Modelul lingvistic mare (LLM) a schimbat modul în care oamenii lucrează. Cu un model precum familia GPT care este utilizat pe scară largă, toată lumea s-a obișnuit cu aceste modele. Folosind puterea LLM, putem obține rapid răspuns la întrebările noastre, codul de depanare și altele. Acest lucru face ca modelul să fie util în multe aplicații.
Una dintre provocările LLM este că modelul este nepotrivit pentru aplicațiile de streaming din cauza incapacității modelului de a gestiona conversații lungi, care depășesc durata predefinită a secvenței de antrenament. În plus, există o problemă cu consumul mai mare de memorie.
De aceea, aceste probleme de mai sus generează cercetări pentru a le rezolva. Ce este această cercetare? Să intrăm în asta.
StreamingLLM este un cadru stabilit de Xiao et al. (2023) cercetare pentru a aborda problemele aplicațiilor de streaming. Metodele existente sunt contestate deoarece fereastra de atenție constrânge LLM-urile în timpul pre-training.
Atenția fereastră tehnica ar putea fi eficientă, dar are de suferit atunci când se manipulează texte mai lungi decât dimensiunea sa cache. De aceea, cercetătorul a încercat să folosească stările Cheie și Valoare ale mai multor token-uri inițiale (attention sink) cu token-urile recente. Comparația dintre StreamingLLM și celelalte tehnici poate fi văzută în imaginea de mai jos.

StreamingLLM vs metoda existentă (Xiao et al. (2023))
Putem vedea cum StreamingLLM abordează provocarea folosind metoda atenției. Acest receptor de atenție (token-uri inițiale) este folosit pentru calcularea stabilă a atenției și îl combină cu jetoane recente pentru eficiență și menține performanța stabilă pe texte mai lungi.
În plus, metodele existente suferă de optimizarea memoriei. Cu toate acestea, LLM evită aceste probleme prin menținerea unei ferestre de dimensiune fixă asupra stărilor Cheie și Valoare ale celor mai recente jetoane. Autorul menționează, de asemenea, beneficiul StreamingLLM ca linie de bază pentru recalcularea ferestrei glisante cu o accelerare de până la 22.2×.
Din punct de vedere al performanței, StreamingLLM oferă o precizie excelentă în comparație cu metoda existentă, așa cum se vede în tabelul de mai jos.
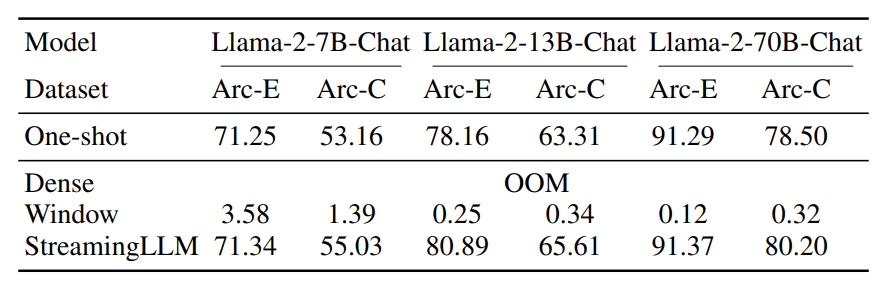
Precizia streaming LLM (Xiao et al. (2023))
Tabelul de mai sus arată că acuratețea StreamingLLM poate depăși celelalte metode din seturile de date de referință. De aceea, StreamingLLM ar putea avea potențial pentru multe aplicații de streaming.
Pentru a încerca StreamingLLM, le puteți vizita Pagina GitHub. Clonați depozitul în directorul dorit și utilizați următorul cod în CLI pentru a seta mediul.
conda create -yn streaming python=3.8
conda activate streaming pip install torch torchvision torchaudio
pip install transformers==4.33.0 accelerate datasets evaluate wandb scikit-learn scipy sentencepiece python setup.py develop
Apoi, puteți utiliza următorul cod pentru a rula chatbot-ul Llama cu LLMstreaming.
CUDA_VISIBLE_DEVICES=0 python examples/run_streaming_llama.py --enable_streaming
Comparația generală a eșantionului cu StreamingLLM poate fi afișată în imaginea de mai jos.
