Вы когда-нибудь ждали ту самую дорогую посылку с надписью «отправлено», но понятия не имели, где она? История отслеживания перестала обновляться пять дней назад, и вы почти потеряли надежду. Но подождите, 11 дней спустя, он у вас на пороге. Вы хотели, чтобы прослеживаемость могла быть лучше, чтобы избавить вас от всего беспокойного ожидания. Вот где в игру вступает «наблюдательность».
В техническом ландшафте вы хотели бы избежать этого с вашим программным обеспечением или системами данных. Таким образом, вы используете инструменты мониторинга, которые собирают журналы и метрики ваших систем и информируют вас об их внутреннем состоянии. Мониторинг работает лучше всего, когда вы хотите, чтобы ваши системы сообщали вам, что это за ошибка, где и когда она произошла, но не сообщали вам, как ее устранить.
Более десяти лет назад инструментам мониторинга не хватало контекста и предвидения основных системных проблем, и команды были ограничены отладкой повседневных операционных ошибок. Сегодня мы работаем и живем в распределенном мире микросервисов и конвейеры данных; даже использование нескольких инструментов мониторинга не поможет вам ответить на такие бизнес-вопросы, как «Почему мое приложение всегда работает медленно?» или «На каком этапе возникла проблема и насколько глубоко она находится в стеке?» или «Как я могу улучшить общую производительность среды?» Становится необходимым проявлять инициативу в принятии этих решений и иметь общую видимость ваших систем, приложений и данных.
Эта блоге by Etsy был опубликован десять лет назад, и во втором абзаце он констатирует сам факт:
«Метрики приложения обычно самые сложные, но самые важные из трех. Они очень специфичны для вашего бизнеса и меняются по мере изменения ваших приложений (а Etsy сильно меняется)».
Итак, как мы измеряем все и вся? Начнем с наблюдаемости.
Что такое наблюдаемость?
Термин «наблюдаемость» был придумано Рудольф Эмиль Кальман в 1960 году в своей инженерной статье для описания математических систем управления. Он определил его как меру того, насколько хорошо внутренние состояния системы могут быть выведены из знания ее внешних выходов. Но разве это не похоже на мониторинг? В принципе, да, это мониторинг.
В наши дни наблюдаемость стала довольно горячей темой. Согласно нескольким исследованиям рынка, это платформа на миллиард долларов. Многие организации приняли эту концепцию и использовали ее в качестве основы для сквозной видимости своих распределенных систем и конвейеров. Однако наблюдаемость путают с мониторингом. На данный момент я могу сказать, что мониторинг — это подмножество наблюдаемости, где наблюдаемость — это один большой общий термин.
Наблюдаемость позволяет выполнять распределенную трассировку путем сбора и агрегирования трассировок, журналов и метрик. Давайте посмотрим, что они предполагают:
- Следы: Когда система получает запрос, трассировка сообщает вам, как этот запрос проходит на протяжении всего своего жизненного цикла от источника к месту назначения. Трассы представлены «промежутками». Трассировка — это дерево отрезков, а отрезок — это отдельная операция внутри трассы. Они помогают обнаруживать ошибки, задержки или узкие места в системе.
- Журналы: Это сгенерированные машиной события с отметкой времени, которые сообщают вам об операциях или изменениях, произошедших в системе. Журналы часто используются для запроса этих ошибок или изменений в системе.
- Метрики: Они предоставляют количественную информацию об использовании ЦП, памяти, диска и производительности системы за определенный период времени.
Эти атрибуты улучшают структуру мониторинга с отслеживаемостью. Отслеживаемость предоставляет вам линзы для отслеживания запроса, который вызывает вашу систему, сколько времени требуется для перехода от одного компонента к другому, какие другие службы он вызывает, выдает ли он какую-либо ошибку, какие журналы он создает, в каком состоянии он находится, когда он начался и закончился, каков график времени, в течение которого он оставался в вашей системе, и т. д. Когда вы собираете, объединяете и анализируете эти следы, вы можете принимать ценные обоснованные решения, такие как график клиентов на веб-сайте электронной коммерции. , сколько времени им потребовалось для поиска продукта, как долго они просматривали продукт, загрузила ли HTML-страница полную информацию, такую как изображения или встроенные видео, сколько времени потребовалось системе для аутентификации и обработки платежа и т. д.
Чего мы достигаем с наблюдаемостью в распределенной среде?
Эволюция распределенных систем началась, когда организации начали переходить от своей централизованной монолитной архитектуры к распределенной и децентрализованной микросервисной архитектуре. И это все еще продолжается, многие организации используют микросервисную природу систем и приложений. И все это можно отнести к большие данные и масштабирование. Управление распределенной средой требует непрерывного обучения, дополнительной рабочей силы, изменений в платформах и политиках, управления ИТ и так далее. Это действительно большое изменение.
