Introducere
Lumea auditării datelor poate fi complexă, cu multe provocări de depășit. Una dintre cele mai mari provocări este gestionarea atributelor categorice în timp ce se ocupă cu seturile de date. În acest articol, vom aprofunda în lumea auditării datelor, a detectării anomaliilor și a impactului codificării atributelor categoriale asupra modelelor.
Una dintre principalele provocări asociate cu detectarea anomaliilor pentru auditarea datelor este gestionarea atributelor categorice. Codificarea atributelor categoriale este obligatorie deoarece modelele nu pot interpreta introducerea textului. În mod obișnuit, acest lucru se face utilizând codarea Label sau One Hot. Cu toate acestea, într-un set de date mare, codificarea One-hot poate duce la performanțe slabe ale modelului din cauza blestemului dimensionalității.
obiective de invatare
-
Pentru a înțelege conceptul de auditare a datelor și provocarea
- Pentru a evalua diferite metode de detecție profundă nesupravegheată a anomaliilor.
- Pentru a înțelege impactul codificării atributelor categoriale asupra modelelor utilizate pentru detectarea anomaliilor în datele de audit.
Acest articol a fost publicat ca parte a Blogathon Data Science.
Cuprins
- Ce este Auata?
- Ce este detectarea anomaliilor?
- Provocări majore cu care se confruntă la auditarea datelor
- Auditarea seturilor de date pentru detectarea anomaliilor
- Codificarea atributelor categoriale
- Codificări categoriale
- Modele de detectare a anomaliilor nesupravegheate
- Cum afectează codificarea atributelor categoriale modelele?
8.1 Reprezentarea t-SNE a setului de date privind asigurarea auto
8.2 Reprezentarea t-SNE a setului de date privind asigurarea vehiculelor
8.3 Reprezentarea t-SNE a setului de date privind reclamațiile pentru vehicule - Concluzie
la datele de auditare?
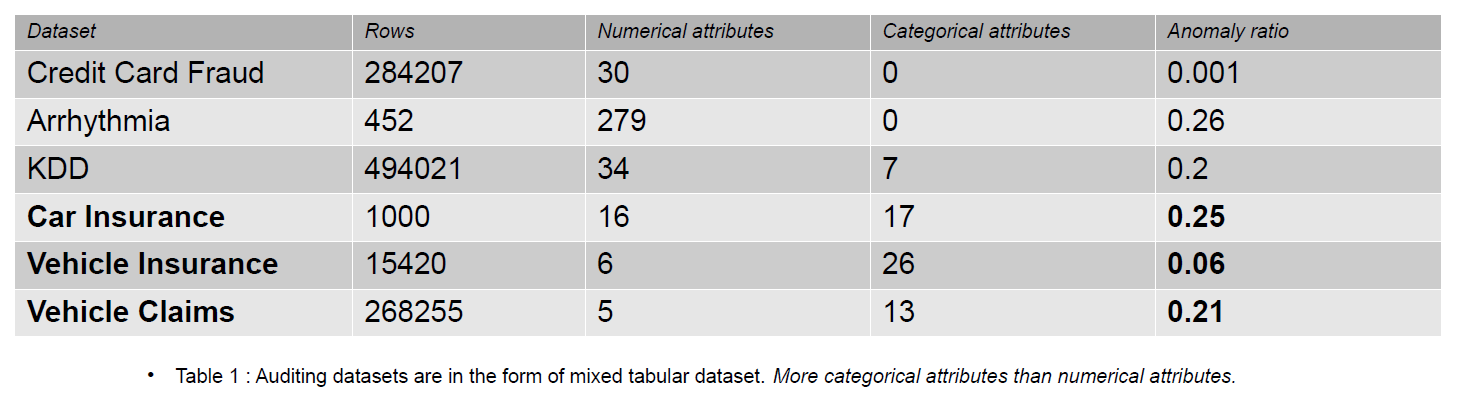
Datele de audit pot include jurnalele, daunele de asigurare și datele de intruziune pentru sistemele informaționale; în acest articol, exemplele oferite sunt daune de asigurare ale vehiculelor. Daunele de asigurare se disting de seturile de date de detectare a anomaliilor, de exemplu, KDD, printr-un număr mai mare de caracteristici categorice.
