Amazon Managed Workflows для Apache Airflow (Amazon MWAA) — это управляемая служба оркестрации для Воздушный поток Apache это упрощает настройку и эксплуатацию сквозных конвейеров данных в облаке в любом масштабе. Конвейер данных — это набор задач и процессов, используемых для автоматизации перемещения и преобразования данных между различными системами. Сообщество с открытым исходным кодом Apache Airflow предоставляет более 1,000 предварительно созданных операторов (плагинов, упрощающих подключение к службам) для Apache Airflow для создания конвейеров данных. Пакет провайдера Amazon для Apache Airflow поставляется с интеграцией для более чем 31 сервиса AWS, таких как Простой сервис хранения Amazon (Амазон С3), Амазонка Redshift, Амазонка ЭМИ, Клей AWS, Создатель мудреца АмазонкиИ многое другое.
Наиболее распространенным вариантом использования Airflow является ETL (извлечение, преобразование и загрузка). Почти все пользователи Airflow реализуют конвейеры ETL, начиная от простых и заканчивая сложными. Оперативное машинное обучение (ML) — еще один растущий вариант использования, когда данные должны быть преобразованы и нормализованы, прежде чем их можно будет загрузить в модель ML. В обоих случаях конвейер данных подготавливает данные к потреблению, получая данные из разных источников и преобразовывая их с помощью ряда шагов.
Наблюдение за различными процессами в конвейере данных является ключевым компонентом для отслеживания успеха или неудачи конвейера. Хотя планирование выполнения задач в конвейере данных контролируется Airflow, выполнение самой задачи (преобразование, нормализация и агрегирование данных) выполняется различными службами в зависимости от варианта использования. Наличие сквозного представления потока данных является проблемой из-за множества точек соприкосновения в конвейере данных.
В этом посте мы представляем обзор улучшений ведения журналов при работе с Amazon MWAA, который является одним из столпов наблюдаемости. Затем мы обсудим решение для дальнейшего повышения сквозной наблюдаемости путем изменения определений задач, составляющих конвейер данных. В этом посте мы сосредоточимся на определениях задач для двух сервисов: AWS Glue и Amazon EMR, однако один и тот же метод можно применять в разных сервисах.
Вызов
Конвейеры данных многих клиентов начинаются с простого, организуя несколько задач, и со временем становятся более сложными, состоящими из большого количества задач и зависимостей между ними. По мере увеличения сложности становится все труднее работать и отлаживать в случае сбоя, что создает потребность в единой панели управления для обеспечения сквозной оркестровки конвейера данных и управления работоспособностью. Для оркестровки конвейера данных Пользовательский интерфейс Apache Airflow — это удобный инструмент, который обеспечивает подробное представление вашего конвейера данных. Когда дело доходит до управления работоспособностью конвейера, каждая служба, с которой взаимодействуют ваши задачи, может хранить или публиковать журналы в разных местах, например в корзине S3 или Amazon CloudWatch журналы. По мере увеличения количества точек соприкосновения с интеграцией объединение распределенных журналов, созданных различными службами в разных местах, может стать сложной задачей.
Одно решение, предоставляемое Amazon MWAA, для консолидации журналов Airflow и задач в ориентированный ациклический граф (DAG) заключается в том, чтобы пересылать журналы на Группы журналов CloudWatch. Для каждой включенной опции ведения журнала Airflow создается отдельная группа журналов (например, DAGProcessing, Scheduler, Task, WebServerи Worker). Эти журналы можно запрашивать через группы журналов. с помощью CloudWatch Logs Insights.
Обычный подход к распределенной трассировке заключается в использовании идентификатора корреляции для объединения и запроса распределенных журналов. Идентификатор корреляции — это уникальный идентификатор, который передается через поток запросов для отслеживания последовательности действий на протяжении всего жизненного цикла рабочего процесса. Когда каждой службе в рабочем процессе необходимо регистрировать информацию, она может включать этот идентификатор корреляции, тем самым гарантируя, что вы сможете отслеживать полный запрос от начала до конца.
