Acest articol a fost publicat ca parte a Blogathon Data Science.
Cuprins
- Introducere
- Intervale de încredere cu statistică Z
- Interpretarea intervalelor de încredere
- Ipoteze pentru CI folosind statistica z
- Intervale de încredere cu t-statistică
- Ipoteze pentru CI folosind t-statistica
- Efectuarea unui interval t cu date împerecheate
- valoarea z vs valoarea t: când să folosiți ce?
- Intervale de încredere cu python
- Notă finală
Introducere
Ori de câte ori rezolvăm o problemă statistică suntem preocupați de estimarea parametrilor populației, dar de cele mai multe ori este aproape imposibil să se calculeze parametrii populației. Ceea ce facem în schimb este să luăm eșantioane aleatorii din populație și să calculăm statisticile eșantionului așteptându-se să aproximeze parametrii populației. Dar de unde știm dacă eșantioanele sunt reprezentanți adevărați ai populației sau cât de mult se abate aceste statistici ale eșantionului de la parametrii populației? Aici intervin intervalele de încredere. Deci, care sunt aceste intervale? Intervalul de încredere este un interval de valori care se situează deasupra și sub statisticile eșantionului sau îl putem defini și ca probabilitatea ca un interval de valori din jurul statisticii eșantionului să conțină parametrul populației adevărat.
Intervale de încredere cu statistică Z
Înainte de a aprofunda subiectul, să ne familiarizăm cu câteva terminologii statistice.
populație: Este ansamblul tuturor indivizilor similari. De exemplu populația unui oraș, studenții unui colegiu etc.
probă: Este un mic set de indivizi similari extrași din populație. În mod similar, un eșantion aleatoriu este un eșantion extras la întâmplare din populație.
parametrii: medie (mu), abateri standard (sigma), proporție (p) derivată din populație.
statistic: medie (x bar), abatere standard (S), proporții (p^) referitoare la eșantioane.
Z-scor: este distanța oricărui punct de date brute pe o distribuție normală față de media normalizată prin abaterea std. Dat de: x-mu/sigma
În regulă, acum suntem gata să ne scufundăm adânc în conceptul de intervale de încredere. Dintr-un anumit motiv, cred că este mult mai bine să înțelegem conceptele prin exemple care pot fi identificate, mai degrabă decât prin definiții matematice brute. Deci sa începem.
Să presupunem că locuiești într-un oraș cu 100,000 de locuitori și se apropie alegeri. În calitate de sondaj, trebuie să prognozați cine va câștiga alegerile fie partidul albastru, fie galben. Deci, vedeți că este aproape imposibil să colectați informații de la întreaga populație, așa că alegeți la întâmplare 100 de persoane. La sfârșitul sondajului, ați descoperit că 62% dintre oameni vor vota galben. Acum întrebarea este să ajungem la concluzia că galbenul va câștiga cu o probabilitate de câștig de 62% sau 62% din întreaga populație va vota pentru galben? Ei bine, răspunsul este NU. Nu știm sigur cât de departe este estimarea noastră de parametrul adevărat, dacă luăm un alt eșantion rezultatul se poate dovedi a fi 58% sau 65%. Deci, ceea ce vom face în schimb este să găsim o gamă de valori în jurul statisticii noastre eșantion care va capta cel mai probabil proporția reală a populației. Aici, proporția se referă la procentul de

imaginea aparține autorului
Acum, dacă luăm o sută de astfel de eșantioane și trasăm proporția eșantionului din fiecare eșantion, vom obține o distribuție normală a proporțiilor de eșantionare, iar media distribuției va fi valoarea cea mai aproximativă a proporției populației. Iar estimarea noastră ar putea fi oriunde pe curba de distribuție. Conform regulii 3-sigma, știm că aproximativ 95% dintre variabilele aleatoare se află în 2 abateri std de la media distribuției. Deci, putem concluziona că probabilitatea ca p^ este în 2 std abateri de p este de 95%. Sau putem afirma, de asemenea, că probabilitatea ca p să fie cu 2 std abateri sub și deasupra p^ este, de asemenea, de 95%. Aceste două afirmații sunt efectiv echivalente. Aceste două puncte de sub și deasupra p^ sunt intervalele noastre de încredere.