Caracteristicile categoriale sunt discutate în datele noastre care pot fi fie de tip întreg, fie de tip caracter. Caracteristicile numerice sunt atribute continue în datele noastre care sunt întotdeauna cu valoare reală. Seturile de date cu caracteristici numerice sunt populare în comunitatea de detectare a anomaliilor, cum ar fi datele privind frauda cu cardul de credit. Cele mai multe dintre seturile de date disponibile public conțin mai puține caracteristici categorice decât datele privind daunele de asigurare. Caracteristicile categoriale sunt mai mult ca număr decât caracteristicile numerice în seturile de date privind daunele de asigurare.
O cerere de asigurare include caracteristici precum Model, Brand, Venituri, Cost, Problemă, Culoare etc. Numărul de caracteristici categorice este mai mare în datele de audit decât în seturile de date Card de credit și KDD. Aceste seturi de date sunt repere în metodele de detectare a anomaliilor nesupravegheate. După cum se vede în tabelul de mai jos, seturile de date privind daunele de asigurări au caracteristici mai categorice, care sunt importante pentru înțelegerea comportamentului datelor frauduloase.
Seturile de date de audit utilizate pentru a evalua impactul codificărilor categoriale sunt asigurarea auto, asigurarea vehiculelor și reclamațiile vehiculelor.
Ce este detectarea anomaliilor?
O anomalie este o observație situată departe de datele normale dintr-un set de date cu o anumită distanță (Prag). În ceea ce privește datele de audit, preferăm termenul de date frauduloase. Detectarea anomaliilor face distincția între datele normale și cele frauduloase folosind învățarea automată sau modelul de învățare profundă. Diferite metode poate fi utilizat pentru detectarea anomaliilor, cum ar fi estimarea densității, eroarea de reconstrucție și metodele de clasificare.
- Estimarea densității – Aceste metode estimează distribuția normală a datelor și clasifică datele anormale dacă nu au fost eșantionate din distribuția învățată.
- Eroare de reconstrucție – Metodele bazate pe erori de reconstrucție se bazează pe principiul că datele normale pot fi reconstruite cu pierderi mai mici decât datele anormale. Cu cât pierderea de reconstrucție este mai mare, crește șansele ca datele să fie o anomalie.
- Metode de clasificare - Metode de clasificare precum Pădurea întâmplătoare, Isolation Forest, One Class – Support Vector Machines și Local Outlier Factors pot fi utilizate pentru detectarea anomaliilor. Clasificarea în detectarea anomaliilor implică identificarea uneia dintre clase ca anomalie. Totuși, clasele sunt împărțite în două grupuri (0 și 1) în scenariul cu mai multe clase, iar clasa cu mai puține date este clasa anormală.
Rezultatele metodelor de mai sus sunt scoruri de anomalii sau erori de reconstrucție. Apoi trebuie să decidem asupra unui prag, în funcție de care clasificăm datele anormale.
Provocări majore cu care se confruntă la auditarea datelor
- Tratarea atributelor categoriale: Codificarea atributelor categoriale este obligatorie deoarece modelul nu poate interpreta textul introdus. Deci, valorile sunt codificate cu codificare Label sau One Hot. Dar într-un set de date mare, One hot encoding transformă datele într-un spațiu dimensional mare prin creșterea numărului de atribute. Modelul are performanțe slabe din cauza blestem de dimensionalitate.
- Selectarea pragului pentru clasificare: Dacă datele nu sunt etichetate, este dificil de evaluat performanța modelului deoarece nu cunoaștem numărul de anomalii prezente în setul de date. Cunoștințele anterioare despre setul de date facilitează determinarea pragului. Să presupunem că avem 5 din 10 eșantioane anormale în datele noastre. Deci, putem selecta pragul la scorul de 50 de procente.
- Seturi de date publice: Cele mai multe seturi de date de audit sunt confidențiale deoarece aparțin companiilor corporative și conțin informații sensibile și personale. O modalitate posibilă de a atenua problemele de confidențialitate este antrenamentul folosind seturi de date sintetice (vehicule Claims).
Auditarea seturilor de date pentru detectarea anomaliilor
Cererile de asigurare pentru vehicule includ informații despre proprietățile vehiculului, cum ar fi modelul, marca, prețul, anul și tipul de combustibil. Include informații despre șofer, data nașterii, sexul și profesia. În plus, cererea poate include informații despre costul total al reparației. Seturile de date utilizate în acest articol sunt toate dintr-un singur domeniu, dar variază în ceea ce privește numărul de atribute și numărul de instanțe.
