Базовые модели (FM) — это большие модели машинного обучения (ML), обученные на широком спектре немаркированных и обобщенных наборов данных. FM, как следует из названия, обеспечивают основу для создания более специализированных последующих приложений и уникальны в своей адаптируемости. Они могут выполнять широкий спектр различных задач, таких как обработка естественного языка, классификация изображений, прогнозирование тенденций, анализ настроений и ответы на вопросы. Масштаб и универсальная адаптивность — вот что отличает FM от традиционных моделей машинного обучения. FM являются мультимодальными; они работают с различными типами данных, такими как текст, видео, аудио и изображения. Большие языковые модели (LLM) представляют собой тип FM и предварительно обучаются на огромных объемах текстовых данных и обычно используются в приложениях, таких как генерация текста, интеллектуальные чат-боты или обобщение.
Потоковая передача данных облегчает постоянный поток разнообразной и актуальной информации, повышая способность моделей адаптироваться и генерировать более точные, контекстуально релевантные результаты. Такая динамическая интеграция потоковых данных позволяет генеративный ИИ приложения оперативно реагировать на изменяющиеся условия, улучшая их адаптивность и общую производительность при выполнении различных задач.
Чтобы лучше это понять, представьте себе чат-бота, который помогает путешественникам забронировать поездку. В этом сценарии чат-боту необходим доступ в режиме реального времени к данным авиакомпаний, статусу рейсов, данным отелей, последним изменениям цен и т. д. Эти данные обычно поступают от третьих сторон, и разработчикам необходимо найти способ принимать эти данные и обрабатывать изменения данных по мере их возникновения.
Пакетная обработка не подходит для этого сценария. Когда данные быстро меняются, их пакетная обработка может привести к тому, что чат-бот будет использовать устаревшие данные, предоставляя клиенту неточную информацию, что влияет на общее качество обслуживания клиентов. Однако потоковая обработка может позволить чат-боту получать доступ к данным в реальном времени и адаптироваться к изменениям доступности и цен, обеспечивая лучшее руководство для клиента и улучшая качество обслуживания клиентов.
Другим примером является решение для наблюдения и мониторинга на основе искусственного интеллекта, в котором FM отслеживают внутренние показатели системы в реальном времени и выдают оповещения. Когда модель обнаруживает аномалию или ненормальное значение метрики, она должна немедленно выдать предупреждение и уведомить об этом оператора. Однако ценность таких важных данных со временем значительно снижается. В идеале эти уведомления должны быть получены в течение нескольких секунд или даже во время процесса. Если операторы получают эти уведомления через несколько минут или часов после того, как они произошли, такая информация бесполезна и потенциально теряет свою ценность. Подобные варианты использования можно найти и в других отраслях, таких как розничная торговля, автомобилестроение, энергетика и финансовая отрасль.
В этом посте мы обсуждаем, почему потоковая передача данных является важнейшим компонентом генеративных приложений искусственного интеллекта из-за ее природы в реальном времени. Мы обсуждаем ценность сервисов потоковой передачи данных AWS, таких как Amazon Managed Streaming для Apache Kafka (Амазон МСК), Потоки данных Amazon Kinesis, Управляемый сервис Amazon для Apache Flinkи Пожарный шланг данных Amazon Kinesis в создании генеративных приложений искусственного интеллекта.
Контекстное обучение
LLM обучаются на данных на определенный момент времени и не имеют встроенной способности доступа к свежим данным во время вывода. По мере появления новых данных вам придется постоянно настраивать или дополнительно обучать модель. Это не только дорогостоящая операция, но и очень ограниченная на практике, поскольку скорость генерации новых данных намного превосходит скорость точной настройки. Кроме того, студентам LLM не хватает контекстуального понимания, они полагаются исключительно на свои тренировочные данные и поэтому склонны к галлюцинациям. Это означает, что они могут дать беглый, связный и синтаксически обоснованный, но фактически неправильный ответ. Они также лишены актуальности, персонализации и контекста.
Однако LLM обладают способностью учиться на данных, которые они получают из контекста, чтобы более точно реагировать, не изменяя веса модели. Это называется контекстное обучениеи может использоваться для получения персонализированных ответов или предоставления точного ответа в контексте политик организации.
Например, в чат-боте события данных могут относиться к перечню рейсов и отелей или изменениям цен, которые постоянно попадают в механизм потокового хранения. Кроме того, события данных фильтруются, обогащаются и преобразуются в потребляемый формат с помощью потокового процессора. Результат становится доступным приложению путем запроса последнего снимка. Снимок постоянно обновляется посредством потоковой обработки; поэтому актуальные данные предоставляются в контексте запроса пользователя к модели. Это позволяет модели адаптироваться к последним изменениям цены и доступности. На следующей диаграмме показан базовый рабочий процесс контекстного обучения.
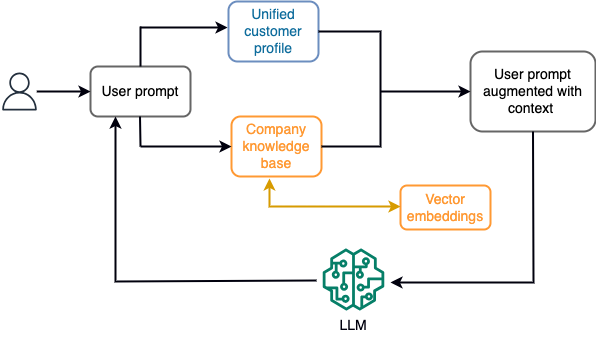
Обычно используемый подход к контекстному обучению заключается в использовании метода под названием «Поисковая дополненная генерация» (RAG). В RAG вы предоставляете соответствующую информацию, такую как наиболее важные политики и записи клиентов, а также вопрос пользователя в подсказке. Таким образом, LLM генерирует ответ на вопрос пользователя, используя дополнительную информацию, предоставленную в качестве контекста. Дополнительную информацию о RAG см. Ответы на вопросы с использованием Retrieval Augmented Generation с базовыми моделями в Amazon SageMaker JumpStart.
