Введение
Добро пожаловать в наш всеобъемлющий анализ данных блог, который углубляется в мир Netflix. Как одна из ведущих потоковых платформ в мире, Netflix произвел революцию в том, как мы потребляем развлечения. Обладая обширной библиотекой фильмов и телешоу, он предлагает множество вариантов для зрителей по всему миру.
Глобальный охват Netflix
Netflix пережил значительный рост и расширил свое присутствие, чтобы стать доминирующей силой в индустрии потокового вещания. Вот некоторые заслуживающие внимания статистические данные, демонстрирующие его глобальное влияние:
- База пользователей: К началу второго квартала 2022 года Netflix накопила около 222 миллиона международных подписчиков, охватывающий более 190 стран (за исключением Китая, Крыма, Северной Кореи, России и Сирии). Эти впечатляющие цифры подчеркивают широкое признание и популярность платформы среди зрителей по всему миру.
- Международная экспансия: Благодаря своей доступности более чем в 190 странах Netflix успешно закрепил свое глобальное присутствие. Компания приложила значительные усилия для локализации своего контента, предлагая субтитры и дубляж на разных языках, обеспечивая доступность для разнообразной аудитории.
В этом блоге мы отправляемся в захватывающее путешествие, чтобы исследовать интригующие закономерности, тенденции и идеи, скрытые в ландшафте контента Netflix. Использование возможностей Питон и ее анализ данных библиотеки, мы погружаемся в обширную коллекцию предложений Netflix, чтобы раскрыть ценную информацию, которая проливает свет на добавление контента, распределение продолжительности, соотношение жанров и даже наиболее часто используемые слова в заголовках и описаниях.
С помощью подробных фрагментов кода и визуализации, мы раскрываем слои экосистемы контента Netflix, чтобы дать свежий взгляд на то, как развивалась платформа. Анализируя модели выпуска, сезонные тенденции и предпочтения аудитории, мы стремимся лучше понять динамику контента в обширной вселенной Netflix.
Эта статья была опубликована в рамках Блогатон по Data Science.
Содержание
Подготовка данных
Данные, используемые в этом тематическом исследовании, получены из Kaggle, популярной платформы для энтузиастов науки о данных и машинного обучения. Набор данных под названием «Фильмы и телешоу Netflix», общедоступно на Kaggle и предоставляет ценную информацию о фильмах и телешоу на потоковой платформе Netflix.
Набор данных имеет табличный формат, содержащий различные столбцы, описывающие различные аспекты каждого фильма или телепередачи. Вот таблица со сводными данными по столбцам и их описаниям:
| Имя столбца | Описание |
|---|---|
| show_id | Уникальный идентификатор для каждого фильма/телешоу |
| напишите | Идентификатор — фильм или телешоу |
| название | Название фильма/телепередачи |
| директор | Режиссер фильма |
| бросить | Актеры, задействованные в фильме/шоу |
| страна | Страна, в которой был снят Фильм/Шоу |
| Дата добавления | Дата добавления на Netflix |
| выпуск_год | Фактический год выхода фильма/шоу |
| рейтинг | ТВ-рейтинг фильма/шоу |
| продолжительность | Общая продолжительность – в минутах или количестве сезонов |
В этом разделе мы выполним задачи по подготовке данных в наборе данных Netflix, чтобы обеспечить его чистоту и пригодность для анализа. Мы будем обрабатывать отсутствующие значения и дубликаты и выполнять преобразования типов данных по мере необходимости. Давайте погрузимся в код и рассмотрим каждый шаг.
Импорт библиотек
Для начала импортируем необходимые библиотеки для анализа и визуализации данных. Эти библиотеки включают панд, numpy и matplotlib. pyplot и Seaborn. Они предоставляют необходимые функции и инструменты для эффективной обработки и визуализации данных.
# Importing necessary libraries for data analysis and visualization
import pandas as pd # pandas for data manipulation and analysis
import numpy as np # numpy for numerical operations
import matplotlib.pyplot as plt # matplotlib for data visualization
import seaborn as sns # seaborn for enhanced data visualizationЗагрузка набора данных
Затем мы загружаем набор данных Netflix с помощью функции pd.read_csv(). Набор данных хранится в файле netflix.csv. Давайте посмотрим на первые пять записей набора данных, чтобы понять его структуру.
# Loading the dataset from a CSV file
df = pd.read_csv('netflix.csv') # Displaying the first few rows of the dataset
df.head()Описательная статистика
Крайне важно понять общие характеристики набора данных через описательная статистика. Мы можем получить представление о числовых атрибутах, таких как количество, среднее значение, стандартное отклонение, минимум, максимум и квартили.
# Computing descriptive statistics for the dataset
df.describe()Краткое резюме
Чтобы получить краткую сводку набора данных, мы используем функцию df.info(). Он предоставляет информацию о количестве ненулевых значений и типах данных каждого столбца. Эта сводка помогает определить отсутствующие значения и потенциальные проблемы с типами данных.
# Obtaining information about the dataset
df.info()Обработка пропущенных значений
Отсутствующие значения могут помешать точному анализу. Этот набор данных исследует отсутствующие значения в каждом столбце с помощью df. isnull().сумма(). Мы стремимся определить столбцы с отсутствующими значениями и определить процент отсутствующих данных в каждом столбце.
# Checking for missing values in the dataset
df.isnull().sum()Для обработки пропущенных значений мы используем разные стратегии для разных столбцов. Пройдемся по каждому шагу:
Дубликаты
Дубликаты могут исказить результаты анализа, поэтому важно их устранить. Мы идентифицируем и удаляем повторяющиеся записи, используя df.duplicated().sum().
# Checking for duplicate rows in the dataset
df.duplicated().sum()Обработка пропущенных значений в определенных столбцах
Для столбцов «режиссер» и «актерский состав» мы заменяем отсутствующие значения на «Нет данных», чтобы сохранить целостность данных и избежать какой-либо предвзятости в анализе.