-
Setul de date Vehicle Claims este mare, conținând peste 250,000 de rânduri, iar atributele sale categoriale au o cardinalitate de 1171. Datorită dimensiunii sale mari, acest set de date suferă de blestemul dimensionalității.
- Setul de date privind asigurarea vehiculelor este de dimensiune medie, cu 15,420 de rânduri și 151 de valori categorice unice. Acest lucru îl face mai puțin predispus să sufere de blestemul dimensionalității.
- Setul de date privind asigurările auto este mic, cu etichete și mostre anormale de 25% și conține un număr similar de caracteristici numerice și categoriale. Cu 169 de categorii unice, nu suferă de blestemul dimensionalității.
Codificarea atributelor categoriale
Diferite codificări ale valorilor categorice
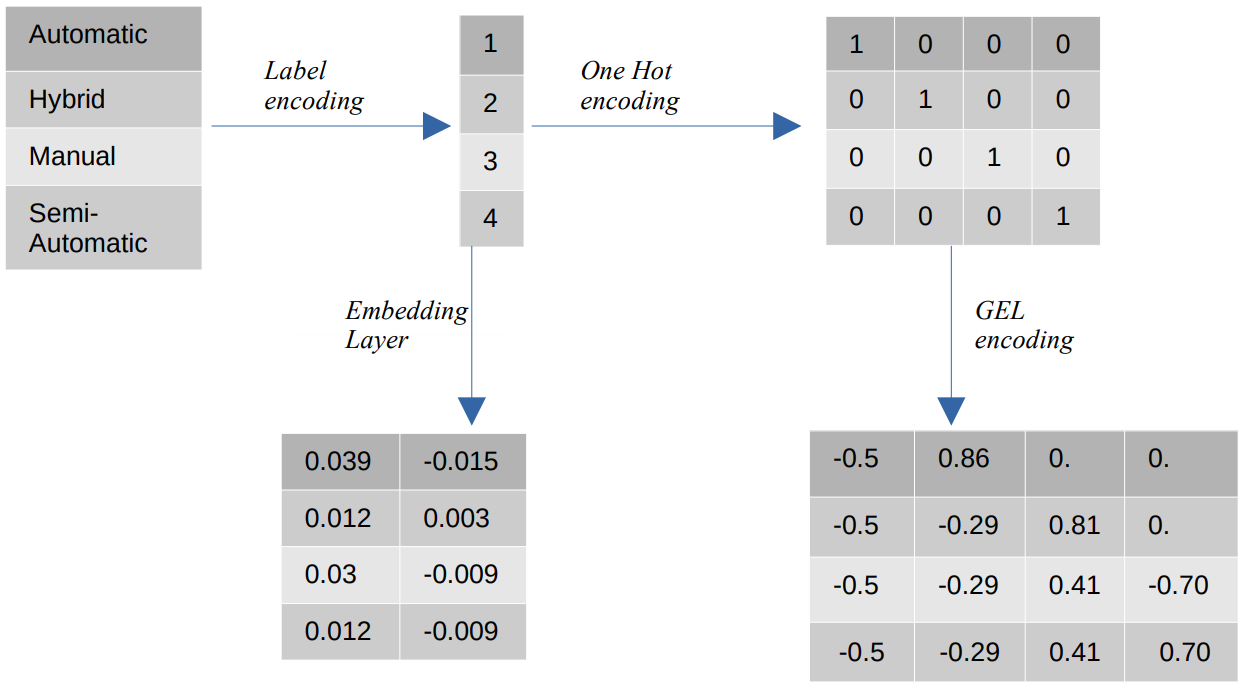
- Codificarea etichetelor – În codificarea etichetelor, valorile categoriale sunt înlocuite cu valori numerice întregi între 1 și numărul de categorii. Codificarea etichetelor reprezintă categoriile în modul prevăzut pentru valorile ordinale. Totuși, atunci când caracteristicile sunt nominale, reprezentarea este incorectă, deoarece valorile categoriale nu sunt conforme cu o anumită ordine.
