В этой статье вы узнаете о различных методах преобразования PDF в Google Таблицы.
Вы также узнаете, как нанонеты могут автоматизировать весь рабочий процесс преобразования PDF в Google Sheets онлайн.
Прежде чем мы рассмотрим, как конвертировать PDF в Google Таблицы, давайте посмотрим, почему это важно сделать.
Зачем конвертировать PDF-файлы в Google Таблицы?
В соответствии с этим Блог Google сообщение с официальной страницы блога Google, более 5 миллионов компаний используют их решение G Suite. В то же время большое количество компаний также начали использовать интеграции с Google Таблицами для автоматизации задач.
Рассмотрим типичный вариант использования. Ваша группа по работе с кредиторской задолженностью получит счет в стандартном формате PDF. Кто-то вручную просматривает счет и вводит необходимую информацию в документ Google Таблиц, прежде чем направить ее в раздел Финансы. Финансовый отдел платит вашему поставщику и делает запись в бухгалтерской книге компании.
Помимо того, что это длительный процесс, он подвержен ошибкам, и было бы гораздо разумнее просто автоматизировать его.
Теперь, когда необходимость преобразования PDF-файлов в форму листа Google очевидна, давайте посмотрим, как структурированы PDF-документы и какие проблемы возникают при их анализе.
Хотите преобразовать PDF файлы Таблицы Google ? Проверять, выписываться Нанонец бесплатно Конвертер PDF в CSV. Или узнать, как автоматизируйте весь рабочий процесс преобразования PDF в Google Sheets с помощью Nanonets.
Проблемы с анализом PDF-документа
Формат переносимых документов был форматом файлов, первоначально разработанным Adobe, а затем выпущенным как открытый стандарт. С тех пор он получил широкое распространение, поскольку не зависит от базовой операционной системы.
Итак, почему так сложно разобрать PDF-файл и преобразовать его содержимое в другой формат? Следующие изображения говорят тысячу слов и убедят вас в этом.
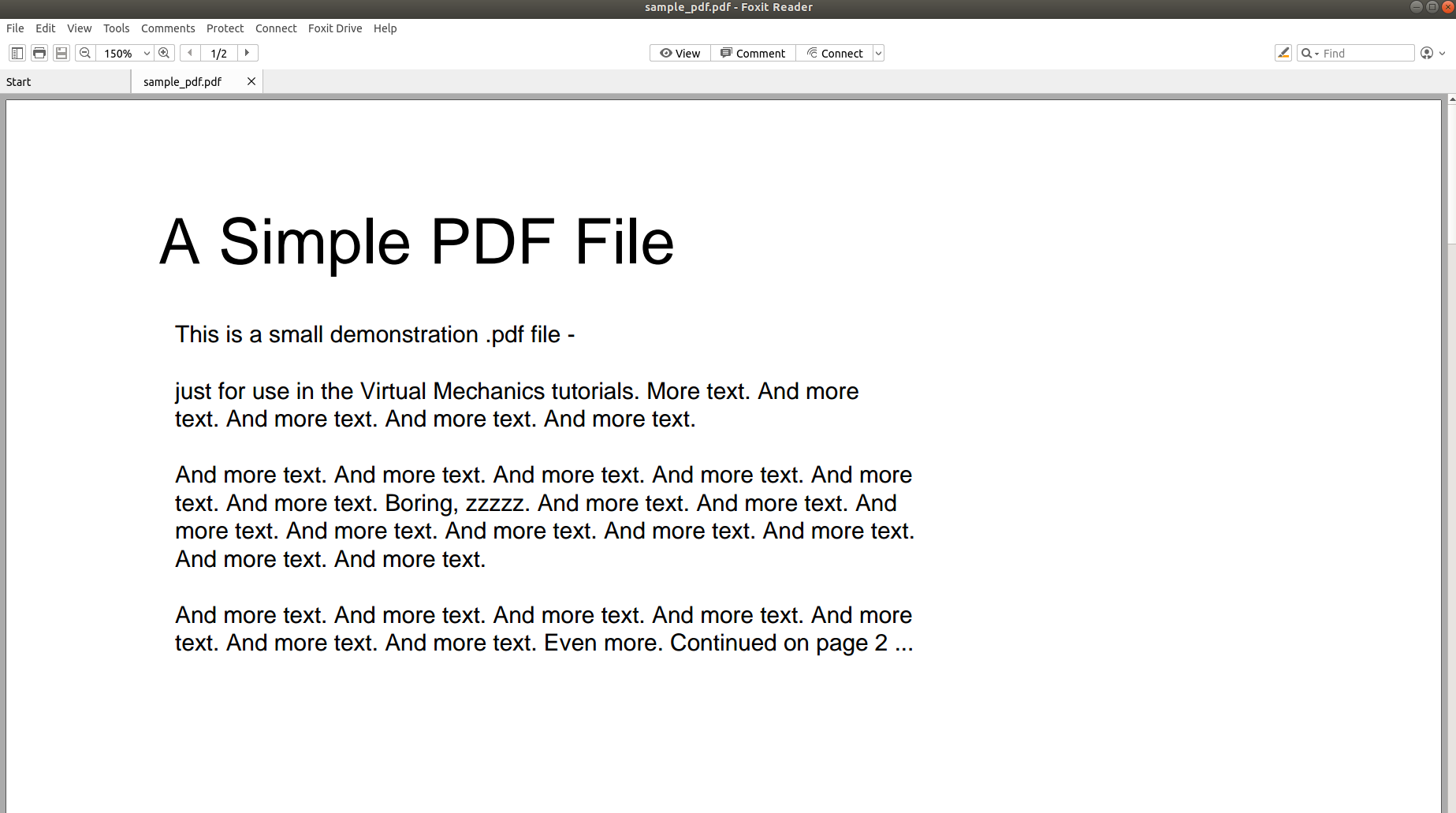
На изображении выше показан снимок экрана документа PDF, который открывается с помощью программы для чтения PDF-файлов. Попробуем открыть тот же PDF-документ в текстовом редакторе.