# Replacing missing values in the 'director' column with 'No Data'
df['director'].replace(np.nan, 'No Data', inplace=True) # Replacing missing values in the 'cast' column with 'No Data'
df['cast'].replace(np.nan, 'No Data', inplace=True)В столбце «страна» мы заполняем пропущенные значения режимом (наиболее часто встречающееся значение), чтобы обеспечить согласованность и минимизировать потерю данных.
# Filling missing values in the 'country' column with the mode value
df['country'] = df['country'].fillna(df['country'].mode()[0])Для столбца «рейтинг» мы заполняем недостающие значения в зависимости от «типа» шоу. Назначаем режим «рейтинга» для фильмов и сериалов отдельно.
# Finding the mode rating for movies and TV shows
movie_rating = df.loc[df['type'] == 'Movie', 'rating'].mode()[0]
tv_rating = df.loc[df['type'] == 'TV Show', 'rating'].mode()[0] # Filling missing rating values based on the type of content
df['rating'] = df.apply(lambda x: movie_rating if x['type'] == 'Movie' and pd.isna(x['rating']) else tv_rating if x['type'] == 'TV Show' and pd.isna(x['rating']) else x['rating'], axis=1)Для столбца «длительность» мы заполняем недостающие значения в зависимости от «типа» шоу. Назначаем режим «длительности» для фильмов и телепередач отдельно.
# Finding the mode duration for movies and TV shows
movie_duration_mode = df.loc[df['type'] == 'Movie', 'duration'].mode()[0]
tv_duration_mode = df.loc[df['type'] == 'TV Show', 'duration'].mode()[0] # Filling missing duration values based on the type of content
df['duration'] = df.apply(lambda x: movie_duration_mode if x['type'] == 'Movie' and pd.isna(x['duration']) else tv_duration_mode if x['type'] == 'TV Show' and pd.isna(x['duration']) else x['duration'], axis=1)Удаление оставшихся пропущенных значений
После обработки отсутствующих значений в определенных столбцах мы удаляем все оставшиеся строки с отсутствующими значениями, чтобы обеспечить чистый набор данных для анализа.
# Dropping rows with missing values
df.dropna(inplace=True)Обработка даты
Мы преобразуем столбец date_added в формат даты и времени, используя pd.to_datetime(), чтобы обеспечить дальнейший анализ на основе атрибутов, связанных с датой.
# Converting the 'date_added' column to datetime format
df["date_added"] = pd.to_datetime(df['date_added'])Дополнительные преобразования данных
Мы извлекаем дополнительные атрибуты из столбца date_added, чтобы расширить наши возможности анализа. Мы удаляем значения месяца и года для анализа тенденций на основе этих временных аспектов.
# Extracting month, month name, and year from the 'date_added' column
df['month_added'] = df['date_added'].dt.month
df['month_name_added'] = df['date_added'].dt.month_name()
df['year_added'] = df['date_added'].dt.yearПреобразование данных: актеры, страна, в списке и режиссер
Чтобы более эффективно анализировать категориальные атрибуты, мы преобразуем их в отдельные кадры данных, что позволяет более неторопливо исследовать и анализировать.
Для столбцов «актерский состав», «страна», «listed_in» и «режиссер» мы разделили значения на основе разделителя-запятой и создали отдельные строки для каждого значения. Это преобразование позволяет нам анализировать данные на более детальном уровне.
# Splitting and expanding the 'cast' column
df_cast = df['cast'].str.split(',', expand=True).stack()
df_cast = df_cast.reset_index(level=1, drop=True).to_frame('cast')
df_cast['show_id'] = df['show_id'] # Splitting and expanding the 'country' column
df_country = df['country'].str.split(',', expand=True).stack()
df_country = df_country.reset_index(level=1, drop=True).to_frame('country')
df_country['show_id'] = df['show_id'] # Splitting and expanding the 'listed_in' column
df_listed_in = df['listed_in'].str.split(',', expand=True).stack()
df_listed_in = df_listed_in.reset_index(level=1, drop=True).to_frame('listed_in')
df_listed_in['show_id'] = df['show_id'] # Splitting and expanding the 'director' column
df_director = df['director'].str.split(',', expand=True).stack()
df_director = df_director.reset_index(level=1, drop=True).to_frame('director')
df_director['show_id'] = df['show_id']После выполнения этих шагов подготовки данных у нас есть чистый и преобразованный набор данных, готовый для дальнейшего анализа. Эти первоначальные манипуляции с данными заложили основу для изучения набора данных Netflix и раскрытия информации о стратегиях потоковой платформы, основанных на данных.
