Поскольку ваша организация становится все более ориентированной на данные и использует их в качестве источника конкурентного преимущества, вам захочется провести аналитику ваших данных, чтобы лучше понять основные движущие силы вашего бизнеса для увеличения продаж, сокращения затрат и оптимизации вашего бизнеса. Чтобы выполнить анализ операционных данных, вы можете создать решение, которое представляет собой комбинацию базы данных, хранилища данных и конвейера извлечения, преобразования и загрузки (ETL). ETL — это метод, который инженеры по обработке данных используют для объединения данных из разных источников.
Чтобы сократить усилия, необходимые для создания и обслуживания конвейеров ETL между транзакционными базами данных и хранилищами данных, AWS объявила: Интеграция Amazon Aurora с нулевым ETL и Amazon Redshift at AWS re: Изобретите 2022 и теперь общедоступен (GA) для Amazon Aurora, совместимая с MySQL, выпуск 3.05.0.
AWS теперь объявляет о фильтрации данных при интеграции с нулевым ETL, что позволяет вам получать выборочные данные из экземпляра базы данных при интеграции с нулевым ETL между Amazon Aurora MySQL и Амазонка Redshift. Эта функция позволяет вам выбирать отдельные базы данных и таблицы для репликации в ваше хранилище данных Redshift для сценариев использования аналитики.
В этом посте мы даем обзор вариантов использования, в которых вы можете использовать эту функцию, и даем пошаговые инструкции о том, как начать работу с оперативной аналитикой, близкой к реальному времени, с использованием этой функции.
Варианты использования фильтрации данных
Фильтрация данных позволяет выбирать базы данных и таблицы для репликации из Amazon Aurora MySQL в Amazon Redshift. Вы можете применить несколько фильтров к интеграции с нулевым ETL, что позволит адаптировать репликацию к вашим конкретным потребностям. Фильтрация данных применяется либо exclude or include правило фильтра и может использовать регулярные выражения для сопоставления нескольких баз данных и таблиц.
В этом разделе мы обсудим некоторые распространенные случаи использования фильтрации данных.
Повысьте безопасность данных, исключив из репликации таблицы, содержащие данные, позволяющие идентифицировать личность.
Оперативные базы данных часто содержат личную информацию (PII). Это конфиденциальная по своей природе информация, которая может включать в себя такую информацию, как почтовые адреса, документацию по проверке клиентов или информацию о кредитной карте.
Из-за строгих правил соблюдения требований безопасности вы можете не захотеть использовать PII для своих сценариев использования аналитики. Фильтрация данных позволяет отфильтровывать базы данных или таблицы, содержащие данные, позволяющие идентифицировать личность, исключая их из репликации в Amazon Redshift. Это повышает безопасность данных и соответствие аналитическим нагрузкам.
Экономьте на расходах на хранение и управляйте аналитическими нагрузками за счет репликации таблиц, необходимых для конкретных случаев использования.
Операционные базы данных часто содержат множество различных наборов данных, которые бесполезны для аналитики. Сюда входят дополнительные данные, данные конкретного приложения и несколько копий одного и того же набора данных для разных приложений.
Более того, на разных складах Redshift обычно создаются разные варианты использования. Эта архитектура требует, чтобы разные наборы данных были доступны в отдельных конечных точках.
Фильтрация данных позволяет реплицировать только те наборы данных, которые необходимы для ваших сценариев использования. Это может сэкономить затраты за счет устранения необходимости хранить данные, которые не используются.
Вы также можете изменить существующие интеграции с нулевым ETL, чтобы при необходимости применить более ограничительную репликацию данных. Если вы добавите фильтр данных в существующую интеграцию, Aurora полностью переоценит данные, реплицируемые с помощью нового фильтра. Это приведет к удалению вновь отфильтрованных данных из целевой конечной точки Redshift.
Дополнительную информацию о квотах для интеграции Aurora с нулевым ETL и Amazon Redshift см. квоты.
