NLP cu mai multe etichete se referă la sarcina de a atribui mai multe etichete la o anumită intrare de text, mai degrabă decât la o singură etichetă. În sarcinile NLP tradiționale, cum ar fi clasificarea textului sau analiza sentimentelor, fiecărei intrări i se atribuie de obicei o singură etichetă pe baza conținutului său. Cu toate acestea, în multe scenarii din lumea reală, o bucată de text poate aparține mai multor categorii sau poate exprima mai multe sentimente simultan.
NLP cu mai multe etichete este important pentru că ne permite să captăm informații mai nuanțate și complexe din datele text. De exemplu, în domeniul analizei feedback-ului clienților, o recenzie a clienților poate exprima atât sentimente pozitive, cât și negative în același timp sau poate atinge mai multe aspecte ale unui produs sau serviciu. Atribuind mai multe etichete unor astfel de intrări, putem obține o înțelegere mai cuprinzătoare a feedback-ului clientului și putem lua măsuri mai bine direcționate pentru a răspunde preocupărilor acestora.
Acest articol analizează un caz demn de remarcat al utilizării de către Provectus a NLP cu mai multe etichete.
Context:
Un client ne-a adresat cu o cerere de ajutor automatizează etichetarea documentelor de un anumit tip. La prima vedere, sarcina părea a fi simplă și ușor de rezolvat. Cu toate acestea, în timp ce lucram la caz, am întâlnit un set de date cu adnotări inconsecvente. Deși clienții noștri s-au confruntat cu provocări cu numere variate de clasă și schimbări în echipa lor de examinare de-a lungul timpului, ei au investit eforturi semnificative în crearea unui set de date divers, cu o serie de adnotări. Deși au existat unele dezechilibre și incertitudini în etichete, acest set de date a oferit o oportunitate valoroasă pentru analiză și explorare ulterioară.
Să aruncăm o privire mai atentă asupra setului de date, să explorăm valorile și abordarea noastră și să recapitulăm modul în care Provectus a rezolvat problema clasificării textului cu mai multe etichete.
Setul de date are 14,354 de observații, cu 124 de clase (etichete) unice. Sarcina noastră este să atribuim una sau mai multe clase fiecărei observații.
Tabelul 1 oferă statistici descriptive pentru setul de date.
În medie, avem aproximativ două clase per observație, cu o medie de 261 de texte diferite care descriu o singură clasă.

Tabelul 1: Statistica setului de date
În Figura 1, vedem distribuția claselor în graficul de sus și avem un anumit număr de etichete HEAD cu cea mai mare frecvență de apariție în setul de date. De asemenea, rețineți că majoritatea claselor au o frecvență scăzută de apariție.
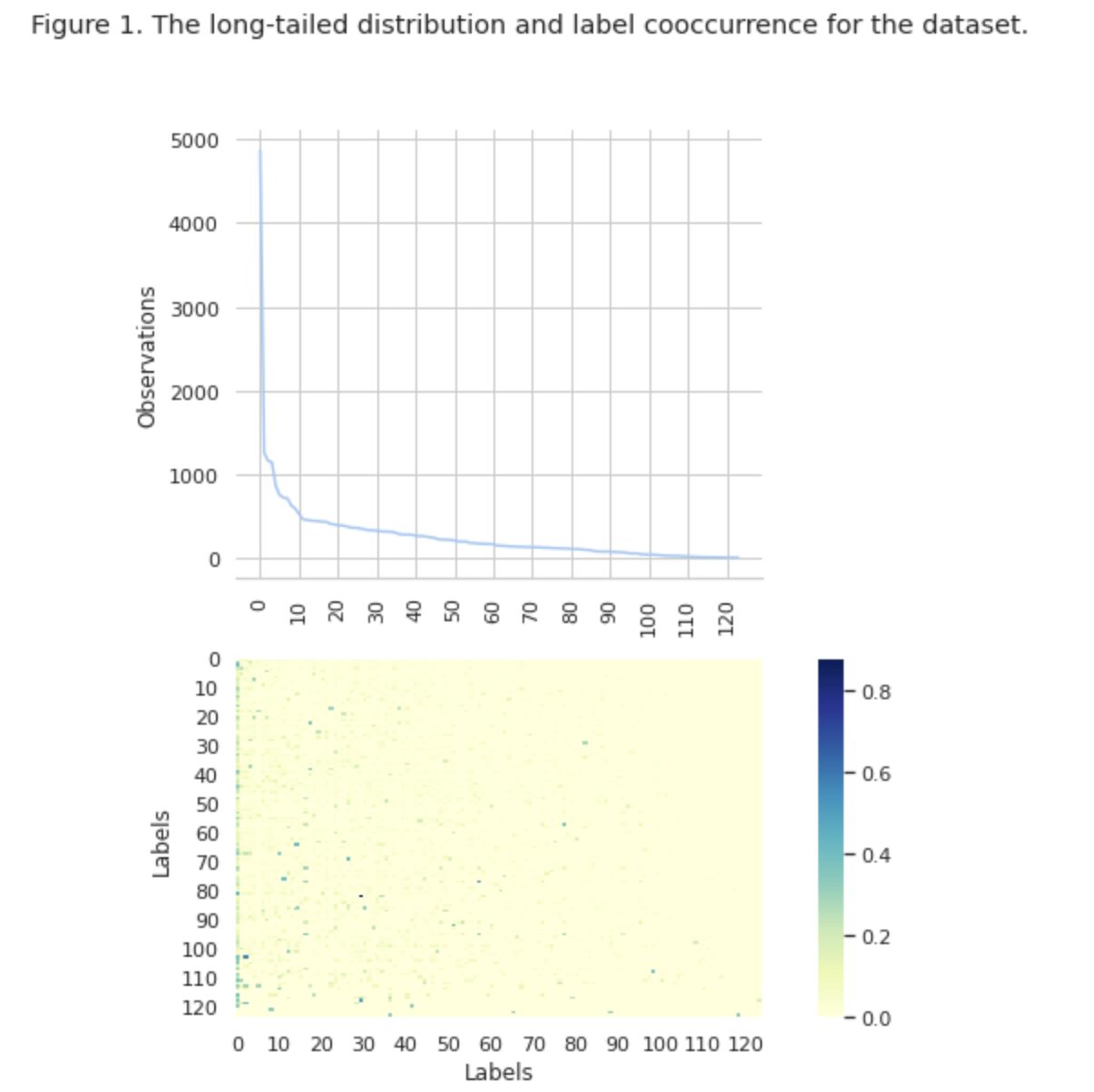
În graficul de jos vedem că există o suprapunere frecventă între clasele care sunt cel mai bine reprezentate în setul de date și clasele care au o semnificație scăzută.
