Введение
Мир аудита данных может быть сложным, с множеством проблем, которые нужно преодолеть. Одной из самых больших проблем является обработка категориальных атрибутов при работе с наборами данных. В этой статье мы углубимся в мир аудита данных, обнаружения аномалий и влияния кодирования категориальных атрибутов на модели.
Одной из основных проблем, связанных с обнаружением аномалий для данных аудита, является обработка категориальных атрибутов. Кодирование категориальных атрибутов является обязательным, поскольку модели не могут интерпретировать ввод текста. Обычно это делается с помощью кодирования Label или One Hot. Однако в большом наборе данных горячее кодирование может привести к ухудшению производительности модели из-за проклятия размерности.
Цели обучения
-
Чтобы понять концепцию аудита данных и проблемы
- Оценить различные методы обнаружения глубоких неконтролируемых аномалий.
- Чтобы понять влияние кодирования категориальных атрибутов на модели, используемые для обнаружения аномалий в данных аудита.
Эта статья была опубликована в рамках Блогатон по Data Science.
Содержание
- Что такое Ауата?
- Что такое обнаружение аномалий?
- Основные проблемы, возникающие при аудите данных
- Аудит наборов данных для обнаружения аномалий
- Кодирование категориальных атрибутов
- Категориальные кодировки
- Модели обнаружения аномалий без присмотра
- Как кодирование категориальных атрибутов влияет на модели?
8.1 Представление t-SNE набора данных по страхованию автомобилей
8.2 Представление t-SNE набора данных по страхованию транспортных средств
8.3 Представление t-SNE набора данных о претензиях к транспортным средствам - Заключение
в Аудит данных?
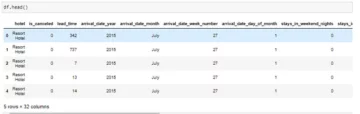
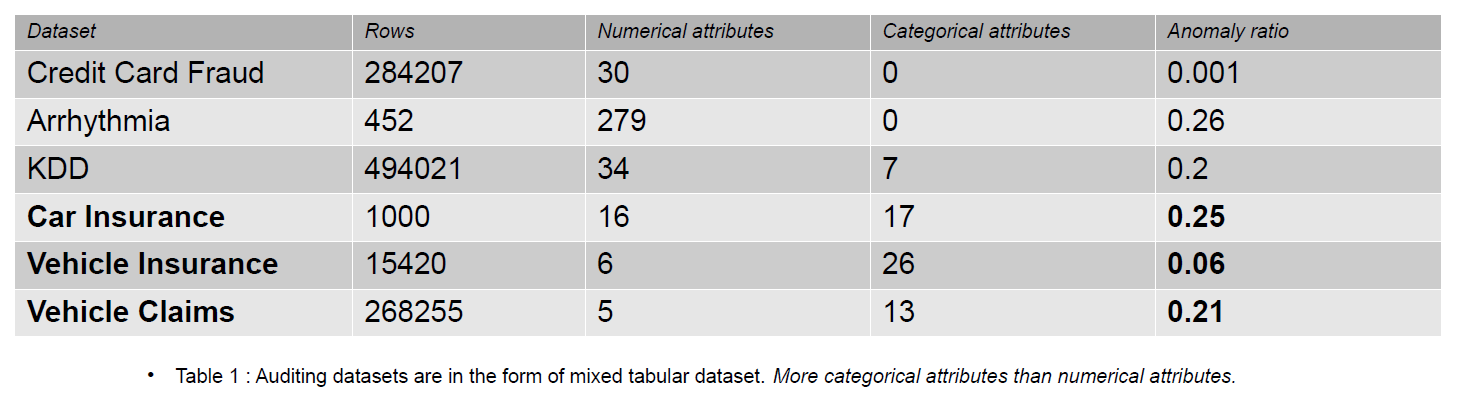
Данные аудита могут включать в себя журналы, страховые претензии и данные о вторжении для информационных систем; в данной статье приведенными примерами являются страховые случаи транспортных средств. Страховые претензии отличаются от наборов данных обнаружения аномалий, например, KDD, большим количеством категориальных признаков.
