Această postare este scrisă împreună cu Mahima Agarwal, inginer de învățare automată și Deepak Mettem, manager senior de inginerie, la VMware Carbon Black
VMware Carbon Black este o soluție de securitate renumită care oferă protecție împotriva întregului spectru de atacuri cibernetice moderne. Cu terabytes de date generați de produs, echipa de analiză a securității se concentrează pe construirea de soluții de învățare automată (ML) pentru a suprafață atacurile critice și pentru a evidenția amenințările emergente din zgomot.
Este esențial pentru echipa VMware Carbon Black să proiecteze și să construiască o conductă MLOps personalizată end-to-end care să orchestreze și să automatizeze fluxurile de lucru în ciclul de viață ML și să permită formarea modelelor, evaluări și implementări.
Există două scopuri principale pentru construirea acestei conducte: sprijinirea cercetătorilor de date pentru dezvoltarea modelului în stadiul ultim și predicțiile modelelor de suprafață în produs, oferind modele în volum mare și în trafic de producție în timp real. Prin urmare, VMware Carbon Black și AWS au ales să construiască o conductă personalizată MLOps folosind Amazon SageMaker pentru ușurința în utilizare, versatilitatea și infrastructura complet gestionată. Ne orchestrăm canalele de instruire și implementare ML folosind Fluxuri de lucru gestionate de Amazon pentru Apache Airflow (Amazon MWAA), care ne permite să ne concentrăm mai mult pe crearea programatică a fluxurilor de lucru și a conductelor, fără a fi nevoie să ne facem griji cu privire la scalarea automată sau întreținerea infrastructurii.
Cu această conductă, ceea ce odată a fost cercetarea ML condusă de notebook-uri Jupyter este acum un proces automatizat care implementează modele în producție cu o intervenție manuală redusă din partea cercetătorilor de date. Anterior, procesul de instruire, evaluare și implementare a unui model putea dura o zi; cu această implementare, totul este doar un declanșator distanță și a redus timpul total la câteva minute.
În această postare, arhitecții VMware Carbon Black și AWS discută despre modul în care am creat și gestionat fluxurile de lucru ML personalizate folosind gitlab, Amazon MWAA și SageMaker. Discutăm despre ceea ce am realizat până acum, îmbunătățiri suplimentare ale conductei și lecțiile învățate pe parcurs.
Prezentare generală a soluțiilor
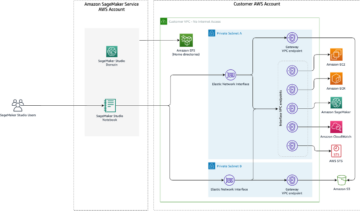
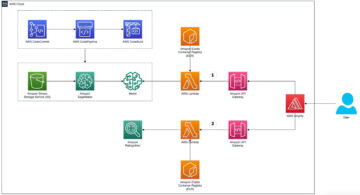
Următoarea diagramă ilustrează arhitectura platformei ML.

Design de soluție la nivel înalt
Această platformă ML a fost concepută și concepută pentru a fi consumată de diferite modele în diferite depozite de cod. Echipa noastră folosește GitLab ca instrument de gestionare a codului sursă pentru a menține toate depozitele de cod. Orice modificare a codului sursă al depozitului de modele este integrată continuu folosind Gitlab CI, care invocă fluxurile de lucru ulterioare în curs (formarea modelului, evaluarea și implementarea).
Următoarea diagramă de arhitectură ilustrează fluxul de lucru end-to-end și componentele implicate în conducta noastră MLOps.

Flux de lucru end-to-end
Conductele de instruire, evaluare și implementare a modelului ML sunt orchestrate folosind Amazon MWAA, denumit Grafic Acyclic direcționat (DAG). Un DAG este o colecție de sarcini împreună, organizate cu dependențe și relații pentru a spune cum ar trebui să ruleze.
