Această serie de trei părți demonstrează cum se utilizează rețelele neuronale grafice (GNN) și Amazon Neptun pentru a genera recomandări de filme folosind IMDb și Box Office Mojo Movies/TV/OTT pachet de date cu licență, care oferă o gamă largă de metadate de divertisment, inclusiv peste 1 miliard de evaluări ale utilizatorilor; credite pentru mai mult de 11 milioane de membri ai distribuției și echipajului; 9 milioane de titluri de filme, TV și divertisment; și date de raportare la box office la nivel mondial din peste 60 de țări. Mulți clienți media și divertisment AWS licențiază datele IMDb prin Schimb de date AWS pentru a îmbunătăți descoperirea de conținut și pentru a crește implicarea și reținerea clienților.
In Partea 1, am discutat despre aplicațiile GNN-urilor și cum să transformăm și să pregătim datele noastre IMDb pentru interogare. În această postare, discutăm despre procesul de utilizare a Neptune pentru a genera înglobări utilizate pentru a efectua căutările noastre în afara catalogului din partea 3. Trecem și noi peste Amazon Neptune ML, caracteristica de învățare automată (ML) a lui Neptune și codul pe care îl folosim în procesul nostru de dezvoltare. În Partea 3, vom parcurge cum să aplicăm înglobarea graficelor noastre de cunoștințe într-un caz de utilizare de căutare în afara catalogului.
Prezentare generală a soluțiilor
Seturile mari de date conectate conțin adesea informații valoroase care pot fi greu de extras folosind interogări bazate doar pe intuiția umană. Tehnicile ML pot ajuta la găsirea corelațiilor ascunse în grafice cu miliarde de relații. Aceste corelații pot fi utile pentru recomandarea produselor, estimarea solvabilității, identificarea fraudelor și multe alte cazuri de utilizare.
Neptune ML face posibilă construirea și antrenamentul de modele ML utile pe grafice mari în ore în loc de săptămâni. Pentru a realiza acest lucru, Neptune ML folosește tehnologia GNN alimentată de Amazon SageMaker si Biblioteca Deep Graph (DGL) (care este open-source). GNN-urile sunt un domeniu emergent în inteligența artificială (de exemplu, a se vedea Un studiu cuprinzător asupra rețelelor neuronale grafice). Pentru un tutorial practic despre utilizarea GNN-urilor cu DGL, consultați Învățarea rețelelor neuronale cu grafice cu Deep Graph Library.
În această postare, arătăm cum să folosim Neptune în conducta noastră pentru a genera înglobări.
Următoarea diagramă ilustrează fluxul general de date IMDb de la descărcare până la generarea de încorporare.
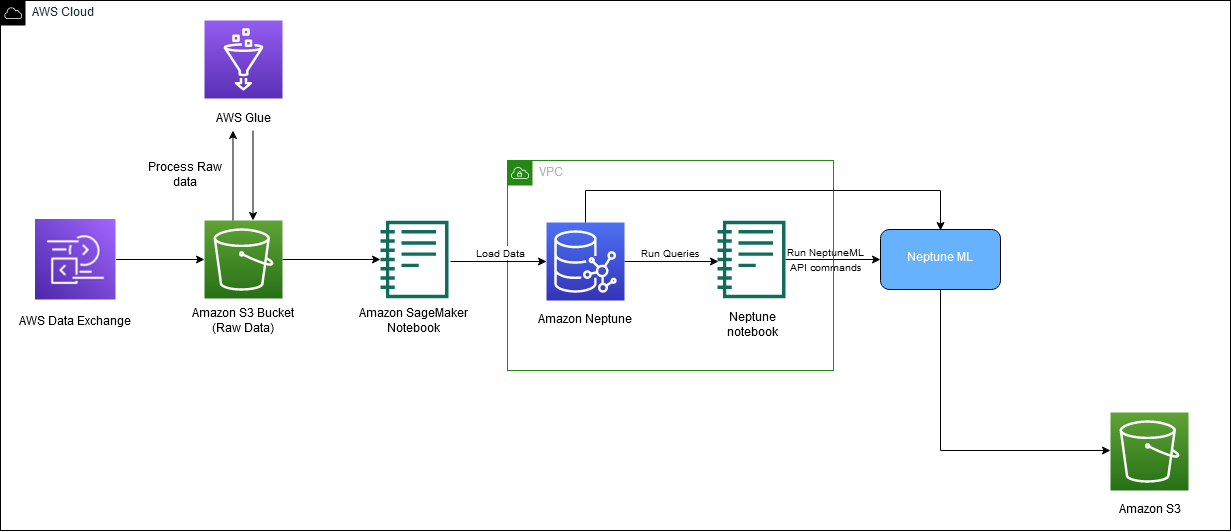
Utilizăm următoarele servicii AWS pentru a implementa soluția:
În această postare, vă prezentăm următorii pași de nivel înalt:
- Configurați variabilele de mediu
- Creați un job de export.