Am schimbat procesul de împărțire a setului de date în seturi de tren/val/test. În loc să folosim o metodă tradițională, am folosit stratificarea iterativă, pentru a oferi o distribuție bine echilibrată a dovezilor relațiilor de etichetă. Pentru asta am folosit Scikit Multi-learn
from skmultilearn.model_selection import iterative_train_test_split mlb = MultiLabelBinarizer() def balanced_split(df, mlb, test_size=0.5): ind = np.expand_dims(np.arange(len(df)), axis=1) mlb.fit_transform(df["tag"]) labels = mlb.transform(df["tag"]) ind_train, _, ind_test, _ = iterative_train_test_split( ind, labels, test_size ) return df.iloc[ind_train[:, 0]], df.iloc[ind_test[:, 0]] df_train, df_tmp = balanced_split(df, test_size=0.4)
df_val, df_test = balanced_split(df_tmp, test_size=0.5)
Am obtinut urmatoarea distributie:
- Setul de date de antrenament conține 60% din date și acoperă toate cele 124 de etichete
- Setul de date de validare conține 20% din date și acoperă toate cele 124 de etichete
- Setul de date de testare conține 20% din date și acoperă toate cele 124 de etichete
Clasificarea cu mai multe etichete este un tip de algoritm de învățare automată supravegheat care ne permite să atribuim mai multe etichete unui singur eșantion de date. Diferă de clasificarea binară în care modelul prezice doar două categorii și de clasificarea multiclasă în care modelul prezice doar una din mai multe clase pentru un eșantion.
Valorile de evaluare pentru performanța clasificării cu mai multe etichete sunt în mod inerent diferite de cele utilizate în clasificarea multiclasă (sau binară), datorită diferențelor inerente ale problemei de clasificare. Informații mai detaliate pot fi găsite pe Wikipedia.
Am selectat valorile care sunt cele mai potrivite pentru noi:
- Precizie măsoară proporția de predicții pozitive adevărate dintre predicțiile pozitive totale făcute de model.
- Rechemare măsoară proporția de predicții pozitive adevărate dintre toate eșantioanele pozitive reale.
- F1-scor este mijlocul armonic al preciziei și reamintirii, care ajută la restabilirea echilibrului între cele două.
- Pierderea Hamming este fracția de etichete care sunt prezise incorect
Urmărim și noi numărul de etichete prezis în setul { definit ca număr pentru etichete, pentru care obținem un scor F1 > 0}.
Clasificarea cu mai multe etichete este un tip de problemă de învățare supravegheată în care o singură instanță sau exemplu poate fi asociată cu mai multe etichete sau clasificări, spre deosebire de clasificarea tradițională cu o singură etichetă, în care fiecare instanță este asociată doar cu o singură etichetă de clasă.
Pentru a rezolva problemele de clasificare cu mai multe etichete, există două categorii principale de tehnici:
- Metode de transformare a problemelor
- Metode de adaptare a algoritmului
Metodele de transformare a problemelor ne permit să transformăm sarcinile de clasificare cu mai multe etichete în sarcini de clasificare cu o singură etichetă. De exemplu, abordarea de bază cu relevanță binară (BR) tratează fiecare etichetă ca pe o problemă de clasificare binară separată. În acest caz, problema cu mai multe etichete este transformată în mai multe probleme cu o singură etichetă.
Metodele de adaptare a algoritmului modifică algoritmii înșiși pentru a gestiona datele cu mai multe etichete în mod nativ, fără a transforma sarcina în sarcini multiple de clasificare cu o singură etichetă. Un exemplu al acestei abordări este modelul BERT, care este un model de limbaj bazat pe transformator pre-antrenat care poate fi reglat fin pentru diverse sarcini NLP, inclusiv clasificarea textului cu mai multe etichete. BERT este proiectat să gestioneze datele cu mai multe etichete în mod direct, fără a fi nevoie de transformarea problemelor.
În contextul utilizării BERT pentru clasificarea textului cu mai multe etichete, abordarea standard este de a utiliza pierderea Binary Cross-Entropy (BCE) ca funcție de pierdere. Pierderea BCE este o funcție de pierdere folosită în mod obișnuit pentru problemele de clasificare binară și poate fi extinsă cu ușurință pentru a gestiona problemele de clasificare cu mai multe etichete, calculând pierderile pentru fiecare etichetă în mod independent și apoi însumând pierderile. În acest caz, funcția de pierdere BCE măsoară eroarea dintre probabilitățile prezise și etichetele adevărate, unde probabilitățile prezise sunt obținute din stratul final de activare a sigmoidului în modelul BERT.
Acum, să aruncăm o privire mai atentă la Figura 2 de mai jos.
