NLP с несколькими метками относится к задаче назначения нескольких меток для данного текстового ввода, а не только одной метки. В традиционных задачах НЛП, таких как классификация текста или анализ тональности, каждому вводу обычно назначается одна метка на основе его содержимого. Однако во многих реальных сценариях фрагмент текста может принадлежать к нескольким категориям или одновременно выражать несколько настроений.
NLP с несколькими метками важен, потому что он позволяет нам извлекать более тонкую и сложную информацию из текстовых данных. Например, в области анализа отзывов клиентов отзыв клиента может выражать как положительные, так и отрицательные чувства одновременно, или он может касаться нескольких аспектов продукта или услуги. Назначая таким входным данным несколько ярлыков, мы можем получить более полное представление об отзывах клиентов и предпринять более целенаправленные действия для решения их проблем.
В этой статье рассматривается примечательный случай использования Provectus НЛП с несколькими метками.
Справочная информация:
К нам обратился клиент с просьбой помочь им автоматизировать маркировку документов определенного типа. На первый взгляд задача казалась простой и легко решаемой. Однако, когда мы работали над этим случаем, мы столкнулись с набором данных с несогласованными аннотациями. Хотя наш клиент сталкивался с проблемами, связанными с различными номерами классов и изменениями в их группе проверки с течением времени, он приложил значительные усилия для создания разнообразного набора данных с рядом аннотаций. Несмотря на то, что в маркировке существовали некоторые диспропорции и неопределенности, этот набор данных предоставил ценную возможность для анализа и дальнейшего изучения.
Давайте подробнее рассмотрим набор данных, изучим метрики и наш подход, а также вспомним, как Provectus решил проблему классификации текста с несколькими метками.
Набор данных содержит 14,354 124 наблюдения со XNUMX уникальными классами (метками). Наша задача — присвоить каждому наблюдению один или несколько классов.
В таблице 1 представлена описательная статистика для набора данных.
В среднем у нас есть около двух классов на одно наблюдение, в среднем 261 различных текстов, описывающих один класс.

Таблица 1: Статистика набора данных
На рисунке 1 мы видим распределение классов на верхнем графике, и у нас есть определенное количество меток HEAD с наибольшей частотой встречаемости в наборе данных. Также обратите внимание, что большинство классов имеют низкую частоту встречаемости.
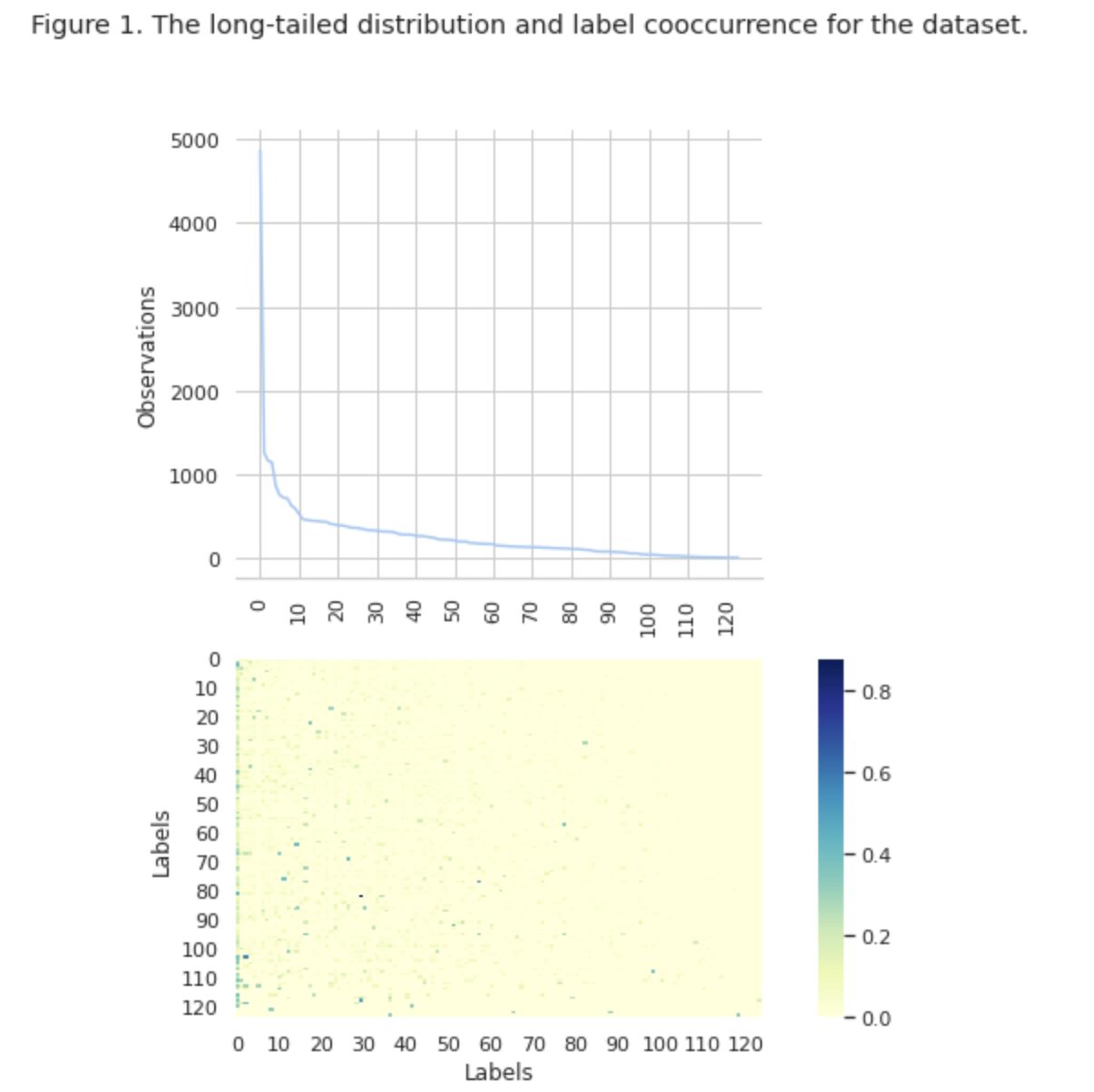
На нижнем графике мы видим частое совпадение между классами, которые лучше всего представлены в наборе данных, и классами с низкой значимостью.
