В области анализа данных организации часто имеют дело со многими таблицами в разных базах данных и форматами файлов для хранения данных для различных бизнес-функций. Бизнес-потребности часто определяют структуру таблиц, например эволюцию схемы (добавление новых столбцов, удаление существующих столбцов, обновление имен столбцов и т. д.) для некоторых из этих таблиц в одной бизнес-функции, которая требует, чтобы другие бизнес-функции реплицировали одни и те же . Этот пост посвящен таким изменениям схемы в таблицах на основе файлов и показывает, как экономично автоматически реплицировать эволюцию схемы структурированных данных из табличных форматов в базах данных в таблицы, хранящиеся в виде файлов.
Клей AWS — это бессерверная служба интеграции данных, которая упрощает обнаружение, подготовку и объединение данных для аналитики, машинного обучения (ML) и разработки приложений. В этом посте мы покажем, как использовать Апач Худи, уровень самоуправляемой базы данных в озерах данных на основе файлов, в AWS Glue для автоматического представления данных в реляционной форме и управления эволюцией их схемы в масштабе с помощью Простой сервис хранения Amazon (Амазон С3), Сервис миграции баз данных AWS (АМС ДМС), AWS Lambda, Клей AWS, Amazon DynamoDB, Амазон Аврораи Амазонка Афина автоматически определять эволюцию схемы и применять ее для управления нагрузкой данных в петабайтном масштабе.
Apache Hudi поддерживает транзакции ACID и операции CRUD в озере данных. Это закладывает основу архитектуры озера данных, обеспечивая поддержку транзакций, эволюцию и управление схемой, отделение хранилища от вычислений и обеспечение поддержки доступности с помощью инструментов бизнес-аналитики (BI). В этом посте мы реализуем архитектуру для создания озера транзакционных данных, основанного на вышеупомянутых функциях Hudi.
Обзор решения
В этом посте предполагается сценарий, в котором в исходной базе данных присутствует несколько таблиц, и мы хотим реплицировать любые изменения схемы в любой из этих таблиц в таблицах Apache Hudi в озере данных. Он использует встроенная поддержка Apache Hudi на AWS Glue для Apache Spark.
В этом посте эволюция схемы исходных таблиц в базе данных Aurora фиксируется с помощью AWS DMS. добавочная загрузка или сбор измененных данных (CDC) Механизм, и та же эволюция схемы реплицируется в таблицах Apache Hudi, хранящихся в Amazon S3. Таблицы Apache Hudi обнаруживаются каталогом данных AWS Glue и запрашиваются Athena. Задание AWS Glue, поддерживаемое конвейером оркестровки с использованием Lambda и таблицы DynamoDB, обеспечивает автоматическую репликацию эволюции схемы в таблицах Apache Hudi.
Мы используем Aurora в качестве примера источника данных, но любой источник данных, который поддерживает операции создания, чтения, обновления и удаления (CRUD), может заменить Aurora в вашем случае использования.
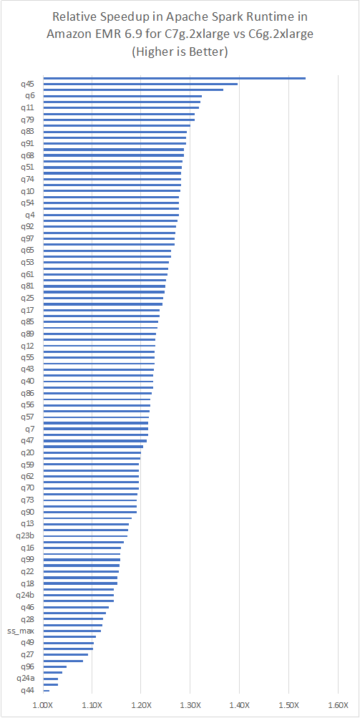
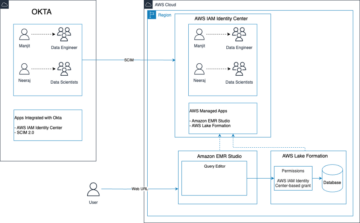
На следующей диаграмме показана архитектура нашего решения.

