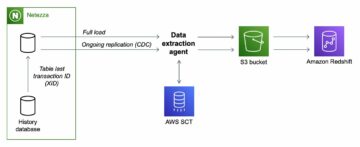
Apache Iceberg este un format de tabel deschis pentru seturi de date analitice foarte mari, care captează informații despre metadate despre starea seturilor de date pe măsură ce acestea evoluează și se schimbă în timp. Adaugă tabele la motoarele de calcul, inclusiv Spark, Trino, PrestoDB, Flink și Hive, folosind un format de tabel de înaltă performanță care funcționează la fel ca un tabel SQL. Iceberg a devenit foarte popular pentru suportul său pentru tranzacțiile ACID în lacurile de date și caracteristici precum evoluția schemei și a partițiilor, călătoria în timp și rollback.
Integrarea Apache Iceberg este susținută de serviciile de analiză AWS, inclusiv Amazon EMR, Amazon Atena, și AWS Adeziv. Amazon EMR poate furniza clustere cu Spark, Hive, Trino și Flink care pot rula Iceberg. Începând cu Amazon EMR versiunea 6.5.0, puteți utilizați Iceberg cu clusterul dvs. EMR fără a necesita o acțiune de bootstrap. La începutul lui 2022, AWS a anunțat disponibilitatea generală a tranzacțiilor Athena ACID, susținute de Apache Iceberg. Cel recent lansat Motorul de interogări Athena versiunea 3 oferă o mai bună integrare cu formatul tabelului Iceberg. AWS Glue 3.0 și versiuni ulterioare acceptă cadrul Apache Iceberg pentru lacuri de date.
În această postare, discutăm ce doresc clienții în lacurile de date moderne și cum Apache Iceberg ajută la satisfacerea nevoilor clienților. Apoi parcurgem o soluție pentru a construi un lac de date Iceberg de înaltă performanță și în evoluție Serviciul Amazon de stocare simplă (Amazon S3) și procesați date incrementale rulând instrucțiuni de inserare, actualizare și ștergere SQL. În cele din urmă, vă arătăm cum să reglați performanța procesului pentru a îmbunătăți performanța de citire și scriere.
Cum Apache Iceberg abordează ceea ce doresc clienții în lacurile de date moderne
Din ce în ce mai mulți clienți construiesc lacuri de date, cu date structurate și nestructurate, pentru a sprijini mulți utilizatori, aplicații și instrumente de analiză. Există o nevoie din ce în ce mai mare de lacurile de date pentru a sprijini bazele de date, cum ar fi tranzacțiile ACID, actualizări și ștergeri la nivel de înregistrare, călătorii în timp și rollback. Apache Iceberg este proiectat să accepte aceste funcții pe lacurile de date rentabile la scară petabyte de pe Amazon S3.
Apache Iceberg se adresează nevoilor clienților prin captarea informațiilor bogate despre metadate despre setul de date în momentul în care fișierele de date individuale sunt create. Există trei straturi în arhitectura unui tabel Iceberg: catalogul Iceberg, stratul de metadate și stratul de date, așa cum este prezentat în figura următoare (sursă).

Catalogul Iceberg stochează indicatorul de metadate către fișierul de metadate curent al tabelului. Când o interogare selectată citește un tabel Iceberg, motorul de interogare merge mai întâi la catalogul Iceberg, apoi preia locația fișierului de metadate curent. Ori de câte ori există o actualizare a tabelului Iceberg, este creat un nou instantaneu al tabelului, iar indicatorul de metadate indică fișierul de metadate curent al tabelului.
Următorul este un exemplu de catalog Iceberg cu implementarea AWS Glue. Puteți vedea numele bazei de date, locația (calea S3) a tabelului Iceberg și locația metadatelor.

Stratul de metadate are trei tipuri de fișiere: fișierul de metadate, lista de manifeste și fișierul de manifest într-o ierarhie. În partea de sus a ierarhiei se află fișierul de metadate, care stochează informații despre schema tabelului, informații despre partiții și instantanee. Instantaneul indică lista de manifeste. Lista de manifeste conține informații despre fiecare fișier manifest care alcătuiește instantaneul, cum ar fi locația fișierului manifest, partițiile cărora îi aparține și limitele inferioare și superioare pentru coloanele de partiții pentru fișierele de date pe care le urmărește. Fișierul manifest urmărește fișierele de date, precum și detalii suplimentare despre fiecare fișier, cum ar fi formatul fișierului. Toate cele trei fișiere funcționează într-o ierarhie pentru a urmări instantaneele, schema, partiționarea, proprietățile și fișierele de date dintr-un tabel Iceberg.
