Întreprinderile din întreaga lume caută să utilizeze mai multe surse de date pentru a implementa o experiență de căutare unificată pentru angajații și clienții finali. Având în vedere volumul mare de date care trebuie examinate și indexate, viteza de recuperare, scalabilitatea soluției și performanța căutării devin factori cheie de luat în considerare atunci când alegeți o soluție de căutare inteligentă pentru întreprinderi. În plus, aceste surse de date unice cuprind depozite de conținut structurate și nestructurate – inclusiv diferite tipuri de fișiere – care pot cauza probleme de compatibilitate.
Amazon Kendra este un serviciu de căutare foarte precis și inteligent, care permite utilizatorilor să caute răspunsuri la întrebările lor din datele dvs. nestructurate și structurate, folosind procesarea limbajului natural și algoritmi de căutare avansați. Acesta returnează răspunsuri specifice la întrebări, oferind utilizatorilor o experiență care este aproape de interacțiunea cu un expert uman.
Astăzi, Amazon Kendra a lansat șapte opțiuni suplimentare de suport pentru format de date pe care le puteți utiliza. Acest lucru vă permite să integrați cu ușurință sursele de date existente așa cum sunt și să efectuați căutare inteligentă în mai multe depozite de conținut.
În această postare, discutăm despre noile formate de date acceptate și despre cum să le folosim.
Noi formate de date acceptate
Anterior, Amazon Kendra documente susținute care includea text structurat sub formă de întrebări și răspunsuri frecvente, precum și text nestructurat sub formă de fișiere HTML, prezentări Microsoft PowerPoint, documente Microsoft Word, documente cu text simplu și PDF-uri.
Odată cu această lansare, Amazon Kendra oferă acum suport pentru șapte formate de date suplimentare:
- Format text îmbogățit (RTF)
- Notarea obiectelor JavaScript (JSON)
- Reducere (MD)
- Valori separate prin virgulă (CSV)
- Microsoft Excel (MS Excel)
- Limbaj extensibil de marcare (XML)
- Transformări de limbă de foaie de stil extensibile (XSLT)
Utilizatorii Amazon Kendra pot asimila aceste documente cu diferite formate de date în indexul lor în următoarele două moduri:
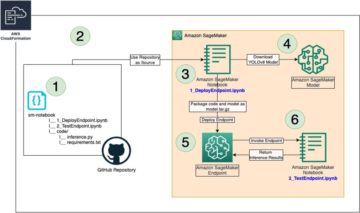
Prezentare generală a soluțiilor
În secțiunile următoare, parcurgem pașii pentru adăugarea documentelor dintr-o sursă de date și efectuarea unei căutări pe acele documente.
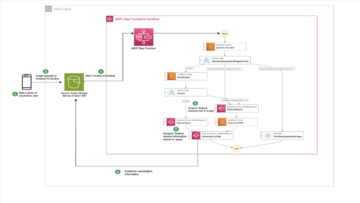
Următoarea diagramă arată arhitectura soluției noastre.