Приложение генеративного искусственного интеллекта на основе RAG может выдавать только общие ответы на основе своих обучающих данных и соответствующих документов в базе знаний. Это решение неэффективно, когда от приложения ожидается персонализированный ответ практически в реальном времени. Например, ожидается, что туристический чат-бот будет учитывать текущие бронирования пользователя, доступные отели и билеты на рейсы и многое другое. Кроме того, соответствующие персональные данные клиента (широко известные как единый профиль клиента) обычно может быть изменено. Если для обновления базы данных профилей пользователей генеративного ИИ используется пакетный процесс, клиент может получить неудовлетворительные ответы на основе старых данных.
В этом посте мы обсуждаем применение потоковой обработки для улучшения решения RAG, используемого для создания агентов, отвечающих на вопросы, с контекстом от доступа в реальном времени до унифицированных профилей клиентов и базы знаний организации.
Обновления профилей клиентов почти в реальном времени
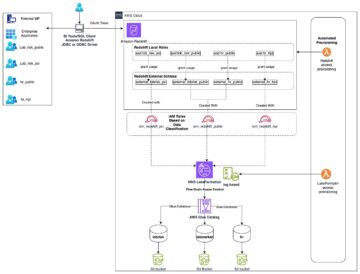
Записи о клиентах обычно распределяются по хранилищам данных внутри организации. Чтобы ваше приложение генеративного ИИ предоставляло актуальный, точный и актуальный профиль клиента, крайне важно создать конвейеры потоковой передачи данных, которые смогут выполнять разрешение идентификационных данных и агрегацию профилей в распределенных хранилищах данных. Потоковые задания постоянно принимают новые данные для синхронизации между системами и могут более эффективно выполнять обогащение, преобразование, объединение и агрегацию в разных окнах времени. События системы отслеживания измененных данных (CDC) содержат информацию об исходной записи, обновлениях и метаданных, таких как время, источник, классификация (вставка, обновление или удаление) и инициатор изменения.
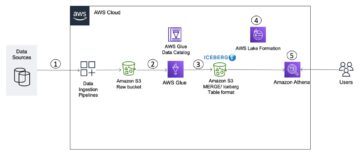
На следующей диаграмме показан пример рабочего процесса приема и обработки потоковой передачи CDC для унифицированных профилей клиентов.

В этом разделе мы обсудим основные компоненты шаблона потоковой передачи CDC, необходимые для поддержки приложений генеративного искусственного интеллекта на основе RAG.
Прием потоковой передачи CDC
Репликатор CDC — это процесс, который собирает изменения данных из исходной системы (обычно путем чтения журналов транзакций или бинлогов) и записывает события CDC в том же порядке, в котором они произошли, в потоке или теме потоковых данных. Это включает в себя сбор журналов с помощью таких инструментов, как Сервис миграции баз данных AWS (AWS DMS) или соединители с открытым исходным кодом, такие как Debezium для подключения Apache Kafka. Apache Kafka Connect является частью среды Apache Kafka, позволяющей получать данные из различных источников и доставлять их в различные места назначения. Вы можете запустить коннектор Apache Kafka на Амазон МСК Коннект в течение нескольких минут, не беспокоясь о настройке, настройке и эксплуатации кластера Apache Kafka. Вам нужно только загрузить скомпилированный код вашего коннектора в Простой сервис хранения Amazon (Amazon S3) и настройте соединитель с учетом конфигурации вашей рабочей нагрузки.
Существуют и другие методы регистрации изменений данных. Например, Amazon DynamoDB предоставляет функцию потоковой передачи данных CDC в Потоки Amazon DynamoDB или потоки данных Kinesis. Amazon S3 предоставляет триггер для вызова AWS Lambda функция, когда сохраняется новый документ.
Потоковое хранилище
Потоковое хранилище функционирует как промежуточный буфер для хранения событий CDC до их обработки. Потоковое хранилище обеспечивает надежное хранение потоковых данных. По своей конструкции он отличается высокой доступностью и устойчивостью к сбоям оборудования или узлов и поддерживает порядок событий по мере их записи. Потоковое хранилище может хранить события данных либо постоянно, либо в течение заданного периода времени. Это позволяет потоковым процессорам читать часть потока в случае сбоя или необходимости повторной обработки. Kinesis Data Streams — это бессерверная служба потоковой передачи данных, которая упрощает захват, обработку и хранение потоков данных в любом масштабе. Amazon MSK — это полностью управляемый, высокодоступный и безопасный сервис, предоставляемый AWS для запуска Apache Kafka.