Двигатель Airflow проходит несколько переменные по умолчанию доступны для всех шаблонов. run_id — одна из таких переменных, которая является уникальным идентификатором для запуска DAG. run_id можно использовать в качестве идентификатора корреляции для запросов к различным группам журналов в CloudWatch для сбора всех журналов для определенного запуска DAG.
Однако имейте в виду, что службы, с которыми взаимодействуют ваши задачи, будут использовать отдельную группу журналов и не будут регистрировать run_id как часть их продукции. Это не позволит вам получить сквозное представление о выполнении DAG.
Например, если ваш конвейер данных состоит из задачи AWS Glue, выполняющей задание Spark как часть конвейера, то журналы задач Airflow будут доступны в одной группе журналов CloudWatch, а журналы заданий AWS Glue — в другой группе журналов CloudWatch. . Однако задание Spark, которое выполняется как часть задания AWS Glue, не имеет доступа к идентификатору корреляции и не может быть привязано к конкретному запуску DAG. Таким образом, даже если вы используете идентификатор корреляции для запроса различных групп журналов CloudWatch, вы не получите никакой информации о выполнении задания Spark.
Обзор решения
Как вы теперь знаете, run_id — это переменная, которая является уникальным идентификатором для запуска DAG. run_id присутствует как часть журналов задач Airflow. Чтобы использовать run_id эффективно и повышать наблюдаемость при прогоне DAG, мы используем run_id в качестве идентификатора корреляции и передавать его различным задачам с помощью DAG. Затем идентификатор корреляции используется сценариями, используемыми в задачах.
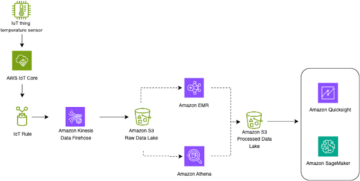
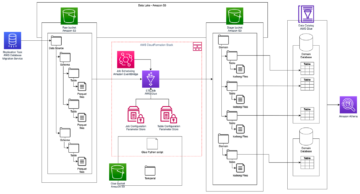
Следующая диаграмма иллюстрирует архитектуру решения.
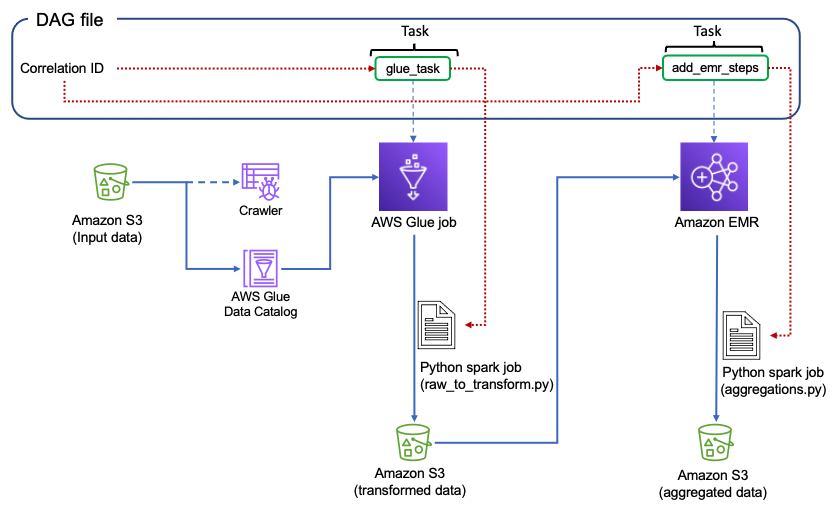
Конвейер данных, на котором мы сосредоточимся, состоит из следующих компонентов:
- Ведро S3, содержащее исходные данные.
- An AWS Glue Crawler который создает метаданные таблицы в каталоге данных из исходных данных
- An AWS Glue работа который преобразует необработанные данные в формат обработанных данных при выполнении преобразования формата файла
- An работа ЭМИ который генерирует отчетные наборы данных
Подробные сведения об архитектуре и полные шаги по запуску группы обеспечения доступности баз данных см. Семинар по Amazon MWAA для аналитики.