Ход решения следующий:
- Aurora, как образец источника данных, содержит таблицу СУБД с несколькими строками, а AWS DMS полностью загружает эти данные в корзину S3 (которую мы называем необработанной корзиной). Мы ожидаем, что у вас может быть несколько исходных таблиц, но в демонстрационных целях в этом посте мы используем только одну исходную таблицу.
- Мы запускаем функцию Lambda с именем исходной таблицы как событие, чтобы соответствующие параметры исходной таблицы считывались из DynamoDB. Чтобы запланировать эту операцию на определенные интервалы времени, мы график Amazon EventBridge для запуска Lambda с именем таблицы в качестве параметра.
- В исходной базе данных много таблиц, и мы хотим запустить одно задание AWS Glue для каждой исходной таблицы для простоты операций. Поскольку мы используем каждое задание AWS Glue для обновления каждой таблицы Apache Hudi, в этом посте используется таблица DynamoDB для хранения параметров конфигурации, используемых каждым заданием AWS Glue для каждой таблицы Apache Hudi. Таблица DynamoDB содержит имя каждой таблицы Apache Hudi, соответствующее имя задания AWS Glue, статус задания AWS Glue, статус загрузки (полный или разностный), ключ раздела, ключ записи и схему для передачи в задание AWS Glue соответствующей таблицы. Значения в таблице DynamoDB являются статическими.
- Чтобы запустить каждое задание AWS Glue (10 DPU G.1X) параллельно для запуска специального кода Apache Hudi для вставки данных в соответствующие таблицы Hudi, Lambda передает параметры каждой таблицы Apache Hudi, считанные из DynamoDB, в каждое задание AWS Glue. Исходные данные поступают из таблиц исходной базы данных Aurora через AWS DMS с полной и инкрементной загрузкой или CDC.
Создавайте ресурсы с помощью AWS CloudFormation
Мы предоставляем AWS CloudFormation шаблон для создания следующих ресурсов:
- Lambda и DynamoDB как оркестраторы управления загрузкой данных
- Сегменты S3 для необработанной, уточненной зоны и активы для хранения кода для эволюции схемы
- Задание AWS Glue для обновления таблиц Hudi и выполнения эволюции схемы с прямой и обратной совместимостью.
Таблица Aurora и экземпляр репликации AWS DMS не предоставляются через этот стек. Инструкции по настройке Aurora см. Создание кластера БД Amazon Aurora.
Запустите следующий стек и укажите имя стека.
eu-west-1 |
Эволюция схемы
Чтобы получить доступ к базе данных Aurora, см. Как подключиться к инстансу Amazon RDS для MySQL с помощью MySQL Workbench. Затем выполните следующие шаги:
- Создайте таблицу с именем object в соответствии с запросами в базе данных Aurora и измените ее схему, чтобы мы могли видеть, как эволюция схемы отражается на уровне озера данных:
После создания стеков необходимо выполнить некоторые действия вручную, чтобы подготовить решение от начала до конца.
- Создайте DMS AWS пример, АМС ДМС конечные точкии AWS DMS задача со следующими конфигурациями:
- Добавьте dataFormat как Parquet в целевую конечную точку.
- Направьте целевую конечную точку AWS DMS на необработанную корзину, которая имеет формат
raw-bucket-<account_number>-<region_name>, а имя папки должно быть POC.
- Запустите задачу AWS DMS.
- Создайте тестовое событие в
HudiLambdaЛямбда-функция с содержимым события JSON в видеPOC.dbи сохранить его. - Запустите лямбда-функцию.
В этом посте эволюция схемы отражена через Синхронизация Hudi Hive в AWS клей. Вы не изменяете запросы отдельно в озере данных.
Теперь мы выполняем следующие шаги, чтобы изменить схему в источнике. Запускайте функцию Lambda после каждого шага, чтобы сгенерировать файл в POC/db/object папка в сыром ведре. AWS DMS почти мгновенно улавливает изменения схемы и отправляет отчеты в корзину необработанных данных.