Из приведенных выше изображений видно, что при сохранении информации в PDF-файле ее исходная структура полностью теряется. Это связано с тем, что формат PDF просто состоит из инструкций о том, как распечатать / нарисовать последовательность символов на странице.
Если вы считаете, что извлечение текста является сложной задачей, извлечение данных, представленных в таблицах, становится еще более сложной задачей из-за большого количества используемых табличных форматов.
Надеюсь, вы убедились, что преобразование документа PDF в форму Google Таблиц - это не прогулка по парку. В следующем разделе рассказывается о подходе, используемом большинством современных парсеров PDF для распознавания / анализа информации из документа PDF.
Современный подход к разбору PDF-документов
Большинство современных анализаторов PDF используют описанный ниже поток для анализа неструктурированных данных из документов PDF.
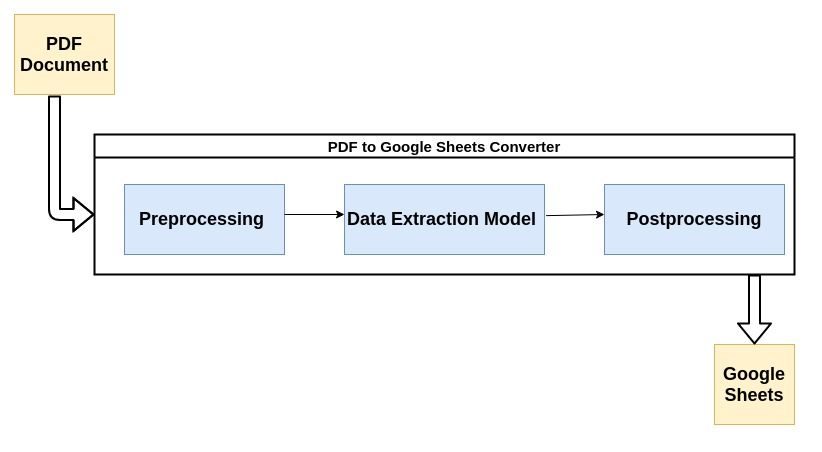
Давайте кратко рассмотрим каждый этап процесса:
1. Предварительная обработка или очистка данных:
Чем лучше выглядит ваш PDF-файл, тем легче вашей модели машинного обучения будет извлекать или захватывать данные от него. Например, если PDF-документ был отсканирован, он обязательно будет содержать некоторые артефакты сканирования, которые могут повлиять на производительность конвертера.
Удаление шума с помощью соответствующих фильтров, бинаризации, коррекции перекоса и т. Д. Являются одними из наиболее распространенных этапов предварительной обработки. Следующий пост Nanonets Нанонец Тессеракт Пост содержит несколько замечательных примеров того, как документы могут быть предварительно обработаны перед Оптическое распознавание символов(OCR) запускается на них.
Здесь происходит большая часть волшебства. Извлечение данных обычно выполняется с помощью модели машинного обучения (ML). Большинство моделей машинного обучения, используемых для извлечения данных из PDF-файлов, содержат комбинацию инструментов оптического распознавания символов, инструментов распознавания текста и образов и т. Д.
В рамках этого поста мы можем рассматривать модель как черный ящик, который принимает ваш PDF-документ в качестве входных данных и выводит проанализированную информацию. Кроме того, поскольку он использует машинное обучение в своей основе, его можно переобучить с помощью пользовательских данных, чтобы они соответствовали сценарию использования вашей компании.
3. Постобработка:
На этом этапе извлеченные данные преобразуются в требуемый формат, такой как CSV, XML, JSON и т. Д. Кроме того, к прогнозам, сделанным ИИ, добавляются дополнительные правила, определяемые пользователем. Это может включать правила форматирования вывода, дополнительные ограничения на извлекаемую информацию и т. Д.
В следующем разделе рассматриваются некоторые показатели, которые мы могли бы использовать для измерения производительности парсера PDF.
Хотите преобразовать PDF файлы Таблицы Google ? Проверять, выписываться Нанонец бесплатно Конвертер PDF в CSV. Узнайте, как автоматизировать весь рабочий процесс преобразования PDF в Google Таблицы с помощью Nanonets.

Метрики для измерения производительности конвертера PDF
Поскольку большинство конвертеров PDF будут использоваться для обработки счетов или связанных задач, точность и скорость извлечения таблиц из документа PDF являются критическим фактором при оценке производительности конвертера PDF.
