Gartner, Inc. estimează că costurile proaste ale datelor organizații o medie de 12.9 milioane USD anual.
Ne ocupăm zilnic de petaocteți de date, iar problemele de calitate a datelor sunt frecvente în cazul unor astfel de volume uriașe de date. Datele proaste costă organizații bani, reputație și timp. Prin urmare, este foarte important să monitorizați și să validăm continuu calitatea datelor.
Datele proaste includ informații inexacte, date lipsă, informații incorecte, date neconforme și date duplicate. Datele proaste vor duce la o analiză incorectă a datelor, rezultând în decizii proaste și strategii ineficiente.
Calitatea datelor Experian a constatat că o companie medie pierde 12% din venituri din cauza datelor insuficiente. În afară de bani, companiile suferă și o pierdere de timp pierdut.
Identificarea anomaliilor din date înainte de procesare va ajuta organizațiile să obțină informații mai valoroase asupra comportamentului clienților și va ajuta la reducerea costurilor.
Biblioteca cu așteptări mari ajută organizațiile să verifice și să afirme astfel de anomalii în date, cu peste 200 de reguli disponibile imediat.
Great Expectations este o bibliotecă Python open-source care ne ajută să validăm datele. Great Expectations furniza un set de metode sau funcții pentru ajuta inginerii de date validează rapid un anumit set de date.
În acest articol, vom analiza pașii implicați în validarea datelor de către biblioteca Great Expectations.
GE este ca testele unitare pentru date. GE furnizează afirmații numite Așteptări pentru a aplica unele reguli la datele testate. De exemplu, ID-ul/numărul poliței nu trebuie să fie necompletat pentru un document de poliță de asigurare. Pentru a configura și a executa GE, trebuie să urmați pașii de mai jos. Deși există mai multe moduri de a lucra cu GE (folosind CLI), voi explica modul programatic de a configura lucrurile în acest articol. Tot codul sursă explicat în acest articol este disponibil în acesta GitHub repo.
Pasul 1: Configurați configurația datelor
GE are un concept de magazine. Magazinele nu sunt altceva decât locația fizică de pe disc unde poate stoca așteptările (reguli/aserțiuni), detaliile rulării, detaliile punctelor de control, rezultatele validării și documentele de date (versiuni HTML statice ale rezultatelor validării). Click aici pentru a afla mai multe despre magazine.
GE acceptă diverse backend-uri de magazine. În acest articol, folosim backend-ul și valorile implicite ale magazinului de fișiere. GE acceptă alte backend-uri de magazin, cum ar fi AWS (Amazon Web Services) S3, Azure Blobs, PostgreSQL etc. Consultați acest lucru la aflați mai multe despre backend-uri. Fragmentul de cod de mai jos arată o configurație de date foarte simplă:
STORE_FOLDER = "/Users/saisyam/work/github/great-expectations-sample/ge_data"
#Setup data config
data_context_config = DataContextConfig( datasources = {}, store_backend_defaults = FilesystemStoreBackendDefaults(root_directory=STORE_FOLDER)
) context = BaseDataContext(project_config = data_context_config)
Configurația de mai sus folosește backend-ul Magazin de fișiere cu valorile implicite. GE va crea automat folderele necesare pentru a rula așteptările. Vom adăuga surse de date în următorul pas.
Pasul 2: Configurați sursa de date
GE acceptă trei tipuri de surse de date:
- ursi panda
- Scânteie
- SQLAlchemy
Configurarea sursei de date îi spune GE să utilizeze un anumit motor de execuție pentru a procesa setul de date furnizat. De exemplu, dacă vă configurați sursa de date pentru a utiliza motorul de execuție Pandas, trebuie să furnizați un cadru de date Pandas cu date către GE pentru a vă rula așteptările. Mai jos este un exemplu pentru utilizarea Pandas ca sursă de date:
datasource_config = { "name": "sales_datasource", "class_name": "Datasource", "module_name": "great_expectations.datasource", "execution_engine": { "module_name": "great_expectations.execution_engine", "class_name": "PandasExecutionEngine", }, "data_connectors": { "default_runtime_data_connector_name": { "class_name": "RuntimeDataConnector", "module_name": "great_expectations.datasource.data_connector", "batch_identifiers": ["default_identifier_name"], }, },
}
context.add_datasource(**datasource_config)
Va rog, referiti-va la această documentație pentru mai multe informații despre sursele de date.
