Концепция Amazon Search заключается в том, чтобы позволить клиентам выполнять поиск без особых усилий. Наша коррекция орфографии поможет вам найти то, что вы хотите, даже если вы не знаете точного написания предполагаемых слов. В прошлом мы использовали классические алгоритмы машинного обучения (ML) с ручной разработкой функций для исправления орфографии. Чтобы совершить следующий скачок в производительности исправления орфографии, мы используем ряд подходов к глубокому обучению, включая модели последовательностей. Модели глубокого обучения (ГО) требуют интенсивных вычислений как при обучении, так и при выводе, и эти затраты исторически делали модели ГО непрактичными в производственных условиях в масштабах Amazon. В этом посте мы представляем результаты эксперимента по оптимизации логического вывода, в ходе которого мы преодолеваем эти препятствия и обеспечиваем ускорение логического вывода на 534 % для популярного преобразователя Hugging Face T5.
Вызов
Преобразователь преобразования текста в текст (T5, Изучение границ трансферного обучения с помощью унифицированного преобразователя текста в текст, Реффель и др.) — это современная архитектура модели обработки естественного языка (NLP). T5 — многообещающая архитектура для исправления орфографии, которая, как мы обнаружили в наших экспериментах, показала хорошие результаты. Модели T5 легко исследовать, разрабатывать и обучать благодаря платформам глубокого обучения с открытым исходным кодом и текущим академическим и корпоративным исследованиям.
Тем не менее, с T5 трудно добиться логического вывода промышленного уровня с малой задержкой. Например, один вывод с помощью PyTorch T5 занимает 45 миллисекунд на одном из четырех графических процессоров NVIDIA V100 с тензорными ядрами, оснащенных инстансом Amazon Elastic Compute Cloud (EC2) p3.8xlarge. (Все представленные логические числа относятся к вводу 9 токенов и выводу 11 токенов. Задержка архитектур T5 чувствительна как к длине ввода, так и к длине вывода.)
Экономичный логический вывод T5 с малой задержкой в масштабе — это известная проблема, о которой сообщили несколько клиентов AWS за пределами Amazon Search, что повышает нашу мотивацию для публикации этой публикации. Чтобы перейти от автономного научного достижения к производственной службе, ориентированной на клиента, Amazon Search сталкивается со следующими проблемами:
- Задержка – Как реализовать вывод T5 с задержкой P50 менее 99 мс.
- Увеличить пропускную способность – Как обрабатывать крупномасштабные параллельные запросы на вывод
- Эффективность затрат - Как держать расходы под контролем
В оставшейся части этого поста мы объясним, как стек оптимизации логического вывода NVIDIA, а именно NVIDIA ТензорРТ компилятор и открытый исходный код Сервер вывода NVIDIA Triton— решает эти задачи. Читать пресс-релиз NVIDIA узнать об обновлениях.
NVIDIA TensorRT: сокращение расходов и задержек за счет оптимизации логических выводов
Фреймворки глубокого обучения удобны для быстрого итерации в науке и имеют множество функций для научного моделирования, загрузки данных и оптимизации обучения. Однако большинство этих инструментов неоптимальны для логических выводов, для которых требуется лишь минимальный набор операторов для умножения матриц и функций активации. Таким образом, значительные преимущества могут быть достигнуты с помощью специализированного приложения, предназначенного только для прогнозирования, вместо выполнения логических выводов в среде разработки глубокого обучения.
NVIDIA TensorRT — это SDK для высокопроизводительного вывода на основе глубокого обучения. TensorRT обеспечивает как оптимизированную среду выполнения с использованием низкоуровневых оптимизированных ядер, доступных на графических процессорах NVIDIA, так и граф модели, предназначенный только для вывода, который перестраивает вычисления вывода в оптимизированном порядке.
В следующем разделе мы поговорим о деталях, лежащих в основе TensorRT, и о том, как он повышает производительность.

- Снижение точности максимизирует пропускную способность с помощью FP16 или INT8 путем квантования моделей при сохранении правильности.
- Слияние слоев и тензоров оптимизирует использование памяти и пропускной способности графического процессора, объединяя узлы в ядре, чтобы избежать задержки запуска ядра.