Обработка потока
Системы потоковой обработки должны быть спроектированы с учетом параллелизма для обработки высокой пропускной способности данных. Им следует разделить входной поток между несколькими задачами, выполняемыми на нескольких вычислительных узлах. Задачи должны иметь возможность отправлять результат одной операции к следующей по сети, что делает возможным параллельную обработку данных при выполнении таких операций, как объединение, фильтрация, обогащение и агрегирование. Приложения потоковой обработки должны иметь возможность обрабатывать события с учетом времени события для случаев использования, когда события могут приходить с опозданием или правильные вычисления зависят от времени возникновения событий, а не от системного времени. Для получения дополнительной информации см. Понятия времени: время события и время обработки.
Потоковые процессы непрерывно выдают результаты в виде событий данных, которые необходимо вывести в целевую систему. Целевой системой может быть любая система, которая может интегрироваться напрямую с процессом или через потоковое хранилище, например, через промежуточное хранилище. В зависимости от платформы, которую вы выберете для потоковой обработки, у вас будут разные варианты целевых систем в зависимости от доступных соединителей приемника. Если вы решите записать результаты в промежуточное потоковое хранилище, вы можете создать отдельный процесс, который считывает события и применяет изменения к целевой системе, например запускает соединитель приемника Apache Kafka. Независимо от того, какой вариант вы выберете, данные CDC требуют дополнительной обработки из-за их характера. Поскольку события CDC несут информацию об обновлениях или удалениях, важно, чтобы они сливались в целевой системе в правильном порядке. Если изменения применяются в неправильном порядке, целевая система не будет синхронизирована с исходной.
Apache Flink — это мощная платформа потоковой обработки, известная своей низкой задержкой и высокой пропускной способностью. Он поддерживает обработку времени события, семантику однократной обработки и высокую отказоустойчивость. Кроме того, он обеспечивает встроенную поддержку данных CDC через специальную структуру, называемую динамические таблицы. Динамические таблицы имитируют таблицы исходной базы данных и обеспечивают столбчатое представление потоковых данных. Данные в динамических таблицах изменяются с каждым обрабатываемым событием. Новые записи можно добавлять, обновлять или удалять в любое время. Динамические таблицы абстрагируют дополнительную логику, которую необходимо реализовать для каждой операции с записью (вставка, обновление, удаление) отдельно. Для получения дополнительной информации см. Динамические таблицы.
Доступно Управляемый сервис Amazon для Apache Flink, вы можете запускать задания Apache Flink и интегрироваться с другими сервисами AWS. Нет серверов и кластеров, которыми нужно управлять, а также нет инфраструктуры вычислений и хранения данных, которую нужно настраивать.
Клей AWS — это полностью управляемый сервис извлечения, преобразования и загрузки (ETL). Это означает, что AWS берет на себя предоставление, масштабирование и обслуживание инфраструктуры за вас. Хотя AWS Glue в первую очередь известен своими возможностями ETL, его также можно использовать для потоковых приложений Spark. AWS Glue может взаимодействовать с сервисами потоковой передачи данных, такими как Kinesis Data Streams и Amazon MSK, для обработки и преобразования данных CDC. AWS Glue также может легко интегрироваться с другими сервисами AWS, такими как Lambda, Шаговые функции AWSи DynamoDB, предоставляющие вам комплексную экосистему для создания конвейеров обработки данных и управления ими.
Единый профиль клиента
Преодоление унификации профиля клиента в различных исходных системах требует разработки надежных конвейеров данных. Вам нужны конвейеры данных, которые могут собирать и синхронизировать все записи в одно хранилище данных. Это хранилище данных предоставляет вашей организации целостное представление записей о клиентах, необходимое для повышения эффективности работы приложений генеративного искусственного интеллекта на основе RAG. Для создания такого хранилища данных лучше всего подойдет неструктурированное хранилище данных.
Граф идентификации — это полезная структура для создания единого профиля клиента, поскольку он консолидирует и интегрирует данные о клиентах из различных источников, обеспечивает точность данных и дедупликацию, предлагает обновления в реальном времени, объединяет межсистемную информацию, обеспечивает персонализацию, улучшает качество обслуживания клиентов и поддерживает соблюдение нормативных требований. Этот унифицированный профиль клиента позволяет генеративному приложению искусственного интеллекта понимать клиентов и эффективно взаимодействовать с ними, а также соблюдать правила конфиденциальности данных, что в конечном итоге улучшает качество обслуживания клиентов и способствует росту бизнеса. Вы можете построить свое решение графа идентичности, используя Амазонка Нептун, быстрый, надежный, полностью управляемый сервис графовых баз данных.
AWS предоставляет несколько других управляемых и бессерверных предложений услуг хранения NoSQL для неструктурированных объектов «ключ-значение». Amazon ДокументБД (с совместимостью с MongoDB) — это быстрое, масштабируемое, высокодоступное и полностью управляемое предприятие. база данных документов сервис, поддерживающий собственные рабочие нагрузки JSON. DynamoDB — это полностью управляемая служба базы данных NoSQL, обеспечивающая быструю и предсказуемую производительность с возможностью плавного масштабирования.
Обновления базы знаний организации практически в реальном времени
Подобно записям клиентов, внутренние хранилища знаний, такие как политики компании и организационные документы, разбросаны по системам хранения. Обычно это неструктурированные данные, которые обновляются неинкрементно. Использование неструктурированных данных для приложений искусственного интеллекта эффективно с использованием векторных векторных представлений, которые представляют собой метод представления многомерных данных, таких как текстовые файлы, изображения и аудиофайлы, в виде многомерных числовых значений.