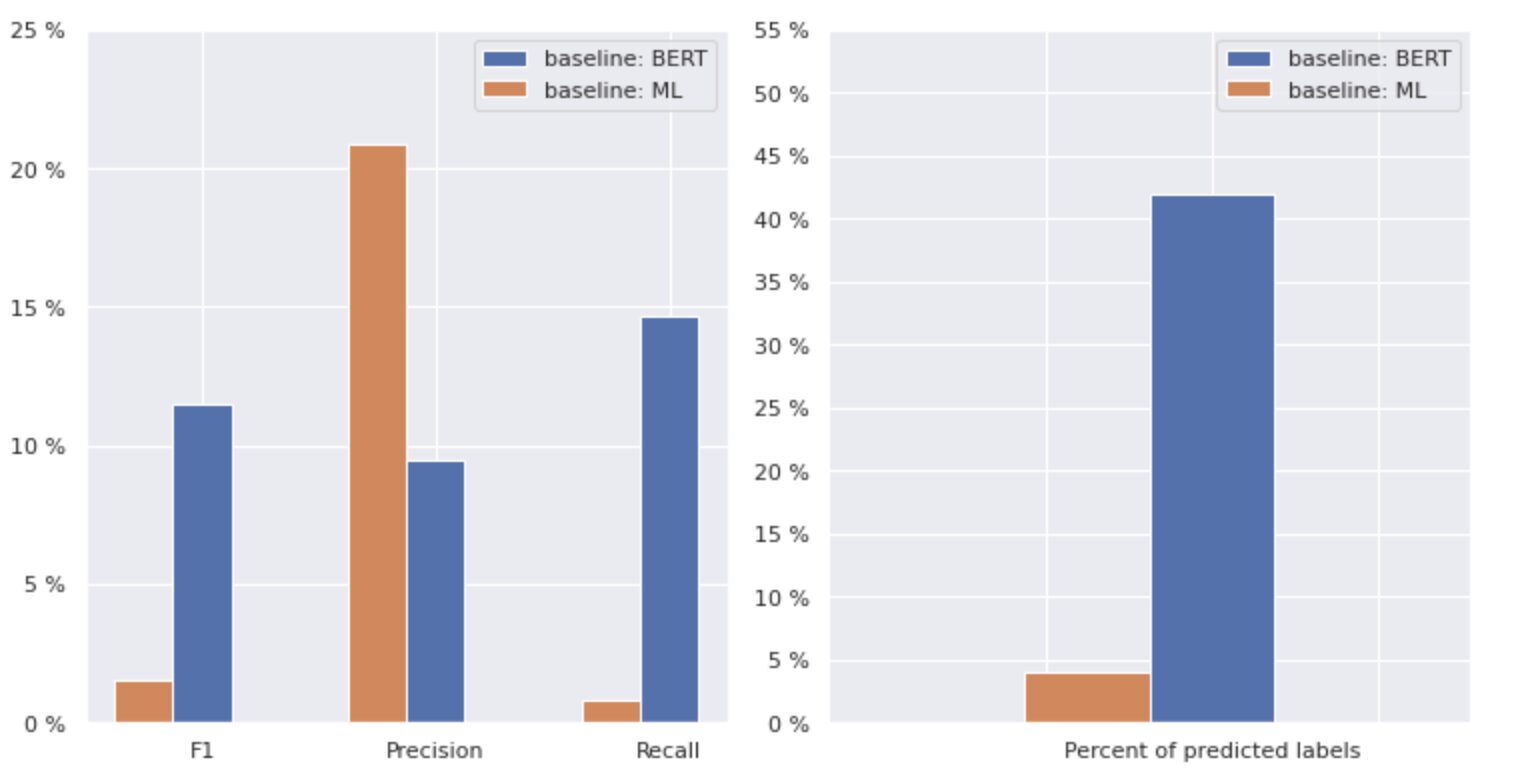
Figura 2. Metrici pentru modelele de bază
Graficul din stânga arată o comparație a valorilor pentru „linia de bază: BERT” și „linia de bază: ML”. Astfel, se poate observa că pentru „baseline: BERT”, scorurile F1 și Recall sunt de aproximativ 1.5 ori mai mari, în timp ce Precizia pentru „baseline: ML” este de 2 ori mai mare decât cea a modelului 1. Analizând procentul total de clasele prezise afișate în dreapta, vedem că „linia de bază: BERT” a prezis clase de peste 10 ori mai mult decât „linia de bază: ML”.
Deoarece rezultatul maxim pentru „linia de bază: BERT” este mai puțin de 50% din toate clasele, rezultatele sunt destul de descurajatoare. Să ne dăm seama cum să îmbunătățim aceste rezultate.
Pe baza articolului remarcabil „Metode de echilibrare pentru clasificarea textului cu mai multe etichete cu distribuirea claselor cu coadă lungă”, am aflat că pierderea echilibrată în distribuție poate fi cea mai potrivită abordare pentru noi.
Pierdere echilibrată în distribuție
Pierderea echilibrată în distribuție este o tehnică utilizată în problemele de clasificare a textului cu mai multe etichete pentru a aborda dezechilibrele în distribuția claselor. În aceste probleme, unele clase au o frecvență mult mai mare de apariție în comparație cu altele, rezultând înclinarea modelului către aceste clase mai frecvente.
Pentru a aborda această problemă, pierderea echilibrată în distribuție urmărește să echilibreze contribuția fiecărui eșantion în funcția de pierdere. Acest lucru se realizează prin reponderarea pierderii fiecărui eșantion pe baza inversului frecvenței sale de apariție în setul de date. Procedând astfel, contribuția claselor mai puțin frecvente este crescută, iar contribuția claselor mai frecvente este redusă, echilibrând astfel distribuția generală a clasei.
Această tehnică s-a dovedit a fi eficientă în îmbunătățirea performanței modelelor în problemele de distribuție a claselor cu coadă lungă. Prin reducerea impactului claselor frecvente și creșterea impactului claselor rare, modelul este capabil să capteze mai bine modelele în date și să producă predicții mai echilibrate.