Начните с небольшой репликации данных и постепенно добавляйте таблицы по мере необходимости.
По мере того как в Amazon Redshift разрабатывается все больше сценариев использования аналитики, вы можете захотеть добавить больше таблиц в отдельную репликацию с нулевым ETL. Вместо того чтобы реплицировать все таблицы в Amazon Redshift, чтобы обеспечить вероятность их использования в будущем, фильтрация данных позволяет начать с малого, используя подмножество таблиц из базы данных Aurora, и постепенно добавлять в фильтр новые таблицы по мере необходимости. .
После обновления фильтра данных при интеграции с нулевым ETL Aurora полностью переоценит весь фильтр, как если бы предыдущий фильтр не существовал, поэтому добавление новых таблиц не влияет на рабочие нагрузки, использующие ранее реплицированные таблицы.
Повышение производительности отдельных рабочих нагрузок за счет процессов репликации с балансировкой нагрузки.
Для больших транзакционных баз данных может потребоваться балансировка нагрузки репликации и любой последующей обработки на несколько кластеров Redshift, чтобы обеспечить снижение требований к вычислительным ресурсам для отдельной конечной точки Redshift и возможность разделения рабочих нагрузок на несколько конечных точек. Балансируя нагрузку между несколькими конечными точками Redshift, вы можете эффективно создать ячеистую архитектуру данных, в которой конечные точки имеют размер, соответствующий индивидуальным рабочим нагрузкам. Это может улучшить производительность и снизить общую стоимость.
Фильтрация данных позволяет реплицировать различные базы данных и таблицы на отдельные конечные точки Redshift.
На следующем рисунке показано, как можно использовать фильтры данных при интеграции с нулевым ETL для разделения разных баз данных в Aurora для разделения конечных точек Redshift.
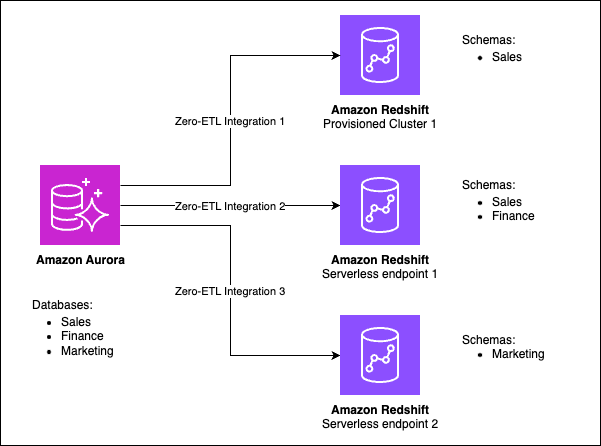
Пример использования
Рассмотрим один пример на платформе БИЛЕТ база данных. Пример базы данных TICKIT содержит данные вымышленной компании, пользователи которой могут покупать и продавать билеты на различные мероприятия. Бизнес-аналитики компании хотят использовать данные, хранящиеся в их базе данных Aurora MySQL, для создания различных показателей и выполнять этот анализ практически в реальном времени. По этой причине компания определила нулевой ETL как потенциальное решение.
В ходе исследования необходимых наборов данных аналитики компании отметили, что таблица пользователей содержит личную информацию о пользователях их клиентов, которая бесполезна для их аналитических требований. Поэтому они хотят реплицировать все данные, кроме таблицы пользователей, и для этого будут использовать фильтрацию данных с нулевым ETL.