La un nivel înalt, arhitectura soluției include trei componente principale:
- Depozitul de coduri ML pipeline
- Conducta de instruire și evaluare a modelului ML
- Conducta de implementare a modelului ML
Să discutăm despre modul în care aceste componente diferite sunt gestionate și cum interacționează între ele.
Depozitul de coduri ML pipeline
După ce repo-ul model integrează repo-ul MLOps ca conductă în aval, iar un om de știință de date comite cod în repo-ul modelului lor, un runner GitLab efectuează validarea și testarea codului standard definite în acel repo și declanșează conducta MLOps pe baza modificărilor codului. Folosim pipeline-ul multi-proiect al Gitlab pentru a activa acest declanșator în diferite repoziții.
Conducta MLOps GitLab rulează un anumit set de etape. Efectuează validarea codului de bază folosind pylint, împachetează codul de antrenament și inferență al modelului în imaginea Docker și publică imaginea containerului pentru Registrul Amazon de containere elastice (Amazon ECR). Amazon ECR este un registru de containere complet gestionat, care oferă găzduire de înaltă performanță, astfel încât să puteți implementa în mod fiabil imagini și artefacte ale aplicațiilor oriunde.
Conducta de instruire și evaluare a modelului ML
După ce imaginea este publicată, declanșează instruirea și evaluarea Flux de aer Apache conducta prin AWS Lambdas funcţie. Lambda este un serviciu de calcul fără server, bazat pe evenimente, care vă permite să rulați cod pentru aproape orice tip de aplicație sau serviciu backend fără a furniza sau gestiona servere.
După ce conducta este declanșată cu succes, rulează DAG de instruire și evaluare, care, la rândul său, începe antrenamentul modelului în SageMaker. La sfârșitul acestui canal de instruire, grupul de utilizatori identificat primește o notificare cu rezultatele formării și evaluării modelului prin e-mail prin Serviciul de notificare simplă Amazon (Amazon SNS) și Slack. Amazon SNS este un serviciu pub/sub gestionat complet pentru mesageria A2A și A2P.
După o analiză meticuloasă a rezultatelor evaluării, cercetătorul de date sau inginerul ML poate implementa noul model dacă performanța modelului nou instruit este mai bună în comparație cu versiunea anterioară. Performanța modelelor este evaluată pe baza valorilor specifice modelului (cum ar fi scorul F1, MSE sau matricea de confuzie).
Conducta de implementare a modelului ML
Pentru a începe implementarea, utilizatorul pornește jobul GitLab care declanșează DAG de implementare prin aceeași funcție Lambda. După ce conducta rulează cu succes, creează sau actualizează punctul final SageMaker cu noul model. Aceasta trimite și o notificare cu detaliile punctului final prin e-mail folosind Amazon SNS și Slack.
În cazul unei defecțiuni în oricare dintre conducte, utilizatorii sunt notificați prin aceleași canale de comunicare.
SageMaker oferă inferență în timp real, care este ideală pentru sarcinile de lucru de inferență cu latență scăzută și cerințe de debit ridicat. Aceste puncte finale sunt complet gestionate, echilibrate de încărcare și scalate automat și pot fi implementate în mai multe zone de disponibilitate pentru o disponibilitate ridicată. Conducta noastră creează un astfel de punct final pentru un model după ce rulează cu succes.
În secțiunile următoare, extindem diferitele componente și ne aruncăm în detalii.
GitLab: Modele de pachete și conducte de declanșare
Folosim GitLab ca depozit de cod și pentru ca pipeline să împacheteze codul modelului și să declanșeze DAG-uri Airflow în aval.
Conductă cu mai multe proiecte
Caracteristica pipeline GitLab pentru mai multe proiecte este utilizată în cazul în care conducta părinte (în amonte) este un model de depozit, iar conducta secundară (în aval) este depozitul MLOps. Fiecare repo menține un .gitlab-ci.yml, iar următorul bloc de cod activat în conducta din amonte declanșează conducta MLOps din aval.