Pentru a testa această soluție pentru oricare dintre formatele acceptate, trebuie să utilizați propriile date. Puteți testa prin încărcarea documentelor de același format sau de formate diferite în bucket-ul S3.
Creați un index Amazon Kendra
Pentru instrucțiuni despre crearea indexului Amazon Kendra, consultați Crearea unui index.
Puteți sări peste acest pas dacă aveți un index preexistent de utilizat pentru această demonstrație.
Încărcați documente într-o găleată S3 și ingerați în index folosind conectorul S3
Parcurgeți următorii pași pentru a conecta o găleată S3 la index:
- Creați o găleată S3 pentru a vă stoca documentele.
- Creați un folder numite eșantion-date.
- Încărcați în dosar documentele pe care doriți să le testați.
- Pe consola Amazon Kendra, accesați indexul dvs. și alegeți Surse de date.
- Alege Adăugați o sursă de date.
- În Surse de date disponibile, Selectați S3 Și alegeți Adăugați conector.
- Introduceți un nume pentru conectorul dvs. (cum ar fi
Demo_S3_connector) și alegeți Pagina Următoare →. - Alege Răsfoiți S3 și alegeți găleata S3 în care ați încărcat documentele.
- Pentru Rolul IAM, creați un nou rol.
- Pentru Setați programul de rulare a sincronizării, Selectați Fugi la cerere.
- Alege Pagina Următoare →.
- Pe Examinați și creați pagina, alege Adăugați o sursă de date.
- După finalizarea procesului de creare, alegeți Sincronizați acum.
Acum că ați ingerat câteva documente, puteți naviga la consola de căutare încorporată pentru a testa interogările.
Căutați documentele dvs. cu consola de căutare Amazon Kendra
Pe consola Amazon Kendra, alegeți Căutați conținut indexat în panoul de navigare.
Următoarele sunt exemple de rezultate ale căutării diferitelor tipuri de documente:
- RTF – Introduceți date în format RTF încărcate în compartimentul S3 și sincronizați sursa de date:

Următoarea captură de ecran arată rezultatele căutării.

- JSON – Introduceți date în format JSON încărcate în compartimentul S3 și sincronizați sursa de date:

Următoarea captură de ecran arată rezultatele căutării.

- Reduceri – Introduceți date în format MD încărcate în compartimentul S3 și sincronizați sursa de date:

Următoarea captură de ecran arată rezultatele căutării.

- CSV – Introduceți date în format CSV încărcate în compartimentul S3 și sincronizați sursa de date:

Următoarea captură de ecran arată rezultatele căutării.

- Excel – Introduceți date în format Excel încărcate în compartimentul S3 și sincronizați sursa de date:

Următoarea captură de ecran arată rezultatele căutării.

- XML – Introduceți date în format XML încărcate în compartimentul S3 și sincronizați sursa de date:

Următoarea captură de ecran arată rezultatele căutării.