Установка
Начните с выполнения шагов, описанных в Руководство по началу работы с операционной аналитикой в режиме, близком к реальному времени, с использованием интеграции Amazon Aurora с нулевым ETL и Amazon Redshift создать новую базу данных Aurora MySQL, Amazon Redshift без сервера конечная точка и интеграция с нулевым ETL. Затем откройте редактор запросов Redshift v2 и выполните следующий запрос, чтобы показать, что данные из таблицы пользователей были успешно реплицированы:

Фильтры данных
Фильтры данных применяются непосредственно к интеграции с нулевым ETL на Сервис реляционной базы данных Amazon (Амазонка РДС). Вы можете определить несколько фильтров для одной интеграции, и каждый фильтр определяется как Include or Exclude тип фильтра. Фильтры данных применяют шаблон к существующим и будущим таблицам базы данных, чтобы определить, какой фильтр следует применить.
Применить фильтр данных
Чтобы применить фильтр для удаления users таблицу из интеграции с нулевым ETL, выполните следующие шаги:
- В консоли Amazon RDS выберите Интеграция с нулевым ETL в навигационной панели.
- Выберите интеграцию с нулевым ETL, к которой нужно добавить фильтр.

Фильтр по умолчанию включает все базы данных и таблицы, представленные include:*.* фильтр.
- Выберите Изменить.

- Выберите Добавить фильтр в Источник .

- Что касается Выберите тип фильтра, выберите Исключать.
- Что касается Выражение фильтра, введите выражение
demodb.users.
Порядок выражений фильтра имеет значение. Фильтры оцениваются слева направо, сверху вниз, а последующие фильтры переопределяют предыдущие. В этом примере Aurora оценит необходимость включения каждой таблицы (фильтр 1), а затем оценит, что demodb.users таблицу следует исключить (фильтр 2). Таким образом, фильтр исключения переопределяет включение, поскольку он находится после фильтра включения.
- Выберите Продолжить.
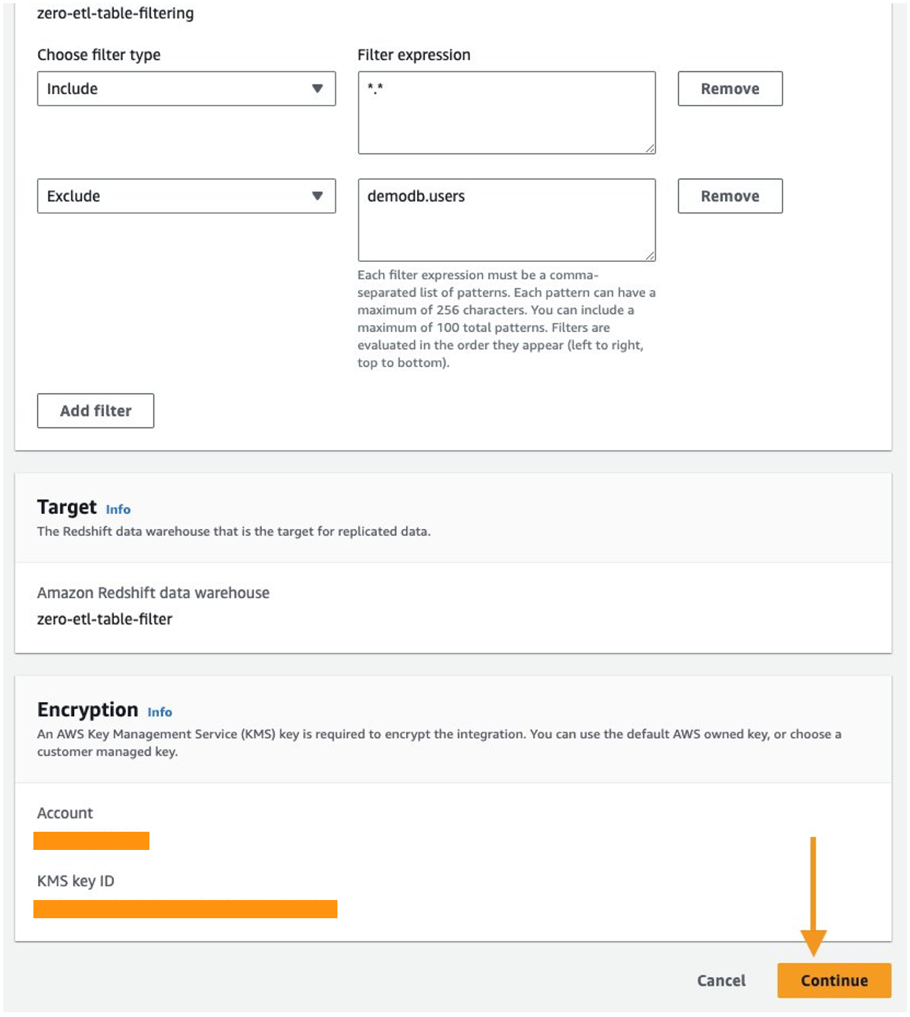
- Просмотрите изменения, убедитесь, что порядок фильтров правильный, и выберите Сохранить изменения.

