Исследования последних нескольких лет показали, что модели машинного обучения (ML) уязвимы для состязательные материалы, где противник может создавать входные данные для стратегического изменения выходных данных модели (в классификация изображений, распознавание речиили обнаружение мошенничества). Например, представьте, что вы развернули модель, которая идентифицирует ваших сотрудников на основе изображений их лиц. Как показано в технической документации Присоединяйтесь к преступлению: настоящие и скрытые атаки на современное распознавание лиц, злоумышленники могут вносить незаметные, но тщательно разработанные изменения в свое изображение и обманывать модель, чтобы аутентифицировать их как других сотрудников. Очевидно, что такие враждебные входные данные, особенно если их много, могут иметь разрушительные последствия для бизнеса.
В идеале мы хотим обнаруживать каждый раз, когда в модель отправляются враждебные входные данные, чтобы количественно определить, как враждебные входные данные влияют на вашу модель и бизнес. С этой целью широкий класс методов анализирует входные данные отдельных моделей для проверки поведения злоумышленников. Однако активные исследования состязательного ОД привели к появлению все более изощренных состязательных входных данных, многие из которых, как известно, делают обнаружение неэффективным. Причина этого недостатка заключается в том, что на основе отдельных входных данных трудно сделать вывод о том, является ли он враждебным или нет. С этой целью новый класс методов фокусируется на проверках на уровне распределения путем одновременного анализа нескольких входных данных. Основная идея этих новых методов заключается в том, что одновременное рассмотрение нескольких входных данных обеспечивает более мощный статистический анализ, который невозможен при использовании отдельных входных данных. Однако перед лицом решительного противника, хорошо знающего модель, даже эти передовые методы обнаружения могут потерпеть неудачу.
Однако мы можем победить даже этих решительных противников, снабдив методы защиты дополнительной информацией. В частности, вместо того, чтобы просто анализировать входные данные модели, анализ скрытых представлений, собранных с промежуточных слоев в глубокой нейронной сети, значительно усиливает защиту.
В этом посте мы расскажем вам, как обнаруживать враждебные входные данные с помощью Монитор моделей Amazon SageMaker и Amazon SageMaker Отладчик для модели классификации изображений, размещенной на Создатель мудреца Амазонки.
Чтобы воспроизвести различные шаги и результаты, перечисленные в этом посте, клонируйте репозиторий. обнаружение враждебных образцов с использованием sagemaker в свой экземпляр блокнота Amazon SageMaker и запустите блокнот.
Обнаружение враждебных входных данных
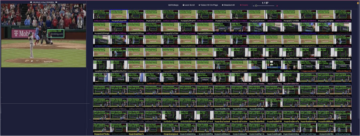
Мы покажем вам, как обнаруживать враждебные входные данные, используя представления, собранные из глубокой нейронной сети. Следующие четыре изображения показывают исходное тренировочное изображение слева (взято из набора данных Tiny ImageNet) и три изображения, созданные с помощью атаки с прогнозируемым градиентным спуском (PGD) [1] с различными параметрами возмущения ϵ. Здесь использовалась модель ResNet18. Параметр ϵ определяет количество враждебного шума, добавляемого к изображениям. Исходное изображение (слева) правильно предсказано как класс 67 (goose). Злоумышленно измененные изображения 2, 3 и 4 неверно предсказаны как класс 51 (mantis) по модели ResNet18. Мы также можем видеть, что изображения, созданные с малым ϵ, перцептивно неотличимы от исходного входного изображения.

Далее мы создаем набор обычных и враждебных изображений и используем Встраивание t-распределенных стохастических соседей (t-SNE [2]), чтобы визуально сравнить их распределения. t-SNE — это метод уменьшения размерности, который отображает многомерные данные в 2- или 3-мерное пространство. Каждая точка данных на следующем изображении представляет входное изображение. Оранжевые точки данных представляют собой нормальные входные данные, взятые из тестового набора, а синие точки данных указывают на соответствующие враждебные изображения, сгенерированные с эпсилон 0.003. Если нормальные и враждебные входные данные различимы, то можно ожидать отдельные кластеры в визуализации t-SNE. Поскольку оба принадлежат одному и тому же кластеру, это означает, что метод обнаружения, ориентированный исключительно на изменения в распределении входных данных модели, не может различить эти входные данные.

Давайте подробнее рассмотрим представления слоев, созданные разными слоями в модели ResNet18. ResNet18 состоит из 18 слоев; на следующем изображении мы визуализируем вложения t-SNE для представлений шести из этих слоев.