Implementarea clasei Resample
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np class ResampleLoss(nn.Module): def __init__( self, use_sigmoid=True, partial=False, loss_weight=1.0, reduction="mean", reweight_func=None, weight_norm=None, focal=dict(focal=True, alpha=0.5, gamma=2), map_param=dict(alpha=10.0, beta=0.2, gamma=0.1), CB_loss=dict(CB_beta=0.9, CB_mode="average_w"), logit_reg=dict(neg_scale=5.0, init_bias=0.1), class_freq=None, train_num=None, ): super(ResampleLoss, self).__init__() assert (use_sigmoid is True) or (partial is False) self.use_sigmoid = use_sigmoid self.partial = partial self.loss_weight = loss_weight self.reduction = reduction if self.use_sigmoid: if self.partial: self.cls_criterion = partial_cross_entropy else: self.cls_criterion = binary_cross_entropy else: self.cls_criterion = cross_entropy # reweighting function self.reweight_func = reweight_func # normalization (optional) self.weight_norm = weight_norm # focal loss params self.focal = focal["focal"] self.gamma = focal["gamma"] self.alpha = focal["alpha"] # mapping function params self.map_alpha = map_param["alpha"] self.map_beta = map_param["beta"] self.map_gamma = map_param["gamma"] # CB loss params (optional) self.CB_beta = CB_loss["CB_beta"] self.CB_mode = CB_loss["CB_mode"] self.class_freq = ( torch.from_numpy(np.asarray(class_freq)).float().cuda() ) self.num_classes = self.class_freq.shape[0] self.train_num = train_num # only used to be divided by class_freq # regularization params self.logit_reg = logit_reg self.neg_scale = ( logit_reg["neg_scale"] if "neg_scale" in logit_reg else 1.0 ) init_bias = ( logit_reg["init_bias"] if "init_bias" in logit_reg else 0.0 ) self.init_bias = ( -torch.log(self.train_num / self.class_freq - 1) * init_bias ) self.freq_inv = ( torch.ones(self.class_freq.shape).cuda() / self.class_freq ) self.propotion_inv = self.train_num / self.class_freq def forward( self, cls_score, label, weight=None, avg_factor=None, reduction_override=None, **kwargs ): assert reduction_override in (None, "none", "mean", "sum") reduction = ( reduction_override if reduction_override else self.reduction ) weight = self.reweight_functions(label) cls_score, weight = self.logit_reg_functions( label.float(), cls_score, weight ) if self.focal: logpt = self.cls_criterion( cls_score.clone(), label, weight=None, reduction="none", avg_factor=avg_factor, ) # pt is sigmoid(logit) for pos or sigmoid(-logit) for neg pt = torch.exp(-logpt) wtloss = self.cls_criterion( cls_score, label.float(), weight=weight, reduction="none" ) alpha_t = torch.where(label == 1, self.alpha, 1 - self.alpha) loss = alpha_t * ((1 - pt) ** self.gamma) * wtloss loss = reduce_loss(loss, reduction) else: loss = self.cls_criterion( cls_score, label.float(), weight, reduction=reduction ) loss = self.loss_weight * loss return loss def reweight_functions(self, label): if self.reweight_func is None: return None elif self.reweight_func in ["inv", "sqrt_inv"]: weight = self.RW_weight(label.float()) elif self.reweight_func in "rebalance": weight = self.rebalance_weight(label.float()) elif self.reweight_func in "CB": weight = self.CB_weight(label.float()) else: return None if self.weight_norm is not None: if "by_instance" in self.weight_norm: max_by_instance, _ = torch.max(weight, dim=-1, keepdim=True) weight = weight / max_by_instance elif "by_batch" in self.weight_norm: weight = weight / torch.max(weight) return weight def logit_reg_functions(self, labels, logits, weight=None): if not self.logit_reg: return logits, weight if "init_bias" in self.logit_reg: logits += self.init_bias if "neg_scale" in self.logit_reg: logits = logits * (1 - labels) * self.neg_scale + logits * labels if weight is not None: weight = ( weight / self.neg_scale * (1 - labels) + weight * labels ) return logits, weight def rebalance_weight(self, gt_labels): repeat_rate = torch.sum( gt_labels.float() * self.freq_inv, dim=1, keepdim=True ) pos_weight = ( self.freq_inv.clone().detach().unsqueeze(0) / repeat_rate ) # pos and neg are equally treated weight = ( torch.sigmoid(self.map_beta * (pos_weight - self.map_gamma)) + self.map_alpha ) return weight def CB_weight(self, gt_labels): if "by_class" in self.CB_mode: weight = ( torch.tensor((1 - self.CB_beta)).cuda() / (1 - torch.pow(self.CB_beta, self.class_freq)).cuda() ) elif "average_n" in self.CB_mode: avg_n = torch.sum( gt_labels * self.class_freq, dim=1, keepdim=True ) / torch.sum(gt_labels, dim=1, keepdim=True) weight = ( torch.tensor((1 - self.CB_beta)).cuda() / (1 - torch.pow(self.CB_beta, avg_n)).cuda() ) elif "average_w" in self.CB_mode: weight_ = ( torch.tensor((1 - self.CB_beta)).cuda() / (1 - torch.pow(self.CB_beta, self.class_freq)).cuda() ) weight = torch.sum( gt_labels * weight_, dim=1, keepdim=True ) / torch.sum(gt_labels, dim=1, keepdim=True) elif "min_n" in self.CB_mode: min_n, _ = torch.min( gt_labels * self.class_freq + (1 - gt_labels) * 100000, dim=1, keepdim=True, ) weight = ( torch.tensor((1 - self.CB_beta)).cuda() / (1 - torch.pow(self.CB_beta, min_n)).cuda() ) else: raise NameError