Ați așteptat vreodată acel pachet scump care arată „expediat”, dar nu aveți nicio idee unde este? Istoricul de urmărire a încetat să se actualizeze acum cinci zile și aproape că v-ați pierdut speranța. Dar stați, 11 zile mai târziu, îl aveți la ușă. Ți-ai fi dorit ca trasabilitatea să fie mai bună pentru a te scuti de toată așteptarea neliniștită. Aici intervine „observabilitatea”.
Într-un peisaj tehnic, ați dori să evitați ca acest lucru să se întâmple software-ului sau sistemelor dvs. de date. Și astfel, adoptați instrumente de monitorizare, care colectează jurnalele și valorile sistemelor dvs. și vă informează despre starea lor internă. Monitorizarea funcționează cel mai bine atunci când doriți ca sistemele dvs. să vă informeze despre ce este eroarea, unde și când s-a întâmplat, dar nu vă spune cum să rezolvați eroarea.
În urmă cu mai bine de un deceniu, instrumentele de monitorizare nu aveau contextul și previziunea problemelor subiacente ale sistemului, iar echipele ar fi limitate la depanarea erorilor operaționale de zi cu zi. Astăzi, lucrăm și trăim într-o lume distribuită de microservicii și conducte de date; chiar și utilizarea mai multor instrumente de monitorizare nu vă va ajuta să răspundeți la întrebările dvs. de afaceri precum „De ce aplicația mea este întotdeauna lentă?” sau „În ce stadiu a apărut problema și cât de adânc este în stivă?” sau „Cum pot îmbunătăți performanța generală a mediului?” Devine necesar să fii proactiv în luarea acestor decizii și să ai o vizibilitate generală a sistemelor, aplicațiilor și datelor tale.
Acest blog de Etsy a fost publicat acum un deceniu și afirmă însuși faptul în al doilea paragraf:
„Metricile aplicației sunt de obicei cele mai dificile, dar cele mai importante dintre cele trei. Sunt foarte specifice afacerii tale și se schimbă pe măsură ce aplicațiile tale se schimbă (și Etsy se schimbă foarte mult).”
Deci, cum măsurăm totul și orice? Începem cu observabilitatea.
Ce este observabilitatea?
Termenul „observabilitate” a fost inventat de Rudolf Emil Kálmán în 1960 în lucrarea sa de inginerie pentru a descrie sistemele de control matematic. El a definit-o ca o măsură a cât de bine pot fi deduse stările interne ale unui sistem din cunoașterea rezultatelor sale externe. Dar nu sună a monitorizare? Practic, da, este monitorizare.
În zilele noastre, observabilitatea a devenit un subiect destul de fierbinte. Potrivit mai multor studii de piață, este o platformă de un miliard de dolari. Multe organizații au adoptat conceptul și l-au folosit ca un cadru pentru vizibilitatea end-to-end a sistemelor și conductelor lor distribuite. Cu toate acestea, observabilitatea este confundată cu monitorizarea. Deocamdată, pot spune că monitorizarea este un subset al observabilității, unde observabilitatea este un termen umbrelă mare.
Observabilitatea permite urmărirea distribuită prin colectarea și agregarea urmelor, jurnalelor și valorilor. Să vedem ce deduc acestea:
- Urme: Când un sistem primește o solicitare, urmele vă spun cum decurge acea cerere, de-a lungul ciclului său de viață, de la sursă la destinație. Urmele sunt reprezentate prin „întinderi”. O urmă este un arbore de intervale, iar un interval este o singură operație în cadrul unei urme. Ele vă ajută să localizați erorile, latența sau blocajele din sistem.
- Jurnale: Acestea sunt evenimente marcate de timp generate de mașină care vă spun despre operațiunile sau modificările care au avut loc în sistem. Jurnalele sunt adesea folosite pentru a interoga aceste erori sau modificări în sistem.
- Valori: Acestea oferă informații cantitative despre CPU, memorie, utilizarea discului și modul în care sistemul funcționează într-o perioadă de timp.
