Организации решили создавать озера данных поверх Простой сервис хранения Amazon (Amazon S3) уже много лет. Озеро данных является наиболее популярным выбором для организаций для хранения всех своих организационных данных, созданных разными командами, в разных бизнес-доменах, из всех различных форматов и даже за всю историю. В соответствии с исследовании, средняя компания видит, что объем их данных растет со скоростью, превышающей 50% в год, обычно управляя в среднем 33 уникальными источниками данных для анализа.
Команды часто пытаются реплицировать тысячи заданий из реляционных баз данных с помощью одного и того же шаблона извлечения, преобразования и загрузки (ETL). Требуется много усилий для поддержания состояния заданий и планирования этих отдельных заданий. Такой подход помогает командам добавлять таблицы с небольшими изменениями, а также поддерживать статус задания с минимальными усилиями. Это может привести к значительному улучшению графика разработки и легкому отслеживанию заданий.
В этом посте мы покажем вам, как легко реплицировать все ваши хранилища реляционных данных в озеро транзакционных данных в автоматическом режиме с помощью одного задания ETL с использованием Apache Iceberg и Клей AWS.
Архитектура решения
Озера данных обычно организованный использование отдельных корзин S3 для трех уровней данных: необработанный слой, содержащий данные в их исходной форме, промежуточный уровень, содержащий промежуточные обработанные данные, оптимизированные для потребления, и аналитический уровень, содержащий агрегированные данные для конкретных случаев использования. На необработанном уровне таблицы обычно организованы на основе их источников данных, тогда как таблицы на уровне этапа организованы на основе бизнес-доменов, к которым они принадлежат.
Этот пост предоставляет AWS CloudFormation шаблон, который развертывает задание AWS Glue, которое считывает путь Amazon S3 для одного источника данных необработанного уровня озера данных и загружает данные в таблицы Apache Iceberg на уровне рабочей области с помощью Поддержка AWS Glue для фреймворков озера данных. Задание предполагает, что таблицы в необработанном слое будут структурированы таким образом, Сервис миграции баз данных AWS (AWS DMS) принимает их: схему, затем таблицу, затем файлы данных.
Это решение использует Хранилище параметров AWS Systems Manager для конфигурации стола. Вам следует изменить этот параметр, указав таблицы, которые вы хотите обрабатывать, и способ их обработки, включая такую информацию, как первичный ключ, разделы и связанный бизнес-домен. Задание использует эту информацию для автоматического создания базы данных (если она еще не существует) для каждого бизнес-домена, создания таблиц Iceberg и выполнения загрузки данных.
Наконец, мы можем использовать Амазонка Афина для запроса данных в таблицах Iceberg.
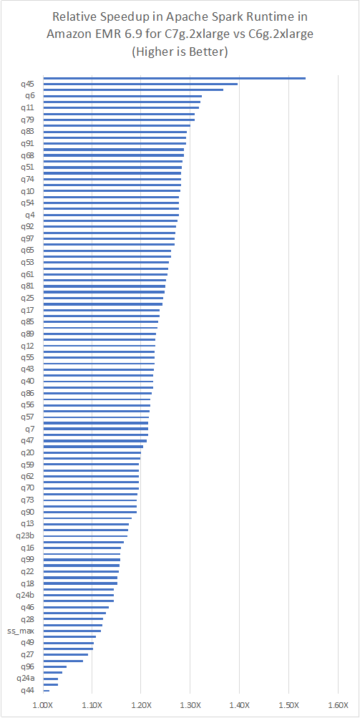
Следующая диаграмма иллюстрирует эту архитектуру.

Эта реализация имеет следующие соображения:
- Все таблицы из источника данных должны иметь первичный ключ для репликации с помощью этого решения. Первичный ключ может быть одним столбцом или составным ключом с более чем одним столбцом.
- Если в озере данных есть таблицы, которые не нуждаются в upserts или не имеют первичного ключа, вы можете исключить их из конфигурации параметров и реализовать традиционные процессы ETL для их загрузки в озеро данных. Это выходит за рамки этого поста.
- Если есть дополнительные источники данных, которые необходимо принять, вы можете развернуть несколько стеков CloudFormation, по одному для обработки каждого источника данных.
- Задание AWS Glue предназначено для обработки данных в два этапа: первоначальная загрузка, которая выполняется после того, как AWS DMS завершит задачу полной загрузки, и дополнительная загрузка, которая выполняется по расписанию, в котором применяются файлы сбора измененных данных (CDC), захваченные AWS DMS. Инкрементальная обработка выполняется с помощью Закладка задания AWS Glue.
Для завершения этого руководства нужно выполнить девять шагов:
- Настройте исходную конечную точку для AWS DMS.
- Разверните решение с помощью AWS CloudFormation.
- Просмотрите задачу репликации AWS DMS.