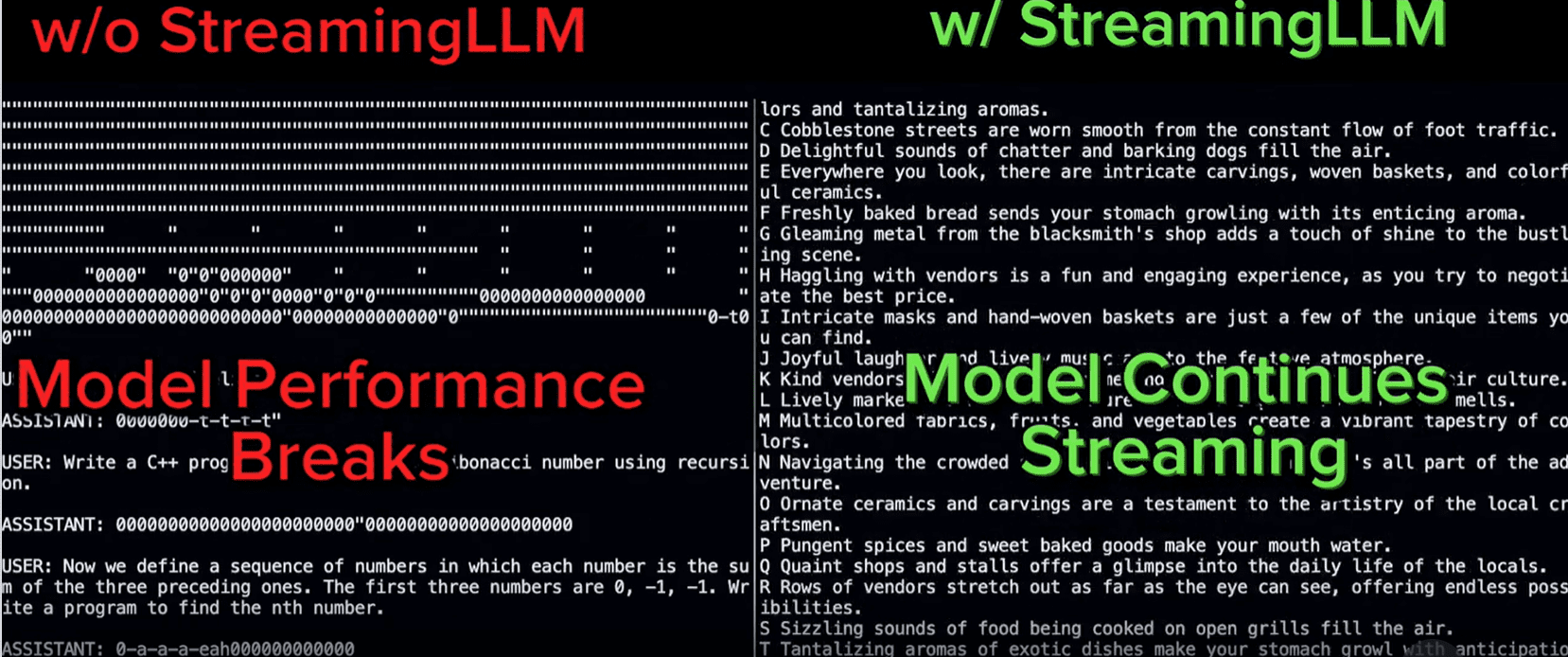
StreamingLLM a arătat performanțe remarcabile în conversații mai extinse (Streaming-llm)
Asta e tot pentru introducerea StreamingLLM. În general, cred că StreamingLLM poate avea un loc în aplicațiile de streaming și poate ajuta la schimbarea modului în care funcționează aplicația în viitor.
A avea un LLM în aplicații de streaming ar ajuta afacerea pe termen lung; cu toate acestea, există provocări de implementat. Majoritatea LLM-urilor nu pot depăși lungimea predefinită a secvenței de antrenament și au un consum mai mare de memorie. Xiao et al. (2023) a dezvoltat un nou cadru numit StreamingLLM pentru a gestiona aceste probleme. Folosind StreamingLLM, acum este posibil să aveți LLM funcțional în aplicația de streaming.