Исследовательский анализ данных
Распределение типов контента
Чтобы определить распределение контента в библиотеке Netflix, мы можем рассчитать процентное распределение типов контента (фильмов и телешоу), используя следующий код:
# Calculate the percentage distribution of content types
x = df.groupby(['type'])['type'].count()
y = len(df)
r = ((x/y) * 100).round(2) # Create a DataFrame to store the percentage distribution
mf_ratio = pd.DataFrame(r)
mf_ratio.rename({'type': '%'}, axis=1, inplace=True) # Plot the 3D-effect pie chart
plt.figure(figsize=(12, 8))
colors = ['#b20710', '#221f1f']
explode = (0.1, 0)
plt.pie(mf_ratio['%'], labels=mf_ratio.index, autopct='%1.1f%%', colors=colors, explode=explode, shadow=True, startangle=90, textprops={'color': 'white'}) plt.legend(loc='upper right')
plt.title('Distribution of Content Types')
plt.show()
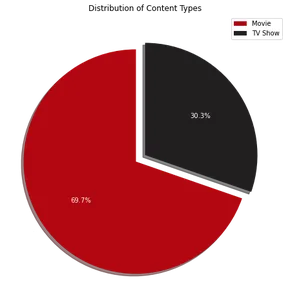
Визуализация круговой диаграммы показывает, что примерно 70% контента на Netflix составляют фильмы, а остальные 30% — телешоу. Далее, чтобы определить 10 самых популярных стран, где Netflix популярен, мы можем использовать следующий код:
Топ-10 стран, где популярен Netflix
Далее, чтобы определить 10 самых популярных стран, где Netflix популярен, мы можем использовать следующий код:
# Remove white spaces from 'country' column
df_country['country'] = df_country['country'].str.rstrip() # Find value counts
country_counts = df_country['country'].value_counts() # Select the top 10 countries
top_10_countries = country_counts.head(10) # Plot the top 10 countries
plt.figure(figsize=(16, 10))
colors = ['#b20710'] + ['#221f1f'] * (len(top_10_countries) - 1)
bar_plot = sns.barplot(x=top_10_countries.index, y=top_10_countries.values, palette=colors) plt.xlabel('Country')
plt.ylabel('Number of Titles')
plt.title('Top 10 Countries Where Netflix is Popular') # Add count values on top of each bar
for index, value in enumerate(top_10_countries.values): bar_plot.text(index, value, str(value), ha='center', va='bottom') plt.show()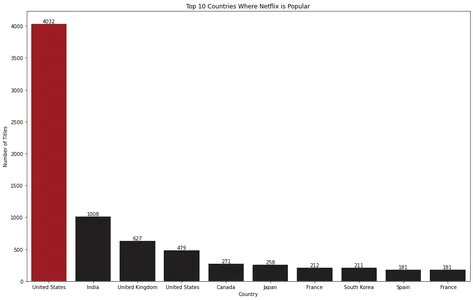
Визуализация гистограммы показывает, что Соединенные Штаты являются самой популярной страной, где Netflix популярен.
10 лучших актеров по количеству фильмов / телешоу
Чтобы определить 10 лучших актеров с наибольшим количеством появлений в фильмах и сериалах, вы можете использовать следующий код:
# Count the occurrences of each actor
cast_counts = df_cast['cast'].value_counts()[1:] # Select the top 10 actors
top_10_cast = cast_counts.head(10) plt.figure(figsize=(16, 8))
colors = ['#b20710'] + ['#221f1f'] * (len(top_10_cast) - 1)
bar_plot = sns.barplot(x=top_10_cast.index, y=top_10_cast.values, palette=colors) plt.xlabel('Actor')
plt.ylabel('Number of Appearances')
plt.title('Top 10 Actors by Movie/TV Show Count') # Add count values on top of each bar
for index, value in enumerate(top_10_cast.values): bar_plot.text(index, value, str(value), ha='center', va='bottom') plt.show()
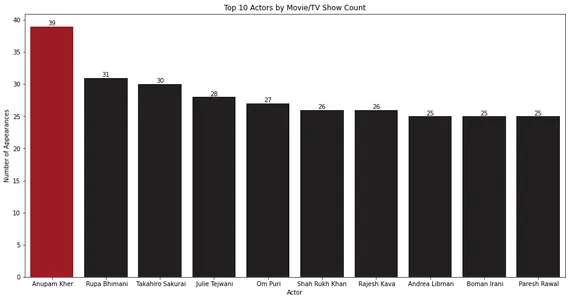
Гистограмма показывает, что Анупам Кхер чаще всего появляется в фильмах и телешоу.
10 лучших режиссеров по количеству фильмов/телешоу
Чтобы определить 10 лучших режиссеров, снявших наибольшее количество фильмов или телешоу, вы можете использовать следующий код:
# Count the occurrences of each actor
director_counts = df_director['director'].value_counts()[1:] # Select the top 10 actors
top_10_directors = director_counts.head(10) plt.figure(figsize=(16, 8))
colors = ['#b20710'] + ['#221f1f'] * (len(top_10_directors) - 1)
bar_plot = sns.barplot(x=top_10_directors.index, y=top_10_directors.values, palette=colors) plt.xlabel('Director')
plt.ylabel('Number of Movies/TV Shows')
plt.title('Top 10 Directors by Movie/TV Show Count') # Add count values on top of each bar
for index, value in enumerate(top_10_directors.values): bar_plot.text(index, value, str(value), ha='center', va='bottom') plt.show()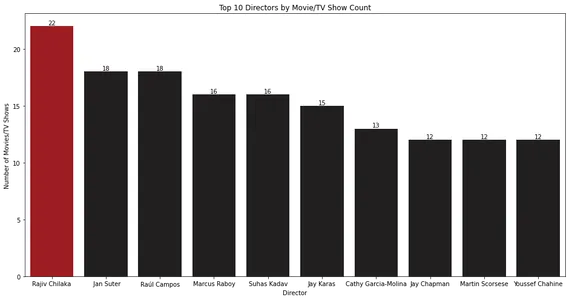
На линейчатой диаграмме показаны 10 лучших режиссеров с наибольшим количеством фильмов или телешоу. Раджив Чилака, кажется, руководил большей частью контента в библиотеке Netflix.
10 лучших категорий по количеству фильмов/телешоу
Для анализа распределения контента по разным категориям можно использовать следующий код:
df_listed_in['listed_in'] = df_listed_in['listed_in'].str.strip() # Count the occurrences of each actor
listed_in_counts = df_listed_in['listed_in'].value_counts() # Select the top 10 actors
top_10_listed_in = listed_in_counts.head(10) plt.figure(figsize=(12, 8))
bar_plot = sns.barplot(x=top_10_listed_in.index, y=top_10_listed_in.values, palette=colors) # Customize the plot
plt.xlabel('Category')
plt.ylabel('Number of Movies/TV Shows')
plt.title('Top 10 Categories by Movie/TV Show Count')
plt.xticks(rotation=45) # Add count values on top of each bar
for index, value in enumerate(top_10_listed_in.values): bar_plot.text(index, value, str(value), ha='center', va='bottom') # Show the plot
plt.show()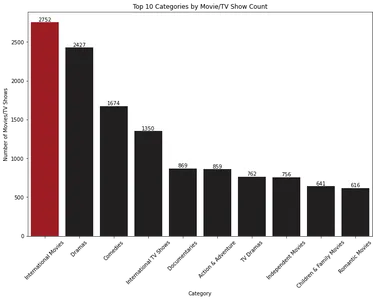
Гистограмма показывает 10 лучших категорий фильмов и телепередач в зависимости от их количества. «Международные фильмы» — самая доминирующая категория, за которой следуют «Драмы».