- Добавьте столбец с названием
test_columnк исходной таблицеobjectв вашей базе данных Aurora:
- Переименуйте столбец
new_field_1вnew_field_2в объекте исходной таблицы:
Колонка new_field_1 ожидается, что он останется в таблице Hudi, но без добавления каких-либо новых значений.
- Удалить столбец
new_field_2из объекта исходной таблицы:
Как и в предыдущей операции, столбец new_field_2 ожидается, что он останется в таблице Hudi, но без добавления каких-либо новых значений.
Если у вас уже есть Формирование озера AWS разрешений данных, настроенных в вашей учетной записи, вы можете столкнуться с проблемами разрешений. В этом случае предоставьте полное разрешение (Super) базе данных по умолчанию (до запуска функции Lambda) и всем таблицам в POC.db базу данных (после завершения загрузки).
Просмотрите результаты
Когда вышеупомянутый запуск происходит после изменения схемы, в уточненном сегменте генерируются следующие результаты. Мы можем просматривать таблицы Apache Hudi с их содержимым в Athena. Чтобы настроить Athena, см. Начинаем!.
Таблица и база данных доступны в каталоге данных AWS Glue и готовы для просмотра схемы.
До изменения схемы результаты Athena выглядят так, как показано на следующем снимке экрана.
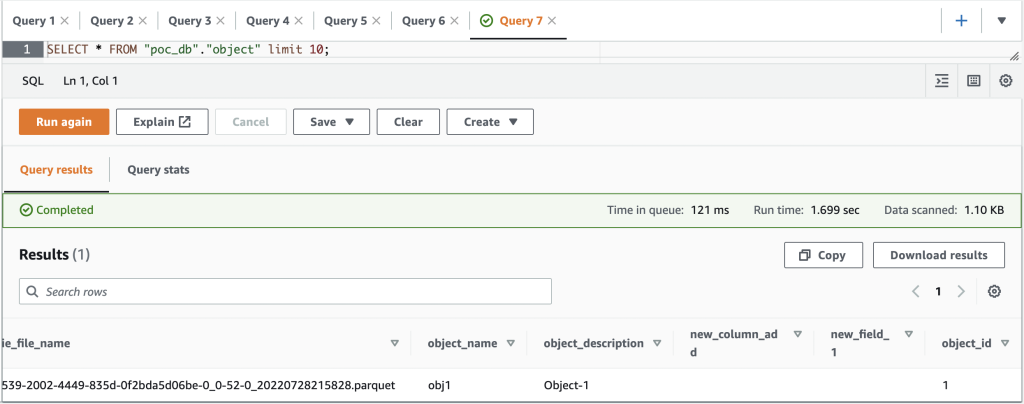
После добавления столбца test_column и вставьте значение в test_column поле в таблице объектов в базе данных Aurora новый столбец (test_column) отражен в соответствующей таблице Apache Hudi в озере данных.
На следующем снимке экрана показаны результаты в Athena.

После переименования столбца new_field_1 в new_field_2 и вставьте значение в new_field_2 поле в таблице объектов, переименованный столбец (new_field_2) отражается в соответствующей таблице Apache Hudi в озере данных, и new_field_1 остается в схеме, не имея нового значения, заполняемого столбцом.
На следующем снимке экрана показаны результаты в Athena.
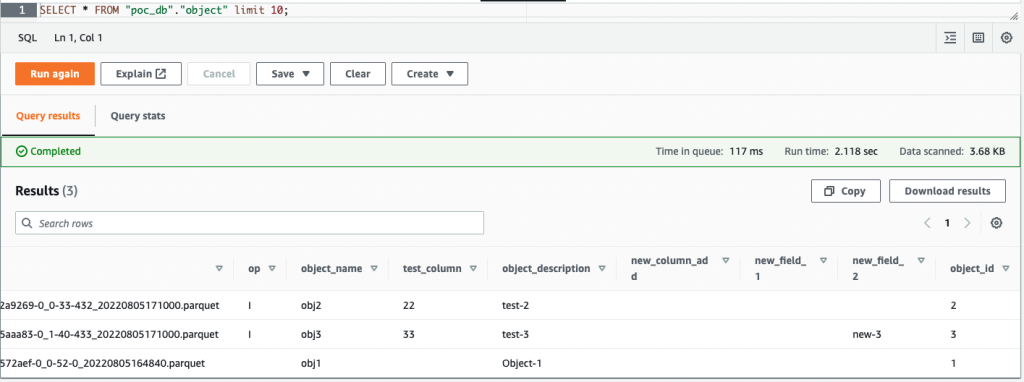
После удаления столбца new_field_2 в таблице объектов и вставьте или обновите любые значения в любых столбцах таблицы объектов, удаленный столбец (new_field_2) остается в соответствующей схеме таблицы Apache Hudi, и в столбец не добавляется новое значение.