- XSLT – Introduceți date în format XSLT încărcate în compartimentul S3 și sincronizați sursa de date:
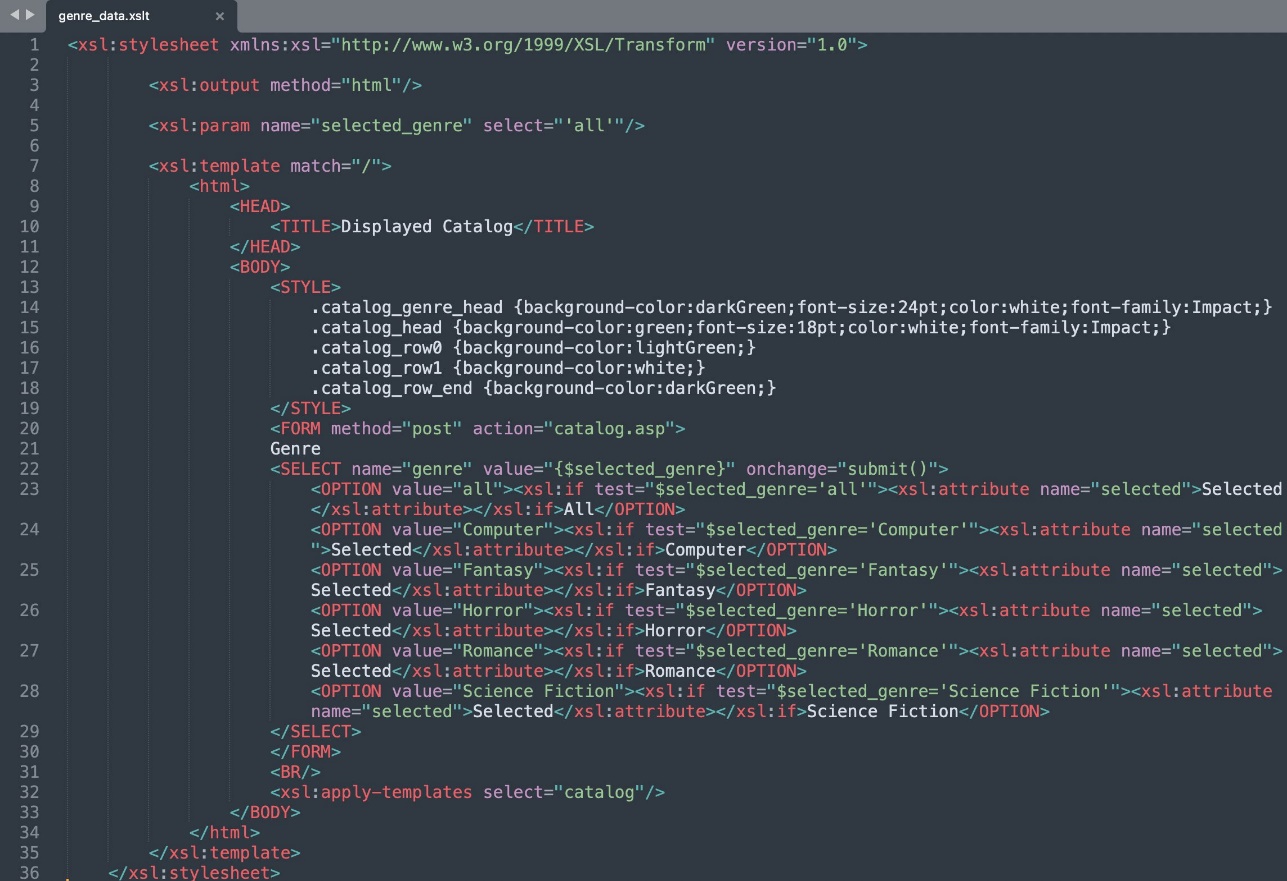
Următoarea captură de ecran arată rezultatele căutării.