Мы изменили процесс разделения набора данных на наборы train/val/test. Вместо использования традиционного метода мы применили итеративную стратификацию, чтобы обеспечить хорошо сбалансированное распределение доказательств отношений меток. Для этого мы использовали Scikit Мультиобучение
from skmultilearn.model_selection import iterative_train_test_split mlb = MultiLabelBinarizer() def balanced_split(df, mlb, test_size=0.5): ind = np.expand_dims(np.arange(len(df)), axis=1) mlb.fit_transform(df["tag"]) labels = mlb.transform(df["tag"]) ind_train, _, ind_test, _ = iterative_train_test_split( ind, labels, test_size ) return df.iloc[ind_train[:, 0]], df.iloc[ind_test[:, 0]] df_train, df_tmp = balanced_split(df, test_size=0.4)
df_val, df_test = balanced_split(df_tmp, test_size=0.5)
Мы получили следующее распределение:
- Набор обучающих данных содержит 60% данных и охватывает все 124 метки.
- Набор данных проверки содержит 20% данных и охватывает все 124 ярлыка.
- Тестовый набор данных содержит 20% данных и охватывает все 124 метки.
Классификация с несколькими метками — это тип контролируемого алгоритма машинного обучения, который позволяет нам назначать несколько меток одной выборке данных. Она отличается от бинарной классификации, где модель предсказывает только две категории, и многоклассовой классификации, когда модель предсказывает только один из нескольких классов для выборки.
Метрики оценки для производительности классификации с несколькими метками по своей сути отличаются от тех, которые используются в классификации с несколькими классами (или двоичной) из-за присущих различий проблемы классификации. Более подробную информацию можно найти в Википедии.
Мы выбрали наиболее подходящие для нас метрики:
- Точность измеряет долю истинных положительных прогнозов среди всех положительных прогнозов, сделанных моделью.
- Вспоминать измеряет долю истинных положительных прогнозов среди всех фактических положительных образцов.
- F1-оценка является гармоническим средним значением точности и отзыва, которое помогает восстановить баланс между ними.
- Потеря Хэмминга это доля меток, которые неверно предсказаны
Мы также отслеживаем количество предсказанных меток в наборе {определяется как количество меток, для которых мы получаем оценку F1 > 0}.
Классификация с несколькими метками — это тип задачи обучения с учителем, в которой один экземпляр или пример может быть связан с несколькими метками или классификациями, в отличие от традиционной классификации с одной меткой, где каждый экземпляр связан только с одной меткой класса.
Для решения задач классификации с несколькими метками существует две основные категории методов:
- Методы преобразования проблемы
- Методы адаптации алгоритма
Методы преобразования проблемы позволяют нам преобразовать задачи классификации с несколькими метками в задачи классификации с несколькими метками. Например, базовый подход Binary Relevance (BR) рассматривает каждую метку как отдельную проблему бинарной классификации. В этом случае проблема с несколькими метками превращается в несколько задач с одной меткой.
Методы адаптации алгоритмов модифицируют сами алгоритмы для естественной обработки данных с несколькими метками, не превращая задачу в несколько задач классификации с одной меткой. Примером такого подхода является модель БЕРТ, которая представляет собой предварительно обученную языковую модель на основе преобразователя, которую можно точно настроить для различных задач НЛП, включая классификацию текста с несколькими метками. BERT предназначен для прямой обработки данных с несколькими метками без необходимости преобразования проблемы.
В контексте использования BERT для классификации текста с несколькими метками стандартным подходом является использование потерь двоичной кросс-энтропии (BCE) в качестве функции потерь. Потери BCE — это обычно используемая функция потерь для задач бинарной классификации, которую можно легко расширить для решения задач классификации с несколькими метками путем независимого вычисления потерь для каждой метки, а затем суммирования потерь. В этом случае функция потерь BCE измеряет ошибку между предсказанными вероятностями и истинными метками, где предсказанные вероятности получаются из последнего сигмоидного слоя активации в модели BERT.
Теперь давайте подробнее рассмотрим рисунок 2 ниже.