В следующих разделах мы рассмотрим следующие темы:
- Файл DAG, чтобы понять, как определить, а затем передать идентификатор корреляции в задачах AWS Glue и EMR.
- Код, необходимый в сценариях Python для вывода информации на основе идентификатора корреляции.
См. Репо GitHub для подробного определения DAG и сценариев Spark. Для запуска скриптов см. Семинар по аналитике Amazon MWAA.
Определения группы обеспечения доступности баз данных
В этом разделе мы рассмотрим фрагменты дополнений, необходимых для файла DAG. Мы также обсудим, как передать идентификатор корреляции заданиям AWS Glue и EMR. Обратитесь к Репо GitHub для полного кода DAG.
Файл DAG начинается с определения переменных:
# Переменные
Далее рассмотрим, как передать идентификатор корреляции в задание AWS Glue с помощью оператора AWS Glue. Операторы являются строительными блоками групп доступности баз данных Airflow. Они содержат логику обработки данных в конвейере данных. Каждая задача в DAG определяется созданием экземпляра оператора.
Airflow предоставляет операторам различные задачи. Для этого поста мы используем Оператор клея AWS.
Определение задачи AWS Glue содержит следующее:
- Сценарий задания Python Spark (raw_to_transform.py) для запуска задания
- Имя DAG, идентификатор задачи и идентификатор корреляции, которые передаются в качестве аргументов.
- Ассоциация Роль сервиса AWS Glue назначенный, у которого есть разрешения на запуск искателя и заданий
Смотрите следующий код:
# Определение задачи склеивания
Затем мы передаем идентификатор корреляции в задание EMR, используя оператор ЭМИ. Это включает следующие шаги:
- Определите конфигурацию кластера EMR.
- Создайте кластер EMR.
- Определите шаги, которые должны выполняться заданием EMR.
- Запустите задание EMR:
- Мы используем скрипт задания Python Spark агрегации.py.
- Мы передаем имя DAG, идентификатор задачи и идентификатор корреляции в качестве аргументов шагов для задачи EMR.
Начнем с определения конфигурации кластера EMR. correlation_id передается в имени кластера, чтобы легко идентифицировать кластер, соответствующий запуску DAG. Журналы, созданные заданиями EMR, публикуются в корзине S3; в correlation_id является частью LogUri также. См. следующий код:
# Определить конфигурацию кластера EMR
Теперь определим задачу по созданию кластера EMR на основе конфигурации:
# Создаем кластер EMR
cluster_creator = EmrCreateJobFlowOperator( task_id= emr_task_id, job_flow_overrides=JOB_FLOW_OVERRIDES, aws_conn_id=’aws_default’, emr_conn_id=’emr_default’, dag=dag
)Далее давайте определим шаги, необходимые для выполнения в рамках задания EMR. Входные и выходные данные, обрабатываемые заданием EMR, хранятся в сегменте S3, который передается в качестве аргументов. Dag_name, task_idи correlation_id также передаются в качестве аргументов. Используемый task_id может быть именем по вашему выбору; здесь мы используем add_steps:
# шаги EMR, которые должны быть выполнены кластером EMR
Далее добавим задачу для выполнения шагов в кластере EMR. job_flow_id это идентификатор JobFlow, который передается из EMR create task описано ранее с использованием XComs с воздушным потоком, Смотрите следующий код:
# Запустить задание EMR
Это завершает шаги, необходимые для передачи идентификатора корреляции в определении задачи DAG.
В следующем разделе мы используем этот идентификатор в скрипте для регистрации подробностей.
Определения сценария работы
В этом разделе мы рассмотрим изменения, необходимые для регистрации информации на основе correlation_id. Начнем со сценария задания AWS Glue (полный код см. файл в Гитхабе):
# Скрипт изменяет файл 'raw_to_transform'
Далее мы сосредоточимся на сценарии задания EMR (полный код см. файл в Гитхабе):
# Скрипт изменяет файл 'nyc_aggregations'
На этом шаги по передаче идентификатора корреляции в запуск скрипта завершены.