A curăța
Pentru a evita costurile viitoare, curățați resursele pe care le-ați creat ca parte a acestei soluții utilizând următorii pași:
- Pe consola Amazon Kendra, alegeți Indexuri în panoul de navigare.
- Alegeți indexul care conține sursa de date de șters.
- În panoul de navigare, alegeți Surse de date.
- Alegeți sursa de date de eliminat, apoi alegeți Șterge.
Când ștergeți o sursă de date, Amazon Kendra elimină toate informațiile stocate despre sursa de date. Amazon Kendra elimină toate datele documentelor stocate în index și toate istoriile și valorile de rulare asociate cu sursa de date. Ștergerea unei surse de date nu elimină documentele originale din stocarea dvs.
- Pe consola Amazon Kendra, alegeți Indecși în panoul de navigare.
- Alegeți indexul de șters, apoi alegeți Șterge.
A se referi la Ștergerea unui index și a unei surse de date pentru mai multe detalii.
- În consola Amazon S3, alegeți Cupă în panoul de navigare.
- Selectați găleata pe care doriți să o ștergeți, apoi alegeți Șterge.
- Introduceți numele găleții pentru a confirma ștergerea, apoi alegeți Ștergeți găleata.
Dacă găleata conține obiecte, veți primi o alertă de eroare. Goliți găleata înainte de a o șterge, alegând linkul din mesajul de eroare și urmând instrucțiunile de pe Galeata goala pagină. Apoi reveniți la Ștergeți găleata pagina și ștergeți găleata.
- Pentru a verifica dacă ați șters găleata, deschideți Cupă pagina și introduceți numele găleții pe care ați șters-o. Dacă găleata nu poate fi găsită, ștergerea dvs. a avut succes.
A se referi la Ștergerea unei pagini de grup pentru mai multe detalii.
Concluzie
În această postare, am discutat despre noile formate de date pe care Amazon Kendra le acceptă acum. În plus, am discutat despre cum să folosiți Amazon Kendra pentru a ingera și a efectua o căutare pe aceste noi tipuri de documente stocate într-o găleată S3. Pentru a afla mai multe despre diferitele formate de date acceptate, consultați Tipuri de documente.
V-am prezentat elementele de bază, dar există multe funcții suplimentare pe care nu le-am acoperit în această postare, cum ar fi următoarele:
- Puteți activa controlul accesului bazat pe utilizator pentru indexul dvs. Amazon Kendra și puteți restricționa accesul la utilizatorii și grupurile pe care le configurați.
- Puteți mapa câmpuri suplimentare la atributele indexului Amazon Kendra și le puteți activa pentru fațetare, căutare și afișare în rezultatele căutării.
- Puteți integra diferiți conectori de surse de date de la terți, cum ar fi Service Now și Salesforce, cu capacitatea de îmbogățire a documentelor personalizate (CDE) în Amazon Kendra pentru a realiza o logică suplimentară de mapare a atributelor și chiar transformarea personalizată a conținutului în timpul ingerării. Pentru lista completă a conectorilor acceptați, consultați conectori.
Pentru a afla despre aceste posibilități și mai multe, consultați Ghidul dezvoltatorului Amazon Kendra.
Despre autori
 Rishabh Yadav este arhitect Partner Solutions la AWS cu o experiență extinsă în ofertele DevOps și securitate la AWS. El lucrează cu partenerii ASEAN pentru a oferi îndrumări cu privire la adoptarea cloud-ului pentru întreprinderi și revizuirile arhitecturii, împreună cu construirea practicii AWS prin implementarea cadrului bine arhitecturat. În afara serviciului, îi place să-și petreacă timpul pe terenul de sport și în jocurile FPS.
Rishabh Yadav este arhitect Partner Solutions la AWS cu o experiență extinsă în ofertele DevOps și securitate la AWS. El lucrează cu partenerii ASEAN pentru a oferi îndrumări cu privire la adoptarea cloud-ului pentru întreprinderi și revizuirile arhitecturii, împreună cu construirea practicii AWS prin implementarea cadrului bine arhitecturat. În afara serviciului, îi place să-și petreacă timpul pe terenul de sport și în jocurile FPS.
 Kruthi Jayasimha Rao este un arhitect de soluții pentru parteneri, cu accent pe AI și ML. Ea oferă îndrumări tehnice partenerilor AWS în urma celor mai bune practici pentru a construi soluții sigure, rezistente și foarte disponibile în AWS Cloud.