Aceste atribute îmbunătățesc cadrul de monitorizare cu trasabilitate. Trasabilitatea vă oferă lentilele pentru a urmări o solicitare care efectuează un apel către sistemul dvs., cât durează trecerea de la o componentă la alta, ce alte servicii invocă, aruncă vreo eroare, ce jurnaluri produce, ce stare se află, când a început și s-a terminat, care este cronologia în care a rămas în sistemul dvs. etc. Când colectați, agregați și analizați aceste urme, puteți lua decizii informate valoroase, cum ar fi cronologia clienților pe un site web de comerț electronic , cât timp le-a luat să caute un produs, cât timp l-au vizualizat, pagina HTML a încărcat detaliile complete, cum ar fi imagini sau videoclipuri încorporate, cât a durat sistemul să se autentifice și să proceseze plata etc.
Ce realizăm cu observabilitatea într-un mediu distribuit?
Evoluția sistemelor distribuite a început atunci când organizațiile au început să treacă de la arhitectura lor centralizată monolit la o arhitectură de microservicii distribuită și descentralizată. Și aceasta este încă o lucrare în desfășurare în care multe organizații îmbrățișează natura microservicii a sistemelor și aplicațiilor. Și toate acestea pot fi atribuite Datele mari și scalarea. Gestionarea unui mediu distribuit necesită învățare continuă, forță de muncă suplimentară, schimbări în cadre și politici, management IT și așa mai departe. Este într-adevăr o mare schimbare.
Anterior, în mediul monolitic limitat, hardware-ul, software-ul, datele și bazele de date trăiau toate sub un singur acoperiș. Odată cu apariția datelor mari în anii 2000, sistemele de monitorizare și scalare au început să devină o preocupare uriașă. Adesea, organizațiile au folosit diferite instrumente de monitorizare pentru a răspunde nevoilor diferitelor lor aplicații. Ca urmare, a devenit în curând o suprasolicitare operațională cu rezistență, vizibilitate și fiabilitate slabe.
Toate aceste aspecte au dat naștere la adoptarea observabilității. Astăzi, există mai multe instrumente de observabilitate pentru securitate, rețea, aplicații și conducte de date pentru urmărirea distribuită într-un mediu complex. Ei coexistă cu vărul lor, cu instrumentele de monitorizare și își iau pârghia de a colecta informații de la vărul lor și adună cu informații suplimentare din propriile date de urmărire.
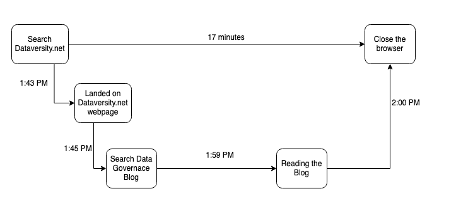
Există o mulțime de componente în mișcare în toate aceste sisteme, ale căror urme atunci când sunt capturate, pot ilustra povestea celor 5 W: când, unde, de ce, ce și cum. De exemplu, accesați site-ul web DATAVERSITY la 1:43 pentru a citi unele postări de blog. Când accesați dataversity.net, cererea HTTP este conectată în sistem. Începeți să căutați o postare pe blog și mergeți la o postare privind guvernarea datelor, unde petreceți 17 minute citind acea postare și apoi închideți fila la 2:00 pm
Vor fi, de asemenea, alte apeluri efectuate către sistemul de rețea pentru capturarea pachetelor de rețea. Instrumentele de observabilitate colectează toate intervalele și le unifică într-o urmă sau urme, permițându-vă să vedeți calea pe care a format-o în timpul ciclului său de viață. Dacă aveți o problemă, cum ar fi latența rețelei sau un defect al sistemului, acum este mai ușor să disecați (decojiți ceapa) și să depanați problema (eroare în ce strat).