- При желании добавьте разрешения на шифрование и дешифрование или Формирование озера AWS.
- Просмотрите конфигурацию таблицы в хранилище параметров.
- Выполните начальную загрузку данных.
- Выполнить инкрементную загрузку данных.
- Мониторинг загрузки таблиц.
- Запланируйте добавочную пакетную загрузку данных.
Предпосылки
Прежде чем приступить к этому руководству, вы уже должны быть знакомы с Iceberg. Если нет, вы можете начать с репликации одной таблицы, следуя инструкциям в Внедрение UPSERT на основе CDC в озере данных с использованием Apache Iceberg и AWS Glue.. Дополнительно настройте следующее:
Настройте исходную конечную точку для AWS DMS
Прежде чем мы создадим нашу задачу AWS DMS, нам нужно настроить исходную конечную точку для подключения к исходной базе данных:
- В консоли AWS DMS выберите Endpoints в навигационной панели.
- Выберите Создать конечную точку.
- Если ваша база данных работает на Amazon RDS, выберите Выберите экземпляр БД RDS, затем выберите экземпляр из списка. В противном случае выберите исходный движок и предоставьте информацию о соединении либо через Менеджер секретов AWS или вручную.
- Что касается Идентификатор конечной точки, введите имя конечной точки; например, исходный-postgresql.
- Выберите Создать конечную точку.
Разверните решение с помощью AWS CloudFormation
Создайте стек CloudFormation, используя предоставленный шаблон. Выполните следующие шаги:
- Выберите Стек запуска:

- Выберите Следующая.
- Укажите имя стека, например
transactionaldl-postgresql. - Введите необходимые параметры:
- DMSS3EndpointIAMRoleARN – Роль IAM ARN для AWS DMS для записи данных в Amazon S3.
- РепликацияЭкземплярАрн – ARN экземпляра репликации AWS DMS.
- S3BucketStage – Имя существующего сегмента, используемого для слоя рабочей области озера данных.
- S3ВедроКлей – Имя существующей корзины S3 для хранения скриптов AWS Glue.
- S3BucketRaw – Имя существующего сегмента, используемого для необработанного слоя озера данных.
- Исходная конечная точкаАрн – ARN конечной точки AWS DMS, созданный ранее.
- ИмяИсточника – Произвольный идентификатор источника данных для репликации (например,
postgres). Это используется для определения пути S3 к озеру данных (необработанный слой), где будут храниться данные.
- Не изменяйте следующие параметры:
- ИсточникS3BucketBlog – Имя сегмента, в котором хранится предоставленный скрипт AWS Glue.
- Префикс SourceS3Bucket – Имя префикса сегмента, в котором хранится предоставленный скрипт AWS Glue.
- Выберите Следующая дважды.
- Выберите Я признаю, что AWS CloudFormation может создавать ресурсы IAM с пользовательскими именами.
- Выберите Создать стек.
Примерно через 5 минут стек CloudFormation будет развернут.
Просмотрите задачу репликации AWS DMS
Развертывание AWS CloudFormation создало для вас целевую конечную точку AWS DMS. Из-за двух конкретных настроек конечной точки данные будут приниматься по мере необходимости в Amazon S3.
- В консоли AWS DMS выберите Endpoints в навигационной панели.
- Найдите и выберите конечную точку, которая начинается с
dmsIcebergs3endpoint. - Проверьте настройки конечной точки:
DataFormatуказывается какparquet.TimestampColumnNameдобавит столбецlast_update_timeс датой создания записей на Amazon S3.

При развертывании также создается задача репликации AWS DMS, которая начинается с dmsicebergtask.
- Выберите Задачи репликации в области навигации и найдите задачу.
Вы увидите, что Тип задачи отмечен как Полная загрузка, текущая репликация. AWS DMS выполнит первоначальную полную загрузку существующих данных, а затем создаст добавочные файлы с изменениями, внесенными в исходную базу данных.
На Правила сопоставления tab есть два типа правил:
- Правило выбора с именем исходной схемы и таблиц, которые будут получены из исходной базы данных. По умолчанию используется образец базы данных, указанный в предварительных требованиях.
dms_sample, и все таблицы с ключевым словом %. - Два правила преобразования, которые включают в целевые файлы на Amazon S3 имя схемы и имя таблицы в виде столбцов. Это используется нашим заданием AWS Glue, чтобы узнать, каким таблицам соответствуют файлы в озере данных.
Чтобы узнать больше о том, как настроить это для ваших собственных источников данных, см. Правила выбора и действия.

Давайте изменим некоторые конфигурации, чтобы закончить подготовку нашей задачи.
- На Действия Меню, выберите Изменить.
- В Настройки задачи в разделе Остановить задачу после завершения полной загрузки, выберите Остановить после применения кешированных изменений.