Conducta din amonte trimite codul de model către conducta din aval, unde sunt declanșate joburile CI de ambalare și publicare. Codul pentru a containeriza codul modelului și a-l publica pe Amazon ECR este menținut și gestionat de conducta MLOps. Trimite variabile precum ACCESS_TOKEN (pot fi create sub setări cont, Acces), JOB_ID (pentru a accesa artefacte în amonte) și $CI_PROJECT_ID (ID-ul proiectului al modelului de depozit), astfel încât conducta MLOps să poată accesa fișierele de cod de model. Cu artefacte de muncă caracteristică de la Gitlab, repo-ul din aval accesează artefactele de la distanță folosind următoarea comandă:
Modelul repo poate consuma conducte în aval pentru mai multe modele din același repo prin extinderea etapei care îl declanșează folosind extinde cuvânt cheie de la GitLab, care vă permite să reutilizați aceeași configurație în diferite etape.
După publicarea imaginii model pe Amazon ECR, conducta MLOps declanșează canalul de antrenament Amazon MWAA folosind Lambda. După aprobarea utilizatorului, declanșează și canalul Amazon MWAA de implementare a modelului folosind aceeași funcție Lambda.
Versiune semantică și trecerea versiunilor în aval
Am dezvoltat cod personalizat pentru versiunea imaginilor ECR și a modelelor SageMaker. Conducta MLOps gestionează logica de versiuni semantică pentru imagini și modele ca parte a etapei în care codul modelului este containerizat și transmite versiunile în etapele ulterioare ca artefacte.
Recalificare
Deoarece recalificarea este un aspect crucial al ciclului de viață ML, am implementat capabilități de recalificare ca parte a conductei noastre. Folosim API-ul SageMaker list-models pentru a identifica dacă se reinstruiește pe baza numărului versiunii de reinstruire a modelului și a marcajului de timp.
Gestionăm programul zilnic al conductei de recalificare folosind Conductele programului GitLab.
Terraform: Configurarea infrastructurii
Pe lângă un cluster Amazon MWAA, depozite ECR, funcții Lambda și subiect SNS, această soluție folosește și Gestionarea identității și accesului AWS (IAM) roluri, utilizatori și politici; Serviciul Amazon de stocare simplă găleți (Amazon S3) și un Amazon CloudWatch expeditor de jurnal.
Pentru a eficientiza configurarea și întreținerea infrastructurii pentru serviciile implicate de-a lungul conductei noastre, folosim Terraform pentru a implementa infrastructura ca cod. Ori de câte ori sunt necesare actualizări infra, modificările codului declanșează o conductă GitLab CI pe care am configurat-o, care validează și implementează modificările în diferite medii (de exemplu, adăugarea unei permisiuni la o politică IAM în conturile de dezvoltare, stadiu și producție).
Amazon ECR, Amazon S3 și Lambda: Facilitare pipeline
Folosim următoarele servicii cheie pentru a ne facilita pipeline:
- Amazon ECR – Pentru a menține și a permite preluări convenabile ale imaginilor containerului model, le etichetăm cu versiuni semantice și le încărcăm în depozitele ECR configurate conform
${project_name}/${model_name}prin Terraform. Acest lucru permite un strat bun de izolare între diferite modele și ne permite să folosim algoritmi personalizați și să formatăm cererile de inferență și răspunsurile pentru a include informațiile dorite despre manifestul modelului (numele modelului, versiunea, calea datelor de antrenament și așa mai departe). - Amazon S3 – Folosim compartimente S3 pentru a persista datele de antrenament ale modelului, artefacte de model antrenate per model, DAG-uri pentru fluxul de aer și alte informații suplimentare cerute de conducte.
- Lambda – Deoarece clusterul nostru Airflow este implementat într-un VPC separat din motive de securitate, DAG-urile nu pot fi accesate direct. Prin urmare, folosim o funcție Lambda, întreținută și cu Terraform, pentru a declanșa orice DAG-uri specificate de numele DAG. Cu o configurare corectă IAM, jobul GitLab CI declanșează funcția Lambda, care trece prin configurații până la DAG-urile de instruire sau de implementare solicitate.