Acum, într-un mediu distribuit mare, când aplicațiile dvs. primesc milioane de solicitări, datele de urmărire cresc în volum enorm. Colectarea și analiza acestor urme este costisitoare pentru consumul de stocare și transferul de date. Deci, pentru a economisi costuri, datele de urmărire sunt eșantionate, deoarece în cele mai multe cazuri, echipele de ingineri au nevoie doar de unele dintre piese pentru a investiga ce a mers prost sau care este modelul de eroare.
Cu acest mic exemplu, înțelegem că obținem informații mult mai profunde asupra sistemelor noastre. Deci, având în vedere o scară mai mare de sisteme, echipele de ingineri pot captura și lucra la datele eșantionate pentru a îmbunătăți structura actuală a sistemului, pot aplica sau retrage noi componente, pot adăuga un alt strat de securitate, pot elimina blocajele și așa mai departe.
Ar trebui organizațiile să aleagă observabilitatea?
Cu toții ar trebui să înțelegem că obiectivele finale sunt o experiență mai bună a utilizatorului și o mai mare satisfacție a utilizatorului. Iar calea către atingerea acestor obiective poate fi simplificată cu un cadru de observabilitate automatizat și proactiv. Stabilirea unei culturi de îmbunătățire continuă și optimizare este considerată abordarea optimă de afaceri și de conducere.
În această eră a transformării digitale, observabilitatea a devenit o necesitate pentru ca o afacere să aibă succes în călătoria sa digitală. Oferându-vă urme perspicace, observabilitatea vă face, de asemenea, să fiți informat pe date, nu doar bazat pe date.
Concluzie
Deși am folosit termenii de monitorizare și observabilitate în mod interschimbabil, am văzut că, în timp ce monitorizarea vă ajută cu informații despre starea de sănătate a sistemului și evenimentele care au loc pe acesta, observabilitatea vă facilitează să faceți inferențe bazate pe dovezi adunate din straturi mai profunde ale unui capăt. mediu până la capăt.
Observabilitatea este și poate fi percepută și ca o componentă a cadrului de guvernare a datelor. În această generație, în care volumul de date din ce în ce mai mare rezidă într-o rețea de hardware de bază, este vital să păstrăm arhitecturile cât mai simple posibil. Și, evident, devine o sarcină imposibilă gestionarea mediului în continuare. Astfel, implementarea politicilor și regulilor de guvernanță adecvate și automatizate pentru a vă menține o rețea mare de sisteme, conducte și date dezordonate necesită acțiune mai devreme decât mai târziu.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- Platoblockchain. Web3 Metaverse Intelligence. Cunoștințe amplificate. Accesați Aici.
- Sursa: https://www.dataversity.net/observability-traceability-for-distributed-systems/
- 1
- 11
- a
- Capabil
- Despre Noi
- Conform
- Obține
- realizarea
- Acțiune
- Suplimentar
- informatii suplimentare
- adopta
- adoptată
- Adoptare
- venire
- TOATE
- permite
- mereu
- analiza
- analiza
- și
- O alta
- răspunde
- aplicație
- aplicatii
- Aplică
- abordare
- adecvat
- arhitectură
- atribute
- autentifica
- Automata
- evita
- bazat
- Pe scurt
- deoarece
- deveni
- devine
- început
- CEL MAI BUN
- Mai bine
- Mare
- Datele mari
- Blog
- Blog
- blocaje
- afaceri
- apel
- apeluri
- captura
- cazuri
- centralizat
- Schimbare
- Modificări
- Alege
- Închide
- colecta
- Colectare
- produs
- Completă
- complex
- component
- componente
- concept
