Эта серия из трех частей демонстрирует, как использовать графовые нейронные сети (GNN) и Амазонка Нептун генерировать рекомендации фильмов с помощью IMDb и Box Office Mojo Movies/TV/OTT лицензируемый пакет данных, который предоставляет широкий спектр развлекательных метаданных, включая более 1 миллиарда пользовательских рейтингов; кредиты для более чем 11 миллионов актеров и членов съемочной группы; 9 миллионов наименований фильмов, телепередач и развлекательных программ; и глобальные отчетные данные о кассовых сборах из более чем 60 стран. Многие клиенты AWS в сфере медиа и развлечений лицензируют данные IMDb через Обмен данными AWS для улучшения обнаружения контента и повышения вовлеченности и удержания клиентов.
In Часть 1, мы обсудили применение GNN, а также то, как преобразовать и подготовить наши данные IMDb для запросов. В этом посте мы обсуждаем процесс использования Neptune для создания вложений, используемых для поиска вне каталога в части 3. Мы также переходим Amazon Нептун ML, функция машинного обучения (ML) Neptune и код, который мы используем в процессе разработки. В части 3 мы рассмотрим, как применить наши вложения графа знаний к варианту использования поиска вне каталога.
Обзор решения
Большие связанные наборы данных часто содержат ценную информацию, которую трудно извлечь с помощью запросов, основанных только на человеческой интуиции. Методы машинного обучения могут помочь найти скрытые корреляции в графиках с миллиардами взаимосвязей. Эти корреляции могут быть полезны для рекомендации продуктов, прогнозирования кредитоспособности, выявления мошенничества и многих других вариантов использования.
Neptune ML позволяет создавать и обучать полезные модели машинного обучения на больших графиках за часы, а не за недели. Для этого Neptune ML использует технологию GNN, основанную на Создатель мудреца Амазонки и Библиотека Deep Graph (DGL) (который открытые источники). GNN — это новая область искусственного интеллекта (например, см. Всесторонний обзор графовых нейронных сетей). Практическое руководство по использованию GNN с DGL см. Изучение графовых нейронных сетей с помощью Deep Graph Library.
В этом посте мы покажем, как использовать Neptune в нашем пайплайне для создания вложений.
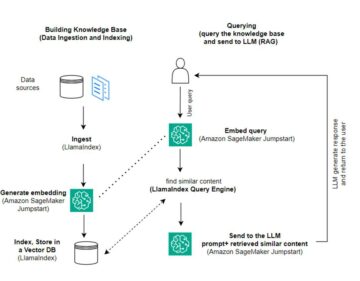
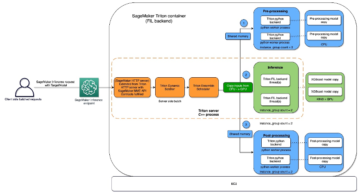
На следующей диаграмме показан общий поток данных IMDb от загрузки до создания встраивания.
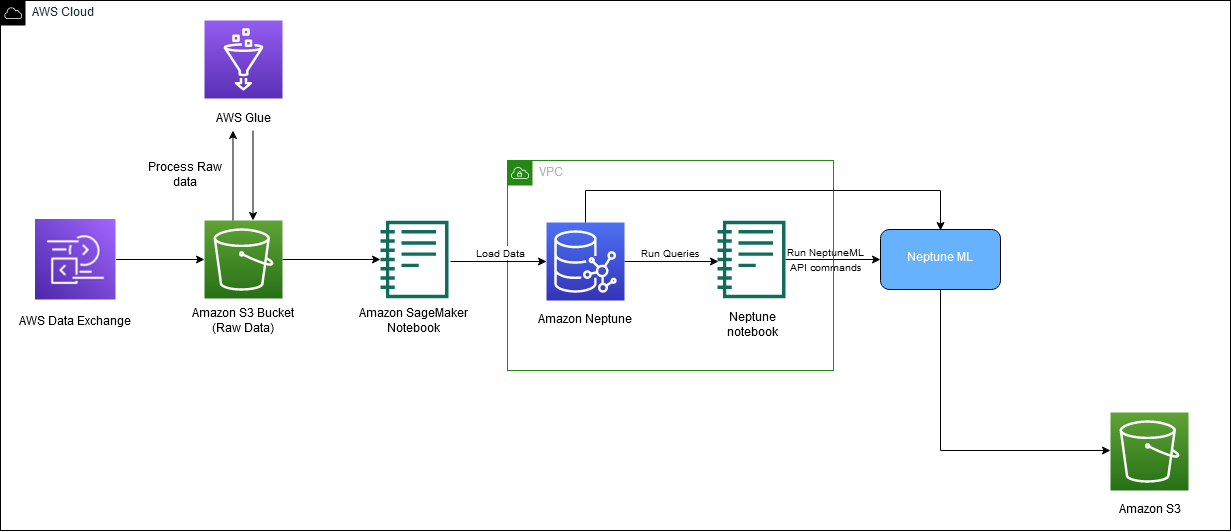
Для реализации решения мы используем следующие сервисы AWS:
В этом посте мы проведем вас через следующие шаги высокого уровня:
- Настройте переменные среды
- Создайте задание на экспорт.
