe cantități foarte mari de date, ceea ce le face mai diverse în cunoștințe.
Prin urmare, transferul de învățare înseamnă, practic, transferul de cunoștințe dobândite prin antrenarea modelului pe date anterioare pentru a ajuta modelul să învețe mai bine și mai rapid pentru a îndeplini o sarcină diferită, dar similară.
De exemplu, folosind un YOLOv5 pentru detectarea obiectelor, dar obiectul este altceva decât datele anterioare ale obiectului utilizate.
Ce și de ce YOLOv5?
YOLOv5 este un model pre-antrenat care înseamnă că arăți doar după ce versiunea 5 este utilizată pentru detectarea obiectelor în timp real și s-a dovedit a fi foarte eficient în ceea ce privește precizia și timpul de inferență. Există și alte versiuni ale YOLO, dar așa cum s-ar putea prezice, YOLOv5 are performanțe mai bune decât alte versiuni. YOLOv5 este rapid și ușor de utilizat. Se bazează pe framework-ul PyTorch, care are o comunitate mai mare decât Yolo v4 Darknet.
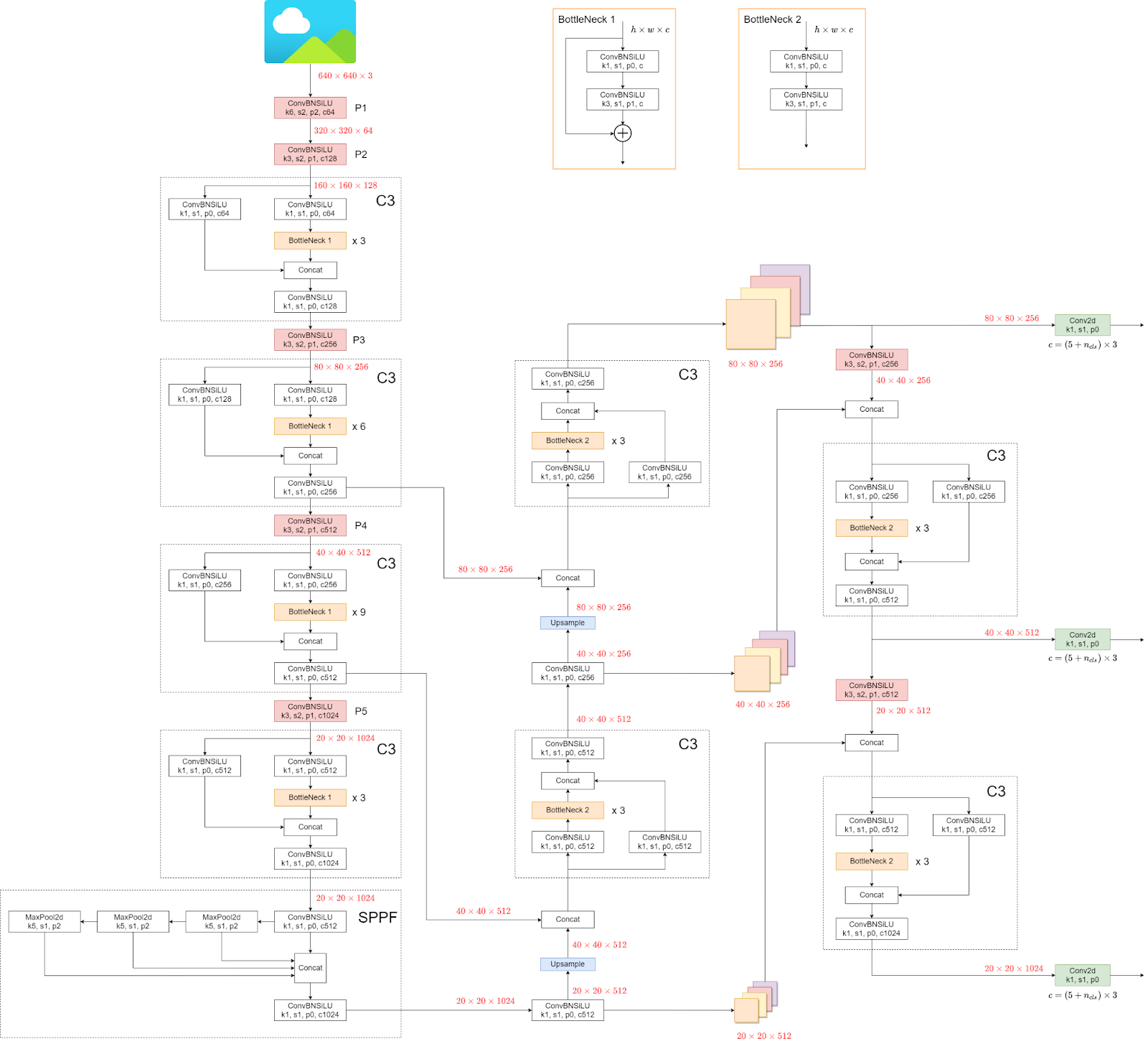
Ne vom uita acum la arhitectura YOLOv5.
Structura poate părea confuză, dar nu contează, deoarece nu trebuie să ne uităm la arhitectură, ci să folosim direct modelul și greutățile.
În învățarea prin transfer, folosim setul de date personalizat, adică datele pe care modelul nu le-a văzut niciodată înainte SAU datele pe care modelul nu este antrenat. Deoarece modelul este deja antrenat pe un set de date mare, avem deja ponderile. Acum putem antrena modelul pentru o serie de epoci pe datele pe care vrem să lucrăm. Este necesară instruirea deoarece modelul a văzut datele pentru prima dată și va necesita anumite cunoștințe pentru a îndeplini sarcina.
Pași implicați în învățarea prin transfer
Învățarea prin transfer este un proces simplu și îl putem face în câțiva pași simpli:
- Pregătirea datelor
- Formatul potrivit pentru adnotări
- Schimbați câteva straturi dacă doriți
- Reantrenați modelul pentru câteva iterații
- Validați/Testați
Pregătirea datelor
Pregătirea datelor poate consuma mult timp dacă datele alese sunt puțin mari. Pregătirea datelor înseamnă adnotarea imaginilor, care este un proces prin care etichetați imaginile făcând o casetă în jurul obiectului din imagine. Procedând astfel, coordonatele obiectului marcat vor fi salvate într-un fișier care va fi apoi alimentat modelului pentru antrenament. Există câteva site-uri web, cum ar fi makeense.ai și roboflow.com, care vă poate ajuta să etichetați datele.
Iată cum puteți adnota datele pentru modelul YOLOv5 pe makeense.ai.