Категориальные признаки — это дискуты в наших данных, которые могут быть как целочисленными, так и символьными. Числовые признаки — это непрерывные атрибуты в наших данных, которые всегда имеют реальное значение. Наборы данных с числовыми характеристиками популярны в сообществе по обнаружению аномалий, например данные о мошенничестве с кредитными картами. Большинство общедоступных наборов данных содержат меньше категориальных признаков, чем данные о страховых выплатах. Категориальных признаков больше, чем числовых признаков в наборах данных о страховых претензиях.
Страховое требование включает в себя такие функции, как модель, бренд, доход, стоимость, выпуск, цвет и т. д. Количество категориальных функций в данных аудита больше, чем в наборах данных кредитной карты и KDD. Эти наборы данных являются эталонными в неконтролируемых методах обнаружения аномалий. Как видно из приведенной ниже таблицы, наборы данных о страховых претензиях имеют более категоричные характеристики, которые важны для понимания поведения мошеннических данных.
Наборы данных аудита, используемые для оценки влияния категориального кодирования, включают страхование автомобилей, страхование транспортных средств и претензии по транспортным средствам.
Что такое обнаружение аномалий?
Аномалия — это наблюдение, расположенное далеко от нормальных данных в наборе данных на определенное расстояние (порог). Что касается данных аудита, мы предпочитаем термин мошеннические данные. Обнаружение аномалий различает нормальные и мошеннические данные с использованием машинного обучения или модели глубокого обучения. Разные методы может использоваться для обнаружения аномалий, таких как оценка плотности, ошибка реконструкции и методы классификации.
- Оценка плотности – Эти методы оценивают нормальное распределение данных и классифицируют аномальные данные, если они не были выбраны из изученного распределения.
- Ошибка реконструкции – Методы восстановления на основе ошибок основаны на том принципе, что нормальные данные могут быть восстановлены с меньшими потерями, чем аномальные данные. Чем выше потери при реконструкции, тем выше вероятность того, что данные являются аномалией.
- Методы классификации – Методы классификации, такие как Случайный Лес, Изолирующий лес, Один класс — машины опорных векторов и Локальные факторы выбросов могут использоваться для обнаружения аномалий. Классификация при обнаружении аномалий включает идентификацию одного из классов как аномалии. Тем не менее, классы делятся на две группы (0 и 1) в мультиклассовом сценарии, и класс с меньшим количеством данных является аномальным классом.
Результатом вышеуказанных методов являются оценки аномалий или ошибки реконструкции. Затем мы должны определиться с порогом, в соответствии с которым мы классифицируем аномальные данные.
Основные проблемы, возникающие при аудите данных
- Обработка категориальных атрибутов: Кодирование категориальных атрибутов является обязательным, поскольку модель не может интерпретировать ввод текста. Таким образом, значения кодируются с помощью кодировки Label или One Hot. Но в большом наборе данных одно горячее кодирование преобразует данные в многомерное пространство за счет увеличения количества атрибутов. Модель работает плохо из-за проклятие размерности.
- Выбор порога для классификации: Если данные не помечены, трудно оценить производительность модели, потому что мы не знаем количество аномалий, присутствующих в наборе данных. Предварительные знания о наборе данных облегчают определение порога. Допустим, у нас есть 5 из 10 аномальных образцов в наших данных. Таким образом, мы можем выбрать порог на уровне 50-го процентиля.
- Общедоступные наборы данных: Большинство наборов данных аудита являются конфиденциальными, поскольку они принадлежат корпоративным компаниям и содержат конфиденциальную и личную информацию. Одним из возможных способов решения проблем с конфиденциальностью является обучение с использованием синтетических наборов данных (заявки на транспортное средство).
Аудит наборов данных для обнаружения аномалий
Страховые претензии для транспортных средств включают информацию о свойствах транспортного средства, таких как модель, марка, цена, год выпуска и тип топлива. Он включает в себя информацию о водителе, дату рождения, пол и профессию. Кроме того, претензия может содержать информацию об общей стоимости ремонта. Все наборы данных, используемые в этой статье, относятся к одному домену, но различаются по количеству атрибутов и количеству экземпляров.