2. Многоязычие:
Большинство крупных компаний обязаны получать счета на разных языках. Анализатор PDF должен либо поддерживать многоязычный синтаксический анализ из коробки, либо предоставлять возможность, с помощью которой пользователи могут обучать модель с использованием пользовательских данных.
3. Интеграция с бухгалтерским ПО:
Идеальный конвертер PDF должен быть модулем plug and play, который можно легко добавить к существующему документооборот. Он должен поддерживать интеграцию с популярными бухгалтерскими программами, такими как QuickBooks, Xero, Wave и т. д.
4. Легко и интуитивно понятно:
Скорее всего, инструментом будут пользоваться нетехнические пользователи. Было бы выгодно, если бы им можно было управлять с минимальными техническими знаниями.
Различные методы преобразования PDF-файлов в Google Таблицы
1. Использование Google Docs для преобразования PDF в Google Sheets
Google Диск имеет встроенную функцию распознавания таблиц и текста в простых документах PDF. Вам просто нужно:
-
Загрузите файл PDF на Google Диск
-
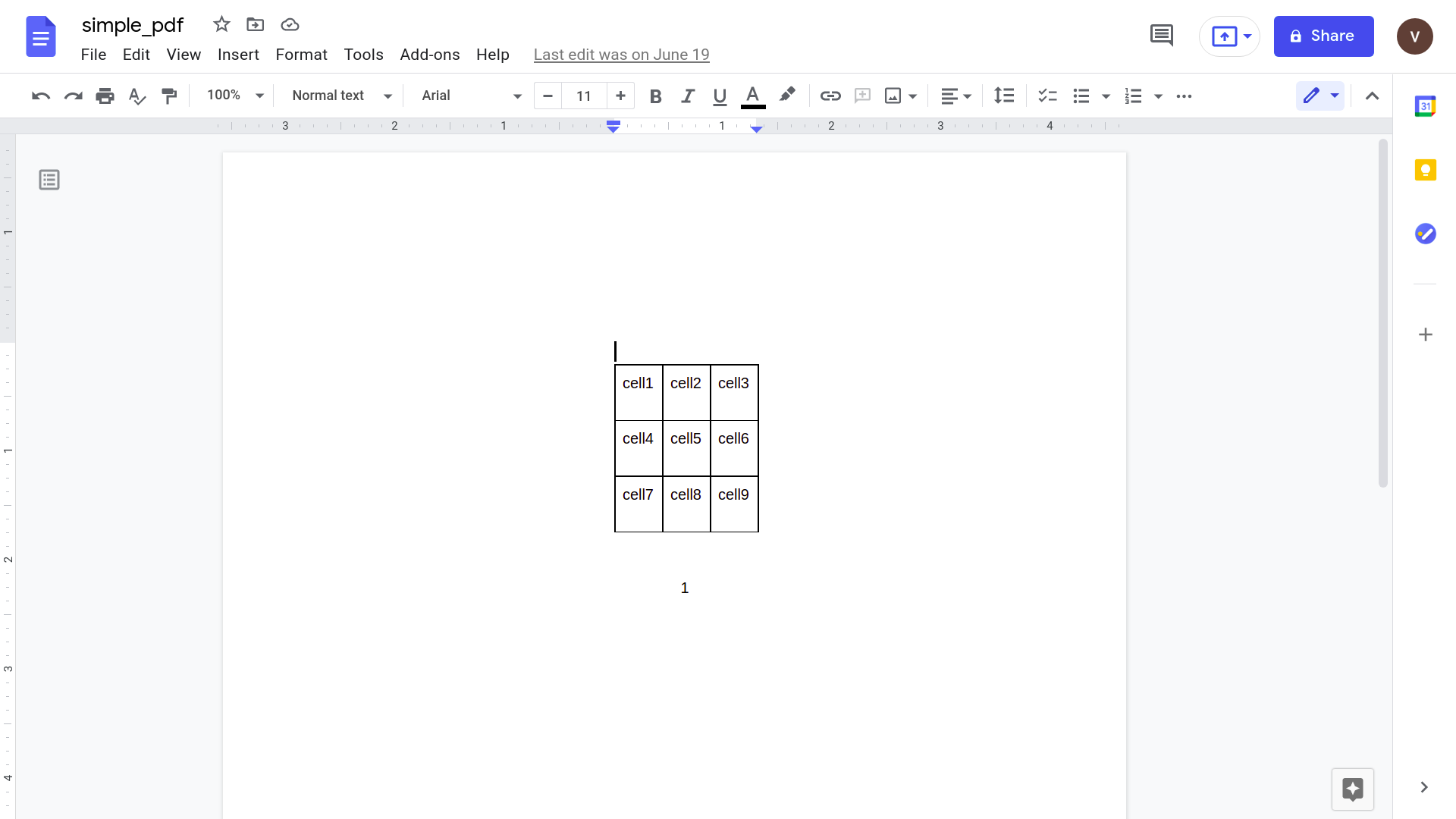
Нажмите «Открыть с помощью Google Docs».
-
Скопируйте нужные данные и вставьте в Google Таблицы.