1. Vizita https://www.makesense.ai/.
2. Faceți clic pe începeți în partea dreaptă jos a ecranului.
3. Selectați imaginile pe care doriți să le etichetați făcând clic pe caseta evidențiată în centru.
Încărcați imaginile pe care doriți să le adnotați și faceți clic pe detectarea obiectelor.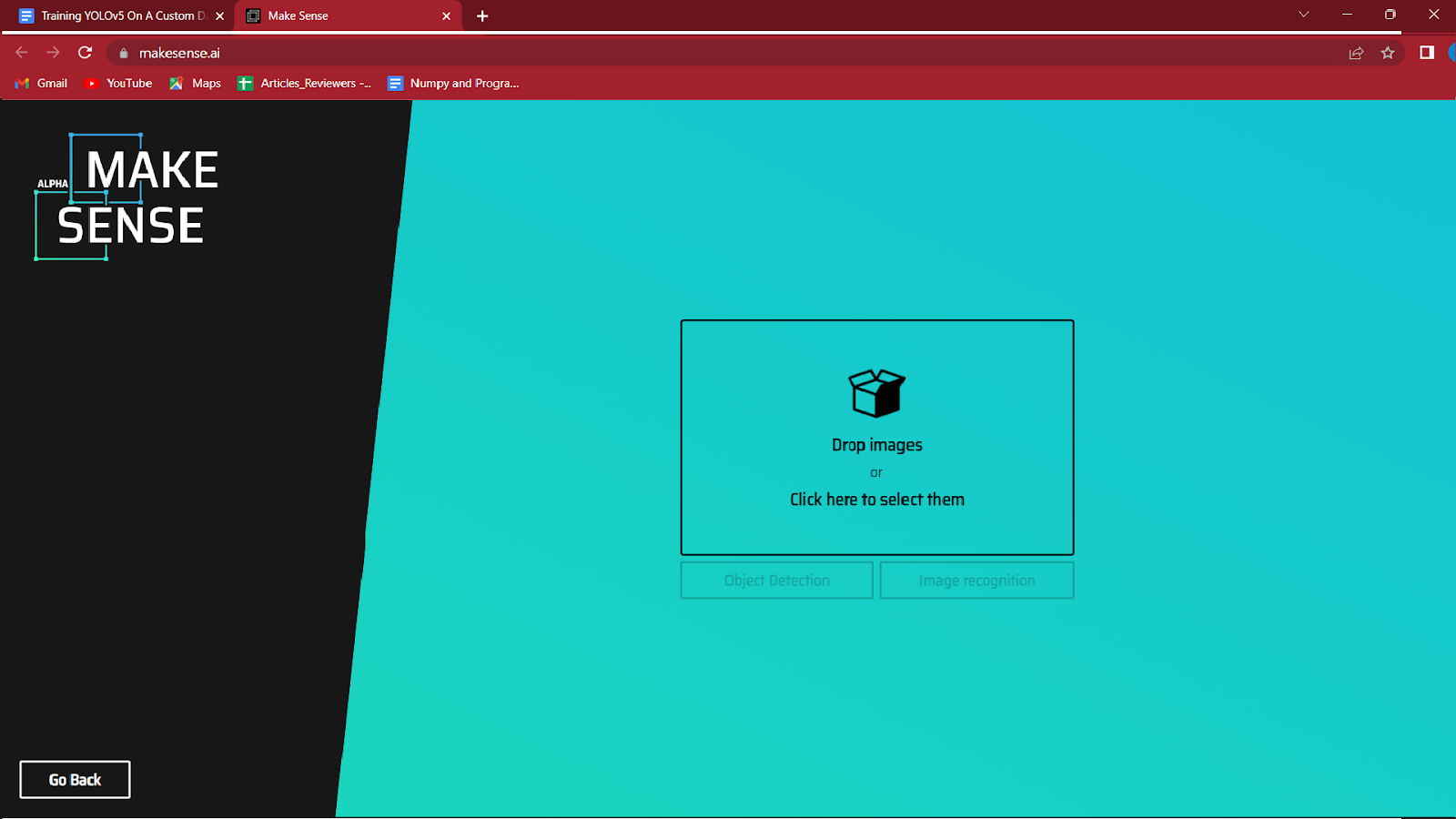
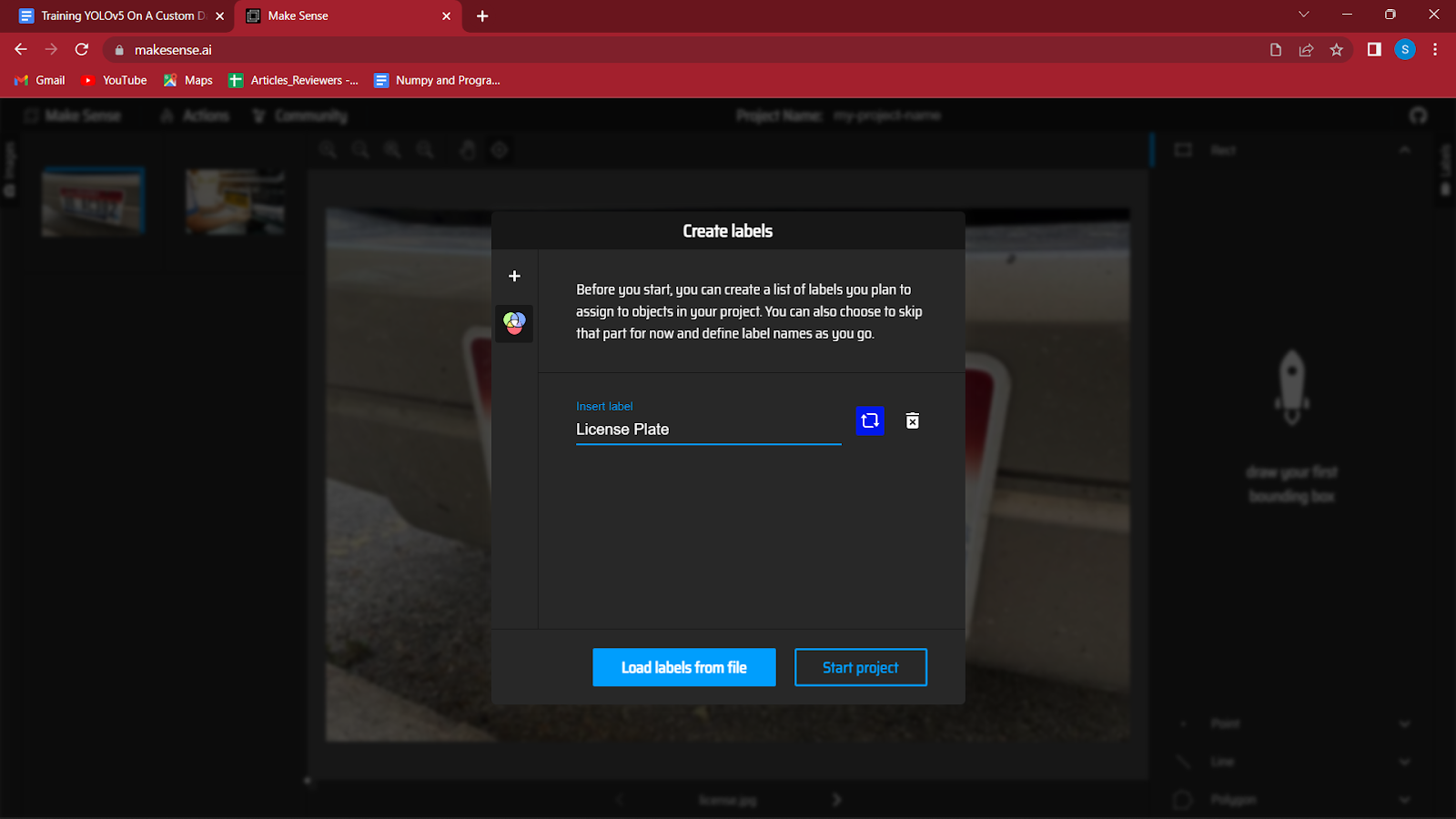
4. După încărcarea imaginilor, vi se va cere să creați etichete pentru diferitele clase ale setului de date.
Detectez plăcuțele de înmatriculare pe un vehicul, așa că singura etichetă pe care o voi folosi este „Placă de înmatriculare”. Puteți crea mai multe etichete apăsând pur și simplu enter făcând clic pe butonul „+” din partea stângă a casetei de dialog.