Таким образом, мы можем контролировать первоначальную загрузку и добавочную генерацию файла как два разных шага. Мы используем этот двухэтапный подход для запуска задания AWS Glue один раз на каждом этапе.
- Под Журналы задач, выберите Включите журналы CloudWatch.
- Выберите Сохранить.
- Подождите около 1 минуты, пока статус задачи переноса базы данных не отобразится как Готовый.
Добавить разрешения для шифрования и дешифрования или Lake Formation
При желании вы можете добавить разрешения на шифрование и расшифровку или Lake Formation.
Добавить разрешения на шифрование и дешифрование
Если ваши корзины S3, используемые для необработанных и сценических слоев, зашифрованы с помощью Служба управления ключами AWS (AWS KMS), управляемые клиентом, необходимо добавить разрешения, чтобы разрешить заданию AWS Glue доступ к данным:
Добавить разрешения на формацию озера
Если вы управляете разрешениями с помощью Lake Formation, вам нужно разрешить вашему заданию AWS Glue создавать базы данных и таблицы вашего домена с помощью роли IAM. GlueJobRole.
- Предоставьте разрешения на создание баз данных (инструкции см. Создание базы данных).
- Предоставьте SUPER разрешения для
defaultбаза данных. - Предоставление разрешений на размещение данных.
- Если вы создаете базы данных вручную, предоставьте разрешения на создание таблиц всем базам данных. Ссылаться на Предоставление прав доступа к таблице с помощью консоли Lake Formation и метода именованного ресурса or Предоставление разрешений каталога данных с использованием метода LF-TBAC в соответствии с вашим вариантом использования.
После того как вы завершите последний этап начальной загрузки данных, не забудьте также добавить разрешения для потребителей на запросы к таблицам. Роль задания станет владельцем всех созданных таблиц, а затем администратор озера данных сможет предоставлять гранты другим пользователям.
Конфигурация таблицы просмотра в хранилище параметров
Задание AWS Glue, выполняющее прием данных в таблицы Iceberg, использует спецификацию таблицы, представленную в хранилище параметров. Выполните следующие шаги, чтобы просмотреть хранилище параметров, которое было автоматически настроено для вас. При необходимости измените в соответствии с вашими потребностями.
- В консоли хранилища параметров выберите Мои параметры в навигационной панели.
Стек CloudFormation создал два параметра:
iceberg-configдля рабочих конфигурацийiceberg-tablesдля конфигурации стола
- Выберите параметр айсберг-таблицы.
Структура JSON содержит информацию, которую AWS Glue использует для чтения данных и записи таблиц Iceberg в целевом домене:
- Один объект на таблицу – Имя объекта создается с использованием имени схемы, периода и имени таблицы; например,
schema.table. - основной ключ – Это должно быть указано для каждой исходной таблицы. Вы можете указать один столбец или список столбцов, разделенных запятыми (без пробелов).
- столбцы раздела – Это опционально разделяет столбцы для целевых таблиц. Если вы не хотите создавать секционированные таблицы, укажите пустую строку. В противном случае укажите один столбец или список столбцов, разделенных запятыми (без пробелов).
- Если вы хотите использовать свой собственный источник данных, используйте следующий код JSON и замените текст в CAPS из предоставленного шаблона. Если вы используете предоставленный пример источника данных, оставьте настройки по умолчанию:
{ "SCHEMA_NAME.TABLE_NAME_1": { "primaryKey": "ONLY_PRIMARY_KEY", "domain": "TARGET_DOMAIN", "partitionCols": "" }, "SCHEMA_NAME.TABLE_NAME_2": { "primaryKey": "FIRST_PRIMARY_KEY,SECOND_PRIMARY_KEY", "domain": "TARGET_DOMAIN", "partitionCols": "PARTITION_COLUMN_ONE,PARTITION_COLUMN_TWO" }
}- Выберите Сохранить изменения.
Выполнить начальную загрузку данных
Теперь, когда необходимая конфигурация завершена, мы загружаем исходные данные. Этот шаг состоит из трех частей: прием данных из исходной реляционной базы данных в необработанный слой озера данных, создание таблиц Iceberg на уровне рабочей области озера данных и проверка результатов с помощью Athena.
Ввод данных в необработанный слой озера данных
Чтобы загрузить данные из реляционного источника данных (PostgreSQL, если вы используете предоставленный образец) в наше озеро транзакционных данных с помощью Iceberg, выполните следующие действия:
- В консоли AWS DMS выберите Задачи миграции базы данных в навигационной панели.
- Выберите созданную задачу репликации и на Действия Меню, выберите Перезапустить/возобновить.
- Подождите около 5 минут, пока задача репликации завершится. Вы можете отслеживать таблицы, загруженные на Показатели вкладка задачи репликации.

Через несколько минут задача завершается сообщением Полная загрузка завершена.
- В консоли Amazon S3 выберите сегмент, который вы определили как необработанный слой.