Интеграция будет добавлена и будет в Изменение состояние до тех пор, пока изменения не будут применены. Это может занять до 30 минут. Чтобы проверить, вступили ли изменения в силу, выберите интеграцию с нулевым ETL и проверьте ее статус. Когда это отображается как Активные, изменения были применены.

Подтвердите изменение
Чтобы убедиться, что интеграция с нулевым ETL обновлена, выполните следующие действия:
- В редакторе запросов Redshift версии 2 подключитесь к кластеру Redshift.
- Выберите (щелкните правой кнопкой мыши)
aurora-zeroetlбазу данных, которую вы создали, и выберите обновление.
- Расширьте
demodbиTables.
Ассоциация users таблица больше не доступна, поскольку она была удалена из репликации. Все остальные таблицы по-прежнему доступны.

- Если вы запустите тот же оператор SELECT, что и ранее, вы получите сообщение об ошибке, сообщающее, что объект не существует в базе данных:

Примените фильтр данных с помощью AWS CLI
Бизнес-аналитики компании теперь понимают, что к базе данных Aurora MySQL добавляется больше баз данных, и они хотят гарантировать, что только demodb база данных реплицируется в их кластер Redshift. С этой целью они хотят обновить фильтры по интеграции нулевого ETL с Интерфейс командной строки AWS (Интерфейс командной строки AWS).
Чтобы добавить фильтры данных в интеграцию с нулевым ETL с помощью интерфейса командной строки AWS, вы можете вызвать изменить-интеграцию команда. Помимо идентификатора интеграции укажите --data-filter параметр со списком разделенных запятыми include и exclude фильтры.
Выполните следующие шаги, чтобы изменить фильтр интеграции с нулевым ETL:
- Откройте терминал с установленным AWS CLI.
- Введите следующую команду, чтобы просмотреть все доступные интеграции:
- Найдите интеграцию, которую хотите обновить, и скопируйте идентификатор интеграции.
Идентификатор интеграции представляет собой буквенно-цифровую строку в конце ARN интеграции.

- Запустите следующую команду, обновив с идентификатором, скопированным с предыдущего шага:

Когда Aurora оценивает этот фильтр, она по умолчанию исключает все, а затем включает только demodb базу данных, но исключить demodb.users таблице.
Фильтры данных могут реализовывать регулярные выражения для баз данных и таблиц. Например, если вы хотите отфильтровать любые таблицы, начинающиеся с user, вы можете запустить следующее:
Как и в случае с предыдущим изменением фильтра, интеграция будет добавлена и будет находиться в Изменение состояние до тех пор, пока изменения не будут применены. Это может занять до 30 минут. Когда это отображается как Активные, изменения были применены.
Убирать
Чтобы удалить фильтр, добавленный к интеграции с нулевым ETL, выполните следующие шаги:
- В консоли Amazon RDS выберите Интеграция с нулевым ETL в навигационной панели.
- Выберите интеграцию с нулевым ETL.
- Выберите Изменить.
- Выберите Удалить рядом с фильтрами, которые вы хотите удалить.