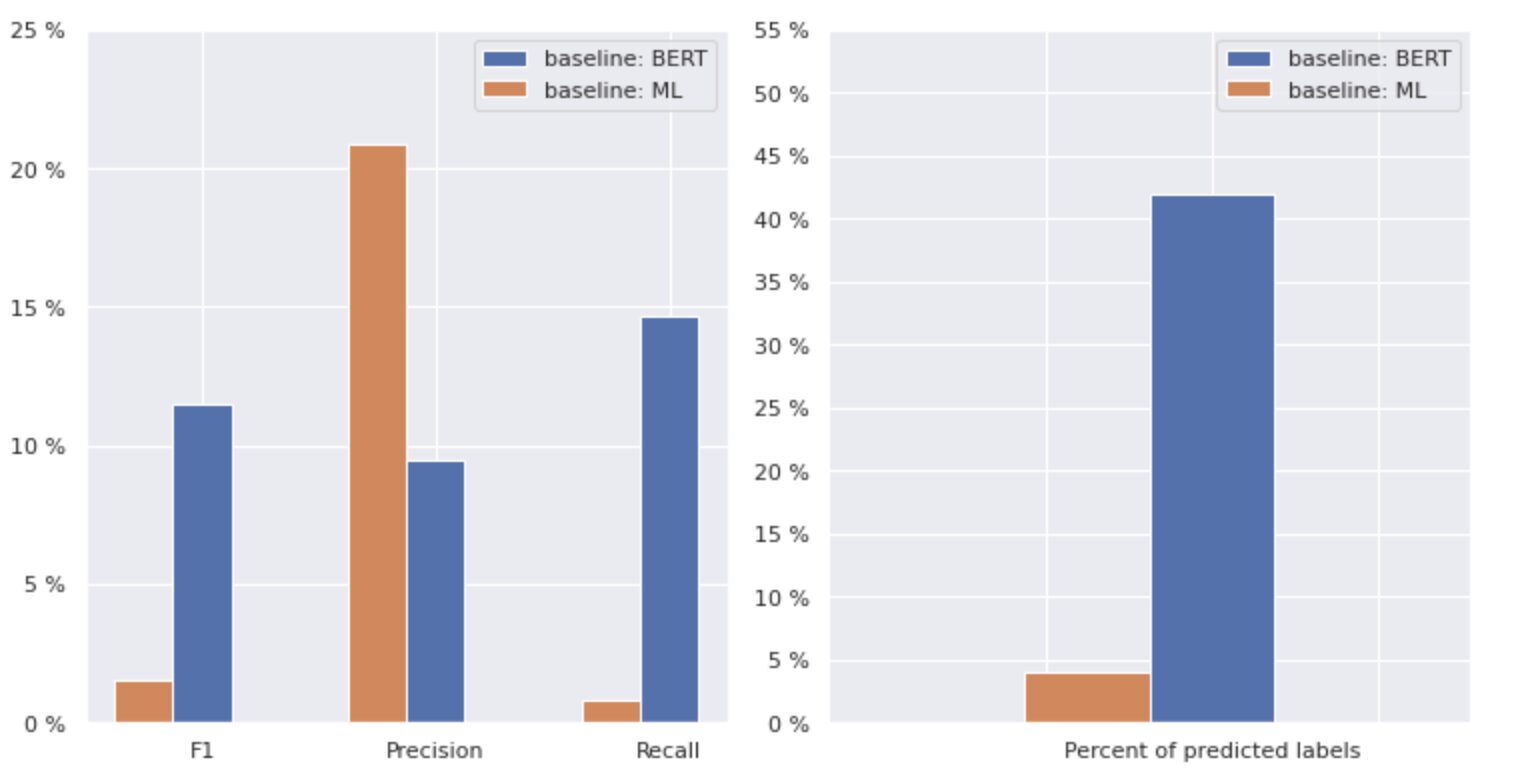
Рисунок 2. Метрики для базовых моделей
На графике слева показано сравнение показателей для «базового уровня: BERT» и «базового уровня: ML». Таким образом, видно, что для «базового уровня: BERT» показатели F1 и Recall примерно в 1.5 раза выше, а точность для «базового уровня: ML» в 2 раза выше, чем у модели 1. Анализируя общий процент предсказанных классов, показанных справа, мы видим, что «базовый уровень: BERT» предсказал классы более чем в 10 раз больше, чем «базовый уровень: ML».
Поскольку максимальный результат для «базового уровня: BERT» составляет менее 50% всех классов, результаты весьма обескураживающие. Давайте разберемся, как улучшить эти результаты.
На основе выдающейся статьи «Методы балансировки для классификации текста с несколькими метками с распределением классов с длинным хвостом», мы узнали, что убыток, сбалансированный по распределению, может быть для нас наиболее подходящим подходом.
Потери, сбалансированные по распределению
Потеря, сбалансированная распределением, — это метод, используемый в задачах классификации текста с несколькими метками для устранения дисбаланса в распределении классов. В этих задачах некоторые классы имеют гораздо более высокую частоту появления по сравнению с другими, что приводит к смещению модели в сторону этих более частых классов.
Чтобы решить эту проблему, потери, сбалансированные по распределению, направлены на то, чтобы сбалансировать вклад каждой выборки в функцию потерь. Это достигается за счет повторного взвешивания потерь каждой выборки на основе обратной частоты ее появления в наборе данных. При этом вклад менее частых классов увеличивается, а вклад более частых классов уменьшается, таким образом уравновешивая общее распределение классов.
Было показано, что этот метод эффективен для улучшения производительности моделей в задачах распределения классов с длинными хвостами. Снижая влияние частых занятий и увеличивая влияние нечастых занятий, модель способна лучше фиксировать закономерности в данных и давать более сбалансированные прогнозы.