Под префиксом S3, определенным в AWS DMS (например, postgres), вы должны увидеть иерархию папок со следующей структурой:
- Схема
- Название таблицы
LOAD00000001.parquetLOAD0000000N.parquet
- Название таблицы

Если ваша корзина S3 пуста, просмотрите Устранение неполадок с задачами миграции в AWS Database Migration Service перед запуском задания AWS Glue.
Создание и загрузка данных в таблицы Iceberg
Перед запуском задания давайте рассмотрим сценарий задания AWS Glue, предоставляемого как часть стека CloudFormation, чтобы понять его поведение.
- На консоли AWS Glue Studio выберите Джобс в навигационной панели.
- Найдите работу, которая начинается с
IcebergJob-и суффикс имени вашего стека CloudFormation (например,IcebergJob-transactionaldl-postgresql). - Выберите работу.

Сценарий задания получает необходимую ему конфигурацию из хранилища параметров. Функция getConfigFromSSM() возвращает конфигурации, связанные с заданием, такие как исходные и целевые сегменты, из которых данные должны быть прочитаны и записаны. Переменная ssmparam_table_values содержат связанную с таблицами информацию, такую как домен данных, имя таблицы, столбцы разделов и первичный ключ таблиц, которые необходимо принять. См. следующий код Python:
# Main application
args = getResolvedOptions(sys.argv, ['JOB_NAME', 'stackName'])
SSM_PARAMETER_NAME = f"{args['stackName']}-iceberg-config"
SSM_TABLE_PARAMETER_NAME = f"{args['stackName']}-iceberg-tables" # Parameters for job
rawS3BucketName, rawBucketPrefix, stageS3BucketName, warehouse_path = getConfigFromSSM(SSM_PARAMETER_NAME)
ssm_param_table_values = json.loads(ssmClient.get_parameter(Name = SSM_TABLE_PARAMETER_NAME)['Parameter']['Value'])
dropColumnList = ['db','table_name', 'schema_name','Op', 'last_update_time', 'max_op_date']Сценарий использует произвольное имя каталога для Iceberg, которое определено как my_catalog. Это реализовано в каталоге данных AWS Glue с использованием конфигураций Spark, поэтому операция SQL, указывающая на my_catalog, будет применена к каталогу данных. См. следующий код:
catalog_name = 'my_catalog'
errored_table_list = [] # Iceberg configuration
spark = SparkSession.builder .config('spark.sql.warehouse.dir', warehouse_path) .config(f'spark.sql.catalog.{catalog_name}', 'org.apache.iceberg.spark.SparkCatalog') .config(f'spark.sql.catalog.{catalog_name}.warehouse', warehouse_path) .config(f'spark.sql.catalog.{catalog_name}.catalog-impl', 'org.apache.iceberg.aws.glue.GlueCatalog') .config(f'spark.sql.catalog.{catalog_name}.io-impl', 'org.apache.iceberg.aws.s3.S3FileIO') .config('spark.sql.extensions', 'org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions') .getOrCreate()
Сценарий выполняет итерацию по таблицам, определенным в хранилище параметров, и выполняет логику для определения того, существует ли таблица и являются ли входящие данные начальной загрузкой или обновлением:
# Iteration over tables stored on Parameter Store
for key in ssm_param_table_values: # Get table data isTableExists = False schemaName, tableName = key.split('.') logger.info(f'Processing table : {tableName}')Ассоциация initialLoadRecordsSparkSQL() функция загружает исходные данные, когда в файлах S3 нет столбца операций. AWS DMS добавляет этот столбец только в файлы данных Parquet, созданные с помощью непрерывной репликации (CDC). Загрузка данных выполняется с помощью команды INSERT INTO в SparkSQL. См. следующий код:
sqltemp = Template(""" INSERT INTO $catalog_name.$dbName.$tableName ($insertTableColumnList) SELECT $insertTableColumnList FROM insertTable $partitionStrSQL """)
SQLQUERY = sqltemp.substitute( catalog_name = catalog_name, dbName = dbName, tableName = tableName, insertTableColumnList = insertTableColumnList[ : -1], partitionStrSQL = partitionStrSQL) logger.info(f'****SQL QUERY IS : {SQLQUERY}')
spark.sql(SQLQUERY)
Теперь мы запускаем задание AWS Glue для загрузки исходных данных в таблицы Iceberg. Стек CloudFormation добавляет --datalake-formats параметр, добавляющий в задание необходимые библиотеки Iceberg.
- Выберите Выполнить задание.
- Выберите Работа выполняется следить за состоянием. Подождите, пока статус Запуск выполнен успешно.
Проверьте загруженные данные
Чтобы убедиться, что задание обработало данные должным образом, выполните следующие действия:
- На консоли Athena выберите Редактор запросов в навигационной панели.
