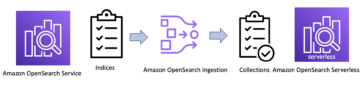
Недавно мы объявили об общедоступности Amazon OpenSearch без сервера , новый вариант для Сервис Amazon OpenSearch это упрощает выполнение крупномасштабных поисковых и аналитических рабочих нагрузок без необходимости настройки, управления или масштабирования кластеров OpenSearch. С OpenSearch Serverless вы получаете такое же интерактивное время отклика в миллисекундах, как и OpenSearch Service, но с простотой бессерверной среды.
В этом посте вы узнаете, как перенести существующие индексы из домена кластера, управляемого службой OpenSearch, в бессерверную коллекцию с помощью Logstash.
С доменами OpenSearch вы получаете выделенные безопасные кластеры, настроенные и оптимизированные для ваших рабочих нагрузок за считанные минуты. У вас есть полный контроль над конфигурацией вычислительных ресурсов, памяти и ресурсов хранения в кластерах для оптимизации затрат и производительности ваших приложений. OpenSearch Serverless предоставляет еще более простой способ запуска рабочих нагрузок поиска и аналитики, даже не задумываясь о кластерах. Вы просто создаете коллекцию и группу индексов и можете начать принимать и запрашивать данные.
Обзор решения
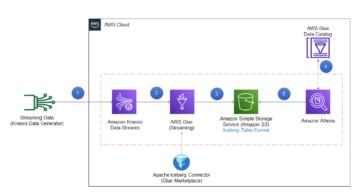
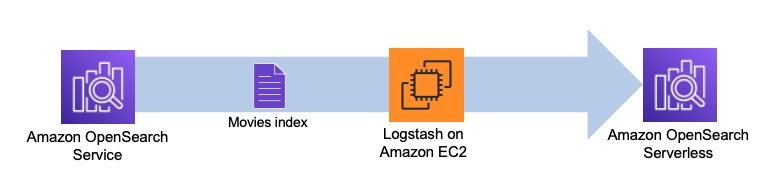
Logstash это программное обеспечение с открытым исходным кодом, которое обеспечивает ETL (извлечение, преобразование и загрузка) для ваших данных. Вы можете настроить Logstash для подключения к источнику и месту назначения через плагины ввода и вывода. В промежутках вы настраиваете фильтры, которые могут преобразовывать ваши данные. В этом посте описаны шаги, необходимые для настройки Logstash для подключения домена службы OpenSearch (вход) к коллекции OpenSearch Serverless (выход).
Вы устанавливаете исходный и конечный плагины в конфигурационном файле Logstash. В конфигурационном файле есть разделы для Input, Filterи Output. После настройки Logstash отправит запрос в домен службы OpenSearch и прочитает данные в соответствии с запросом, который вы указали в input раздел. После того, как данные будут прочитаны из OpenSearch Service, вы можете при желании отправить их на следующий этап. Filter для преобразований, таких как добавление или удаление поля из входных данных или обновление поля с другими значениями. В этом примере вы не будете использовать Filter плагин. Далее идет Output плагин. Версия Logstash с открытым исходным кодом (Logstash OSS) предоставляет удобный способ использования массового API для загрузки данных в ваши коллекции. OpenSearch Serverless поддерживает logstash-выход-opensearch выходной плагин, который поддерживает Управление идентификацией и доступом AWS (IAM) учетные данные для управления доступом к данным.
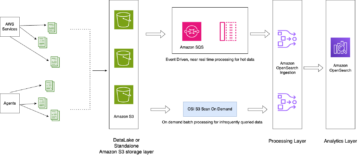
Следующая диаграмма иллюстрирует рабочий процесс нашего решения.
Предпосылки
Прежде чем начать, убедитесь, что вы выполнили следующие предварительные условия:
- Запишите ARN, имя пользователя и пароль вашего домена службы OpenSearch.
- Создайте коллекцию OpenSearch Serverless. Если вы новичок в OpenSearch Serverless, см. Простой анализ журналов с помощью Amazon OpenSearch Serverless для получения подробной информации о том, как настроить свою коллекцию.
Настройте Logstash и плагины ввода и вывода для OpenSearch.
Выполните следующие шаги, чтобы настроить Logstash и ваши плагины:
- Скачать
logstash-oss-with-opensearch-output-plugin. (В этом примере используется дистрибутив для macos-x64. Другие дистрибутивы см. артефактов.) - Извлеките загруженный архив:
- Обновите
logstash-output-opensearchплагин последней версии: - Установить
logstash-input-opensearchплагин:
Протестируйте плагин
Давайте начнем и посмотрим, как работает плагин. Следующий файл конфигурации извлекает данные из movies индексировать в вашем домене службы OpenSearch и индексировать эти данные в вашей коллекции OpenSearch Serverless с тем же именем индекса, movies.