- Вы также можете изменить Исключать тип фильтра для Включают.
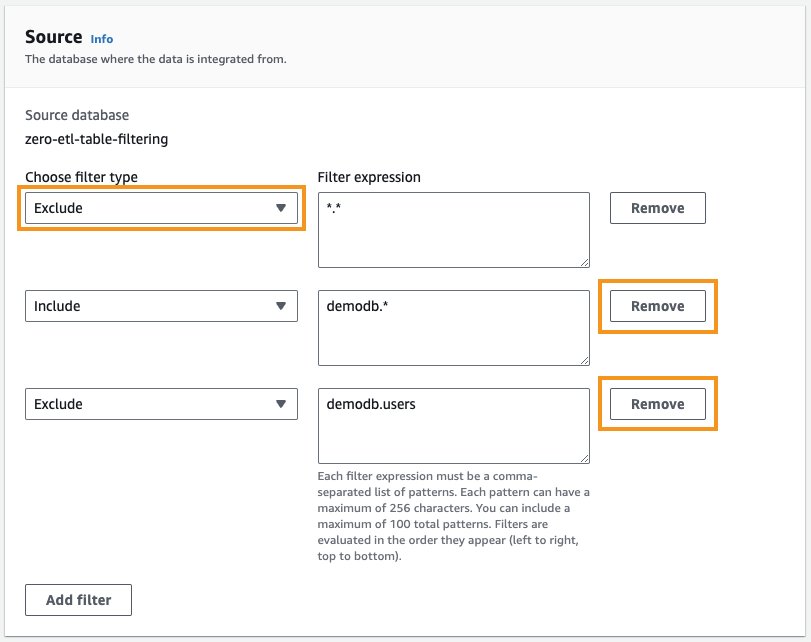
Альтернативно вы можете использовать интерфейс командной строки AWS для запуска следующего:
- Выберите Продолжить.
- Выберите Сохранить изменения.
Фильтру данных потребуется до 30 минут, чтобы применить изменения. После удаления фильтров данных Aurora повторно оценивает оставшиеся фильтры, как если бы удаленный фильтр никогда не существовал. Любые данные, которые раньше не соответствовали критериям фильтрации, а теперь соответствуют, реплицируются в целевое хранилище данных Redshift.
Заключение
В этом посте мы показали, как настроить фильтрацию данных при интеграции Aurora с нулевым ETL из Amazon Aurora MySQL в Amazon Redshift. Это позволяет вам осуществлять аналитику транзакционных и операционных данных практически в реальном времени, реплицируя только необходимые данные.
С помощью фильтрации данных вы можете разделить рабочие нагрузки на отдельные конечные точки Redshift, ограничить репликацию частных или конфиденциальных наборов данных и повысить производительность рабочих нагрузок за счет репликации только необходимых наборов данных.
Дополнительные сведения об интеграции Aurora с нулевым ETL с Amazon Redshift см. Работа с интеграцией Aurora с нулевым ETL и Amazon Redshift. и Работа с интеграциями с нулевым ETL.
Об авторах
 Джоти Аггарвал является руководителем отдела управления продуктами в AWS с нулевым ETL. Она возглавляет продуктовую и бизнес-стратегию, включая реализацию инициатив, касающихся производительности, качества обслуживания клиентов и безопасности. Она обладает опытом в области облачных вычислений, конвейеров данных, аналитики, искусственного интеллекта (ИИ) и служб данных, включая базы данных, хранилища данных и озера данных.
Джоти Аггарвал является руководителем отдела управления продуктами в AWS с нулевым ETL. Она возглавляет продуктовую и бизнес-стратегию, включая реализацию инициатив, касающихся производительности, качества обслуживания клиентов и безопасности. Она обладает опытом в области облачных вычислений, конвейеров данных, аналитики, искусственного интеллекта (ИИ) и служб данных, включая базы данных, хранилища данных и озера данных.