- Автонастройка ядра выбирает лучшие уровни данных и алгоритмы на основе целевой платформы графического процессора и форм ядра данных.
- Динамическая тензорная память минимизирует объем памяти, освобождая ненужное потребление памяти для промежуточных результатов и эффективно повторно использует память для тензоров.
- Многопотоковое выполнение использует масштабируемый дизайн для параллельной обработки нескольких входных потоков с выделенными потоками CUDA.
- Слияние времени оптимизирует рекуррентные нейронные сети по временным шагам с динамически генерируемыми ядрами.
T5 использует слои преобразователя в качестве строительных блоков для своих архитектур. В последнем выпуске NVIDIA TensorRT 8.2 представлены новые оптимизации для моделей T5 и GPT-2 для логических выводов в реальном времени. В следующей таблице мы видим ускорение с помощью TensorRT на некоторых общедоступных моделях T5, работающих на инстансах Amazon EC2G4dn с графическими процессорами NVIDIA T4, и инстансах EC2 G5 с графическими процессорами NVIDIA A10G.
| Модель | Пример | Базовая задержка Pytorch (мс) | Задержка TensorRT 8.2 (мс) | Ускорение по сравнению с базовой линией HF | ||||||||
| FP32 | FP32 | FP16 | FP32 | FP16 | ||||||||
| кодировщик | дешифратор | Концы с концами | кодировщик | дешифратор | Концы с концами | кодировщик | дешифратор | Концы с концами | Концы с концами | Концы с концами | ||
| т5-маленький | g4dn.xlarge | 5.98 | 9.74 | 30.71 | 1.28 | 2.25 | 7.54 | 0.93 | 1.59 | 5.91 | 407.40% | 519.34% |
| g5.xlarge | 4.63 | 7.56 | 24.22 | 0.61 | 1.05 | 3.99 | 0.47 | 0.80 | 3.19 | 606.66% | 760.01% | |
| т5-база | g4dn.xlarge | 11.61 | 19.05 | 78.44 | 3.18 | 5.45 | 19.59 | 3.15 | 2.96 | 13.76 | 400.48% | 569.97% |
| g5.xlarge | 8.59 | 14.23 | 59.98 | 1.55 | 2.47 | 11.32 | 1.54 | 1.65 | 8.46 | 530.05% | 709.20% | |
Для получения дополнительной информации об оптимизации и воспроизведении присоединенной производительности см. Оптимизация T5 и GPT-2 для логического вывода в реальном времени с помощью NVIDIA TensorRT.
Важно отметить, что компиляция сохраняет точность модели, поскольку она работает со средой логического вывода и планированием вычислений, оставляя науку о модели неизменной — в отличие от сжатия с удалением веса, такого как дистилляция или обрезка. NVIDIA TensorRT позволяет комбинировать компиляцию с квантованием для дальнейшего выигрыша. Квантование имеет двойное преимущество на новейшем оборудовании NVIDIA: оно уменьшает использование памяти и позволяет использовать тензорные ядра NVIDIA, ячейки, специфичные для машинного обучения, которые выполняют объединенную матрицу-умножение-сложение со смешанной точностью.
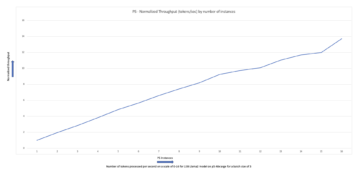
В случае эксперимента Amazon Search с моделью Hugging Face T5 замена PyTorch на TensorRT для вывода модели увеличивает скорость на 534%.
NVIDIA Triton: обслуживание логических выводов с малой задержкой и высокой пропускной способностью
Современные решения для обслуживания моделей могут преобразовать модели, обученные в автономном режиме, в ориентированные на клиента продукты на основе машинного обучения. Чтобы поддерживать разумные затраты в таком масштабе, важно поддерживать низкие накладные расходы на обслуживание (обработка HTTP, предварительная и постобработка, связь ЦП и ГП) и в полной мере использовать возможности параллельной обработки графических процессоров.