AWS предоставляет несколько векторный движок, Такие, как Amazon OpenSearch без сервера, Амазон Кендраи Версия, совместимая с Amazon Aurora PostgreSQL с расширением pgvector для хранения векторных вложений. Приложения генеративного искусственного интеллекта могут улучшить взаимодействие с пользователем, преобразовав приглашение пользователя в вектор и используя его для запроса векторного механизма для получения контекстно-релевантной информации. Полученные подсказки и векторные данные затем передаются в LLM для получения более точного и персонализированного ответа.
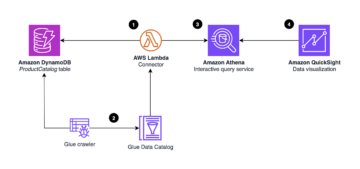
На следующей диаграмме показан пример рабочего процесса потоковой обработки векторных вложений.

Содержимое базы знаний необходимо преобразовать в векторные представления перед записью в хранилище векторных данных. Коренная порода Амазонки or Создатель мудреца Амазонки может помочь вам получить доступ к выбранной вами модели и предоставить частную конечную точку для этого преобразования. Кроме того, вы можете использовать такие библиотеки, как LangChain, для интеграции с этими конечными точками. Создание пакетного процесса может помочь вам преобразовать содержимое базы знаний в векторные данные и первоначально сохранить их в векторной базе данных. Однако вам необходимо полагаться на интервал повторной обработки документов для синхронизации вашей векторной базы данных с изменениями в содержимом вашей базы знаний. При большом количестве документов этот процесс может быть неэффективным. Между этими интервалами пользователи вашего генеративного приложения ИИ будут получать ответы в соответствии со старым контентом или получат неточный ответ, поскольку новый контент еще не векторизован.
Потоковая обработка является идеальным решением этих проблем. Первоначально он создает события в соответствии с существующими документами, а затем отслеживает исходную систему и создает событие изменения документа, как только они происходят. Эти события могут храниться в потоковом хранилище и ожидать обработки заданием потоковой передачи. Задание потоковой передачи считывает эти события, загружает содержимое документа и преобразует его в массив связанных токенов слов. Каждый токен далее преобразуется в векторные данные посредством вызова API во встроенный FM. Результаты отправляются на хранение в векторное хранилище через оператор-приемник.
Если вы используете Amazon S3 для хранения своих документов, вы можете создать архитектуру источника событий на основе триггеров изменения объектов S3 для Lambda. Функция Lambda может создать событие в нужном формате и записать его в ваше потоковое хранилище.
Вы также можете использовать Apache Flink для запуска задания потоковой передачи. Apache Flink предоставляет собственный коннектор источника файловой системы, который может обнаруживать существующие файлы и первоначально читать их содержимое. После этого он может постоянно отслеживать вашу файловую систему на наличие новых файлов и захватывать их содержимое. Коннектор поддерживает чтение набора файлов из распределенных файловых систем, таких как Amazon S3 или HDFS, в формате обычного текста, Avro, CSV, Parquet и других, и создает потоковую запись. Являясь полностью управляемой услугой, Managed Service for Apache Flink устраняет операционные издержки, связанные с развертыванием и обслуживанием заданий Flink, позволяя вам сосредоточиться на создании и масштабировании приложений потоковой передачи. Благодаря полной интеграции с потоковыми сервисами AWS, такими как Amazon MSK или Kinesis Data Streams, он обеспечивает такие функции, как автоматическое масштабирование, безопасность и отказоустойчивость, предоставляя надежные и эффективные приложения Flink для обработки потоковых данных в реальном времени.
В зависимости от ваших предпочтений DevOps вы можете выбрать между Kinesis Data Streams или Amazon MSK для хранения записей потоковой передачи. Kinesis Data Streams упрощает создание и управление пользовательскими приложениями потоковой передачи данных, позволяя вам сосредоточиться на получении аналитической информации из ваших данных, а не на обслуживании инфраструктуры. Клиенты, использующие Apache Kafka, часто выбирают Amazon MSK из-за его простоты, масштабируемости и надежности в управлении кластерами Apache Kafka в среде AWS. Будучи полностью управляемым сервисом, Amazon MSK берет на себя операционные сложности, связанные с развертыванием и обслуживанием кластеров Apache Kafka, позволяя вам сосредоточиться на создании и расширении приложений потоковой передачи.
Поскольку интеграция RESTful API соответствует природе этого процесса, вам нужна платформа, которая поддерживает шаблон обогащения с отслеживанием состояния посредством вызовов RESTful API для отслеживания сбоев и повторения неудачного запроса. Apache Flink снова представляет собой платформу, которая может выполнять операции с состоянием со скоростью памяти. Чтобы понять, как лучше всего выполнять вызовы API через Apache Flink, см. Общие шаблоны обогащения потоковых данных в Amazon Kinesis Data Analytics для Apache Flink.
Apache Flink предоставляет встроенные соединители приемников для записи данных в хранилища векторных данных, такие как Amazon Aurora для PostgreSQL, с помощью pgvector или Сервис Amazon OpenSearch с ВекторБД. Альтернативно вы можете разместить выходные данные задания Flink (векторизованные данные) в теме MSK или потоке данных Kinesis. Служба OpenSearch обеспечивает поддержку собственного приема из потоков данных Kinesis или тем MSK. Для получения дополнительной информации см. Представляем Amazon MSK в качестве источника приема данных Amazon OpenSearch и Загрузка потоковых данных из Amazon Kinesis Data Streams.