imaginea aparține autorului
Dacă putem găsi cumva sigma, putem calcula intervalul necesar. Dar sigma aici este parametrul populației și știm că este adesea aproape imposibil de calculat, așa că în schimb vom folosi statistici eșantion, adică eroarea standard. Acesta este dat ca
unde p^= proporția eșantionului, n=numărul de eșantioane
SE =√(0.62 . 0.38/100) = 0.05
deci, 2xSE = 0.1
Intervalul de încredere pentru datele noastre este (0.62-0.1,0.62+0.1) sau (0.52,0.72). Deoarece am luat 2xSE, acest lucru se traduce într-un interval de încredere de 95%.
Acum, întrebarea este ce dacă vrem să creăm un interval de încredere de 92%? În exemplul anterior, am înmulțit 2 cu SE pentru a construi un interval de încredere de 95%, acest 2 este scorul z pentru un interval de încredere de 95% (valoarea exactă fiind 1.96) și această valoare poate fi găsită dintr-un tabel z. Valoarea critică a lui z pentru un interval de încredere de 92% este 1.75. A se referi la acest articol pentru o mai bună înțelegere a scorului z și tabelului z.
Intervalul este dat de: (p^ + z*.SE , p^-z*.SE).
Dacă în loc de proporția eșantionului se dă media eșantionului, eroarea standard va fi sigma/sqrt(n). Aici sigma este abaterea std a populației, deoarece adesea nu avem, folosim în schimb abaterea std eșantion. Dar se observă adesea că acest tip de estimare în care se dă media rezultatului tinde să fie puțin părtinitoare. Deci, în astfel de cazuri, este de preferat să folosiți statistica t în loc de statistica z.
Formula generală pentru un interval de încredere cu statistici z este dată de
Aici, statistica se referă fie la media eșantionului, fie la proporția eșantionului. sigmas sunt deviația standard a populației.
Interpretarea intervalelor de încredere
Este foarte important să interpretăm corect intervalele de încredere. Luați în considerare exemplul anterior al sondajului în care am calculat intervalul nostru de încredere de 95% ca fiind (0.52,0.62, 95). Ce inseamna asta? Ei bine, un interval de încredere de 95% înseamnă că dacă extragem n eșantioane din populație, atunci 95% din timp intervalul derivat va conține proporția reală a populației. Amintiți-vă că un interval de încredere de 95% nu înseamnă că există o probabilitate de 90% ca intervalul să conțină proporția reală a populației. De exemplu, pentru un interval de încredere de 10%, dacă extragem 9 eșantioane dintr-o populație, atunci de 10 din XNUMX ori intervalul menționat va conține parametrul populației adevărat. Priviți imaginea de mai jos pentru o mai bună înțelegere.

imaginea aparține autorului
Ipoteze pentru intervalele de încredere folosind statistica Z
Există anumite ipoteze pe care trebuie să le căutăm pentru a construi un interval de încredere valid folosind statistica z.
- Eșantion aleatoriu: mostrele trebuie să fie aleatorii. Există diferite metode de eșantionare, cum ar fi eșantionarea stratificată, eșantionarea aleatorie simplă, eșantionarea în cluster pentru a obține eșantioane aleatorii.
- Condiție normală: datele trebuie să îndeplinească această condiție np^>=10 și n.(1-p^)>=10. În esență, aceasta înseamnă că distribuția noastră de eșantionare a mijloacelor eșantionului trebuie să fie normală, nu deformată pe nici o parte.
- Independent: mostrele trebuie să fie independente. Numărul de probe trebuie să fie mai mic sau egal cu 10% din populația totală sau dacă eșantionarea se face cu înlocuire.