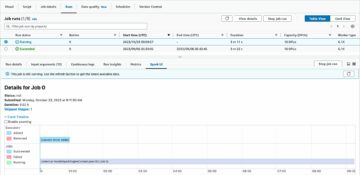
После того, как мы завершим определения DAG и добавим скрипты, мы можем запустить DAG. Журналы для конкретного запуска DAG можно запрашивать с помощью идентификатора корреляции. Идентификатор корреляции для запуска DAG можно найти с помощью Интерфейс воздушного потока. Пример идентификатора корреляции: manual__2022-07-12T00:22:36.111190+00:00. С помощью этой уникальной строки мы можем выполнять запросы к соответствующим группам журналов CloudWatch с помощью CloudWatch Logs Insights. Результат запроса включает журнал, предоставленный сценариями AWS Glue и EMR, а также другие журналы, связанные с идентификатором корреляции.
Пример запроса для журналов уровня DAG: manual__2022-07-12T00:22:36.111190+00:00
Мы также можем получить журналы уровня задачи, используя формат <dag_name.task_id correlation_id>:
Пример запроса: data_pipeline.glue_task manual__2022-07-12T00:22:36.111190+00:00
Убирать
Если вы создали установку для запуска и тестирования скриптов с помощью Семинар по аналитике Amazon MWAA, выполните уборка шаги, чтобы избежать обвинений.
Заключение
В этом посте мы показали, как отправлять журналы Amazon MWAA в группы журналов CloudWatch. Затем мы обсудили, как связать журналы разных задач в группе обеспечения доступности баз данных с помощью уникального идентификатора корреляции. Идентификатор корреляции может быть выведен с любым количеством информации, необходимой для вашего задания, чтобы предоставить более подробную информацию по всему вашему запуску DAG. Затем вы можете использовать CloudWatch Logs Insights для запроса журналов.
Благодаря этому решению вы можете использовать Amazon MWAA как единую панель управления конвейером данных и журналы CloudWatch для управления состоянием конвейера данных. Уникальный идентификатор улучшает сквозную наблюдаемость выполнения группы обеспечения доступности баз данных и помогает сократить время, необходимое для устранения неполадок.
Чтобы узнать больше и получить практический опыт, начните с Семинар по аналитике Amazon MWAA а затем использовать сценарии в Репо GitHub чтобы получить больше наблюдаемости вашего запуска DAG.
Об авторе
 Паял Сингх является архитектором партнерских решений в Amazon Web Services, специализирующимся на бессерверной платформе. Она отвечает за помощь партнерам и клиентам в модернизации и переносе их приложений на AWS.
Паял Сингх является архитектором партнерских решений в Amazon Web Services, специализирующимся на бессерверной платформе. Она отвечает за помощь партнерам и клиентам в модернизации и переносе их приложений на AWS.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- Платоблокчейн. Интеллект метавселенной Web3. Расширение знаний. Доступ здесь.