-
Набор данных Vehicle Claims большой, содержит более 250,000 1171 строк, а его категориальные атрибуты имеют кардинальность XNUMX. Из-за большого размера этот набор данных страдает от проклятия размерности.
- Набор данных по страхованию транспортных средств имеет средний размер и содержит 15,420 151 строк и XNUMX уникальное значение категории. Это делает его менее подверженным проклятию размерности.
- Набор данных Car Insurance небольшой, с метками и 25% аномальных выборок, и он содержит такое же количество числовых и категориальных признаков. Имея 169 уникальных категорий, он не страдает от проклятия размерности.
Кодирование категориальных атрибутов
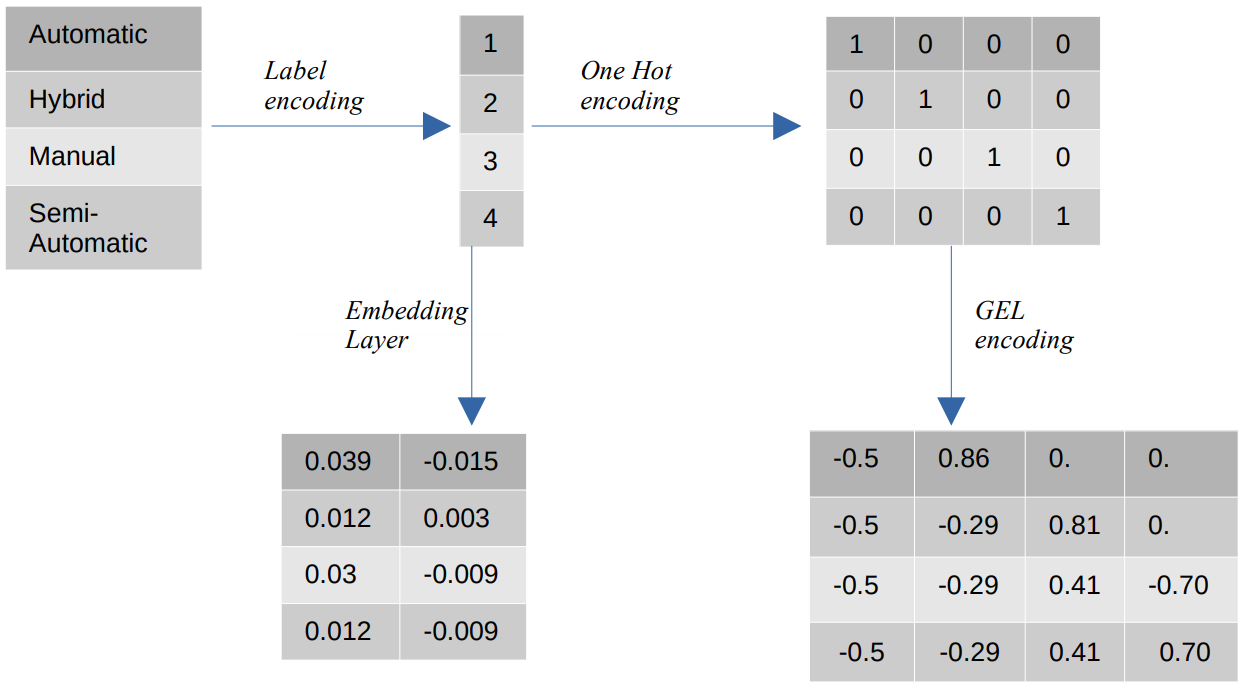
Различные кодировки категориальных значений
- Кодировка метки – При кодировании меток категориальные значения заменяются числовыми целыми значениями от 1 до количества категорий. Кодировка меток представляет категории предполагаемым образом для порядковых значений. Тем не менее, когда функции являются номинальными, представление неверно, поскольку категориальные значения не соответствуют определенному порядку.