NVIDIA Triton — это программное обеспечение для обработки логических выводов, предлагающее широкую поддержку сред выполнения моделей (среди прочего, NVIDIA TensorRT, ONNX, PyTorch, XGBoost) и инфраструктурных серверных частей, включая графические процессоры, ЦП и Инферентия AWS.
Специалисты по машинному обучению любят Triton по нескольким причинам. Его динамическая пакетная способность позволяет накапливать запросы на вывод в течение определяемой пользователем задержки и в пределах максимального размера пакета, определяемого пользователем, так что вывод графического процессора группируется, амортизируя накладные расходы на связь ЦП-ГП. Обратите внимание, что динамическая пакетная обработка происходит на стороне сервера и в очень короткие промежутки времени, так что запрашивающий клиент по-прежнему имеет синхронный вызов в режиме, близком к реальному времени. Пользователям Triton также нравится возможность параллельного выполнения моделей. Графические процессоры — это мощные многозадачные устройства, которые отлично справляются с параллельным выполнением ресурсоемких рабочих нагрузок. Triton максимизирует использование графического процессора и пропускную способность, используя потоки CUDA для одновременного запуска нескольких экземпляров модели. Эти экземпляры модели могут быть разными моделями из разных фреймворков для разных вариантов использования или прямой копией одной и той же модели. Это приводит к прямому улучшению пропускной способности, когда у вас достаточно свободной памяти графического процессора. Кроме того, поскольку Triton не привязан к конкретной среде разработки DL, он позволяет ученым полностью выразить себя с помощью инструмента по своему выбору.
Благодаря Triton на AWS Amazon Search ожидает лучшего обслуживания Amazon.com клиентов и удовлетворять требования к задержке при низких затратах. Тесная интеграция между средой выполнения TensorRT и сервером Triton упрощает процесс разработки. Использование облачной инфраструктуры AWS позволяет увеличивать или уменьшать масштаб за считанные минуты в зависимости от требований к пропускной способности, сохраняя при этом высокую планку надежности и безопасности.
Как AWS снижает входной барьер
Хотя Amazon Search провел этот эксперимент на инфраструктуре Amazon EC2, существуют и другие сервисы AWS, которые облегчают разработку, обучение и размещение передовых решений для глубокого обучения.
Например, AWS и NVIDIA совместно выпустили управляемую реализацию Triton Inference Server в Создатель мудреца Амазонки ; для получения дополнительной информации см. Развертывайте быстрый и масштабируемый ИИ с помощью NVIDIA Triton Inference Server в Amazon SageMaker. AWS также сотрудничала с Hugging Face для разработки управляемой оптимизированной интеграции между Amazon SageMaker и Hugging Face Transformers — платформой с открытым исходным кодом, на основе которой создана модель Amazon Search T5; читать больше на https://aws.amazon.com/machine-learning/hugging-face/.
Мы рекомендуем клиентам с чувствительными к задержкам приложениями для глубокого обучения ЦП и ГП, чтобы рассмотреть NVIDIA TensorRT и Triton на AWS. Дайте нам знать, что вы строите!
Увлекаетесь глубоким обучением и созданием решений на основе глубокого обучения для Amazon Search? Проверьте наши страница карьеры.
Об авторах
 RJ — инженер команды Search M5, возглавляющей усилия по созданию крупномасштабных систем глубокого обучения для обучения и логического вывода. Вне работы он пробует разные кухни и занимается спортом с ракеткой.
RJ — инженер команды Search M5, возглавляющей усилия по созданию крупномасштабных систем глубокого обучения для обучения и логического вывода. Вне работы он пробует разные кухни и занимается спортом с ракеткой.
 Хемант Пугалия является прикладным ученым в Search M5. Он работает над применением новейших исследований в области обработки естественного языка и глубокого обучения, чтобы улучшить качество обслуживания клиентов при совершении покупок на Amazon по всему миру. Его исследовательские интересы включают обработку естественного языка и крупномасштабные системы машинного обучения. Вне работы он любит ходить в походы, готовить и читать.
