Этот пост написан совместно с Махимой Агарвал, инженером по машинному обучению, и Дипаком Меттемом, старшим инженером-менеджером в VMware Carbon Black.
Черный углерод VMware — известное решение для обеспечения безопасности, обеспечивающее защиту от всего спектра современных кибератак. Используя терабайты данных, генерируемых продуктом, команда аналитиков безопасности сосредоточилась на создании решений машинного обучения (ML) для обнаружения критических атак и выявления новых угроз из шума.
Для команды VMware Carbon Black крайне важно спроектировать и построить настраиваемый сквозной конвейер MLOps, который организует и автоматизирует рабочие процессы в жизненном цикле машинного обучения и обеспечивает обучение, оценку и развертывание моделей.
Существует две основные цели построения этого пайплайна: поддержка специалистов по обработке и анализу данных в разработке моделей на поздних стадиях и прогнозирование поверхностных моделей в продукте путем обслуживания моделей в больших объемах и в режиме реального времени в производственном трафике. Поэтому VMware Carbon Black и AWS решили создать специальный конвейер MLOps с использованием Создатель мудреца Амазонки за простоту использования, универсальность и полностью управляемую инфраструктуру. Мы организуем наши конвейеры обучения и развертывания машинного обучения, используя Amazon Managed Workflows для Apache Airflow (Amazon MWAA), что позволяет нам больше сосредоточиться на программной разработке рабочих процессов и конвейеров, не беспокоясь об автоматическом масштабировании или обслуживании инфраструктуры.
Благодаря этому конвейеру то, что когда-то было исследованием машинного обучения Jupyter на основе ноутбуков, теперь превратилось в автоматизированный процесс развертывания моделей в рабочей среде с минимальным ручным вмешательством специалистов по данным. Раньше процесс обучения, оценки и развертывания модели мог занимать целый день; с этой реализацией все находится на расстоянии одного триггера, и общее время сократилось до нескольких минут.
В этом посте архитекторы VMware Carbon Black и AWS рассказывают, как мы создавали настраиваемые рабочие процессы машинного обучения и управляли ими с помощью Gitlab, Amazon MWAA и SageMaker. Мы обсуждаем, чего мы достигли на данный момент, дальнейшие усовершенствования конвейера и уроки, извлеченные на этом пути.
Обзор решения
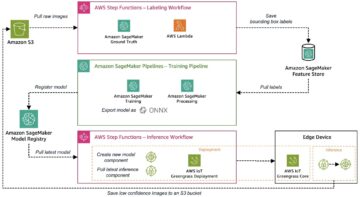
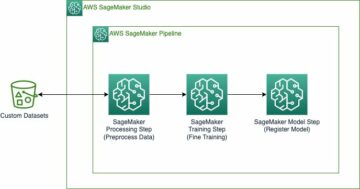
Следующая диаграмма иллюстрирует архитектуру платформы машинного обучения.

Высокоуровневый дизайн решения
Эта платформа машинного обучения была задумана и разработана для использования различными моделями в различных репозиториях кода. Наша команда использует GitLab в качестве инструмента управления исходным кодом для поддержки всех репозиториев кода. Любые изменения в исходном коде репозитория моделей постоянно интегрируются с помощью Гитлаб КИ, который вызывает последующие рабочие процессы в конвейере (обучение модели, оценка и развертывание).
Следующая диаграмма архитектуры иллюстрирует сквозной рабочий процесс и компоненты, задействованные в нашем конвейере MLOps.

Сквозной рабочий процесс
Конвейеры обучения, оценки и развертывания модели машинного обучения организованы с помощью Amazon MWAA, называемого Направленный ациклический график (ДАГ). Группа обеспечения доступности баз данных — это совокупность задач, организованных с помощью зависимостей и отношений, которые определяют, как они должны выполняться.
На высоком уровне архитектура решения включает три основных компонента:
- Репозиторий кода конвейера машинного обучения
- Конвейер обучения и оценки модели машинного обучения
- Конвейер развертывания модели машинного обучения
Давайте обсудим, как управляются эти разные компоненты и как они взаимодействуют друг с другом.
Репозиторий кода конвейера машинного обучения
После того, как репозиторий модели интегрирует репозиторий MLOps в качестве своего нижестоящего конвейера, а специалист по данным фиксирует код в своем репозитории модели, исполнитель GitLab выполняет стандартную проверку и тестирование кода, определенные в этом репозитории, и запускает конвейер MLOps на основе изменений кода. Мы используем многопроектный конвейер Gitlab, чтобы включить этот триггер в разных репозиториях.
