Pilot automat cu Amazon SageMaker este o soluție automatizată de învățare automată (AutoML) care îndeplinește toate sarcinile de care aveți nevoie pentru a finaliza un flux de lucru end-to-end de învățare automată (ML). Acesta explorează și pregătește datele dvs., aplică diferiți algoritmi pentru a genera un model și oferă în mod transparent informații despre model și rapoarte de explicabilitate pentru a vă ajuta să interpretați rezultatele. Autopilot poate crea, de asemenea, un punct final în timp real pentru inferența online. Puteți accesa funcțiile Autopilot cu un singur clic în Amazon SageMaker Studio sau folosind SDK AWS pentru Python (Boto3) sau SDK-ul SageMaker Python.
În această postare, arătăm cum să facem predicții pe lot pe un set de date neetichetat folosind un model antrenat de Autopilot. Folosim un set de date generat sintetic, care este indicativ pentru tipurile de caracteristici pe care le vedeți de obicei atunci când estimați pierderea clienților.
Prezentare generală a soluțiilor
Lot inferență sau Offline inferența, este procesul de generare a predicțiilor asupra unui lot de observații. Inferența în lot presupune că nu aveți nevoie de un răspuns imediat la o solicitare de predicție a modelului, așa cum ați face atunci când utilizați un punct final de model online, în timp real. Predicțiile offline sunt potrivite pentru seturi de date mai mari și în cazurile în care vă puteți permite să așteptați câteva minute sau ore pentru un răspuns. În contrast, on-line inferența generează predicții ML în timp real și este denumită în mod adecvat în timp real deducere sau dinamic deducere. De obicei, aceste predicții sunt generate pe baza unei singure observații a datelor în timpul execuției.
Pierderea clienților este costisitoare pentru orice afacere. Identificarea precoce a clienților nemulțumiți vă oferă șansa de a le oferi stimulente pentru a rămâne. Operatorii de telefonie mobilă au date istorice ale clienților care îi arată pe cei care au renunțat și pe cei care și-au menținut serviciul. Putem folosi aceste informații istorice pentru a construi un model care să prezică dacă un client va renunța folosind ML.
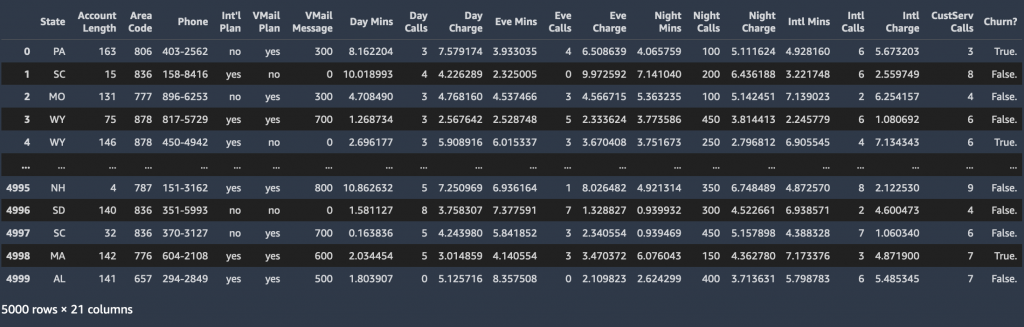
După ce antrenăm un model ML, putem transmite informațiile de profil ale unui client arbitrar (aceeași informații de profil pe care le-am folosit pentru antrenament) modelului și putem avea modelul să prezică dacă clientul va renunța sau nu. Setul de date folosit pentru această postare este găzduit în folderul sagemaker-sample-files într-un Serviciul Amazon de stocare simplă Bucket public (Amazon S3), pe care îl puteți descărca. Este format din 5,000 de înregistrări, în care fiecare înregistrare utilizează 21 de atribute pentru a descrie profilul unui client pentru un operator de telefonie mobilă necunoscut din SUA. Atributele sunt după cum urmează:
- Stat – statul SUA în care își are reședința clientul, indicat printr-o abreviere din două litere; de exemplu, TX sau CA
- Lungimea contului – Numărul de zile în care acest cont a fost activ
- Prefixul zonei – Prefix din trei cifre al numărului de telefon al clientului corespunzător
- Telefon – Numărul de telefon rămas din șapte cifre
- Planul Internațional – Are un plan de apeluri internaționale: Da/Nu
- Planul VMail – Are o funcție de mesagerie vocală: Da/Nu
- Mesaj VMail – Numărul mediu de mesaje vocale pe lună
- Ziua Min – Numărul total de minute de apel utilizate în timpul zilei
- Apeluri de zi – Numărul total de apeluri efectuate în timpul zilei
- Taxă de zi – Costul facturat al apelurilor în timpul zilei
