Bruce Warrington prin Unsplash
Motivul pentru care modelele de învățare automată în general devin mai inteligente se datorează dependenței lor de utilizarea datelor etichetate pentru a le ajuta să discearnă între două obiecte similare.
Cu toate acestea, fără aceste seturi de date etichetate, veți întâmpina obstacole majore atunci când creați cel mai eficient și de încredere model de învățare automată. Seturile de date etichetate în timpul fazei de instruire a unui model sunt importante.
Învățarea profundă a fost utilizată pe scară largă pentru a rezolva sarcini precum viziunea computerizată folosind învățarea supravegheată. Cu toate acestea, ca și în multe lucruri în viață, vine cu restricții. Clasificarea supravegheată necesită o cantitate și o calitate ridicată a datelor de formare etichetate pentru a produce un model robust. Aceasta înseamnă că modelul de clasificare nu poate gestiona clase nevăzute.
Și știm cu toții câtă putere de calcul, reinstruire, timp și bani este nevoie pentru a antrena un model de învățare profundă.
Dar poate un model să poată discerne între două obiecte fără a fi folosit date de antrenament? Da, se numește învățare zero-shot. Învățarea zero-shot este capacitatea unui model de a fi capabil să finalizeze o sarcină fără a fi primit sau folosit exemple de antrenament.
Oamenii sunt în mod natural capabili să învețe zero-shot fără a fi nevoie să depună mult efort. Creierul nostru stochează deja dicționare și ne permite să diferențiem obiectele uitându-ne la proprietățile lor fizice datorită bazei noastre actuale de cunoștințe. Putem folosi această bază de cunoștințe pentru a vedea asemănările și diferențele dintre obiecte și pentru a găsi legătura dintre ele.
De exemplu, să presupunem că încercăm să construim un model de clasificare pe speciile de animale. Conform Our WorldInData, au fost 2.13 milioane de specii calculate în 2021. Prin urmare, dacă dorim să creăm cel mai eficient model de clasificare pentru speciile de animale, am avea nevoie de 2.13 milioane de clase diferite. De asemenea, vor fi necesare o mulțime de date. Cantitatea mare și datele de calitate sunt greu de găsit.
Deci, cum rezolvă învățarea zero această problemă?
Deoarece învățarea zero-shot nu necesită ca modelul să fi învățat datele de antrenament și cum să clasificăm clasele, ne permite să ne bazăm mai puțin pe nevoia modelului de date etichetate.
Următoarele sunt în ce vor trebui să conțină datele dumneavoastră pentru a continua cu învățarea zero-shot.
Clasele văzute
Acesta constă din clasele de date care au fost utilizate anterior pentru a antrena un model.
Clasele nevăzute
Acesta constă din clasele de date care NU au fost folosite pentru a antrena un model, iar noul model de învățare zero-shot se va generaliza.
Informații auxiliare
Deoarece datele din clasele nevăzute nu sunt etichetate, învățarea zero-shot va necesita informații auxiliare pentru a învăța și pentru a găsi corelații, legături și proprietăți. Aceasta poate fi sub formă de înglobare de cuvinte, descrieri și informații semantice.
Metode de învățare zero-shot
Învățarea zero-shot este de obicei utilizată în:
- Metode bazate pe clasificatori
- Metode bazate pe instanțe
stagii
Învățarea zero-shot este utilizată pentru a construi modele pentru clasele care nu se antrenează folosind date etichetate, prin urmare necesită aceste două etape:
1. Instruire
Etapa de instruire este procesul metodei de învățare care încearcă să capteze cât mai multe cunoștințe despre calitățile datelor. Putem vedea aceasta ca fiind faza de învățare.
2. Inferență
În timpul etapei de inferență, toate cunoștințele învățate din etapa de instruire sunt aplicate și utilizate pentru a clasifica exemplele într-un nou set de clase. Putem vedea aceasta ca fiind faza de a face predicții.
Cum functioneaza?
Cunoștințele din clasele văzute vor fi transferate către clasele nevăzute într-un spațiu vectorial cu dimensiuni înalte; acesta se numește spațiu semantic. De exemplu, în clasificarea imaginii, spațiul semantic împreună cu imaginea vor parcurge doi pași:
1. Spațiu de încorporare comun
Aici sunt proiectați vectorii semantici și vectorii caracteristicii vizuale.
2. Cea mai mare asemănare
Aici funcțiile sunt comparate cu cele ale unei clase nevăzute.
Pentru a ajuta la înțelegerea procesului cu cele două etape (antrenament și inferență), să le aplicăm în utilizarea clasificării imaginilor.