- Îngrijorare
- confuz
- luate în considerare
- luand in considerare
- consum
- context
- continuu
- Control
- Cheltuieli
- ar putea
- Procesor
- Cultură
- Curent
- client
- de date
- Pe bază de date
- baze de date
- VERSITATE DE DATE
- zilnic
- Zi
- deceniu
- descentralizată
- Deciziile
- adânc
- Mai adânc
- definit
- descrie
- destinație
- detalii
- FĂCUT
- diferit
- digital
- Transformarea digitală
- distribuite
- sisteme distribuite
- Nu
- jos
- în timpul
- e-commerce
- mai ușor
- încorporat
- îmbrățișare
- permițând
- un capăt la altul
- Inginerie
- Mediu inconjurator
- eroare
- Erori
- stabilirea
- etc
- Chiar
- evenimente
- EVER
- tot mai mare
- tot
- dovadă
- evoluţie
- exemplu
- scump
- experienţă
- extern
- facilitează
- fluxurilor
- format
- Cadru
- cadre
- din
- generaţie
- obține
- Go
- Goluri
- guvernare
- mai mare
- creste
- sa întâmplat
- lucru
- Piese metalice
- Sănătate
- ajutor
- ajută
- istorie
- Lovit
- speranţă
- FIERBINTE
- Cum
- Cum Pentru a
- Totuși
- HTML
- HTTPS
- mare
- imagini
- Punere în aplicare a
- important
- imposibil
- îmbunătăţi
- îmbunătățire
- in
- informații
- informat
- perspective
- intern
- investiga
- invocă
- problema
- probleme de
- IT
- Management IT
- călătorie
- A pastra
- cunoştinţe
- peisaj
- mare
- mai mare
- Latență
- strat
- straturi
- Conducere
- învăţare
- Lentilele
- Pârghie
- ciclu de viață
- Limitat
- Linie
- trăi
- încărca
- Lung
- Lot
- făcut
- face
- FACE
- Efectuarea
- administra
- administrare
- de conducere
- multe
- Piață
- matematic
- max-width
- măsura
- Memorie
- Metrici
- microservices
- milioane
- minute
- Monitorizarea
- Monolitic
- cele mai multe
- muta
- în mişcare
- multiplu
- Trebuie avut
- Natură
- necesar
- Nevoie
- nevoilor
- net
- reţea
- sistem de rețea
- Nou
- ONE
- operaţie
- operațional
- Operațiuni
- optimă
- optimizare
- organizații
- Altele
- global
- propriu
- Hârtie
- cale
- Model
- plată
- percepută
- performanță
- efectuarea
- perioadă
- piese
- platformă
- Plato
- Informații despre date Platon
- PlatoData
- Joaca
- Politicile
- sărac
- posibil
- Post
- postări
- Proactivă
- Problemă
- proces
- Produs
- Progres
- furniza
- furnizează
- furnizarea
- publicat
- cantitativ
- Întrebări
- mai degraba
- Citeste
- Citind
- a primi
- primește
- încredere
- scoate
- reprezentate
- solicita
- cereri de
- Necesită
- elasticitate
- limitat
- rezultat
- Ridica
- acoperiş
- norme
- satisfacție
- Economisiți
- Scară
- scalare
- Caută
- căutare
- Al doilea
- securitate
- Servicii
- câteva
- să
- Emisiuni
- simplu
- singur
- încetini
- mic
- So
- Software
- REZOLVAREA
- unele
- Curând
- Suna
- Sursă
- se întinde
- specific
- petrece
- stivui
- Etapă
- Începe
- început
- Stat
- Statele
- au stat
- Încă
- oprit
- depozitare
- Poveste
- structura
- de succes
- sistem
- sisteme
- Lua
- ia
- Sarcină
- echipe
- Tehnic
- termeni
- informațiile
- Sursa
- lor
- astfel
- trei
- Prin
- de-a lungul
- timp
- cronologie
- la
- astăzi
- Unelte
- subiect
- urmări
- Trasabilitatea
- calc
- Urmărire
- transfer
- Transformare
- umbrelă
- în
- care stau la baza
- înţelege
- actualizarea
- Folosire
- Utilizator
- Experiența de utilizare
- obișnuit
- Valoros
- diverse
- Video
- vizibilitate
- vital
- volum
- aștepta
- Aşteptare
- website
- Ce
- Ce este
- care
- în timp ce
- voi
- în
- Apartamente
- Forta de munca
- fabrică
- lume
- ar
- Greșit
- Ta
- zephyrnet