В этом посте мы демонстрируем Kubeflow на AWS (специальный дистрибутив Kubeflow для AWS) и преимущества, которые он добавляет по сравнению с Kubeflow с открытым исходным кодом за счет интеграции высокооптимизированных облачных сервисов AWS, готовых для предприятий.
Kubeflow — это платформа машинного обучения (ML) с открытым исходным кодом, предназначенная для простого, переносимого и масштабируемого развертывания рабочих процессов ML в Kubernetes. Kubeflow предоставляет множество компонентов, в том числе центральную панель управления, многопользовательские блокноты Jupyter, Kubeflow Pipelines, KFServing и Katib, а также распределенных операторов обучения для TensorFlow, PyTorch, MXNet и XGBoost для создания простых, масштабируемых и переносимых рабочих процессов машинного обучения. .
Недавно AWS запустила Kubeflow версии 1.4 как часть собственного дистрибутива Kubeflow (называемого Kubeflow на AWS), который оптимизирует задачи обработки данных и помогает создавать высоконадежные, безопасные, переносимые и масштабируемые системы машинного обучения с сокращением операционных издержек за счет интеграции с управляемыми сервисами AWS. . Вы можете использовать этот дистрибутив Kubeflow для создания систем машинного обучения поверх Амазон Эластик Кубернетес Сервис (Amazon EKS) для создания, обучения, настройки и развертывания моделей машинного обучения для самых разных вариантов использования, включая компьютерное зрение, обработку естественного языка, перевод речи и финансовое моделирование.
Проблемы с Kubeflow с открытым исходным кодом
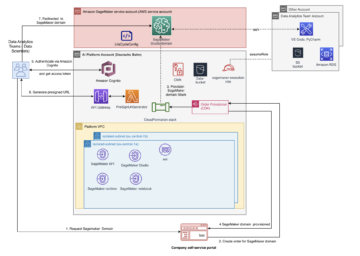
Когда вы используете проект Kubeflow с открытым исходным кодом, он развертывает все компоненты плоскости управления Kubeflow и плоскости данных на рабочих узлах Kubernetes. Службы компонентов Kubeflow развертываются как часть плоскости управления Kubeflow, а все развертывания ресурсов, связанные с Jupyter, обучением моделей, настройкой и размещением, развертываются в плоскости данных Kubeflow. Плоскость управления Kubeflow и плоскость данных могут работать на одном или разных рабочих узлах Kubernetes. Этот пост посвящен компонентам плоскости управления Kubeflow, как показано на следующей диаграмме.

Эта модель развертывания может не обеспечивать готовность предприятия по следующим причинам:
- Все тяжелые компоненты инфраструктуры плоскости управления Kubeflow, включая базу данных, хранилище и аутентификацию, развертываются на самом рабочем узле кластера Kubernetes. Это усложняет реализацию высокодоступной архитектуры проектирования плоскости управления Kubeflow с постоянным состоянием в случае сбоя рабочего узла.
- Артефакты, создаваемые плоскостью управления Kubeflow (такие как экземпляры MySQL, журналы модулей или хранилище MinIO), со временем растут, и для удовлетворения растущего спроса на хранилище требуются тома хранения с изменяемым размером и возможностями непрерывного мониторинга. Поскольку плоскость управления Kubeflow разделяет ресурсы с рабочими нагрузками плоскости данных Kubeflow (например, для учебных заданий, конвейеров и развертываний), правильное определение размера и масштабирование кластера Kubernetes и томов хранилища может стать сложной задачей и привести к увеличению эксплуатационных расходов.
- Kubernetes ограничивает размер файла журнала, при этом в большинстве установок последний предел составляет 10 МБ. По умолчанию журналы модулей становятся недоступными после достижения этого верхнего предела. Журналы также могут стать недоступными, если модули вытеснены, аварийно завершены, удалены или запланированы на другом узле, что может повлиять на доступность журнала вашего приложения и возможности мониторинга.
Kubeflow на AWS
Kubeflow на AWS предоставляет простой способ использования Kubeflow со следующими сервисами AWS:
- Балансировщик нагрузки приложений для безопасного управления внешним трафиком через HTTPS
- Amazon CloudWatch для постоянного управления журналом
- AWS Когнито для аутентификации пользователя с помощью Transport Layer Security (TLS)
- Контейнеры глубокого обучения AWS для высокооптимизированных образов сервера ноутбуков Jupyter
- Эластичная файловая система Amazon (Amazon EFS) или Amazon FSx для блеска для простого, масштабируемого и бессерверного решения для хранения файлов для повышения эффективности обучения
- Amazon EKS для управляемых кластеров Kubernetes
- Сервис реляционной базы данных Amazon (Amazon RDS) для высокомасштабируемых конвейеров и хранилища метаданных
- Менеджер секретов AWS для защиты секретов, необходимых для доступа к вашим приложениям
- Простой сервис хранения Amazon (Amazon S3) для простого в использовании конвейерного хранилища артефактов.