Например, если у нас есть такие категории, как автоматический, гибридный, ручной и полуавтоматический в функции, кодирование меток преобразует эти значения в {1: автоматический, 2: гибридный, 3: ручной, 4: полуавтоматический}. Это представление не предоставляет информации о категориальных значениях, но такое представление, как {0: Низкое, 1: Среднее, 2: Высокое}, обеспечивает четкое представление, поскольку переменной признака Низкий присваивается более низкое числовое значение. Таким образом, кодирование меток лучше для порядковых значений, но невыгодно для номинальных значений. - Одна горячая кодировка – Одно горячее кодирование используется для решения проблемы номинальных значений кодирования, которое преобразует каждое категориальное значение в отдельный признак в наборе данных, состоящем из двоичных значений. Например, в случае четырех разных категорий, закодированных как {1, 2, 3, 4}, кодирование One Hot создаст новые функции, такие как {Автоматическое: [1,0,0,0], Гибридное: [0,1,0,0 ,0,0,1,0], Ручной: [0,0,0,1], Полуавтоматический: [XNUMX]}.
Затем размер набора данных напрямую зависит от количества категорий, присутствующих в наборе данных. В результате кодирование One Hot может привести к проклятию размерности, что является недостатком этого метода кодирования. - GEL-кодирование – Кодирование GEL – это метод встраивания, который можно использовать в контролируемых и неконтролируемых методах обучения. Он основан на принципе кодирования One Hot и может использоваться для уменьшения размерности категориальных признаков, которые были закодированы с использованием кодирования One Hot.
- Встраивание слоя – Вложения слов позволяют использовать компактное и плотное представление, в котором похожие слова имеют сходные кодировки. Вложение — это плотный вектор значений с плавающей запятой, которые являются обучаемыми параметрами. Вложения слов могут варьироваться от 8-мерных (для небольших наборов данных) до 1024-мерных (для больших наборов данных).
Встраивание более высокого измерения может фиксировать более подробные отношения между словами, но для его изучения требуется больше данных. Слой внедрения представляет собой таблицу поиска, которая преобразует каждое слово, присутствующее в матрице, в вектор определенного размера.
Модели обнаружения аномалий без присмотра
В реальном мире данные в большинстве случаев не маркируются, а маркировка данных требует больших затрат и времени. Поэтому мы будем использовать неконтролируемые модели для наших оценок.
- SOM – Самоорганизующаяся карта (SOM) — это метод конкурентного обучения, в котором веса нейронов обновляются конкурентно, а не с использованием обучения с обратным распространением. SOM состоит из карты нейронов, каждый из которых имеет весовой вектор того же размера, что и входной вектор. Весовой вектор инициализируется случайными весами перед началом обучения. Во время обучения каждый вход сравнивается с нейронами карты на основе метрики расстояния (например, евклидово расстояние) и сопоставляется с наилучшей соответствующей единицей (BMU), которая представляет собой нейрон с минимальным расстоянием до входного вектора.
Веса BMU обновляются весами входного вектора, а соседние нейроны обновляются на основе радиуса соседства (сигма). Поскольку нейроны соревнуются друг с другом за наилучшую совпадающую единицу, этот процесс известен как конкурентное обучение. В конце концов, нейроны для нормальных образцов расположены ближе, чем для аномальных. Показатели аномалий определяются ошибкой квантования, которая представляет собой разницу между входной выборкой и весами наилучшей совпадающей единицы. Более высокая ошибка квантования указывает на более высокую вероятность того, что образец является аномалией. - ДАГММ – Модель смеси Гаусса с глубоким автоматическим кодированием (DAGMM) — это метод оценки плотности, который предполагает, что аномалии лежат в области с низкой вероятностью. Сеть разделена на две части: сеть сжатия, которая используется для проецирования данных в более низкие измерения с помощью автоэнкодера, и сеть оценки, которая используется для оценки параметров смешанной модели Гаусса. DAGMM оценивает k число гауссовских смесей, где k может быть любым числом от 1 до N (количество точек данных), и предполагается, что нормальные точки лежат в области высокой плотности, что означает, что вероятность выборки из Гауссова смесь выше для нормальных точек, чем для аномальных выборок. Показатели аномалии определяются оценочной энергией образца.