Intervale de încredere cu T-statistică
Ce se întâmplă dacă dimensiunea eșantionului este relativ mică și abaterea standard a populației nu este dată sau nu poate fi presupusă? Cum construim un interval de încredere? Ei bine, aici intervine t-statistica. Formula de bază pentru găsirea intervalului de încredere aici rămâne aceeași cu doar z* înlocuit cu t*. Formula generală este dată de
unde S = abaterea standard a probei, n = numărul de probe
Să presupunem că ați găzduit o petrecere și doriți să estimați consumul mediu de bere de către invitații dvs. Deci, obțineți un eșantion aleatoriu de 20 de indivizi și măsurați consumul de bere. Datele eșantionului sunt simetrice, cu o medie 0f 1200 ml și o abatere standard de 120 ml. Deci, acum doriți să construiți un interval de încredere de 95%.
Deci, avem deviația standard a eșantionului, numărul de eșantioane și media eșantionului. Tot ce ne trebuie este t*. Deci, t* pentru un interval de încredere de 95% cu un grad de libertate de 19(n-1 = 20-1) este 2.093. Deci, intervalul nostru necesar este după ce calculul este (1256.16, 1143.83) cu o marjă de eroare de 56.16. A se referi la acest video pentru a ști cum să citești tabelul t.
Ipoteze pentru CI folosind T-statistic
Similar cu cazul statisticii z și aici și în cazul statisticii t, există anumite condiții pe care trebuie să le luăm în considerare în datele date.
- Eșantionul trebuie să fie aleatoriu
- Eșantionul trebuie să fie normal. Pentru a fi normal, dimensiunea eșantionului ar trebui să fie mai mare sau egală cu 30 sau dacă setul de date părinte, adică populația este aproximativ normală. Sau dacă dimensiunea eșantionului este sub 30, atunci distribuția trebuie să fie aproximativ simetrică.
- Observațiile individuale trebuie să fie independente. Aceasta înseamnă că urmează regula 10% sau eșantionarea se face cu înlocuire.
Realizarea unui interval T pentru datele pereche
Până acum am folosit doar date dintr-un singur eșantion. Acum vom vedea cum putem construi un interval t pentru datele pereche. În datele pereche, facem două observații asupra aceluiași individ. De exemplu, compararea notelor pre-test și post-test ale studenților sau date privind efectul unui medicament și placebo asupra unui grup de persoane. În datele pereche, am găsit diferența dintre cele două observații în coloana a treia. Ca de obicei, vom parcurge un exemplu pentru a înțelege și acest concept,
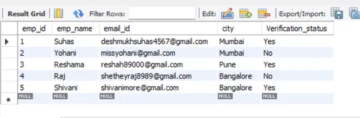
Î. Un profesor a încercat să evalueze efectul unui nou curriculum asupra rezultatului testului. Mai jos sunt rezultatele observațiilor.

imaginea aparține autorului
Deoarece intenționăm să găsim intervale pentru diferența de medie, avem nevoie doar de statistici pentru diferențe. Vom folosi aceeași formulă pe care am folosit-o înainte
statistic +- (valoare critică sau valoare t) (abaterea standard a statisticii)
xd = media diferenței, Sd = abaterea std eșantionului, pentru un CI de 95% cu un grad de libertate 5 t* este dat de 2.57. Marja de eroare = 0.97 și intervalul de încredere (4.18,6.13).
Interpretare: Din estimările de mai sus, după cum putem vedea, intervalul de încredere nu conține valori zero sau negative. Astfel, putem concluziona că noul curriculum a avut un impact pozitiv asupra performanțelor la test ale elevilor. Dacă ar avea doar valori negative atunci am putea spune că curriculum-ul a avut un impact negativ. Sau dacă ar conține zero, atunci ar putea exista posibilitatea ca diferența să fie zero sau să nu aibă niciun efect al curriculumului asupra rezultatelor testelor.