Stratul de date are fișierele de date individuale ale tabelului Iceberg. Iceberg acceptă o gamă largă de formate de fișiere, inclusiv Parquet, ORC și Avro. Deoarece tabelul Iceberg urmărește fișierele de date individuale în loc să indice doar locația partiției cu fișiere de date, izolează operațiunile de scriere de operațiunile de citire. Puteți scrie fișierele de date în orice moment, dar doar comiteți modificarea în mod explicit, ceea ce creează o nouă versiune a fișierelor instantanee și metadate.
Prezentare generală a soluțiilor
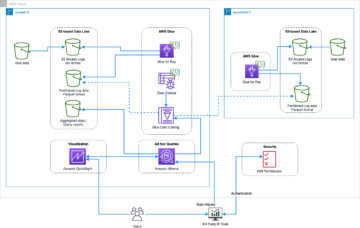
În această postare, vă prezentăm o soluție pentru a construi un lac de date Apache Iceberg de înaltă performanță pe Amazon S3; procesează date incrementale cu instrucțiuni SQL de inserare, actualizare și ștergere; și reglați tabelul Iceberg pentru a îmbunătăți performanța de citire și scriere. Următoarea diagramă ilustrează arhitectura soluției.

Pentru a demonstra această soluție, folosim Recenzii pentru clienți Amazon set de date într-o găleată S3 (s3://amazon-reviews-pds/parquet/). În cazul real de utilizare, ar fi date brute stocate în compartimentul S3. Putem verifica dimensiunea datelor cu următorul cod în fișierul Interfața liniei de comandă AWS (AWS CLI):
Numărul total de obiecte este de 430, iar dimensiunea totală este de 47.4 GiB.
Pentru a configura și testa această soluție, parcurgem următorii pași de nivel înalt:
- Configurați o găleată S3 în zona curată pentru a stoca datele convertite în format tabel Iceberg.
- Lansați un cluster EMR cu configurații adecvate pentru Apache Iceberg.
- Creați un blocnotes în EMR Studio.
- Configurați sesiunea Spark pentru Apache Iceberg.
- Convertiți datele în formatul tabelului Iceberg și mutați datele în zona curată.
- Rulați interogări de inserare, actualizare și ștergere în Athena pentru a procesa date incrementale.
- Efectuați reglarea performanței.
Cerințe preliminare
Pentru a urma acest tutorial, trebuie să aveți un Cont AWS cu o Gestionarea identității și accesului AWS (IAM) rol care are acces suficient pentru a furniza resursele necesare.
Configurați găleata S3 pentru datele Iceberg în zona curată din lacul dvs. de date
Alegeți regiunea în care doriți să creați compartimentul S3 și furnizați un nume unic:
Lansați un cluster EMR pentru a rula joburi Iceberg folosind Spark
Puteți crea un cluster EMR din Consola de administrare AWS, Amazon EMR CLI sau Kit AWS Cloud Development (AWS CDK). Pentru această postare, vă prezentăm cum să creați un cluster EMR din consolă.
- Pe consola Amazon EMR, alegeți Creați cluster.
- Alege Opţiuni avansate.
- Pentru Configurarea software-ului, alege cea mai recentă versiune Amazon EMR. Din ianuarie 2023, cea mai recentă versiune este 6.9.0. Iceberg necesită versiunea 6.5.0 și o versiune ulterioară.
- Selectați JupyterEnterpriseGateway și Scânteie ca software de instalat.
- Pentru Editați setările software-ului, Selectați Introduceți configurația și intră
[{"classification":"iceberg-defaults","properties":{"iceberg.enabled":true}}]. - Lăsați celelalte setări la valorile implicite și alegeți Pagina Următoare →.

- Pentru Piese metalice, utilizați setarea implicită.
- Alege Pagina Următoare →.
- Pentru Numele clusterului, introduceți un nume. Folosim
iceberg-blog-cluster. - Lăsați setările rămase neschimbate și alegeți Pagina Următoare →.