return weight def RW_weight(self, gt_labels, by_class=True): if "sqrt" in self.reweight_func: weight = torch.sqrt(self.propotion_inv) else: weight = self.propotion_inv if not by_class: sum_ = torch.sum(weight * gt_labels, dim=1, keepdim=True) weight = sum_ / torch.sum(gt_labels, dim=1, keepdim=True) return weight def reduce_loss(loss, reduction): """Reduce loss as specified. Args: loss (Tensor): Elementwise loss tensor. reduction (str): Options are "none", "mean" and "sum". Return: Tensor: Reduced loss tensor. """ reduction_enum = F._Reduction.get_enum(reduction) # none: 0, elementwise_mean:1, sum: 2 if reduction_enum == 0: return loss elif reduction_enum == 1: return loss.mean() elif reduction_enum == 2: return loss.sum() def weight_reduce_loss(loss, weight=None, reduction="mean", avg_factor=None): """Apply element-wise weight and reduce loss. Args: loss (Tensor): Element-wise loss. weight (Tensor): Element-wise weights. reduction (str): Same as built-in losses of PyTorch. avg_factor (float): Avarage factor when computing the mean of losses. Returns: Tensor: Processed loss values. """ # if weight is specified, apply element-wise weight if weight is not None: loss = loss * weight # if avg_factor is not specified, just reduce the loss if avg_factor is None: loss = reduce_loss(loss, reduction) else: # if reduction is mean, then average the loss by avg_factor if reduction == "mean": loss = loss.sum() / avg_factor # if reduction is 'none', then do nothing, otherwise raise an error elif reduction != "none": raise ValueError( 'avg_factor can not be used with reduction="sum"' ) return loss def binary_cross_entropy( pred, label, weight=None, reduction="mean", avg_factor=None
): # weighted element-wise losses if weight is not None: weight = weight.float() loss = F.binary_cross_entropy_with_logits( pred, label.float(), weight, reduction="none" ) loss = weight_reduce_loss( loss, reduction=reduction, avg_factor=avg_factor ) return loss
DBLoss
loss_func = ResampleLoss( reweight_func="rebalance", loss_weight=1.0, focal=dict(focal=True, alpha=0.5, gamma=2), logit_reg=dict(init_bias=0.05, neg_scale=2.0), map_param=dict(alpha=0.1, beta=10.0, gamma=0.405), class_freq=class_freq, train_num=train_num,
) """
class_freq - list of frequencies for each class,
train_num - size of train dataset """
Prin investigarea atentă a setului de date, am ajuns la concluzia că parametrul
= 0.405.
Reglajul pragului
Un alt pas în îmbunătățirea modelului nostru a fost procesul de reglare a pragului, atât în etapa de antrenament, cât și în etapele de validare și testare. Am calculat dependențele unor valori cum ar fi scorul f1, precizia și reamintirea la nivelul pragului și am selectat pragul pe baza celui mai mare scor al valorii. Mai jos puteți vedea implementarea funcției a acestui proces.
Optimizarea scorului F1 prin reglarea pragului:
def optimise_f1_score(true_labels: np.ndarray, pred_labels: np.ndarray): best_med_th = 0.5 true_bools = [tl == 1 for tl in true_labels] micro_thresholds = (np.array(range(-45, 15)) / 100) + best_med_th f1_results, pre_results, recall_results = [], [], [] for th in micro_thresholds: pred_bools = [pl > th for pl in pred_labels] test_f1 = f1_score(true_bools, pred_bools, average="micro", zero_division=0) test_precision = precision_score( true_bools, pred_bools, average="micro", zero_division=0 ) test_recall = recall_score( true_bools, pred_bools, average="micro", zero_division=0 ) f1_results.append(test_f1) prec_results.append(test_precision) recall_results.append(test_recall) best_f1_idx = np.argmax(f1_results) return micro_thresholds[best_f1_idx]Evaluare și comparare cu valoarea de bază
Aceste abordări ne-au permis să antrenăm un nou model și să obținem următorul rezultat, care este comparat cu linia de bază: BERT din Figura 3 de mai jos.

Figura 3. Măsuri de comparație după linia de bază și abordarea mai nouă.
Comparând valorile relevante pentru clasificare, observăm o creștere semnificativă a măsurilor de performanță de aproape 5-6 ori:
Scorul F1 a crescut de la 12% → 55%, în timp ce Precizia a crescut de la 9% → 59% și Recall a crescut de la 15% → 51%.
Cu modificările prezentate în graficul din dreapta din Figura 3, acum putem prezice 80% din clase.
Felii de cursuri
Ne-am împărțit etichetele în patru grupuri: CAP, MEDIU, COADA și ZERO. Fiecare grup conține etichete cu o cantitate similară de observații de date justificative.
După cum se vede în Figura 4, distribuțiile grupurilor sunt distincte. Cutia de trandafiri (HEAD) are o distribuție declinată negativ, caseta de mijloc (MEDIUM) are o distribuție declinată pozitiv, iar caseta verde (COADA) pare să aibă o distribuție normală.
Toate grupurile au, de asemenea, valori aberante, care sunt puncte în afara mustăților în diagrama cu case. Grupul HEAD are un impact major asupra unei clase MAJOR.
În plus, am identificat un grup separat numit „ZERO” care conține etichete pe care modelul nu a putut să le învețe și nu le poate recunoaște din cauza numărului minim de apariții din setul de date (mai puțin de 3% din toate observațiile).