Эти интеграции сервисов AWS с Kubeflow (как показано на следующей диаграмме) позволяют нам отделить критически важные части плоскости управления Kubeflow от Kubernetes, обеспечивая безопасную, масштабируемую, отказоустойчивую и оптимизированную по стоимости структуру.

Давайте обсудим преимущества интеграции каждой службы и их решения в области безопасности, запуска конвейеров машинного обучения и хранения.
Безопасная аутентификация пользователей Kubeflow с помощью Amazon Cognito
Облачная безопасность в AWS является наивысшим приоритетом, и мы инвестируем в тесную интеграцию безопасности Kubeflow непосредственно в сервисы безопасности AWS с общей ответственностью, такие как следующие:
- Application Load Balancer (ALB) для управления внешним трафиком
- Диспетчер сертификатов AWS (ACM) для поддержки TLS
- Роли IAM для учетных записей служб (IRSA) для детального контроля доступа на уровне Kubernetes Pod.
- Служба управления ключами AWS (AWS KMS) для управления ключами шифрования данных
- щит AWS для защиты от DDoS-атак
В этом разделе мы сосредоточимся на интеграции плоскости управления AWS Kubeflow с Amazon Cognito. Amazon Cognito устраняет необходимость в управлении и обслуживании собственного решения Dex (поставщик OpenID Connect (OIDC) с открытым исходным кодом, поддерживаемый локальным LDAP) для аутентификации пользователей и упрощает управление секретами.
Вы также можете использовать Amazon Cognito, чтобы быстро и легко добавить регистрацию пользователей, вход в систему и контроль доступа к пользовательскому интерфейсу Kubeflow. Amazon Cognito масштабируется до миллионов пользователей и поддерживает вход с помощью поставщиков социальных удостоверений (IdP), таких как Facebook, Google и Amazon, а также корпоративных IdP через SAML 2.0. Это упростит настройку Kubeflow, упростив ее работу и обеспечив многопользовательскую изоляцию.
Давайте рассмотрим поток многопользовательской аутентификации с интеграцией Amazon Cognito, ALB и ACM с Kubeflow на AWS. В рамках этой интеграции есть ряд ключевых компонентов. Amazon Cognito настроен как IdP с обратным вызовом аутентификации, настроенным для направления запроса в Kubeflow после аутентификации пользователя. В рамках настройки Kubeflow создается входной ресурс Kubernetes для управления внешним трафиком к сервису Istio Gateway. Контроллер входящего трафика AWS ALB выделяет балансировщик нагрузки для этого входящего трафика. Мы используем Amazon Route 53 настроить общедоступный DNS для зарегистрированного домена и создать сертификаты с помощью ACM, чтобы включить аутентификацию TLS в балансировщике нагрузки.
На следующей диаграмме показан типичный рабочий процесс пользователя при входе в Amazon Cognito и перенаправлении в Kubeflow в соответствующем пространстве имен.

Рабочий процесс состоит из следующих этапов:
- Пользователь отправляет HTTPS-запрос на центральную панель управления Kubeflow, размещенную за балансировщиком нагрузки. Маршрут 53 разрешает полное доменное имя в запись псевдонима ALB.
- Если файл cookie отсутствует, балансировщик нагрузки перенаправляет пользователя на конечную точку авторизации Amazon Cognito, чтобы Amazon Cognito мог аутентифицировать пользователя.
- После аутентификации пользователя Amazon Cognito отправляет его обратно в балансировщик нагрузки с кодом предоставления авторизации.
- Балансировщик нагрузки предоставляет код предоставления авторизации конечной точке токена Amazon Cognito.
- После получения действительного кода предоставления авторизации Amazon Cognito предоставляет токен идентификатора и токен доступа балансировщику нагрузки.
- После успешной аутентификации пользователя балансировщик нагрузки отправляет токен доступа в конечную точку информации о пользователе Amazon Cognito и получает заявки пользователей. Балансировщик нагрузки подписывает и добавляет пользовательские утверждения в заголовок HTTP.
x-amzn-oidc-*в формате запроса веб-токена JSON (JWT). - Запрос балансировщика нагрузки отправляется в модуль Istio Ingress Gateway.
- Используя фильтр посланников, Istio Gateway декодирует
x-amzn-oidc-dataзначение, извлекает поле электронной почты и добавляет настраиваемый заголовок HTTPkubeflow-userid, который используется уровнем авторизации Kubeflow. - Политики управления доступом на основе ресурсов Istio применяются к входящему запросу для проверки доступа к панели управления Kubeflow. Если какой-либо из них недоступен для пользователя, возвращается ответ об ошибке. Если запрос подтвержден, он перенаправляется в соответствующую службу Kubeflow и предоставляет доступ к панели управления Kubeflow.