Аналитика обратной связи и тонкая настройка
Менеджерам по операциям с данными и разработчикам искусственного интеллекта и машинного обучения важно получить представление о производительности приложения генеративного искусственного интеллекта и используемых FM. Для этого вам необходимо построить конвейеры данных, которые рассчитывают важные данные ключевого показателя производительности (KPI) на основе отзывов пользователей, а также различных журналов приложений и метрик. Эта информация полезна для заинтересованных сторон, поскольку позволяет в режиме реального времени получать представление о производительности FM, приложения и общей удовлетворенности пользователей качеством поддержки, которую они получают от вашего приложения. Вам также необходимо собирать и хранить историю разговоров для дальнейшей тонкой настройки ваших FM-устройств, чтобы улучшить их способность выполнять задачи, специфичные для предметной области.
Этот вариант использования очень хорошо подходит для потоковой аналитики. Ваше приложение должно хранить каждый разговор в потоковом хранилище. Ваше приложение может сообщать пользователям об их оценке точности каждого ответа и их общей удовлетворенности. Эти данные могут быть в формате двоичного выбора или в текстовой форме произвольной формы. Эти данные можно хранить в потоке данных Kinesis или теме MSK и обрабатывать для создания ключевых показателей эффективности в режиме реального времени. Вы можете использовать FM для анализа настроений пользователей. FM могут проанализировать каждый ответ и назначить категорию удовлетворенности пользователей.
Архитектура Apache Flink позволяет выполнять сложную агрегацию данных за определенные промежутки времени. Он также обеспечивает поддержку SQL-запросов через поток событий данных. Таким образом, используя Apache Flink, вы можете быстро анализировать необработанные пользовательские данные и генерировать ключевые показатели эффективности в режиме реального времени, написав знакомые запросы SQL. Для получения дополнительной информации см. Табличный API и SQL.
Доступно Управляемый сервис Amazon для Apache Flink Studio, вы можете создавать и запускать приложения потоковой обработки Apache Flink с использованием стандартных SQL, Python и Scala в интерактивном блокноте. Ноутбуки Studio работают на базе Apache Zeppelin и используют Apache Flink в качестве механизма потоковой обработки. Ноутбуки Studio органично сочетают в себе эти технологии, делая расширенную аналитику потоков данных доступной разработчикам с любым набором навыков. Благодаря поддержке определяемых пользователем функций (UDF) Apache Flink позволяет создавать собственные операторы для интеграции с внешними ресурсами, такими как FM, для выполнения сложных задач, таких как анализ настроений. Вы можете использовать пользовательские функции для расчета различных показателей или обогащать необработанные данные отзывов пользователей дополнительной информацией, например о настроениях пользователей. Чтобы узнать больше об этом шаблоне, см. Упреждающее решение проблем клиентов в режиме реального времени с помощью GenAI, Flink, Apache Kafka и Kinesis..
С помощью Managed Service для Apache Flink Studio вы можете одним щелчком мыши развернуть свой блокнот Studio как задание потоковой передачи. Вы можете использовать собственные соединители приемников, предоставляемые Apache Flink, для отправки выходных данных в выбранное вами хранилище или размещения их в потоке данных Kinesis или теме MSK. Амазонка Redshift и OpenSearch Service идеально подходят для хранения аналитических данных. Оба механизма обеспечивают встроенную поддержку приема данных из Kinesis Data Streams и Amazon MSK через отдельный потоковый конвейер в озеро данных или хранилище данных для анализа.
Amazon Redshift использует SQL для анализа структурированных и полуструктурированных данных в хранилищах данных и озерах данных, используя оборудование, разработанное AWS, и машинное обучение, чтобы обеспечить лучшее соотношение цены и производительности в масштабе. Служба OpenSearch предлагает возможности визуализации на базе OpenSearch Dashboards и Kibana (версии от 1.5 до 7.10).
Вы можете использовать результаты такого анализа в сочетании с данными подсказок пользователю для точной настройки FM, когда это необходимо. SageMaker — это самый простой способ точно настроить FM. Использование Amazon S3 с SageMaker обеспечивает мощную и простую интеграцию для точной настройки ваших моделей. Amazon S3 представляет собой масштабируемое и надежное решение для хранения объектов, обеспечивающее простое хранение и извлечение больших наборов данных, обучающих данных и артефактов моделей. SageMaker — это полностью управляемый сервис машинного обучения, который упрощает весь жизненный цикл машинного обучения. Используя Amazon S3 в качестве серверной части хранилища для SageMaker, вы можете воспользоваться преимуществами масштабируемости, надежности и экономичности Amazon S3, а также легко интегрировать его с возможностями обучения и развертывания SageMaker. Такое сочетание обеспечивает эффективное управление данными, облегчает совместную разработку моделей и обеспечивает оптимизацию и масштабируемость рабочих процессов машинного обучения, что в конечном итоге повышает общую гибкость и производительность процесса машинного обучения. Для получения дополнительной информации см. Точная настройка Falcon 7B и других LLM на Amazon SageMaker с помощью декоратора @remote.
Благодаря коннектору приемника файловой системы задания Apache Flink могут доставлять данные в Amazon S3 в файлах открытого формата (например, JSON, Avro, Parquet и т. д.) в виде объектов данных. Если вы предпочитаете управлять озером данных с помощью инфраструктуры озера транзакционных данных (например, Apache Hudi, Apache Iceberg или Delta Lake), все эти платформы предоставляют специальный соединитель для Apache Flink. Для получения более подробной информации см. Создайте конвейер озера «источник-данные» с малой задержкой, используя Amazon MSK Connect, Apache Flink и Apache Hudi..
