Этот пост написан в соавторстве с Анатолием Хоменко, инженером по машинному обучению, и Абденуром Беззу, техническим директором Talent.com.
Основанный в 2011 году, Talent.com является одним из крупнейших источников занятости в мире. Компания объединяет оплачиваемые списки вакансий от своих клиентов с общедоступными списками вакансий в единую платформу с возможностью поиска. Talent.com предлагает более 30 миллионов вакансий в более чем 75 странах и предлагает вакансии на многих языках, в разных отраслях и каналах распространения. В результате появилась платформа, которая помогает миллионам соискателей найти доступные рабочие места.
Миссия Talent.com — централизовать все вакансии, доступные в Интернете, чтобы помочь соискателям найти наиболее подходящую кандидатуру, одновременно предоставляя им лучшие возможности поиска. Основное внимание уделяется релевантности, поскольку порядок рекомендуемых вакансий жизненно важен для отображения вакансий, наиболее соответствующих интересам пользователей. Эффективность алгоритма сопоставления Talent.com имеет первостепенное значение для успеха бизнеса и является ключевым фактором удобства пользователей. Трудно предсказать, какие вакансии подходят соискателю, основываясь на ограниченном объеме предоставленной информации, обычно содержащейся в нескольких ключевых словах и местоположении.
Учитывая эту миссию, Talent.com и AWS объединили усилия для создания системы рекомендаций по вакансиям, использующей современную обработку естественного языка (NLP) и методы обучения моделей глубокого обучения с Создатель мудреца Амазонки предоставить непревзойденный опыт для соискателей работы. В этом посте показан наш совместный подход к разработке системы рекомендаций по вакансиям, включая разработку функций, проектирование архитектуры модели глубокого обучения, оптимизацию гиперпараметров и оценку модели, что обеспечивает надежность и эффективность нашего решения как для соискателей работы, так и для работодателей. Система разработана командой преданных своему делу ученых в области прикладного машинного обучения (ML), инженеров ML и экспертов в конкретных областях в сотрудничестве между AWS и Talent.com.
Система рекомендаций привела к увеличению рейтинга кликов (CTR) на 8.6% в онлайн-тестировании A/B по сравнению с предыдущим решением на базе XGBoost, помогая миллионам пользователей Talent.com найти более выгодные рабочие места.
Обзор решения
Обзор системы показан на следующем рисунке. Система принимает поисковый запрос пользователя в качестве входных данных и выводит ранжированный список вакансий в порядке их релевантности. Соответствие вакансии измеряется вероятностью клика (вероятность того, что соискатель нажмет на вакансию для получения дополнительной информации).
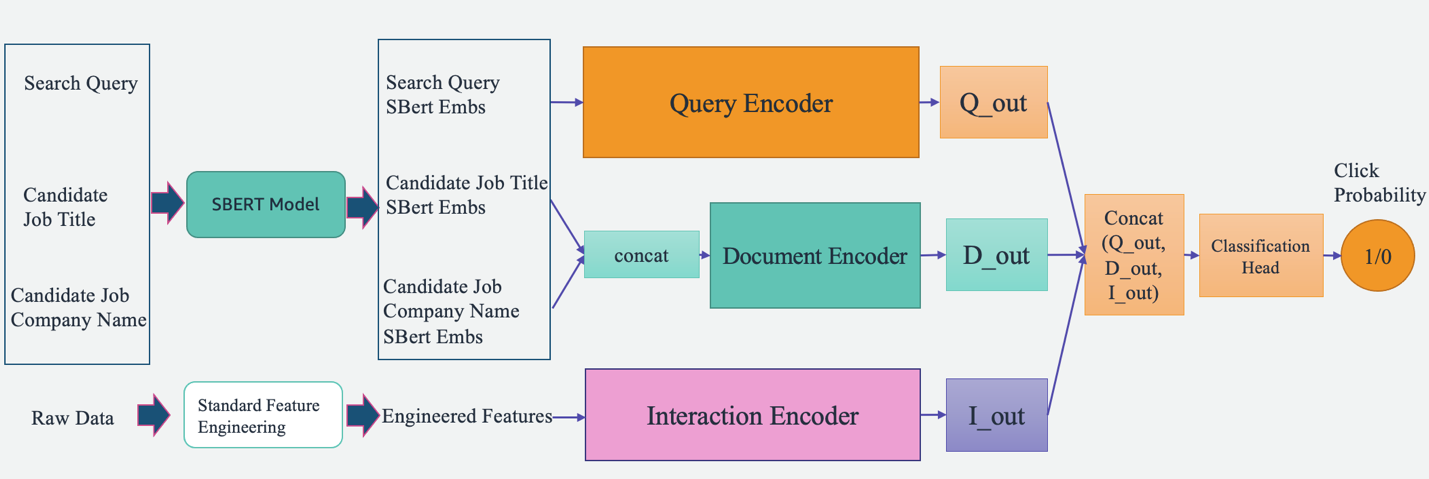
Система включает в себя четыре основных компонента:
- Модельная архитектура – Ядром этого механизма рекомендаций вакансий является основанная на глубоком обучении модель Triple Tower Pointwise, которая включает в себя кодировщик запросов, который кодирует поисковые запросы пользователей, кодировщик документов, который кодирует описания должностей, и кодировщик взаимодействия, который обрабатывает прошлые задания пользователя. особенности взаимодействия. Выходные данные трех башен объединяются и пропускаются через классификационную головку для прогнозирования вероятности выполнения задания. Обучая эту модель поисковым запросам, специфике работы и историческим данным взаимодействия с пользователем с Talent.com, эта система предоставляет соискателям персонализированные и весьма релевантные рекомендации по работе.
