Эта статья была опубликована в рамках Блогатон по Data Science
Введение
В этой статье мы рассмотрим другой подход к кластеризации K-средств, называемый иерархической кластеризацией. По сравнению с K-средним или K-режимом иерархическая кластеризация имеет другой алгоритм, лежащий в основе работы механизма кластеризации. Иерархическая кластеризация использует агломеративные или разделяющие методы, тогда как K-среднее использует комбинацию центроида и евклидова расстояния для формирования кластеров. Дендрограммы можно использовать для визуализации кластеров в иерархической кластеризации, что может помочь лучше интерпретировать результаты с помощью значимой таксономии. Нам не нужно указывать количество кластеров при построении дендрограммы.
Здесь мы используем Python для объяснения модели иерархической кластеризации. В нашем наборе данных есть данные о 200 клиентах торговых центров. В фрейм данных включаются идентификатор клиента, жанр, возраст, годовой доход и оценка расходов каждого клиента. Сумма, вычисляемая для каждого из баллов расходов их клиентов, основана на нескольких критериях, таких как их доход, количество раз в неделю, которое они посещают торговый центр, и сумма денег, которую они потратили за год. Этот балл варьируется от 1 до 100. Поскольку мы не знаем ответов, бизнес-проблема превращается в проблему кластеризации. Окончательные категории данных нам неизвестны. В результате наша цель - выявить ранее неизвестные кластеры клиентов.
Но сначала мы рассмотрим некоторые важные термины иерархической кластеризации.
Важные термины в иерархической кластеризации
Методы связи
Если есть (a) исходные наблюдения a [0],…, a [| a | 1] в кластере (a) и (b) исходные объекты b [0],…, b [| b | 1] в кластере ( б), то мы должны вычислить расстояние между двумя кластерами (а) и (б), чтобы объединить их (б). Допустим, есть точка (d), которая не была назначена ни одному из кластеров. Нам нужно будет выяснить, как далеко кластер (a) находится от кластера (d), а кластер (b) - от кластера (d).
Кластеры теперь обычно содержат несколько точек, поэтому требуется другой метод вычисления матрицы расстояний. Метод, с помощью которого рассчитывается расстояние между кластерами или расстояние от точки до кластера, определяется связью. Ниже приведены некоторые из наиболее часто используемых механизмов связи:
Одиночная связь - Расстояния между наиболее похожими элементами вычисляются для каждой пары кластеров, а затем кластеры объединяются на основе кратчайшего расстояния.
Средняя связь - Рассчитывается расстояние между всеми элементами одного кластера и всеми элементами другого кластера. После этого среднее значение этих расстояний используется для определения, какие кластеры будут сливаться.
Полная связь - Для каждой пары кластеров вычисляются расстояния между наиболее разнородными элементами, а затем кластеры объединяются на основе кратчайшего расстояния.
Среднее сцепление - Мы используем среднее расстояние вместо среднего расстояния так же, как и среднее расстояние.
Связь вард - Определяет расстояние между кластерами с помощью метода дисперсионного анализа.
Связь с центроидом - Центроид каждого кластера вычисляется путем усреднения всех точек, назначенных кластеру, а расстояние между кластерами затем вычисляется с использованием этого центроида.
Расчет расстояний
Существует несколько подходов к вычислению расстояния между двумя или более кластерами, наиболее популярным из которых является евклидово расстояние. Другие показатели расстояния, такие как Минковский, Городской квартал, Хэмминг, Жаккар и Чебышев, также могут использоваться с иерархической кластеризацией. Различные метрики расстояния влияют на иерархическую кластеризацию, как показано на рисунке 2.

Дендрограмма
Отношения между объектами в пространстве признаков представлены дендрограммой. В пространстве функций он используется для отображения расстояния между каждой парой последовательно соединенных объектов. Дендрограммы часто используются для изучения иерархических кластеров перед принятием решения о подходящем количестве кластеров для набора данных. Расстояние на дендрограмме - это расстояние между двумя кластерами, когда они объединяются. Расстояние дендрограммы определяет, являются ли два или более кластера непересекающимися или могут быть объединены вместе, чтобы сформировать единый кластер.
Пример
Теперь мы рассмотрим примеры использования Python, чтобы продемонстрировать модель иерархической кластеризации. В нашем Набор данных. Во фрейм данных включаются идентификатор клиента, жанр, возраст, годовой доход и оценка расходов. Сумма, вычисляемая для каждого из баллов расходов их клиентов, основана на нескольких критериях, таких как их доход, количество посещений торгового центра в неделю и деньги, которые они потратили в течение года. Этот балл варьируется от 1 до 100. Поскольку мы не знаем ответов, бизнес-проблема превращается в проблему кластеризации.
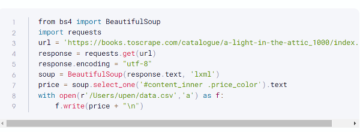
# 1 Импорт библиотек импортировать numpy как np import matplotlib.pyplot as plt import pandas as pd
# 2 Импорт набора данных Mall_Customers с помощью pandas
dataset = pd.read_csv ('Mall_Customers.csv') X = dataset.iloc [:, [3,4]]. значения
Этот новый шаг в иерархической кластеризации также влечет за собой определение оптимального количества кластеров. На этот раз мы не будем использовать метод локтя. Воспользуемся дендрограммой.
# 3 Использование дендрограммы, чтобы найти оптимальное количество кластеров. # Первое, что мы собираемся сделать, это импортировать scipy-библиотеку. scipy - это библиотека Python с открытым исходным кодом, которая содержит инструменты для иерархической кластеризации и построения дендрограмм. # Импортируйте только необходимый инструмент. импортировать scipy.cluster.hierarchy как sch
# Давайте создадим переменную дендрограммы Это дендрограмма набора данных X = sch.dendrogram (sch.linkage (X, method = "ward")) plt.title ('Дендрограмма') plt.xlabel ('Клиенты') plt.ylabel ('Евклидовы расстояния') plt. Показать()
Метод Уорда - это метод, который пытается уменьшить дисперсию в каждом кластере. Это почти то же самое, что и при использовании K-средних для минимизации wcss для построения нашей диаграммы метода локтя; единственная разница в том, что вместо wcss мы минимизируем варианты внутри кластера. Внутри каждого кластера это дисперсия. Дендрограмма представлена ниже.