Как показано на предыдущем рисунке, естественные и враждебные входные данные становятся более различимыми для более глубоких уровней модели ResNet18.
Основываясь на этих наблюдениях, мы используем статистический метод, который измеряет различимость с проверкой гипотез. Метод состоит из двухвыборочный тест через максимальное среднее расхождение (ММД). MMD — это метрика на основе ядра для измерения сходства между двумя дистрибутивами, генерирующими данные. Тест с двумя выборками берет два набора, которые содержат входные данные, взятые из двух распределений, и определяет, являются ли эти распределения одинаковыми. Мы сравниваем распределение входных данных, наблюдаемых в обучающих данных, и сравниваем его с распределением входных данных, полученных во время вывода.
Наш метод использует эти входные данные для оценки p-значения с использованием MMD. Если p-значение превышает порог значимости для конкретного пользователя (в нашем случае 5%), мы делаем вывод, что оба распределения различны. Порог настраивает компромисс между ложными положительными и ложными отрицательными результатами. Более высокий порог, такой как 10%, снижает процент ложноотрицательных результатов (меньше случаев, когда оба распределения были разными, но тест этого не показал). Однако это также приводит к большему количеству ложных срабатываний (тест показывает, что оба распределения различны, даже если это не так). С другой стороны, более низкий порог, например 1%, приводит к меньшему количеству ложноположительных результатов, но к большему количеству ложноотрицательных результатов.
Вместо того, чтобы применять этот метод исключительно к необработанным входным данным модели (изображениям), мы используем скрытые представления, созданные промежуточными слоями нашей модели. Чтобы учесть его вероятностный характер, мы применяем проверку гипотезы 100 раз на 100 случайно выбранных естественных входных данных и 100 случайно выбранных враждебных входных данных. Затем мы сообщаем уровень обнаружения как процент тестов, которые привели к событию обнаружения в соответствии с нашим порогом значимости 5%. Более высокая скорость обнаружения является более убедительным признаком того, что эти два распределения различны. Эта процедура дает нам следующие показатели обнаружения:
- Слой 1: 3%
- Слой 4: 7%
- Слой 8: 84%
- Слой 12: 95%
- Слой 14: 100%
- Слой 15: 100%
В начальных слоях скорость обнаружения довольно низкая (менее 10%), но возрастает до 100% в более глубоких слоях. Используя статистический тест, метод может уверенно обнаруживать враждебные входные данные в более глубоких слоях. Часто бывает достаточно просто использовать представления, сгенерированные предпоследним слоем (последним слоем перед классификационным слоем в модели). Для более сложных враждебных входных данных полезно использовать представления из других слоев и агрегировать уровни обнаружения.
Обзор решения
В предыдущем разделе мы увидели, как обнаруживать враждебные входные данные, используя представления из предпоследнего слоя. Далее мы покажем, как автоматизировать эти тесты в SageMaker с помощью Model Monitor и Debugger. В этом примере мы сначала обучаем модель ResNet18 для классификации изображений на крошечном наборе данных ImageNet. Затем мы развертываем модель в SageMaker и создаем собственное расписание монитора модели, которое запускает статистический тест. После этого мы запускаем вывод с нормальными и состязательными входными данными, чтобы увидеть, насколько эффективен метод.
Захват тензоров с помощью отладчика
Во время обучения модели мы используем отладчик для захвата представлений, созданных предпоследним слоем, которые позже используются для получения информации о распределении нормальных входных данных. Отладчик — это функция SageMaker, которая позволяет собирать и анализировать информацию, такую как параметры модели, градиенты и активации во время обучения модели. Эти тензоры параметров, градиента и активации загружаются в Простой сервис хранения Amazon (Amazon S3) во время обучения. Вы можете настроить правила, которые анализируют их на наличие таких проблем, как переоснащение и исчезновение градиентов. В нашем случае мы хотим захватить только предпоследний слой модели (.*avgpool_output) и выходные данные модели (прогнозы). Мы указываем конфигурацию ловушки отладчика, которая определяет регулярное выражение для собираемых представлений слоев. Мы также указываем save_interval который указывает отладчику собирать эти данные на этапе проверки каждые 100 проходов вперед. См. следующий код:
Запустите обучение SageMaker
Передаем конфигурацию Debugger в оценщик SageMaker и запускаем обучение:
Развертывание модели классификации изображений
После завершения обучения модели мы развертываем модель в качестве конечной точки в SageMaker. Мы указываем сценарий вывода это определяет model_fn и transform_fn функции. Эти функции определяют, как модель загружается и как входящие данные должны быть предварительно обработаны для выполнения вывода модели. В нашем случае мы разрешаем отладчику собирать соответствующие данные во время логического вывода. в model_fn мы указываем ловушку отладчика и save_config который указывает, что для каждого запроса на вывод записываются входные данные модели (изображения), выходные данные модели (прогнозы) и предпоследний слой (.*avgpool_output). Затем мы регистрируем крючок на модели. См. следующий код:
Теперь разворачиваем модель, что мы можем сделать из блокнота двумя способами. Мы можем либо позвонить pytorch_estimator.deploy() или создайте модель PyTorch, указывающую на файлы артефактов модели в Amazon S3, созданные с помощью обучающего задания SageMaker. В этом посте мы делаем последнее. Это позволяет нам передавать переменные среды в контейнер Docker, который создается и развертывается SageMaker. Нам нужна переменная окружения tensors_output чтобы сообщить сценарию, куда загружать тензоры, собранные отладчиком SageMaker Debugger во время логического вывода. См. следующий код:
Затем мы развертываем предиктор на экземпляре типа ml.m5.xlarge:
Создание пользовательского расписания монитора модели
Когда конечная точка запущена и работает, мы создаем индивидуальное расписание монитора модели. Это Задание обработки SageMaker который работает с периодическим интервалом (например, ежечасно или ежедневно) и анализирует данные логического вывода. Model Monitor предоставляет предварительно настроенный контейнер, который анализирует и обнаруживает дрейф данных. В нашем случае мы хотим настроить его так, чтобы он извлекал данные отладчика и запускал двухвыборочный тест MMD для извлеченных представлений слоев.
Чтобы настроить его, мы сначала определяем объект Model Monitor, который указывает, на каком типе экземпляра будут выполняться эти задания, и расположение нашего пользовательского контейнера Model Monitor:
Мы хотим запускать это задание ежечасно, поэтому указываем CronExpressionGenerator.hourly() и места вывода, куда загружаются результаты анализа. Для этого нам нужно определить ProcessingOutput для вывода обработки SageMaker:
Давайте посмотрим поближе на то, что работает в нашем пользовательском контейнере Model Monitor. Мы создаем сценарий оценки, который загружает данные, захваченные отладчиком. Мы также создаем пробный объект, что позволяет нам получать доступ, запрашивать и фильтровать данные, сохраненные отладчиком. С пробным объектом мы можем повторять шаги, сохраненные на этапах вывода и обучения. trial.steps(mode).
Сначала мы получаем выходные данные модели (trial.tensor("ResNet_output_0")), а также предпоследний слой (trial.tensor_names(regex=".*avgpool_output")). Мы делаем это на этапах вывода и проверки обучения (modes.EVAL и modes.PREDICT). Тензоры на этапе проверки служат оценкой нормального распределения, которую мы затем используем для сравнения распределения данных вывода. Мы создали класс ЛАДИС (Обнаружение враждебных входных распределений с помощью послойной статистики). Этот класс предоставляет соответствующие функции для выполнения двухвыборочного теста. Он берет список тензоров из этапов вывода и проверки и запускает тест с двумя выборками. Он возвращает уровень обнаружения, который представляет собой значение от 0 до 100%. Чем выше значение, тем более вероятно, что данные вывода следуют другому распределению. Кроме того, мы вычисляем оценку для каждой выборки, которая указывает, насколько вероятно, что выборка является состязательной, и регистрируются 100 лучших выборок, чтобы пользователи могли их дополнительно проверить. См. следующий код:
Тест против враждебных входных данных
Теперь, когда наше пользовательское расписание Model Monitor развернуто, мы можем получить некоторые результаты логического вывода.
Сначала мы запускаем данные из набора удержания, а затем — со враждебными входными данными:
Затем мы можем проверить отображение Model Monitor в Студия Amazon SageMaker или использование Amazon CloudWatch журналы, чтобы узнать, была ли обнаружена проблема.