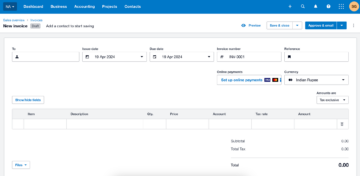
Хотя это, кажется, работает хорошо, давайте попробуем что-нибудь более практичное. Рассмотрим этот простой счет.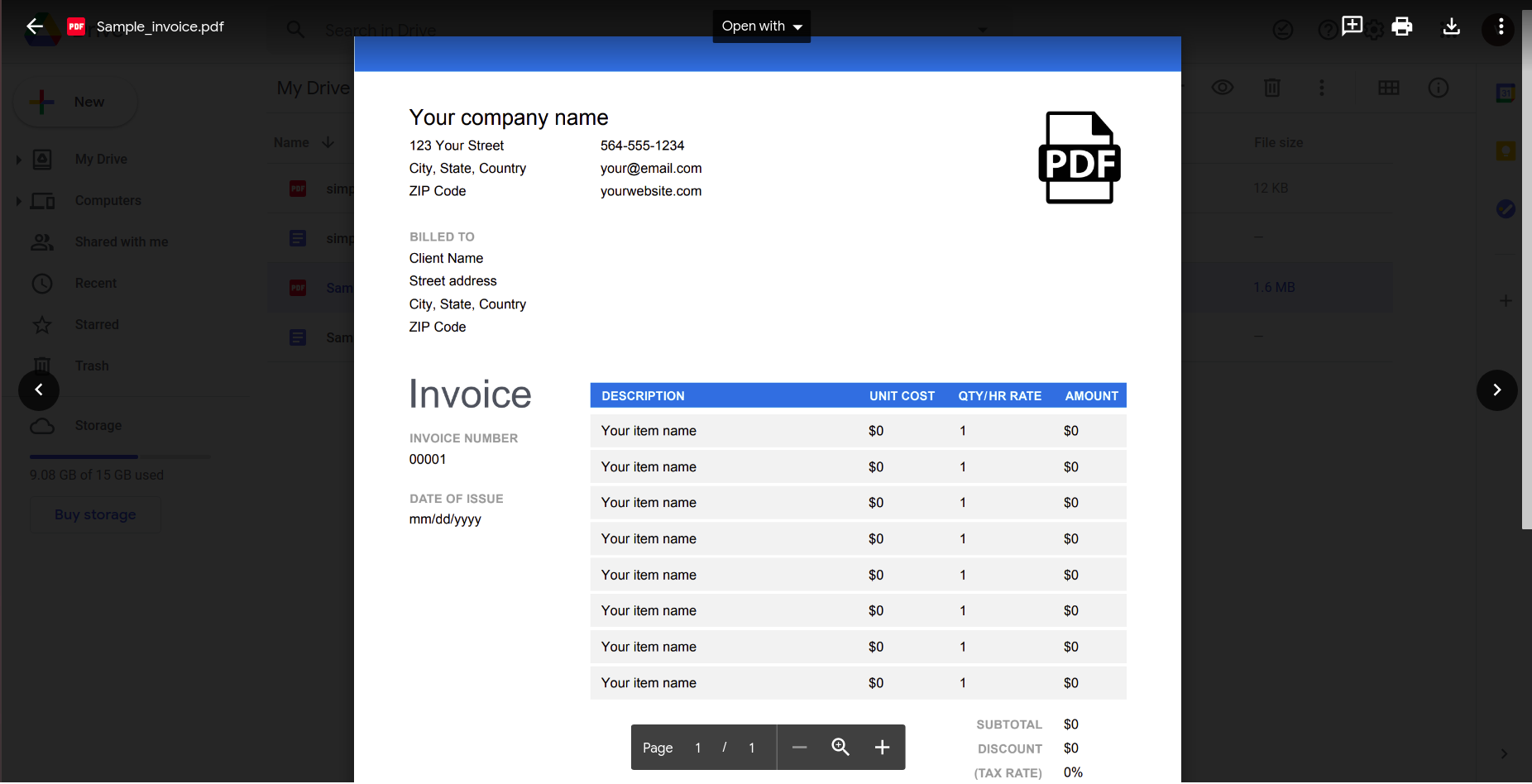
Открытие его с помощью приложения Google docs дает следующий результат.
Очевидно, что по мере увеличения сложности документа нам необходимо полагаться на более сложные инструменты для распознавания данных.
2. Использование онлайн-инструментов:
Несколько онлайн-инструментов, таких как экстрактор таблиц PDF, Online2PDF и т. д., напрямую интегрируются с Google Диском и предоставляют готовые возможности для преобразования PDF-документов в Google Таблицы.
Однако, когда эти инструменты были протестированы с использованием приведенного выше примера счета в формате PDF, в большинстве случаев таблицы не были обнаружены.
Хотите преобразовать PDF файлы Таблицы Google ? Проверять, выписываться Нанонец бесплатно Конвертер PDF в CSV. Узнайте, как автоматизировать весь рабочий процесс преобразования PDF в Google Таблицы с помощью Nanonets, как показано ниже.
Автоматизация процесса преобразования PDF в Google Sheets
Мы можем полностью автоматизировать процесс анализа PDF-файла и извлечения данных в форму Google Таблиц с помощью следующих инструментов.
1. Использование Webhooks:
Веб-перехватчики - это настраиваемые HTTP-запросы. Обычно они запускаются по событию, т.е. когда событие происходит, приложение отправляет информацию по заранее заданному URL-адресу.