Pasul 3: Creați o suită de așteptări și adăugați așteptări
Acest pas este partea crucială. În acest pas, vom crea o suită și vom adăuga așteptări la suită. Puteți considera o suită ca un grup de așteptări care va rula ca un lot. Așteptările pe care le creăm aici sunt de a valida un exemplu de raport de vânzări. Puteți descărca vânzări.csv fișier.
Fragmentul de cod de mai jos arată cum să creați o suită și să adăugați așteptări. Vom adăuga două așteptări la suita noastră.
# Create expectations suite and add expectations
suite = context.create_expectation_suite(expectation_suite_name="sales_suite", overwrite_existing=True) expectation_config_1 = ExpectationConfiguration( expectation_type="expect_column_values_to_be_in_set", kwargs={ "column": "product_group", "value_set": ["PG1", "PG2", "PG3", "PG4", "PG5", "PG6"] }
) suite.add_expectation(expectation_configuration=expectation_config_1) expectation_config_2 = ExpectationConfiguration( expectation_type="expect_column_values_to_be_unique", kwargs={ "column": "id" }
) suite.add_expectation(expectation_configuration=expectation_config_2)
context.save_expectation_suite(suite, "sales_suite")
Prima așteptare, „expect_column_values_to_be_in_set” verifică dacă valorile coloanei (product_group) sunt egale cu oricare dintre valorile din value_set dat. A doua așteptare verifică dacă valorile coloanei „id” sunt unice.
Odată ce așteptările sunt adăugate și salvate, acum putem rula aceste așteptări pe un set de date pe care îl vom vedea la pasul 4.
Pasul 4: Încărcați și validați datele
În acest pas, vom încărca fișierul CSV în pandas.DataFrame și vom crea un punct de control pentru a rula așteptările pe care le-am creat mai sus.
# load and validate data
df = pd.read_csv("./sales.csv") batch_request = RuntimeBatchRequest( datasource_name="sales_datasource", data_connector_name="default_runtime_data_connector_name", data_asset_name="product_sales", runtime_parameters={"batch_data":df}, batch_identifiers={"default_identifier_name":"default_identifier"}
) checkpoint_config = { "name": "product_sales_checkpoint", "config_version": 1, "class_name":"SimpleCheckpoint", "expectation_suite_name": "sales_suite"
}
context.add_checkpoint(**checkpoint_config)
results = context.run_checkpoint( checkpoint_name="product_sales_checkpoint", validations=[ {"batch_request": batch_request} ]
)
Creăm o cerere de lot pentru datele noastre, furnizând numele sursei de date, care va spune GE să folosească un motor de execuție specific, în cazul nostru, Pandas. Creăm o configurare a punctului de control și apoi validăm cererea noastră de lot față de punctul de control. Puteți adăuga mai multe solicitări de loturi dacă așteptările se aplică datelor din lot într-un singur punct de control. Metoda `run_checkpoint` returnează rezultatul în format JSON și poate fi folosită pentru procesări ulterioare sau analize.