- Функциональная инженерия – Мы выполняем два набора функций проектирования, чтобы извлечь ценную информацию из входных данных и передать ее в соответствующие башни модели. Эти два набора представляют собой стандартную разработку функций и точно настроенные внедрения Sentence-BERT (SBERT). Мы используем стандартные инженерные функции в качестве входных данных для кодировщика взаимодействия и передаем встраивание, полученное из SBERT, в кодировщик запросов и кодировщик документов.
- Оптимизация и настройка модели – Мы используем передовые методики обучения для обучения, тестирования и развертывания системы с помощью SageMaker. Сюда входит обучение SageMaker Distributed Data Parallel (DDP), автоматическая настройка модели SageMaker (AMT), планирование скорости обучения и ранняя остановка для повышения производительности модели и скорости обучения. Использование платформы обучения DDP помогло ускорить обучение нашей модели примерно в восемь раз.
- Оценка модели – Мы проводим как оффлайн, так и онлайн оценку. Мы оцениваем производительность модели с помощью площади под кривой (AUC) и средней средней точности при K (mAP@K) в автономной оценке. Во время онлайн-A/B-тестирования мы оцениваем улучшение CTR.
В следующих разделах мы представим подробную информацию об этих четырех компонентах.
Проектирование архитектуры модели глубокого обучения
Мы разрабатываем модель Triple Tower Deep Pointwise (TTDP), используя архитектуру глубокого обучения Triple Tower и подход поточечного парного моделирования. Архитектура тройной башни предоставляет три параллельные глубокие нейронные сети, каждая из которых независимо обрабатывает набор функций. Этот шаблон проектирования позволяет модели изучать различные представления из разных источников информации. После того, как представления от всех трех башен получены, они объединяются и проходят через головку классификации, чтобы сделать окончательный прогноз (0–1) вероятности щелчка (установка точечного моделирования).
Три башни названы в зависимости от информации, которую они обрабатывают: кодировщик запросов обрабатывает поисковый запрос пользователя, кодировщик документов обрабатывает документацию кандидата на должность, включая название должности и название компании, а кодировщик взаимодействия использует соответствующие функции, извлеченные из прошлых взаимодействий с пользователем. и история (подробнее обсуждается в следующем разделе).
Каждая из этих башен играет решающую роль в обучении тому, как рекомендовать работу:
- Кодировщик запросов – Кодер запроса принимает встраивания SBERT, полученные из запроса пользователя на поиск работы. Мы улучшаем встраивания с помощью модели SBERT, которую мы точно настроили. Этот кодировщик обрабатывает и понимает намерения пользователя по поиску работы, включая детали и нюансы, фиксируемые нашими внедрениями, специфичными для конкретной предметной области.