Amazon MWAA: conducte de instruire și implementare
După cum am menționat mai devreme, folosim Amazon MWAA pentru a orchestra conductele de instruire și implementare. Folosim operatorii SageMaker disponibili în Pachet furnizor Amazon pentru Airflow pentru a se integra cu SageMaker (pentru a evita șabloanele jinja).
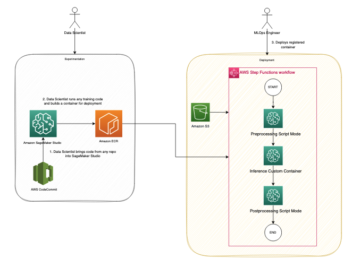
Utilizăm următorii operatori în această conductă de instruire (prezentată în următoarea diagramă a fluxului de lucru):

Conducta de formare MWAA
Utilizăm următorii operatori în conducta de implementare (prezentați în următoarea diagramă a fluxului de lucru):

Conducta de implementare a modelului
Folosim Slack și Amazon SNS pentru a publica mesajele de eroare/succes și rezultatele evaluării în ambele conducte. Slack oferă o gamă largă de opțiuni pentru personalizarea mesajelor, inclusiv următoarele:
- SnsPublishOperator - Folosim SnsPublishOperator pentru a trimite notificări de succes/eșec către e-mailurile utilizatorilor
- Slack API – Noi am creat URL de intrare webhook pentru a primi notificările pipeline către canalul dorit
CloudWatch și VMware Wavefront: Monitorizare și înregistrare
Folosim un tablou de bord CloudWatch pentru a configura monitorizarea și înregistrarea punctelor finale. Ajută la vizualizarea și ținerea evidenței diferitelor metrici de performanță operaționale și model specifice fiecărui proiect. Pe lângă politicile de scalare automată configurate pentru a urmări unele dintre ele, monitorizăm continuu modificările în utilizarea CPU și a memoriei, solicitările pe secundă, latența de răspuns și valorile modelului.
CloudWatch este integrat chiar și cu un tablou de bord VMware Tanzu Wavefront, astfel încât să poată vizualiza valorile pentru punctele finale ale modelului, precum și alte servicii la nivel de proiect.
Beneficii de afaceri și ce urmează
Conductele ML sunt foarte esențiale pentru serviciile și caracteristicile ML. În această postare, am discutat despre un caz de utilizare ML end-to-end folosind capabilități de la AWS. Am construit o conductă personalizată folosind SageMaker și Amazon MWAA, pe care le putem reutiliza în proiecte și modele, și am automatizat ciclul de viață ML, ceea ce a redus timpul de la formarea modelului până la implementarea producției la doar 10 minute.
Odată cu trecerea sarcinii ciclului de viață ML către SageMaker, acesta a oferit o infrastructură optimizată și scalabilă pentru instruirea și implementarea modelului. Servirea modelelor cu SageMaker ne-a ajutat să facem predicții în timp real cu latențe în milisecunde și capabilități de monitorizare. Am folosit Terraform pentru ușurința instalării și pentru a gestiona infrastructura.
Următorii pași pentru această conductă ar fi îmbunătățirea conductei de antrenare a modelului cu capacități de reantrenare, indiferent dacă este programată sau bazată pe detectarea derivei modelului, suportă implementarea umbră sau testarea A/B pentru o implementare mai rapidă și calificată a modelului și urmărirea descendenței ML. De asemenea, intenționăm să evaluăm Pipelines Amazon SageMaker deoarece integrarea GitLab este acum acceptată.
Lecții învățate
Ca parte a construirii acestei soluții, am învățat că ar trebui să generalizați devreme, dar nu să generalizați prea mult. Când am terminat prima dată proiectarea arhitecturii, am încercat să creăm și să aplicăm modele de cod pentru codul modelului ca cea mai bună practică. Cu toate acestea, a fost atât de devreme în procesul de dezvoltare încât șabloanele au fost fie prea generalizate, fie prea detaliate pentru a fi reutilizabile pentru modelele viitoare.