REZULTATE
Odată ce am rulat așteptările pe setul nostru de date, GE creează un tablou de bord HTML static cu rezultatele pentru punctul nostru de control. Rezultatele conțin numărul de așteptări evaluate, așteptări de succes, așteptări nereușite și procente de succes. Orice înregistrări care nu se potrivesc cu așteptările date vor fi evidențiate pe pagină. Mai jos este un exemplu de execuție cu succes:
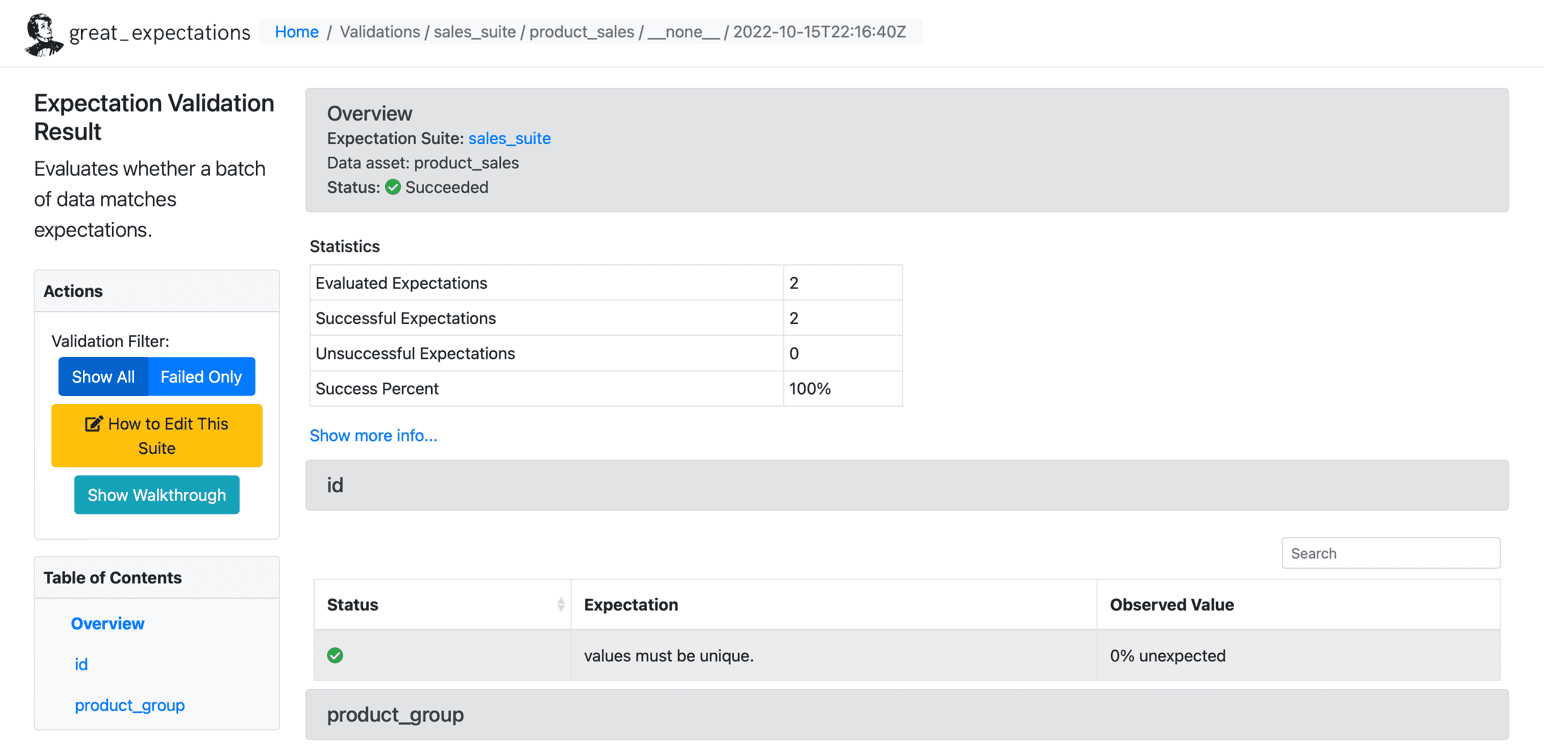
Sursa: Great Expectations
Mai jos este o mostră de așteptare nereușită:
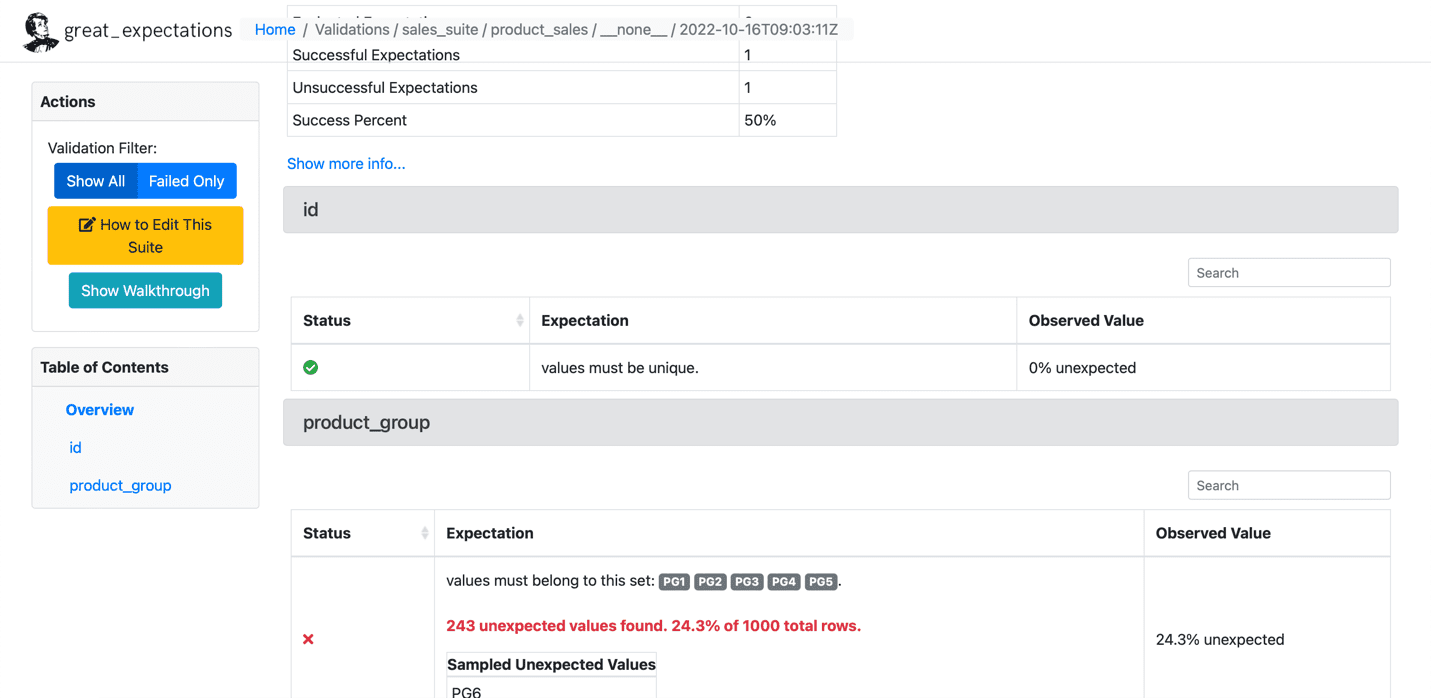
Sursa: Great Expectations
Am configurat GE în patru pași și am rulat cu succes așteptările pe un anumit set de date. GE are funcții mai avansate, cum ar fi scrierea așteptărilor dvs. personalizate, pe care le vom acoperi în articolele viitoare. Multe organizații folosesc GE pe scară largă pentru a personaliza cerințele clienților lor și pentru a scrie așteptări personalizate.
Saisyam Dampuri are peste 18 ani de experiență în dezvoltarea de software și este pasionat de explorarea noilor tehnologii și instrumente. În prezent lucrează ca arhitect senior cloud la Anblicks, TX, SUA. Deși nu codifică, el va fi ocupat cu fotografie, gătit și călătorii.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- Platoblockchain. Web3 Metaverse Intelligence. Cunoștințe amplificate. Accesați Aici.