- Кодировщик документов – Кодировщик документов обрабатывает информацию каждого списка вакансий. В частности, он использует встраивания SBERT составного текста из названия должности и компании. Интуиция подсказывает, что пользователи будут больше интересоваться кандидатами на вакансии, которые более релевантны поисковому запросу. Сопоставляя вакансии и поисковые запросы с одним и тем же векторным пространством (определенным SBERT), модель может научиться предсказывать вероятность потенциальных вакансий, на которые нажмет соискатель.
- Кодер взаимодействия – Кодировщик взаимодействия учитывает прошлые взаимодействия пользователя со списками вакансий. Функции создаются с помощью стандартного этапа разработки функций, который включает в себя расчет показателей популярности должностей и компаний, определение оценок сходства контекста и извлечение параметров взаимодействия из предыдущих взаимодействий с пользователями. Он также обрабатывает именованные объекты, указанные в названии должности и поисковых запросах, с помощью предварительно обученной модели распознавания именованных объектов (NER).
Каждая башня параллельно генерирует независимые выходные данные, которые затем объединяются вместе. Этот объединенный вектор признаков затем передается для прогнозирования вероятности клика по списку вакансий по пользовательскому запросу. Архитектура с тремя башнями обеспечивает гибкость в фиксации сложных взаимосвязей между различными входными данными или функциями, позволяя модели использовать сильные стороны каждой башни и одновременно изучать более выразительные представления для данной задачи.
Прогнозируемые вероятности кликов кандидатов на вакансии ранжируются от высокой к низкой, что позволяет генерировать персонализированные рекомендации по вакансиям. Благодаря этому процессу мы гарантируем, что каждая часть информации — будь то цель поиска пользователя, сведения о списке вакансий или прошлые взаимодействия — полностью захватывается специальной вышкой, предназначенной для нее. Сложные взаимоотношения между ними также отражаются посредством комбинации выходов башни.
Функциональная инженерия
Мы выполняем два набора процессов проектирования признаков, чтобы извлечь ценную информацию из необработанных данных и передать ее в соответствующие башни модели: стандартное проектирование признаков и точно настроенные внедрения SBERT.
Разработка стандартных функций
Наш процесс подготовки данных начинается с проектирования стандартных функций. В целом мы определяем четыре типа функций:
- Популярные – Мы рассчитываем рейтинг популярности на уровне отдельной должности, профессии и компании. Это дает показатель того, насколько привлекательной может быть конкретная работа или компания.
- Текстовое сходство – Чтобы понять контекстуальную связь между различными текстовыми элементами, мы вычисляем показатели сходства, включая сходство строк между поисковым запросом и названием должности. Это помогает нам оценить актуальность вакансии для истории поиска или подачи заявок соискателем.
- Взаимодействие – Кроме того, мы извлекаем функции взаимодействия из прошлых взаимодействий пользователей со списками вакансий. Ярким примером этого является встроенное сходство между названиями должностей, по которым вы нажимали в прошлом, и названиями должностей кандидатов. Эта мера помогает нам понять сходство между предыдущими вакансиями, к которым пользователь проявил интерес, и предстоящими вакансиями. Это повышает точность нашей системы рекомендаций по вакансиям.
- Профиль – Наконец, мы извлекаем определяемую пользователем информацию о заинтересованности в работе из профиля пользователя и сравниваем ее с новыми кандидатами на работу. Это помогает нам понять, соответствует ли кандидат на работу интересам пользователя.
Важным шагом в подготовке данных является применение предварительно обученной модели NER. Внедряя модель NER, мы можем идентифицировать и маркировать именованные объекты в названиях должностей и поисковых запросах. Следовательно, это позволяет нам вычислить показатели сходства между этими идентифицированными объектами, обеспечивая более целенаправленную и контекстно-зависимую меру родства. Эта методология уменьшает шум в наших данных и дает нам более тонкий, контекстно-зависимый метод сравнения вакансий.