Хемант Пугалия является прикладным ученым в Search M5. Он работает над применением новейших исследований в области обработки естественного языка и глубокого обучения, чтобы улучшить качество обслуживания клиентов при совершении покупок на Amazon по всему миру. Его исследовательские интересы включают обработку естественного языка и крупномасштабные системы машинного обучения. Вне работы он любит ходить в походы, готовить и читать.
 Энди Сан является инженером-программистом и техническим руководителем по исправлению орфографии при поиске. Его исследовательские интересы включают оптимизацию задержки логического вывода при глубоком обучении и создание платформ для быстрых экспериментов. Вне работы он увлекается кино и акробатикой.
Энди Сан является инженером-программистом и техническим руководителем по исправлению орфографии при поиске. Его исследовательские интересы включают оптимизацию задержки логического вывода при глубоком обучении и создание платформ для быстрых экспериментов. Вне работы он увлекается кино и акробатикой.
 Ле Кай работает инженером-программистом в Amazon Search. Он работает над улучшением функции исправления орфографии в поиске, чтобы помочь клиентам совершать покупки. Он занимается высокопроизводительным онлайн-логическим выводом и оптимизацией распределенного обучения для модели глубокого обучения. Вне работы он любит кататься на лыжах, ходить в походы и кататься на велосипеде.
Ле Кай работает инженером-программистом в Amazon Search. Он работает над улучшением функции исправления орфографии в поиске, чтобы помочь клиентам совершать покупки. Он занимается высокопроизводительным онлайн-логическим выводом и оптимизацией распределенного обучения для модели глубокого обучения. Вне работы он любит кататься на лыжах, ходить в походы и кататься на велосипеде.
 Энтони Ко в настоящее время работает инженером-программистом в Search M5 Palo Alto, CA. Он работает над созданием инструментов и продуктов для развертывания моделей и оптимизации логических выводов. Вне работы он любит готовить и играть в ракетки.
Энтони Ко в настоящее время работает инженером-программистом в Search M5 Palo Alto, CA. Он работает над созданием инструментов и продуктов для развертывания моделей и оптимизации логических выводов. Вне работы он любит готовить и играть в ракетки.
 Оливье Крючан является специалистом по машинному обучению и архитектором решений в AWS, базирующейся во Франции. Оливье помогает клиентам AWS — от небольших стартапов до крупных предприятий — разрабатывать и развертывать приложения машинного обучения производственного уровня. В свободное время он любит читать исследовательские работы и исследовать пустыню с друзьями и семьей.
Оливье Крючан является специалистом по машинному обучению и архитектором решений в AWS, базирующейся во Франции. Оливье помогает клиентам AWS — от небольших стартапов до крупных предприятий — разрабатывать и развертывать приложения машинного обучения производственного уровня. В свободное время он любит читать исследовательские работы и исследовать пустыню с друзьями и семьей.
 Аниш Мохан является архитектором машинного обучения в NVIDIA и техническим руководителем по взаимодействию машинного обучения и глубокого обучения со своими клиентами в Большом Сиэтле.
Аниш Мохан является архитектором машинного обучения в NVIDIA и техническим руководителем по взаимодействию машинного обучения и глубокого обучения со своими клиентами в Большом Сиэтле.
 Цзяхонг Лю является архитектором решений в команде поставщиков облачных услуг в NVIDIA. Он помогает клиентам внедрить решения для машинного обучения и искусственного интеллекта, которые используют ускоренные вычисления NVIDIA для решения их задач обучения и логических выводов. В свободное время он увлекается оригами, проектами «сделай сам» и играет в баскетбол.
Цзяхонг Лю является архитектором решений в команде поставщиков облачных услуг в NVIDIA. Он помогает клиентам внедрить решения для машинного обучения и искусственного интеллекта, которые используют ускоренные вычисления NVIDIA для решения их задач обучения и логических выводов. В свободное время он увлекается оригами, проектами «сделай сам» и играет в баскетбол.
 Элиут Триана является менеджером по связям с разработчиками в NVIDIA. Он связывает руководителей продуктов, разработчиков и ученых Amazon и AWS с технологами и руководителями продуктов NVIDIA, чтобы ускорить рабочие нагрузки Amazon ML/DL, продукты EC2 и сервисы AWS AI. Кроме того, Элиут страстный байкер, лыжник и игрок в покер.