Создайте новый файл и добавьте следующее содержимое, затем сохраните файл как opensearch-serverless-migration.conf. Укажите значения для конечной точки домена службы OpenSearch в разделе ВЕДУЩИЙ, USERNAMEи PASSWORD в input раздел и сведения о конечной точке коллекции OpenSearch Serverless в разделе ВЕДУЩИЙ вместе с РЕГИОН, AWS_ACCESS_KEY_IDи AWS_SECRET_ACCESS_KEY в output .
Вы можете задать запрос в input раздел предыдущей конфигурации. match_all запрос соответствует всем данным в movies индекс. Вы можете изменить запрос, если хотите выбрать подмножество данных. Вы также можете использовать запрос для распараллеливания передачи данных, запустив несколько процессов Logstash с конфигурациями, которые определяют разные срезы данных. Вы также можете распараллелить, запустив процессы Logstash для нескольких индексов, если они у вас есть.
Запустить Логсташ
Используйте следующую команду для запуска Logstash:
После того, как вы запустите команду, Logstash извлечет данные из исходного индекса из вашего домена службы OpenSearch и запишет в целевой индекс в вашей коллекции OpenSearch Serverless. Когда передача данных завершена, Logstash закрывается. См. следующий код:
Проверка данных в OpenSearch Serverless
Вы можете убедиться, что Logstash скопировал все ваши данные, сравнив количество документов в вашем домене и в вашей коллекции. Запустите следующий запрос либо из Инструменты разработки вкладка или с curl, postmanили аналогичный HTTP-клиент. Следующий запрос поможет вам найти все документы из movies index и возвращает лучшие документы вместе со счетчиком. По умолчанию OpenSearch возвращает количество документов, не превышающее 10,000 XNUMX. Добавление track_total_hits флаг помогает вам получить точное количество документов, если количество документов превышает 10,000 XNUMX.
Заключение
В этом посте вы перенесли данные из своего домена службы OpenSearch в свою коллекцию OpenSearch Serverless с помощью подключаемых модулей ввода и вывода Logstash OpenSearch.
Следите за серией сообщений, посвященных различным вариантам, доступным для создания эффективных решений для анализа журналов и поиска с помощью OpenSearch Serverless. Вы также можете обратиться к Начало работы с Amazon OpenSearch Serverless мастер-класс, чтобы узнать больше об OpenSearch Serverless.
Если у вас есть отзывы об этом посте, отправьте их в разделе комментариев. Если у вас есть вопросы по этому сообщению, начните новую тему на Форум сервиса Amazon OpenSearch or связаться со службой поддержки AWS.
Об авторах
 Прашант Агравал является старшим специалистом по поиску, архитектором решений в Amazon OpenSearch Service. Он тесно сотрудничает с клиентами, помогая им перенести свои рабочие нагрузки в облако, и помогает существующим клиентам настраивать свои кластеры для повышения производительности и экономии средств. Перед тем, как присоединиться к AWS, он помогал различным клиентам использовать OpenSearch и Elasticsearch для поиска и анализа журналов. Когда он не работает, вы можете найти его путешествующим и исследующим новые места. Короче говоря, ему нравится делать «Ешь» → «Путешествуй» → «Повторять».
Прашант Агравал является старшим специалистом по поиску, архитектором решений в Amazon OpenSearch Service. Он тесно сотрудничает с клиентами, помогая им перенести свои рабочие нагрузки в облако, и помогает существующим клиентам настраивать свои кластеры для повышения производительности и экономии средств. Перед тем, как присоединиться к AWS, он помогал различным клиентам использовать OpenSearch и Elasticsearch для поиска и анализа журналов. Когда он не работает, вы можете найти его путешествующим и исследующим новые места. Короче говоря, ему нравится делать «Ешь» → «Путешествуй» → «Повторять».
 Джон Хэндлер (@_searchgeek) — старший главный архитектор решений в Amazon Web Services в Пало-Альто, Калифорния. Джон тесно сотрудничает с командами CloudSearch и Elasticsearch, предоставляя помощь и рекомендации широкому кругу клиентов, у которых есть поисковые рабочие нагрузки, которые они хотят перенести в облако AWS. До прихода в AWS карьера Джона в качестве разработчика программного обеспечения включала четыре года кодирования крупной поисковой системы для электронной коммерции.