- Alege Creați cluster.
Creați un blocnotes în EMR Studio
Vă prezentăm acum cum să creați un blocnotes în EMR Studio din consolă.
- Pe consola IAM, creați un rol de serviciu EMR Studio.
- Pe consola Amazon EMR, alegeți EMR Studio.
- Alege Incepe.
Incepe pagina apare într-o filă nouă.
- Alege Creați Studio în noua filă.
- Introduceți un nume. Folosim iceberg-studio.
- Alegeți același VPC și subrețea ca cele pentru clusterul EMR și grupul de securitate implicit.
- Alege AWS Identity and Access Management (IAM) pentru autentificare și alegeți rolul de serviciu EMR Studio pe care tocmai l-ați creat.
- Alegeți o cale S3 pentru Backup pentru spații de lucru.
- Alege Creați Studio.
- După crearea Studioului, alegeți adresa URL de acces la Studio.
- Pe tabloul de bord EMR Studio, alegeți Creați spațiu de lucru.
- Introduceți un nume pentru spațiul dvs. de lucru. Folosim
iceberg-workspace. - Extinde Configurare avansată Și alegeți Atașați spațiul de lucru la un cluster EMR.
- Alegeți clusterul EMR pe care l-ați creat mai devreme.
- Alege Creați spațiu de lucru.
- Alegeți numele spațiului de lucru pentru a deschide o filă nouă.
În panoul de navigare, există un blocnotes care are același nume ca și spațiul de lucru. În cazul nostru, este un iceberg-spațiu de lucru.
- Deschide caietul.
- Când vi se solicită să alegeți un nucleu, alegeți Scânteie.
Configurați o sesiune Spark pentru Apache Iceberg
Utilizați următorul cod, furnizând propriul nume de compartiment S3:
Aceasta setează următoarele configurații de sesiune Spark:
- spark.sql.catalog.demo – Înregistrează un catalog Spark denumit demo, care utilizează pluginul de catalog Iceberg Spark.
- spark.sql.catalog.demo.catalog-impl – Catalogul demonstrativ Spark folosește AWS Glue ca catalog fizic pentru a stoca baza de date Iceberg și informațiile din tabel.
- spark.sql.catalog.demo.warehouse – Catalogul demonstrativ Spark stochează toate metadatele și fișierele de date Iceberg sub calea rădăcină definită de această proprietate:
s3://iceberg-curated-blog-data. - spark.sql.extensions – Adaugă suport pentru extensiile SQL Iceberg Spark, care vă permite să rulați procedurile Iceberg Spark și unele comenzi SQL numai pentru Iceberg (veți folosi acest lucru într-un pas ulterior).
- spark.sql.catalog.demo.io-impl – Iceberg permite utilizatorilor să scrie date pe Amazon S3 prin S3FileIO. Catalogul de date AWS Glue utilizează în mod implicit acest FileIO, iar alte cataloage pot încărca acest FileIO folosind proprietatea de catalog io-impl.
Convertiți datele în format de tabel Iceberg
Puteți folosi fie Spark pe Amazon EMR, fie Athena pentru a încărca tabelul Iceberg. În sesiunea Spark de blocnotes EMR Studio Workspace, rulați următoarele comenzi pentru a încărca datele:
După ce rulați codul, ar trebui să găsiți două prefixe create în calea S3 a depozitului de date (s3://iceberg-curated-blog-data/reviews.db/all_reviews): date și metadate.
Procesați date incrementale utilizând instrucțiuni SQL de inserare, actualizare și ștergere în Athena
Athena este un motor de interogare fără server pe care îl puteți folosi pentru a efectua sarcini de citire, scriere, actualizare și optimizare împotriva tabelelor Iceberg. Pentru a demonstra modul în care formatul lacului de date Apache Iceberg acceptă asimilarea incrementală a datelor, rulăm instrucțiuni de inserare, actualizare și ștergere SQL pe lacul de date.
Navigați la consola Athena și alegeți Editor de interogări. Dacă este prima dată când utilizați editorul de interogări Athena, trebuie configurați locația rezultatului interogării să fie găleata S3 pe care ați creat-o mai devreme. Ar trebui să puteți vedea că tabelul reviews.all_reviews este disponibil pentru interogare. Rulați următoarea interogare pentru a verifica dacă ați încărcat cu succes tabelul Iceberg:
Procesați datele incrementale rulând instrucțiuni SQL de inserare, actualizare și ștergere:
Reglarea performanței
În această secțiune, parcurgem diferite moduri de a îmbunătăți performanța de citire și scriere a Apache Iceberg.