Cornellius Yudha Wijaya este un asistent manager și redactor de date pentru știința datelor. În timp ce lucrează cu normă întreagă la Allianz Indonesia, îi place să împărtășească sfaturi Python și date prin intermediul rețelelor sociale și al rețelelor de scris.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- PlatoData.Network Vertical Generative Ai. Împuterniciți-vă. Accesați Aici.
- PlatoAiStream. Web3 Intelligence. Cunoștințe amplificate. Accesați Aici.
- PlatoESG. carbon, CleanTech, Energie, Mediu inconjurator, Solar, Managementul deșeurilor. Accesați Aici.
- PlatoHealth. Biotehnologie și Inteligență pentru studii clinice. Accesați Aici.
- Sursa: https://www.kdnuggets.com/introduction-to-streaming-llm-llms-for-infinite-length-inputs?utm_source=rss&utm_medium=rss&utm_campaign=introduction-to-streaming-llm-llms-for-infinite-length-inputs
- :are
- :este
- $UP
- 2023
- 22
- 33
- 7
- 8
- 9
- a
- mai sus
- accelera
- precizie
- În plus,
- TOATE
- Allianz
- de asemenea
- an
- și
- aplicație
- aplicatii
- SUNT
- AS
- Asistent
- At
- atenţie
- autor
- De bază
- BE
- deoarece
- Crede
- de mai jos
- Benchmark
- beneficia
- afaceri
- dar
- by
- cache
- denumit
- CAN
- contesta
- contestate
- provocări
- Schimbare
- si-a schimbat hainele;
- chatbot
- cod
- combină
- comparație
- comparație
- calcul
- consum
- conversații
- ar putea
- crea
- de date
- știința datelor
- seturi de date
- dezvoltat
- în timpul
- eficiență
- eficient
- Mediu inconjurator
- stabilit
- evalua
- toată lumea
- depăși
- excelent
- existent
- familie
- următor
- Pentru
- Cadru
- din
- viitor
- obține
- manipula
- Manipularea
- Avea
- he
- ajutor
- superior
- Cum
- Totuși
- HTTPS
- i
- imagine
- punerea în aplicare a
- in
- incapacitate
- Indonezia
- inițială
- intrări
- instala
- destinate
- în
- Introducere
- probleme de
- IT
- ESTE
- KDnuggets
- Cheie
- limbă
- mare
- Lungime
- efectului de pârghie
- Lamă
- Lung
- mai lung
- iubeste
- mentine
- susține
- FACE
- manager
- multe
- Mass-media
- Memorie
- menționează
- metodă
- Metode
- ar putea
- model
- Modele
- mai mult
- cele mai multe
- Nou
- acum
- of
- on
- optimizare
- Altele
- Altele
- al nostru
- afară
- outperform
- remarcabil
- global
- oameni
- performanță
- Loc
- Plato
- Informații despre date Platon
- PlatoData
- posibil
- potenţial
- putere
- Problemă
- probleme
- furnizează
- Piton
- Întrebări
- repede
- recent
- depozit
- cercetare
- cercetător
- Alerga
- s
- Ştiinţă
- scikit-learn
- vedea
- văzut
- Secvenţă
- set
- configurarea
- câteva
- Distribuie
- a arătat
- indicat
- Emisiuni
- Mărimea
- alunecare
- Social
- social media
- REZOLVAREA
- Icre
- stabil
- Statele
- de streaming
- astfel de
- suferă
- tabel
- aborda
- Parime
- tehnică
- tehnici de
- decât
- acea
- Viitorul
- lor
- Lor
- Acolo.
- Acestea
- acest
- Sfaturi
- la
- indicativele
- lanternă
- Torchvision
- Pregătire
- încercat
- încerca
- utilizare
- utilizat
- util
- folosind
- valoare
- de
- Vizita
- vs
- Cale..
- we
- Ce
- Ce este
- cand
- în timp ce
- de ce
- pe larg
- fereastră
- cu
- Apartamente
- de lucru
- fabrică
- ar
- scriitor
- scris
- tu
- Ta
- zephyrnet