Реализация класса Resample
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np class ResampleLoss(nn.Module): def __init__( self, use_sigmoid=True, partial=False, loss_weight=1.0, reduction="mean", reweight_func=None, weight_norm=None, focal=dict(focal=True, alpha=0.5, gamma=2), map_param=dict(alpha=10.0, beta=0.2, gamma=0.1), CB_loss=dict(CB_beta=0.9, CB_mode="average_w"), logit_reg=dict(neg_scale=5.0, init_bias=0.1), class_freq=None, train_num=None, ): super(ResampleLoss, self).__init__() assert (use_sigmoid is True) or (partial is False) self.use_sigmoid = use_sigmoid self.partial = partial self.loss_weight = loss_weight self.reduction = reduction if self.use_sigmoid: if self.partial: self.cls_criterion = partial_cross_entropy else: self.cls_criterion = binary_cross_entropy else: self.cls_criterion = cross_entropy # reweighting function self.reweight_func = reweight_func # normalization (optional) self.weight_norm = weight_norm # focal loss params self.focal = focal["focal"] self.gamma = focal["gamma"] self.alpha = focal["alpha"] # mapping function params self.map_alpha = map_param["alpha"] self.map_beta = map_param["beta"] self.map_gamma = map_param["gamma"] # CB loss params (optional) self.CB_beta = CB_loss["CB_beta"] self.CB_mode = CB_loss["CB_mode"] self.class_freq = ( torch.from_numpy(np.asarray(class_freq)).float().cuda() ) self.num_classes = self.class_freq.shape[0] self.train_num = train_num # only used to be divided by class_freq # regularization params self.logit_reg = logit_reg self.neg_scale = ( logit_reg["neg_scale"] if "neg_scale" in logit_reg else 1.0 ) init_bias = ( logit_reg["init_bias"] if "init_bias" in logit_reg else 0.0 ) self.init_bias = ( -torch.log(self.train_num / self.class_freq - 1) * init_bias ) self.freq_inv = ( torch.ones(self.class_freq.shape).cuda() / self.class_freq ) self.propotion_inv = self.train_num / self.class_freq def forward( self, cls_score, label, weight=None, avg_factor=None, reduction_override=None, **kwargs ): assert reduction_override in (None, "none", "mean", "sum") reduction = ( reduction_override if reduction_override else self.reduction ) weight = self.reweight_functions(label) cls_score, weight = self.logit_reg_functions( label.float(), cls_score, weight ) if self.focal: logpt = self.cls_criterion( cls_score.clone(), label, weight=None, reduction="none", avg_factor=avg_factor, ) # pt is sigmoid(logit) for pos or sigmoid(-logit) for neg pt = torch.exp(-logpt) wtloss = self.cls_criterion( cls_score, label.float(), weight=weight, reduction="none" ) alpha_t = torch.where(label == 1, self.alpha, 1 - self.alpha) loss = alpha_t * ((1 - pt) ** self.gamma) * wtloss loss = reduce_loss(loss, reduction) else: loss = self.cls_criterion( cls_score, label.float(), weight, reduction=reduction ) loss = self.loss_weight * loss return loss def reweight_functions(self, label): if self.reweight_func is None: return None elif self.reweight_func in ["inv", "sqrt_inv"]: weight = self.RW_weight(label.float()) elif self.reweight_func in "rebalance": weight = self.rebalance_weight(label.float()) elif self.reweight_func in "CB": weight = self.CB_weight(label.float()) else: return None if self.weight_norm is not None: if "by_instance" in self.weight_norm: max_by_instance, _ = torch.max(weight, dim=-1, keepdim=True) weight = weight / max_by_instance elif "by_batch" in self.weight_norm: weight = weight / torch.max(weight) return weight def logit_reg_functions(self, labels, logits, weight=None): if not self.logit_reg: return logits, weight if "init_bias" in self.logit_reg: logits += self.init_bias if "neg_scale" in self.logit_reg: logits = logits * (1 - labels) * self.neg_scale + logits * labels if weight is not None: weight = ( weight / self.neg_scale * (1 - labels) + weight * labels ) return logits, weight def rebalance_weight(self, gt_labels): repeat_rate = torch.sum( gt_labels.float() * self.freq_inv, dim=1, keepdim=True ) pos_weight = ( self.freq_inv.clone().detach().unsqueeze(0) / repeat_rate ) # pos and neg are equally treated weight = ( torch.sigmoid(self.map_beta * (pos_weight - self.map_gamma)) + self.map_alpha ) return weight def CB_weight(self, gt_labels): if "by_class" in self.CB_mode: weight = ( torch.tensor((1 - self.CB_beta)).cuda() / (1 - torch.pow(self.CB_beta, self.class_freq)).cuda() ) elif "average_n" in self.CB_mode: avg_n = torch.sum( gt_labels * self.class_freq, dim=1, keepdim=True ) / torch.sum(gt_labels, dim=1, keepdim=True) weight = ( torch.tensor((1 - self.CB_beta)).cuda() / (1 - torch.pow(self.CB_beta, avg_n)).cuda() ) elif "average_w" in self.CB_mode: weight_ = ( torch.tensor((1 - self.CB_beta)).cuda() / (1 - torch.pow(self.CB_beta, self.class_freq)).cuda() ) weight = torch.sum( gt_labels * weight_, dim=1, keepdim=True ) / torch.sum(gt_labels, dim=1, keepdim=True) elif "min_n" in self.CB_mode: min_n, _ = torch.min( gt_labels * self.class_freq + (1 - gt_labels) * 100000, dim=1, keepdim=True, ) weight = ( torch.tensor((1 - self.CB_beta)).cuda() / (1 - torch.pow(self.CB_beta, min_n)).cuda() ) else: raise NameError return weight def RW_weight(self, gt_labels, by_class=True): if "sqrt" in self.reweight_func: weight = torch.sqrt(self.propotion_inv) else: weight = self.propotion_inv if not by_class: sum_ = torch.sum(weight * gt_labels, dim=1, keepdim=True) weight = sum_ / torch.sum(gt_labels, dim=1, keepdim=True) return weight def reduce_loss(loss, reduction): """Reduce loss as specified. Args: loss (Tensor): Elementwise loss tensor. reduction (str): Options are "none", "mean" and "sum". Return: Tensor: Reduced loss tensor. """ reduction_enum = F._Reduction.get_enum(reduction) # none: 0, elementwise_mean:1, sum: 2 if reduction_enum == 0: return loss elif reduction_enum == 1: return loss.mean() elif reduction_enum == 2: return loss.sum() def weight_reduce_loss(loss, weight=None, reduction="mean", avg_factor=None): """Apply element-wise weight and reduce loss. Args: loss (Tensor): Element-wise loss. weight (Tensor): Element-wise weights. reduction (str): Same as built-in losses of PyTorch. avg_factor (float): Avarage factor when computing the mean of losses. Returns: Tensor: Processed loss values. """ # if weight is specified, apply element-wise weight if weight is not None: loss = loss * weight # if avg_factor is not specified, just reduce the loss if avg_factor is None: loss = reduce_loss(loss, reduction) else: # if reduction is mean, then average the loss by avg_factor if reduction == "mean": loss = loss.sum() / avg_factor # if reduction is 'none', then do nothing, otherwise raise an error elif reduction != "none": raise ValueError( 'avg_factor can not be used with reduction="sum"' ) return loss def binary_cross_entropy( pred, label, weight=None, reduction="mean", avg_factor=None
): # weighted element-wise losses if weight is not None: weight = weight.float() loss = F.binary_cross_entropy_with_logits( pred, label.float(), weight, reduction="none" ) loss = weight_reduce_loss( loss, reduction=reduction, avg_factor=avg_factor ) return loss
ДБЛосс
loss_func = ResampleLoss( reweight_func="rebalance", loss_weight=1.0, focal=dict(focal=True, alpha=0.5, gamma=2), logit_reg=dict(init_bias=0.05, neg_scale=2.0), map_param=dict(alpha=0.1, beta=10.0, gamma=0.405), class_freq=class_freq, train_num=train_num,
) """
class_freq - list of frequencies for each class,
train_num - size of train dataset """
Внимательно изучив набор данных, мы пришли к выводу, что параметр
= 0.405.
Настройка порога
Еще одним шагом в улучшении нашей модели стал процесс настройки порога, как на этапе обучения, так и на этапах проверки и тестирования. Мы рассчитали зависимости таких показателей, как оценка f1, точность и полнота, от порогового уровня и выбрали порог на основе наивысшего показателя. Ниже вы можете увидеть функциональную реализацию этого процесса.
Оптимизация оценки F1 путем настройки порога:
def optimise_f1_score(true_labels: np.ndarray, pred_labels: np.ndarray): best_med_th = 0.5 true_bools = [tl == 1 for tl in true_labels] micro_thresholds = (np.array(range(-45, 15)) / 100) + best_med_th f1_results, pre_results, recall_results = [], [], [] for th in micro_thresholds: pred_bools = [pl > th for pl in pred_labels] test_f1 = f1_score(true_bools, pred_bools, average="micro", zero_division=0) test_precision = precision_score( true_bools, pred_bools, average="micro", zero_division=0 ) test_recall = recall_score( true_bools, pred_bools, average="micro", zero_division=0 ) f1_results.append(test_f1) prec_results.append(test_precision) recall_results.append(test_recall) best_f1_idx = np.argmax(f1_results) return micro_thresholds[best_f1_idx]Оценка и сравнение с исходным уровнем
Эти подходы позволили нам обучить новую модель и получить следующий результат, который сравнивается с базовым уровнем: BERT на рисунке 3 ниже.

Рис. 3. Сравнение показателей базового уровня и нового подхода.
Сравнивая релевантные для классификации метрики, мы видим существенный рост показателей производительности почти в 5-6 раз:
Показатель F1 увеличился с 12% до 55%, в то время как точность увеличилась с 9% до 59%, а отзыв увеличился с 15% до 51%.
С изменениями, показанными на правом графике на рис. 3, теперь мы можем прогнозировать 80% классов.
Срезы классов
Мы разделили наши метки на четыре группы: HEAD, MEDIUM, TAIL и ZERO. Каждая группа содержит метки с одинаковым количеством вспомогательных данных наблюдений.
Как видно на рисунке 4, распределение групп различно. Розовое поле (ГОЛОВА) имеет отрицательное асимметричное распределение, среднее поле (СРЕДНИЙ) имеет положительное асимметричное распределение, а зеленое поле (ХВОСТ) имеет нормальное распределение.
Все группы также имеют выбросы, которые являются точками за пределами усов на блочной диаграмме. Группа HEAD оказывает большое влияние на класс MAJOR.
Кроме того, мы выделили отдельную группу под названием «ZERO», которая содержит метки, которые модель не смогла изучить и не может распознать из-за минимального количества вхождений в наборе данных (менее 3% всех наблюдений).