După ce ați creat toate etichetele, faceți clic pe Start proiect.
Dacă ați omis vreo etichetă, le puteți edita mai târziu făcând clic pe acțiuni și apoi editați etichetele.
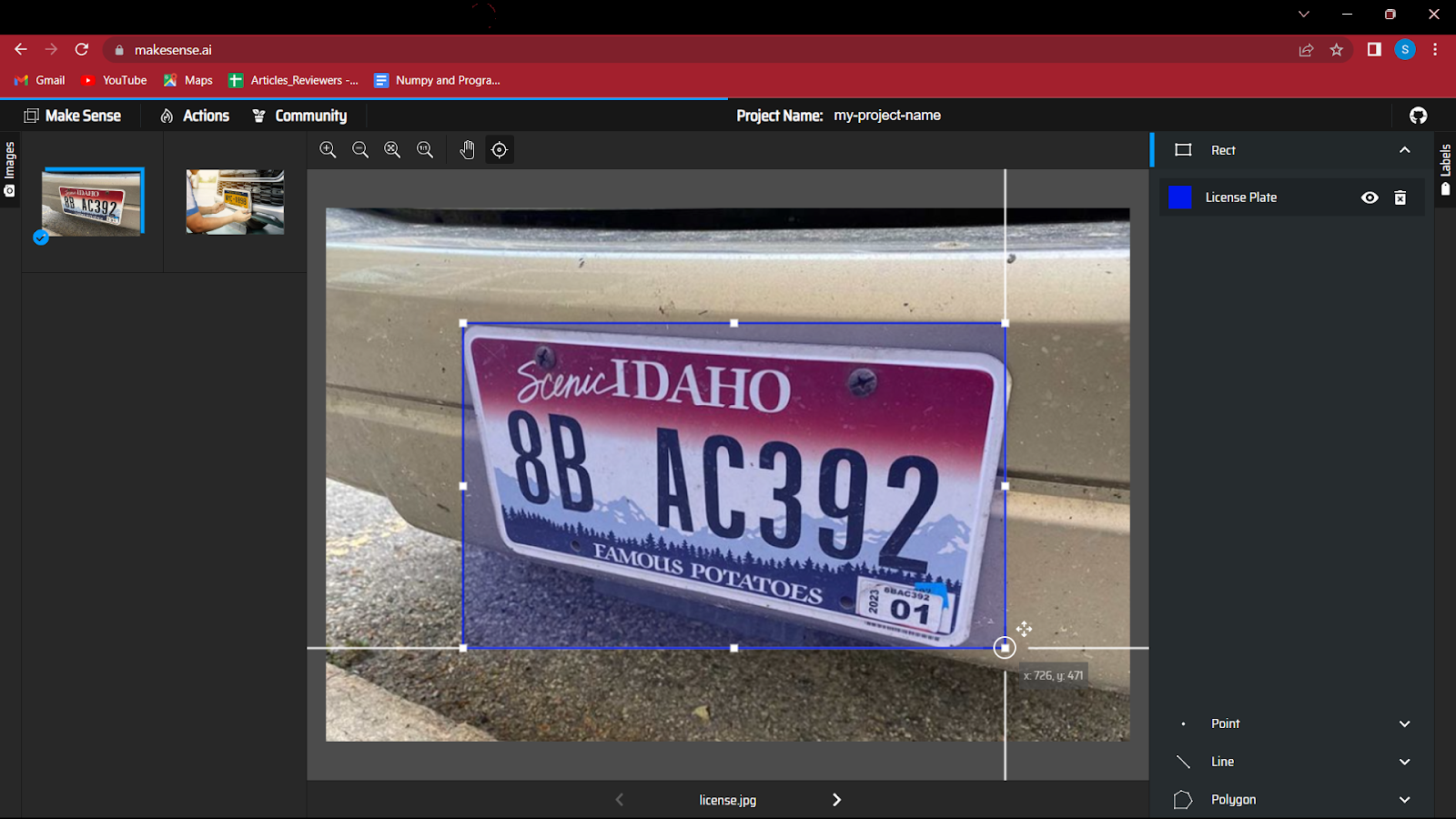
5. Începeți să creați o casetă de delimitare în jurul obiectului din imagine. Acest exercițiu poate fi puțin distractiv inițial, dar cu date foarte mari, poate fi obositor.
6. După adnotarea tuturor imaginilor, trebuie să salvați fișierul care va conține coordonatele casetelor de delimitare împreună cu clasa.
Așa că trebuie să vă îndreptați către butonul de acțiuni și să faceți clic pe export adnotări, nu uitați să bifați opțiunea „Un pachet zip care conține fișiere în format YOLO”, deoarece aceasta va salva fișierele în formatul corect, așa cum este necesar în modelul YOLO.