Фильмы и телешоу, добавленные со временем
Для анализа добавления фильмов и сериалов с течением времени можно использовать следующий код:
# Filter the DataFrame to include only Movies and TV Shows
df_movies = df[df['type'] == 'Movie']
df_tv_shows = df[df['type'] == 'TV Show'] # Group the data by year and count the number of Movies and TV Shows # added in each year
movies_count = df_movies['year_added'].value_counts().sort_index()
tv_shows_count = df_tv_shows['year_added'].value_counts().sort_index() # Create a line chart to visualize the trends over time
plt.figure(figsize=(16, 8))
plt.plot(movies_count.index, movies_count.values, color='#b20710', label='Movies', linewidth=2)
plt.plot(tv_shows_count.index, tv_shows_count.values, color='#221f1f', label='TV Shows', linewidth=2) # Fill the area under the line charts
plt.fill_between(movies_count.index, movies_count.values, color='#b20710')
plt.fill_between(tv_shows_count.index, tv_shows_count.values, color='#221f1f') # Customize the plot
plt.xlabel('Year')
plt.ylabel('Count')
plt.title('Movies & TV Shows Added Over Time')
plt.legend() # Show the plot
plt.show()
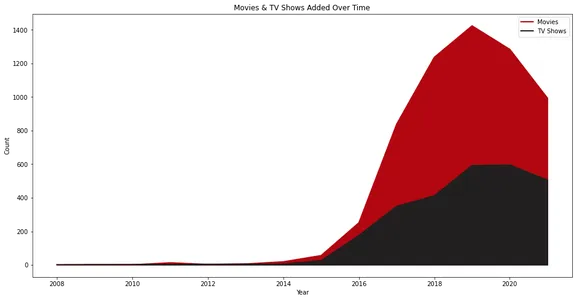
На линейной диаграмме показано количество фильмов и телешоу, добавленных в Netflix с течением времени. Он визуально представляет рост и тенденции в добавлении контента с отдельными строками для фильмов и телешоу.
Netflix продемонстрировал реальный рост, начиная с 2015 года, и мы видим, что за эти годы он добавил больше фильмов, чем телешоу.
Также интересно, что добавление контента в 2020 году сократилось. Возможно, это связано с ситуацией с пандемией.
Далее мы исследуем распределение добавленного контента в разные месяцы. Этот анализ помогает нам выявлять закономерности и понимать, когда Netflix представляет новый контент.
Контент, добавленный по месяцам
Чтобы исследовать это, мы извлекаем месяц из столбца date_added и подсчитываем количество вхождений каждого месяца. Визуализация этих данных в виде гистограммы позволяет нам быстро определить месяцы с наибольшим добавлением контента.
# Extract the month from the 'date_added' column
df['month_added'] = pd.to_datetime(df['date_added']).dt.month_name() # Define the order of the months
month_order = ['January', 'February', 'March', 'April', 'May', 'June', 'July', 'August', 'September', 'October', 'November', 'December'] # Count the number of shows added in each month
monthly_counts = df['month_added'].value_counts().loc[month_order] # Determine the maximum count
max_count = monthly_counts.max() # Set the color for the highest bar and the rest of the bars
colors = ['#b20710' if count == max_count else '#221f1f' for count in monthly_counts] # Create the bar chart
plt.figure(figsize=(16, 8))
bar_plot = sns.barplot(x=monthly_counts.index, y=monthly_counts.values, palette=colors) # Customize the plot
plt.xlabel('Month')
plt.ylabel('Count')
plt.title('Content Added by Month') # Add count values on top of each bar
for index, value in enumerate(monthly_counts.values): bar_plot.text(index, value, str(value), ha='center', va='bottom') # Rotate x-axis labels for better readability
plt.xticks(rotation=45) # Show the plot
plt.show()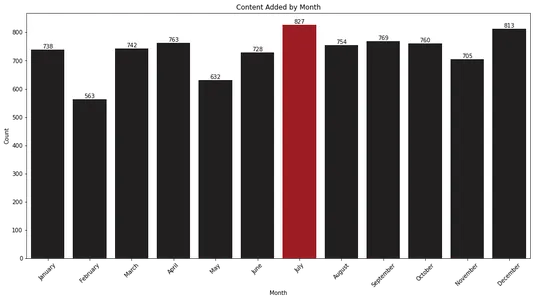
Гистограмма показывает, что июль и декабрь — это месяцы, когда Netflix добавляет больше всего контента в свою библиотеку. Эта информация может быть полезна для зрителей, которые хотят ожидать новых выпусков в течение этих месяцев.
Еще одним важным аспектом анализа контента Netflix является понимание распределения рейтингов. Изучив количество каждой рейтинговой категории, мы можем определить наиболее распространенные типы контента на платформе.
Распределение рейтингов
Мы начинаем с расчета вхождений каждой рейтинговой категории и визуализируем их с помощью гистограммы. Эта визуализация дает четкое представление о распределении рейтингов.