Kruthi Jayasimha Rao este un arhitect de soluții pentru parteneri, cu accent pe AI și ML. Ea oferă îndrumări tehnice partenerilor AWS în urma celor mai bune practici pentru a construi soluții sigure, rezistente și foarte disponibile în AWS Cloud.
 Keerthi Kumar Kallur este inginer de dezvoltare software la AWS. El face parte din echipa AWS Kendra din ultimii 2 ani și a lucrat la diverse funcții, precum și la clienți. În timpul liber, îi place să facă activități în aer liber precum drumeții, sporturi precum voleiul.
Keerthi Kumar Kallur este inginer de dezvoltare software la AWS. El face parte din echipa AWS Kendra din ultimii 2 ani și a lucrat la diverse funcții, precum și la clienți. În timpul liber, îi place să facă activități în aer liber precum drumeții, sporturi precum voleiul.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- Platoblockchain. Web3 Metaverse Intelligence. Cunoștințe amplificate. Accesați Aici.
- Sursa: https://aws.amazon.com/blogs/machine-learning/new-expanded-data-format-support-in-amazon-kendra/
- 10
- 100
- 7
- a
- Despre Noi
- acces
- precis
- peste
- activităţi de
- plus
- Suplimentar
- În plus,
- Adoptare
- avansat
- AI
- Alerta
- algoritmi
- TOATE
- permite
- Amazon
- Amazon Kendra
- și
- răspunsuri
- arhitectură
- Asean
- asociate
- atribute
- disponibil
- evita
- AWS
- fundal
- Noțiuni de bază
- deveni
- înainte
- CEL MAI BUN
- Cele mai bune practici
- construi
- Clădire
- construit-in
- Provoca
- Alege
- alegere
- Închide
- Cloud
- adoptarea norului
- compatibilitate
- Completă
- Confirma
- Conectați
- Lua în considerare
- luand in considerare
- Consoleze
- conține
- conţinut
- Control
- Cheltuieli
- acoperi
- crea
- a creat
- Crearea
- creaţie
- personalizat
- clienţii care
- de date
- Demo
- detalii
- Dezvoltator
- Dezvoltare
- DevOps
- diferit
- discuta
- discutat
- Afişa
- document
- documente
- în timpul
- cu ușurință
- de angajați
- permite
- permite
- inginer
- Intrați
- Afacere
- eroare
- Eter (ETH)
- Chiar
- exemple
- Excel
- existent
- extins
- experienţă
- expert
- extensiv
- factori
- DESCRIERE
- camp
- Domenii
- Fișier
- Fişiere
- Concentra
- următor
- formă
- format
- găsit
- FPS
- Cadru
- frecvent
- din
- viitor
- jocuri
- Oferirea
- glob
- Go
- Grupului
- extrem de
- drumeții
- Cum
- Cum Pentru a
- HTML
- HTTPS
- uman
- punerea în aplicare a
- implementarea
- in
- inclus
- index
- informații
- intrare
- instrucțiuni
- integra
- Inteligent
- interacționând
- introdus
- probleme de
- IT
- JSON
- Cheie
- limbă
- mare
- lansa
- a lansat
- AFLAȚI
- LINK
- Listă
- cautati
- multe
- Hartă
- cartografiere
- mesaj
- Metrici
- Microsoft
- Microsoft Word
- ML
- mai mult
- MS
- multiplu
- nume
- Numit
- Natural
- Limbajul natural
- Procesarea limbajului natural
- Navigaţi
- Navigare
- Nevoie
- nevoilor
- Nou
- obiect
- obiecte
- ofertele
- promoții
- deschide
- Opţiuni
- original
- Activități în aer liber
- exterior
- propriu
- pâine
- parte
- partener
- parteneri
- trecut
- efectua
- performanță
- efectuarea
- Simplu
- Plato
- Informații despre date Platon
- PlatoData
- posibilităţile de
- Post
- practică
- practicile
- Prezentări
- proces
- prelucrare
- furniza
- furnizează
- Întrebări
- a primi
- scoate
- elastic
- Resurse
- restrânge
- REZULTATE
- reveni
- Returnează
- Recenzii
- Rol
- Alerga
- Salesforce
- acelaşi
- scalabilitate
- Caută
- secțiuni
- sigur
- securitate
- serviciu
- Șapte
- Emisiuni
- întrucât
- Software
- de dezvoltare de software
- soluţie
- soluţii
- unele
- Sursă
- Surse
- specific
- viteză
- petrece
- Sportul
- Pas
- paşi
- depozitare
- stoca
- stocate
- structurat
- de succes
- astfel de
- a sustine
- Suportat
- Sprijină
- echipă
- Tehnic
- test
- Testarea
- Noțiuni de bază
- lor
- terț
- Prin
- timp
- la
- Transformare
- transformări
- Tipuri
- unificat
- unic
- încărcat
- Se încarcă
- utilizare
- utilizatorii
- folosi
- Valori
- diverse
- verifica
- volum
- modalități de
- Cuvânt
- Apartamente
- a lucrat
- fabrică
- XML
- XSLT
- ani
- Ta
- zephyrnet