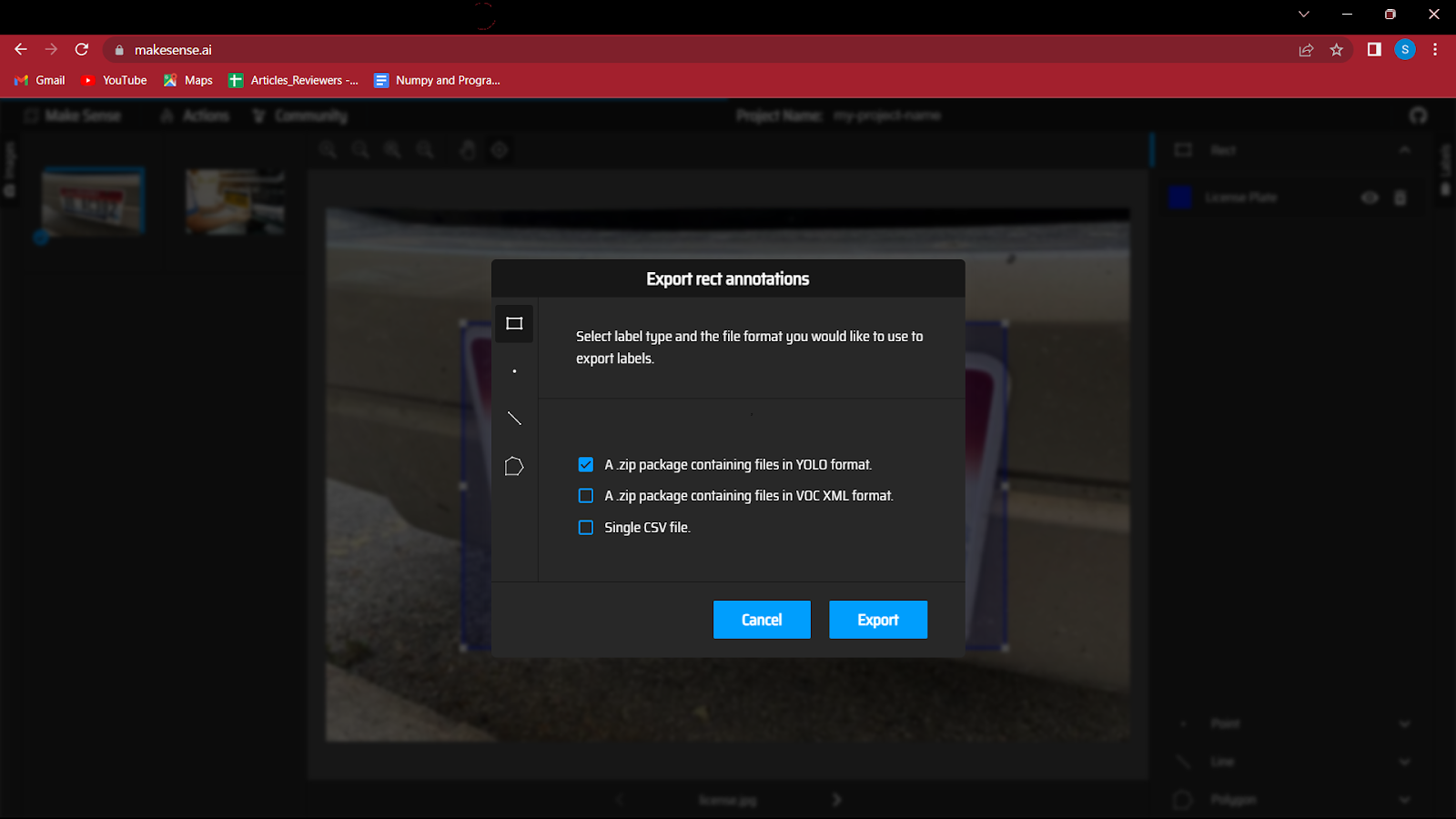
7. Acesta este un pas important, așa că urmați-l cu atenție.
După ce aveți toate fișierele și imaginile, faceți un folder cu orice nume. Faceți clic pe folder și creați încă două foldere cu numele imaginilor și etichetele în interiorul folderului. Nu uitați să denumiți folderul la fel ca mai sus, deoarece modelul caută automat etichete după ce introduceți calea de antrenament în comandă.
Pentru a vă face o idee despre folder, am creat un folder numit „CarsData” și în acel folder am creat două foldere – „imagini” și „etichete”.
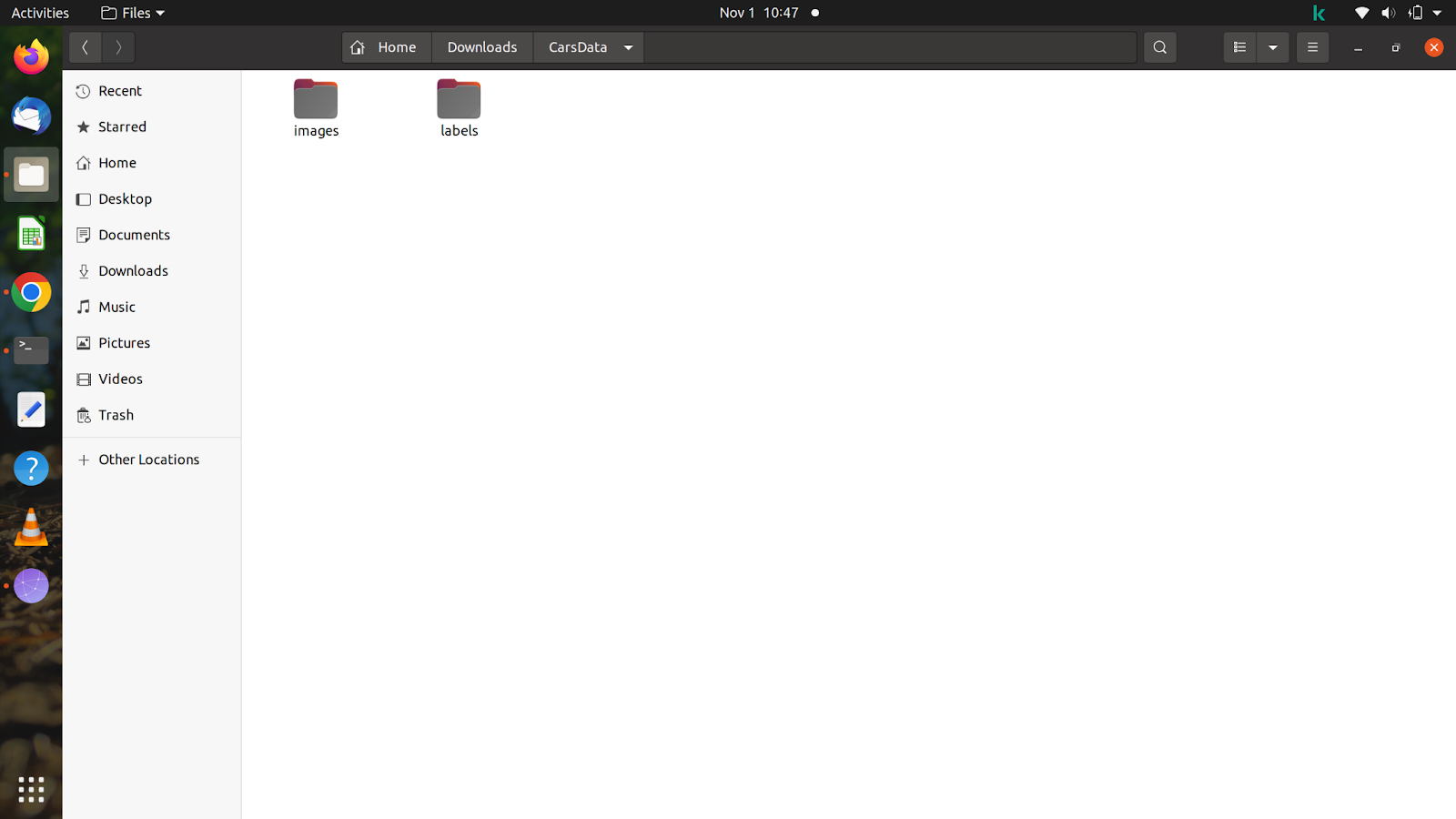
În interiorul celor două foldere, trebuie să creați încă două foldere numite „train” și „val”. În dosarul cu imagini, puteți împărți imaginile în funcție de voința dvs., dar trebuie să aveți grijă când împărțiți eticheta, deoarece etichetele ar trebui să se potrivească cu imaginile pe care le-ați împărțit.
8. Acum faceți un fișier zip al folderului și încărcați-l pe unitate, astfel încât să-l putem folosi în colab.
Punerea în aplicare
Vom ajunge acum la partea de implementare, care este foarte simplă, dar complicată. Dacă nu știți exact ce fișiere să schimbați, nu veți putea antrena modelul pe setul de date personalizat.
Deci, iată codurile pe care ar trebui să le urmați pentru a antrena modelul YOLOv5 pe un set de date personalizat
Vă recomand să utilizați google colab pentru acest tutorial, deoarece oferă și un GPU care oferă calcule mai rapide.
1. !git clona https://github.com/ultralytics/yolov5
Acest lucru va face o copie a depozitului YOLOv5, care este un depozit GitHub creat de ultralytics.
2. cd yolov5
Aceasta este o comandă shell din linia de comandă folosită pentru a schimba directorul de lucru curent în directorul YOLOv5.
3. !pip install -r requirements.txt
Această comandă va instala toate pachetele și bibliotecile utilizate în antrenamentul modelului.