# Count the occurrences of each rating
rating_counts = df['rating'].value_counts() # Create a bar chart to visualize the ratings
plt.figure(figsize=(16, 8))
colors = ['#b20710'] + ['#221f1f'] * (len(rating_counts) - 1)
sns.barplot(x=rating_counts.index, y=rating_counts.values, palette=colors) # Customize the plot
plt.xlabel('Rating')
plt.ylabel('Count')
plt.title('Distribution of Ratings') # Rotate x-axis labels for better readability
plt.xticks(rotation=45) # Show the plot
plt.show()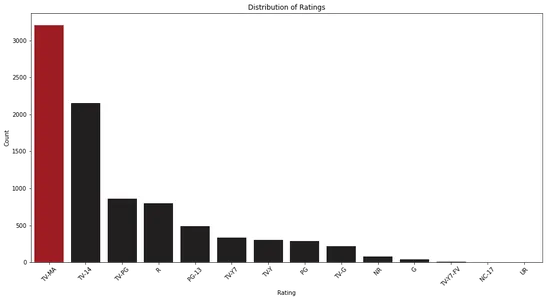
Анализируя гистограмму, мы можем наблюдать распределение рейтингов на Netflix. Это помогает нам определить наиболее распространенные рейтинговые категории и их относительную частоту.
Тепловая карта корреляции жанров
Жанры играют важную роль в категоризации и организации контента на Netflix. Анализ соотношения между жанрами может выявить интересные отношения между различными типами контента.
Мы создаем DataFrame жанровых данных для исследования корреляции жанров и заполняем его нулями. Перебирая каждую строку в исходном кадре данных, мы обновляем кадр данных жанра на основе перечисленных жанров. Затем мы создаем матрицу корреляции, используя данные этого жанра, и визуализируем ее в виде тепловой карты.
# Extracting unique genres from the 'listed_in' column
genres = df['listed_in'].str.split(', ', expand=True).stack().unique() # Create a new DataFrame to store the genre data
genre_data = pd.DataFrame(index=genres, columns=genres, dtype=float) # Fill the genre data DataFrame with zeros
genre_data.fillna(0, inplace=True) # Iterate over each row in the original DataFrame and update the genre data DataFrame
for _, row in df.iterrows(): listed_in = row['listed_in'].split(', ') for genre1 in listed_in: for genre2 in listed_in: genre_data.at[genre1, genre2] += 1 # Create a correlation matrix using the genre data
correlation_matrix = genre_data.corr() # Create the heatmap
plt.figure(figsize=(20, 16))
sns.heatmap(correlation_matrix, annot=False, cmap='coolwarm') # Customize the plot
plt.title('Genre Correlation Heatmap')
plt.xticks(rotation=90)
plt.yticks(rotation=0) # Show the plot
plt.show()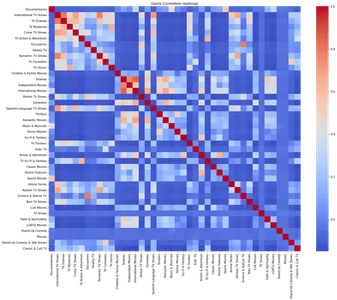
Тепловая карта демонстрирует корреляцию между разными жанрами. Анализируя тепловую карту, мы можем выявить сильную положительную корреляцию между определенными жанрами, такими как драмы и международные телешоу, романтические телешоу и международные телешоу.
Распределение продолжительности фильмов и количества серий телешоу
Понимание продолжительности фильмов и телепередач дает представление о продолжительности контента и помогает зрителям планировать время просмотра. Изучая распределение продолжительности фильмов и телешоу, мы можем лучше понять контент, доступный на Netflix.
Для этого мы извлекаем продолжительность фильмов и количество эпизодов телешоу из столбца «длительность». Затем мы строим гистограммы и диаграммы, чтобы визуализировать распределение продолжительности фильмов и телешоу.
# Extract the movie lengths and TV show episode counts
movie_lengths = df_movies['duration'].str.extract('(d+)', expand=False).astype(int)
tv_show_episodes = df_tv_shows['duration'].str.extract('(d+)', expand=False).astype(int) # Plot the histogram
plt.figure(figsize=(10, 6))
plt.hist(movie_lengths, bins=10, color='#b20710', label='Movies')
plt.hist(tv_show_episodes, bins=10, color='#221f1f', label='TV Shows') # Customize the plot
plt.xlabel('Duration/Episode Count')
plt.ylabel('Frequency')
plt.title('Distribution of Movie Lengths and TV Show Episode Counts')
plt.legend() # Show the plot
plt.show()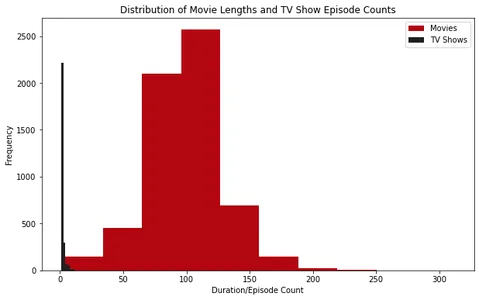
Анализируя гистограммы, мы можем заметить, что большинство фильмов на Netflix имеют продолжительность около 100 минут. С другой стороны, у большинства сериалов на Netflix всего один сезон.
Кроме того, изучая диаграммы, мы видим, что фильмы продолжительностью более 2.5 часов считаются выбросами. Для телешоу найти те, у которых более четырех сезонов, необычно.
Тенденция длины фильмов/телешоу с годами
Мы можем построить линейные графики, чтобы понять, как менялись продолжительность фильмов и количество эпизодов телешоу с годами. Выявление закономерностей или сдвигов в продолжительности контента путем анализа этих тенденций.