- РСРЭЭ – Надежный уровень восстановления поверхности для неконтролируемого обнаружения аномалий — это метод реконструкции ошибок, который сначала проецирует данные в более низкое измерение с помощью автоэнкодера. Затем скрытое представление подвергается ортогональной проекции на линейное подпространство, устойчивое к выбросам. Затем декодер восстанавливает выходные данные из линейного подпространства. В этом методе более высокая ошибка реконструкции указывает на более высокую вероятность того, что образец является аномалией.
- СОМ-ДАГММ- Самоорганизующаяся карта (SOM) — модель смеси Гаусса с глубоким автоматическим кодированием (DAGMM) также является моделью оценки плотности. Как и DAGMM, он также оценивает распределение вероятностей нормальных точек данных и классифицирует точку данных как аномалию, если она имеет низкую вероятность выборки из изученного распределения. Основное различие между SOM-DAGMM и DAGMM заключается в том, что SOM-DAGMM включает нормализованные координаты SOM для входной выборки, что обеспечивает недостающую топологическую информацию в случае DAGMM для сети оценки. Цель также аналогична DAGMM в том, что оценки аномалии определяются оценочной энергией образца, а низкая энергия указывает на более высокую вероятность того, что образец является аномалией.
Далее мы рассмотрим проблему обработки категориальных атрибутов.
Как кодирование категориальных атрибутов влияет на модели?
Чтобы понять влияние различных кодировок на наборы данных, мы будем использовать t-SNE для визуализации низкоразмерных представлений данных для разных кодировок. t-SNE проецирует многомерные данные в низкоразмерное пространство, облегчая визуализацию. При сравнении визуализаций t-SNE и числовых результатов различных кодировок одного и того же набора данных наблюдается разница в полученных представлениях и понимании влияния кодирования на набор данных.
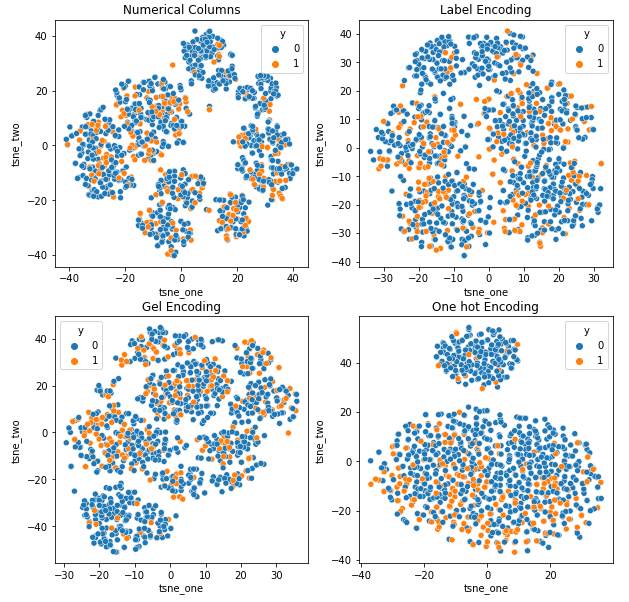
t-SNE представление набора данных Car Insurance
Представление t-SNE набора данных по страхованию транспортных средств
-
Данные ближе друг к другу, потому что количество строк больше, чем в наборе данных Car Insurance. Становится трудно разделить с повышенной размерностью в кодировании One Hot.
-
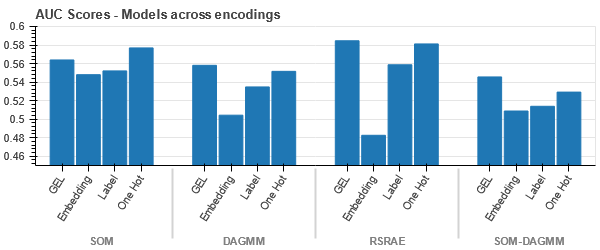
Кодирование GEL лучше, чем кодирование One Hot во всех случаях, кроме DAGMM.