- проверить
AwsDataCatalogвыбран в качестве источника данных. - Под База данных, выберите домен данных, который вы хотите исследовать, на основе конфигурации, определенной вами в хранилище параметров. Если вы используете предоставленный пример базы данных, используйте
sports.
Под Таблицы и представления, мы можем увидеть список таблиц, созданных заданием AWS Glue.
- Выберите меню параметров (три точки) рядом с именем первой таблицы, затем выберите Предварительный просмотр данных.
Вы можете увидеть данные, загруженные в таблицы Iceberg. 
Выполнить добавочную загрузку данных
Теперь мы начинаем собирать изменения из нашей реляционной базы данных и применять их к озеру транзакционных данных. Этот шаг также разделен на три части: запись изменений, их применение к таблицам Iceberg и проверка результатов.
Захват изменений из реляционной базы данных
Из-за указанной нами конфигурации задача репликации остановилась после выполнения фазы полной загрузки. Теперь мы перезапускаем задачу, чтобы добавить инкрементные файлы с изменениями в необработанный слой озера данных.
- В консоли AWS DMS выберите задачу, которую мы создали и выполнили ранее.
- На Действия Меню, выберите Продолжить.
- Выберите Начать задачу чтобы начать фиксировать изменения.
- Чтобы инициировать создание нового файла в озере данных, выполните вставку, обновление или удаление таблиц исходной базы данных с помощью предпочитаемого вами инструмента администрирования базы данных. Если вы используете предоставленный образец базы данных, вы можете запустить следующие команды SQL:
UPDATE dms_sample.nfl_stadium_data_upd
SET seatin_capacity=93703
WHERE team = 'Los Angeles Rams' and sport_location_id = '31'; update dms_sample.mlb_data set bats = 'R'
where mlb_id=506560 and bats='L'; update dms_sample.sporting_event set start_date = current_date where id=11 and sold_out=0;
- На странице сведений о задаче AWS DMS выберите Таблица статистики вкладку, чтобы увидеть захваченные изменения.

- Откройте необработанный слой озера данных, чтобы найти новый файл, содержащий добавочные изменения внутри префикса каждой таблицы, например, в
sporting_eventприставка.
Запись с изменениями для sporting_event таблица выглядит как на следующем снимке экрана.

Обратите внимание, что Op столбец в начале идентифицирован с обновлением (U). Кроме того, второе значение даты/времени — это контрольный столбец, добавленный AWS DMS со временем фиксации изменения.

Применение изменений к таблицам Iceberg с помощью AWS Glue
Теперь мы снова запускаем задание AWS Glue, и оно будет автоматически обрабатывать только новые добавочные файлы, поскольку закладка задания включена. Давайте рассмотрим, как это работает.
Ассоциация dedupCDCRecords() Функция выполняет дедупликацию данных, поскольку в одном и том же файле данных на Amazon S3 могут быть зафиксированы несколько изменений одного идентификатора записи. Дедупликация выполняется на основе last_update_time столбец, добавленный AWS DMS, который указывает отметку времени фиксации изменения. См. следующий код Python:
def dedupCDCRecords(inputDf, keylist): IDWindowDF = Window.partitionBy(*keylist).orderBy(inputDf.last_update_time).rangeBetween(-sys.maxsize, sys.maxsize) inputDFWithTS = inputDf.withColumn('max_op_date', max(inputDf.last_update_time).over(IDWindowDF)) NewInsertsDF = inputDFWithTS.filter('last_update_time=max_op_date').filter("op='I'") UpdateDeleteDf = inputDFWithTS.filter('last_update_time=max_op_date').filter("op IN ('U','D')") finalInputDF = NewInsertsDF.unionAll(UpdateDeleteDf) return finalInputDFВ строке 99 upsertRecordsSparkSQL() Функция выполняет upsert аналогично начальной загрузке, но на этот раз с помощью команды SQL MERGE.
Просмотрите примененные изменения
Откройте консоль Athena и запустите запрос, который выбирает измененные записи в исходной базе данных. Если вы используете предоставленный пример базы данных, используйте один из следующих SQL-запросов:
SELECT * FROM "sports"."nfl_stadiu_data_upd"
WHERE team = 'Los Angeles Rams' and sport_location_id = 31
LIMIT 1;

Мониторинг загрузки таблицы
Сценарий задания AWS Glue закодирован с помощью простого Обработка исключений Python для отлова ошибок при обработке конкретной таблицы. Закладка задания сохраняется после успешного завершения обработки каждой таблицы, чтобы избежать повторной обработки таблиц, если задание повторяется для таблиц с ошибками.
Ассоциация Интерфейс командной строки AWS (AWS CLI) предоставляет get-job-bookmark команда для AWS Glue, предоставляющая информацию о состоянии закладки для каждой обработанной таблицы.
- В консоли AWS Glue Studio выберите задание ETL.