Мы начинаем с извлечения продолжительности фильма и количества эпизодов телешоу из столбца «длительность». Затем мы создаем линейные графики, чтобы визуализировать изменения продолжительности фильмов и эпизодов телешоу с годами.
import seaborn as sns
import matplotlib.pyplot as plt # Extract the movie lengths and TV show episodes from the 'duration' column
movie_lengths = df_movies['duration'].str.extract('(d+)', expand=False).astype(int)
tv_show_episodes = df_tv_shows['duration'].str.extract('(d+)', expand=False).astype(int) # Create line plots for movie lengths and TV show episodes
plt.figure(figsize=(16, 8)) plt.subplot(2, 1, 1)
sns.lineplot(data=df_movies, x='release_year', y=movie_lengths, color=colors[0])
plt.xlabel('Release Year')
plt.ylabel('Movie Length')
plt.title('Trend of Movie Lengths Over the Years') plt.subplot(2, 1, 2)
sns.lineplot(data=df_tv_shows, x='release_year', y=tv_show_episodes,color=colors[1])
plt.xlabel('Release Year')
plt.ylabel('TV Show Episodes')
plt.title('Trend of TV Show Episodes Over the Years') # Adjust the layout and spacing
plt.tight_layout() # Show the plots
plt.show()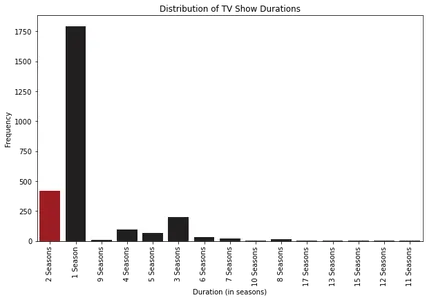
Анализируя линейные графики, мы наблюдаем захватывающие закономерности. Мы видим, что продолжительность фильма сначала увеличивалась примерно до 1963-1964 годов, а затем постепенно сокращалась, стабилизировавшись в среднем на уровне 100 минут. Это свидетельствует об изменении предпочтений аудитории с течением времени.
Что касается эпизодов телешоу, то с начала 2000-х годов мы заметили постоянную тенденцию, когда большинство телешоу на Netflix имеют от одного до трех сезонов. Это указывает на то, что зрители отдают предпочтение более коротким сериалам или ограниченным форматам сериалов.
Самые распространенные слова в заголовках и описаниях
Анализ наиболее распространенных слов, используемых в заголовках и описаниях, может дать представление о темах и контенте, ориентированных на Netflix. Мы можем создавать облака слов, чтобы выявить эти шаблоны на основе заголовков и описаний контента Netflix.
from wordcloud import WordCloud # Concatenate all the titles into a single string
text = ' '.join(df['title']) wordcloud = WordCloud(width = 800, height = 800, background_color ='white', min_font_size = 10).generate(text) # plot the WordCloud image
plt.figure(figsize = (8, 8), facecolor = None)
plt.imshow(wordcloud)
plt.axis("off")
plt.tight_layout(pad = 0) plt.show() # Concatenate all the titles into a single string
text = ' '.join(df['description']) wordcloud = WordCloud(width = 800, height = 800, background_color ='white', min_font_size = 10).generate(text) # plot the WordCloud image
plt.figure(figsize = (8, 8), facecolor = None)
plt.imshow(wordcloud)
plt.axis("off")
plt.tight_layout(pad = 0) plt.show()
Изучая облако слов на предмет заголовков, мы замечаем, что часто используются такие термины, как «Любовь», «Девушка», «Мужчина», «Жизнь» и «Мир», что указывает на присутствие романтики, взросления и драмы. жанры в библиотеке контента Netflix.
Анализируя облако слов для описания, мы замечаем доминирующие слова, такие как «жизнь», «найти» и «семья», предлагая темы личных путешествий, отношений и семейной динамики, преобладающие в контенте Netflix.
Распределение продолжительности фильмов и сериалов
Анализ распределения продолжительности фильмов и телешоу позволяет нам понять типичную продолжительность контента, доступного на Netflix. Мы можем создавать диаграммы для визуализации этих распределений и выявления выбросов или стандартной продолжительности.
# Extracting and converting the duration for movies
df_movies['duration'] = df_movies['duration'].str.extract('(d+)', expand=False).astype(int) # Creating a boxplot for movie duration
plt.figure(figsize=(10, 6))
sns.boxplot(data=df_movies, x='type', y='duration')
plt.xlabel('Content Type')
plt.ylabel('Duration')
plt.title('Distribution of Duration for Movies')
plt.show() # Extracting and converting the duration for TV shows
df_tv_shows['duration'] = df_tv_shows['duration'].str.extract('(d+)', expand=False).astype(int) # Creating a boxplot for TV show duration
plt.figure(figsize=(10, 6))
sns.boxplot(data=df_tv_shows, x='type', y='duration')
plt.xlabel('Content Type')
plt.ylabel('Duration')
plt.title('Distribution of Duration for TV Shows')
plt.show()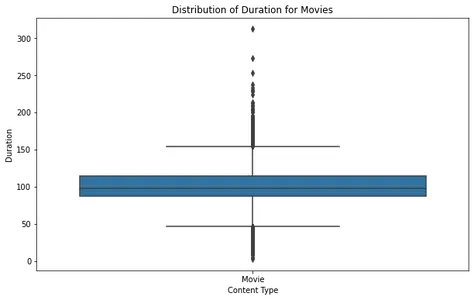
Анализируя сюжет коробки с фильмом, мы видим, что большинство фильмов попадают в разумный диапазон продолжительности, с небольшими выбросами, превышающими примерно 2.5 часа. Это говорит о том, что большинство фильмов на Netflix рассчитаны на стандартное время просмотра.
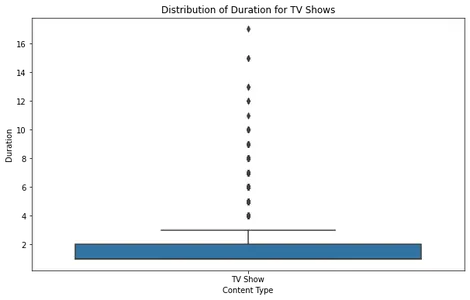
Для телешоу сюжет коробки показывает, что большинство шоу имеют от одного до четырех сезонов, и очень немногие выбросы имеют более длительную продолжительность. Это согласуется с более ранними тенденциями, указывая на то, что Netflix фокусируется на форматах более коротких сериалов.