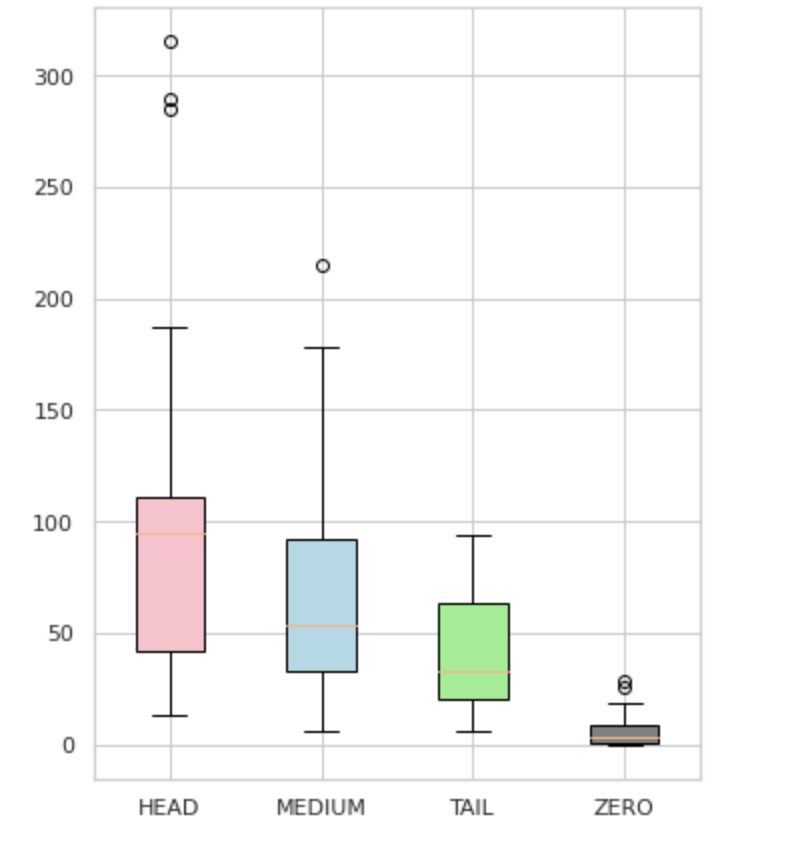
Figura 4. Numărările de etichete față de grupuri
Tabelul 2 oferă informații despre valorile pentru fiecare grup de etichete pentru subsetul de date de testare.
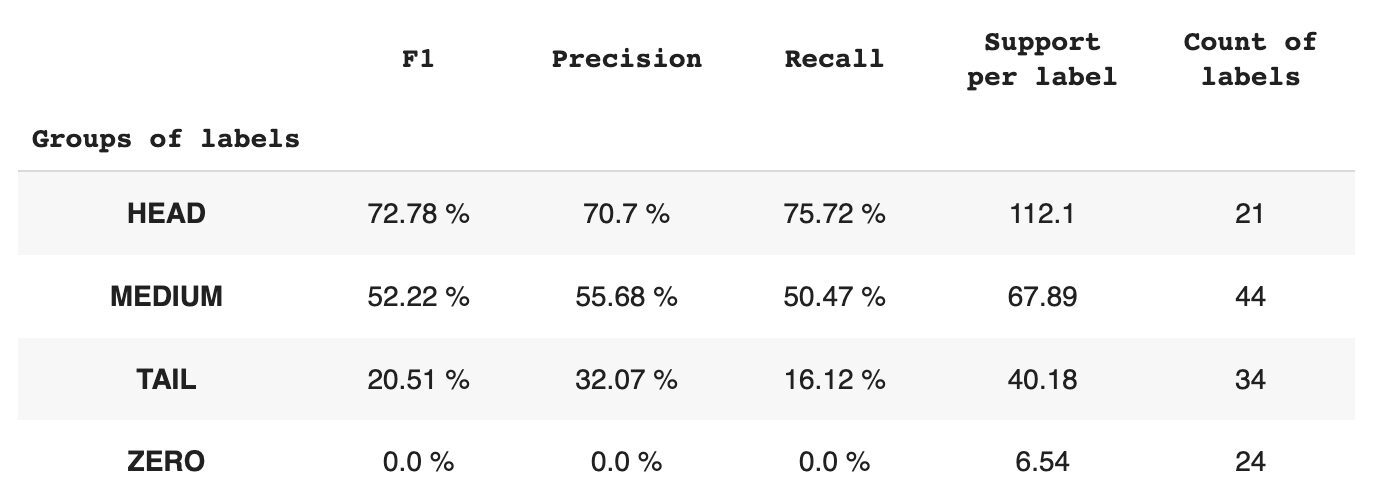
Tabelul 2. Valori pe grup.
- Grupul HEAD conține 21 de etichete cu o medie de 112 observații de sprijin pe etichetă. Acest grup este afectat de valori aberante și, datorită reprezentării sale ridicate în setul de date, valorile sale sunt mari: F1 – 73%, Precizie – 71%, Recall – 75%.
- Grupul MEDIU este format din 44 de etichete cu un suport mediu de 67 de observații, ceea ce este de aproximativ două ori mai mic decât grupul HEAD. Valorile pentru acest grup sunt de așteptat să scadă cu 50%: F1 – 52%, Precizie – 56%, Recall – 51%.
- Grupul TAIL are cel mai mare număr de clase, dar toate sunt slab reprezentate în setul de date, cu o medie de 40 de observații suport pe etichetă. Ca urmare, valorile scad semnificativ: F1 – 21%, Precizie – 32%, Recall – 16%.
- Grupul ZERO include clase pe care modelul nu le poate recunoaște deloc, posibil din cauza apariției lor scăzute în setul de date. Fiecare dintre cele 24 de etichete din acest grup are o medie de 7 observații de sprijin.
Figura 5 vizualizează informațiile prezentate în Tabelul 2, oferind o reprezentare vizuală a valorilor pe grup de etichete.