Конвейер MLOps GitLab выполняет определенный набор этапов. Он выполняет базовую проверку кода с помощью pylint, упаковывает код обучения и логического вывода модели в образ Docker и публикует образ контейнера в Реестр Amazon Elastic Container (Амазон ЭКР). Amazon ECR — это полностью управляемый реестр контейнеров, предлагающий высокопроизводительный хостинг, поэтому вы можете надежно развертывать образы приложений и артефакты в любом месте.
Конвейер обучения и оценки модели машинного обучения
После того, как изображение опубликовано, оно запускает обучение и оценку Воздушный поток Apache трубопровод через AWS Lambda функция. Lambda — это бессерверная служба вычислений, управляемая событиями, которая позволяет запускать код практически для любого типа приложений или серверных служб без выделения серверов или управления ими.
После успешного запуска конвейера запускается группа DAG для обучения и оценки, которая, в свою очередь, запускает обучение модели в SageMaker. В конце этого конвейера обучения идентифицированная группа пользователей получает уведомление с результатами обучения и оценки модели по электронной почте через Amazon Простая служба уведомлений (Amazon SNS) и Slack. Amazon SNS — это полностью управляемая служба публикации/подписки для обмена сообщениями A2A и A2P.
После тщательного анализа результатов оценки специалист по данным или инженер по машинному обучению может развернуть новую модель, если производительность новой обученной модели выше по сравнению с предыдущей версией. Производительность моделей оценивается на основе показателей, специфичных для модели (таких как оценка F1, MSE или матрица путаницы).
Конвейер развертывания модели машинного обучения
Чтобы начать развертывание, пользователь запускает задание GitLab, которое запускает группу обеспечения доступности баз данных развертывания с помощью той же функции Lambda. После успешного запуска конвейера он создает или обновляет конечную точку SageMaker с помощью новой модели. Это также отправляет уведомление с информацией о конечной точке по электронной почте с использованием Amazon SNS и Slack.
В случае сбоя в любом из конвейеров пользователи уведомляются по тем же каналам связи.
SageMaker предлагает логические выводы в реальном времени, которые идеально подходят для рабочих нагрузок логических выводов с малой задержкой и высокими требованиями к пропускной способности. Эти конечные точки полностью управляемы, сбалансированы по нагрузке и автоматически масштабируются и могут быть развернуты в нескольких зонах доступности для обеспечения высокой доступности. Наш конвейер создает такую конечную точку для модели после ее успешного запуска.
В следующих разделах мы подробно рассмотрим различные компоненты и углубимся в детали.
GitLab: Пакетные модели и триггерные пайплайны
Мы используем GitLab в качестве репозитория кода и конвейера для упаковки кода модели и запуска нижестоящих DAG Airflow.
Многопроектный конвейер
Функция многопроектного конвейера GitLab используется, когда родительский конвейер (восходящий поток) представляет собой репозиторий модели, а дочерний конвейер (нисходящий поток) — репозиторий MLOps. Каждое репо поддерживает .gitlab-ci.yml, а следующий блок кода, включенный в восходящем конвейере, запускает нисходящий конвейер MLOps.
Восходящий конвейер отправляет код модели в нисходящий конвейер, где запускаются задания упаковки и публикации CI. Код для контейнеризации кода модели и его публикации в Amazon ECR поддерживается и управляется конвейером MLOps. Он отправляет переменные, такие как ACCESS_TOKEN (может быть создан в Настройки, О компании), переменные JOB_ID (для доступа к вышестоящим артефактам) и переменные $CI_PROJECT_ID (идентификатор проекта репозитория модели), чтобы конвейер MLOps мог получить доступ к файлам кода модели. С артефакты работы особенность от Gitlab, нижестоящий репозиторий получает доступ к удаленным артефактам с помощью следующей команды:
Репозиторий модели может использовать нисходящие конвейеры для нескольких моделей из одного и того же репозитория, расширяя этап, который запускает его, с помощью продолжается ключевое слово из GitLab, которое позволяет повторно использовать одну и ту же конфигурацию на разных этапах.
После публикации образа модели в Amazon ECR конвейер MLOps запускает конвейер обучения Amazon MWAA с помощью Lambda. После утверждения пользователем он также запускает конвейер Amazon MWAA для развертывания модели, используя ту же функцию Lambda.