Точные настройки SBERT-вложений
Чтобы повысить актуальность и точность нашей системы рекомендаций по вакансиям, мы используем возможности SBERT, мощной модели на основе преобразователя, известной своей способностью улавливать семантические значения и контексты из текста. Однако общие внедрения, такие как SBERT, хотя и эффективны, могут не полностью отражать уникальные нюансы и терминологию, присущие конкретной области, такой как наша, которая сосредоточена вокруг трудоустройства и поиска работы. Чтобы преодолеть эту проблему, мы настраиваем встраивания SBERT, используя данные, специфичные для нашей предметной области. Этот процесс тонкой настройки оптимизирует модель для лучшего понимания и обработки отраслевого языка, жаргона и контекста, делая встраивания более отражающими нашу конкретную предметную область. В результате улучшенные внедрения обеспечивают повышенную производительность при сборе как семантической, так и контекстной информации в нашей сфере, что приводит к более точным и содержательным рекомендациям по работе для наших пользователей.
На следующем рисунке показан этап тонкой настройки SBERT.

Мы настраиваем вложения SBERT, используя Тройная потеря с метрикой косинусного расстояния, которая изучает встраивание текста, где привязочный и позитивный тексты имеют более высокое косинусное сходство, чем привязочный и негативный тексты. В качестве якорных текстов мы используем поисковые запросы пользователей. Мы объединяем названия должностей и имена работодателей в качестве входных данных для позитивных и негативных текстов. Положительные тексты выбираются из объявлений о вакансиях, на которые нажимал соответствующий пользователь, тогда как негативные тексты выбираются из объявлений о вакансиях, на которые пользователь не нажимал. Ниже приведен пример реализации процедуры тонкой настройки:
Обучение модели с помощью SageMaker Distributed Data Parallel
Мы используем SageMaker Distributed Data Parallel (SMDDP), функцию платформы SageMaker ML, построенную на основе PyTorch DDP. Он обеспечивает оптимизированную среду для выполнения заданий обучения PyTorch DDP на платформе SageMaker. Он предназначен для значительного ускорения обучения модели глубокого обучения. Это достигается за счет разделения большого набора данных на более мелкие фрагменты и распределения их по нескольким графическим процессорам. Модель реплицируется на каждом графическом процессоре. Каждый графический процессор обрабатывает назначенные ему данные независимо, а результаты сопоставляются и синхронизируются на всех графических процессорах. DDP заботится о градиентной коммуникации, чтобы синхронизировать реплики модели, и накладывает на них вычисления градиента, чтобы ускорить обучение. SMDDP использует оптимизированный алгоритм AllReduce для минимизации обмена данными между графическими процессорами, сокращения времени синхронизации и повышения общей скорости обучения. Алгоритм адаптируется к различным условиям сети, что делает его высокоэффективным как для локальных, так и для облачных сред. В архитектуре SMDDP (как показано на следующем рисунке) распределенное обучение также масштабируется с использованием кластера из многих узлов. Это означает не просто несколько графических процессоров в вычислительном экземпляре, а множество экземпляров с несколькими графическими процессорами, что еще больше ускоряет обучение.

Дополнительную информацию об этой архитектуре см. Введение в библиотеку параллельных распределенных данных SageMaker.
Благодаря SMDDP нам удалось существенно сократить время обучения нашей модели TTDP, сделав ее в восемь раз быстрее. Более быстрое обучение означает, что мы можем быстрее повторять и улучшать наши модели, что приводит к более качественным рекомендациям по работе для наших пользователей за более короткий промежуток времени. Такое повышение эффективности играет важную роль в поддержании конкурентоспособности нашей системы рекомендации вакансий на быстро развивающемся рынке труда.
Вы можете адаптировать свой сценарий обучения с помощью SMDDP, используя всего три строки кода, как показано в следующем блоке кода. Используя PyTorch в качестве примера, единственное, что вам нужно сделать, это импортировать клиент PyTorch библиотеки SMDDP (smdistributed.dataparallel.torch.torch_smddp). Клиент регистрируется smddp в качестве бэкэнда для PyTorch.
После того, как у вас есть работающий скрипт PyTorch, адаптированный для использования параллельной библиотеки распределенных данных, вы можете запустить задание распределенного обучения с помощью SageMaker Python SDK.
Оценка производительности модели
При оценке эффективности системы рекомендаций крайне важно выбирать показатели, которые тесно связаны с бизнес-целями и обеспечивают четкое понимание эффективности модели. В нашем случае мы используем AUC для оценки эффективности прогнозирования кликов по вакансиям нашей модели TTDP и mAP@K для оценки качества окончательного ранжированного списка вакансий.