Valoarea Z vs valoarea T
Există multă confuzie la început cu privire la când să folosiți ce. Regula generală este atunci când dimensiunea eșantionului este >= 30 și se știe că deviația standard a populației folosește statisticile z. În cazul în care dimensiunea eșantionului este < 30, utilizați statisticile t. În viața reală, nu avem parametri de populație, așa că vom merge cu z sau t în funcție de dimensiunea eșantionului.
La eșantioane mai mici (n<30) nu se aplică teorema LIMIT centrală și se folosește o altă distribuție numită distribuția t a lui Student. Distribuția t este similară cu distribuția normală, dar ia forme diferite în funcție de dimensiunea eșantionului. În loc de valorile z, sunt utilizate valorile t care sunt mai mari pentru eșantioanele mai mici, producând o marjă de eroare mai mare. Deoarece un eșantion mic va fi mai puțin precis.
Intervale de încredere cu Python
Python are o bibliotecă vastă care acceptă tot felul de calcule statistice care ne fac viața puțin mai ușoară. În această secțiune, vom analiza datele despre obiceiurile de somn ale copiilor mici. Cei 20 de participanți la aceste observații au fost sănătoși, s-au comportat normal, nu au avut nicio tulburare de somn. Scopul nostru este să analizăm ora de culcare a copiilor mici și care nu dorm.
Referință: Akacem LD, Simpkin CT, Carskadon MA, Wright KP Jr, Jenni OG, Achermann P și colab. (2015) Timpul ceasului circadian și a somnului diferă între copiii care dorm și cei care nu dorm. PLoS ONE 10(4): e0125181. https://doi.org/10.1371/journal.pone.0125181
Vom importa biblioteci de care vom avea nevoie
import numpy as np import pandas as pd from scipy.stats import t pd.set_option('display.max_columns', 30) # set so can see all columns of the DataFrame import math
df = pd.read_csv(nap_no_nap.csv) #reading data
df.head ()

Creați două intervale de încredere de 95% pentru ora medie de culcare, unul pentru copiii mici care dorm și unul pentru copiii mici care nu. În primul rând, vom izola coloana „ora de culcare noaptea” pentru cei care dorm într-o nouă variabilă și pentru cei care nu au dormit într-o altă variabilă nouă. Ora de culcare aici este zecimalizată.
bedtime_nap = df['night bedtime'].loc[df['napping'] == 1] bedtime_no_nap = df['night bedtime'].loc[df['napping'] == 0]
print(len(ora de somn))
print(len(ora de culcare_nu_sesta))
ieșire: 15 n 5
Acum, vom găsi exemplul de ora medie de culcare pentru nap și no_nap.
nap_mean_bedtime = bedtime_nap.mean() #20.304 no_nap_mean_bedtime = bedtime_no_nap.mean() #19.59
Acum, vom găsi abaterea standard eșantion pentru Xzi și Xnici un pui de somn
nap_s_bedtime = np.std(bedtime_nap,ddof=1) no_nap_s_bedtime = np.std(bedtime_no_nap,ddof=1)
Notă: Parametrul ddof este setat la 1 pentru eșantion std dev sau va deveni populație std dev.
Acum, vom găsi eșantionul de eroare standard pentru Xzi și Xnici un pui de somn
nap_se_mean_bedtime = nap_s_bedtime/math.sqrt(len(bedtime_nap)) #0.1526 no_nap_se_mean_bedtime = no_nap_s_bedtime/math.sqrt(len(bedtime_no_nap)) #0.2270
Până acum e bine, acum, deoarece dimensiunea eșantionului este mică și nu avem o abatere standard a proporției populației, vom folosi valoarea t*. O modalitate de a găsi valoarea t* este prin utilizarea scipy.stats t.ppf funcţie. Argumentele pentru t.ppf() sunt q = procent, df = grad de libertate, scară = std dev, loc = medie. Deoarece distribuția t este simetrică pentru un interval de încredere de 95%, q va fi 0.975. A se referi la acest pentru mai multe informații despre t.ppf().