Семантическое управление версиями и передача версий вниз по течению
Мы разработали собственный код для версии изображений ECR и моделей SageMaker. Конвейер MLOps управляет семантической логикой управления версиями для изображений и моделей как часть этапа, на котором код модели контейнеризуется, и передает версии на более поздние этапы в виде артефактов.
Переподготовка
Поскольку переобучение является важным аспектом жизненного цикла машинного обучения, мы реализовали возможности переобучения как часть нашего конвейера. Мы используем API-интерфейс SageMaker list-models, чтобы определить, выполняется ли переобучение, на основе номера версии переобучения модели и метки времени.
Мы управляем ежедневным графиком конвейера переподготовки, используя Конвейеры расписания GitLab.
Terraform: настройка инфраструктуры
Помимо кластера Amazon MWAA, репозиториев ECR, функций Lambda и раздела SNS, это решение также использует Управление идентификацией и доступом AWS (IAM) роли, пользователи и политики; Простой сервис хранения Amazon (Amazon S3) ведра и Amazon CloudWatch пересылка журналов.
Чтобы упростить настройку и обслуживание инфраструктуры для сервисов, задействованных в нашем конвейере, мы используем Terraform реализовать инфраструктуру в виде кода. Всякий раз, когда требуются обновления инфраструктуры, изменения кода запускают настроенный нами конвейер GitLab CI, который проверяет и развертывает изменения в различных средах (например, добавление разрешения в политику IAM в учетных записях dev, stage и prod).
Amazon ECR, Amazon S3 и Lambda: упрощение конвейера
Мы используем следующие ключевые сервисы для облегчения нашего конвейера:
- Амазонка ЭКР – Для поддержки и обеспечения удобного извлечения изображений контейнеров моделей мы помечаем их семантическими версиями и загружаем в репозитории ECR, настроенные для
${project_name}/${model_name}через Терраформ. Это обеспечивает хороший уровень изоляции между различными моделями и позволяет нам использовать настраиваемые алгоритмы и форматировать запросы на вывод и ответы, чтобы включать желаемую информацию о манифесте модели (имя модели, версию, путь к обучающим данным и т. д.). - Amazon S3 — Мы используем корзины S3 для сохранения данных обучения модели, артефактов обученной модели для каждой модели, групп доступности баз данных Airflow и другой дополнительной информации, необходимой для конвейеров.
- Лямбда – Поскольку из соображений безопасности наш кластер Airflow развернут в отдельном облаке VPC, прямой доступ к группам обеспечения доступности баз данных невозможен. Поэтому мы используем функцию Lambda, также поддерживаемую Terraform, для запуска любых DAG, указанных именем DAG. При правильной настройке IAM задание GitLab CI запускает функцию Lambda, которая передает конфигурации вниз к запрошенным группам обеспечения доступности баз данных для обучения или развертывания.
Amazon MWAA: конвейеры обучения и развертывания
Как упоминалось ранее, мы используем Amazon MWAA для организации конвейеров обучения и развертывания. Мы используем операторы SageMaker, доступные в Пакет провайдера Amazon для Airflow для интеграции с SageMaker (чтобы избежать шаблонов jinja).
В этом обучающем конвейере мы используем следующие операторы (показаны на следующей схеме рабочего процесса):

Канал обучения MWAA
Мы используем следующие операторы в конвейере развертывания (показаны на следующей схеме рабочего процесса):

Конвейер развертывания модели
Мы используем Slack и Amazon SNS для публикации сообщений об ошибках/успехах и результатов оценки в обоих конвейерах. Slack предоставляет широкий спектр параметров для настройки сообщений, в том числе следующие:
- SnsPublishOperator - Мы используем SnsPublishOperator отправлять уведомления об успехе/неуспехе на электронную почту пользователя
- Слабый API – Мы создали входящий URL-адрес веб-перехватчика чтобы получать уведомления конвейера на нужный канал
CloudWatch и VMware Wavefront: мониторинг и ведение журнала
Мы используем панель инструментов CloudWatch для настройки мониторинга конечных точек и ведения журналов. Это помогает визуализировать и отслеживать различные метрики производительности операций и моделей, характерные для каждого проекта. Помимо политик автоматического масштабирования, настроенных для отслеживания некоторых из них, мы постоянно отслеживаем изменения в использовании ЦП и памяти, запросов в секунду, задержек ответа и показателей модели.
CloudWatch даже интегрирован с панелью мониторинга VMware Tanzu Wavefront, что позволяет визуализировать метрики для конечных точек модели, а также других сервисов на уровне проекта.