Заключение
С помощью этой статьи мы смогли узнать о-
- Количество: Наш анализ показал, что Netflix добавил больше фильмов, чем телешоу, что соответствует ожиданиям, что фильмы доминируют в их библиотеке контента.
- Добавление контента: июль стал месяцем, когда Netflix добавляет больше всего контента, за ним следует декабрь, что указывает на стратегический подход к выпуску контента.
- Жанровая корреляция: Сильные положительные ассоциации наблюдались между различными жанрами, такими как телевизионные драмы и международные телешоу, романтические и международные телешоу, а также независимые фильмы и драмы. Эти корреляции дают представление о предпочтениях зрителей и взаимосвязях контента.
- Продолжительность фильмов: анализ продолжительности фильмов показал пик в 1960-х годах, за которым последовала стабилизация около 100 минут, подчеркнув тенденцию продолжительности фильмов с течением времени.
- Эпизоды телешоу: большинство телешоу на Netflix имеют один сезон, что говорит о том, что зрители отдают предпочтение более коротким сериалам.
- Общие темы: такие слова, как любовь, жизнь, семья и приключение, часто встречались в заголовках и описаниях, отражая повторяющиеся темы в контенте Netflix.
- Распределение рейтингов. Распределение рейтингов по годам дает представление о меняющемся ландшафте контента и восприятии аудитории.
- Аналитика, основанная на данных: Наше путешествие по анализу данных продемонстрировало силу данных в разгадке тайн ландшафта контента Netflix, предоставляя ценную информацию для зрителей и создателей контента.
- Постоянная актуальность: по мере развития индустрии потокового вещания понимание этих закономерностей и тенденций становится все более важным для навигации по динамичному ландшафту Netflix и его обширной библиотеки.
- Happy Streaming: мы надеемся, что этот блог был поучительным и интересным путешествием в мир Netflix, и мы призываем вас изучить захватывающие истории в его постоянно меняющемся контенте. Пусть данные направят ваши стриминговые приключения!
Официальная документация и ресурсы
Ниже вы найдете официальные ссылки на библиотеки, использованные в нашем анализе. Вы можете обратиться к этим ссылкам для получения дополнительной информации о методах и функциях, предоставляемых этими библиотеками:
- Панды: https://pandas.pydata.org/
- Числовой: https://numpy.org/
- Матплотлиб: https://matplotlib.org/
- Научный: https://scipy.org/
- Сиборн: https://seaborn.pydata.org/
Материалы, показанные в этой статье, не принадлежат Analytics Vidhya и используются по усмотрению Автора.
Похожие страницы:
- SEO-контент и PR-распределение. Получите усиление сегодня.
- ПлатонАйСтрим. Анализ данных Web3. Расширение знаний. Доступ здесь.
- Чеканка будущего с Эдриенн Эшли. Доступ здесь.
- Покупайте и продавайте акции компаний PREIPO® с помощью PREIPO®. Доступ здесь.
- Источник: https://www.analyticsvidhya.com/blog/2023/06/netflix-case-study-eda-unveiling-data-driven-strategies-for-streaming/
- :имеет
- :является
- :нет
- :куда
- 1
- 10
- 100
- 12
- 20
- 2015
- 2020
- 2022
- 8
- 9
- a
- в состоянии
- О нас
- изобилие
- принятие
- доступность
- точный
- Достигать
- через
- актеры
- Добавить
- добавленный
- дополнение
- дополнительный
- дополнениями
- адрес
- Добавляет
- Приключение.
- цель
- Выравнивает
- Все
- Позволяющий
- позволяет
- накопил
- среди
- an
- анализ
- аналитика
- Аналитика Видхья
- анализировать
- анализ
- и
- предвидеть
- любой
- Выступления
- подхода
- примерно
- апрель
- МЫ
- ПЛОЩАДЬ
- около
- гайд
- AS
- внешний вид
- аспекты
- ассоциации
- At
- Атрибуты
- аудитория
- Август
- свободных мест
- доступен
- в среднем
- избежать
- назад
- бар
- бары
- Использование темпера с изогнутым основанием
- основанный
- BE
- становиться
- становится
- было
- начинать
- начало
- ниже
- Лучшая
- между
- смещение
- Блог
- Дно
- Коробка
- by
- вычислять
- расчет
- CAN
- возможности
- пленительный
- Захват
- случаев
- тематическое исследование
- категории
- категоризации
- Категории
- Центр
- изменения
- характеристика
- График
- Графики
- контроль
- Китай
- выбор
- Очистить
- тесно
- облако
- код
- лыжных шлемов
- цвет
- Column
- Колонки
- Общий
- обычно
- Компания
- комплектующие
- комплексный
- вычисление
- считается
- последовательный
- состоит
- потреблять
- содержание
- создатели контента
- Типы контента
- конверсий
- конвертировать
- преобразование
- Корреляция
- корреляции
- может
- страны
- страна
- Создайте
- создали
- Создающий
- Создатели
- решающее значение
- настроить
- данным
- анализ данных
- Потеря данных
- Подготовка данных
- наука о данных
- визуализация данных
- управляемых данными
- Стратегия, основанная на данных
- Дата и время
- Декабрь
- глубоко
- демонстрирует
- описывать
- описание
- предназначенный
- подробный
- Определять
- отклонение
- различный
- направленный
- директор
- Директора
- усмотрение
- отображать
- дисплеев
- распределение
- распределения
- Разное
- Разнообразная аудитория
- документации
- доминирующий
- господствовать
- Драма
- Падение
- упал
- Опустившись
- два
- дубликаты