Раньше в ограниченной монолитной среде оборудование, программное обеспечение, данные и базы данных находились под одной крышей. С появлением больших данных в 2000-х годах системы мониторинга и масштабирования стали вызывать серьезную озабоченность. Часто организации использовали различные инструменты мониторинга для удовлетворения потребностей своих различных приложений. В результате он вскоре стал операционным накладным расходом с плохой устойчивостью, видимостью и надежностью.
Все эти проблемы привели к принятию наблюдаемости. Сегодня существует множество инструментов наблюдения для безопасности, сети, приложений и конвейеров данных для распределенной трассировки в сложной среде. Они сосуществуют со своим двоюродным братом, инструментами мониторинга, и используют возможность сбора информации от своего двоюродного брата и объединения с дополнительной информацией из собственных данных трассировки.
Во всех этих системах есть много движущихся компонентов, чьи следы при захвате могут проиллюстрировать историю 5 W: когда, где, почему, что и как. Например, вы заходите на сайт DATAVERSITY в 1:43, чтобы прочитать несколько сообщений в блоге. Когда вы попадаете на dataversity.net, HTTP-запрос регистрируется в системе. Вы начинаете искать сообщение в блоге и переходите к сообщению об управлении данными, где вы читаете это сообщение 17 минут, а затем закрываете вкладку в 2:00.
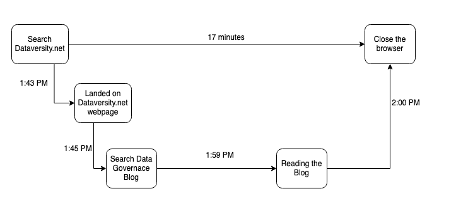
Также будут совершаться другие вызовы в сетевую систему для перехвата сетевых пакетов. Инструменты наблюдения собирают все промежутки и объединяют их в трассу или трассы, позволяя вам увидеть путь, который он сформировал в течение своего жизненного цикла. Если у вас есть такая проблема, как задержка в сети или системный дефект, теперь проще проанализировать (очистить луковицу) и отладить проблему (ошибка в каком слое).
Теперь в большой распределенной среде, когда ваши приложения получают миллионы запросов, данные трассировки растут в огромных объемах. Сбор и анализ этих трассировок требует больших затрат на хранение и передачу данных. Таким образом, для экономии средств данные трассировки выбираются, потому что в большинстве случаев инженерным группам нужны только некоторые части для исследования того, что пошло не так или какова картина ошибки.
На этом небольшом примере мы понимаем, что получаем гораздо более глубокое понимание наших систем. Таким образом, с учетом больших масштабов систем группы инженеров могут собирать и обрабатывать выборочные данные, чтобы улучшить текущую структуру системы, применять или удалять новые компоненты, добавлять еще один уровень безопасности, устранять узкие места и т. д.
Должны ли организации выбирать наблюдаемость?
Мы все должны понимать, что конечными целями являются улучшение пользовательского опыта и повышение удовлетворенности пользователей. И путь к достижению этих целей можно упростить с помощью автоматизированной и упреждающей системы наблюдения. Создание культуры постоянного совершенствования и оптимизации считается оптимальным подходом к бизнесу и лидерству.
В наш век цифровых преобразований наблюдаемость стала обязательным условием успеха бизнеса в цифровом путешествии. Предоставляя вам проницательные следы, наблюдаемость также маневрирует, чтобы вы были информированы о данных, а не просто управлялись данными.
Заключение
Хотя мы использовали термины «мониторинг» и «наблюдаемость» как синонимы, мы увидели, что, хотя мониторинг помогает вам получить информацию о состоянии системы и событиях, происходящих в ней, наблюдаемость помогает вам делать выводы на основе данных, собранных из более глубоких слоев конечной системы. конечная среда.
Наблюдаемость является и может также восприниматься как компонент структуры управления данными. В этом поколении, когда постоянно растущий объем данных находится в сети стандартного оборудования, жизненно важно сохранять как можно более простую архитектуру. И, очевидно, становится невыполнимой задачей управление окружающей средой в будущем. Таким образом, внедрение надлежащих и автоматизированных политик и правил управления, чтобы ваша большая сеть систем, конвейеров и данных не загромождалась, требует действий как можно раньше.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- Платоблокчейн. Интеллект метавселенной Web3. Расширение знаний. Доступ здесь.