Преимущества для бизнеса и что дальше
Конвейеры машинного обучения очень важны для сервисов и функций машинного обучения. В этом посте мы обсудили вариант использования сквозного машинного обучения с использованием возможностей AWS. Мы создали специальный конвейер с помощью SageMaker и Amazon MWAA, который мы можем повторно использовать в проектах и моделях, и автоматизировали жизненный цикл машинного обучения, что сократило время от обучения модели до производственного развертывания до 10 минут.
С переносом бремени жизненного цикла машинного обучения на SageMaker он предоставил оптимизированную и масштабируемую инфраструктуру для обучения и развертывания модели. Обработка моделей с помощью SageMaker помогла нам делать прогнозы в реальном времени с миллисекундными задержками и возможностями мониторинга. Мы использовали Terraform для простоты настройки и управления инфраструктурой.
Следующими шагами для этого конвейера будут расширение конвейера обучения модели с возможностями повторного обучения, независимо от того, запланировано ли оно или основано на обнаружении дрейфа модели, поддержка теневого развертывания или A/B-тестирования для более быстрого и квалифицированного развертывания модели, а также отслеживание происхождения ML. Мы также планируем оценить Конвейеры Amazon SageMaker потому что теперь поддерживается интеграция с GitLab.
Уроки, извлеченные
В рамках создания этого решения мы узнали, что вы должны обобщать заранее, но не слишком обобщать. Когда мы впервые завершили проектирование архитектуры, мы попытались создать и внедрить шаблоны кода для кода модели в качестве передовой практики. Однако это было так рано в процессе разработки, что шаблоны были либо слишком обобщенными, либо слишком подробными, чтобы их можно было повторно использовать для будущих моделей.
После доставки первой модели через конвейер, шаблоны вышли естественным образом на основе идей из нашей предыдущей работы. Конвейер не может делать все с первого дня.
Эксперименты с моделями и производство часто имеют очень разные (а иногда даже противоречащие) требования. Крайне важно с самого начала сбалансировать эти требования в команде и соответствующим образом расставить приоритеты.
Кроме того, вам могут не понадобиться все функции службы. Использование основных функций сервиса и модульная структура являются ключом к более эффективной разработке и гибкому конвейеру.
Заключение
В этом посте мы показали, как мы создали решение MLOps с помощью SageMaker и Amazon MWAA, которое автоматизировало процесс развертывания моделей в рабочей среде с минимальным ручным вмешательством специалистов по данным. Мы рекомендуем вам оценить различные сервисы AWS, такие как SageMaker, Amazon MWAA, Amazon S3 и Amazon ECR, для создания полноценного решения MLOps.
*Apache, Apache Airflow и Airflow являются либо зарегистрированными товарными знаками, либо товарными знаками Apache Software Foundation в США и / или других странах.
Об авторах
 Дипак Меттем является старшим инженером-менеджером в VMware, подразделение Carbon Black. Он и его команда работают над созданием потоковых приложений и сервисов, которые отличаются высокой доступностью, масштабируемостью и отказоустойчивостью, чтобы предоставлять клиентам решения на основе машинного обучения в режиме реального времени. Он и его команда также несут ответственность за создание инструментов, необходимых специалистам по данным для создания, обучения, развертывания и проверки своих моделей машинного обучения в производственной среде.
Дипак Меттем является старшим инженером-менеджером в VMware, подразделение Carbon Black. Он и его команда работают над созданием потоковых приложений и сервисов, которые отличаются высокой доступностью, масштабируемостью и отказоустойчивостью, чтобы предоставлять клиентам решения на основе машинного обучения в режиме реального времени. Он и его команда также несут ответственность за создание инструментов, необходимых специалистам по данным для создания, обучения, развертывания и проверки своих моделей машинного обучения в производственной среде.
 Махима Агарвал работает инженером по машинному обучению в VMware, подразделение Carbon Black.
Махима Агарвал работает инженером по машинному обучению в VMware, подразделение Carbon Black.
Она занимается проектированием, созданием и разработкой основных компонентов и архитектуры платформы машинного обучения для VMware CB SBU.
 Вамши Кришна Энаботала является старшим архитектором прикладного ИИ в AWS. Он работает с клиентами из разных секторов, чтобы ускорить инициативы в области данных, аналитики и машинного обучения. Он увлечен рекомендательными системами, НЛП и компьютерным зрением в области искусственного интеллекта и машинного обучения. Вне работы Вамши увлекается радиоуправлением, собирает радиоуправляемое оборудование (самолеты, автомобили и дроны), а также увлекается садоводством.