AUC относится к области под кривой рабочей характеристики приемника (ROC). Он представляет собой вероятность того, что случайно выбранный положительный пример будет оценен выше, чем случайно выбранный отрицательный пример. Он варьируется от 0 до 1, где 1 указывает на идеальный классификатор, а 0.5 представляет собой случайное предположение. mAP@K — это показатель, обычно используемый для оценки качества систем поиска информации, таких как наш механизм рекомендаций вакансий. Он измеряет среднюю точность получения K самых релевантных элементов для данного запроса или пользователя. Он варьируется от 0 до 1, где 1 указывает на оптимальное ранжирование, а 0 указывает на минимально возможную точность при данном значении K. Мы оцениваем AUC, mAP@1 и mAP@3. В совокупности эти показатели позволяют нам оценить способность модели различать положительные и отрицательные классы (AUC) и ее успех в ранжировании наиболее релевантных элементов наверху (mAP@K).
Согласно нашей автономной оценке, модель TTDP превзошла базовую модель — существующую производственную модель на основе XGBoost — на 16.65 % для AUC, на 20 % для mAP@1 и на 11.82 % для mAP@3.

Кроме того, мы разработали онлайн-тест A/B для оценки предлагаемой системы и провели тестирование на определенном проценте пользователей электронной почты в США в течение 6 недель. Всего с использованием задания, рекомендованного новой системой, было отправлено около 22 миллионов электронных писем. В результате прирост количества кликов по сравнению с предыдущей серийной моделью составил 8.6%. Talent.com постепенно увеличивает процент внедрения новой системы для всего населения и каналов.
Заключение
Создание системы рекомендаций по вакансиям — сложная задача. У каждого соискателя работы есть уникальные потребности, предпочтения и профессиональный опыт, которые невозможно определить по короткому поисковому запросу. В этом посте компания Talent.com в сотрудничестве с AWS разработала комплексное решение для рекомендации вакансий на основе глубокого обучения, которое ранжирует списки вакансий, которые можно рекомендовать пользователям. Команде Talent.com очень понравилось сотрудничать с командой AWS на протяжении всего процесса решения этой проблемы. Это знаменует собой важную веху в трансформационном пути Talent.com, поскольку команда использует возможности глубокого обучения для расширения возможностей своего бизнеса.
Этот проект был доработан с использованием SBERT для создания вложений текста. На момент написания AWS представила Вложения Amazon Titan как часть их основополагающих моделей (FM), предлагаемых через Коренная порода Амазонки, который представляет собой полностью управляемый сервис, предоставляющий выбор высокопроизводительных базовых моделей от ведущих компаний в области искусственного интеллекта. Мы призываем читателей изучить методы машинного обучения, представленные в этой записи блога, и использовать возможности AWS, такие как SMDDP, а также использовать базовые модели AWS Bedrock для создания собственных функций поиска.
Рекомендации
Об авторах
 Йи Сян является научным сотрудником второго уровня в лаборатории решений машинного обучения Amazon, где она помогает клиентам AWS в различных отраслях ускорить внедрение искусственного интеллекта и облачных технологий.
Йи Сян является научным сотрудником второго уровня в лаборатории решений машинного обучения Amazon, где она помогает клиентам AWS в различных отраслях ускорить внедрение искусственного интеллекта и облачных технологий.
 Тонг Ван — старший научный сотрудник лаборатории решений для машинного обучения Amazon, где он помогает клиентам AWS в различных отраслях ускорить внедрение ИИ и облачных технологий.
Тонг Ван — старший научный сотрудник лаборатории решений для машинного обучения Amazon, где он помогает клиентам AWS в различных отраслях ускорить внедрение ИИ и облачных технологий.
 Дмитрий Беспалов — старший научный сотрудник лаборатории решений для машинного обучения Amazon, где он помогает клиентам AWS в различных отраслях ускорить внедрение ИИ и облачных технологий.
Дмитрий Беспалов — старший научный сотрудник лаборатории решений для машинного обучения Amazon, где он помогает клиентам AWS в различных отраслях ускорить внедрение ИИ и облачных технологий.