- Выберите Работа выполняется вкладку и скопируйте идентификатор запуска задания.
- Выполните следующую команду на терминале, аутентифицированном для AWS CLI, заменив
<GLUE_JOB_RUN_ID>в строке 1 со значением, которое вы скопировали. Если ваш стек CloudFormation не названtransactionaldl-postgresql, укажите название вашей работы в строке 2 скрипта:
jobrun=<GLUE_JOB_RUN_ID>
jobname=IcebergJob-transactionaldl-postgresql
aws glue get-job-bookmark --job-name jobname --run-id $jobrunВ этом решении, когда обработка таблицы вызывает исключение, задание AWS Glue не завершается ошибкой в соответствии с этой логикой. Вместо этого таблица будет добавлена в массив, который распечатывается после завершения задания. В таком сценарии задание будет помечено как не выполненное после того, как оно попытается обработать остальные таблицы, обнаруженные в необработанном источнике данных. Таким образом, таблицам без ошибок не нужно ждать, пока пользователь идентифицирует и решит проблему с конфликтующими таблицами. Пользователь может быстро определить запуски заданий, в которых возникли проблемы, используя состояние выполнения заданий AWS Glue, и определить, какие конкретные таблицы вызывают проблемы, используя журналы CloudWatch для выполнения задания.
- Сценарий задания реализует эту функцию с помощью следующего кода Python:
# Performed for every table try: # Table processing logic except Exception as e: logger.info(f'There is an issue with table: {tableName}') logger.info(f'The exception is : {e}') errored_table_list.append(tableName) continue job.commit()
if (len(errored_table_list)): logger.info('Total number of errored tables are ',len(errored_table_list)) logger.info('Tables that failed during processing are ', *errored_table_list, sep=', ') raise Exception(f'***** Some tables failed to process.')На следующем снимке экрана показано, как журналы CloudWatch ищут таблицы, которые вызывают ошибки при обработке.

В соответствии с Объектив анализа данных AWS Well-Architected Framework практики, вы можете адаптировать более сложные механизмы контроля, чтобы выявлять и уведомлять заинтересованные стороны при появлении ошибок в конвейерах данных. Например, вы можете использовать Amazon DynamoDB контрольная таблица для хранения всех таблиц и выполнения заданий с ошибками или с использованием Amazon Простая служба уведомлений (Amazon SNS) в отправлять оповещения операторам при соблюдении определенных критериев.
Запланировать добавочную пакетную загрузку данных
Стек CloudFormation развертывает Amazon EventBridge правило (по умолчанию отключено), которое может запускать задание AWS Glue по расписанию. Чтобы указать собственное расписание и включить правило, выполните следующие действия:
- В консоли EventBridge выберите Правила в навигационной панели.
- Найдите правило с префиксом имени вашего стека CloudFormation, за которым следует
JobTrigger(например,transactionaldl-postgresql-JobTrigger-randomvalue). - Выберите правило.
- Под Расписание Мероприятия, выберите Редактировать.
Расписание по умолчанию настроено на запуск каждый час.
- Укажите расписание, по которому вы хотите запустить задание.
- Кроме того, вы можете использовать Выражение хрона EventBridge выбрав Подробный график.

- Когда вы закончите настройку выражения cron, выберите Следующая три раза и, наконец, выберите Правило обновления для сохранения изменений.
По умолчанию это правило отключено, чтобы вы могли сначала запустить начальную загрузку данных.
- Активируйте правило, выбрав Включите.
Вы можете использовать мониторинг вкладку для просмотра вызовов правил или непосредственно на AWS Glue Выполнение задания Детали.
Заключение
После развертывания этого решения вы автоматизировали прием ваших таблиц в один реляционный источник данных. Организациям, использующим озеро данных в качестве центральной платформы данных, обычно приходится работать с несколькими, а иногда и с десятками источников данных. Кроме того, все больше и больше вариантов использования требуют от организаций внедрения транзакционных возможностей в озеро данных. Вы можете использовать это решение, чтобы ускорить внедрение таких возможностей во всех ваших реляционных источниках данных, чтобы включить новые варианты использования в бизнесе, автоматизировав процесс внедрения, чтобы извлечь больше пользы из ваших данных.
Об авторах
 Луис Херардо Баэса является архитектором больших данных в лаборатории данных Amazon Web Services (AWS). Он имеет 12-летний опыт работы, помогая организациям в сфере здравоохранения, финансов и образования внедрять программы корпоративной архитектуры, облачные вычисления и возможности анализа данных. В настоящее время Луис помогает организациям по всей Латинской Америке ускорить инициативы в области стратегических данных.