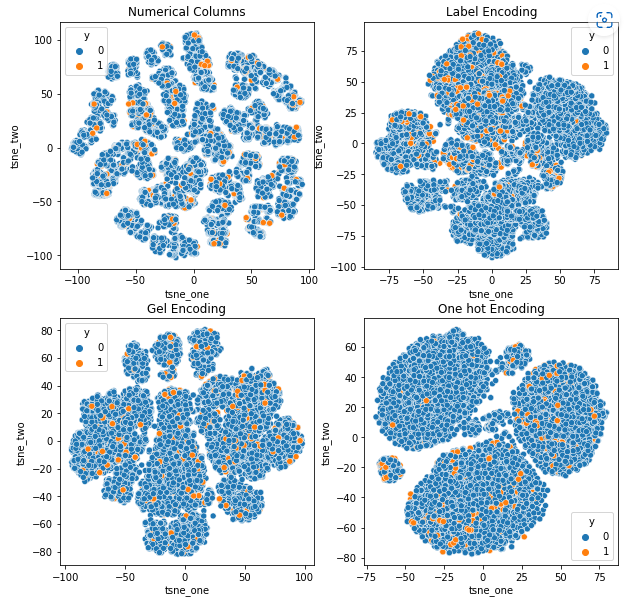
Представление t-SNE набора данных о претензиях к транспортным средствам
-
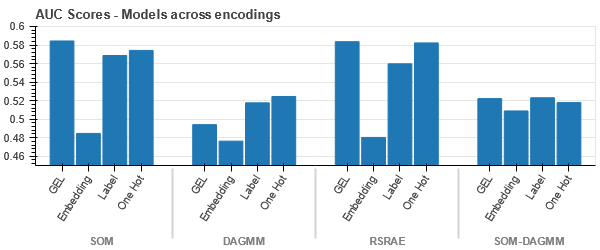
Данные тесно связаны во всех случаях, что затрудняет их разделение при увеличении размерности. Это одна из причин низкой производительности моделей из-за повышенной размерности.
- SOM превосходит все другие модели для этого набора данных. Тем не менее, в большинстве случаев более подходящим является слой внедрения, что дает нам альтернативу кодированию. категориальные атрибуты для обнаружения аномалий.
Заключение
В этой статье представлен краткий обзор данных аудита, обнаружения аномалий и категориального кодирования. Важно понимать, что обработка категориальных атрибутов при аудите данных является сложной задачей. Понимая влияние кодирования атрибутов на модели, мы можем повысить точность обнаружения аномалий в наборах данных. Основные выводы из этой статьи:
- По мере увеличения размера данных важно использовать альтернативные подходы к кодированию для категориальных атрибутов, такие как кодирование GEL и слои внедрения, поскольку кодирование One Hot не подходит.
- Одна модель не работает для всех наборов данных. Для табличных наборов данных знание предметной области чрезвычайно важно.
- Выбор метода кодирования зависит от выбора модели.
Код для оценки моделей доступен на GitHub.
Материалы, показанные в этой статье, не принадлежат Analytics Vidhya и используются по усмотрению Автора.
Похожие страницы:
- SEO-контент и PR-распределение. Получите усиление сегодня.
- Платоблокчейн. Интеллект метавселенной Web3. Расширение знаний. Доступ здесь.