- Источник: https://aws.amazon.com/blogs/big-data/improve-observability-across-amazon-mwaa-tasks/
- 000
- 1
- 10
- 100
- 11
- a
- О нас
- доступ
- доступной
- через
- активно
- ациклический
- дополнениями
- против
- Все
- Несмотря на то, что
- Amazon
- Amazon Web Services
- аналитика
- и
- Другой
- апаш
- Приложения
- прикладной
- подхода
- архитектура
- Аргументы
- назначенный
- связанный
- автоматизировать
- доступен
- избежать
- AWS
- Клей AWS
- назад
- основанный
- становится
- до
- между
- Блоки
- строить
- строитель
- Строительство
- захватить
- случаев
- случаев
- каталог
- вызов
- сложные
- изменения
- расходы
- выбор
- облако
- Кластер
- код
- Общий
- сообщество
- полный
- зАВЕРШАЕТ
- комплекс
- сложность
- компонент
- компоненты
- Конфигурация
- Коммутация
- Состоящий из
- консолидировать
- потребленный
- потребление
- содержит
- контроль
- Основные
- Корреляция
- соответствующий
- может
- гусеничный
- Создайте
- создали
- создает
- Клиенты
- DAG
- данным
- По умолчанию
- определенный
- определяющий
- описано
- подробный
- подробнее
- различный
- обсуждать
- обсуждается
- распределенный
- не
- вниз
- каждый
- Ранее
- легко
- фактически
- включен
- впритык
- Двигатель
- обеспечение
- Весь
- Эфир (ETH)
- Даже
- пример
- опыт
- Больше
- извлечение
- Ошибка
- несколько
- Файл
- окончание
- поток
- Фокус
- внимание
- после
- формат
- вперед
- найденный
- от
- полный
- Функции
- далее
- Gain
- генерируется
- генерирует
- получить
- получающий
- GitHub
- стекло
- график
- группы
- Группы
- Расти
- Рост
- практический
- Жесткий
- имеющий
- Медицина
- помощь
- помогает
- здесь
- Как
- How To
- Однако
- HTML
- HTTPS
- идентификатор
- определения
- осуществлять
- Импортировать
- улучшать
- улучшается
- in
- включают
- включает в себя
- Увеличение
- Увеличивает
- все больше и больше
- информация
- вход
- размышления
- интеграции.
- интеграций
- взаимодействующий
- IT
- саму трезвость
- работа
- Джобс
- Основные
- Знать
- большой
- УЧИТЬСЯ
- изучение
- уровень
- продолжительность жизни
- мало
- загрузка
- места
- Лог4дж
- посмотреть
- машина
- обучение с помощью машины
- сделать
- ДЕЛАЕТ
- управляемого
- управление
- рынок
- мастер
- Метаданные
- метод
- мигрировать
- ML
- модель
- Модели
- модернизировать
- монитор
- БОЛЕЕ
- самых
- движение
- с разными
- имя
- почти
- Необходимость
- необходимый
- потребности
- следующий
- узлы
- номер
- получать
- ONE
- с открытым исходным кодом
- работать
- оператор
- Операторы
- Опция
- оркестровка
- заказ
- Другое
- обзор
- хлеб
- часть
- особый
- партнер
- Прошло
- проходит
- Прохождение
- выполнять
- выполнения
- Разрешения
- трубопровод
- Платформа
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- плагины
- пунктов
- После
- подготовка
- представить
- предотвращать
- Процессы
- обеспечивать
- при условии
- Недвижимости
- поставщики
- приводит
- опубликованный
- Издательство
- Питон
- ранжирование
- Сырье
- необработанные данные
- уменьшить
- соответствующие
- Reporting
- запросить
- обязательный
- ответственный
- результат
- обзоре
- Run
- Бег
- то же
- SC
- Шкала
- скрипты
- Раздел
- разделах
- отдельный
- Последовательность
- Серии
- Serverless
- обслуживание
- Услуги
- Сессия
- набор
- установка
- просто
- упростить
- одинарной
- So
- Решение
- Решения
- Источник
- Источники
- Искриться
- SQL
- Начало
- и политические лидеры
- Шаги
- диск
- хранить
- успех
- такие
- системы
- ТАБЛИЦЫ
- Сложность задачи
- задачи
- шаблоны
- тестXNUMX
- Ассоциация
- Источник
- их
- тем самым
- Через
- по всему
- TIE
- Связанный
- время
- в
- инструментом
- Темы
- трогать
- трассировка
- трек
- Отслеживание
- Transform
- трансформация
- преобразован
- превращение
- правда
- понимать
- созданного
- Применение
- использование
- прецедент
- удобно
- пользователей
- различный
- с помощью
- Вид
- Просмотры
- Web
- веб-сервисы
- который
- в то время как
- будете
- в
- рабочий
- Рабочие процессы
- работает
- Семинары
- ВАШЕ
- зефирнет