 Шон Бит — архитектор аналитических решений в Amazon Web Services. Он имеет опыт реализации полного жизненного цикла модернизации платформы данных с использованием сервисов AWS и работает с клиентами, помогая повысить ценность аналитики на AWS.
Шон Бит — архитектор аналитических решений в Amazon Web Services. Он имеет опыт реализации полного жизненного цикла модернизации платформы данных с использованием сервисов AWS и работает с клиентами, помогая повысить ценность аналитики на AWS.
 Гокул Соундарараджан является главным инженером в AWS, имеет докторскую степень в Университете Торонто и работает в области хранения данных, баз данных и аналитики.
Гокул Соундарараджан является главным инженером в AWS, имеет докторскую степень в Университете Торонто и работает в области хранения данных, баз данных и аналитики.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- PlatoData.Network Вертикальный генеративный ИИ. Расширьте возможности себя. Доступ здесь.
- ПлатонАйСтрим. Интеллект Web3. Расширение знаний. Доступ здесь.
- ПлатонЭСГ. Углерод, чистые технологии, Энергия, Окружающая среда, Солнечная, Управление отходами. Доступ здесь.
- ПлатонЗдоровье. Биотехнологии и клинические исследования. Доступ здесь.
- Источник: https://aws.amazon.com/blogs/big-data/announcing-data-filtering-for-amazon-aurora-mysql-zero-etl-integration-with-amazon-redshift/
- :имеет
- :является
- :нет
- :куда
- $UP
- 05
- 1
- 10
- 100
- 2%
- 30
- 4
- 420
- 5
- 6
- 7
- 8
- a
- способность
- О нас
- через
- Добавить
- добавленный
- дополнение
- адреса
- плюс
- После
- AI
- Все
- позволять
- Позволяющий
- позволяет
- вдоль
- причислены
- изменять
- Amazon
- Амазон РДС
- Amazon Web Services
- an
- анализ
- Аналитики
- аналитика
- и
- объявило
- объявляющий
- любой
- Применение
- Приложения
- прикладной
- применяется
- Применить
- Применение
- надлежащим образом
- архитектура
- МЫ
- области
- около
- искусственный
- искусственный интеллект
- Искусственный интеллект (AI)
- AS
- Оценка
- At
- Aurora
- доступен
- AWS
- Баланс
- Балансировка
- BE
- , так как:
- становится
- было
- не являетесь
- Лучшая
- между
- Дно
- приносить
- Приносит
- строить
- Строительство
- бизнес
- бизнес стратегия
- но
- купить
- by
- призывают
- CAN
- карта
- случаев
- шанс
- изменение
- изменения
- проверка
- Выберите
- кли
- облако
- Кластер
- сочетание
- объединять
- Общий
- Компания
- Компании
- конкурентоспособный
- полный
- Соответствие закону
- Вычисление
- конфиденциальный
- Свяжитесь
- Консоли
- содержать
- содержащие
- содержит
- копии
- копия
- Основные
- исправить
- Цена
- Расходы
- может
- Создайте
- создали
- кредит
- кредитная карта
- Критерии
- клиент
- опыт работы с клиентами
- Клиенты
- данным
- Платформа данных
- безопасность данных
- информационное хранилище
- хранилища данных
- База данных
- базы данных
- Наборы данных
- По умолчанию
- определять
- определенный
- поставка
- желанный
- Определять
- развитый
- различный
- непосредственно
- обсуждать
- do
- документации
- приносит
- управлять
- управляемый
- драйверы
- вождение
- каждый
- Ранее
- edition
- редактор
- фактически
- усилие
- или
- уничтожение
- включить
- позволяет
- конец
- Конечная точка
- конечные точки
- инженер
- Инженеры
- обеспечивать
- Enter
- Весь
- ошибка
- Эфир (ETH)
- оценивать
- оценивается
- События
- Каждая
- многое
- пример
- Кроме
- исключенный
- без учета
- существовать
- существовавший
- существующий
- опыт
- опыта
- выражение
- выражения
- извлечение
- Особенность
- вымышленный
- фигура
- фильтр
- фильтрация
- фильтры
- законченный
- после
- Что касается
- от
- полный
- полностью
- будущее
- в общем
- порождать
- получить
- Расти
- руководство
- инструкция
- было
- Есть
- he
- помощь
- Как
- How To
- HTML
- HTTP
- HTTPS
- идентифицируемый
- идентифицированный
- идентификатор
- if
- влияние
- осуществлять
- улучшать
- улучшается
- in
- включают
- включены
- включает в себя
- В том числе
- включение
- Увеличение
- individual
- информация
- инициативы
- установлен
- пример
- интеграции.