De exemplu, dacă avem categorii precum Automat, Hibrid, Manual și Semi-automat într-o caracteristică, codificarea etichetelor transformă aceste valori în {1: Automatic, 2: Hybrid, 3: Manual, 4:Semi-Automatic}. Această reprezentare nu oferă informații despre valorile categoriale, dar o reprezentare precum {0: Scăzut, 1: Mediu, 2: Ridicat} oferă o reprezentare clară, deoarece variabilei caracteristice Scăzut i se atribuie o valoare numerică mai mică. Prin urmare, codificarea etichetelor este mai bună pentru valorile ordinale, dar dezavantajoasă pentru valorile nominale. - O codare la cald – One Hot encoding este folosită pentru a aborda problema valorilor nominale de codare, care transformă fiecare valoare categorială într-o caracteristică distinctă în setul de date constând din valori binare. De exemplu, în cazul a patru categorii diferite codificate ca {1, 2, 3, 4}, One Hot encoding ar crea funcții noi, cum ar fi {Automatic: [1,0,0,0], Hybrid: [0,1,0,0] ,0,0,1,0], Manual: [0,0,0,1], Semi-automat: [XNUMX]}.
Dimensiunea setului de date depinde apoi direct de numărul de categorii prezente în setul de date. Drept urmare, codificarea One Hot poate duce la blestemul dimensionalității, care este un dezavantaj al acestei metode de codare. - Codificare GEL – Codarea GEL este o tehnică de încorporare care poate fi utilizată în metodele de învățare supravegheate și nesupravegheate. Se bazează pe principiul codării One Hot și poate fi folosit pentru a reduce dimensionalitatea caracteristicilor categoriale care au fost codificate folosind codificarea One Hot.
- Strat de încorporare - Încorporarea cuvintelor oferă o modalitate de a utiliza o reprezentare compactă și densă în care cuvintele similare au codificări similare. O încorporare este un vector dens de valori în virgulă mobilă care sunt parametri antrenabili. Înglobările de cuvinte pot varia de la 8-dimensionale (pentru seturi de date mici) la 1024-dimensionale (pentru seturi de date mari).
O încorporare dimensională mai mare poate capta relații mai detaliate între cuvinte, dar necesită mai multe date pentru a învăța. Stratul de încorporare este un tabel de căutare care convertește fiecare cuvânt prezent în matrice într-un vector de o anumită dimensiune.
Modele de detectare a anomaliilor nesupravegheate
În lumea reală, datele nu sunt etichetate în majoritatea cazurilor, iar etichetarea datelor este costisitoare și necesită timp. Prin urmare, vom folosi modele nesupravegheate pentru evaluările noastre.
- SOM - Harta de auto-organizare (SOM) este o metodă de învățare competitivă în care greutățile neuronilor sunt actualizate în mod competitiv, mai degrabă decât să utilizeze învățarea prin retropropagare. SOM constă dintr-o hartă de neuroni, fiecare cu un vector de greutate de aceeași dimensiune ca vectorul de intrare. Vectorul de greutate este inițializat cu greutăți aleatorii înainte de începerea antrenamentului. În timpul antrenamentului, fiecare intrare este comparată cu neuronii hărții pe baza unei metrici a distanței (de exemplu, distanța euclidiană) și este mapată la cea mai bună unitate de potrivire (BMU), care este neuronul cu distanța minimă până la vectorul de intrare.
Greutățile BMU sunt actualizate cu greutățile vectorului de intrare, iar neuronii vecini sunt actualizați pe baza razei de vecinătate (sigma). Deoarece neuronii concurează între ei pentru a fi cea mai bună unitate de potrivire, acest proces este cunoscut sub numele de învățare competitivă. În cele din urmă, neuronii pentru probele normale sunt mai aproape decât cei anormali. Scorurile de anomalie sunt definite de eroarea de cuantizare, care este diferența dintre eșantionul de intrare și ponderile celei mai bune unități de potrivire. O eroare de cuantizare mai mare indică o probabilitate mai mare ca eșantionul să fie o anomalie. - DAGMM – Modelul Deep Autoencoding Gaussian Mixture Model (DAGMM) este o metodă de estimare a densității care presupune că anomaliile se află într-o regiune cu probabilitate scăzută. Rețeaua este împărțită în două părți: o rețea de compresie, care este utilizată pentru a proiecta datele în dimensiuni mai mici folosind un autoencoder și o rețea de estimare, care este utilizată pentru a estima parametrii modelului de amestec gaussian. DAGMM estimează numărul k de amestecuri gaussiene, unde k poate fi orice număr de la 1 la N (numărul de puncte de date) și se presupune că punctele normale se află într-o regiune cu densitate mare, ceea ce înseamnă că probabilitatea de a fi eșantionat dintr-un Amestecul gaussian este mai mare pentru punctele normale decât pentru probele anormale. Scorurile anomaliilor sunt definite de energia estimată a probei.