- Creați un job de procesare a datelor.
- Trimiteți un job de formare.
- Descărcați încorporații.
Cod pentru comenzile Neptune ML
Utilizăm următoarele comenzi ca parte a implementării acestei soluții:
Noi folosim neptune_ml export pentru a verifica starea sau a începe un proces de export Neptune ML și neptune_ml training pentru a începe și a verifica starea unui job de formare model Neptune ML.
Pentru mai multe informații despre aceste și alte comenzi, consultați Folosind magia bancului de lucru Neptune în caietele tale.
Cerințe preliminare
Pentru a urma această postare, ar trebui să aveți următoarele:
- An Cont AWS
- Familiarizare cu SageMaker, Amazon S3 și AWS CloudFormation
- Grafice datele încărcate în clusterul Neptun (vezi Partea 1 pentru mai multe informatii)
Configurați variabilele de mediu
Înainte de a începe, va trebui să vă configurați mediul setând următoarele variabile: s3_bucket_uri și processed_folder. s3_bucket_uri este numele găleții utilizate în partea 1 și processed_folder este locația Amazon S3 pentru ieșirea din jobul de export.
Creați un job de export
În partea 1, am creat un notebook SageMaker și un serviciu de export pentru a ne exporta datele din clusterul Neptune DB în Amazon S3 în formatul necesar.
Acum că datele noastre sunt încărcate și serviciul de export este creat, trebuie să creăm un job de export, porniți-l. Pentru a face acest lucru, folosim NeptuneExportApiUri și creați parametri pentru jobul de export. În codul următor, folosim variabilele expo și export_params. A stabilit expo de dvs. NeptuneExportApiUri valoare, pe care o puteți găsi pe ieşiri fila din stiva dvs. CloudFormation. Pentru export_params, folosim punctul final al clusterului dvs. Neptune și oferim valoarea pentru outputS3path, care este locația Amazon S3 pentru ieșirea din jobul de export.
Pentru a trimite jobul de export, utilizați următoarea comandă:
Pentru a verifica starea jobului de export, utilizați următoarea comandă:
După finalizarea sarcinii, setați processed_folder variabilă pentru a furniza locația Amazon S3 a rezultatelor procesate:
Creați un job de procesare a datelor
Acum că exportul este finalizat, creăm o lucrare de procesare a datelor pentru a pregăti datele pentru procesul de instruire Neptune ML. Acest lucru se poate face în câteva moduri diferite. Pentru acest pas, puteți schimba job_name și modelType variabile, dar toți ceilalți parametri trebuie să rămână aceiași. Partea principală a acestui cod este modelType parametru, care poate fi fie modele grafice eterogene (heterogeneous) sau grafice de cunoștințe (kge).
Lucrarea de export include și training-data-configuration.json. Utilizați acest fișier pentru a adăuga sau elimina orice noduri sau margini pe care nu doriți să le furnizați pentru antrenament (de exemplu, dacă doriți să preziceți legătura dintre două noduri, puteți elimina legătura respectivă din acest fișier de configurare). Pentru această postare de blog folosim fișierul de configurare original. Pentru informații suplimentare, vezi Editarea unui fișier de configurare a antrenamentului.
Creați-vă jobul de procesare a datelor cu următorul cod:
Pentru a verifica starea jobului de export, utilizați următoarea comandă:
Trimiteți un job de formare
După ce lucrarea de procesare este finalizată, putem începe munca noastră de formare, care este locul în care ne creăm înglobările. Vă recomandăm un tip de instanță ml.m5.24xlarge, dar îl puteți modifica pentru a se potrivi nevoilor dvs. de calcul. Vezi următorul cod:
Tipărim variabila training_results pentru a obține ID-ul jobului de instruire. Utilizați următoarea comandă pentru a verifica starea jobului dvs.:
%neptune_ml training status --job-id {training_results['id']} --store-to training_status_results
Descărcați încorporații
După ce munca dvs. de formare este finalizată, ultimul pas este să descărcați încorporațiile dvs. brute. Următorii pași vă arată cum să descărcați înglobările create folosind KGE (puteți folosi același proces pentru RGCN).
În următorul cod, folosim neptune_ml.get_mapping() și get_embeddings() pentru a descărca fișierul de mapare (mapping.info) și fișierul de încorporare brută (entity.npy). Apoi trebuie să mapam înglobările corespunzătoare la ID-urile corespunzătoare.
Pentru a descărca RGCN, urmați același proces cu un nou nume de job de antrenament prin procesarea datelor cu parametrul modelType setat la heterogeneous, apoi antrenați-vă modelul cu parametrul modelName setat la rgcn vedea aici pentru mai multe detalii. Odată ce ați terminat, sunați la get_mapping și get_embeddings funcții pentru a descărca noul dvs mapping.info și entitate.npy fișiere. După ce aveți fișierele de entitate și de mapare, procesul de creare a fișierului CSV este identic.