După livrarea primului model prin conductă, șabloanele au apărut în mod natural, pe baza informațiilor din munca noastră anterioară. O conductă nu poate face totul din prima zi.
Experimentarea și producția modelelor au adesea cerințe foarte diferite (sau uneori chiar conflictuale). Este esențial să echilibrezi aceste cerințe de la început ca o echipă și să prioritizezi în consecință.
În plus, este posibil să nu aveți nevoie de fiecare caracteristică a unui serviciu. Utilizarea caracteristicilor esențiale dintr-un serviciu și a avea un design modular sunt cheia pentru o dezvoltare mai eficientă și o conductă flexibilă.
Concluzie
În această postare, am arătat cum am construit o soluție MLOps folosind SageMaker și Amazon MWAA care a automatizat procesul de implementare a modelelor în producție, cu puțină intervenție manuală din partea cercetătorilor de date. Vă încurajăm să evaluați diverse servicii AWS, cum ar fi SageMaker, Amazon MWAA, Amazon S3 și Amazon ECR, pentru a construi o soluție MLOps completă.
*Apache, Apache Airflow și Airflow sunt fie mărci comerciale înregistrate, fie mărci comerciale ale Apache Software Foundation în Statele Unite și / sau în alte țări.
Despre Autori
 Deepak Mettem este Senior Engineering Manager în VMware, Carbon Black Unit. El și echipa sa lucrează la construirea de aplicații și servicii bazate pe streaming, care sunt foarte disponibile, scalabile și rezistente pentru a oferi clienților soluții bazate pe învățarea automată în timp real. El și echipa sa sunt, de asemenea, responsabili pentru crearea instrumentelor necesare pentru oamenii de știință de date pentru a construi, antrena, implementa și valida modelele lor ML în producție.
Deepak Mettem este Senior Engineering Manager în VMware, Carbon Black Unit. El și echipa sa lucrează la construirea de aplicații și servicii bazate pe streaming, care sunt foarte disponibile, scalabile și rezistente pentru a oferi clienților soluții bazate pe învățarea automată în timp real. El și echipa sa sunt, de asemenea, responsabili pentru crearea instrumentelor necesare pentru oamenii de știință de date pentru a construi, antrena, implementa și valida modelele lor ML în producție.
 Mahima Agarwal este inginer de învățare automată în VMware, unitate Carbon Black.
Mahima Agarwal este inginer de învățare automată în VMware, unitate Carbon Black.
Ea lucrează la proiectarea, construirea și dezvoltarea componentelor de bază și arhitecturii platformei de învățare automată pentru VMware CB SBU.
 Vamshi Krishna Enabothala este un arhitect Sr. Specialist AI aplicat la AWS. Lucrează cu clienți din diferite sectoare pentru a accelera inițiativele de date cu impact mare, analize și învățare automată. Este pasionat de sistemele de recomandare, NLP și domeniile de viziune computerizată în AI și ML. În afara serviciului, Vamshi este un entuziast RC, construiește echipamente RC (avioane, mașini și drone) și îi place, de asemenea, grădinăritul.
Vamshi Krishna Enabothala este un arhitect Sr. Specialist AI aplicat la AWS. Lucrează cu clienți din diferite sectoare pentru a accelera inițiativele de date cu impact mare, analize și învățare automată. Este pasionat de sistemele de recomandare, NLP și domeniile de viziune computerizată în AI și ML. În afara serviciului, Vamshi este un entuziast RC, construiește echipamente RC (avioane, mașini și drone) și îi place, de asemenea, grădinăritul.
 Sahil Thapar este arhitect de soluții pentru întreprinderi. Lucrează cu clienții pentru a-i ajuta să creeze aplicații foarte disponibile, scalabile și rezistente pe AWS Cloud. În prezent, se concentrează pe containere și soluții de învățare automată.