Луис Херардо Баэса является архитектором больших данных в лаборатории данных Amazon Web Services (AWS). Он имеет 12-летний опыт работы, помогая организациям в сфере здравоохранения, финансов и образования внедрять программы корпоративной архитектуры, облачные вычисления и возможности анализа данных. В настоящее время Луис помогает организациям по всей Латинской Америке ускорить инициативы в области стратегических данных.
 СайКиран Редди Энугу является архитектором данных в лаборатории данных Amazon Web Services (AWS). Он имеет 10-летний опыт внедрения процессов загрузки, преобразования и визуализации данных. В настоящее время SaiKiran помогает организациям в Северной Америке внедрять современные архитектуры данных, такие как озера данных и сетки данных. Имеет опыт работы в розничной торговле, авиаперевозках и финансовом секторе.
СайКиран Редди Энугу является архитектором данных в лаборатории данных Amazon Web Services (AWS). Он имеет 10-летний опыт внедрения процессов загрузки, преобразования и визуализации данных. В настоящее время SaiKiran помогает организациям в Северной Америке внедрять современные архитектуры данных, такие как озера данных и сетки данных. Имеет опыт работы в розничной торговле, авиаперевозках и финансовом секторе.
 Нарендра Мерла является архитектором данных в лаборатории данных Amazon Web Services (AWS). Он имеет 12-летний опыт проектирования и производства конвейеров данных как в реальном времени, так и в пакетном режиме, а также в создании озер данных как в облачных, так и в локальных средах. В настоящее время Нарендра помогает организациям в Северной Америке создавать и проектировать надежные архитектуры данных и имеет опыт работы в телекоммуникационном и финансовом секторах.
Нарендра Мерла является архитектором данных в лаборатории данных Amazon Web Services (AWS). Он имеет 12-летний опыт проектирования и производства конвейеров данных как в реальном времени, так и в пакетном режиме, а также в создании озер данных как в облачных, так и в локальных средах. В настоящее время Нарендра помогает организациям в Северной Америке создавать и проектировать надежные архитектуры данных и имеет опыт работы в телекоммуникационном и финансовом секторах.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- Платоблокчейн. Интеллект метавселенной Web3. Расширение знаний. Доступ здесь.
- Источник: https://aws.amazon.com/blogs/big-data/automate-replication-of-relational-sources-into-a-transactional-data-lake-with-apache-iceberg-and-aws-glue/
- 1
- 10
- 100
- 102
- 107
- 7
- a
- О нас
- ускорять
- доступ
- По
- признавать
- через
- приспосабливать
- добавленный
- дополнительный
- Дополнительно
- Добавляет
- Администратор
- администрация
- принять
- Принятие
- После
- авиакомпания
- Все
- уже
- Amazon
- Амазонка Афина
- Амазон РДС
- Amazon Web Services
- Веб-службы Amazon (AWS)
- Америка
- анализ
- аналитика
- и
- -Анджелесе
- апаш
- появиться
- Применение
- прикладной
- Применение
- подхода
- примерно
- архитектура
- массив
- связанный
- подлинности
- автоматизировать
- Автоматизированный
- автоматически
- Автоматизация
- в среднем
- избежать
- AWS
- AWS CloudFormation
- Клей AWS
- основанный
- летучие мыши
- , так как:
- становиться
- до
- начало
- большой
- Big Data
- строить
- строитель
- Строительство
- бизнес
- Может получить
- возможности
- крышки
- захватить
- Захват
- случаев
- случаев
- каталог
- Привлекайте
- Вызывать
- Причины
- Причинение
- CDC
- центральный
- определенный
- изменение
- изменения
- выбор
- Выберите
- Выбирая
- выбранный
- облако
- облачных вычислений
- код
- Column
- Колонки
- Компания
- полный
- вычисление
- Конфигурация
- Конфигурации
- подтвердить
- противоречивый
- Свяжитесь
- связи
- соображения
- Консоли
- Потребители
- потребление
- содержит
- продолжать
- (CIJ)
- контроль
- может
- Создайте
- создали
- создает
- Создающий
- создание
- Критерии
- В настоящее время
- изготовленный на заказ
- клиент
- настроить
- данным
- Анализ данных
- Озеро данных
- Платформа данных
- База данных
- базы данных
- Время
- По умолчанию
- определенный
- развертывание
- развернуть
- развертывание
- развертывание
- развертывает
- Проект
- предназначенный
- проектирование
- подробнее
- обнаруженный
- Развитие
- различный
- непосредственно
- инвалид
- Разделенный