Configurați proprietățile tabelului Apache Iceberg
Apache Iceberg este un format de tabel și acceptă proprietățile tabelului pentru a configura comportamentul tabelului, cum ar fi citirea, scrierea și catalogul. Puteți îmbunătăți performanța de citire și scriere pe tabelele Iceberg ajustând proprietățile tabelului.
De exemplu, dacă observați că scrieți prea multe fișiere mici pentru un tabel Iceberg, puteți configura dimensiunea fișierului de scriere pentru a scrie mai puține fișiere, dar mai mari, pentru a ajuta la îmbunătățirea performanței interogărilor.
| Proprietate | Mod implicit | Descriere |
| write.target-file-size-bytes | 536870912 (512 MB) | Controlează dimensiunea fișierelor generate pentru a viza aproximativ acești mulți octeți |
Utilizați următorul cod pentru a modifica formatul tabelului:
Partiționare și sortare
Pentru ca o interogare să ruleze rapid, cu cât sunt citite mai puține date, cu atât mai bine. Iceberg profită de metadatele bogate pe care le captează în timpul scrierii și facilitează tehnici precum planificarea scanării, partiționarea, tăierea și statisticile la nivel de coloană, cum ar fi valorile min/max, pentru a ignora fișierele de date care nu au înregistrări de potrivire. Vă prezentăm cum funcționează planificarea și partiționarea interogărilor în Iceberg și cum le folosim pentru a îmbunătăți performanța interogărilor.
Planificarea scanării interogărilor
Pentru o anumită interogare, primul pas într-un motor de interogare este planificarea scanării, care este procesul de găsire a fișierelor într-un tabel necesar pentru o interogare. Planificarea într-un tabel Iceberg este foarte eficientă, deoarece metadatele bogate ale Iceberg pot fi utilizate pentru a tăia fișierele de metadate care nu sunt necesare, pe lângă filtrarea fișierelor de date care nu conțin date care se potrivesc. În testele noastre, am observat că Athena a scanat 50% sau mai puține date pentru o anumită interogare pe un tabel Iceberg în comparație cu datele originale înainte de conversia în format Iceberg.
Există două tipuri de filtrare:
- Filtrarea metadatelor – Iceberg folosește două niveluri de metadate pentru a urmări fișierele într-un instantaneu: lista de manifeste și fișierele manifest. Mai întâi folosește lista de manifeste, care acționează ca un index al fișierelor manifest. În timpul planificării, Iceberg filtrează manifestele folosind intervalul de valori ale partiției din lista de manifeste fără a citi toate fișierele manifest. Apoi folosește fișierele manifest selectate pentru a obține fișiere de date.
- Filtrarea datelor – După selectarea listei de fișiere manifest, Iceberg utilizează datele partiției și statisticile la nivel de coloană pentru fiecare fișier de date stocat în fișierele manifest pentru a filtra fișierele de date. În timpul planificării, predicatele de interogare sunt convertite în predicate pe datele partiției și aplicate mai întâi pentru a filtra fișierele de date. Apoi, statisticile coloanei, cum ar fi valorile la nivel de coloană, nulele, limitele inferioare și limitele superioare sunt folosite pentru a filtra fișierele de date care nu se potrivesc cu predicatul de interogare. Prin utilizarea limitelor superioare și inferioare pentru a filtra fișierele de date în momentul planificării, Iceberg îmbunătățește considerabil performanța interogărilor.
Partiționare și sortare
Partiționarea este o modalitate de a grupa în scris înregistrările cu aceleași valori ale coloanei cheie. Avantajul partiționării este interogările mai rapide care accesează doar o parte din date, așa cum sa explicat mai devreme în planificarea scanării interogărilor: filtrarea datelor. Iceberg face partiționarea simplă prin suportarea partiționării ascunse, în felul în care Iceberg produce valori de partiție prin luarea unei valori de coloană și, opțional, transformând-o.