Сохранение метаданных компонентов Kubeflow и хранилища артефактов с помощью Amazon RDS и Amazon S3
Kubeflow на AWS обеспечивает интеграцию с Сервис реляционной базы данных Amazon (Amazon RDS) в Kubeflow Pipelines и AutoML (Катиб) для постоянного хранения метаданных и Amazon S3 в Kubeflow Pipelines для постоянного хранения артефактов. Продолжим более подробно обсуждать Kubeflow Pipelines.
Kubeflow Pipelines — это платформа для создания и развертывания переносимых масштабируемых рабочих процессов машинного обучения. Эти рабочие процессы могут помочь автоматизировать сложные конвейеры машинного обучения с использованием встроенных и настраиваемых компонентов Kubeflow. Kubeflow Pipelines включает Python SDK, компилятор DSL для преобразования кода Python в статическую конфигурацию, службу Pipelines, которая запускает конвейеры из статической конфигурации, и набор контроллеров для запуска контейнеров в модулях Kubernetes, необходимых для завершения конвейера.
Метаданные Kubeflow Pipelines для экспериментов и запусков конвейера хранятся в MySQL, а артефакты, включая пакеты конвейера и метрики, хранятся в MinIO.
Как показано на следующей диаграмме, Kubeflow на AWS позволяет хранить следующие компоненты с управляемыми сервисами AWS:
- Метаданные пайплайна в Amazon RDS – Amazon RDS предоставляет масштабируемую, высокодоступную и надежную архитектуру развертывания в нескольких зонах доступности со встроенным автоматическим механизмом аварийного переключения и изменяемой емкостью для стандартной реляционной базы данных, такой как MySQL. Он управляет общими задачами администрирования базы данных без необходимости предоставления инфраструктуры или обслуживания программного обеспечения.
- Артефакты конвейера в Amazon S3 – Amazon S3 предлагает лучшую в отрасли масштабируемость, доступность данных, безопасность и производительность и может использоваться для удовлетворения ваших потребностей. требования соответствия.
Эти интеграции помогают перенести управление и обслуживание хранилища метаданных и артефактов с самоуправляемого Kubeflow на управляемые сервисы AWS, которые проще настроить, использовать и масштабировать.

Поддержка распределенных файловых систем с Amazon EFS и Amazon FSx.
Kubeflow основан на Kubernetes, который предоставляет инфраструктуру для крупномасштабной распределенной обработки данных, включая обучение и настройку больших моделей с помощью глубокой сети с миллионами или даже миллиардами параметров. Для поддержки таких распределенных систем машинного обучения Kubeflow на AWS обеспечивает интеграцию со следующими сервисами хранения:
- Амазон ЭФС – Высокопроизводительная облачная распределенная файловая система, которой можно управлять через Драйвер Amazon EFS CSI. Amazon EFS предоставляет
ReadWriteManyрежим доступа, и теперь вы можете использовать его для подключения к модулям (Jupyter, обучение модели, настройка модели), работающим в плоскости данных Kubeflow, чтобы обеспечить постоянное, масштабируемое и совместно используемое рабочее пространство, которое автоматически увеличивается и уменьшается при добавлении и удалении файлов с помощью нет необходимости в управлении. - Amazon FSx для блеска – Оптимизированная файловая система для ресурсоемких рабочих нагрузок, таких как высокопроизводительные вычисления и машинное обучение, которой можно управлять с помощью Драйвер Amazon FSx CSI. FSx for Lustre предоставляет
ReadWriteManyрежим доступа, и вы можете использовать его для кэширования данных обучения с прямым подключением к Amazon S3 в качестве резервного хранилища, которое вы можете использовать для поддержки серверов ноутбуков Jupyter или распределенного обучения, работающего в плоскости данных Kubeflow. При такой конфигурации вам не нужно передавать данные в файловую систему перед использованием тома. FSx для Lustre обеспечивает стабильные задержки менее миллисекунды и высокий уровень параллелизма, а также может масштабироваться до ТБ/с пропускной способности и миллионов операций ввода-вывода в секунду.
Варианты развертывания Kubeflow
AWS предоставляет различные варианты развертывания Kubeflow:
- Развертывание с помощью Amazon Cognito
- Развертывание с помощью Amazon RDS и Amazon S3
- Развертывание с помощью Amazon Cognito, Amazon RDS и Amazon S3
- Ванильное развертывание
Для получения подробной информации об интеграции службы и доступных надстройках для каждого из этих вариантов см. Варианты развертывания. Вы можете подобрать вариант, который лучше всего подходит для вашего варианта использования.
В следующем разделе мы рассмотрим шаги по установке дистрибутива AWS Kubeflow версии 1.4 на Amazon EKS. Затем мы используем существующий пример конвейера XGBoost, доступный на центральной панели пользовательского интерфейса Kubeflow, чтобы продемонстрировать интеграцию и использование AWS Kubeflow с Amazon Cognito, Amazon RDS и Amazon S3 с Secrets Manager в качестве надстройки.