- продолжительность
- в течение
- динамический
- динамика
- каждый
- Ранее
- Рано
- экосистема
- фактически
- усилия
- еще
- начинать
- появившийся
- включить
- позволяет
- поощрять
- повышать
- расширение
- обеспечивать
- обеспечение
- развлекательный
- Развлечения
- энтузиастов
- эпизод
- Эпизоды
- существенный
- установленный
- Эфир (ETH)
- Даже
- постоянно меняющихся
- Каждая
- эволюционировали
- эволюционирует
- развивается
- Изучение
- захватывающий
- без учета
- расширенный
- расширяющийся
- расширение
- ожидание
- опытные
- исследование
- Больше
- исследует
- Исследование
- извлечение
- Осень
- семья
- февраль
- несколько
- цифры
- Файл
- заполнять
- фильм
- пленки
- фильтр
- Найдите
- обнаружение
- Во-первых,
- соответствовать
- Фокус
- фокусируется
- следует
- после
- Что касается
- Форс-мажор
- формат
- найденный
- Год основания
- 4
- частота
- часто
- свежий
- от
- функция
- функциональные возможности
- Функции
- далее
- Gain
- порождать
- получить
- Глобальный
- глобальное присутствие
- ГЛОБАЛЬНО
- Go
- постепенно
- группы
- Рост
- инструкция
- было
- рука
- обрабатывать
- Управляемость
- Есть
- имеющий
- высота
- помощь
- помогает
- здесь
- Скрытый
- наивысший
- выделив
- препятствовать
- надежды
- ЧАСЫ
- Как
- HTTPS
- ID
- определения
- идентифицирующий
- if
- иллюстрирует
- изображение
- Влияние
- Импортировать
- импортирующий
- впечатляющий
- in
- включают
- расширились
- все больше и больше
- независимые
- индекс
- указанный
- указывает
- промышленность
- информация
- начальный
- первоначально
- размышления
- целостность
- интересный
- Мультиязычность
- в
- интригующий
- Представляет
- исследовать
- вовлеченный
- вопросы
- IT
- ЕГО
- январь
- путешествие
- Путешествия
- июль
- июнь
- Корея
- Этикетки
- пейзаж
- Языки
- слоев
- Планировка
- ведущий
- УЧИТЬСЯ
- изучение
- Длина
- уровень
- Используя
- библиотеки
- Библиотека
- ЖИЗНЬЮ
- легкий
- такое как
- Ограниченный
- линия
- линий
- связи
- Включенный в список
- загрузка
- погрузка
- дольше
- посмотреть
- от
- любят
- машина
- обучение с помощью машины
- сделанный
- поддерживать
- Манипуляция
- Март
- Matplotlib
- матрица
- максимальный
- Май..
- значить
- Медиа
- методы
- миллиона
- минимизировать
- минимальный
- минут
- отсутствующий
- режим
- Месяц
- месяцев
- БОЛЕЕ
- самых
- кино
- Кино
- имя
- навигационный
- необходимо
- необходимый
- Netflix
- Новые
- следующий
- нет
- север
- Северная Корея
- Примечательно
- Уведомление..
- Ноябрь
- номер
- NumPy
- наблюдать
- получение
- происходящий
- октябрь
- of
- от
- предлагающий
- Предложения
- Предложения
- Официальный представитель в Грузии
- on
- ONE
- только
- Операционный отдел
- or
- заказ
- организации
- оригинал
- Другое
- наши
- за
- общий
- обзор
- принадлежащих
- площадка
- панд
- пандемия
- часть
- паттеранами
- Вершина горы
- процент
- выполнять
- личного
- перспектива
- план
- Платформа
- Платформы
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- Играть
- Популярное
- популярность
- положительный
- потенциал
- мощностью
- предпочтения
- подготовка
- присутствие
- превалирующий
- обеспечивать
- при условии
- приводит
- обеспечение
- публично
- опубликованный
- Четверть
- быстро
- ассортимент
- рейтинг
- рейтинги
- готовый
- реальные
- разумный
- прием
- учет
- повторяющихся
- Отношения
- относительный
- освободить
- публикации
- актуальность
- осталось
- замечательный
- удаление
- замещать
- представляет
- ОТДЫХ
- Итоги
- показывать
- Показали
- Показывает
- революция
- правую
- Роли
- РЯД
- Россия
- Наука
- рожденное море
- Время года
- сезонный
- сезоны
- Во-вторых
- вторая четверть
- Раздел
- посмотреть
- кажется
- отдельный
- отдельно
- сентябрь
- Серии
- набор
- сдвиг
- Смены
- показывать
- демонстрации
- продемонстрированы
- показанный
- Шоу
- значительный
- с
- одинарной
- ситуация
- So
- некоторые
- источников
- пространства
- конкретный
- раскол
- стандарт
- Начало
- Начало
- Области
- статистике
- Шаг
- Шаги
- магазин
- хранить
- Истории
- Стратегический
- стратегическим походом
- стратегий
- Стратегия
- потоковый
- строка
- сильный
- Структура
- Кабинет
- субтитры
- Успешно
- такие
- Предлагает
- пригодность
- РЕЗЮМЕ
- Сирия
- ТАБЛИЦЫ
- задачи
- terms
- чем
- который
- Ассоциация
- Местоположение
- мир
- их
- Их
- тогда
- Эти
- они
- этой
- те
- три
- Через
- время
- Название
- титулованный
- позиций
- в
- инструменты
- топ
- Топ-10
- Transform
- трансформация
- преобразован
- тенденция
- Тенденции
- tv
- ТВ-шоу
- напишите
- Типы
- типичный
- Обычный
- открывай
- под
- подчеркивание
- понимать
- понимание
- созданного
- Объединенный
- США
- Вселенная
- до
- обнародование
- Обновление ПО
- us
- использование
- используемый
- через
- ценный
- Ценная информация
- ценностное
- Наши ценности
- различный
- Огромная
- очень
- просмотров
- просмотр
- визуализация
- визуализации
- хотеть
- законопроект
- наблюдение
- we
- WebP
- были
- когда
- в то время как
- белый
- КТО
- широко распространена
- будете
- в
- Word
- слова
- Мир
- по всему миру
- X
- год
- лет
- являетесь
- ВАШЕ
- зефирнет