În cazul nostru de utilizare, mai întâi rulăm următoarea interogare pe tabelul Iceberg nepartiționat. Apoi împărțim tabelul Iceberg în funcție de categoria recenziilor, care va fi folosită în condiția de interogare WHERE pentru a filtra înregistrările. Cu partiționare, interogarea ar putea scana mult mai puține date. Vezi următorul cod:
Rulați următoarea instrucțiune select pe tabelul all_reviews nepartiționat față de tabelul partiționat pentru a vedea diferența de performanță:
Următorul tabel arată îmbunătățirea performanței partiționării datelor, cu aproximativ 50% îmbunătățire a performanței și cu 70% mai puține date scanate.
| Numele setului de date | Set de date nepartiționat | Set de date partiționat |
| Timp de rulare (secunde) | 8.20 | 4.25 |
| Date scanate (MB) | 131.55 | 33.79 |
Rețineți că durata de rulare este durata medie de rulare cu mai multe rulări în testul nostru.
Am observat o îmbunătățire bună a performanței după partiționare. Cu toate acestea, acest lucru poate fi îmbunătățit și mai mult prin utilizarea statisticilor la nivel de coloană din fișierele manifest Iceberg. Pentru a utiliza eficient statisticile la nivel de coloană, doriți să sortați în continuare înregistrările pe baza modelelor de interogare. Sortarea întregului set de date folosind coloanele care sunt adesea folosite în interogări va reordona datele în așa fel încât fiecare fișier de date să ajungă cu un interval unic de valori pentru coloanele specifice. Dacă aceste coloane sunt utilizate în condiția de interogare, aceasta permite motoarelor de interogare să ignore în continuare fișierele de date, permițând astfel interogări și mai rapide.
Copiere la scriere vs. citire la îmbinare
Când implementați actualizarea și ștergerea tabelelor Iceberg din lacul de date, există două abordări definite de proprietățile tabelului Iceberg:
- Copie pe scriere – Cu această abordare, atunci când există modificări ale tabelului Iceberg, fie actualizări, fie ștergeri, fișierele de date asociate înregistrărilor afectate vor fi duplicate și actualizate. Înregistrările vor fi fie actualizate, fie șterse din fișierele de date duplicate. Va fi creat un nou instantaneu al tabelului Iceberg și va indica versiunea mai nouă a fișierelor de date. Acest lucru face ca scrierile generale să fie mai lente. Pot exista situații în care sunt necesare scrieri concomitente cu conflicte, așa că trebuie să se întâmple reîncercarea, ceea ce crește și mai mult timpul de scriere. Pe de altă parte, atunci când citiți datele, nu este nevoie de un proces suplimentar. Interogarea va prelua date din cea mai recentă versiune a fișierelor de date.
- Îmbinare la citire – Cu această abordare, atunci când există actualizări sau ștergeri pe tabelul Iceberg, fișierele de date existente nu vor fi rescrise; în schimb, vor fi create noi fișiere de ștergere pentru a urmări modificările. Pentru ștergeri, va fi creat un nou fișier de ștergere cu înregistrările șterse. Când citiți tabelul Iceberg, fișierul de ștergere va fi aplicat datelor preluate pentru a filtra înregistrările șterse. Pentru actualizări, va fi creat un nou fișier de ștergere pentru a marca înregistrările actualizate ca șterse. Apoi va fi creat un nou fișier pentru acele înregistrări, dar cu valori actualizate. Când citiți tabelul Iceberg, atât fișierele șterse, cât și cele noi vor fi aplicate datelor preluate pentru a reflecta cele mai recente modificări și pentru a produce rezultatele corecte. Deci, pentru orice interogări ulterioare, va avea loc un pas suplimentar pentru a îmbina fișierele de date cu fișierele de ștergere și noi, ceea ce va crește de obicei timpul de interogare. Pe de altă parte, scrierile ar putea fi mai rapide, deoarece nu este nevoie să rescrieți fișierele de date existente.