Sahil Thapar este arhitect de soluții pentru întreprinderi. Lucrează cu clienții pentru a-i ajuta să creeze aplicații foarte disponibile, scalabile și rezistente pe AWS Cloud. În prezent, se concentrează pe containere și soluții de învățare automată.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- Platoblockchain. Web3 Metaverse Intelligence. Cunoștințe amplificate. Accesați Aici.
- Sursa: https://aws.amazon.com/blogs/machine-learning/how-vmware-built-an-mlops-pipeline-from-scratch-using-gitlab-amazon-mwaa-and-amazon-sagemaker/
- :este
- $UP
- 1
- 10
- 100
- 7
- 8
- a
- Despre Noi
- accelera
- acces
- accesate
- în consecință
- Conturi
- realizat
- peste
- aciclic
- plus
- Suplimentar
- informatii suplimentare
- După
- împotriva
- AI
- algoritmi
- TOATE
- permite
- Amazon
- Amazon SageMaker
- analiză
- Google Analytics
- și
- oriunde
- Apache
- api
- aplicație
- aplicatii
- aplicat
- AI aplicată
- aprobare
- arhitectură
- SUNT
- domenii
- AS
- aspect
- At
- Atacuri
- autor
- Auto
- Automata
- automate
- disponibilitate
- disponibil
- evita
- AWS
- Backend
- Sold
- bazat
- de bază
- BE
- deoarece
- Început
- Beneficiile
- CEL MAI BUN
- Mai bine
- între
- Negru
- Bloca
- Branch firma
- aduce
- construi
- Clădire
- construit
- povară
- by
- CAN
- nu poti
- capacități
- carbon
- masini
- caz
- CB
- sigur
- Modificări
- canale
- copil
- a ales
- Cloud
- Grup
- cod
- colectare
- Comunicare
- comparație
- Completă
- componente
- Calcula
- calculator
- Computer Vision
- conduite
- Configuraţie
- configuraţiile
- În conflict
- confuzie
- Considerații
- consuma
- consumate
- Recipient
- Containere
- continuu
- Convenabil
- Nucleu
- ar putea
- țări
- Procesor
- crea
- a creat
- creează
- Crearea
- critic
- crucial
- În prezent
- personalizat
- clienţii care
- personaliza
- atacuri cibernetice
- DAG
- zilnic
- tablou de bord
- de date
- om de știință de date
- zi
- definit
- livrarea
- implementa
- dislocate
- Implementarea
- desfășurarea
- implementări
- implementează
- Amenajări
- proiectat
- proiect
- detaliat
- detalii
- Detectare
- dev
- dezvoltat
- în curs de dezvoltare
- Dezvoltare
- diferit
- direct
- discuta
- discutat
- Docher
- Dont
- jos
- Drone
- fiecare
- Mai devreme
- Devreme
- ușurință în utilizare
- eficient
- oricare
- șmirghel
- permite
- activat
- permite
- încuraja
- un capăt la altul
- Punct final
- inginer
- Inginerie
- Afacere
- Soluții pentru întreprinderi
- entuziast
- medii
- echipament
- esenţial
- Eter (ETH)
- evalua
- evaluat
- evaluarea
- evaluare
- evaluări
- Chiar
- eveniment
- Fiecare
- tot
- exemplu
- Extinde
- extindere
- f1
- facilita
- Eșec
- departe
- mai repede
- Caracteristică
- DESCRIERE
- puțini
- Fişiere
- First
- flexibil
- Concentra
- concentrat
- se concentrează
- următor
- Pentru
- format
- din
- Complet
- Full Spectrum
- complet
- funcţie
- funcții
- mai mult
- viitor
- generată
- obține
- bine
- grup
- Avea
- având în
- ajutor
- a ajutat
- ajută
- Înalt
- performanta ridicata
- extrem de
- găzduire
- Cum
- Totuși
- HTML
- http
- HTTPS
- IAM
- ID
- ideal
- identificat
- identifica
- Identitate
- imagine
- imagini
- punerea în aplicare a
- implementarea