4. !unzip „/content/drive/MyDrive/CarsData.zip”
Dezarhivând folderul care conține imagini și etichete în google colab
Aici vine cel mai important pas...
Acum ați efectuat aproape toți pașii și trebuie să scrieți încă o linie de cod care va antrena modelul, dar, înainte de aceasta, trebuie să efectuați încă câțiva pași și să schimbați niște directoare pentru a oferi calea setului dvs. de date personalizate. și antrenează-ți modelul pe acele date.
Iată ce trebuie să faci.
După efectuarea celor 4 pași de mai sus, veți avea folderul yolov5 în google colab. Accesați folderul yolov5 și faceți clic pe folderul „date”. Acum veți vedea un folder numit „coco128.yaml”.
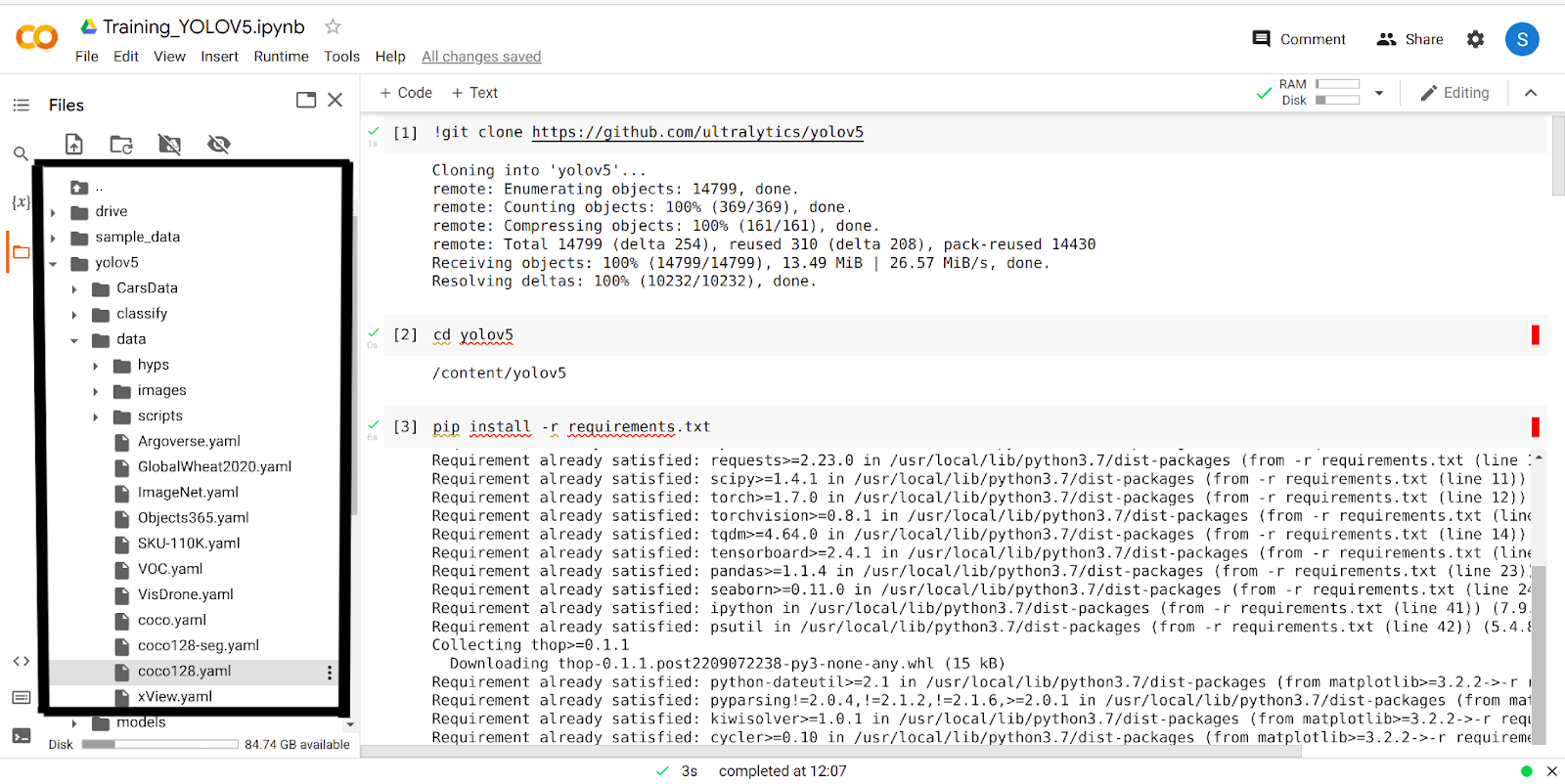
Continuați și descărcați acest folder.
După ce folderul este descărcat, trebuie să-i faceți câteva modificări și să-l încărcați înapoi în același folder din care l-ați descărcat.
Să ne uităm acum la conținutul fișierului pe care l-am descărcat și va arăta cam așa.
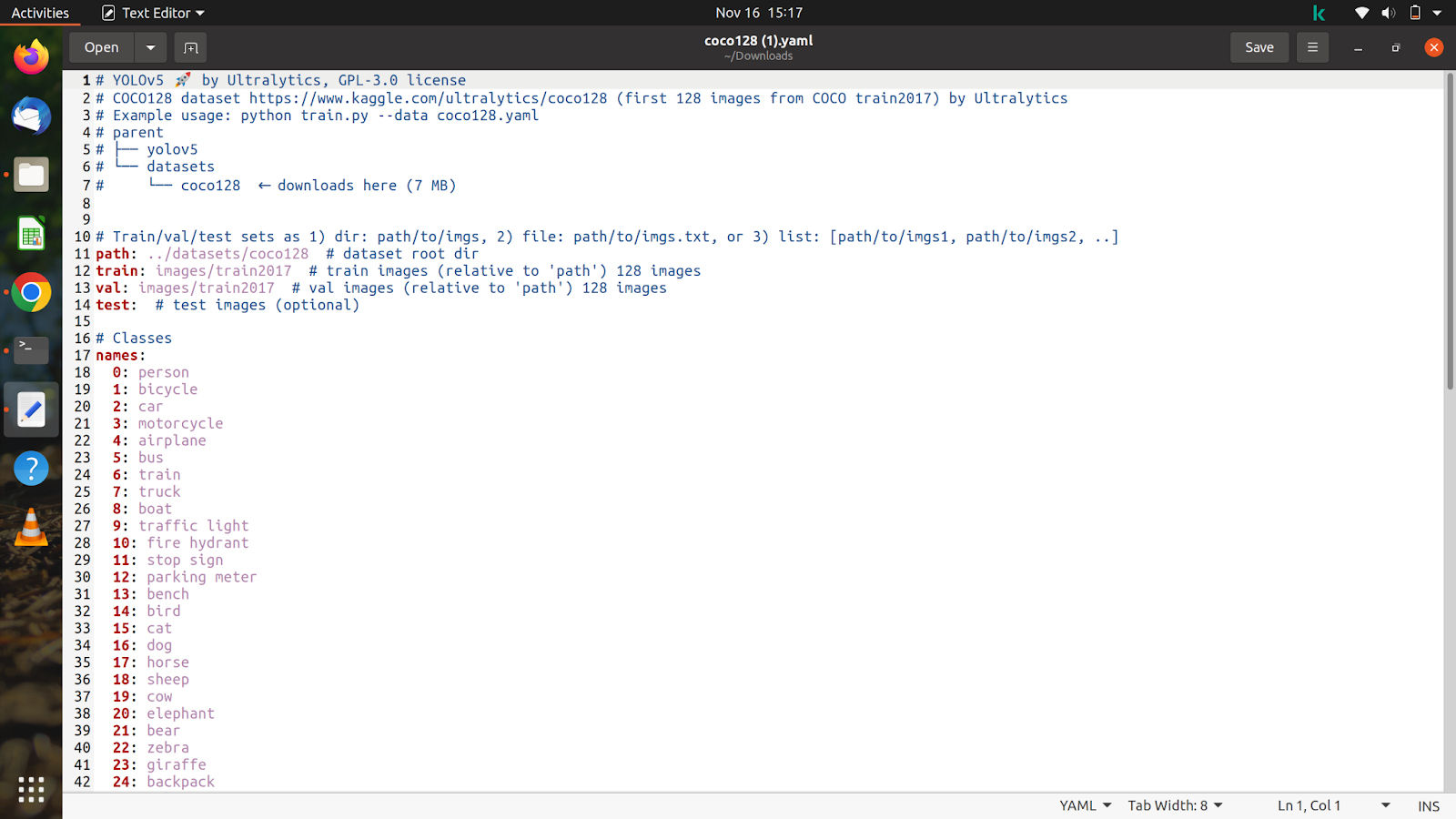
Vom personaliza acest fișier în funcție de setul de date și adnotările noastre.
