Очистка данных — очень важный и важный шаг в вашем проекте по науке о данных. Успех машинной модели зависит от того, как вы предварительно обработаете данные. Если вы недооцените и пропустите предварительную обработку вашего набора данных, модель не будет работать должным образом, и вы потеряете много времени на поиски того, почему она работает не так, как вы ожидаете.
В последнее время я начал создавать шпаргалки, чтобы ускорить свою деятельность по науке о данных, в частности сводку с основами очистки данных. В этом посте и чит-лист, я собираюсь показать пять различных аспектов, которые характеризуют этапы предварительной обработки в вашем проекте по науке о данных.

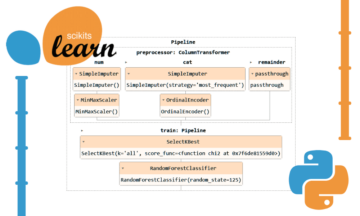
В этой шпаргалке, мы переходим от обнаружения и обработки отсутствующих данных, работы с дубликатами и поиска решений для дубликатов, обнаружения выбросов, кодирования меток и горячего кодирования категориальных признаков к преобразованиям, таким как нормализация MinMax и стандартная нормализация. Более того, в этом руководстве для отображения графиков используются методы, предоставляемые тремя самыми популярными библиотеками Python: Pandas, Scikit-Learn и Seaborn.
Изучение этих приемов Python поможет вам извлечь как можно больше информации из набора данных, и, следовательно, модель машинного обучения сможет работать лучше, обучаясь на чистом и предварительно обработанном входе.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- Платоблокчейн. Интеллект метавселенной Web3. Расширение знаний. Доступ здесь.
- Источник: https://www.kdnuggets.com/2023/02/data-cleaning-python-cheat-sheet.html?utm_source=rss&utm_medium=rss&utm_campaign=data-cleaning-with-python-cheat-sheet
- a
- в состоянии
- активно
- и
- аспекты
- Основы
- начал
- Лучшая
- охарактеризовать
- Уборка
- вследствие этого
- Создайте
- критической
- данным
- наука о данных
- занимавшийся
- зависит
- обнаружение
- различный
- отображать
- не
- дубликаты
- ожидать
- использует
- извлечение
- Особенности
- обнаружение
- от
- Go
- будет
- инструкция
- Управляемость
- помощь
- Как
- HTTPS
- важную
- in
- информация
- вход
- IT
- КДнаггетс
- этикетка
- изучение
- библиотеки
- терять
- серия
- машина
- обучение с помощью машины
- методы
- отсутствующий
- модель
- БОЛЕЕ
- самых
- Самые популярные
- панд
- особый
- выполнять
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- Популярное
- возможное
- После
- Проект
- при условии
- Питон
- Наука
- scikit учиться
- рожденное море
- поиск
- показывать
- Решения
- скорость
- стандарт
- Шаг
- Шаги
- успех
- такие
- РЕЗЮМЕ
- Ассоциация
- Основы
- три
- время
- в
- преобразований
- трюки
- понимать
- будете
- Работа
- бы
- ВАШЕ
- зефирнет