- Создайте задание обработки данных.
- Отправьте задание на обучение.
- Скачать вложения.
Код для команд Neptune ML
Мы используем следующие команды как часть реализации этого решения:
МЫ ИСПОЛЬЗУЕМ neptune_ml export чтобы проверить статус или запустить процесс экспорта Neptune ML, а также neptune_ml training для запуска и проверки состояния задания обучения модели Neptune ML.
Дополнительные сведения об этих и других командах см. Использование магии верстака Neptune в ваших ноутбуках.
Предпосылки
Чтобы следовать этому посту, у вас должно быть следующее:
- An Аккаунт AWS
- Знакомство с SageMaker, Amazon S3 и AWS CloudFormation.
- Данные графика, загруженные в кластер Neptune (см. Часть 1 Чтобы получить больше информации)
Настройте переменные среды
Прежде чем мы начнем, вам нужно настроить среду, установив следующие переменные: s3_bucket_uri и processed_folder. s3_bucket_uri - это имя ведра, используемого в Части 1, и processed_folder — это расположение Amazon S3 для выходных данных задания экспорта.
Создать задание на экспорт
В части 1 мы создали записную книжку SageMaker и службу экспорта для экспорта наших данных из кластера Neptune DB в Amazon S3 в требуемом формате.
Теперь, когда наши данные загружены и сервис экспорта создан, нам нужно создать задание экспорта и запустить его. Для этого мы используем NeptuneExportApiUri и создайте параметры для задания экспорта. В следующем коде мы используем переменные expo и export_params, Набор expo . NeptuneExportApiUri значение, которое вы можете найти на Выходы вкладку вашего стека CloudFormation. За export_params, мы используем конечную точку вашего кластера Neptune и предоставляем значение для outputS3path, который является расположением Amazon S3 для выходных данных задания экспорта.
Чтобы отправить задание на экспорт, используйте следующую команду:
Чтобы проверить статус задания экспорта, используйте следующую команду:
После завершения работы установите processed_folder для указания местоположения Amazon S3 обработанных результатов:
Создать задание обработки данных
Теперь, когда экспорт завершен, мы создаем задание обработки данных, чтобы подготовить данные для процесса обучения Neptune ML. Это можно сделать несколькими способами. Для этого шага вы можете изменить job_name и modelType переменные, но все остальные параметры должны оставаться неизменными. Основной частью этого кода является modelType параметром, который может быть либо разнородными графовыми моделями (heterogeneous) или графы знаний (kge).
Задание экспорта также включает training-data-configuration.json. Используйте этот файл, чтобы добавить или удалить любые узлы или ребра, которые вы не хотите предоставлять для обучения (например, если вы хотите предсказать связь между двумя узлами, вы можете удалить эту связь в этом файле конфигурации). Для этого сообщения в блоге мы используем исходный файл конфигурации. Для получения дополнительной информации см. Редактирование файла конфигурации обучения.