Вамши Кришна Энаботала является старшим архитектором прикладного ИИ в AWS. Он работает с клиентами из разных секторов, чтобы ускорить инициативы в области данных, аналитики и машинного обучения. Он увлечен рекомендательными системами, НЛП и компьютерным зрением в области искусственного интеллекта и машинного обучения. Вне работы Вамши увлекается радиоуправлением, собирает радиоуправляемое оборудование (самолеты, автомобили и дроны), а также увлекается садоводством.
 Сахил Тапар является архитектором корпоративных решений. Он работает с клиентами, помогая им создавать высокодоступные, масштабируемые и отказоустойчивые приложения в облаке AWS. В настоящее время он занимается контейнерами и решениями для машинного обучения.
Сахил Тапар является архитектором корпоративных решений. Он работает с клиентами, помогая им создавать высокодоступные, масштабируемые и отказоустойчивые приложения в облаке AWS. В настоящее время он занимается контейнерами и решениями для машинного обучения.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- Платоблокчейн. Интеллект метавселенной Web3. Расширение знаний. Доступ здесь.
- Источник: https://aws.amazon.com/blogs/machine-learning/how-vmware-built-an-mlops-pipeline-from-scratch-using-gitlab-amazon-mwaa-and-amazon-sagemaker/
- :является
- $UP
- 1
- 10
- 100
- 7
- 8
- a
- О нас
- ускорять
- доступ
- Доступ
- соответственно
- Учетные записи
- достигнутый
- через
- ациклический
- дополнение
- дополнительный
- Дополнительная информация
- После
- против
- AI
- алгоритмы
- Все
- позволяет
- Amazon
- Создатель мудреца Амазонки
- анализ
- аналитика
- и
- откуда угодно
- апаш
- API
- Применение
- Приложения
- прикладной
- Прикладной ИИ
- утверждение
- архитектура
- МЫ
- области
- AS
- внешний вид
- At
- нападки
- авторинга
- автоматический
- Автоматизированный
- автоматы
- свободных мест
- доступен
- избежать
- AWS
- Backend
- Баланс
- основанный
- основной
- BE
- , так как:
- начало
- Преимущества
- ЛУЧШЕЕ
- Лучшая
- между
- Черный
- Заблокировать
- Филиал
- приносить
- строить
- Строительство
- построенный
- бремя
- by
- CAN
- не могу
- возможности
- углерод
- легковые автомобили
- случаев
- CB
- определенный
- изменения
- каналы
- ребенок
- выбрал
- облако
- Кластер
- код
- лыжных шлемов
- Связь
- сравненный
- полный
- компоненты
- Вычисление
- компьютер
- Компьютерное зрение
- дирижирует
- Конфигурация
- Конфигурации
- противоречивый
- замешательство
- соображения
- потреблять
- потребленный
- Container
- Контейнеры
- непрерывно
- Удобно
- Основные
- может
- страны
- ЦП
- Создайте
- создали
- создает
- Создающий
- критической
- решающее значение
- В настоящее время
- изготовленный на заказ
- Клиенты
- настроить
- кибератаки
- DAG
- ежедневно
- приборная панель
- данным
- ученый данных
- день
- определенный
- доставки
- развертывание
- развернуть
- развертывание
- развертывание
- развертывания
- развертывает
- Проект
- предназначенный
- проектирование
- подробный
- подробнее
- обнаружение
- Дев
- развитый
- развивающийся
- Разработка
- различный
- непосредственно
- обсуждать
- обсуждается
- Docker
- Dont
- вниз
- беспилотники
- каждый
- Ранее
- Рано
- простота в использовании
- эффективный
- или
- появление
- включить
- включен
- позволяет
- поощрять
- впритык
- Конечная точка
- инженер
- Проект и
- Предприятие
- Решения для предприятий
- энтузиаст
- средах
- Оборудование
- существенный
- Эфир (ETH)
- оценивать
- оценивается
- оценки
- оценка
- оценки
- Даже
- События
- Каждая
- многое
- пример
- Расширьте
- простирающийся
- f1
- содействовал
- Ошибка
- далеко
- быстрее
- Особенность
- Особенности
- несколько
- Файлы
- First
- гибкого
- Фокус
- внимание
- фокусируется
- после
- Что касается
- формат
- от
- полный
- Полный спектр
- полностью
- функция
- Функции
- далее
- будущее
- генерируется
- получить
- хорошо
- группы
- Есть
- имеющий
- помощь
- помог
- помогает
- High
- высокая производительность
- очень
- хостинг
- Как
- Однако
- HTML
- HTTP
- HTTPS
- IAM
- ID
- идеальный
- идентифицированный
- определения
- Личность
- изображение
- изображений
- осуществлять
- реализация
- в XNUMX году
- in
- включают
- включает в себя
- В том числе
- информация
- Инфраструктура
- инициативы
- размышления
- интегрировать
- интегрированный
- Интегрируется
- интеграции.