Am dezarhivat deja setul de date din colab, așa că vom copia calea trenului și imaginile de validare. După ce ați copiat calea imaginilor trenului, care va fi în folderul setului de date și arată cam așa „/content/yolov5/CarsData/images/train”, lipiți-o în fișierul coco128.yaml, pe care tocmai l-am descărcat.
Faceți același lucru cu imaginile de testare și validare.
Acum, după ce am terminat cu asta, vom menționa numărul de clase precum „nc: 1”. Numărul de clase, în acest caz, este doar 1. Vom menționa apoi numele așa cum se arată în imaginea de mai jos. Eliminați toate celelalte clase și partea comentată, care nu este necesară, după care fișierul nostru ar trebui să arate cam așa.
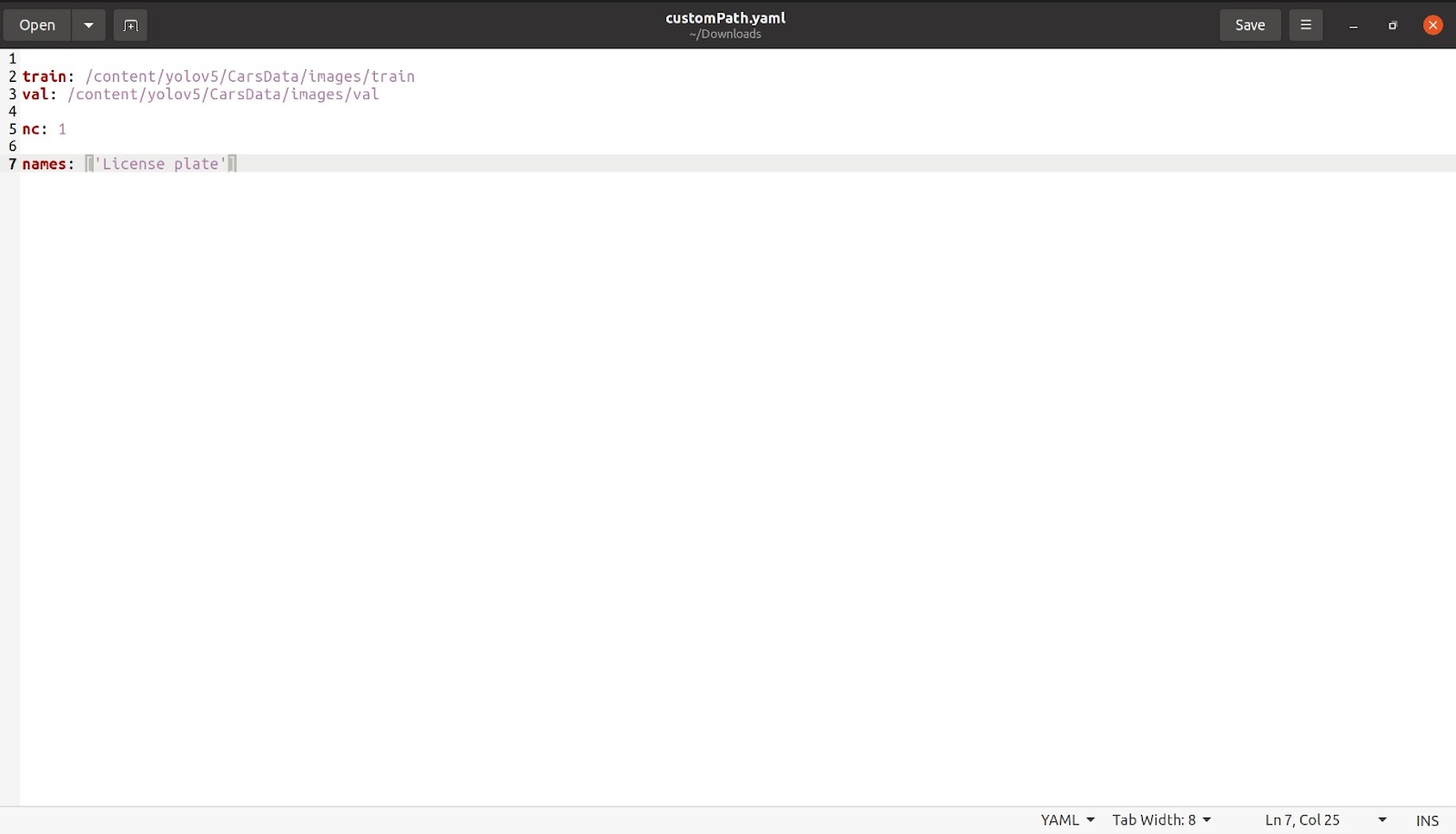
Salvați acest fișier cu orice nume doriți. Am salvat fișierul cu numele customPath.yaml și acum încarc acest fișier înapoi în colab în același loc în care a fost coco128.yaml.
Acum am terminat cu partea de editare și gata să antrenăm modelul.
Rulați următoarea comandă pentru a vă instrui modelul pentru câteva interacțiuni cu setul de date personalizat.
Nu uitați să schimbați numele fișierului pe care l-ați încărcat ('customPath.yaml). De asemenea, puteți modifica numărul de epoci în care doriți să antrenați modelul. În acest caz, voi antrena modelul doar pentru 3 epoci.
5. !python train.py –img 640 –batch 16 –epochs 10 –data /content/yolov5/customPath.yaml –weights yolov5s.pt
Rețineți calea în care încărcați folderul. Dacă calea este schimbată, atunci comenzile nu vor funcționa deloc.
După ce rulați această comandă, modelul dvs. ar trebui să înceapă antrenamentul și veți vedea așa ceva pe ecran.