- implementat
- in
- include
- include
- Inclusiv
- informații
- Infrastructură
- inițiative
- perspective
- integra
- integrate
- integreaza
- integrare
- interacţiona
- intervenţie
- invocă
- implicat
- izolare
- IT
- ESTE
- Loc de munca
- Locuri de munca
- jpg
- A pastra
- Cheie
- chei
- Latență
- strat
- învățat
- învăţare
- Lectii
- Lectii invatate
- Permite
- Nivel
- ciclu de viață
- ca
- mic
- încărca
- Jos
- maşină
- masina de învățare
- Principal
- menține
- susține
- întreținere
- face
- administra
- gestionate
- administrare
- manager
- gestionează
- de conducere
- manual
- Matrice
- Memorie
- menționat
- mesaje
- mesagerie
- Metrici
- ar putea
- milisecundă
- minute
- ML
- MLOps
- model
- Modele
- Modern
- monitor
- Monitorizarea
- mai mult
- mai eficient
- multiplu
- nume
- natural
- necesar
- Nevoie
- Nou
- următor
- nlp
- Zgomot
- notificare
- notificări
- număr
- of
- oferind
- promoții
- on
- ONE
- operațional
- Operatorii
- optimizate
- Opţiuni
- orchestrat
- Organizat
- Altele
- exterior
- global
- pachet
- ofertele
- ambalaje
- parte
- trece
- Care trece
- pasionat
- cale
- performanță
- permisiune
- conducte
- plan
- Avioane
- platformă
- Plato
- Informații despre date Platon
- PlatoData
- Politicile
- Politica
- Post
- practică
- Predictii
- precedent
- Prioritizarea
- proces
- Produs
- producere
- proiect
- Proiecte
- adecvat
- protecţie
- prevăzut
- furnizorul
- furnizează
- publica
- publicat
- publică
- Editare
- scopuri
- calificat
- gamă
- în timp real
- Recomandare
- Redus
- menționat
- înregistrată
- registru
- Relaţii
- la distanta
- Renumit
- depozit
- solicitat
- cereri de
- necesar
- Cerinţe
- cercetare
- elastic
- răspuns
- responsabil
- REZULTATE
- reconversie profesională
- reutilizabile
- rolurile
- Alerga
- alergător
- sagemaker
- acelaşi
- scalabil
- scalare
- programa
- programată
- Om de stiinta
- oamenii de stiinta
- Al doilea
- secțiuni
- sectoare
- securitate
- senior
- distinct
- serverless
- Servere
- serviciu
- Servicii
- servire
- set
- configurarea
- Umbră
- SCHIMBARE
- să
- indicat
- simplu
- moale
- So
- până acum
- Software
- soluţie
- soluţii
- unele
- Sursă
- cod sursă
- specialist
- specific
- specificată
- Spectru
- Reflector
- Etapă
- Stadiile
- standard
- Începe
- începe
- Statele
- paşi
- depozitare
- Strategie
- de streaming
- simplifica
- ulterior
- Reușit
- astfel de
- a sustine
- Suportat
- Suprafață
- sisteme
- TAG
- Lua
- sarcini
- echipă
- şabloane
- Terraform
- Testarea
- acea
- lor
- Lor
- prin urmare
- Acestea
- amenințări
- trei
- Prin
- de-a lungul
- debit
- timp
- timestamp-ul
- la
- împreună
- de asemenea
- instrument
- Unelte
- top
- subiect
- urmări
- Urmărire
- mărci comerciale
- trafic
- Tren
- dresat
- Pregătire
- declanşa
- a declanșat
- ÎNTORCĂ
- în
- unitate
- Unit
- Statele Unite
- actualizări
- us
- Folosire
- utilizare
- carcasa de utilizare
- Utilizator
- utilizatorii
- VALIDA
- validare
- variabile
- diverse
- versiune
- practic
- viziune
- imagina
- VMware
- volum
- Cale..
- BINE
- Ce
- dacă
- care
- larg
- Gamă largă
- cu
- în
- fără
- Apartamente
- flux de lucru
- fluxuri de lucru
- fabrică
- ar
- zephyrnet
- Zip
- zone