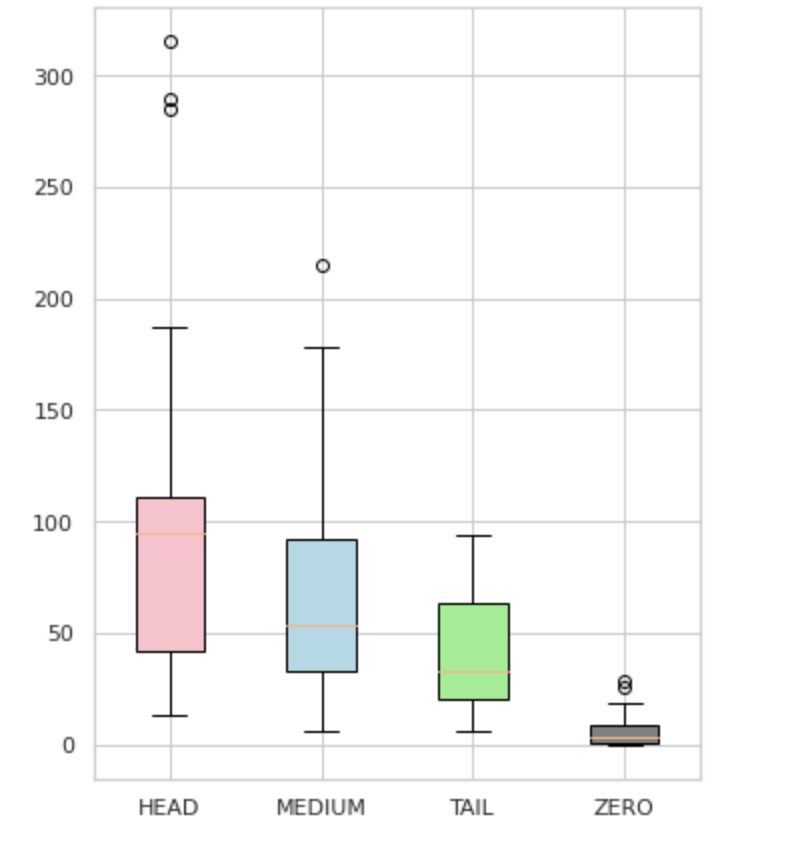
Рисунок 4. Количество меток в сравнении с группами
В таблице 2 представлена информация о метриках по каждой группе меток для тестового подмножества данных.
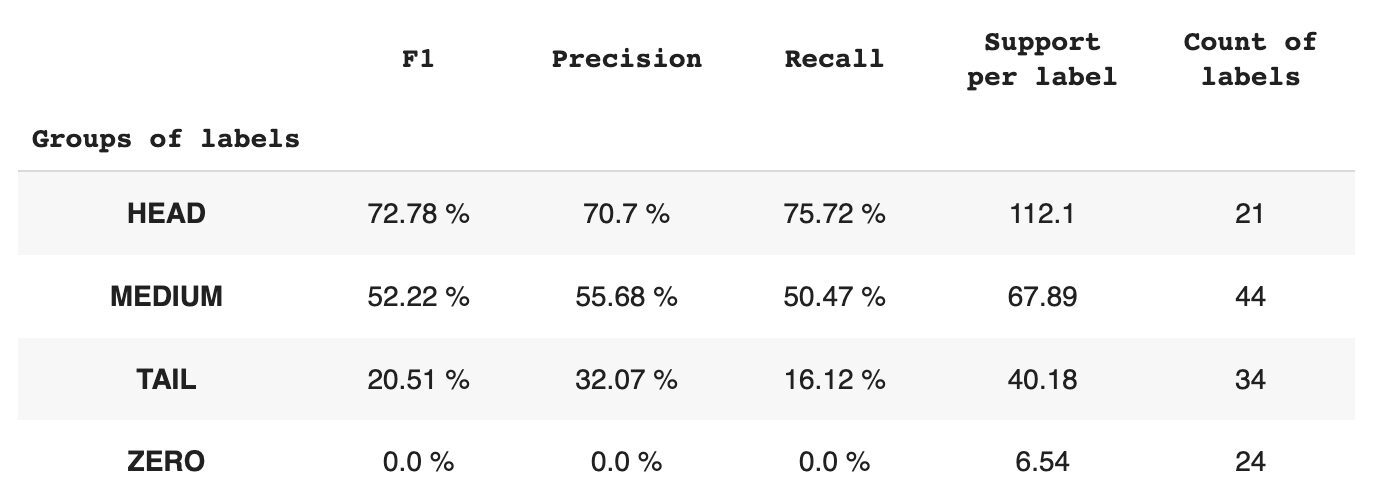
Таблица 2. Показатели по группам.
- Группа HEAD содержит 21 ярлык, в среднем по 112 вспомогательных наблюдений на каждый ярлык. На эту группу влияют выбросы, и из-за ее высокой представленности в наборе данных ее показатели высоки: F1 — 73%, точность — 71%, полнота — 75%.
- Группа MEDIUM состоит из 44 меток со средней поддержкой 67 наблюдений, что примерно в два раза ниже группы HEAD. Ожидается снижение метрик этой группы на 50%: F1 — 52%, Precision — 56%, Recall — 51%.
- Группа TAIL имеет наибольшее количество классов, но все они плохо представлены в наборе данных, в среднем 40 вспомогательных наблюдений на метку. В результате показатели значительно падают: F1 — 21%, Precision — 32%, Recall — 16%.
- В группу ZERO входят классы, которые модель вообще не может распознать, возможно, из-за их низкой встречаемости в наборе данных. Каждая из 24 меток в этой группе имеет в среднем 7 поддерживающих наблюдений.
Рисунок 5 визуализирует информацию, представленную в таблице 2, обеспечивая визуальное представление метрик для каждой группы меток.