Как вы можете использовать это для автоматизации рабочего процесса? Рассмотрим типичный вариант использования обработки счетов. Вы получаете ряд счетов-фактур от своих поставщиков и вводите их в конвертер PDF в Google Таблицы, который находится в облаке. Как узнать, что модель закончила обработку документов?
Вместо того, чтобы вручную проверять, завершено ли преобразование, вы можете просто использовать веб-перехватчик, который уведомляет вас, когда данные из PDF-файла были извлечены в документ Google Sheets.
2. Использование API
API означает интерфейс прикладного программирования. Используя соответствующие вызовы API, преобразование документов PDF в Google Таблицы может оказаться таким же простым, как написание следующих строк кода:
#Feed the PDF documents into the PDF to Google sheets converter
Success_code, unique_id = NanonetsAPI.uploaddata(PDF_documents)
Если ваша компания уже настроила интеграцию с Webhooks, вы получите уведомление об успешном преобразовании ваших PDF-документов. Затем вы можете загрузить форму Google Таблиц, используя API, показанный ниже.
#Download Google Sheets forms
Google_sheets_data = NanonetsAPI.downloaddata(unqiue_id)
PDF в Google Таблицы с Nanonets
Парсер Nanonets PDF делает синтаксический анализ и преобразование простым и точным. Парсер PDF использовался для анализа образца счета. Этот раздел демонстрирует простоту использования и точность инструмента. Вместо того, чтобы говорить о том, насколько это здорово, следующие изображения хорошо иллюстрируют эту мысль.
Изображение, показанное ниже, представляет собой снимок экрана с образцом счета-фактуры, который был передан синтаксическому анализатору Nanonets PDF.
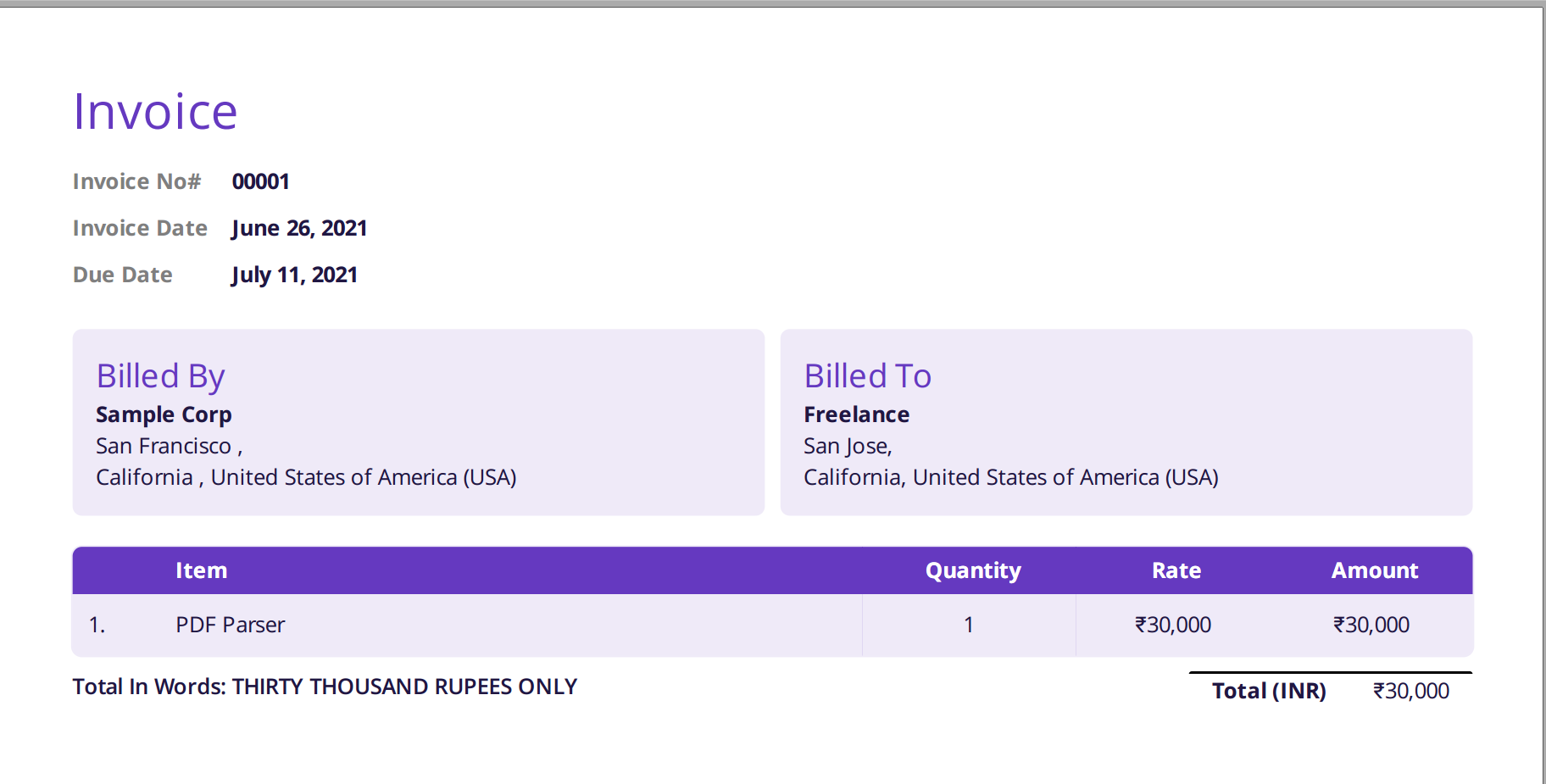
Просто перейдите на сайт Nanonets и загрузите счет. Преобразование занимает всего несколько секунд, после чего проанализированные данные могут быть загружены в различных форматах, таких как CSV, XLSX и т. д. (см. Конвертер PDF в CSV)
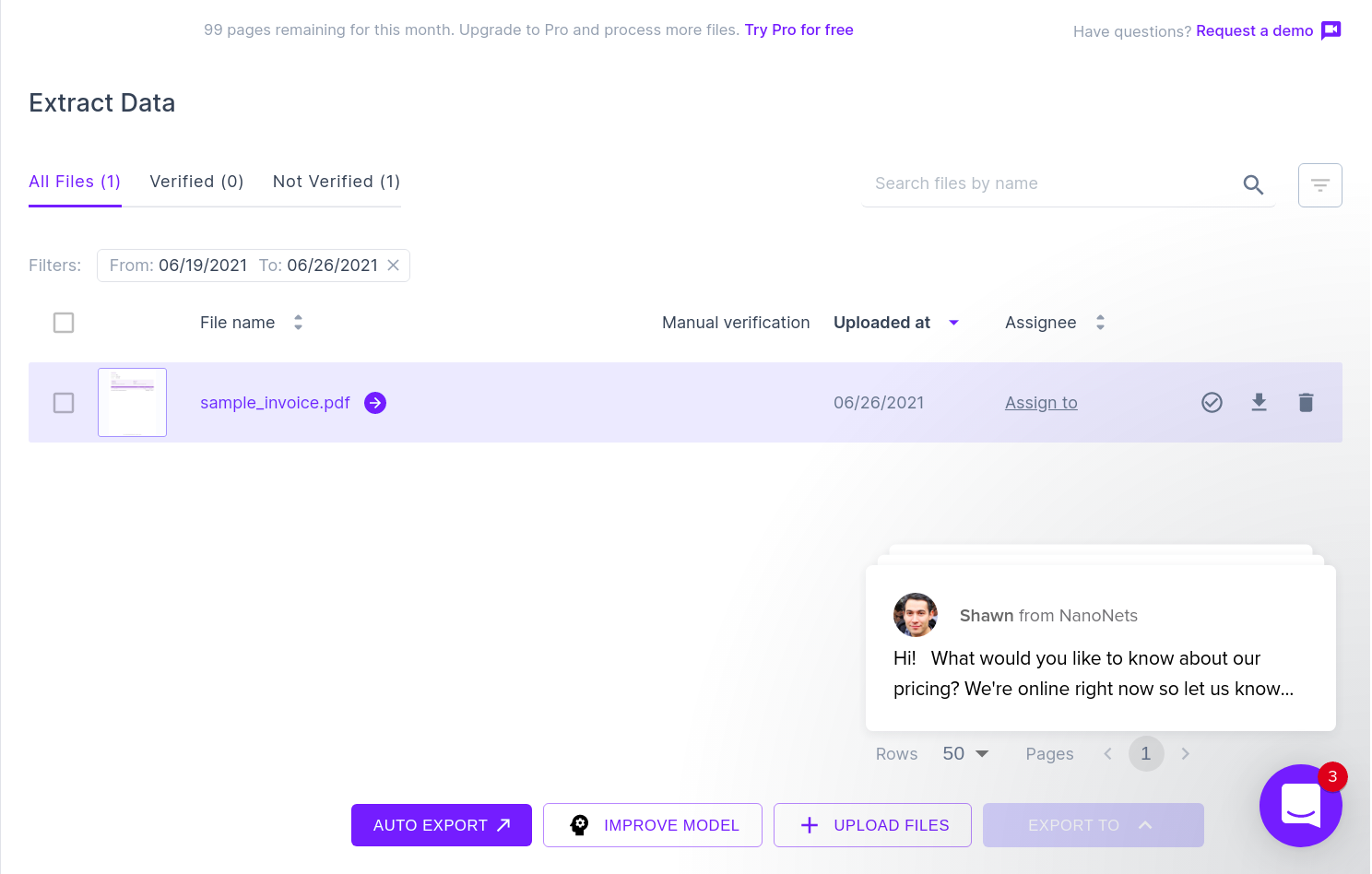
На следующем изображении показан снимок экрана файла CSV, который содержит проанализированные данные из документа PDF.

Наконец, чтобы преобразовать файл CSV в форму листов Google, достаточно просто загрузить файл XLSX / CSV на ваш диск Google. Этот шаг можно автоматизировать, используя API-интерфейсы Google Drive.