Обзор
Для приложения генеративного ИИ, основанного на модели RAG, вам необходимо рассмотреть возможность создания двух систем хранения данных, а также вам необходимо создать операции с данными, которые будут поддерживать их актуальность во всех исходных системах. Традиционных пакетных заданий недостаточно для обработки размера и разнообразия данных, необходимых для интеграции с вашим генеративным приложением искусственного интеллекта. Задержки в обработке изменений в исходных системах приводят к неточному ответу и снижают эффективность вашего генеративного приложения ИИ. Потоковая передача данных позволяет получать данные из различных баз данных в различных системах. Это также позволяет вам эффективно преобразовывать, обогащать, объединять и агрегировать данные из многих источников почти в реальном времени. Потоковая передача данных обеспечивает упрощенную архитектуру данных для сбора и преобразования реакций пользователей или комментариев к ответам приложений в реальном времени, помогая доставлять и сохранять результаты в озере данных для точной настройки модели. Потоковая передача данных также помогает оптимизировать конвейеры данных, обрабатывая только события изменения, что позволяет быстрее и эффективнее реагировать на изменения данных.
Узнать больше о Сервисы потоковой передачи данных AWS и начните создавать собственное решение для потоковой передачи данных.
Об авторах
 Али Алеми является специалистом по потоковой передаче, архитектором решений в AWS. Али консультирует клиентов AWS по рекомендациям в области архитектуры и помогает им разрабатывать надежные, безопасные, эффективные и экономичные системы аналитических данных в реальном времени. Он работает в обратном направлении от сценариев использования клиентов и разрабатывает решения для данных для решения их бизнес-задач. До прихода в AWS Али поддерживал нескольких клиентов из государственного сектора и партнеров-консультантов AWS в процессе модернизации приложений и миграции в облако.
Али Алеми является специалистом по потоковой передаче, архитектором решений в AWS. Али консультирует клиентов AWS по рекомендациям в области архитектуры и помогает им разрабатывать надежные, безопасные, эффективные и экономичные системы аналитических данных в реальном времени. Он работает в обратном направлении от сценариев использования клиентов и разрабатывает решения для данных для решения их бизнес-задач. До прихода в AWS Али поддерживал нескольких клиентов из государственного сектора и партнеров-консультантов AWS в процессе модернизации приложений и миграции в облако.
 Имтиаз (Таз) Сайед — мировой технологический лидер в области аналитики в AWS. Ему нравится взаимодействовать с сообществом по всем вопросам, связанным с данными и аналитикой. С ним можно связаться через LinkedIn.
Имтиаз (Таз) Сайед — мировой технологический лидер в области аналитики в AWS. Ему нравится взаимодействовать с сообществом по всем вопросам, связанным с данными и аналитикой. С ним можно связаться через LinkedIn.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- PlatoData.Network Вертикальный генеративный ИИ. Расширьте возможности себя. Доступ здесь.
- ПлатонАйСтрим. Интеллект Web3. Расширение знаний. Доступ здесь.
- ПлатонЭСГ. Углерод, чистые технологии, Энергия, Окружающая среда, Солнечная, Управление отходами. Доступ здесь.
- ПлатонЗдоровье. Биотехнологии и клинические исследования. Доступ здесь.
- Источник: https://aws.amazon.com/blogs/big-data/exploring-real-time-streaming-for-generative-ai-applications/
- :имеет
- :является
- :нет
- :куда
- $UP
- 1
- 10
- 100
- 5
- 7
- a
- способность
- в состоянии
- ненормальный
- О нас
- АБСТРАКТ НАЯ
- доступ
- доступной
- По
- точность
- точный
- точно
- Достигать
- через
- действенные
- приспосабливать
- адаптируемость
- дополнительный
- Дополнительная информация
- Дополнительно
- адресация
- придерживаться
- продвинутый
- После
- снова
- агенты
- совокупный
- агрегирование
- AI
- AI / ML
- авиакомпания
- Оповещение
- Оповещения
- Все
- Позволяющий
- позволяет
- вдоль
- причислены
- Несмотря на то, что
- Amazon
- Амазонка Кинезис
- Создатель мудреца Амазонки
- Amazon Web Services
- суммы
- an
- анализ
- Аналитические фармацевтические услуги
- аналитика
- анализировать
- анализ
- и
- ответ
- ответ
- ответы
- любой
- апаш
- Апач Кафка
- API
- появляется
- Применение
- Приложения
- прикладной
- применяется
- подхода
- архитектурный
- архитектура
- МЫ
- массив
- прибывать
- AS
- назначать
- связанный
- At
- аудио
- дополненная
- Aurora
- Автоматический
- свободных мест
- доступен
- прочь
- AWS
- Клей AWS
- Backend
- Использование темпера с изогнутым основанием
- основанный
- основной
- BE
- , так как:
- до
- не являетесь