- RSRAE – Stratul robust de recuperare a suprafeței pentru detectarea nesupravegheată a anomaliilor este o metodă de eroare de reconstrucție care proiectează mai întâi datele la o dimensiune inferioară folosind un codificator automat. Reprezentarea latentă este apoi supusă unei proiecții ortogonale pe un subspațiu liniar care este robust la valori aberante. Decodorul reconstruiește apoi ieșirea din subspațiul liniar. În această metodă, o eroare de reconstrucție mai mare indică o probabilitate mai mare ca eșantionul să fie o anomalie.
- SOM-DAGMM- O hartă auto-organizată (SOM) – Modelul mixt gaussian cu codificare automată profundă (DAGMM) este, de asemenea, un model de estimare a densității. La fel ca DAGMM, de asemenea, estimează distribuția de probabilitate a punctelor de date normale și clasifică un punct de date ca o anomalie dacă are o probabilitate scăzută de a fi eșantionat din distribuția învățată. Principala diferență dintre SOM-DAGMM și DAGMM este că SOM-DAGMM include coordonatele normalizate ale SOM pentru eșantionul de intrare, care furnizează informațiile topologice lipsă în cazul DAGMM rețelei de estimare. Obiectivul este, de asemenea, similar cu DAGMM prin aceea că scorurile anomaliilor sunt definite de energia estimată a eșantionului, iar energia scăzută indică o probabilitate mai mare ca eșantionul ca anomalie.
În continuare, vom aborda provocarea de a gestiona atributele categoriale.
Cum afectează codificarea atributelor categoriale modelele?
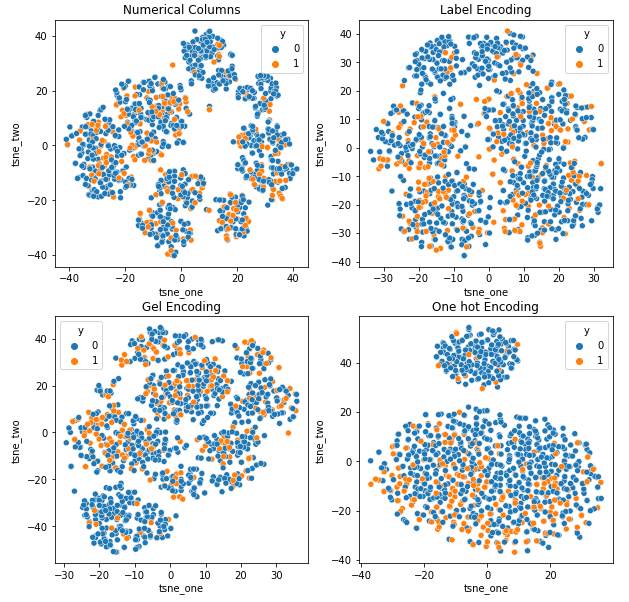
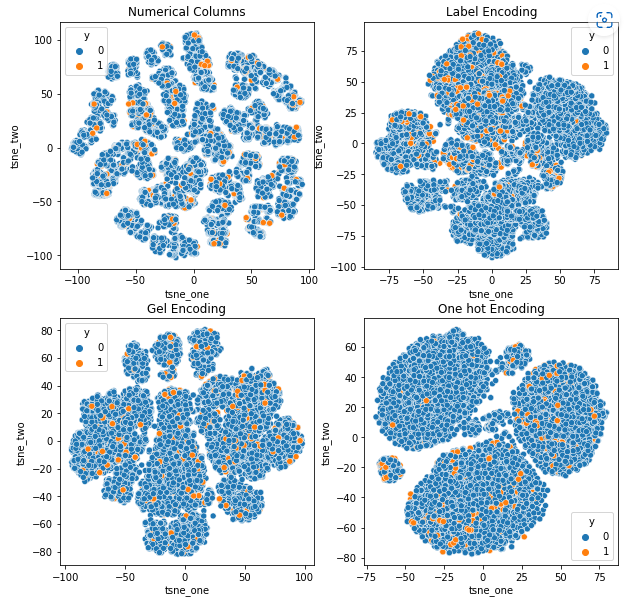
Pentru a înțelege impactul diferitelor codificări asupra seturilor de date, vom folosi t-SNE pentru a vizualiza reprezentările de dimensiuni joase ale datelor pentru diferite codificări. t-SNE proiectează date de dimensiuni înalte într-un spațiu de dimensiuni inferioare, făcându-le mai ușor de vizualizat. Prin compararea vizualizărilor t-SNE și a rezultatelor numerice ale diferitelor codificări ale aceluiași set de date, diferența este observată în reprezentările rezultate și înțelegerea impactului codificării asupra setului de date.