На следующем снимке экрана показаны результаты в Athena.

Убирать
Когда вы закончите с этим решением, удалите образцы данных в необработанных и уточненных корзинах S3 и удалите корзины.
Кроме того, удалите стек CloudFormation, чтобы удалить все ресурсы службы, используемые в этом решении.
Заключение
В этом посте показано, как реализовать эволюцию схемы с помощью решения с открытым исходным кодом с использованием Apache Hudi в среде AWS с конвейером оркестрации.
Вы можете изучить различные Конфигурации AWS Glue, чтобы изменить структуру заданий AWS Glue и внедрить ее для анализа данных и других вариантов использования.
Об авторах
 Сугро Бозе является старшим архитектором данных в Emergent Technologies and Intelligence Platform в Amazon. Ему нравится решать научные задачи с помощью новейших технологий, таких как AI/ML, большие данные, квантовые вычисления и т. д., чтобы помочь предприятиям из разных отраслевых вертикалей добиться успеха в своем инновационном пути. В свободное время он любит играть в настольный теннис, изучать теории экономики окружающей среды и пробовать лучшие маффины в городе.
Сугро Бозе является старшим архитектором данных в Emergent Technologies and Intelligence Platform в Amazon. Ему нравится решать научные задачи с помощью новейших технологий, таких как AI/ML, большие данные, квантовые вычисления и т. д., чтобы помочь предприятиям из разных отраслевых вертикалей добиться успеха в своем инновационном пути. В свободное время он любит играть в настольный теннис, изучать теории экономики окружающей среды и пробовать лучшие маффины в городе.
 Кетан Каралкар является консультантом по решениям для больших данных в AWS. Он имеет почти 2 лет опыта, помогая клиентам разрабатывать и создавать решения для анализа данных и баз данных. Он верит в использование технологий как средства решения реальных бизнес-задач.
Кетан Каралкар является консультантом по решениям для больших данных в AWS. Он имеет почти 2 лет опыта, помогая клиентам разрабатывать и создавать решения для анализа данных и баз данных. Он верит в использование технологий как средства решения реальных бизнес-задач.
 Ева Фанг работает специалистом по данным в Professional Services в AWS. Она увлечена использованием технологий для обеспечения ценности для клиентов и достижения результатов в бизнесе. Она живет в Лондоне, в свободное время любит смотреть фильмы и мюзиклы.
Ева Фанг работает специалистом по данным в Professional Services в AWS. Она увлечена использованием технологий для обеспечения ценности для клиентов и достижения результатов в бизнесе. Она живет в Лондоне, в свободное время любит смотреть фильмы и мюзиклы.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- Платоблокчейн. Интеллект метавселенной Web3. Расширение знаний. Доступ здесь.