- польза
- ЛУЧШЕЕ
- лучшие практики
- Лучшая
- между
- двоичный
- книга
- заказы
- изоферменты печени
- приносить
- широкий
- буфер
- строить
- Строительство
- бизнес
- но
- by
- вычислять
- призывают
- под названием
- Объявления
- CAN
- возможности
- Пропускная способность
- захватить
- Захват
- автомобиль
- нести
- случаев
- случаев
- Категории
- CDC
- проблемы
- изменение
- изменения
- изменения
- Chatbot
- chatbots
- выбор
- Выберите
- классификация
- нажмите на
- облако
- Кластер
- код
- ПОСЛЕДОВАТЕЛЬНЫЙ
- совместный
- собирать
- улавливается
- сочетание
- объединять
- сочетании
- выходит
- Комментарии
- обычно
- сообщество
- Компания
- совместимость
- скомпилированный
- комплекс
- сложности
- Соответствие закону
- компонент
- компоненты
- комплексный
- вычисление
- Вычисление
- сконцентрировать
- Беспокойство
- Условия
- Конфигурация
- Свяжитесь
- Разъемы
- подключает
- Рассматривать
- консолидирует
- постоянная
- постоянно
- строительство
- консалтинг
- содержать
- содержание
- содержание
- контекст
- контекстной
- непрерывно
- Разговор
- Конверсия
- конвертировать
- переделанный
- исправить
- рентабельным
- может
- Создайте
- создает
- Создающий
- решающее значение
- Текущий
- изготовленный на заказ
- клиент
- данные клиентов
- опыт работы с клиентами
- профиль пользователя
- Клиенты
- щитки
- данным
- Анализ данных
- обогащение данных
- Озеро данных
- управление данными
- конфиденциальность данных
- обработка данных
- хранение данных
- информационное хранилище
- хранилища данных
- База данных
- базы данных
- Наборы данных
- Время
- решать
- задержки
- удалять
- удаленный
- удалений
- доставить
- поставляется
- Delta
- в зависимости
- развертывание
- развертывание
- развертывание
- вывода
- Проект
- предназначенный
- конструкций
- желанный
- направления
- подробнее
- застройщиков
- Развитие
- DevOps
- диаграмма
- различный
- непосредственно
- обнаружить
- обсуждать
- распределенный
- Разное
- Разнообразие
- do
- документ
- Документация
- домен
- вождение
- два
- динамический
- каждый
- экосистема
- Эффективный
- фактически
- затрат
- эффективный
- эффективно
- или
- вложения
- занятых
- Наделяет
- включить
- позволяет
- позволяет
- Конечная точка
- конечные точки
- энергетика
- заниматься
- привлечение
- Двигатель
- Двигатели
- повышать
- Усиливает
- повышение
- обогащать
- обогащенный
- обогащение
- обеспечивает
- Предприятие
- Весь
- Окружающая среда
- Эфир (ETH)
- Даже
- События
- События
- Каждая
- точный
- пример
- существующий
- расширяющийся
- ожидаемый
- дорогим
- опыт
- Впечатления
- Исследование
- экспонаты
- расширение
- и, что лучший способ
- дополнительно
- извлечение
- облегчает
- Oшибка
- Ошибка
- сбои
- сокол
- Водопад
- знакомый
- далеко
- Фэшн
- БЫСТРО
- вина
- Особенность
- Особенности
- Обратная связь
- несколько
- Файл
- Файлы
- фильтрация
- финансовый
- Найдите
- находит
- соответствовать
- припадки
- полет
- Авиабилеты
- поток
- Фокус
- после
- Что касается
- форма
- формат
- Год основания
- Рамки
- каркасы
- Бесплатно
- свежий
- от
- полностью
- функция
- Функции
- далее
- Более того
- Gain
- Genai
- общее назначение
- обобщенный
- порождать
- генерирует
- поколение
- генеративный
- Генеративный ИИ
- получить
- график
- Рост
- руководство
- обрабатывать
- Ручки
- Управляемость
- происходить
- произошло
- Случай
- Аппаратные средства
- Есть
- he
- помощь
- помощь
- помогает
- High
- очень
- история
- целостный
- Гостиница
- отели
- ЧАСЫ
- Однако
- HTML
- HTTP
- HTTPS
- идеальный
- Идеально
- Личность
- if
- иллюстрирует
- изображений
- картина
- немедленно
- Воздействие
- осуществлять
- важную
- улучшать
- улучшение
- in
- В других
- неточный
- неправильный
- Индикаторные
- промышленности
- промышленность
- неэффективное
- информация
- Инфраструктура
- свойственный
- первоначально
- инициатор
- вход
- затраты
- понимание
- размышления
- интегрировать
- Интегрируется
- Интегрируя
- интеграции.
- Умный
- взаимодействовать
- интерактивный
- посредник
- Intermediate
- в нашей внутренней среде,
- интервал
- в
- инвентаризация
- включает в себя
- IT
- ЕГО
- работа
- Джобс
- присоединиться
- присоединение
- Играя
- путешествие
- JPG
- JSON
- Кафка
- Сохранить
- Основные
- Потоки данных Kinesis
- знания
- известный
- Отсутствие
- озеро
- озера
- язык
- большой
- Поздно
- Задержка
- последний
- лидер
- УЧИТЬСЯ
- изучение
- библиотеки
- Жизненный цикл
- такое как
- ограничивающий
- LLM
- загрузка
- грузы
- логика
- потерянный
- Низкий
- машина
- обучение с помощью машины
- сделанный
- Главная
- сохранение
- поддерживает
- техническое обслуживание
- сделать
- ДЕЛАЕТ
- Создание
- управлять
- управляемого
- управление
- Менеджеры
- управления
- производство
- многих
- Май..