Reprezentarea t-SNE a setului de date privind asigurările auto
Reprezentarea t-SNE a setului de date privind asigurarea vehiculelor
-
Datele sunt mai aproape unele de altele, deoarece numărul de rânduri este mai mare decât în setul de date Asigurări auto. Devine dificil de separat cu o dimensionalitate crescută în codificarea One Hot.
-
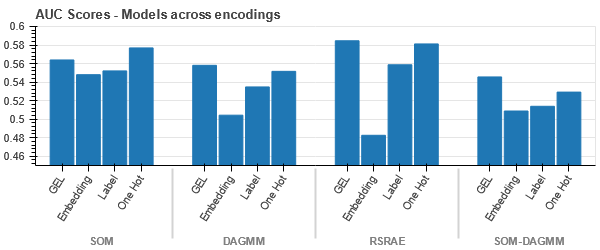
Codificarea GEL este mai bună decât codarea One Hot în toate cazurile, cu excepția DAGMM.
Reprezentarea t-SNE a setului de date privind reclamațiile pentru vehicule
-
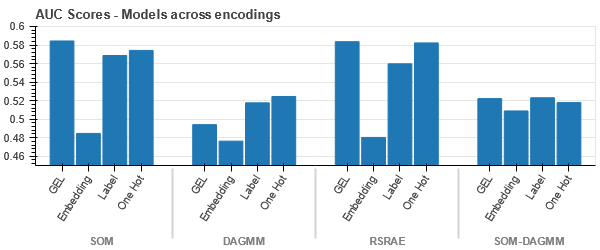
Datele sunt strâns legate în toate cazurile, ceea ce face dificilă separarea cu o dimensionalitate crescută. Acesta este unul dintre motivele performanței slabe a modelelor din cauza dimensionalității crescute.
- SOM depășește toate celelalte modele pentru acest set de date. Cu toate acestea, stratul de încorporare este mai potrivit în majoritatea cazurilor, ceea ce ne permite o alternativă la codificare atribute categoriale pentru detectarea anomaliilor.
Concluzie
Acest articol prezintă o scurtă prezentare generală a datelor de audit, a detectării anomaliilor și a codificărilor categoriale. Este important să înțelegeți că gestionarea atributelor categorice în datele de audit este o provocare. Înțelegând impactul codificării atributelor asupra modelelor, putem îmbunătăți acuratețea detectării anomaliilor în seturile de date. Principalele concluzii din acest articol sunt:
- Pe măsură ce dimensiunea datelor crește, este important să folosiți abordări alternative de codificare pentru atribute categorice, cum ar fi codificarea GEL și straturile de încorporare, deoarece codarea One Hot este nepotrivită.
- Un model nu funcționează pentru toate seturile de date. Pentru seturile de date tabelare, cunoașterea domeniului este extrem de importantă.
- Alegerea metodei de codificare depinde de alegerea modelului.
Codul pentru evaluarea modelelor este disponibil pe GitHub.
Media prezentată în acest articol nu este deținută de Analytics Vidhya și este utilizată la discreția Autorului.
Legate de
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- Platoblockchain. Web3 Metaverse Intelligence. Cunoștințe amplificate. Accesați Aici.