Предпосылки
Для этого прохождения у вас должны быть следующие предпосылки:
- An Аккаунт AWS.
- Существующий кластер Amazon EKS. Это должен быть Kubernetes версии 1.19 или выше. Для автоматического создания кластера с помощью эксктлСм. Создайте кластер Amazon EKS и используйте опцию eksctl.
Установите следующие инструменты на клиентский компьютер, используемый для доступа к вашему кластеру Kubernetes. Ты можешь использовать Облако AWS9, облачная интегрированная среда разработки (IDE) для настройки кластера Kubernetes.
- Интерфейс командной строки AWS (AWS CLI) — инструмент командной строки для взаимодействия с сервисами AWS. Инструкции по установке см. Установка, обновление и удаление интерфейса командной строки AWS.
- эксктл > 0.56 — инструмент командной строки для работы с кластерами Amazon EKS, автоматизирующий множество отдельных задач.
- кубектл - Инструмент командной строки для работы с кластерами Kubernetes.
- мерзавец – Распределенное программное обеспечение для контроля версий.
- Python 3.8 + – Среда программирования Python.
- типун — Менеджер пакетов для Python.
- настроить версию 3.2.0 – Инструмент командной строки для настройки объектов Kubernetes с помощью файла настройки.
Установите Kubeflow на AWS
Настройте kubectl, чтобы вы могли подключиться к кластеру Amazon EKS:
Различные контроллеры в развертывании Kubeflow используют Роли IAM для учетных записей служб (ИРСА). Чтобы кластер мог использовать IRSA, должен существовать поставщик OIDC. Создайте поставщика OIDC и свяжите его с кластером Amazon EKS, выполнив следующую команду, если в вашем кластере ее еще нет:
Клонируйте репозиторий манифестов AWS и репозиторий манифестов Kubeflow и проверьте соответствующие ветки выпуска:
Дополнительные сведения об этих версиях см. Релизы и версии.
Настройте Amazon RDS, Amazon S3 и Secrets Manager.
Вы создаете ресурсы Amazon RDS и Amazon S3 до развертывания манифестов Kubeflow. Мы используем автоматизированные сценарии Python, которые заботятся о создании корзины S3, базы данных RDS и необходимых секретов в Secrets Manager. Он также редактирует необходимые файлы конфигурации для конвейера Kubeflow и AutoML для правильной настройки базы данных RDS и корзины S3 во время установки Kubeflow.
Создать пользователя IAM с разрешениями разрешить GetBucketLocation и доступ для чтения и записи к объектам в корзине S3, где вы хотите хранить артефакты Kubeflow. Использовать AWS_ACCESS_KEY_ID и AWS_SECRET_ACCESS_KEY пользователя IAM в следующем коде:
Настройте Amazon Cognito в качестве поставщика аутентификации.
В этом разделе мы создадим собственный домен в Route 53 и ALB для маршрутизации внешнего трафика на шлюз Kubeflow Istio. Мы используем ACM для создания сертификата для включения аутентификации TLS в ALB и Amazon Cognito для поддержки пула пользователей и управления аутентификацией пользователей.
Подставьте следующие значения в
- маршрут53.rootDomain.name – Зарегистрированный домен. Предположим, что этот домен
example.com. - маршрут53.rootDomain.hostedZoneId – Если ваш домен управляется в Route53, введите идентификатор размещенной зоны, указанный в сведениях о размещенной зоне. Пропустите этот шаг, если ваш домен управляется другим провайдером домена.
- маршрут53.поддомен.имя – Имя поддомена, на котором вы хотите разместить Kubeflow (например,
platform.example.com). Для получения дополнительной информации о поддоменах см. Развертывание Kubeflow с AWS Cognito в качестве IdP. - имя_кластера – Имя кластера и место, где развернут Kubeflow.
- кластер.регион – Регион кластера, в котором развернут Kubeflow (например,
us-west-2). - cognitoUserpool.name – Имя пула пользователей Amazon Cognito (например,
kubeflow-users).
Файл конфигурации выглядит примерно так:
Запустите скрипт для создания ресурсов:
Скрипт обновляет config.yaml файл с именами ресурсов, идентификаторами и ARN, которые он создал. Это выглядит примерно как следующий код:
Создание манифестов и развертывание Kubeflow
Разверните Kubeflow с помощью следующей команды:
Обновите домен с адресом ALB
Развертывание создает балансировщик нагрузки приложения AWS, управляемый входом. Мы обновляем записи DNS для поддомена в Route 53 с помощью DNS балансировщика нагрузки. Выполните следующую команду, чтобы проверить, подготовлен ли балансировщик нагрузки (это займет около 3–5 минут):
Если же линия индикатора ADDRESS поле пусто через несколько минут, проверьте журналы alb-ingress-controller. Инструкции см. ALB не может предоставить.