Затем мы используем враждебные входные данные для модели, размещенной в SageMaker. Мы используем тестовый набор данных Tiny ImageNet и применяем атаку PGD, которая вносит возмущения на уровне пикселей, так что модель не распознает правильные классы. На следующих изображениях в левой колонке показаны два исходных тестовых изображения, в средней колонке показаны их искаженные версии, а в правой колонке показана разница между обоими изображениями.

Теперь мы можем проверить состояние монитора модели и увидеть, что некоторые изображения вывода были взяты из другого дистрибутива.

Результаты и действия пользователя
Пользовательское задание Model Monitor определяет баллы для каждого запроса на вывод, которые показывают, насколько вероятно, что образец является состязательным в соответствии с тестом MMD. Эти оценки собираются для всех запросов на вывод. Их оценка с соответствующим номером шага отладчика записывается в файл JSON и загружается в Amazon S3. После завершения задания мониторинга модели мы загружаем файл JSON, получаем номера шагов и используем отладчик для получения соответствующих входных данных модели для этих шагов. Это позволяет нам проверять изображения, которые были обнаружены как враждебные.
В следующем блоке кода отображаются первые два изображения, которые были идентифицированы как наиболее вероятно враждебные:
В нашем тестовом прогоне мы получаем следующий результат. Изображение медузы было ошибочно предсказано как апельсин, а изображение верблюда — как панда. Очевидно, что модель потерпела неудачу на этих входных данных и даже не предсказала аналогичный класс изображений, например золотую рыбку или лошадь. Для сравнения мы также показываем соответствующие природные образцы из тестовой выборки с правой стороны. Мы можем заметить, что случайные возмущения, внесенные злоумышленником, хорошо видны на фоне обоих изображений.


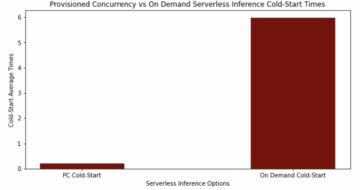
Пользовательское задание Model Monitor публикует уровень обнаружения в CloudWatch, поэтому мы можем исследовать, как этот уровень менялся с течением времени. Значительное изменение между двумя точками данных может указывать на то, что злоумышленник пытался обмануть модель в определенный период времени. Кроме того, вы также можете отобразить количество запросов на вывод, обрабатываемых в каждом задании Model Monitor, и базовую скорость обнаружения, которая вычисляется по набору данных проверки. Базовая скорость обычно близка к 0 и служит только в качестве показателя сравнения.
На следующем снимке экрана показаны метрики, созданные нашими тестовыми прогонами, в которых выполнялись три задания мониторинга моделей в течение 3 часов. Каждое задание обрабатывает примерно 200–300 запросов на вывод за раз. Уровень обнаружения составляет 100% между 5:00 и 6:00, а затем падает.

Кроме того, мы также можем проверять распределения представлений, созданных промежуточными слоями модели. С помощью Debugger мы можем получить доступ к данным на этапе проверки задания обучения и тензорам на этапе вывода и использовать t-SNE для визуализации их распределения для определенных прогнозируемых классов. См. следующий код:
В нашем тестовом примере мы получаем следующую визуализацию t-SNE для второго класса изображений. Мы можем заметить, что враждебные выборки сгруппированы иначе, чем естественные.