În cele din urmă, încărcați încorporațiile dvs. în locația dorită din Amazon S3:
Asigurați-vă că vă amintiți această locație S3, va trebui să o utilizați în partea 3.
A curăța
Când ați terminat de utilizat soluția, asigurați-vă că curățați orice resurse pentru a evita taxele continue.
Concluzie
În această postare, am discutat despre cum să folosiți Neptune ML pentru a antrena înglobările GNN din datele IMDb.
Unele aplicații înrudite ale înglobărilor de grafice de cunoștințe sunt concepte precum căutarea în afara catalogului, recomandările de conținut, publicitatea direcționată, predicția legăturilor lipsă, căutarea generală și analiza cohortelor. Căutarea în afara catalogului este procesul de căutare a conținutului pe care nu îl dețineți și de găsire sau recomandare de conținut care se află în catalogul dvs., care este cât mai aproape de ceea ce a căutat utilizatorul. Ne aprofundăm în căutarea în afara catalogului în partea 3.
Despre Autori
 Matthew Rhodes este un Data Scientist și lucrez în Amazon ML Solutions Lab. El este specializat în construirea conductelor de învățare automată care implică concepte precum Procesarea limbajului natural și Viziunea pe computer.
Matthew Rhodes este un Data Scientist și lucrez în Amazon ML Solutions Lab. El este specializat în construirea conductelor de învățare automată care implică concepte precum Procesarea limbajului natural și Viziunea pe computer.
 Divya Bhargavi este Data Scientist și Media and Entertainment Vertical Lead la Amazon ML Solutions Lab, unde rezolvă probleme de afaceri de mare valoare pentru clienții AWS folosind Machine Learning. Lucrează la înțelegerea imaginilor/video, sistemelor de recomandare cu grafice de cunoștințe, cazuri de utilizare a publicității predictive.
Divya Bhargavi este Data Scientist și Media and Entertainment Vertical Lead la Amazon ML Solutions Lab, unde rezolvă probleme de afaceri de mare valoare pentru clienții AWS folosind Machine Learning. Lucrează la înțelegerea imaginilor/video, sistemelor de recomandare cu grafice de cunoștințe, cazuri de utilizare a publicității predictive.
 Gaurav Rele este Data Scientist la Amazon ML Solution Lab, unde lucrează cu clienții AWS din diferite verticale pentru a accelera utilizarea învățării automate și a serviciilor AWS Cloud pentru a-și rezolva provocările de afaceri.
Gaurav Rele este Data Scientist la Amazon ML Solution Lab, unde lucrează cu clienții AWS din diferite verticale pentru a accelera utilizarea învățării automate și a serviciilor AWS Cloud pentru a-și rezolva provocările de afaceri.
 Karan Sindwani este Data Scientist la Amazon ML Solutions Lab, unde construiește și implementează modele de deep learning. Este specializat în domeniul vederii computerizate. În timpul liber, îi place drumețiile.
Karan Sindwani este Data Scientist la Amazon ML Solutions Lab, unde construiește și implementează modele de deep learning. Este specializat în domeniul vederii computerizate. În timpul liber, îi place drumețiile.
 Soji Adeshina este un om de știință aplicat la AWS, unde dezvoltă modele bazate pe rețele neuronale grafice pentru învățarea automată pe sarcini de grafice cu aplicații pentru fraudă și abuz, grafice de cunoștințe, sisteme de recomandare și științe ale vieții. În timpul liber, îi place să citească și să gătească.
Soji Adeshina este un om de știință aplicat la AWS, unde dezvoltă modele bazate pe rețele neuronale grafice pentru învățarea automată pe sarcini de grafice cu aplicații pentru fraudă și abuz, grafice de cunoștințe, sisteme de recomandare și științe ale vieții. În timpul liber, îi place să citească și să gătească.
 Vidya Sagar Ravipati este manager la Amazon ML Solutions Lab, unde își valorifică experiența vastă în sistemele distribuite la scară largă și pasiunea pentru învățarea automată pentru a ajuta clienții AWS din diferite verticale din industrie să-și accelereze adoptarea AI și a cloud-ului.
Vidya Sagar Ravipati este manager la Amazon ML Solutions Lab, unde își valorifică experiența vastă în sistemele distribuite la scară largă și pasiunea pentru învățarea automată pentru a ajuta clienții AWS din diferite verticale din industrie să-și accelereze adoptarea AI și a cloud-ului.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- Platoblockchain. Web3 Metaverse Intelligence. Cunoștințe amplificate. Accesați Aici.