 Анатолий Хоменко — старший инженер по машинному обучению в Talent.com, увлеченный обработкой естественного языка и подбирающий хороших людей для хорошей работы.
Анатолий Хоменко — старший инженер по машинному обучению в Talent.com, увлеченный обработкой естественного языка и подбирающий хороших людей для хорошей работы.
 Абденур Беззу — руководитель с более чем 25-летним опытом создания и предоставления технологических решений, которые масштабируются для миллионов клиентов. Абденур занимал должность технического директора (CTO) в Talent.com когда команда AWS разработала и реализовала это конкретное решение для Talent.com.
Абденур Беззу — руководитель с более чем 25-летним опытом создания и предоставления технологических решений, которые масштабируются для миллионов клиентов. Абденур занимал должность технического директора (CTO) в Talent.com когда команда AWS разработала и реализовала это конкретное решение для Talent.com.
 Дейл Жак — старший специалист по стратегии в области искусственного интеллекта в Инновационном центре генеративного искусственного интеллекта, где он помогает клиентам AWS воплощать бизнес-проблемы в решения на базе искусственного интеллекта.
Дейл Жак — старший специалист по стратегии в области искусственного интеллекта в Инновационном центре генеративного искусственного интеллекта, где он помогает клиентам AWS воплощать бизнес-проблемы в решения на базе искусственного интеллекта.
 Янцзюнь Ци является старшим менеджером по прикладным наукам в лаборатории решений Amazon для машинного обучения. Она внедряет инновации и применяет машинное обучение, чтобы помочь клиентам AWS ускорить внедрение ИИ и облачных технологий.
Янцзюнь Ци является старшим менеджером по прикладным наукам в лаборатории решений Amazon для машинного обучения. Она внедряет инновации и применяет машинное обучение, чтобы помочь клиентам AWS ускорить внедрение ИИ и облачных технологий.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- PlatoData.Network Вертикальный генеративный ИИ. Расширьте возможности себя. Доступ здесь.
- ПлатонАйСтрим. Интеллект Web3. Расширение знаний. Доступ здесь.
- ПлатонЭСГ. Углерод, чистые технологии, Энергия, Окружающая среда, Солнечная, Управление отходами. Доступ здесь.
- ПлатонЗдоровье. Биотехнологии и клинические исследования. Доступ здесь.
- Источник: https://aws.amazon.com/blogs/machine-learning/from-text-to-dream-job-building-an-nlp-based-job-recommender-at-talent-com-with-amazon-sagemaker/
- :имеет
- :является
- :нет
- :куда
- $UP
- 1
- 100
- 11
- 16
- 2011
- 22
- 25
- 30
- 31
- 32
- 75
- 8
- a
- способность
- в состоянии
- О нас
- ускорять
- точность
- точный
- через
- приспосабливать
- адаптированный
- адаптируются
- дополнение
- Принятие
- продвинутый
- плюс
- После
- против
- AI
- алгоритм
- выравнивать
- Все
- позволять
- Позволяющий
- позволяет
- причислены
- Несмотря на то, что
- Amazon
- Амазонское машинное обучение
- Создатель мудреца Амазонки
- Amazon Web Services
- количество
- an
- Ведущий
- и
- Применение
- прикладной
- применяется
- подхода
- примерно
- архитектура
- МЫ
- ПЛОЩАДЬ
- около
- AS
- оценить
- назначенный
- At
- привлекательный
- Auc
- Автоматический
- доступен
- в среднем
- AWS
- Backend
- основанный
- Базовая линия
- BE
- , так как:
- было
- ЛУЧШЕЕ
- Лучшая
- между
- Заблокировать
- Блог
- изоферменты печени
- Строительство
- построенный
- бизнес
- но
- by
- вычислять
- расчет
- CAN
- кандидат
- кандидатов
- возможности
- захватить
- захваченный
- Захват
- заботится
- случаев
- Центр
- Центры
- сложные
- каналы
- характеристика
- главный
- Главный технический директор
- Выберите
- выбранный