- Источник: https://www.dataversity.net/observability-traceability-for-distributed-systems/
- 1
- 11
- a
- в состоянии
- О нас
- По
- Достигать
- достижение
- Действие
- дополнительный
- Дополнительная информация
- принять
- принял
- Принятие
- приход
- Все
- позволяет
- всегда
- анализировать
- анализ
- и
- Другой
- ответ
- Применение
- Приложения
- Применить
- подхода
- соответствующий
- архитектура
- Атрибуты
- проверять подлинность
- Автоматизированный
- избежать
- основанный
- в основном
- , так как:
- становиться
- становится
- начал
- ЛУЧШЕЕ
- Лучшая
- большой
- Big Data
- Блог
- Сообщения в блоге
- узкие
- бизнес
- призывают
- Объявления
- захватить
- случаев
- централизованная
- изменение
- изменения
- Выберите
- Закрыть
- собирать
- Сбор
- товар
- полный
- комплекс
- компонент
- компоненты
- сама концепция
- Беспокойство
- спутанный
- считается
- принимая во внимание
- потребление
- контекст
- (CIJ)
- контроль
- Расходы
- может
- ЦП
- Культура
- Текущий
- клиент
- данным
- управляемых данными
- базы данных
- ДАТАВЕРСИЯ
- дня в день
- Дней
- десятилетие
- децентрализованная
- решения
- глубоко
- более глубокий
- определенный
- описывать
- назначение
- подробнее
- DID
- различный
- Интернет
- цифровое преобразование
- распределенный
- распределенные системы
- не
- вниз
- в течение
- электронная коммерция
- легче
- встроенный
- охватывающий
- позволяет
- впритык
- Проект и
- Окружающая среда
- ошибка
- ошибки
- налаживание
- и т.д
- Даже
- События
- НИКОГДА
- постоянно растет
- многое
- , поскольку большинство сенаторов
- эволюция
- пример
- дорогим
- опыт
- и, что лучший способ
- облегчает
- Потоки
- сформированный
- Рамки
- каркасы
- от
- поколение
- получить
- Go
- Цели
- управление
- большой
- Растет
- произошло
- Случай
- Аппаратные средства
- Медицина
- помощь
- помогает
- история
- Удар
- надежды
- ГОРЯЧИЙ
- Как
- How To
- Однако
- HTML
- HTTPS
- огромный
- изображений
- Осуществляющий
- важную
- что она
- улучшать
- улучшение
- in
- информация
- сообщил
- размышления
- в нашей внутренней среде,
- исследовать
- Запускает
- вопрос
- вопросы
- IT
- Управление ИТ
- путешествие
- Сохранить
- знания
- пейзаж
- большой
- больше
- Задержка
- слой
- слоев
- Наша команда
- изучение
- линзы
- Кредитное плечо
- Жизненный цикл
- Ограниченный
- линия
- жить
- загрузка
- Длинное
- серия
- сделанный
- сделать
- ДЕЛАЕТ
- Создание
- управлять
- управление
- управления
- многих
- рынок
- математический
- макс-ширина
- проводить измерение
- Память
- Метрика
- microservices
- миллионы
- минут
- Мониторинг
- монолитный
- самых
- двигаться
- перемещение
- с разными
- Должен иметь
- природа
- необходимо
- Необходимость
- потребности
- сеть
- сеть
- сетевая система
- Новые
- ONE
- операция
- оперативный
- Операционный отдел
- оптимальный
- оптимизация
- организации
- Другие контрактные услуги
- общий
- собственный
- бумага & картон
- путь
- шаблон
- оплата
- восприятии
- производительность
- выполнения
- период
- штук
- Платформа
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- Играть
- сборах
- состояния потока
- возможное
- После
- Блог
- Проактивная
- Проблема
- процесс
- Продукт
- Прогресс
- обеспечивать
- приводит
- обеспечение
- опубликованный
- количественный
- Вопросы
- скорее
- Читать
- Reading
- Получать
- получает
- надежность
- удаление
- представленный
- запросить
- Запросы
- требуется
- упругость
- ограниченный
- результат
- Рост
- крыша
- условиями,
- удовлетворение
- Сохранить
- Шкала
- масштабирование
- Поиск
- поиск
- Во-вторых
- безопасность
- Услуги
- несколько
- должен
- Шоу
- просто
- одинарной
- медленной
- небольшой
- So
- Software
- РЕШАТЬ
- некоторые
- Скоро
- Звук
- Источник
- пролеты
- конкретный
- тратить
- стек
- Этап
- Начало
- и политические лидеры
- Область
- Области
- остались
- По-прежнему
- остановившийся
- диск
- История
- Структура
- успешный
- система
- системы
- взять
- принимает
- Сложность задачи
- команды
- Технический
- terms
- Ассоциация
- информация
- Источник
- их
- тем самым
- три
- Через
- по всему
- время
- Сроки
- в
- сегодня
- инструменты
- тема
- прослеживать
- Прослеживаемость
- трассировка
- Отслеживание
- перевод
- трансформация
- зонтик
- под
- лежащий в основе
- понимать
- обновление
- Применение
- Информация о пользователе
- Пользовательский опыт
- обычно
- ценный
- различный
- Видео
- видимость
- жизненный
- объем
- ждать
- Ожидание
- Вебсайт
- Что
- Что такое
- который
- в то время как
- будете
- в
- Работа
- Трудовые ресурсы
- работает
- Мир
- бы
- Неправильно
- ВАШЕ
- зефирнет