nap_t_star = t.ppf(0.975,df=14) #2.14 no_nap_t_star = t.ppf(0.975,df=5) #2.57
Acum, vom adăuga piesele pentru a ne construi în sfârșit intervalul de încredere.
nap_ci_plus = nap_mean_bedtime + nap_t_star*nap_se_bedtime
nap_ci_minus = nap_mean_bedtime – nap_t_star*nap_se_bedtime
print(nap_ci_minus,nap_ci_plus)
no_nap_ci_plus = no_nap_mean_bedtime + no_nap_t_star*nap_se_bedtime
no_nap_ci_minus = no_nap_mean_bedtime – no_nap_t_star*nap_se_bedtime
print(no_nap_ci_minus,no_nap_ci_plus)
output: 19.976680775477412 20.631319224522585 18.95974084563192 20.220259154368087
Interpretare:
Din rezultatele de mai sus, concluzionăm că suntem 95% încrezători că ora medie de culcare pentru copiii mici este între orele 19.98 – 20.63 (pm), în timp ce pentru copiii care nu dorm este între 18.96 – 20.22 (pm). Aceste rezultate sunt conform așteptărilor noastre că, dacă tragi un pui de somn în timpul zilei, vei dormi noaptea târziu.
Note de sfârșit
Deci, totul a fost vorba despre simple intervale de încredere folosind valorile z și t. Este într-adevăr un concept important de cunoscut în cazul oricărui studiu statistic. O metodă statistică inferențială excelentă pentru a estima parametrii populației din datele eșantionului. Intervalele de încredere sunt, de asemenea, legate de testarea ipotezei conform căreia pentru un CI de 95% lăsați spațiu de 5% pentru anomalii. Dacă ipoteza nulă se încadrează în intervalul de încredere, atunci valoarea p va fi mare și nu vom putea respinge nul. În schimb, dacă depășește, atunci vom avea suficiente dovezi pentru a respinge ipotezele nule și pentru a accepta ipoteze alternative.
Sper că ți-a plăcut articolul și La mulți ani (:
Media prezentate în acest articol nu este deținută de Analytics Vidhya și sunt utilizate la discreția Autorului.
Legate de
Sursa: https://www.analyticsvidhya.com/blog/2022/01/understanding-confidence-intervals-with-python/
- "
- 000
- 100
- 9
- 98
- Despre Noi
- TOATE
- Google Analytics
- API-uri
- argumente
- în jurul
- articol
- in medie
- bere
- Început
- fiind
- Pic
- cazuri
- Oraș
- Ceas
- Colegiu
- Coloană
- încredere
- confuzie
- consum
- ar putea
- critic
- curba
- de date
- zi
- dev
- diferi
- diferit
- tulburare
- distanţă
- elaborate
- medicament
- în timpul
- efect
- Alegere
- estima
- estimări
- etc
- exemplu
- În cele din urmă
- First
- găsit
- Libertate
- funcţie
- General
- merge
- bine
- mare
- grup
- aici
- Cum
- Cum Pentru a
- HTTPS
- imagine
- Impactul
- important
- importatoare
- individ
- info
- informații
- IT
- mare
- Bibliotecă
- Efectuarea
- Mass-media
- ML
- mai mult
- înmulțit
- În apropiere
- Anul Nou
- oameni
- procent
- imagine
- populație
- Problemă
- dovadă
- Piton
- întrebare
- gamă
- Crud
- date neprelucrate
- REZULTATE
- Scară
- Ştiinţă
- set
- forme
- asemănător
- simplu
- Mărimea
- dormi
- mic
- So
- REZOLVAREA
- Spaţiu
- început
- Stat
- statistică
- Statistici
- Studiu
- Sondaj de opinie
- profesor
- test
- Testarea
- Prin
- timp
- valoare
- Video
- Vot
- Vot
- Ce
- OMS
- câştiga
- în
- X
- an
- zero