Элиут Триана является менеджером по связям с разработчиками в NVIDIA. Он связывает руководителей продуктов, разработчиков и ученых Amazon и AWS с технологами и руководителями продуктов NVIDIA, чтобы ускорить рабочие нагрузки Amazon ML/DL, продукты EC2 и сервисы AWS AI. Кроме того, Элиут страстный байкер, лыжник и игрок в покер.
- Коинсмарт. Лучшая в Европе биржа биткойнов и криптовалют.
- Платоблокчейн. Интеллект метавселенной Web3. Расширение знаний. БЕСПЛАТНЫЙ ДОСТУП.
- КриптоХок. Альткоин Радар. Бесплатная пробная версия.
- Источник: https://aws.amazon.com/blogs/machine-learning/how-amazon-search-achieves-low-latency-high-throughput-t5-inference-with-nvidia-triton-on-aws/
- "
- 100
- 11
- 9
- О нас
- ускорять
- ускоренный
- дополнение
- адрес
- плюс
- AI
- Услуги искусственного интеллекта
- алгоритмы
- Все
- Amazon
- среди
- Применение
- Приложения
- Применение
- архитектура
- доступен
- AWS
- Баскетбол
- Преимущества
- ЛУЧШЕЕ
- Строительство
- Пропускная способность
- случаев
- проблемы
- облако
- облачная инфраструктура
- Связь
- Вычисление
- вычисление
- потребление
- способствовать
- Удобно
- Основные
- Расходы
- опыт работы с клиентами
- Клиенты
- данным
- преданный
- задерживать
- обеспечивает
- развертывание
- развертывание
- Проект
- развивать
- Застройщик
- застройщиков
- Развитие
- различный
- направлять
- распределенный
- Сделай сам
- двойной
- вниз
- динамический
- усилия
- поощрять
- инженер
- Проект и
- Предприятие
- Окружающая среда
- пример
- Excel
- выполнение
- надеется
- опыт
- эксперимент
- Face
- лица
- семья
- БЫСТРО
- Особенность
- после
- питание
- след
- найденный
- Рамки
- Франция
- GPU / ГРАФИЧЕСКИЙ ПРОЦЕССОР
- Управляемость
- Аппаратные средства
- помощь
- помогает
- High
- Как
- How To
- HTTPS
- реализация
- важную
- улучшать
- включают
- В том числе
- информация
- Инфраструктура
- интеграции.
- интересы
- IT
- известный
- язык
- большой
- последний
- запуск
- вести
- ведущий
- УЧИТЬСЯ
- изучение
- Кредитное плечо
- любят
- машина
- обучение с помощью машины
- поддерживать
- управляемого
- менеджер
- руководство
- матрица
- Память
- смешанный
- ML
- модель
- Модели
- БОЛЕЕ
- самых
- MS
- натуральный
- сетей
- узлы
- номер
- номера
- многочисленный
- онлайн
- открытый
- с открытым исходным кодом
- оптимизация
- заказ
- Другое
- производительность
- Платформа
- Платформы
- игрок
- Популярное
- мощный
- представить
- нажмите
- процесс
- Продукт
- Производство
- Продукция
- проектов
- многообещающий
- что такое варган?
- Reading
- реального времени
- реализованный
- разумный
- причины
- снижение
- освободить
- Требования
- исследованиям
- ОТДЫХ
- Итоги
- Run
- Бег
- масштабируемые
- Шкала
- Наука
- Ученый
- Ученые
- SDK
- Поиск
- безопасность
- обслуживание
- Услуги
- выступающей
- набор
- установка
- формы
- Шоппинг
- Короткое
- значительный
- Размер
- небольшой
- So
- Software
- Инженер-программист
- Решение
- Решения
- специализированный
- скорость
- Спорт
- Стартапы
- современное состояние
- поддержка
- системы
- Говорить
- цель
- команда
- Технический
- технологов
- Связанный
- время
- Лексемы
- инструментом
- инструменты
- Обучение
- Transform
- Updates
- us
- использование
- пользователей
- видение
- Что
- в
- слова
- Работа
- работает
- работает
- по всему миру