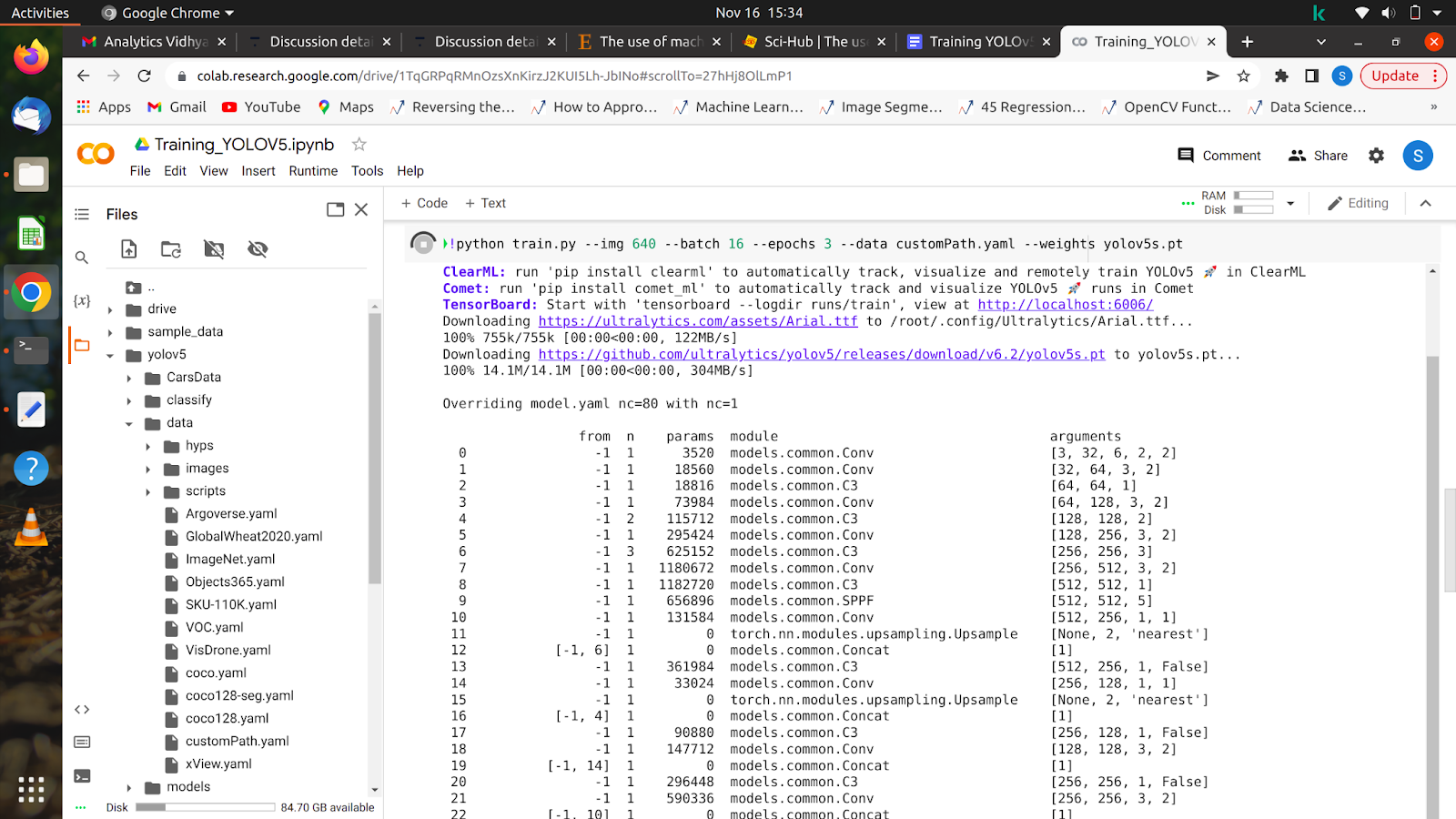
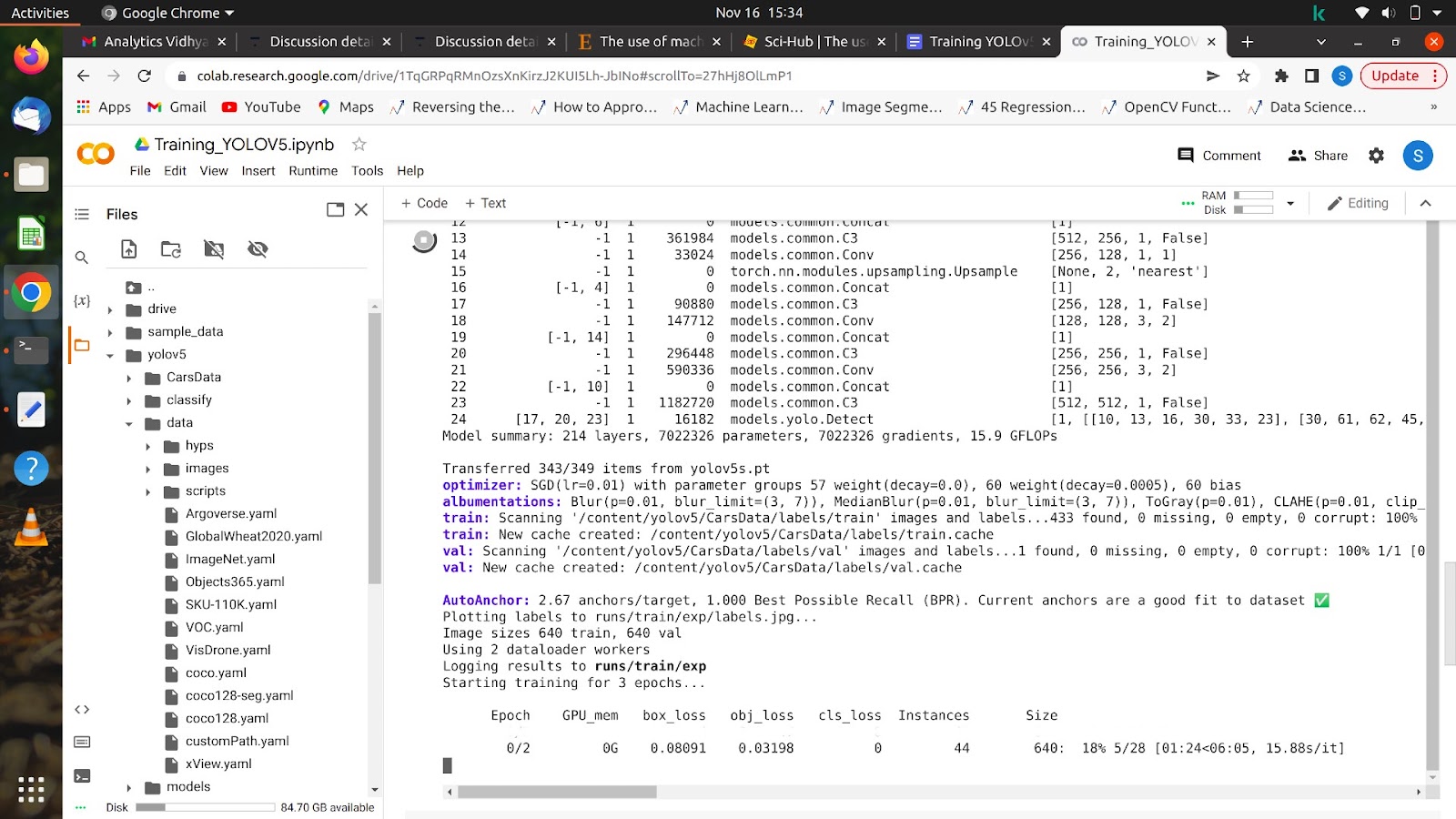
După ce toate epocile sunt finalizate, modelul tău poate fi testat pe orice imagine.