- интеграций
- Интеллекта
- в
- ходе расследования,
- вовлеченный
- IT
- ЕГО
- JPEG
- JPG
- озера
- большой
- вести
- Лиды
- УЧИТЬСЯ
- оставил
- Жизненный цикл
- такое как
- ОГРАНИЧЕНИЯ
- линия
- Список
- загрузка
- дольше
- ниже
- рассылки
- сохранение
- Создание
- управлять
- управление
- многих
- Совпадение
- Вопросы
- Май..
- сетке
- Метрика
- может быть
- минут
- модернизация
- изменять
- БОЛЕЕ
- с разными
- MySQL
- природа
- Навигация
- Возле
- Необходимость
- потребности
- никогда
- Новые
- вновь
- следующий
- нет
- отметил,
- сейчас
- объект
- of
- .
- on
- только
- на
- открытый
- оперативный
- Оптимизировать
- or
- заказ
- организация
- Другое
- внешний
- общий
- переопределение
- обзор
- хлеб
- параметр
- шаблон
- выполнять
- производительность
- личного
- персональная информация
- Лично
- кандидат наук
- PII
- трубопровод
- Платформа
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- После
- потенциал
- предыдущий
- предварительно
- Основной
- частная
- процесс
- обработка
- Продукт
- Управление продуктом
- обеспечивать
- запрос
- скорее
- RE
- реальные
- реального времени
- причина
- Получать
- получила
- уменьшить
- снижение
- переоценить
- относиться
- регулярный
- правила
- осталось
- удаление
- удален
- реплицируются
- копирование
- представленный
- обязательный
- Требования
- требуется
- ограничительный
- правую
- Щелкните правой кнопкой мыши
- Правило
- Run
- главная
- то же
- образец
- удовлетворить
- Сохранить
- Раздел
- безопасность
- посмотреть
- выберите
- селективный
- продаем
- чувствительный
- отдельный
- Услуги
- набор
- она
- должен
- показывать
- показал
- Шоу
- одинарной
- размера
- небольшой
- So
- Решение
- Решения
- некоторые
- Источник
- Источники
- конкретный
- раскол
- Начало
- и политические лидеры
- Начало
- Область
- заявление
- заявив,
- Статус:
- Шаг
- Шаги
- По-прежнему
- диск
- магазин
- хранить
- Стратегия
- строгий
- строка
- последующее
- Успешно
- такие
- Убедитесь
- ТАБЛИЦЫ
- портной
- взять
- цель
- Терминал
- чем
- который
- Ассоциация
- Будущее
- их
- Их
- тогда
- следовательно
- они
- этой
- билеты
- время
- в
- топ
- Торонто
- транзакционный
- Transform
- напишите
- понимать
- Университет
- до
- Обновление ПО
- обновление
- обновление
- использование
- используемый
- полезный
- Информация о пользователе
- пользователей
- использования
- через
- ценностное
- различный
- проверка
- проверить
- хотеть
- Склады
- we
- Web
- веб-сервисы
- когда
- который
- в то время как
- будете
- работает
- работает
- бы
- являетесь
- ВАШЕ
- зефирнет