Pentru a testa impactul celor două abordări, puteți rula următorul cod pentru a seta proprietățile tabelului Iceberg:
Rulați actualizarea, ștergeți și selectați instrucțiunile SQL în Athena pentru a arăta diferența de rulare pentru copiere la scriere față de îmbinare la citire:
Următorul tabel rezumă timpii de execuție a interogărilor.
| Întrebare | Copie pe scriere | Merge-on-Read | ||||
| UPDATE | DELETE | SELECT | UPDATE | DELETE | SELECT | |
| Timp de rulare (secunde) | 66.251 | 116.174 | 97.75 | 10.788 | 54.941 | 113.44 |
| Date scanate (MB) | 494.06 | 3.07 | 137.16 | 494.06 | 3.07 | 137.16 |
Rețineți că durata de rulare este durata medie de rulare cu mai multe rulări în testul nostru.
După cum arată rezultatele testelor noastre, există întotdeauna compromisuri în cele două abordări. Ce abordare de utilizat depinde de cazurile dvs. de utilizare. În rezumat, considerentele se reduc la latența citirii vs scrierii. Puteți consulta următorul tabel și puteți face alegerea corectă.
| . | Copie pe scriere | Merge-on-Read |
| Pro-uri | Citiri mai rapide | Scrie mai repede |
| Contra | Scrieri scumpe | Latență mai mare la citiri |
| Când să folosiți | Bun pentru citiri frecvente, actualizări și ștergeri rare sau actualizări în loturi mari | Bun pentru tabelele cu actualizări și ștergeri frecvente |
Compactarea datelor
Dacă dimensiunea fișierului dvs. de date este mică, puteți ajunge cu mii sau milioane de fișiere într-un tabel Iceberg. Acest lucru crește dramatic operațiunea I/O și încetinește interogările. În plus, Iceberg urmărește fiecare fișier de date dintr-un set de date. Mai multe fișiere de date duc la mai multe metadate. Acest lucru, la rândul său, crește supraîncărcarea și operațiunea I/O la citirea fișierelor de metadate. Pentru a îmbunătăți performanța interogărilor, se recomandă compactarea fișierelor de date mici în fișiere de date mai mari.
Când actualizați și ștergeți înregistrările din tabelul Iceberg, dacă se folosește abordarea citire la îmbinare, s-ar putea ajunge la multe ștergeri mici sau fișiere de date noi. Rularea compactării va combina toate aceste fișiere și va crea o versiune mai nouă a fișierului de date. Acest lucru elimină necesitatea reconcilierii lor în timpul citirilor. Este recomandat să aveți lucrări regulate de compactare pentru a afecta citirile cât mai puțin posibil, menținând în același timp o viteză de scriere mai mare.
Rulați următoarea comandă de compactare a datelor, apoi executați interogarea de selectare din Athena:
Următorul tabel compară timpul de rulare înainte și după compactarea datelor. Puteți vedea o îmbunătățire a performanței cu aproximativ 40%.
| Întrebare | Înainte de compactarea datelor | După compactarea datelor |
| Timp de rulare (secunde) | 97.75 | 32.676 secunde |
| Date scanate (MB) | 137.16 M | 189.19 M |
Rețineți că interogările selectate au rulat pe all_reviews tabel după operațiunile de actualizare și ștergere, înainte și după compactarea datelor. Durata de rulare este durata medie de rulare cu mai multe rulări în testul nostru.
A curăța
După ce urmați explicația soluției pentru a efectua cazurile de utilizare, parcurgeți următorii pași pentru a vă curăța resursele și a evita costurile suplimentare:
- Aruncați tabelele și baza de date AWS Glue din Athena sau rulați următorul cod în blocnotes:
- Pe consola EMR Studio, alegeți Spațiile de lucru în panoul de navigare.
- Selectați spațiul de lucru pe care l-ați creat și alegeți Șterge.
- Pe consola EMR, navigați la Studios .
- Selectați Studioul pe care l-ați creat și alegeți Șterge.
- Pe consola EMR, alegeți clusterele în panoul de navigare.
- Selectați clusterul și alegeți termina.
- Ștergeți compartimentul S3 și orice alte resurse pe care le-ați creat ca parte a cerințelor preliminare pentru această postare.
Concluzie
În această postare, am prezentat cadrul Apache Iceberg și modul în care acesta ajută la rezolvarea unora dintre provocările pe care le avem într-un lac de date modern. Apoi v-am prezentat o soluție de procesare a datelor incrementale într-un lac de date folosind Apache Iceberg. În cele din urmă, am făcut o scufundare profundă în reglarea performanței pentru a îmbunătăți performanța de citire și scriere pentru cazurile noastre de utilizare.