Клиенты представлены на оси x, а евклидово расстояние между кластерами представлено на оси y. Как определить наилучшее количество кластеров на основе этой диаграммы? Мы хотим найти самое длинное вертикальное расстояние, которое мы можем, не пересекая горизонтальные линии, это линия в красной рамке на диаграмме выше. Давайте посчитаем линии на диаграмме и выясним, сколько кластеров лучше всего. Для этого набора данных номер кластера будет 5.
# 4 Подгонка иерархической кластеризации к набору данных Mall_Customes # Существует два алгоритма иерархической кластеризации: агломеративная иерархическая кластеризация и # разделительная иерархическая кластеризация. Мы выбираем евклидово расстояние и метод защиты для нашего # класса алгоритма из sklearn.cluster import AgglomerativeClustering hc = AgglomerativeClustering (n_clusters = 5, affinity = 'euclidean', linkage = 'ward') # Давайте попробуем подогнать алгоритм иерархической кластеризации к набору данных X при создании вектора # кластеров, который сообщает каждому клиенту, к какому кластеру он принадлежит. y_hc = hc.fit_predict (X)
# 5 Визуализация кластеров. Этот код похож на код визуализации k-means. # Мы заменяем только имя вектора y_kmeans на y_hc для иерархической кластеризации plt.scatter (X [y_hc == 0, 0], X [y_hc == 0, 1], s = 100, c = 'red', label = 'Cluster 1') plt.scatter (X [y_hc == 1, 0], X [y_hc == 1, 1], s = 100, c = 'blue', label = 'Cluster 2') plt.scatter ( X [y_hc == 2, 0], X [y_hc == 2, 1], s = 100, c = 'green', label = 'Cluster 3') plt.scatter (X [y_hc == 3, 0] , X [y_hc == 3, 1], s = 100, c = 'cyan', label = 'Cluster 4') plt.scatter (X [y_hc == 4, 0], X [y_hc == 4, 1 ], s = 100, c = 'magenta', label = 'Cluster 5') plt.title ('Clusters of Customers (Hierarchical Clustering Model)') plt.xlabel ('Annual Income (k $)') plt.ylabel ('Оценка расходов (1-100') plt.show ()

Эти кластеры можно рассматривать как клиентский сегмент торгового центра.

Это все, что нужно для стандартной модели иерархической кластеризации. Набор данных, а также все коды доступны в разделе Github.
Заключение
В любом упражнении по кластеризации определение количества кластеров - это трудоемкий процесс. Поскольку коммерческая сторона бизнеса больше заинтересована в извлечении смысла из этих групп, очень важно визуализировать кластеры в двух измерениях и видеть, различны ли они. Для достижения этой цели можно использовать PCA или факторный анализ. Это распространенный метод представления окончательных результатов различным заинтересованным сторонам, что упрощает их использование для всех.
EndNote
Спасибо за чтение!
Надеюсь, вам понравилась статья и вы расширили свои знания.
Пожалуйста, не стесняйтесь обращаться ко мне on Эл. адрес
Что-то не упомянуто или хотите поделиться своими мыслями? Не стесняйтесь комментировать ниже, и я вернусь к вам.
Об авторе
Хардиккумар М. Дхадук
Аналитик данных | Специалист по анализу цифровых данных | Ученик в области науки о данных
Связаться со мной на LinkedIn
Связаться со мной на Github
Медиа, показанные в этой статье, не принадлежат Analytics Vidhya и используются по усмотрению автора.
Похожие страницы:
Источник: https://www.analyticsvidhya.com/blog/2021/08/hierarchical-clustering-algorithm-python/
- 100
- алгоритм
- алгоритмы
- Все
- анализ
- аналитик
- аналитика
- гайд
- ЛУЧШЕЕ
- Строительство
- бизнес
- Город
- код
- коммерческая
- Общий
- потреблять
- Создающий
- Клиенты
- данным
- анализ данных
- наука о данных
- Интернет
- расстояние
- Упражнение
- Особенность
- фигура
- First
- соответствовать
- форма
- Бесплатно
- GIF
- GitHub
- Зелёная
- Как
- HTTPS
- Влияние
- импортирующий
- доход
- IT
- знания
- Библиотека
- линия
- Создание
- Медиа
- Участники
- Метрика
- модель
- деньги
- Самые популярные
- номера
- открытый
- с открытым исходным кодом
- заказ
- Другие контрактные услуги
- Популярное
- Питон
- RE
- уменьшить
- Итоги
- Наука
- Поделиться
- Space
- Расходы
- говорит
- время
- us
- визуализация
- неделя
- в
- работает
- X
- год