- классов
- классификация
- Очистить
- нажмите на
- клиент
- клиентов
- тесно
- облако
- принятие облака
- Кластер
- код
- сотрудничало
- сотрудничество
- сотрудничество
- коллективно
- COM
- сочетание
- объединять
- сочетании
- комбинаты
- обычно
- Связь
- Компании
- Компания
- сравнить
- сравненный
- сравнив
- конкурентоспособность
- полный
- комплекс
- компоненты
- расчеты
- Вычисление
- вычисление
- Условия
- Проводить
- Свяжитесь
- вследствие этого
- строить
- содержащегося
- содержание
- контекст
- контексты
- контекстной
- участник
- Основные
- соответствующий
- страны
- Создайте
- решающее значение
- CTO
- кривая
- Клиенты
- данным
- Подготовка данных
- Дата и время
- DDP
- Акции
- преданный
- глубоко
- глубокое обучение
- глубокие нейронные сети
- определять
- определенный
- доставки
- развертывание
- Производный
- Проект
- предназначенный
- проектирование
- подробнее
- развивать
- развитый
- DID
- различный
- обсуждается
- расстояние
- отчетливый
- выделить
- распределенный
- распределенное обучение
- распределительный
- распределение
- do
- документ
- домен
- мечта
- управляемый
- в течение
- каждый
- Рано
- Эффективный
- эффективность
- затрат
- эффективный
- 8
- элементы
- Писем
- вложения
- работодателей
- занятость
- расширение прав и возможностей
- поощрять
- впритык
- прилагать усилия
- обязательств
- Двигатель
- инженер
- инженерии
- Проект и
- Инженеры
- повышать
- Усиливает
- наслаждались
- обеспечивать
- обеспечивает
- лиц
- организация
- Окружающая среда
- средах
- налаживание
- Эфир (ETH)
- оценивать
- оценки
- оценка
- Каждая
- пример
- выполненный
- исполнительный
- существующий
- опыт
- Впечатления
- эксперты
- Больше
- выразительный
- извлечение
- быстрее
- Особенность
- Особенности
- несколько
- фигура
- окончательный
- Найдите
- Трансформируемость
- Фокус
- внимание
- после
- Что касается
- Войска
- 4
- Рамки
- от
- полностью
- функциональные возможности
- далее
- Gain
- калибр
- порождать
- генерирует
- порождающий
- генеративный
- Генеративный ИИ
- данный
- дает
- Цели
- хорошо
- GPU / ГРАФИЧЕСКИЙ ПРОЦЕССОР
- Графические процессоры
- постепенно
- Есть
- he
- Герой
- помощь
- помог
- помощь
- помогает
- High
- высокопроизводительный
- высший
- очень
- исторический
- история
- Как
- How To
- Однако
- HTML
- HTTP
- HTTPS
- Оптимизация гиперпараметра
- идеальный
- идентифицированный
- определения
- if
- ii
- иллюстрирует
- реализация
- Осуществляющий
- Импортировать
- важную
- улучшать
- улучшенный
- улучшение
- улучшение
- in
- включает в себя
- В том числе
- Увеличение
- повышение
- независимые
- самостоятельно
- указывает
- с указанием
- individual
- промышленности
- отраслевые
- информация
- свойственный
- Инновации
- вход
- затраты
- пример
- случаев
- инструментальный
- намерение
- взаимодействие
- взаимодействие
- интерес
- заинтересованный
- интересы
- в
- выпустили
- интуиция
- IT
- пункты
- ЕГО
- жаргон
- работа
- Поиск работы
- Предложения работы
- ищущие работу
- названия должностей
- Джобс
- присоединился
- совместная
- путешествие
- всего
- Сохранить
- Основные
- ключевые слова
- известный
- лаборатория
- этикетка
- язык
- Языки
- большой
- крупнейших
- наконец
- ведущий
- УЧИТЬСЯ
- изучение
- уровень
- Кредитное плечо
- Библиотека
- такое как
- Ограниченный
- линий
- Список
- Включенный в список
- листинг
- Объявления
- Списки
- загрузка
- расположение
- потери
- Низкий
- низший
- машина
- обучение с помощью машины
- Методы машинного обучения
- Главная
- сохранение
- сделать
- Создание
- управляемого
- менеджер
- многих
- отображение
- рынок
- Совпадение
- спички
- согласование
- математике
- Вопрос
- Май..