Puteți face ceva mai multă personalizare în fișierul detect.py asupra a ceea ce doriți să salvați și a ceea ce nu vă place, detectările unde sunt detectate plăcuțele de înmatriculare etc.
6. !python detect.py –weight /content/yolov5/runs/train/exp/weights/best.pt –source path_of_the_image
Puteți folosi această comandă pentru a testa predicția modelului pe unele imagini.
Câteva provocări pe care le puteți face față
Deși pașii explicați mai sus sunt corecti, există unele probleme cu care te poți confrunta dacă nu le urmezi întocmai.
- Calea greșită: aceasta poate fi o durere de cap sau o problemă. Dacă ați intrat pe calea greșită undeva în antrenamentul imaginii, poate să nu fie ușor de identificat și nu veți putea antrena modelul.
- Format greșit al etichetelor: aceasta este o problemă larg răspândită cu care se confruntă oamenii în timpul antrenării unui YOLOv5. Modelul acceptă doar un format în care fiecare imagine are propriul fișier text cu formatul dorit în interior. Adesea, un fișier în format XLS sau un singur fișier CSV este alimentat în rețea, rezultând o eroare. Dacă descărcați datele de undeva, în loc să adnotați fiecare imagine, poate exista un alt format de fișier în care sunt salvate etichetele. Iată un articol pentru a converti formatul XLS în format YOLO. (link după finalizarea articolului).
- Nu denumirea corectă a fișierelor: Nedenumirea corectă a fișierului va duce din nou la o eroare. Acordați atenție pașilor în timp ce denumiți folderele și evitați această eroare.
Concluzie
În acest articol, am aflat ce este învățarea prin transfer și modelul pre-antrenat. Am învățat când și de ce să folosim modelul YOLOv5 și cum să antrenăm modelul pe un set de date personalizat. Am parcurs fiecare pas, de la pregătirea setului de date până la schimbarea căilor și, în cele din urmă, alimentarea lor în rețea în implementarea tehnicii și am înțeles bine pașii. De asemenea, am analizat problemele comune cu care se confruntă în timpul antrenării unui YOLOv5 și soluția acestora. Sper că acest articol v-a ajutat să vă instruiți primul YOLOv5 pe un set de date personalizat și că vă place articolul.
Legate de
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- Platoblockchain. Web3 Metaverse Intelligence. Cunoștințe amplificate. Accesați Aici.
- Sursa: https://www.analyticsvidhya.com/blog/2023/02/how-to-train-a-custom-dataset-with-yolov5/
- 1
- 10
- a
- Capabil
- mai sus
- acceptă
- Conform
- precizie
- acțiuni
- După
- înainte
- AI
- TOATE
- deja
- Sume
- și
- arhitectură
- în jurul
- articol
- atenţie
- în mod automat
- disponibil
- evita
- înapoi
- bazat
- Pe scurt
- înainte
- de mai jos
- Mai bine
- Pic
- De jos
- Cutie
- Dulapuri
- buton
- atent
- cu grijă
- caz
- CD
- Centru
- provocări
- Schimbare
- Modificări
- schimbarea
- verifica
- ales
- clasă
- clase
- clasificare
- cod
- cum
- a comentat
- Comun
- comunitate
- Terminat
- completare
- complicat
- calcule
- confuz
- conține
- conţinut
- converti
- copiere
- corect
- crea
- a creat
- Crearea
- Curent
- personalizat
- personalizare
- personaliza
- Darknet
- de date
- Pregătirea datelor
- om de știință de date
- adânc
- învățare profundă
- defineste
- depinde de
- detectat
- Detectare
- Dialog
- diferit
- direct
- directoare
- descoperirea
- diferit
- face
- Dont
- Descarca
- conduce
- fiecare
- faciliteaza
- educa
- Eficace
- în mod eficient
- eficient
- Intrați
- a intrat
- epoci
- eroare
- etc
- Chiar
- Fiecare
- exact
- exemplu
- Exercita
- Explica
- a explicat
- explicând
- exporturile
- extraordinar
- Față
- cu care se confruntă
- FAST
- mai repede
- fed-
- hrănire
- puțini
- Fișier
- Fişiere
- În cele din urmă
- First
- prima dată
- Concentra
- urma
- următor
- format
- Cadru
- din
- distracţie
- obține
- GitHub
- Da
- Go
- merge
- bine
- GPU
- cap
- auzit
- ajutor
- a ajutat
- aici
- Evidențiat
- extrem de
- lovind
- speranţă
- Cum
- Cum Pentru a
- HTTPS
- mare
- idee
- Identificare
- identifica
- imagine
- imagini
- implementarea
- important
- in
- inițial
- instala
- in schimb
- interacţiuni
- Internet
- implicat
- IT
- Cunoaște
- cunoştinţe
- Etichetă
- etichete
- mare
- pe scară largă
- mai mare
- straturi
- conduce
- AFLAȚI
- învățat
- învăţare
- biblioteci
- Licență
- Linie
- LINK
- încărcare
- Uite
- uitat
- Se pare
- făcut
- face
- Efectuarea
- marcat
- Meci
- materie
- max-width
- mijloace
- Metode
- ar putea
- milioane
- minte
- model
- Modele
- mai mult
- cele mai multe
- nume
- Numit
- denumire
- Nevoie
- necesar
- reţea
- rețele
- număr
- obiect
- Detectarea obiectelor
- ONE
- optimizate
- Opțiune
- comandă
- Altele
- propriu
- pachet
- ofertele
- parte
- cale
- Plătește
- oameni
- efectua
- performanță
- efectuarea
- efectuează
- Loc
- Plato
- Informații despre date Platon
- PlatoData
- prezice
- prezicere
- pregătirea
- precedent
- în prealabil
- Problemă
- probleme
- proces
- proiect
- dovedit
- furnizează
- scop
- pirtorh
- gata
- în timp real
- recent
- recomanda
- rafinat
- scoate
- depozit
- necesita
- necesar
- Cerinţe
- rezultând
- REZULTATE
- Alerga
- acelaşi
- Economisiți
- economisire
- Om de stiinta
- oamenii de stiinta
- Ecran
- servi
- Coajă
- să
- Arăta
- indicat
- semnificativ
- asemănător
- simplu
- pur şi simplu
- întrucât
- singur
- So
- soluţie
- unele
- ceva
- undeva
- împărţi
- stivuite
- Standuri
- Începe
- început
- Pas
- paşi
- structura
- astfel de
- Lua
- Sarcină
- sarcini
- Tehnologia
- termeni
- test
- lor
- complet
- Prin
- timp
- consumă timp
- la
- împreună
- top
- Tren
- dresat
- Pregătire
- transfer
- transferare
- tutorial
- tipic
- înţelege
- înțeles
- utilizare
- obișnuit
- validare
- diverse
- vehicul
- versiune
- website
- site-uri web
- săptămâni
- Ce
- care
- în timp ce
- pe larg
- pe scară largă
- voi
- fără
- Apartamente
- de lucru
- ar
- scrie
- Greșit
- yaml
- Yolo
- Ta
- zephyrnet
- Zip