- означает
- идти
- Метаданные
- методы
- метрический
- Метрика
- миграция
- минут
- ML
- модель
- Модели
- модернизация
- MongoDB
- монитор
- Мониторинг
- Мониторы
- БОЛЕЕ
- Более того
- самых
- с разными
- имя
- родной
- натуральный
- Естественный язык
- Обработка естественного языка
- природа
- Необходимость
- необходимый
- потребности
- сеть
- Новые
- следующий
- нет
- узел
- узлы
- ноутбук
- ноутбуки
- Уведомления
- номер
- объект
- Хранение объектов
- объекты
- происходить
- произошло
- of
- Предложения
- Предложения
- .
- Старый
- on
- ONE
- только
- открытый
- с открытым исходным кодом
- операционный
- операция
- оперативный
- Операционный отдел
- оператор
- Операторы
- выбирать
- Оптимизировать
- Опция
- Опции
- or
- заказ
- организация
- организационной
- Другое
- внешний
- Результат
- выходной
- выходы
- за
- общий
- накладные расходы
- контроль
- собственный
- Параллельные
- часть
- Стороны
- партнеры
- Прошло
- шаблон
- паттеранами
- для
- выполнять
- производительность
- выполнения
- период
- постоянно
- личного
- личные данные
- воплощение
- Персонализированные
- трубопровод
- одноцветный
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- сборах
- политика
- возможное
- После
- Postgresql
- потенциально
- Питание
- мощный
- практика
- практиками
- необходимость
- предсказуемый
- предпочитать
- цена
- в первую очередь
- Предварительный
- политикой конфиденциальности.
- частная
- проблемам
- процесс
- обрабатываемых
- Процессы
- обработка
- процессор
- процессоры
- производит
- производит
- Профиль
- Профили
- быстро
- обеспечивать
- при условии
- приводит
- обеспечение
- что такое варган?
- положил
- Питон
- Запросы
- запрос
- вопрос
- Вопросы
- быстро
- тряпка
- ассортимент
- быстро
- Обменный курс
- скорее
- рейтинг
- Сырье
- необработанные данные
- достиг
- реакции
- Читать
- Reading
- реальные
- реального времени
- данные в реальном времени
- Получать
- получила
- запись
- учет
- уменьшить
- относиться
- Несмотря на
- С уважением
- правила
- регуляторы
- Соответствие нормативным требованиям
- Связанный
- актуальность
- соответствующие
- надежность
- складская
- полагается
- полагаться
- удаляет
- представление
- представляющий
- запросить
- обязательный
- требуется
- упругий
- Постановления
- Полезные ресурсы
- Реагируйте
- ответ
- ответы
- результат
- Итоги
- розничный
- поиск
- правую
- надежный
- Run
- Бег
- sagemaker
- то же
- удовлетворение
- масштаб
- Масштабируемость
- масштабируемые
- Шкала
- масштабирование
- сценарий
- бесшовные
- легко
- секунды
- Раздел
- сектор
- безопасный
- безопасность
- семантика
- Отправить
- послать
- настроение
- отдельный
- отдельно
- Serverless
- Серверы
- служит
- обслуживание
- Услуги
- набор
- Наборы
- установка
- несколько
- Короткое
- должен
- существенно
- разобщенный
- аналогичный
- просто
- упрощенный
- упрощает
- Размер
- умение
- Снимок
- только
- Решение
- Решения
- РЕШАТЬ
- Скоро
- Звук
- Источник
- Источники
- Искриться
- особый
- специалист
- специализированный
- конкретный
- Спектр
- скорость
- SQL
- Этап
- заинтересованных сторон
- стандарт
- и политические лидеры
- Статус:
- Шаг
- диск
- магазин
- хранить
- магазины
- хранение
- простой
- поток
- потоковый
- Потоковые службы
- обтекаемый
- потоки
- Структура
- структурированный
- студия
- предмет
- такие
- достаточный
- Предлагает
- масти
- поддержка
- Поддержанный
- Поддержка
- Убедитесь
- синхронизации.
- синхронизировать
- система
- системы
- принимает
- цель
- задачи
- технологии
- техника
- технологии
- текст
- генерация текста
- чем
- который
- Ассоциация
- Источник
- их
- Их
- тогда
- Там.
- следовательно
- Эти
- они
- вещи
- В третьих
- третье лицо
- этой
- Через
- пропускная способность
- время
- в
- знак
- Лексемы
- терпимость
- инструменты
- тема
- Темы
- трек
- традиционный
- Train
- специалистов
- Обучение
- сделка
- транзакционный
- Transform
- преобразований
- преобразован
- превращение
- прообразы
- путешествовать
- путешественники
- Тенденции
- вызвать
- два
- напишите
- Типы
- типично
- В конечном счете
- понимать
- понимание
- унифицированный
- созданного
- неструктурированных
- новейший
- Обновление ПО
- обновление
- Updates
- использование
- прецедент
- используемый
- полезный
- Информация о пользователе
- Пользовательский опыт
- пользователей
- использования
- через
- обычно
- ценностное
- разнообразие
- различный
- Огромная
- вектор
- версии
- очень
- с помощью
- Видео
- Вид
- визуализация
- жизненный
- ждать
- Склады
- Путь..
- способы
- we
- Web
- веб-сервисы
- ЧТО Ж
- Что
- когда
- который
- в то время как
- зачем
- широкий
- Широкий диапазон
- будете
- окна
- в
- без
- слова
- Работа
- рабочий
- Рабочие процессы
- работает
- Семинары
- беспокоиться
- бы
- записывать
- письмо
- письменный
- Неправильно
- еще
- являетесь
- ВАШЕ
- зефирнет
- Zeppelin