Обзор
В этом посте мы показали, как использовать тест с двумя выборками, используя максимальное среднее несоответствие для обнаружения враждебных входных данных. Мы продемонстрировали, как можно развернуть такие механизмы обнаружения с помощью Debugger и Model Monitor. Этот рабочий процесс позволяет отслеживать ваши модели, размещенные в SageMaker, в масштабе и автоматически обнаруживать враждебные входные данные. Чтобы узнать больше об этом, посетите наш Репо GitHub.
Рекомендации
[1] Александр Мадри, Александр Макелов, Людвиг Шмидт, Димитрис Ципрас и Адриан Владу. На пути к моделям глубокого обучения, устойчивым к атакам со стороны противника. В Международная конференция по обучению представительств, 2018.
[2] Лоренс ван дер Маатен и Джеффри Хинтон. Визуализация данных с использованием t-SNE. Журнал исследований машинного обучения, 9: 2579–2605, 2008 г. URL-адрес. http://www.jmlr.org/papers/v9/vandermaaten08a.html.
Об авторах
 Натали Раушмайр — старший научный сотрудник AWS, где она помогает клиентам разрабатывать приложения для глубокого обучения.
Натали Раушмайр — старший научный сотрудник AWS, где она помогает клиентам разрабатывать приложения для глубокого обучения.
 Йигиткан Кая является аспирантом пятого курса Университета Мэриленда и стажером прикладного ученого в AWS, работающим над безопасностью машинного обучения и приложениями машинного обучения для обеспечения безопасности.
Йигиткан Кая является аспирантом пятого курса Университета Мэриленда и стажером прикладного ученого в AWS, работающим над безопасностью машинного обучения и приложениями машинного обучения для обеспечения безопасности.
 Билал Зафар — ученый-прикладник в AWS, работающий над справедливостью, объяснимостью и безопасностью в машинном обучении.
Билал Зафар — ученый-прикладник в AWS, работающий над справедливостью, объяснимостью и безопасностью в машинном обучении.
 Сергул Айдоре — старший научный сотрудник AWS, работающий над конфиденциальностью и безопасностью в машинном обучении.
Сергул Айдоре — старший научный сотрудник AWS, работающий над конфиденциальностью и безопасностью в машинном обучении.
- Коинсмарт. Лучшая в Европе биржа биткойнов и криптовалют.
- Платоблокчейн. Интеллект метавселенной Web3. Расширение знаний. БЕСПЛАТНЫЙ ДОСТУП.
- КриптоХок. Альткоин Радар. Бесплатная пробная версия.
- Источник: https://aws.amazon.com/blogs/machine-learning/detect-adversarial-inputs-using-amazon-sagemaker-model-monitor-and-amazon-sagemaker-debugger/
- "
- 10
- 100
- 67
- 9
- О нас
- доступ
- По
- Учетная запись
- активный
- дополнительный
- продвинутый
- Все
- Amazon
- количество
- анализ
- Приложения
- Применение
- примерно
- AWS
- фон
- Базовая линия
- основа
- становиться
- не являетесь
- Заблокировать
- бизнес
- призывают
- захватить
- случаев
- изменение
- Проверки
- класс
- классов
- классификация
- ближе
- код
- собирать
- Column
- Вычисление
- Конференция
- Конфигурация
- Container
- способствовать
- создали
- Преступление
- изготовленный на заказ
- Клиенты
- данным
- более глубокий
- Защита
- убивают
- развертывание
- развернуть
- обнаруженный
- обнаружение
- развивать
- различный
- трудный
- Дисплей
- распределение
- Docker
- не
- Эффективный
- сотрудников
- включить
- Конечная точка
- Окружающая среда
- оценка
- События
- пример
- ожидать
- Face
- лица
- Особенность
- фигура
- First
- фокусируется
- после
- вперед
- найденный
- КАДР
- полный
- функция
- далее
- порождающий
- будет
- большой
- помогает
- здесь
- высший
- Как
- How To
- HTTPS
- идея
- изображение
- Влияние
- индекс
- individual
- информация
- вход
- исследовать
- вопрос
- вопросы
- IT
- работа
- Джобс
- журнал
- Основные
- знания
- известный
- Этикетки
- большой
- УЧИТЬСЯ
- изучение
- привело
- уровень
- Вероятно
- Список
- Включенный в список
- расположение
- места
- машина
- обучение с помощью машины
- Карты
- Мэриленд
- Метрика
- MIT
- ML
- модель
- Модели
- монитор
- Мониторинг
- БОЛЕЕ
- самых
- с разными
- натуральный
- природа
- сеть
- Шум
- "обычные"
- ноутбук
- номер
- номера
- Другое
- процент
- фаза
- Точка
- возможное
- мощный
- предсказывать
- прогноз
- Predictions
- представить
- политикой конфиденциальности.
- Конфиденциальность и безопасность
- Процессы
- производит
- Произведенный
- приводит
- обеспечение
- Стоимость
- Сырье
- признавать
- зарегистрироваться
- регулярный
- соответствующие
- отчету
- хранилище
- запросить
- Запросы
- исследованиям
- Итоги
- Возвращает
- условиями,
- Run
- Бег
- Шкала
- Ученый
- безопасность
- выбранный
- набор
- значительный
- аналогичный
- просто
- ШЕСТЬ
- небольшой
- So
- некоторые
- сложный
- Space
- конкретно
- Начало
- современное состояние
- статистический
- статистика
- Статистика
- Статус:
- диск
- "Студент"
- тестXNUMX
- Тестирование
- тестов
- Через
- время
- топ
- к
- Обучение
- суд
- Университет
- us
- использование
- пользователей
- обычно
- ценностное
- видимый
- визуализация
- Уязвимый
- Что
- будь то
- в то время как
- Руководство пользователя
- Википедия.
- работает
- бы
- год
- лет