Sperăm că această postare vă oferă câteva informații utile pentru a vă decide dacă doriți să adoptați Apache Iceberg în soluția dvs. de lac de date.
Despre Autori
 Flora Wu este arhitect rezident senior la AWS Data Lab. Ea îi ajută pe clienții întreprinderilor să creeze strategii de analiză a datelor și să construiască soluții pentru a-și accelera rezultatele afacerii. În timpul liber, îi place să joace tenis, să danseze salsa și să călătorească.
Flora Wu este arhitect rezident senior la AWS Data Lab. Ea îi ajută pe clienții întreprinderilor să creeze strategii de analiză a datelor și să construiască soluții pentru a-și accelera rezultatele afacerii. În timpul liber, îi place să joace tenis, să danseze salsa și să călătorească.
 Daniel Li este arhitect senior de soluții la Amazon Web Services. El se concentrează pe a ajuta clienții să dezvolte, să adopte și să implementeze serviciile și strategia cloud. Când nu lucrează, îi place să petreacă timpul în aer liber cu familia.
Daniel Li este arhitect senior de soluții la Amazon Web Services. El se concentrează pe a ajuta clienții să dezvolte, să adopte și să implementeze serviciile și strategia cloud. Când nu lucrează, îi place să petreacă timpul în aer liber cu familia.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- Platoblockchain. Web3 Metaverse Intelligence. Cunoștințe amplificate. Accesați Aici.
- Sursa: https://aws.amazon.com/blogs/big-data/use-apache-iceberg-in-a-data-lake-to-support-incremental-data-processing/
- 10
- 100
- 11
- 2022
- 2023
- 7
- 9
- a
- Capabil
- Despre Noi
- mai sus
- accelera
- acces
- managementul accesului
- Acțiune
- Acte
- plus
- Suplimentar
- adresa
- adrese
- Adaugă
- adopta
- Avantaj
- După
- împotriva
- TOATE
- permite
- mereu
- Amazon
- Amazon EMR
- Amazon Web Services
- analitic
- Google Analytics
- și
- a anunțat
- Apache
- aplicatii
- aplicat
- abordare
- abordari
- adecvat
- arhitectură
- asociate
- Autentificare
- disponibilitate
- disponibil
- in medie
- evita
- AWS
- AWS Adeziv
- bazat
- deoarece
- deveni
- înainte
- beneficia
- Mai bine
- între
- mai mare
- Bootstrap
- construi
- Clădire
- întreprinderi
- capturi
- capturarea
- caz
- cazuri
- catalog
- cataloage
- Categorii
- provocări
- Schimbare
- Modificări
- verifica
- alegere
- Alege
- clasificare
- Cloud
- servicii de tip cloud
- Grup
- cod
- Coloană
- Coloane
- combina
- cum
- comite
- comparație
- Completă
- Calcula
- concurent
- condiție
- configuraţiile
- Considerații
- Consoleze
- Convertire
- convertit
- cost-eficiente
- Cheltuieli
- ar putea
- crea
- a creat
- creează
- curator
- Curent
- client
- clienţii care
- Dans
- tablou de bord
- de date
- Analiza datelor
- Lacul de date
- de prelucrare a datelor
- depozit de date
- Baza de date
- seturi de date
- adânc
- scufundare adâncă
- Mod implicit
- definit
- Demo
- demonstra
- depinde de
- proiectat
- detalii
- dezvolta
- Dezvoltare
- diferenţă
- diferit
- discuta
- Dont
- jos
- dramatic
- Picătură
- în timpul
- fiecare
- Mai devreme
- Devreme
- editor
- în mod eficient
- eficient
- oricare
- elimină
- activat
- permițând
- se încheie
- Motor
- Motoare
- Intrați
- Afacere
- clienții întreprinderii
- Eter (ETH)
- Chiar
- evoluţie
- evolua
- evoluție
- exemplu
- existent
- există
- a explicat
- extensii
- suplimentar
- facilitează
- familie
- FAST
- mai repede
- DESCRIERE