- взаимодействовать
- вмешательство
- Запускает
- вовлеченный
- изоляция
- IT
- ЕГО
- работа
- Джобс
- JPG
- Сохранить
- Основные
- ключи
- Задержка
- слой
- узнали
- изучение
- Уроки
- Уроки, извлеченные
- Lets
- уровень
- Жизненный цикл
- такое как
- мало
- загрузка
- Низкий
- машина
- обучение с помощью машины
- Главная
- поддерживать
- поддерживает
- техническое обслуживание
- сделать
- управлять
- управляемого
- управление
- менеджер
- управляет
- управления
- руководство
- матрица
- Память
- упомянутый
- Сообщения
- обмен сообщениями
- Метрика
- может быть
- миллисекунды
- минут
- ML
- млн операций в секунду
- модель
- Модели
- Модерн
- монитор
- Мониторинг
- БОЛЕЕ
- более эффективным
- с разными
- имя
- естественно
- необходимо
- Необходимость
- Новые
- следующий
- НЛП
- Шум
- уведомление
- Уведомления
- номер
- of
- предлагающий
- Предложения
- on
- ONE
- оперативный
- Операторы
- оптимизированный
- Опции
- организовал
- Организованный
- Другие контрактные услуги
- внешнюю
- общий
- пакет
- пакеты
- коробок
- часть
- проходит
- Прохождение
- страстный
- путь
- производительность
- разрешение
- трубопровод
- план
- Planes
- Платформа
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- сборах
- политика
- После
- практика
- Predictions
- предыдущий
- Расставляйте приоритеты
- процесс
- Продукт
- Производство
- Проект
- проектов
- правильный
- защиту
- при условии
- Недвижимости
- приводит
- публиковать
- опубликованный
- Публикует
- Издательство
- целей
- квалифицированный
- ассортимент
- реального времени
- Рекомендация
- Цена снижена
- назвало
- зарегистрированный
- реестра
- Отношения
- удаленные
- Знаменитый
- хранилище
- просил
- Запросы
- обязательный
- Требования
- исследованиям
- упругий
- ответ
- ответственный
- Итоги
- переквалификация
- многоразовый
- роли
- Run
- бегун
- sagemaker
- то же
- масштабируемые
- масштабирование
- график
- считаться
- Ученый
- Ученые
- Во-вторых
- разделах
- Сектора юридического права
- безопасность
- старший
- отдельный
- Serverless
- Серверы
- обслуживание
- Услуги
- выступающей
- набор
- установка
- Shadow
- СДВИГАЯ
- должен
- показанный
- просто
- слабина
- So
- уже
- Software
- Решение
- Решения
- некоторые
- Источник
- исходный код
- специалист
- конкретный
- указанный
- Спектр
- Прожектор
- Этап
- этапы
- стандарт
- Начало
- начинается
- Области
- Шаги
- диск
- Стратегия
- потоковый
- упорядочить
- последующее
- Успешно
- такие
- поддержка
- Поддержанный
- Поверхность
- системы
- TAG
- взять
- задачи
- команда
- шаблоны
- Terraform
- Тестирование
- который
- Ассоциация
- их
- Их
- следовательно
- Эти
- угрозы
- три
- Через
- по всему
- пропускная способность
- время
- отметка времени
- в
- вместе
- слишком
- инструментом
- инструменты
- топ
- тема
- трек
- Отслеживание
- торговая марка
- трафик
- Train
- специалистов
- Обучение
- вызвать
- срабатывает
- ОЧЕРЕДЬ
- под
- Ед. изм
- Объединенный
- США
- Updates
- us
- Применение
- использование
- прецедент
- Информация о пользователе
- пользователей
- VALIDATE
- Проверка
- переменные
- различный
- версия
- фактически
- видение
- визуализации
- VMware
- объем
- Путь..
- ЧТО Ж
- Что
- будь то
- который
- широкий
- Широкий диапазон
- в
- без
- Работа
- рабочий
- Рабочие процессы
- работает
- бы
- зефирнет
- ZIP
- зоны