- не
- домен
- доменов
- Dont
- в течение
- каждый
- Ранее
- легко
- Обучение
- усилие
- или
- включить
- включен
- зашифрованный
- шифрование
- Конечная точка
- Двигатель
- Enter
- Предприятие
- средах
- ошибки
- Эфир (ETH)
- Даже
- Каждая
- пример
- превышает
- Кроме
- исключение
- существующий
- существует
- ожидаемый
- надеется
- опыт
- Больше
- расширения
- извлечение
- XNUMX ошибка
- знакомый
- Мода
- Особенность
- несколько
- Файл
- Файлы
- в заключение
- финансы
- финансовый
- Найдите
- окончание
- First
- следует
- после
- Для потребителей
- форма
- образование
- Рамки
- от
- полный
- функция
- генерируется
- поколение
- получить
- предоставлять
- гранты
- Рост
- обрабатывать
- здравоохранение
- помощь
- помогает
- иерархия
- история
- проведение
- Как
- How To
- HTML
- HTTPS
- огромный
- IAM
- идентифицированный
- идентификатор
- идентифицирует
- определения
- осуществлять
- реализация
- в XNUMX году
- Осуществляющий
- инвентарь
- улучшение
- in
- включают
- включает в себя
- В том числе
- Входящий
- указывает
- individual
- информация
- начальный
- инициативы
- Вставки
- понимание
- пример
- вместо
- инструкции
- Intermediate
- вопрос
- вопросы
- IT
- итерация
- работа
- Джобс
- JSON
- Сохранить
- Основные
- ключи
- Знать
- лаборатория
- озеро
- латинский
- Латинская Америка
- слой
- слоев
- вести
- УЧИТЬСЯ
- библиотеки
- ОГРАНИЧЕНИЯ
- линия
- Список
- загрузка
- погрузка
- грузы
- расположение
- посмотреть
- ВЗГЛЯДЫ
- лос
- Лос-Анджелес
- серия
- Главная
- поддерживает
- сделать
- управляемого
- управление
- менеджер
- управления
- вручную
- многих
- отображение
- с пометкой
- Меню
- идти
- сообщение
- может быть
- миграция
- минимальный
- минут
- минут
- Модерн
- изменять
- монитор
- Мониторинг
- БОЛЕЕ
- самых
- Самые популярные
- с разными
- имя
- Названный
- имена
- Откройте
- Навигация
- Необходимость
- необходимый
- потребности
- Новые
- следующий
- север
- Северная Америка
- уведомление
- номер
- объект
- объекты
- ONE
- постоянный
- OP
- операция
- оптимизированный
- Опции
- организационной
- организации
- Организованный
- оригинал
- в противном случае
- внешнюю
- собственный
- владелец
- хлеб
- параметр
- параметры
- часть
- части
- путь
- шаблон
- выполнять
- выполнения
- выполняет
- период
- Разрешения
- фаза
- Платформа
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- Популярное
- После
- Postgresql
- практиками
- привилегированный
- предпосылки
- представить
- первичный
- Проблема
- процесс
- Процессы
- обработка
- Произведенный
- Программы
- обеспечивать
- при условии
- приводит
- Питон
- быстро
- повышение
- Обменный курс
- Сырье
- необработанные данные
- Читать
- реального времени
- запись
- учет
- замещать
- реплицируются
- копирование
- требовать
- обязательный
- ресурс
- Полезные ресурсы
- ОТДЫХ
- Итоги
- розничный
- возвращают
- Возвращает
- обзоре
- надежный
- Роли
- Правило
- условиями,
- Run
- Бег
- то же
- Сохранить
- сценарий
- график
- сфера
- скрипты
- Поиск
- Во-вторых
- Сектора юридического права
- видя
- выбранный
- выбор
- выбор
- отдельный
- Услуги
- набор
- установка
- настройки
- должен
- показывать
- Шоу
- аналогичный
- просто
- с
- одинарной
- So
- Решение
- Решает
- некоторые
- сложный
- Источник
- Источники
- пространства
- Искриться
- конкретный
- Спецификация
- указанный
- Спорт
- SQL
- стек
- Стеки
- Этап
- заинтересованных сторон
- Начало
- и политические лидеры
- Начало
- начинается
- Области
- статистика
- Статус:
- Шаг
- Шаги
- остановившийся
- диск
- магазин
- хранить
- магазины
- Стратегический
- Структура
- структурированный
- студия
- Успешно
- такие
- супер
- поддержка
- системы
- ТАБЛИЦЫ
- цель
- Сложность задачи
- задачи
- команда
- команды
- телеком
- шаблон
- Терминал
- Ассоциация
- Источник
- их
- тысячи
- три
- Через
- время
- Сроки
- раз
- отметка времени
- в
- инструментом
- топ
- Всего
- Отслеживание
- традиционный
- транзакционный
- Transform
- трансформация
- вызвать
- учебник
- Типы
- под
- понимать
- созданного
- Обновление ПО
- Updates
- использование
- прецедент
- Информация о пользователе
- пользователей
- обычно
- ценностное
- проверка
- Вид
- визуализация
- объем
- ждать
- Склады
- Web
- веб-сервисы
- который
- будете
- в
- без
- работает
- записывать
- письменный
- YAML
- год
- лет
- ВАШЕ
- зефирнет