- Figura
- Fișier
- Fişiere
- filtru
- filtrare
- Filtre
- În cele din urmă
- Găsi
- First
- prima dată
- se concentrează
- urma
- următor
- format
- Cadru
- frecvent
- din
- mai mult
- În plus
- General
- generată
- obține
- dat
- Merge
- bine
- foarte mult
- grup
- mână
- întâmpla
- ajutor
- ajutor
- ajută
- Ascuns
- ierarhie
- la nivel înalt
- performanta ridicata
- performanta inalta
- Stup
- speranţă
- Cum
- Cum Pentru a
- Totuși
- HTML
- HTTPS
- IAM
- Identitate
- gestionarea identității și accesului
- Impactul
- afectate
- punerea în aplicare a
- implementarea
- Punere în aplicare a
- îmbunătăţi
- îmbunătățit
- îmbunătățire
- îmbunătăţeşte
- in
- Inclusiv
- Crește
- a crescut
- Creșteri
- index
- individ
- informații
- instala
- in schimb
- integrare
- introdus
- izolatele
- IT
- ianuarie
- Locuri de munca
- Cheie
- de laborator
- lac
- mare
- mai mare
- Latență
- Ultimele
- ultima lansare
- strat
- straturi
- conduce
- nivelurile de
- LIMITĂ
- Linie
- Listă
- mic
- încărca
- locaţie
- face
- FACE
- administrare
- multe
- marca
- piaţă
- Meci
- potrivire
- Îmbina
- Metadata
- ar putea
- milioane
- Modern
- mai mult
- muta
- multiplu
- nume
- Numit
- Navigaţi
- Navigare
- Nevoie
- necesar
- nevoilor
- Nou
- caiet
- obiect
- deschide
- operaţie
- Operațiuni
- optimizare
- Optimizați
- comandă
- original
- Altele
- în aer liber
- global
- propriu
- pâine
- parte
- cale
- modele
- efectua
- performanță
- fizic
- planificare
- Plato
- Informații despre date Platon
- PlatoData
- joc
- conecteaza
- puncte
- Popular
- posibil
- Post
- alimentat
- premise
- Proceduri
- proces
- prelucrare
- produce
- proprietăţi
- proprietate
- furniza
- furnizează
- furnizarea
- dispoziţie
- gamă
- Crud
- date neprelucrate
- Citeste
- Citind
- real
- recent
- recomandat
- înregistrări
- reflecta
- regiune
- registre
- regulat
- eliberaţi
- eliberat
- rămas
- necesar
- Necesită
- Resurse
- rezultat
- REZULTATE
- Recenzii
- Bogat
- Rol
- rădăcină
- Alerga
- funcţionare
- acelaşi
- scanare
- secunde
- Secțiune
- securitate
- selectate
- selectarea
- serverless
- serviciu
- Servicii
- sesiune
- set
- Seturi
- instalare
- setări
- să
- Arăta
- Emisiuni
- simplu
- situații
- Mărimea
- încetineşte
- mic
- Instantaneu
- So
- Software
- soluţie
- soluţii
- unele
- Scânteie
- specific
- viteză
- Cheltuire
- SQL
- Pornire
- Stat
- Declarație
- Declarații
- Statistici
- Pas
- paşi
- Încă
- depozitare
- stoca
- stocate
- magazine
- strategii
- Strategie
- structurat
- date structurate și nestructurate
- studio
- subrețea
- ulterior
- Reușit
- astfel de
- suficient
- REZUMAT
- a sustine
- Suportat
- De sprijin
- Sprijină
- tabel
- ia
- luare
- Ţintă
- sarcini
- tehnici de
- tenis
- test
- Testarea
- teste
- informațiile
- Statul
- lor
- astfel
- mii
- trei
- Prin
- timp
- timp de călătorie
- la
- împreună
- de asemenea
- Unelte
- top
- Total
- urmări
- Tranzacții
- transformare
- călătorie
- Traveling
- ÎNTORCĂ
- Tipuri
- în
- unic
- Actualizează
- actualizat
- actualizări
- actualizarea
- URL-ul
- utilizare
- carcasa de utilizare
- utilizatorii
- obișnuit
- VAL
- valoare
- Valori
- verifica
- versiune
- umblat
- walkthrough
- Depozit
- Ceasuri
- modalități de
- web
- servicii web
- Ce
- dacă
- care
- în timp ce
- larg
- Gamă largă
- voi
- fără
- Apartamente
- de lucru
- fabrică
- ar
- scrie
- scris
- Ta
- zephyrnet