Когда балансировщик нагрузки подготовлен, скопируйте DNS-имя балансировщика нагрузки и замените адрес для kubeflow.alb.dns in ${kubeflow_manifest_dir}/tests/e2e/utils/cognito_bootstrap/config.yaml. Раздел Kubeflow файла конфигурации выглядит следующим образом:
Запустите следующий сценарий, чтобы обновить записи DNS для поддомена в Route 53 с помощью DNS подготовленного балансировщика нагрузки:
УСТРАНЕНИЕ НЕПОЛАДОК
Если у вас возникнут какие-либо проблемы во время установки, см. руководство по устранению неполадок или начните заново, следуя разделу «Очистка» в этом блоге.
Пошаговое руководство по варианту использования
Теперь, когда мы завершили установку необходимых компонентов Kubeflow, давайте посмотрим на них в действии, используя один из существующих примеров, предоставленных Kubeflow Pipelines на панели инструментов.
Доступ к информационной панели Kubeflow с помощью Amazon Cognito
Для начала давайте получим доступ к панели управления Kubeflow. Поскольку мы использовали Amazon Cognito в качестве IdP, используйте информацию, представленную в официальный файл README. Сначала мы создадим несколько пользователей на консоли Amazon Cognito. Это пользователи, которые будут входить в центральную панель управления. Следующий, создать профиль для пользователя, которого вы создали. Затем вы сможете получить доступ к панели инструментов через страницу входа по адресу https://kubeflow.platform.example.com.

На следующем снимке экрана показана панель управления Kubeflow.

Запустить конвейер
На панели инструментов Kubeflow выберите Трубопроводы в названии навигации. Вы должны увидеть четыре примера, предоставленные Kubeflow Pipelines, которые вы можете запустить напрямую, чтобы изучить различные функции Pipelines.
В этом посте мы используем пример XGBoost под названием [Demo] XGBoost — итеративное обучение модели. Вы можете найти исходный код на GitHub. Это простой конвейер, который использует существующий XGBoost/Train и XGBoost/Predict Компоненты конвейера Kubeflow для итеративного обучения модели до тех пор, пока метрики не будут считаться хорошими на основе указанных метрик.
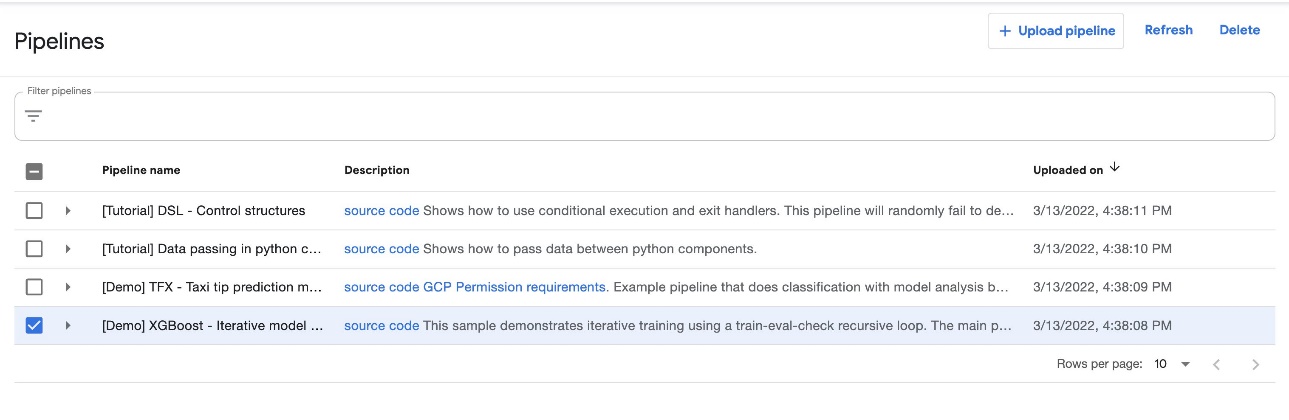
Чтобы запустить конвейер, выполните следующие шаги:
- Выберите трубопровод и выберите Создать эксперимент.

- Под Сведения об эксперименте, введите имя (для этого сообщения
demo-blog) и необязательное описание. - Выберите Следующая.

- Под Детали запуска¸ выберите свой конвейер и версию конвейера.
- Что касается Название запускавведите имя.
- Что касается Эксперимент, выберите созданный вами эксперимент.
- Что касается Тип запуска, наведите на Единовременный.
- Выберите Start.

После запуска конвейера вы должны увидеть завершение компонентов (в течение нескольких секунд). На этом этапе вы можете выбрать любой из готовых компонентов, чтобы увидеть более подробную информацию.

Доступ к артефактам в Amazon S3
При развертывании Kubeflow мы указали, что Kubeflow Pipelines должен использовать Amazon S3 для хранения своих артефактов. Сюда входят все артефакты вывода конвейера, кэшированные запуски и графики конвейера — все это можно затем использовать для расширенных визуализаций и оценки производительности.