- значить
- значимым
- значения
- означает
- проводить измерение
- измеренный
- меры
- метод
- методологии
- Методология
- метрический
- Метрика
- может быть
- веха
- миллиона
- миллионы
- минимизировать
- Наша миссия
- ML
- модель
- моделирование
- Модели
- БОЛЕЕ
- самых
- с разными
- имя
- Названный
- имена
- натуральный
- Естественный язык
- Обработка естественного языка
- Необходимость
- потребности
- отрицательный
- негативах
- сеть
- сетей
- нервный
- нейронные сети
- Новые
- следующий
- НЛП
- узлы
- Шум
- нюансы
- полученный
- оккупация
- of
- предлагают
- предложенный
- сотрудник
- оффлайн
- on
- ONE
- онлайн
- только
- открытие
- операционный
- Возможности
- оптимальный
- оптимизация
- оптимизированный
- оптимизирует
- or
- заказ
- наши
- наш
- внешний
- превзошел
- выходной
- выходы
- за
- общий
- Преодолеть
- обзор
- собственный
- выплачен
- пара
- Параллельные
- параметры
- Первостепенный
- часть
- особый
- Прошло
- страсть
- мимо
- шаблон
- Люди
- процент
- выполнять
- производительность
- Персонализированные
- кусок
- Платформа
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- играет
- популярность
- население
- должность
- положительный
- возможное
- После
- потенциал
- мощностью
- мощный
- Точность
- предсказывать
- предсказанный
- прогноз
- предпочтения
- подготовка
- представить
- представлены
- предыдущий
- Простое число
- вероятность
- Проблема
- проблемам
- процедуры
- процесс
- Процессы
- обработка
- Произведенный
- Производство
- профессиональный
- Профиль
- Проект
- предложило
- обеспечивать
- при условии
- приводит
- обеспечение
- что такое варган?
- Питон
- pytorch
- Qi
- Запросы
- быстро
- случайный
- вошел
- Ранжирование
- ряды
- Обменный курс
- Сырье
- необработанные данные
- читатели
- признание
- рекомендовать
- Рекомендация
- рекомендаций
- Управление по борьбе с наркотиками (DEA)
- уменьшить
- снижает
- снижение
- относиться
- понимается
- рафинированный
- регистры
- отношения
- Отношения
- актуальность
- соответствующие
- надежность
- реплицируются
- представляет
- результат
- в результате
- Итоги
- Роли
- роли
- Катить
- Бег
- sagemaker
- Автоматическая настройка модели SageMaker
- то же
- Шкала
- планирование
- Наука
- Ученый
- Ученые
- множество
- скрипт
- Поиск
- поиск
- Раздел
- разделах
- выбор
- старший
- послать
- служит
- обслуживание
- Услуги
- набор
- Наборы
- установка
- она
- Короткое
- показывать
- показанный
- Шоу
- значительный
- существенно
- одинарной
- меньше
- Решение
- Решения
- Решение
- Источники
- Space
- конкретный
- конкретно
- конкретика
- скорость
- скорость
- стандарт
- современное состояние
- Шаг
- остановка
- хранить
- Стратег
- сильные
- строка
- предмет
- по существу
- успех
- такие
- синхронизация
- система
- системы
- взять
- принимает
- Талант
- Сложность задачи
- команда
- снижения вреда
- Технологии
- тестXNUMX
- Тестирование
- текст
- текстовый
- чем
- который
- Ассоциация
- Местоположение
- информация
- их
- Их
- тогда
- Эти
- они
- задача
- этой
- три
- Через
- по всему
- время
- раз
- исполин
- Название
- позиций
- в
- вместе
- топ
- факел
- Всего
- Башня
- Train
- Обучение
- преобразующей
- переведите
- Тройной
- по-настоящему
- два
- Типы
- под
- понимать
- понимание
- понимает
- созданного
- непревзойденный
- Предстоящие
- взброс
- us
- использование
- используемый
- Информация о пользователе
- пользователей
- использования
- через
- обычно
- использовать
- использует
- ценный
- Ценная информация
- ценностное
- с помощью
- vs
- законопроект
- we
- Web
- веб-сервисы
- Недели
- были
- когда
- в то время как
- который
- в то время как
- будете
- в
- работает
- мире
- письмо
- лет
- являетесь
- ВАШЕ
- зефирнет