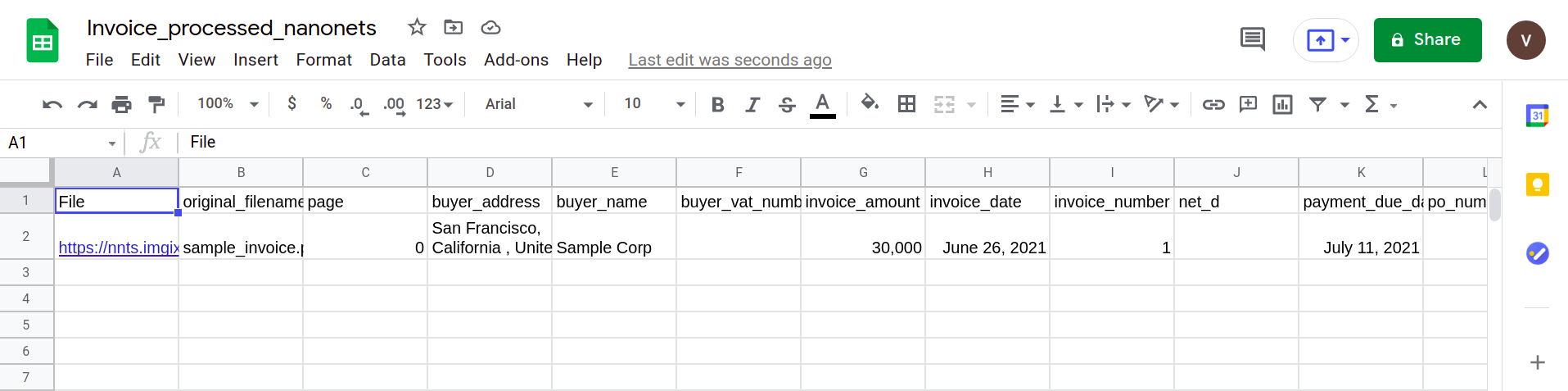
В следующем разделе показано, как можно создать простой конвейер, используя синтаксический анализатор Nanonets PDF.
Хотите извлечь информацию из документов PDF и преобразовать / добавить их в документ Google Таблиц? Проверьте Нанонеты™ автоматизировать экспорт любой информации из любого PDF-документа в Google Таблицы!
Создание простого конвейера
1. Автоматически загружайте PDF-документы с помощью Nanonets API.
API Nanonets позволяет автоматически загружать документы, которые необходимо проанализировать. В следующем фрагменте кода показано, как это можно сделать с помощью python.
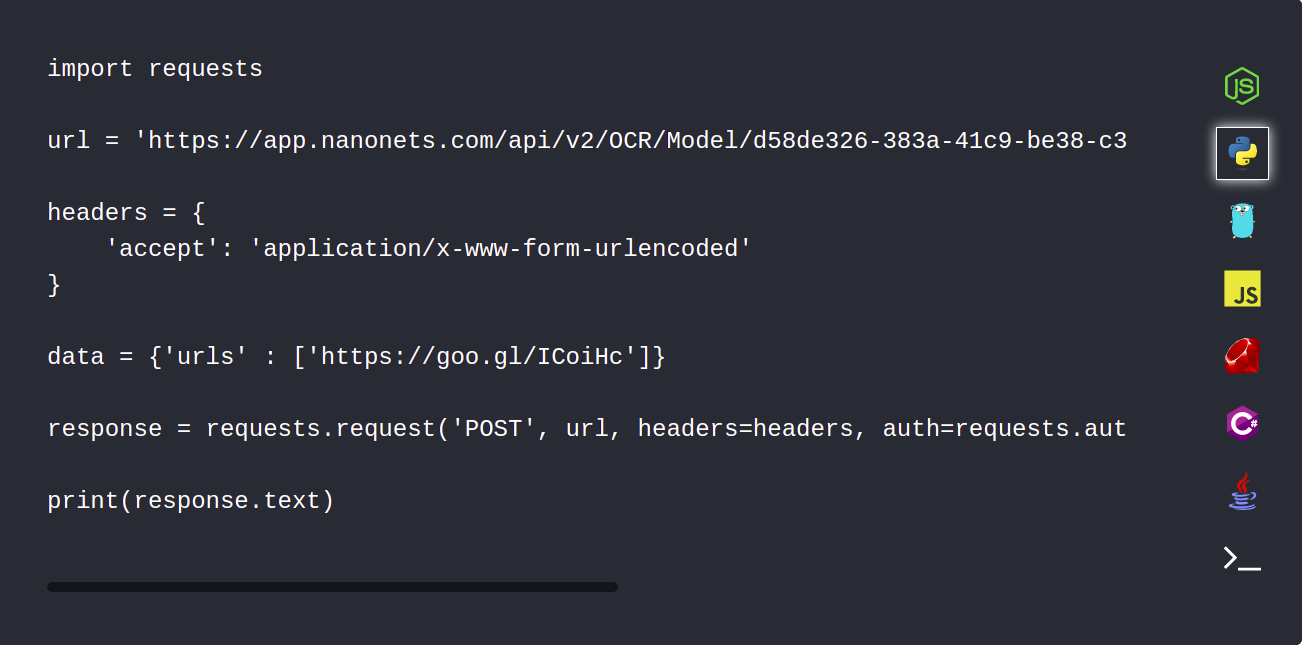
2. Используйте интеграцию с веб-перехватчиками, чтобы получать уведомление о завершении синтаксического анализа.
Веб-перехватчики могут быть настроены на автоматическое уведомление вас после анализа документов.
3. Просмотрите и загрузите в Google Таблицы.
Загрузите и просмотрите файлы CSV, чтобы убедиться, что все в порядке, и загрузите данные в Google Таблицы с помощью Google Drive API.