Джон Хэндлер (@_searchgeek) — старший главный архитектор решений в Amazon Web Services в Пало-Альто, Калифорния. Джон тесно сотрудничает с командами CloudSearch и Elasticsearch, предоставляя помощь и рекомендации широкому кругу клиентов, у которых есть поисковые рабочие нагрузки, которые они хотят перенести в облако AWS. До прихода в AWS карьера Джона в качестве разработчика программного обеспечения включала четыре года кодирования крупной поисковой системы для электронной коммерции.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- Платоблокчейн. Интеллект метавселенной Web3. Расширение знаний. Доступ здесь.
- Источник: https://aws.amazon.com/blogs/big-data/migrate-your-indexes-to-amazon-opensearch-serverless-with-logstash/
- 000
- 10
- 100
- 28
- 39
- 7
- a
- О нас
- доступ
- По
- Достигать
- Действие
- После
- против
- Агент
- Все
- Amazon
- Amazon Web Services
- аналитика
- и
- объявило
- API
- Приложения
- свободных мест
- доступен
- AWS
- основанный
- до
- Лучшая
- между
- широкий
- строить
- CA
- Карьера
- случаев
- CD
- изменение
- клиент
- тесно
- облако
- Кластер
- код
- Кодирование
- лыжных шлемов
- Коллекции
- Комментарии
- сравнив
- полный
- Заполненная
- Вычисление
- Конфигурация
- Свяжитесь
- содержание
- контроль
- Удобно
- Цена
- Создайте
- Полномочия
- Клиенты
- данным
- доступ к данным
- преданный
- По умолчанию
- назначение
- подробнее
- Застройщик
- различный
- инвалид
- документ
- Документация
- дело
- домен
- доменов
- вниз
- есть
- электронной коммерции
- Эффективный
- или
- Elasticsearch
- Конечная точка
- Двигатель
- Окружающая среда
- Эфир (ETH)
- Даже
- НИКОГДА
- пример
- превышает
- существующий
- Исследование
- извлечение
- Обратная связь
- поле
- Файл
- фильтры
- Найдите
- фокусировка
- после
- от
- полный
- Общие
- получить
- получающий
- группы
- имеющий
- помощь
- помог
- помогает
- Как
- How To
- HTTPS
- IAM
- Личность
- in
- включены
- индекс
- Индексы
- Индексы
- info
- вход
- устанавливать
- интерактивный
- IT
- присоединение
- Знать
- крупномасштабный
- последний
- УЧИТЬСЯ
- загрузка
- Главная
- сделать
- ДЕЛАЕТ
- управлять
- управляемого
- максимальный
- Память
- мигрировать
- миллисекунды
- минут
- БОЛЕЕ
- двигаться
- Кино
- с разными
- имя
- Необходимость
- Новые
- следующий
- с открытым исходным кодом
- Программное обеспечение с открытым исходным кодом
- Оптимизировать
- оптимизированный
- Опция
- Опции
- Oss
- Другое
- Пало-Альто
- Пароль
- производительность
- трубопровод
- Мест
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- плагин
- плагины
- После
- Блог
- предпосылки
- Основной
- Предварительный
- Процессы
- обеспечивать
- приводит
- обеспечение
- положил
- Вопросы
- ассортимент
- Читать
- недавно
- область
- реестра
- удален
- удаление
- повторять
- запросить
- Полезные ресурсы
- ответ
- возвращают
- Возвращает
- Run
- бегун
- Бег
- то же
- Сохранить
- Шкала
- Поиск
- Поисковая система
- Раздел
- разделах
- безопасный
- Серии
- Serverless
- обслуживание
- Услуги
- набор
- Короткое
- выключать
- Завершает
- аналогичный
- простота
- просто
- Software
- Решение
- Решения
- Источник
- специалист
- Этап
- Начало
- и политические лидеры
- Шаги
- диск
- отправить
- Успешно
- такие
- Поддержка
- команды
- Ассоциация
- Источник
- их
- Через
- раз
- в
- топ
- перевод
- Transform
- преобразований
- путешествовать
- Путешествие
- правда
- под
- Обновление ПО
- обновление
- использование
- Информация о пользователе
- Наши ценности
- различный
- проверить
- версия
- с помощью
- Web
- веб-сервисы
- который
- КТО
- будете
- без
- рабочий
- работает
- работает
- семинар
- Семинары
- записывать
- лет
- ВАШЕ
- зефирнет