- Источник: https://aws.amazon.com/blogs/big-data/automate-schema-evolution-at-scale-with-apache-hudi-in-aws-glue/
- 1
- 10
- 100
- 107
- 11
- 7
- a
- О нас
- доступ
- доступность
- Учетная запись
- Достигать
- через
- дополнение
- После
- AI / ML
- Все
- уже
- Amazon
- Амазон РДС
- amp
- аналитика
- и
- апаш
- Применение
- Разработка приложения
- Применить
- архитектура
- Активы
- Aurora
- автоматизировать
- Автоматизированный
- автоматически
- доступен
- AWS
- Клей AWS
- основанный
- , так как:
- до
- не являетесь
- считает,
- ЛУЧШЕЕ
- большой
- Big Data
- просмотр
- строить
- построенный
- бизнес
- хозяйственная деятельность
- бизнес-аналитика
- бизнес
- призывают
- под названием
- захватить
- заботится
- случаев
- случаев
- каталог
- CDC
- изменение
- изменения
- Город
- код
- Column
- Колонки
- объединять
- полный
- Вычисление
- Конфигурация
- Конфигурации
- Свяжитесь
- консультант
- содержит
- содержание
- содержание
- соответствующий
- рентабельным
- Создайте
- Создающий
- Клиенты
- данным
- Анализ данных
- Интеграция данных
- Озеро данных
- ученый данных
- База данных
- базы данных
- сделка
- десятилетия
- По умолчанию
- Delta
- Проект
- Развитие
- различный
- обнаружить
- открытый
- Dont
- управлять
- Падение
- каждый
- Экономика
- позволяет
- столкновение
- Конечная точка
- обеспечение
- Окружающая среда
- окружающий
- Эфир (ETH)
- События
- эволюция
- существующий
- ожидать
- ожидаемый
- опыт
- Больше
- Особенности
- поле
- Файл
- Файлы
- поток
- фокусируется
- после
- следующим образом
- форма
- Год основания
- от
- полный
- функция
- Функции
- порождать
- генерируется
- предоставлять
- происходит
- имеющий
- помощь
- помощь
- Hive
- держать
- проведение
- Как
- How To
- HTML
- HTTPS
- определения
- осуществлять
- in
- промышленность
- Инновации
- пример
- инструкции
- интеграции.
- Интеллекта
- вопросы
- IT
- работа
- путешествие
- JSON
- Основные
- озеро
- слой
- Lays
- УЧИТЬСЯ
- изучение
- уровень
- ЖИЗНЬЮ
- загрузка
- Лондон
- посмотреть
- выглядит как
- машина
- обучение с помощью машины
- ДЕЛАЕТ
- управлять
- управление
- руководство
- многих
- механизм
- миграция
- ML
- БОЛЕЕ
- Кино
- с разными
- MySQL
- имя
- Названный
- имена
- почти
- необходимый
- потребности
- Новые
- объект
- ONE
- с открытым исходным кодом
- операция
- Операционный отдел
- оркестровка
- организации
- Другое
- Параллельные
- параметр
- параметры
- проходит
- страстный
- выполнять
- разрешение
- Разрешения
- петабайт
- Выборы
- трубопровод
- Платформа
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- игры
- PoC
- населенный
- После
- Подготовить
- представить
- предыдущий
- проблемам
- профессиональный
- обеспечивать
- целей
- Квантовый
- Сырье
- Читать
- готовый
- реальные
- реальная жизнь
- запись
- рафинированный
- отметила
- остатки
- удаление
- удаление
- замещать
- реплицируются
- копирование
- Отчеты
- представлять
- требуется
- Полезные ресурсы
- Итоги
- Run
- то же
- Сохранить
- Шкала
- сценарий
- график
- Наука
- Ученый
- старший
- Serverless
- обслуживание
- Услуги
- набор
- должен
- показывать
- Шоу
- просто
- простота
- So
- Решение
- Решения
- РЕШАТЬ
- Решение
- некоторые
- Источник
- Space
- конкретный
- стек
- Стеки
- Статус:
- оставаться
- Шаг
- Шаги
- диск
- хранить
- Структура
- структурированный
- быть успешными
- такие
- супер
- поддержка
- Поддержанный
- Поддержка
- ТАБЛИЦЫ
- принимает
- цель
- Сложность задачи
- технологии
- Технологии
- шаблон
- теннис
- тестXNUMX
- Ассоциация
- Источник
- их
- Через
- время
- в
- инструменты
- сделка
- транзакционный
- Сделки
- вызвать
- срабатывание
- под
- Обновление ПО
- использование
- прецедент
- ценностное
- Наши ценности
- вертикалей
- с помощью
- Вид
- Смотреть
- который
- в
- без
- ВАШЕ
- зефирнет