- Sursa: https://aws.amazon.com/blogs/machine-learning/part-2-power-recommendations-and-search-using-an-imdb-knowledge-graph/
- 1
- 10
- 100
- 11
- 116
- 7
- 9
- a
- Despre Noi
- abuz
- accelera
- peste
- Suplimentar
- informatii suplimentare
- Adoptare
- Promovare
- După
- AI
- TOATE
- singur
- Amazon
- Laboratorul Amazon ML Solutions
- analiză
- și
- aplicatii
- aplicat
- Aplică
- adecvat
- ZONĂ
- artificial
- inteligență artificială
- AWS
- bazat
- între
- Miliard
- miliarde
- Blog
- Cutie
- box office
- construi
- Clădire
- construiește
- afaceri
- apel
- caz
- cazuri
- catalog
- provocări
- Schimbare
- taxe
- verifica
- Închide
- Cloud
- adoptarea norului
- servicii de tip cloud
- Grup
- cod
- Cohortă
- Completă
- cuprinzător
- calculator
- Computer Vision
- tehnica de calcul
- Concepte
- Conduce
- Configuraţie
- legat
- conţinut
- Corespunzător
- țări
- crea
- a creat
- credit
- credite
- client
- Angajarea cu clienții
- clienţii care
- de date
- de prelucrare a datelor
- om de știință de date
- seturi de date
- adânc
- învățare profundă
- Mai adânc
- implementează
- detalii
- Dezvoltare
- dezvoltă
- dgl
- diferit
- descoperire
- discuta
- discutat
- distribuite
- sisteme distribuite
- Dont
- Descarca
- oricare
- șmirghel
- Punct final
- angajament
- Divertisment
- entitate
- Mediu inconjurator
- Eter (ETH)
- exemplu
- experienţă
- exporturile
- extrage
- Caracteristică
- puțini
- camp
- Fișier
- Fişiere
- Găsi
- descoperire
- debit
- urma
- următor
- format
- fraudă
- din
- Complet
- funcții
- General
- genera
- generaţie
- obține
- Caritate
- Go
- grafic
- grafice
- hands-on
- Greu
- ajutor
- util
- Ascuns
- la nivel înalt
- ORE
- Cum
- Cum Pentru a
- HTML
- HTTPS
- uman
- identic
- identificarea
- punerea în aplicare a
- Punere în aplicare a
- îmbunătăţi
- in
- include
- Inclusiv
- Crește
- index
- industrie
- info
- informații
- instanță
- in schimb
- Inteligență
- implica
- IT
- Loc de munca
- JSON
- Cheie
- cunoştinţe
- de laborator
- limbă
- mare
- pe scară largă
- Nume
- conduce
- învăţare
- pîrghii
- Bibliotecă
- Licență
- Viaţă
- Life Sciences
- LINK
- Link-uri
- locaţie
- maşină
- masina de învățare
- Principal
- FACE
- manager
- multe
- Hartă
- cartografiere
- Mass-media
- mediu
- Membri actuali
- Metadata
- milion
- dispărut
- ML
- model
- Modele
- mai mult
- film
- nume
- Natural
- Procesarea limbajului natural
- Nevoie
- nevoilor
- Neptun
- bazat pe rețea
- rețele
- rețele neuronale
- Nou
- noduri
- caiet
- Birou
- în curs de desfășurare
- original
- Altele
- global
- propriu
- pachet
- parametru
- parametrii
- parte
- pasiune
- conducte
- Plato
- Informații despre date Platon
- PlatoData
- posibil
- Post
- putere
- alimentat
- prezice
- estimarea
- Pregăti
- probleme
- proces
- prelucrare
- Produse
- Profil
- furniza
- furnizează
- gamă
- evaluări
- Crud
- Citind
- recomanda
- Recomandare
- Recomandări
- recomandând
- legate de
- Relaţii
- rămâne
- minte
- scoate
- Raportarea
- necesar
- Resurse
- REZULTATE
- retenţie
- sagemaker
- acelaşi
- ȘTIINȚE
- Om de stiinta
- Caută
- căutare
- serie
- serviciu
- Servicii
- set
- instalare
- să
- Arăta
- soluţie
- soluţii
- REZOLVAREA
- rezolvă
- specializată
- stivui
- Începe
- Stare
- Pas
- paşi
- stoca
- prezenta
- astfel de
- Costum
- Sondaj de opinie
- sisteme
- vizate
- sarcini
- tehnici de
- Tehnologia
- Zona
- lor
- Prin
- timp
- titluri
- la
- Tren
- Pregătire
- Transforma
- adevărat
- tutorial
- tv
- înţelegere
- utilizare
- carcasa de utilizare
- Utilizator
- Valoros
- valoare
- Fixă
- versiune
- verticalele
- viziune
- modalități de
- săptămâni
- Ce
- care
- larg
- Gamă largă
- voi
- de lucru
- fabrică
- Ta
- zephyrnet