После завершения конвейера вы сможете увидеть артефакты в корзине S3, созданной во время установки. Чтобы убедиться в этом, выберите любой завершенный компонент пайплайна и проверьте Ввод, вывод раздел по умолчанию График вкладка URL-адреса артефактов должны указывать на корзину S3, которую вы указали во время развертывания.
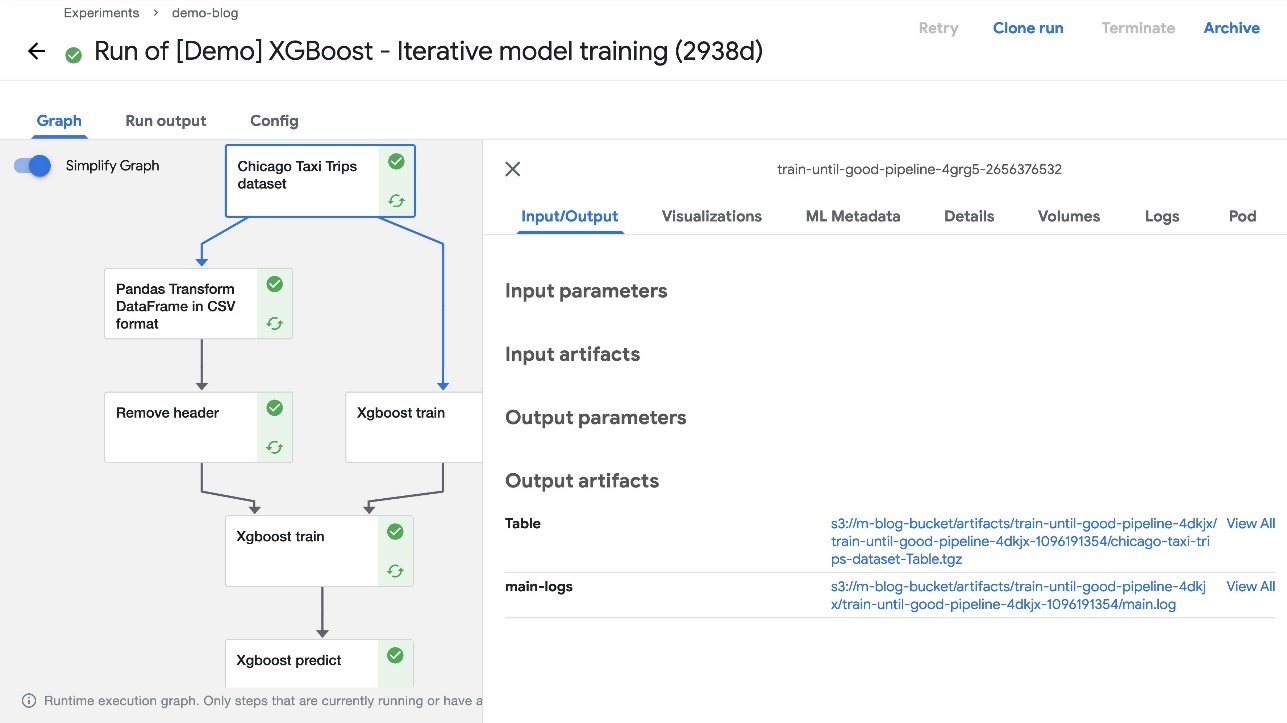
Чтобы убедиться, что ресурсы были добавлены в Amazon S3, мы также можем проверить корзину S3 в нашей учетной записи AWS через консоль Amazon S3.

На следующем снимке экрана показаны наши файлы.
Проверка метаданных машинного обучения в Amazon RDS
Мы также интегрировали Kubeflow Pipelines с Amazon RDS во время развертывания, что означает, что все метаданные конвейера должны храниться в Amazon RDS. Сюда входит любая информация о времени выполнения, например состояние задачи, доступность артефактов, настраиваемые свойства, связанные с запуском или артефактами, и многое другое.