- Eve Mins, Eve Calls, Eve Charge – Cost facturat pentru apelurile efectuate în timpul serii
- Minute de noapte, Apeluri de noapte, Taxare de noapte – Costul facturat pentru apelurile efectuate în timpul nopții
- Intl Mins, Intl Calls, Intl Charge – Costul facturat pentru apelurile internaționale
- Apeluri CustServ – Numărul de apeluri efectuate către Serviciul Clienți
- Putinei? – Clientul a părăsit serviciul: Adevărat/Fals
Ultimul atribut, Churn?, este atributul țintă pe care dorim să îl prezică modelul ML. Deoarece atributul țintă este binar, modelul nostru realizează predicție binară, cunoscută și ca clasificare binară.
Cerințe preliminare
Descărcați setul de date în mediul dvs. de dezvoltare local și explorați-l rulând următoarea comandă de copiere S3 cu Interfața liniei de comandă AWS (AWS CLI):
Apoi, puteți copia setul de date într-un compartiment S3 din propriul cont AWS. Aceasta este locația de intrare pentru Autopilot. Puteți copia setul de date în Amazon S3 fie încărcându-l manual în compartimentul dvs., fie rulând următoarea comandă folosind AWS CLI:
Creați un experiment Autopilot
Când setul de date este gata, puteți inițializa un experiment Autopilot în SageMaker Studio. Pentru instrucțiuni complete, consultați Creați un experiment Amazon SageMaker Autopilot.
În Setări de bază, puteți crea cu ușurință un experiment Autopilot furnizând un nume de experiment, locațiile de intrare și de ieșire a datelor și specificând datele țintă de estimat. Opțional, puteți specifica tipul de problemă ML pe care doriți să o rezolvați. În caz contrar, utilizați Auto setare, iar Autopilot determină automat modelul pe baza datelor pe care le furnizați.

De asemenea, puteți rula un experiment Autopilot cu cod folosind fie SDK-ul AWS pentru Python (Boto3), fie SDK-ul SageMaker Python. Următorul fragment de cod demonstrează cum să inițializați un experiment Autopilot utilizând SDK-ul SageMaker Python. Noi folosim Clasa AutoML de la SageMaker Python SDK.
După ce Autopilot începe un experiment, serviciul inspectează automat datele brute de intrare, aplică procesoare de caracteristici și alege cel mai bun set de algoritmi. După ce alege un algoritm, Autopilot își optimizează performanța utilizând un proces de căutare de optimizare a hiperparametrilor. Acest lucru este adesea denumit antrenament și reglare a modelului. În cele din urmă, acest lucru ajută la producerea unui model care poate face predicții cu precizie asupra datelor pe care nu le-a văzut niciodată. Autopilot urmărește automat performanța modelului și apoi clasifică modelele finale pe baza unor valori care descriu acuratețea și precizia unui model.

De asemenea, aveți opțiunea de a implementa oricare dintre modelele clasate fie alegând modelul (clic dreapta) și alegând Implementează modelul, sau selectând modelul din lista clasată și alegând Implementează modelul.
Efectuați predicții pe lot folosind un model din Autopilot
Când experimentul Autopilot este finalizat, puteți utiliza modelul antrenat pentru a rula predicții pe lot pe setul de date de testare sau de reținere pentru evaluare. Puteți compara apoi etichetele estimate cu etichetele așteptate dacă setul de date de testare sau de reținere este pre-etichetat. Aceasta este în esență o modalitate de a compara predicțiile unui model cu adevărul. Dacă mai multe dintre predicțiile modelului se potrivesc cu etichetele adevărate, în general putem clasifica modelul ca având performanțe bune. De asemenea, puteți rula predicții pe lot pentru a eticheta datele neetichetate. Puteți realiza cu ușurință același lucru folosind SDK-ul de nivel înalt SageMaker Python cu câteva linii de cod.