- Sursa: https://www.kdnuggets.com/2023/01/overcome-data-quality-issues-great-expectations.html?utm_source=rss&utm_medium=rss&utm_campaign=overcome-your-data-quality-issues-with-great-expectations
- 1
- 11
- 18+
- 9
- a
- Despre Noi
- mai sus
- adăugat
- avansat
- împotriva
- TOATE
- Amazon
- Amazon Web Services
- analiză
- Google Analytics
- și
- separat
- Aplică
- articol
- bunuri
- în mod automat
- disponibil
- in medie
- AWS
- Azuriu
- Backend
- Rău
- date proaste
- înainte
- de mai jos
- denumit
- caz
- Verificări
- clientii
- Cloud
- cod
- Codificare
- Coloană
- Comun
- Companii
- companie
- concept
- Configuraţie
- Lua în considerare
- context
- gătit
- Cheltuieli
- acoperi
- crea
- a creat
- creează
- crucial
- În prezent
- personalizat
- client
- comportamentul clienților
- personaliza
- zilnic
- tablou de bord
- de date
- analiza datelor
- calitatea datelor
- set de date
- afacere
- Deciziile
- implicite
- detalii
- Dezvoltare
- document
- Descarca
- Motor
- estimări
- etc
- Eter (ETH)
- evaluat
- exemplu
- a executa
- execuție
- aşteptare
- aşteptări
- experienţă
- Explica
- a explicat
- Explorarea
- A eșuat
- DESCRIERE
- Fișier
- First
- urma
- Forbes
- format
- găsit
- FRAME
- din
- funcții
- mai mult
- viitor
- Câştig
- ge
- dat
- mare
- grup
- ajutor
- ajută
- aici
- Evidențiat
- Cum
- Cum Pentru a
- HTML
- HTTPS
- mare
- important
- in
- inexact
- Inc
- include
- informații
- perspective
- asigurare
- implicat
- probleme de
- IT
- JSON
- KDnuggets
- AFLAȚI
- Bibliotecă
- încărca
- locaţie
- Uite
- Pierde
- de pe
- multe
- Meci
- metodă
- Metode
- milion
- dispărut
- bani
- monitor
- mai mult
- multiplu
- nume
- necesar
- Nevoie
- necesar
- Nou
- Noi tehnologii
- următor
- număr
- open-source
- organizații
- Altele
- Învinge
- panda
- parte
- pasionat
- fotografie
- fizic
- Plato
- Informații despre date Platon
- PlatoData
- Politica
- postgresql
- proces
- prelucrare
- programatic
- furniza
- prevăzut
- furnizează
- furnizarea
- Piton
- calitate
- repede
- înregistrări
- Redus
- raportează
- reputație
- solicita
- cereri de
- Cerinţe
- rezultat
- rezultând
- REZULTATE
- Returnează
- venituri
- norme
- Alerga
- de vânzări
- Al doilea
- Servicii
- set
- instalare
- să
- Emisiuni
- simplu
- singur
- Software
- de dezvoltare de software
- unele
- Sursă
- cod sursă
- Surse
- specific
- Pas
- paşi
- stoca
- magazine
- strategii
- succes
- de succes
- Reușit
- astfel de
- suită
- Sprijină
- Tehnologii
- spune
- test
- teste
- Sursa
- lor
- lucruri
- trei
- timp
- la
- Unelte
- Traveling
- TX
- Tipuri
- în
- unic
- unitate
- us
- USD
- utilizare
- VALIDA
- validare
- Valoros
- Valori
- diverse
- verifica
- volume
- modalități de
- web
- servicii web
- dacă
- care
- în timp ce
- voi
- Apartamente
- de lucru
- scrie
- scris
- ani
- Ta
- zephyrnet

![Cum se accelerează interogările SQL folosind indexuri [Ediția Python] - KDnuggets](https://platoaistream.net/wp-content/uploads/2023/08/how-to-speed-up-sql-queries-using-indexes-python-edition-kdnuggets-360x203.png)