- Sursa: https://www.analyticsvidhya.com/blog/2023/01/impact-of-categorical-encodings-on-anomaly-detection-methods/
- 000
- 1
- 10
- 420
- a
- Despre Noi
- mai sus
- Conform
- precizie
- În plus,
- adresa
- TOATE
- permite
- alternativă
- mereu
- Google Analytics
- Analize Vidhya
- și
- detectarea anomaliilor
- abordari
- articol
- alocate
- asociate
- asumat
- atribute
- audit
- Automat
- disponibil
- bazat
- deoarece
- devine
- înainte
- fiind
- de mai jos
- valori de referință
- CEL MAI BUN
- Mai bine
- între
- Cea mai mare
- legat
- marca
- nu poti
- captura
- mașină
- asigurare auto
- card
- caz
- cazuri
- categorii
- contesta
- provocări
- provocare
- șansele
- caracter
- alegere
- pretinde
- creanțe
- clasă
- clase
- clasificare
- Clasifica
- clar
- mai aproape
- cod
- culoare
- în mod obișnuit
- comunitate
- Companii
- comparație
- compararea
- concura
- competitiv
- complex
- concept
- confidențialitate
- Constând
- conține
- continuu
- Istoria
- A costat
- crea
- credit
- card de credit
- de date
- puncte de date
- seturi de date
- Data
- abuzive
- scădea
- adânc
- învățare profundă
- depinde de
- detaliat
- Detectare
- Determina
- diferenţă
- diferit
- dificil
- Dimensiune
- Dimensiuni
- direct
- discreție
- distanţă
- distinct
- distribuire
- împărțit
- domeniu
- şofer
- în timpul
- fiecare
- mai ușor
- oricare
- energie
- eroare
- Erori
- estima
- estimativ
- estimări
- etc
- evalua
- evaluare
- evaluări
- exemplu
- exemple
- Cu excepția
- scump
- extrem
- cu care se confruntă
- factori
- Caracteristică
- DESCRIERE
- First
- pădure
- fraudă
- necinstit
- din
- Combustibil
- Gen
- Grupului
- Manipularea
- Înalt
- superior
- FIERBINTE
- Totuși
- HTTPS
- Hibrid
- identificarea
- Impactul
- important
- îmbunătăţi
- in
- include
- include
- Venituri
- a crescut
- Creșteri
- crescând
- indică
- informații
- Sisteme de informare
- intrare
- asigurare
- izolare
- problema
- probleme de
- IT
- Cheie
- Cunoaște
- cunoştinţe
- cunoscut
- Etichetă
- etichetarea
- etichete
- mare
- mai mare
- strat
- straturi
- conduce
- AFLAȚI
- învățat
- învăţare
- local
- situat
- căutare
- de pe
- pierderi
- Jos
- maşină
- masina de învățare
- Masini
- Principal
- FACE
- Efectuarea
- obligatoriu
- manual
- multe
- Hartă
- potrivire
- Matrice
- sens
- Mass-media
- mediu
- metodă
- Metode
- metric
- minim
- dispărut
- diminua
- amestec
- model
- Modele
- mai mult
- cele mai multe
- reţea
- neuronii
- Nou
- Funcții noi
- normală.
- număr
- obiectiv
- ONE
- comandă
- Altele
- surclasează
- Învinge
- Prezentare generală
- deţinute
- parametrii
- parte
- piese
- performanță
- efectuează
- personal
- Plato
- Informații despre date Platon
- PlatoData
- Punct
- puncte
- sărac
- Popular
- posibil
- a prefera
- prezenta
- cadouri
- preţ
- principiu
- anterior
- probabilitate
- Problemă
- proces
- profesie
- proiect
- datele proiectului
- Proiectare
- Proiecte
- proprietăţi
- furniza
- prevăzut
- furnizează
- publicat
- aleator
- gamă
- real
- lumea reală
- motive
- recuperare
- regiune
- Relaţii
- repararea
- înlocuiește
- reprezentare
- reprezintă
- Necesită
- rezultat
- rezultând
- REZULTATE
- robust
- acelaşi
- Ştiinţă
- sensibil
- distinct
- indicat
- Sigma
- asemănător
- întrucât
- singur
- Mărimea
- mic
- mai mici
- So
- Spaţiu
- specific
- începe
- Încă
- astfel de
- suferă
- potrivit
- a sustine
- Suprafață
- sintetic
- sisteme
- tabel
- Takeaways
- termeni
- lumea
- prin urmare
- prag
- strans
- consumă timp
- la
- Total
- Tren
- Pregătire
- înţelege
- înţelegere
- unic
- unitate
- învățare nesupravegheată
- actualizat
- us
- utilizare
- valoare
- Valori
- vehicul
- Vehicule
- greutate
- Ce
- Ce este
- care
- în timp ce
- voi
- Cuvânt
- cuvinte
- Apartamente
- lume
- ar
- an
- zephyrnet