Pregătire

Jari Hytönen prin Unsplash
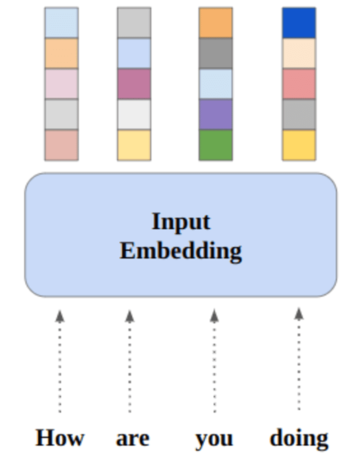
Ca om, dacă ar fi să citești textul din dreapta din imaginea de mai sus, ai presupune instantaneu că sunt 4 pisoi într-un coș maro. Dar să presupunem că nu ai idee ce este un „pisoi”. Veți presupune că există un coș maro cu 4 lucruri înăuntru, care se numesc „pisici”. Odată ce dai peste mai multe imagini care conțin ceva care arată ca un „pisoi”, vei putea diferenția un „pisoi” de alte animale.
Acesta este ceea ce se întâmplă atunci când utilizați Preantrenamentul contrastant limbaj-imagine (CLIP) de OpenAI pentru învățarea zero-shot în clasificarea imaginilor. Este cunoscută ca informații auxiliare.
S-ar putea să vă gândiți, „ei bine, acestea sunt doar date etichetate”. Înțeleg de ce ai crede asta, dar nu sunt. Informațiile auxiliare nu sunt etichete ale datelor, ele sunt o formă de supraveghere pentru a ajuta modelul să învețe în timpul etapei de formare.
Când un model de învățare zero-shot vede o cantitate suficientă de perechi imagine-text, va fi capabil să diferențieze și să înțeleagă fraze și modul în care acestea se corelează cu anumite modele din imagini. Folosind tehnica CLIP „învățare contrastantă”, modelul de învățare zero-shot a reușit să acumuleze o bază de cunoștințe bună pentru a putea face predicții privind sarcinile de clasificare.
Acesta este un rezumat al abordării CLIP în care antrenează un codificator de imagine și un codificator de text împreună pentru a prezice perechile corecte ale unui lot de exemple de antrenament (imagine, text). Vă rugăm să vedeți imaginea de mai jos:

Învățarea modelelor vizuale transferabile din supravegherea limbajului natural
deducție
Odată ce modelul a trecut prin etapa de antrenament, are o bază bună de cunoștințe despre asocierea imagine-text și poate fi folosit acum pentru a face predicții. Dar înainte de a putea începe să facem predicții, trebuie să setăm sarcina de clasificare prin crearea unei liste cu toate etichetele posibile pe care modelul le-ar putea scoate.
De exemplu, rămânând cu sarcina de clasificare a imaginilor pe specii de animale, vom avea nevoie de o listă cu toate speciile de animale. Fiecare dintre aceste etichete va fi codificată, T? la T? folosind codificatorul de text preantrenat care a avut loc în etapa de antrenament.
Odată ce etichetele au fost codificate, putem introduce imagini prin codificatorul de imagini pre-antrenat. Vom folosi similaritatea cosinusului metric al distanței pentru a calcula asemănările dintre codificarea imaginii și codificarea fiecărei etichete de text.
Clasificarea imaginii se face pe baza etichetei cu cea mai mare asemanare cu imaginea. Și așa se realizează învățarea zero-shot, în special în clasificarea imaginilor.
Lipsa datelor
După cum s-a menționat anterior, datele cantități mari și de calitate sunt greu de pus mâna. Spre deosebire de oamenii care posedă deja capacitatea de învățare zero-shot, mașinile necesită date etichetate de intrare pentru a învăța și apoi să se poată adapta la variațiile care pot apărea în mod natural.
Dacă ne uităm la exemplul speciilor de animale, au fost atât de multe. Și pe măsură ce numărul de categorii continuă să crească în diferite domenii, va fi nevoie de multă muncă pentru a ține pasul cu colectarea datelor adnotate.
Datorită acestui fapt, învățarea zero-shot a devenit mai valoroasă pentru noi. Din ce în ce mai mulți cercetători sunt interesați de recunoașterea automată a atributelor pentru a compensa lipsa datelor disponibile.
Etichetarea datelor
Un alt beneficiu al învățării zero-shot este proprietățile sale de etichetare a datelor. Etichetarea datelor poate fi laborioasă și foarte obositoare și, din această cauză, poate duce la erori în timpul procesului. Etichetarea datelor necesită experți, cum ar fi profesioniștii medicali care lucrează la un set de date biomedicale, ceea ce este foarte costisitor și consuma mult timp.