Descrieți un experiment Autopilot rulat anterior
Mai întâi trebuie să extragem informațiile dintr-un experiment Autopilot finalizat anterior. Putem folosi clasa AutoML din SDK-ul SageMaker Python pentru a crea un obiect automl care încapsulează informațiile unui experiment Autopilot anterior. Puteți utiliza numele experimentului pe care l-ați definit la inițializarea experimentului Autopilot. Vezi următorul cod:
Cu obiectul automl, putem descrie și recrea cu ușurință cel mai bine antrenat model, așa cum se arată în următoarele fragmente:
În unele cazuri, este posibil să doriți să utilizați un alt model decât cel mai bun model, așa cum este clasat de Autopilot. Pentru a găsi un astfel de model candidat, puteți utiliza obiectul automl și puteți itera prin lista tuturor candidaților sau a celor mai de top N model și alegeți modelul pe care doriți să îl recreați. Pentru această postare, folosim o buclă simplă Python For pentru a itera printr-o listă de candidați model:
Personalizați răspunsul de inferență
Când recreăm cel mai bun model sau oricare altul dintre modelele antrenate de Autopilot, putem personaliza răspunsul de inferență pentru model adăugând un parametru suplimentar inference_response_keys, așa cum se arată în exemplul precedent. Puteți utiliza acest parametru pentru ambele tipuri de probleme de clasificare binară sau multiclasă:
- etichetă_prevăzută – Clasa prezisă.
- probabilitate – În clasificarea binară, probabilitatea ca rezultatul să fie prezis ca a doua clasă sau adevărată în coloana țintă. În clasificarea multiclasă, probabilitatea clasei câștigătoare.
- etichete – O listă cu toate clasele posibile.
- probabilități – O listă cu toate probabilitățile pentru toate clasele (ordinea corespunde etichetelor).
Deoarece problema pe care o abordăm în această postare este clasificarea binară, setăm acest parametru după cum urmează în fragmentele precedente în timp ce creăm modelele:
Creați transformator și rulați predicții pe lot
În cele din urmă, după ce recreăm modelele candidate, putem crea un transformator pentru a porni jobul de predicții pe lot, așa cum se arată în următoarele două fragmente de cod. În timpul creării transformatorului, definim specificațiile cluster-ului pentru a rula jobul de lot, cum ar fi numărul și tipul de instanțe. Intrarea și ieșirea lotului sunt locațiile Amazon S3 în care sunt stocate intrările și ieșirile noastre de date. Lucrarea de predicție a lotului este alimentată de Transformarea lotului SageMaker.
Când lucrarea este finalizată, putem citi rezultatul lotului și putem efectua evaluări și alte acțiuni în aval.
Rezumat
În această postare, am demonstrat cum să faceți rapid și ușor predicții pe lot utilizând modele antrenate cu Autopilot pentru evaluările dvs. post-antrenament. Am folosit SageMaker Studio pentru a inițializa un experiment Autopilot pentru a crea un model de estimare a ratei clienților. Apoi, am făcut referire la cel mai bun model al Autopilot pentru a rula predicții pe lot folosind clasa automl cu SDK-ul SageMaker Python. De asemenea, am folosit SDK-ul pentru a efectua predicții pe lot cu alți modele candidați. Cu Autopilot, ne-am explorat și preprocesat automat datele, apoi am creat mai multe modele ML cu un singur clic, lăsând SageMaker să se ocupe de gestionarea infrastructurii necesare pentru a ne instrui și ajusta modelele. În cele din urmă, am folosit transformarea lotului pentru a face predicții cu modelul nostru folosind cod minim.
Pentru mai multe informații despre Autopilot și funcționalitățile sale avansate, consultați Automatizați dezvoltarea modelului cu Amazon SageMaker Autopilot. Pentru o prezentare detaliată a exemplului din postare, aruncați o privire la următoarele exemplu caiet.