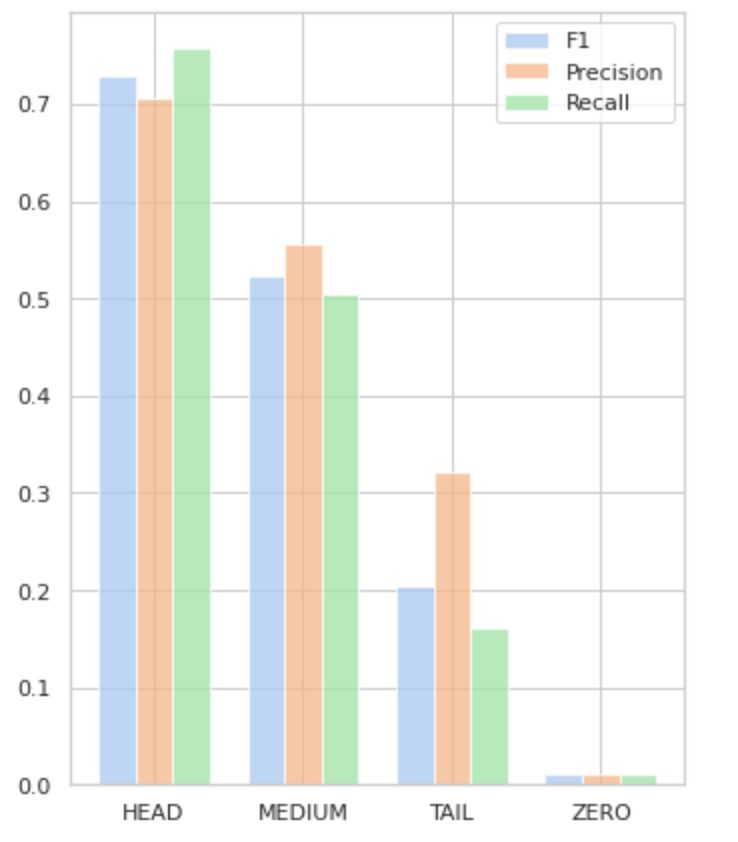
Рисунок 5. Метрики и группы меток. Все значения ZERO = 0.
В этой подробной статье мы продемонстрировали, что, казалось бы, простая задача классификации текста с несколькими метками может оказаться сложной при применении традиционных методов. Мы предложили использовать функции потерь распределения-балансировки для решения проблемы дисбаланса классов.
Мы сравнили эффективность предложенного нами подхода с классическим методом и оценили его с использованием реальных бизнес-показателей. Результаты показывают, что использование функций потерь для устранения дисбаланса классов и совпадения меток предлагает жизнеспособное решение для классификации текста с несколькими метками.
Предлагаемый вариант использования подчеркивает важность рассмотрения различных подходов и методов при работе с текстовой классификацией с несколькими метками, а также потенциальные преимущества функций потерь распределения-балансировки при устранении дисбаланса классов.
Если вы столкнулись с похожей проблемой и хотите оптимизировать операции по обработке документов внутри вашей организации, пожалуйста, свяжитесь со мной или командой Provectus. Мы будем рады помочь вам найти более эффективные методы автоматизации ваших процессов.
Алексей Бабич работает инженером по машинному обучению в Provectus. Имея опыт работы в области физики, он обладает отличными аналитическими и математическими способностями и приобрел ценный опыт благодаря научным исследованиям и презентациям на международных конференциях, включая SPIE Photonics West. Алексей специализируется на создании комплексных масштабных решений AI/ML для здравоохранения и финтеха. Он участвует в каждом этапе жизненного цикла разработки ML, от выявления бизнес-проблем до развертывания и запуска производственных моделей ML.
Ринат Ахметов является архитектором решений машинного обучения в Provectus. Обладая солидным практическим опытом в области машинного обучения (особенно в области компьютерного зрения), Ринат — ботаник, энтузиаст данных, инженер-программист и трудоголик, второй по величине страстью которого является программирование. В Provectus Ринат отвечает за этапы обнаружения и проверки концепции, а также руководит выполнением сложных проектов ИИ.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- Платоблокчейн. Интеллект метавселенной Web3. Расширение знаний. Доступ здесь.