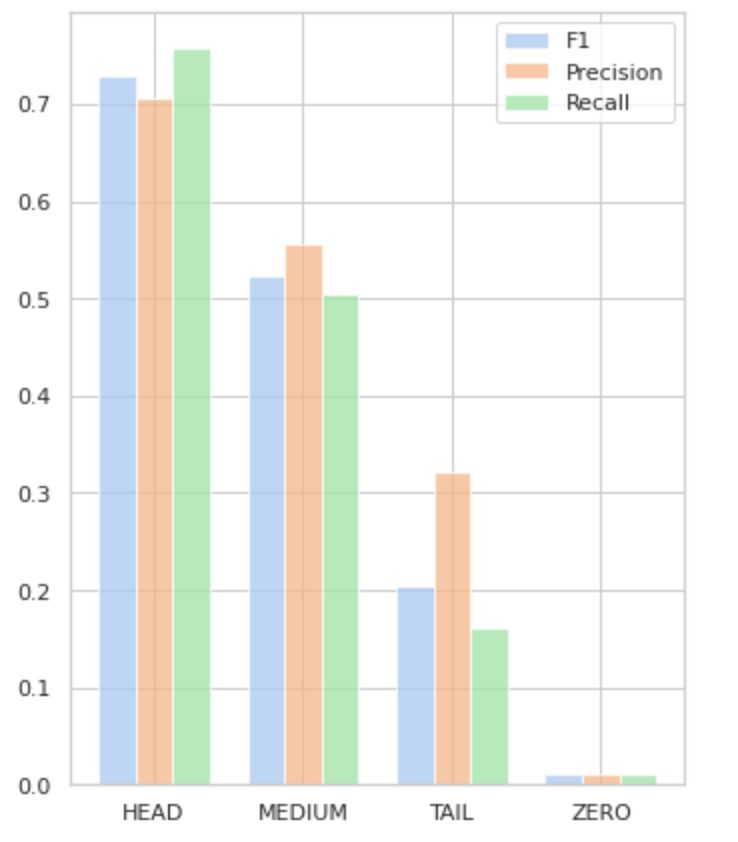
Figura 5. Valori vs. grupuri de etichete. Toate valorile ZERO = 0.
În acest articol cuprinzător, am demonstrat că o sarcină aparent simplă de clasificare a textului cu mai multe etichete poate fi o provocare atunci când sunt aplicate metodele tradiționale. Am propus utilizarea funcțiilor de pierdere de echilibrare a distribuției pentru a aborda problema dezechilibrului de clasă.
Am comparat performanța abordării noastre propuse cu metoda clasică și am evaluat-o utilizând metrici de afaceri din lumea reală. Rezultatele demonstrează că utilizarea funcțiilor de pierdere pentru a aborda dezechilibrele de clasă și aparițiile co-etichetelor oferă o soluție viabilă pentru clasificarea textului cu mai multe etichete.
Cazul de utilizare propus evidențiază importanța luării în considerare a diferitelor abordări și tehnici atunci când se ocupă de clasificarea textului cu mai multe etichete și beneficiile potențiale ale funcțiilor de pierdere de echilibrare a distribuției în abordarea dezechilibrelor de clasă.
Dacă vă confruntați cu o problemă similară și doriți să o faceți eficientizați operațiunile de procesare a documentelor în cadrul organizației dumneavoastră, vă rugăm să mă contactați pe mine sau cu echipa Provectus. Vom fi bucuroși să vă ajutăm în găsirea unor metode mai eficiente de automatizare a proceselor dumneavoastră.
Oleksii Babych este inginer de învățare automată la Provectus. Cu o experiență în fizică, posedă abilități excelente analitice și matematice și a câștigat o experiență valoroasă prin cercetări științifice și prezentări la conferințe internaționale, inclusiv SPIE Photonics West. Oleksii este specializată în crearea de soluții AI/ML la scară largă, de la capăt la capăt, pentru industria medicală și fintech. El este implicat în fiecare etapă a ciclului de viață al dezvoltării ML, de la identificarea problemelor de afaceri până la implementarea și rularea modelelor ML de producție.
Rinat Akhmetov este arhitectul soluției ML la Provectus. Cu un fundal practic solid în învățarea automată (în special în viziunea computerizată), Rinat este un tocilar, pasionat de date, inginer de software și dependent de muncă a cărui a doua mare pasiune este programarea. La Provectus, Rinat este responsabil de fazele de descoperire și demonstrare a conceptului și conduce execuția proiectelor complexe de IA.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- Platoblockchain. Web3 Metaverse Intelligence. Cunoștințe amplificate. Accesați Aici.