Învățarea zero-shot devine din ce în ce mai populară din cauza limitărilor de mai sus ale datelor. Există câteva lucrări pe care ți-aș recomanda să le citești dacă ești interesat de abilitățile sale:
Nisha Arya este un Data Scientist și un scriitor tehnic independent. Ea este interesată în special să ofere sfaturi în carieră în domeniul științei datelor sau tutoriale și cunoștințe bazate pe teorie în jurul științei datelor. Ea dorește, de asemenea, să exploreze diferitele moduri în care Inteligența Artificială este/poate aduce beneficii longevității vieții umane. O învățătoare pasionată, care încearcă să-și extindă cunoștințele tehnice și abilitățile de scriere, în timp ce îi ajută să-i ghideze pe alții.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- Platoblockchain. Web3 Metaverse Intelligence. Cunoștințe amplificate. Accesați Aici.
- Sursa: https://www.kdnuggets.com/2022/12/zeroshot-learning-explained.html?utm_source=rss&utm_medium=rss&utm_campaign=zero-shot-learning-explained
- 2021
- a
- abilități
- capacitate
- Capabil
- Despre Noi
- mai sus
- Conform
- Acumula
- realizat
- peste
- adapta
- sfat
- împotriva
- TOATE
- permite
- deja
- sumă
- și
- animal
- animale
- aplicat
- Aplică
- abordare
- în jurul
- artificial
- inteligență artificială
- Automat
- disponibil
- de bază
- bazat
- coş
- deveni
- devenire
- înainte
- fiind
- de mai jos
- beneficia
- între
- biomedicale
- extinde
- construi
- calculată
- denumit
- Poate obține
- nu poti
- capabil
- captura
- Carieră
- categorii
- sigur
- clasă
- clase
- clasificare
- Clasifica
- Colectare
- cum
- Completă
- puterea de calcul
- Calcula
- calculator
- Computer Vision
- continuă
- ar putea
- crea
- Crearea
- Curent
- de date
- știința datelor
- om de știință de date
- seturi de date
- adânc
- învățare profundă
- Dependenţă
- diferenţele
- diferit
- distinge
- distanţă
- domenii
- în timpul
- fiecare
- Eficace
- efort
- Erori
- exemplu
- exemple
- scump
- experți
- a explicat
- explora
- Caracteristică
- DESCRIERE
- puțini
- Găsi
- următor
- formă
- independent
- din
- General
- obține
- bine
- cea mai mare
- Crește
- ghida
- manipula
- mâini
- se întâmplă
- Greu
- având în
- ajutor
- ajutor
- Înalt
- cea mai mare
- extrem de
- Cum
- Cum Pentru a
- Totuși
- HTTPS
- uman
- Oamenii
- idee
- imagine
- Clasificarea imaginilor
- imagini
- important
- in
- informații
- intrare
- Inteligență
- interesat
- IT
- pasionat
- A pastra
- Cunoaște
- cunoştinţe
- cunoscut
- Etichetă
- etichetarea
- etichete
- lipsă
- limbă
- conduce
- AFLAȚI
- învățat
- învăţare
- Viaţă
- limitări
- LINK
- Link-uri
- Listă
- longevitate
- Uite
- cautati
- Se pare
- Lot
- maşină
- masina de învățare
- Masini
- major
- face
- Efectuarea
- multe
- mijloace
- medical
- menționat
- metodă
- Metode
- metric
- ar putea
- milion
- model
- Modele
- bani
- mai mult
- cele mai multe
- Natural
- Nevoie
- Nou
- număr
- obiecte
- obstacole
- a avut loc
- ONE
- OpenAI
- comandă
- Altele
- Altele
- împerechere
- împerecherilor
- lucrări
- în special
- modele
- fază
- Expresii
- fizic
- Plato
- Informații despre date Platon
- PlatoData
- "vă rog"
- Popular
- posibil
- putere
- prezice
- Predictii
- în prealabil
- Problemă
- proces
- produce
- profesioniști
- proiectat
- proprietăţi
- furnizarea
- pune
- calităţi
- calitate
- cantitate
- Citeste
- motiv
- primit
- recunoaştere
- recomanda
- necesita
- Necesită
- cercetători
- restricții
- robust
- Ştiinţă
- Om de stiinta
- caută
- vede
- set
- asemănător
- asemănări
- aptitudini
- mai inteligent
- So
- REZOLVAREA
- ceva
- Spaţiu
- specific
- Etapă
- Stadiile
- paşi
- lipirea
- Încă
- stoca
- astfel de
- suficient
- REZUMAT
- supraveghere
- Lua
- ia
- Sarcină
- sarcini
- tech
- Tehnic
- lor
- prin urmare
- lucruri
- Gândire
- Prin
- timp
- consumă timp
- la
- împreună
- Tren
- Pregătire
- transferat
- demn de încredere
- tutoriale
- tipic
- înţelege
- us
- utilizare
- utilizate
- Valoros
- de
- Vizualizare
- viziune
- modalități de
- Ce
- care
- În timp ce
- OMS
- pe larg
- voi
- fără
- Cuvânt
- Apartamente
- de lucru
- ar
- scriitor
- scris
- Ta
- zephyrnet
- Învățare Zero-Shot