Край нанонетов
Вот некоторые особенности Nanonets PDF Parser, которые делают его идеальным инструментом для вашего бизнеса.
1.Внешняя интеграция:
Модель наносетей может быть легко интегрирована с MySql, Quickbooks, Salesforce и т. Д. Это означает, что ваш текущий рабочий процесс останется без изменений, и преобразователь наносетей можно просто подключить как дополнительный модуль.
2. Высокая точность и малое время обработки:
Инструмент парсера Nanonets PDF имеет точность более 95% +, что намного выше, чем у его конкурентов.
3. Крутые функции постобработки:
Предположим, что ваша база данных интегрирована с моделью наносетей. Модель автоматически заполняет некоторые поля (данными из вашей базы данных) на основе данных, извлеченных из документа. Например:
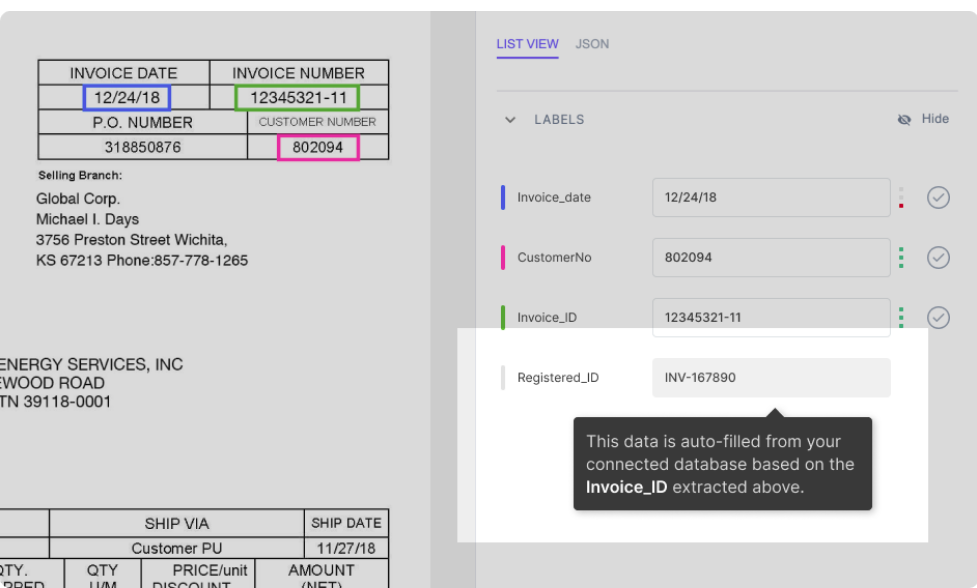
Как показано на рисунке, поле Registered_ID заполняется автоматически (путем поиска в базе данных) на основе Invoice_ID, извлеченного из PDF.
4. Простой и понятный интерфейс.
Хотя эта функция недооценена, я обнаружил, что пользовательский интерфейс и пользовательский интерфейс находятся на высоте. Весь процесс регистрации, загрузки документа и анализа данных занял менее 5 минут. Это почти равно времени загрузки моего ноутбука!
5. Огромная клиентская база
Если у вас все еще есть сомнения по поводу использования наносетей для автоматизации вашего рабочего процесса, просто взгляните на некоторые из компаний, которые пользуются их услугами.
- Deloitte
- Sherwin Williams
- DoorDash
- P & G
Хотите извлечь информацию из документов PDF и преобразовать / добавить их в документ Google Таблиц? Проверьте Нанонеты™ автоматизировать экспорт любой информации из любого PDF-документа в Google Таблицы!
Заключение
В этом посте мы рассмотрели, как можно автоматизировать рабочий процесс с помощью конвертера PDF в Google Таблицы. Изначально мы узнали о необходимости преобразования PDF-документов в Google Таблицы, а затем о проблемах, с которыми пришлось столкнуться в этом процессе. Затем мы погрузились в подходы, используемые современными парсерами для анализа PDF-документов, а также реализовали некоторые из распространенных подходов. Мы также узнали, как мы можем полностью автоматизировать преобразование с помощью внешних интеграций, таких как веб-перехватчики и API. Наконец, мы использовали инструмент Nanonets для анализа образца счета-фактуры, извлечения данных в форму Google Таблиц, а также исследовали некоторые из его интересных функций постобработки.
Вы попробовали модель Nanonets? Если да, оставьте комментарий ниже о своем опыте использования этого инструмента. Если нет, попробуйте. Это может просто сделать твой день!
- AI
- ИИ и машинное обучение
- ай искусство
- генератор искусств ай
- искусственный интеллект
- искусственный интеллект
- сертификация искусственного интеллекта
- искусственный интеллект в банковском деле
- робот с искусственным интеллектом
- роботы с искусственным интеллектом
- программное обеспечение искусственного интеллекта
- блокчейн
- конференция по блокчейну
- Coingenius
- разговорный искусственный интеллект
- криптоконференция ИИ
- дал-и
- глубокое обучение
- google ai
- обучение с помощью машины
- пдф в гугл таблицы
- Платон
- Платон Ай
- Платон Интеллектуальные данные
- Платон игра
- ПлатонДанные
- платогейминг
- масштаб ай
- синтаксис
- зефирнет