Despre Autori
 Arunprasath Shankar este un arhitect specializat în soluții de inteligență artificială și învățare automată (AI / ML) cu AWS, ajutând clienții globali să își scaleze soluțiile de AI în mod eficient și eficient în cloud. În timpul liber, lui Arun îi place să urmărească filme SF și să asculte muzică clasică.
Arunprasath Shankar este un arhitect specializat în soluții de inteligență artificială și învățare automată (AI / ML) cu AWS, ajutând clienții globali să își scaleze soluțiile de AI în mod eficient și eficient în cloud. În timpul liber, lui Arun îi place să urmărească filme SF și să asculte muzică clasică.
 Peter Chung este arhitect de soluții pentru AWS și este pasionat de a ajuta clienții să descopere informații din datele lor. El a construit soluții pentru a ajuta organizațiile să ia decizii bazate pe date, atât în sectorul public, cât și în cel privat. El deține toate certificările AWS, precum și două certificări GCP. Îi place cafeaua, să gătească, să rămână activ și să petreacă timpul cu familia.
Peter Chung este arhitect de soluții pentru AWS și este pasionat de a ajuta clienții să descopere informații din datele lor. El a construit soluții pentru a ajuta organizațiile să ia decizii bazate pe date, atât în sectorul public, cât și în cel privat. El deține toate certificările AWS, precum și două certificări GCP. Îi place cafeaua, să gătească, să rămână activ și să petreacă timpul cu familia.
- Coinsmart. Cel mai bun schimb de Bitcoin și Crypto din Europa.
- Platoblockchain. Web3 Metaverse Intelligence. Cunoștințe amplificate. ACCES LIBER.
- CryptoHawk. Radar Altcoin. Încercare gratuită.
- Sursa: https://aws.amazon.com/blogs/machine-learning/make-batch-predictions-with-amazon-sagemaker-autopilot/
- "
- 000
- 100
- Despre Noi
- acces
- Cont
- acțiuni
- activ
- avansat
- AI
- Algoritmul
- algoritmi
- TOATE
- Amazon
- ZONĂ
- artificial
- inteligență artificială
- Inteligența artificială și învățarea în mașină
- Automata
- in medie
- AWS
- CEL MAI BUN
- frontieră
- Clădire
- afaceri
- pasă
- cazuri
- clasificare
- Cloud
- cod
- Cafea
- Coloană
- Crearea
- clienţii care
- de date
- implementa
- Dezvoltare
- diferit
- Devreme
- cu ușurință
- Punct final
- Mediu inconjurator
- exemplu
- execuție
- de aşteptat
- experiment
- familie
- Caracteristică
- DESCRIERE
- First
- următor
- Complet
- genera
- Caritate
- ajutor
- ajută
- istoric
- deține
- Cum
- Cum Pentru a
- HTTPS
- imediat
- informații
- Infrastructură
- perspective
- Inteligență
- Internațional
- IT
- Loc de munca
- Locuri de munca
- cunoscut
- etichete
- mai mare
- învăţare
- Linie
- Listă
- Ascultare
- local
- locaţie
- Locații
- maşină
- masina de învățare
- de conducere
- manual
- Meci
- Metrici
- ML
- Mobil
- model
- Modele
- Filme
- Muzică
- număr
- oferi
- on-line
- optimizare
- Opțiune
- comandă
- organizații
- Altele
- in caz contrar
- performanță
- posibil
- prezicere
- Predictii
- privat
- Problemă
- proces
- produce
- Profil
- furniza
- furnizează
- public
- repede
- Crud
- în timp real
- record
- înregistrări
- Rapoarte
- răspuns
- REZULTATE
- Alerga
- funcţionare
- Scară
- sdk
- Caută
- sectoare
- serviciu
- set
- instalare
- simplu
- soluţii
- REZOLVAREA
- Cheltuire
- Începe
- Stat
- şedere
- depozitare
- studio
- Ţintă
- sarcini
- test
- Prin
- timp
- top
- Pregătire
- Transforma
- TX
- descoperi
- us
- utilizare
- Voce
- aștepta
- dacă
- OMS
- în