Чтобы проверить интеграцию с Amazon RDS, выполните действия, описанные в официальный файл README. В частности, выполните следующие шаги:
- Получите имя пользователя и пароль Amazon RDS из секрета, созданного во время установки:
- Используйте эти учетные данные для подключения к Amazon RDS из кластера:
- Когда откроется приглашение MySQL, мы можем проверить
mlpipelinesбазу данных следующим образом: - Теперь мы можем прочитать содержимое определенных таблиц, чтобы убедиться, что мы видим метаданные об экспериментах, в которых запускались конвейеры:
Убирать
Чтобы удалить Kubeflow и удалить созданные вами ресурсы AWS, выполните следующие действия:
- Удалите входящий и управляемый входящим потоком балансировщик нагрузки, выполнив следующую команду:
- Удалите остальные компоненты Kubeflow:
- Удалите ресурсы AWS, созданные скриптами:
- Ресурсы, созданные для интеграции Amazon RDS и Amazon S3. Убедитесь, что у вас есть файл конфигурации, созданный сценарием в
${kubeflow_manifest_dir}/tests/e2e/utils/rds-s3/metadata.yaml: - Ресурсы, созданные для интеграции с Amazon Cognito. Убедитесь, что у вас есть файл конфигурации, созданный сценарием в
${kubeflow_manifest_dir}/tests/e2e/utils/cognito_bootstrap/config.yaml:
- Ресурсы, созданные для интеграции Amazon RDS и Amazon S3. Убедитесь, что у вас есть файл конфигурации, созданный сценарием в
- Если вы создали выделенный кластер Amazon EKS для Kubeflow с помощью eksctl, вы можете удалить его с помощью следующей команды:
Обзор
В этом посте мы подчеркнули ценность, которую Kubeflow на AWS обеспечивает за счет встроенной интеграции сервисов, управляемых AWS, для безопасных, масштабируемых и готовых к корпоративному использованию рабочих нагрузок AI и ML. Вы можете выбрать один из нескольких вариантов развертывания для установки Kubeflow на AWS с различными интеграциями сервисов. Пример использования в этом посте продемонстрировал интеграцию Kubeflow с Amazon Cognito, Secrets Manager, Amazon RDS и Amazon S3. Чтобы начать работу с Kubeflow на AWS, ознакомьтесь с доступными вариантами развертывания, интегрированными с AWS, в Kubeflow на AWS.
Начиная с версии 1.3, вы можете следовать Репозиторий лабораторий AWS для отслеживания всех вкладов AWS в Kubeflow. Вы также можете найти нас на Kubeflow #AWS Slack-канал; ваши отзывы помогут нам определить приоритеты следующих функций для участия в проекте Kubeflow.
Об авторах
 Канвалджит Хурми является специалистом по архитектуре решений AI/ML в Amazon Web Services. Он работает с продуктом AWS, инженерами и клиентами, предоставляя рекомендации и техническую помощь, помогая им повысить ценность своих гибридных решений машинного обучения при использовании AWS. Kanwaljit специализируется на помощи клиентам с контейнерными приложениями и приложениями машинного обучения.
Канвалджит Хурми является специалистом по архитектуре решений AI/ML в Amazon Web Services. Он работает с продуктом AWS, инженерами и клиентами, предоставляя рекомендации и техническую помощь, помогая им повысить ценность своих гибридных решений машинного обучения при использовании AWS. Kanwaljit специализируется на помощи клиентам с контейнерными приложениями и приложениями машинного обучения.
 Мегна Байджал — инженер-программист с искусственным интеллектом AWS, упрощающим пользователям адаптацию своих рабочих нагрузок машинного обучения к AWS путем создания продуктов и платформ машинного обучения, таких как контейнеры для глубокого обучения, AMI для глубокого обучения, контроллеры AWS для Kubernetes (ACK) и Kubeflow на AWS. . Вне работы она любит читать, путешествовать и заниматься живописью.
Мегна Байджал — инженер-программист с искусственным интеллектом AWS, упрощающим пользователям адаптацию своих рабочих нагрузок машинного обучения к AWS путем создания продуктов и платформ машинного обучения, таких как контейнеры для глубокого обучения, AMI для глубокого обучения, контроллеры AWS для Kubernetes (ACK) и Kubeflow на AWS. . Вне работы она любит читать, путешествовать и заниматься живописью.
 Сурадж Кота инженер-программист, специализирующийся на инфраструктуре машинного обучения. Он создает инструменты, позволяющие легко приступить к работе и масштабировать рабочую нагрузку машинного обучения на AWS. Он работал над контейнерами глубокого обучения AWS, AMI глубокого обучения, операторами SageMaker для Kubernetes и другими интеграциями с открытым исходным кодом, такими как Kubeflow.
Сурадж Кота инженер-программист, специализирующийся на инфраструктуре машинного обучения. Он создает инструменты, позволяющие легко приступить к работе и масштабировать рабочую нагрузку машинного обучения на AWS. Он работал над контейнерами глубокого обучения AWS, AMI глубокого обучения, операторами SageMaker для Kubernetes и другими интеграциями с открытым исходным кодом, такими как Kubeflow.
- Коинсмарт. Лучшая в Европе биржа биткойнов и криптовалют.
- Платоблокчейн. Интеллект метавселенной Web3. Расширение знаний. БЕСПЛАТНЫЙ ДОСТУП.
- КриптоХок. Альткоин Радар. Бесплатная пробная версия.