- Источник: https://www.analyticsvidhya.com/blog/2023/01/impact-of-categorical-encodings-on-anomaly-detection-methods/
- 000
- 1
- 10
- 420
- a
- О нас
- выше
- По
- точность
- Дополнительно
- адрес
- Все
- позволяет
- альтернатива
- всегда
- аналитика
- Аналитика Видхья
- и
- обнаружение аномалии
- подходы
- гайд
- назначенный
- связанный
- предполагается,
- Атрибуты
- аудит
- Автоматический
- доступен
- основанный
- , так как:
- становится
- до
- не являетесь
- ниже
- тесты
- ЛУЧШЕЕ
- Лучшая
- между
- Крупнейшая
- связанный
- марка
- не могу
- захватить
- автомобиль
- страхование автомобиля
- карта
- случаев
- случаев
- категории
- вызов
- проблемы
- сложные
- шансы
- персонаж
- выбор
- утверждать
- требования
- класс
- классов
- классификация
- классифицировать
- Очистить
- ближе
- код
- цвет
- обычно
- сообщество
- Компании
- сравненный
- сравнив
- конкурировать
- конкурентоспособный
- комплекс
- сама концепция
- конфиденциальность
- Состоящий из
- содержит
- (CIJ)
- Корпоративное
- Цена
- Создайте
- кредит
- кредитная карта
- данным
- точки данных
- Наборы данных
- Время
- занимавшийся
- снижение
- глубоко
- глубокое обучение
- зависит
- подробный
- обнаружение
- Определять
- разница
- различный
- трудный
- Размеры
- размеры
- непосредственно
- усмотрение
- расстояние
- отчетливый
- распределение
- Разделенный
- домен
- водитель
- в течение
- каждый
- легче
- или
- энергетика
- ошибка
- ошибки
- оценка
- По оценкам,
- Оценки
- и т.д
- оценивать
- оценка
- оценки
- пример
- Примеры
- Кроме
- дорогим
- чрезвычайно
- сталкиваются
- факторы
- Особенность
- Особенности
- First
- лес
- мошенничество
- и мошенническими
- от
- топливо
- пол
- Группы
- Управляемость
- High
- высший
- ГОРЯЧИЙ
- Однако
- HTTPS
- Гибридный
- идентифицирующий
- Влияние
- важную
- улучшать
- in
- включают
- включает в себя
- доход
- расширились
- Увеличивает
- повышение
- указывает
- информация
- Информационные системы
- вход
- страхование
- изоляция
- вопрос
- вопросы
- IT
- Основные
- Знать
- знания
- известный
- этикетка
- маркировка
- Этикетки
- большой
- больше
- слой
- слоев
- вести
- УЧИТЬСЯ
- узнали
- изучение
- локальным
- расположенный
- поиск
- от
- потери
- Низкий
- машина
- обучение с помощью машины
- Продукция
- Главная
- ДЕЛАЕТ
- Создание
- обязательный
- руководство
- многих
- карта
- согласование
- матрица
- смысл
- Медиа
- средний
- метод
- методы
- метрический
- минимальный
- отсутствующий
- смягчать
- смесь
- модель
- Модели
- БОЛЕЕ
- самых
- сеть
- Нейроны
- Новые
- Новые функции
- "обычные"
- номер
- цель
- ONE
- заказ
- Другое
- Превосходит
- Преодолеть
- обзор
- принадлежащих
- параметры
- часть
- части
- производительность
- выполняет
- личного
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- Точка
- пунктов
- состояния потока
- Популярное
- возможное
- предпочитать
- представить
- разрабатывает
- цена
- принцип
- Предварительный
- вероятность
- Проблема
- процесс
- профессия
- Проект
- данные проекта
- Проекция
- проектов
- свойства
- обеспечивать
- при условии
- приводит
- опубликованный
- случайный
- ассортимент
- реальные
- реальный мир
- причины
- выздоровление
- область
- Отношения
- ремонт
- заменить
- представление
- представляет
- требуется
- результат
- в результате
- Итоги
- надежный
- то же
- Наука
- чувствительный
- отдельный
- показанный
- Сигма
- аналогичный
- с
- одинарной
- Размер
- небольшой
- меньше
- So
- Space
- конкретный
- начинается
- По-прежнему
- такие
- Страдает
- подходящее
- поддержка
- Поверхность
- синтетический
- системы
- ТАБЛИЦЫ
- Takeaways
- terms
- Ассоциация
- мир
- следовательно
- порог
- плотно
- кропотливый
- в
- Всего
- Train
- Обучение
- понимать
- понимание
- созданного
- Ед. изм
- неконтролируемое обучение
- обновление
- us
- использование
- ценностное
- Наши ценности
- автомобиль
- Транспорт
- вес
- Что
- Что такое
- который
- в то время как
- будете
- Word
- слова
- Работа
- Мир
- бы
- год
- зефирнет