- Sursa: https://www.kdnuggets.com/2023/03/multilabel-nlp-analysis-class-imbalance-loss-function-approaches.html?utm_source=rss&utm_medium=rss&utm_campaign=multi-label-nlp-an-analysis-of-class-imbalance-and-loss-function-approaches
- :este
- 1
- 10
- 100
- 15%
- 67
- 7
- 9
- a
- Capabil
- Despre Noi
- Obține
- realizat
- acțiuni
- Activarea
- adaptare
- adresa
- adresare
- AI
- AI / ML
- isi propune
- Algoritmul
- algoritmi
- TOATE
- permite
- Alfa
- printre
- sumă
- analiză
- Analitic
- analiza
- și
- a apărut
- aplicat
- Aplică
- abordare
- abordari
- aproximativ
- SUNT
- articol
- AS
- aspecte
- alocate
- ajuta
- asociate
- At
- automatizarea
- in medie
- fundal
- Sold
- bazat
- De bază
- BE
- deoarece
- de mai jos
- Beneficiile
- CEL MAI BUN
- beta
- Mai bine
- între
- părtinire
- Cea mai mare
- De jos
- Cutie
- construit-in
- afaceri
- by
- calculată
- CAN
- nu poti
- captura
- caz
- categorii
- CB
- sigur
- provocări
- provocare
- Modificări
- taxă
- clasă
- clase
- clasic
- clasificare
- client
- îndeaproape
- mai aproape
- în mod obișnuit
- comparație
- compararea
- comparație
- complex
- cuprinzător
- calculator
- Computer Vision
- tehnica de calcul
- concept
- preocupările
- încheiat
- Conferință
- luand in considerare
- contactați-ne
- conține
- conţinut
- context
- contribuţie
- acoperă
- Crearea
- client
- ciclu
- de date
- abuzive
- scădea
- definit
- demonstra
- demonstrat
- Implementarea
- proiectat
- detaliat
- Dezvoltare
- diferenţele
- diferit
- direct
- descoperire
- distinct
- distribuire
- distribuții
- diferit
- împărțit
- document
- documente
- face
- domeniu
- Picătură
- fiecare
- cu ușurință
- Eficace
- eficient
- Eforturile
- permite
- un capăt la altul
- inginer
- entuziast
- la fel de
- eroare
- mai ales
- Eter (ETH)
- evaluat
- Fiecare
- dovadă
- exemplu
- excelent
- execuție
- de aşteptat
- experienţă
- explorare
- explora
- expres
- f1
- cu care se confruntă
- cu care se confruntă
- feedback-ul
- Figura
- final
- descoperire
- FinTech
- First
- pluti
- următor
- Pentru
- găsit
- fracțiune
- Frecvență
- frecvent
- din
- funcţie
- funcțional
- funcții
- mai mult
- Câştig
- dat
- ochire
- grafic
- Verde
- grup
- Grupului
- manipula
- fericit
- Avea
- cap
- de asistență medicală
- ajutor
- ajută
- Înalt
- superior
- cea mai mare
- highlights-uri
- Cum
- Cum Pentru a
- Totuși
- HTML
- http
- HTTPS
- identificat
- identificarea
- dezechilibru
- Impactul
- afectate
- implementarea
- import
- importanță
- important
- îmbunătăţi
- îmbunătățirea
- in
- include
- Inclusiv
- în mod incorect
- Crește
- a crescut
- crescând
- independent
- industrii
- informații
- inerent
- intrare
- instanță
- in schimb
- Internațional
- investit
- implicat
- problema
- IT
- ESTE
- jpg
- doar unul
- KDnuggets
- Etichetă
- etichetarea
- etichete
- limbă
- pe scară largă
- cea mai mare
- strat
- Conduce
- AFLAȚI
- învățat
- învăţare
- Nivel
- Viaţă
- Listă
- Uite
- de pe
- pierderi
- Jos
- maşină
- masina de învățare
- făcut
- Principal
- major
- Majoritate
- multe
- cartografiere
- matematica
- maxim
- măsuri
- mediu
- metodă
- Metode
- metric
- Metrici
- minim
- ML
- MLB
- model
- Modele
- modifica
- modul
- mai mult
- mai eficient
- cele mai multe
- multiplu
- Numit
- Nevoie
- negativ
- negativ
- Nou
- nlp
- normală.
- remarcabil
- număr
- numere
- NumPy
- obține
- obținut
- of
- oferi
- on
- ONE
- Oportunitate
- opus
- Opţiuni
- organizație
- Altele
- in caz contrar
- exterior
- remarcabil
- global
- parametru
- pasiune
- modele
- procent
- performanță
- Fizică
- bucată
- Plato
- Informații despre date Platon
- PlatoData
- "vă rog"
- puncte
- PoS
- pozitiv
- potenţial
- potenţial
- Practic
- Precizie
- prezice
- a prezis
- Predictii
- prezice
- Prezentări
- prezentat
- Problemă
- probleme
- proces
- procese
- prelucrare
- produce
- Produs
- producere
- Programare
- Proiecte
- dovadă
- dovada de concept
- propus
- furniza
- prevăzut
- furnizează
- furnizarea
- pirtorh
- ridica
- gamă
- mai degraba
- lumea reală
- reechilibreze
- recapitula
- recunoaște
- reduce
- Redus
- reducerea
- se referă
- relaţii
- relevanţa
- reprezentare
- reprezentate
- solicita
- cercetare
- rezultat
- rezultând
- REZULTATE
- reveni
- Returnează
- revizuiască
- ROSE
- funcţionare
- s
- acelaşi
- scenarii
- Cercetare științifică
- Al doilea
- caută
- selectate
- SELF
- sentiment
- distinct
- serviciu
- set
- Seturi
- Modela
- indicat
- Emisiuni
- semnificație
- semnificativ
- semnificativ
- asemănător
- simplu
- simultan
- singur
- Mărimea
- aptitudini
- So
- Software
- Inginer Software
- solid
- soluţie
- soluţii
- REZOLVAREA
- unele
- specializată
- specificată
- Etapă
- Stadiile
- standard
- statistică
- Pas
- simplu
- astfel de
- potrivit
- învățare supravegheată
- a sustine
- De sprijin
- tabel
- TAG
- Lua
- vizate
- Sarcină
- sarcini
- echipă
- tehnici de
- test
- Testarea
- Clasificarea textului
- acea
- informațiile
- lor
- Lor
- se
- Acestea
- prag
- Prin
- timp
- ori
- la
- top
- lanternă
- Total
- atingeţi
- spre
- urmări
- tradiţional
- Tren
- Pregătire
- Transforma
- Transformare
- transformat
- transformare
- tratează
- adevărat
- tipic
- incertitudini
- înţelegere
- unic
- us
- utilizare
- carcasa de utilizare
- Utilizand
- validare
- Valoros
- Valori
- diverse
- viabil
- viziune
- vs
- greutate
- Vest
- care
- în timp ce
- Wikipedia
- voi
- cu
- în
- fără
- a lucrat
- Ta
- zephyrnet
- zero