- Источник: https://aws.amazon.com/blogs/machine-learning/build-and-deploy-a-scalable-machine-learning-system-on-kubernetes-with-kubeflow-on-aws/
- "
- 10
- 100
- 420
- 7
- О нас
- доступ
- Учетная запись
- Действие
- Дополнительный
- адрес
- Администратор
- администрация
- филиалы
- AI
- Все
- уже
- Amazon
- Amazon Web Services
- Другой
- Применение
- Приложения
- соответствующий
- архитектура
- около
- Юрист
- подлинности
- проверяет подлинность
- Аутентификация
- разрешение
- автоматизировать
- Автоматизированный
- автоматы
- свободных мест
- доступен
- AWS
- становиться
- Преимущества
- ЛУЧШЕЕ
- миллиарды
- Блог
- граница
- строить
- Строительство
- строит
- встроенный
- возможности
- Пропускная способность
- заботится
- случаев
- CD
- сертификат
- сертификаты
- сложные
- Оформить заказ
- Выберите
- требования
- класс
- код
- Общий
- комплектующие
- комплекс
- компонент
- компьютер
- вычисление
- Конфигурация
- Свяжитесь
- связь
- Консоли
- Контейнеры
- содержит
- содержание
- продолжать
- способствовать
- контроль
- контроллер
- авторское право
- может
- Создайте
- создали
- создает
- Создающий
- создание
- Полномочия
- критической
- изготовленный на заказ
- Клиенты
- приборная панель
- данным
- обработка данных
- наука о данных
- База данных
- DDoS
- преданный
- Спрос
- демонстрировать
- убивают
- развертывание
- развернуть
- развертывание
- развертывание
- развертывания
- развертывает
- Проект
- подробность
- подробнее
- Развитие
- Dex
- различный
- направлять
- непосредственно
- обсуждать
- распределенный
- распределение
- DNS
- не
- домен
- легко
- Простой в использовании
- эхо
- включить
- шифрование
- Конечная точка
- инженер
- Проект и
- Enter
- Предприятие
- Окружающая среда
- оценка
- События
- пример
- существующий
- опыт
- эксперимент
- Больше
- что его цель
- Ошибка
- Особенности
- Обратная связь
- финансовый
- First
- соответствовать
- поток
- Фокус
- фокусируется
- следовать
- после
- формат
- найденный
- свежий
- получающий
- идти
- GitHub
- хорошо
- Расти
- Рост
- помощь
- помощь
- помогает
- здесь
- High
- высший
- Выделенные
- очень
- хостинг
- HTTPS
- Гибридный
- Личность
- Влияние
- осуществлять
- улучшать
- Инк
- включает в себя
- В том числе
- расширились
- individual
- отрасли
- info
- информация
- Инфраструктура
- устанавливать
- интегрированный
- интеграции.
- интеграций
- инвестирование
- изоляция
- вопросы
- IT
- саму трезвость
- Джобс
- хранение
- Основные
- Labs
- язык
- большой
- запустили
- изучение
- Подтяжка лица
- линия
- загрузка
- локальным
- машина
- обучение с помощью машины
- поддерживать
- ДЕЛАЕТ
- Создание
- управлять
- управляемого
- управление
- менеджер
- Метрика
- миллионы
- ML
- модель
- Модели
- Мониторинг
- БОЛЕЕ
- самых
- имена
- натуральный
- Навигация
- сеть
- сеть
- узлы
- ноутбук
- номер
- Предложения
- открытый
- с открытым исходным кодом
- Откроется
- Операторы
- оптимизированный
- Опция
- Опции
- Другое
- собственный
- Пароль
- производительность
- Платформа
- Платформы
- Точка
- сборах
- бассейн
- представить
- приоритет
- обработка
- Продукт
- Продукция
- Программирование
- Проект
- для защиты
- обеспечивать
- приводит
- обеспечение
- что такое варган?
- быстро
- достигать
- Reading
- причины
- запись
- зарегистрированный
- освободить
- запросить
- обязательный
- Требования
- ресурс
- Полезные ресурсы
- ответ
- ОТДЫХ
- дорога
- Run
- Бег
- Масштабируемость
- масштабируемые
- Шкала
- масштабирование
- Наука
- SDK
- SEC / КОМИССИЯ ПО ЦЕННЫМ БУМАГАМ И БИРЖАМ
- секунды
- безопасный
- безопасность
- Serverless
- обслуживание
- Услуги
- набор
- установка
- Акции
- Признаки
- просто
- Размер
- слабина
- спать
- So
- Соцсети
- Software
- Инженер-программист
- твердый
- Решение
- Решения
- некоторые
- удалось
- исходный код
- специалист
- специализированный
- специализируется
- конкретно
- Этап
- Начало
- и политические лидеры
- начинается
- Область
- Статус:
- диск
- магазин
- Успешно
- поддержка
- Поддержка
- система
- системы
- задачи
- Технический
- Источник
- Через
- время
- знак
- инструментом
- инструменты
- топ
- трек
- трафик
- Обучение
- перевод
- Переводы
- перевозки
- Путешествие
- ui
- Обновление ПО
- Updates
- us
- использование
- пользователей
- подтверждено
- ценностное
- разнообразие
- различный
- проверить
- видение
- объем
- Web
- веб-сервисы
- КТО
- в
- без
- Работа
- работавший
- работает
- работает