- Источник: https://www.kdnuggets.com/2023/03/multilabel-nlp-analysis-class-imbalance-loss-function-approaches.html?utm_source=rss&utm_medium=rss&utm_campaign=multi-label-nlp-an-analysis-of-class-imbalance-and-loss-function-approaches
- :является
- 1
- 10
- 100
- 15%
- 67
- 7
- 9
- a
- в состоянии
- О нас
- Достигать
- достигнутый
- действия
- Активация
- адаптация
- адрес
- адресация
- AI
- AI / ML
- Цель
- алгоритм
- алгоритмы
- Все
- позволяет
- Альфа
- среди
- количество
- анализ
- Аналитические фармацевтические услуги
- анализ
- и
- появившийся
- прикладной
- Применить
- подхода
- подходы
- примерно
- МЫ
- гайд
- AS
- аспекты
- назначенный
- помощь
- связанный
- At
- Автоматизация
- в среднем
- фон
- Баланс
- основанный
- Базовая линия
- BE
- , так как:
- ниже
- Преимущества
- ЛУЧШЕЕ
- beta
- Лучшая
- между
- смещение
- Крупнейшая
- Дно
- Коробка
- встроенный
- бизнес
- by
- рассчитанный
- CAN
- не могу
- захватить
- случаев
- категории
- CB
- определенный
- проблемы
- сложные
- изменения
- заряд
- класс
- классов
- классический
- классификация
- клиент
- тесно
- ближе
- обычно
- сравненный
- сравнив
- сравнение
- комплекс
- комплексный
- компьютер
- Компьютерное зрение
- вычисление
- сама концепция
- Обеспокоенность
- в заключении исследования, финансируемого Центрами по контролю и профилактике заболеваний (CDC) и написанного бывшим начальником полиции Вермонта
- Конференция
- принимая во внимание
- обращайтесь
- содержит
- содержание
- контекст
- вклад
- чехлы
- Создающий
- клиент
- цикл
- данным
- занимавшийся
- снижение
- определенный
- демонстрировать
- убивают
- развертывание
- предназначенный
- подробный
- Развитие
- Различия
- различный
- непосредственно
- открытие
- отчетливый
- распределение
- распределения
- Разное
- Разделенный
- документ
- Документация
- дело
- домен
- Падение
- каждый
- легко
- Эффективный
- эффективный
- усилия
- включить
- впритык
- инженер
- энтузиаст
- одинаково
- ошибка
- особенно
- Эфир (ETH)
- оценивается
- Каждая
- , поскольку большинство сенаторов
- пример
- отлично
- выполнение
- ожидаемый
- опыт
- исследование
- Больше
- экспресс
- f1
- сталкиваются
- всего лишь пяти граммов героина
- Обратная связь
- фигура
- окончательный
- обнаружение
- FinTech
- First
- Поплавок
- после
- Что касается
- найденный
- доля
- частота
- частое
- от
- функция
- функциональная
- Функции
- далее
- Gain
- данный
- взгляд
- график
- Зелёная
- группы
- Группы
- обрабатывать
- счастливый
- Есть
- здравоохранение
- помощь
- помогает
- High
- высший
- наивысший
- основной момент
- Как
- How To
- Однако
- HTML
- HTTP
- HTTPS
- идентифицированный
- идентифицирующий
- дисбаланс
- Влияние
- влияние
- реализация
- Импортировать
- значение
- важную
- улучшать
- улучшение
- in
- включает в себя
- В том числе
- неверно
- Увеличение
- расширились
- повышение
- самостоятельно
- промышленности
- информация
- свойственный
- вход
- пример
- вместо
- Мультиязычность
- инвестиций
- вовлеченный
- вопрос
- IT
- ЕГО
- JPG
- только один
- КДнаггетс
- этикетка
- маркировка
- Этикетки
- язык
- крупномасштабный
- крупнейших
- слой
- Лиды
- УЧИТЬСЯ
- узнали
- изучение
- уровень
- ЖИЗНЬЮ
- Список
- посмотреть
- от
- потери
- Низкий
- машина
- обучение с помощью машины
- сделанный
- Главная
- основной
- Большинство
- многих
- отображение
- математике
- максимальный
- меры
- средний
- метод
- методы
- метрический
- Метрика
- минимальный
- ML
- MLB
- модель
- Модели
- изменять
- модуль
- БОЛЕЕ
- более эффективным
- самых
- с разными
- Названный
- Необходимость
- отрицательный
- отрицательно
- Новые
- НЛП
- "обычные"
- Примечательно
- номер
- номера
- NumPy
- получать
- полученный
- of
- предлагают
- on
- ONE
- Возможность
- против
- Опции
- организация
- Другое
- в противном случае
- внешнюю
- выдающийся
- общий
- параметр
- страсть
- паттеранами
- процент
- производительность
- Физика
- кусок
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- пожалуйста
- пунктов
- PoS
- положительный
- потенциал
- потенциально
- практическое
- Точность
- предсказывать
- предсказанный
- Predictions
- предсказывает
- Presentations
- представлены
- Проблема
- проблемам
- процесс
- Процессы
- обработка
- производит
- Продукт
- Производство
- Программирование
- проектов
- доказательство
- доказательство концепции
- предложило
- обеспечивать
- при условии
- приводит
- обеспечение
- pytorch
- повышение
- ассортимент
- скорее
- реальный мир
- восстановить равновесие
- резюме
- признавать
- уменьшить
- Цена снижена
- снижение
- понимается
- отношения
- актуальность
- соответствующие
- представление
- представленный
- запросить
- исследованиям
- результат
- в результате
- Итоги
- возвращают
- Возвращает
- обзоре
- ROSE
- Бег
- s
- то же
- Сценарии
- Научные Исследования
- Во-вторых
- поиск
- выбранный
- SELF
- настроение
- отдельный
- обслуживание
- набор
- Наборы
- Форма
- показанный
- Шоу
- значение
- значительный
- существенно
- аналогичный
- просто
- одновременно
- одинарной
- Размер
- навыки
- So
- Software
- Инженер-программист
- твердый
- Решение
- Решения
- РЕШАТЬ
- некоторые
- специализируется
- указанный
- Этап
- этапы
- стандарт
- статистика
- Шаг
- простой
- такие
- подходящее
- контролируемое обучение
- поддержка
- поддержки
- ТАБЛИЦЫ
- TAG
- взять
- целевое
- Сложность задачи
- задачи
- команда
- снижения вреда
- тестXNUMX
- Тестирование
- Классификация текста
- который
- Ассоциация
- информация
- их
- Их
- сами
- Эти
- порог
- Через
- время
- раз
- в
- топ
- факел
- Всего
- трогать
- к
- трек
- традиционный
- Train
- Обучение
- Transform
- трансформация
- преобразован
- превращение
- относится к
- правда
- типично
- неопределенности
- понимание
- созданного
- us
- использование
- прецедент
- Использующий
- Проверка
- ценный
- Наши ценности
- различный
- жизнеспособный
- видение
- vs
- вес
- запад
- который
- в то время как
- Википедия.
- будете
- в
- без
- работавший
- ВАШЕ
- зефирнет
- нуль