Создайте задание обработки данных с помощью следующего кода:
Чтобы проверить статус задания экспорта, используйте следующую команду:
Отправить работу по обучению
После того, как работа по обработке завершена, мы можем начать нашу работу по обучению, где мы создаем наши вложения. Мы рекомендуем тип экземпляра ml.m5.24xlarge, но вы можете изменить его в соответствии со своими вычислительными потребностями. См. следующий код:
Мы печатаем переменную training_results, чтобы получить идентификатор задания обучения. Используйте следующую команду, чтобы проверить статус вашего задания:
%neptune_ml training status --job-id {training_results['id']} --store-to training_status_results
Скачать вложения
После того, как ваша учебная работа будет завершена, последним шагом будет загрузка необработанных вложений. Следующие шаги показывают, как загружать вложения, созданные с помощью KGE (вы можете использовать тот же процесс для RGCN).
В следующем коде мы используем neptune_ml.get_mapping() и get_embeddings() скачать файл сопоставления (mapping.info) и необработанный файл вложений (entity.npy). Затем нам нужно сопоставить соответствующие вложения с их соответствующими идентификаторами.
Чтобы загрузить RGCN, выполните тот же процесс с новым именем задания обучения, обработав данные с параметром modelType, установленным на heterogeneous, затем обучите свою модель с параметром modelName, установленным на rgcn посмотреть здесь Больше подробностей. Как только это будет сделано, позвоните в get_mapping и get_embeddings функции для загрузки новых картографирование.info и сущность.npy файлы. После того, как у вас есть файлы сущности и сопоставления, процесс создания файла CSV идентичен.
Наконец, загрузите свои вложения в желаемое местоположение Amazon S3:
Убедитесь, что вы помните это местоположение S3, вам нужно будет использовать его в части 3.
Убирать
Когда вы закончите использовать решение, обязательно очистите все ресурсы, чтобы избежать текущих расходов.
Заключение
В этом посте мы обсудили, как использовать Neptune ML для обучения встраиванию GNN на основе данных IMDb.
Некоторыми связанными приложениями встраивания графа знаний являются такие концепции, как поиск вне каталога, рекомендации по содержанию, целевая реклама, прогнозирование отсутствующих ссылок, общий поиск и когортный анализ. Поиск вне каталога — это процесс поиска содержимого, которым вы не владеете, а также поиска или рекомендации содержимого в вашем каталоге, максимально близкого к тому, что искал пользователь. Мы углубимся в поиск вне каталога в части 3.
Об авторах
 Мэтью Родс — специалист по данным. Я работаю в лаборатории решений Amazon ML. Он специализируется на построении конвейеров машинного обучения, включающих такие концепции, как обработка естественного языка и компьютерное зрение.
Мэтью Родс — специалист по данным. Я работаю в лаборатории решений Amazon ML. Он специализируется на построении конвейеров машинного обучения, включающих такие концепции, как обработка естественного языка и компьютерное зрение.
 Дивья Бхаргави является специалистом по данным и руководителем направления медиа и развлечений в лаборатории решений Amazon ML, где она решает важные бизнес-задачи для клиентов AWS с помощью машинного обучения. Она работает над пониманием изображений/видео, рекомендательными системами графов знаний, предиктивными примерами использования рекламы.
Дивья Бхаргави является специалистом по данным и руководителем направления медиа и развлечений в лаборатории решений Amazon ML, где она решает важные бизнес-задачи для клиентов AWS с помощью машинного обучения. Она работает над пониманием изображений/видео, рекомендательными системами графов знаний, предиктивными примерами использования рекламы.
 Гаурав Реле — специалист по данным в лаборатории решений Amazon ML, где он работает с клиентами AWS в разных вертикалях, чтобы ускорить использование ими машинного обучения и облачных сервисов AWS для решения своих бизнес-задач.
Гаурав Реле — специалист по данным в лаборатории решений Amazon ML, где он работает с клиентами AWS в разных вертикалях, чтобы ускорить использование ими машинного обучения и облачных сервисов AWS для решения своих бизнес-задач.
 Каран Синдвани — специалист по данным в лаборатории Amazon ML Solutions Lab, где он создает и развертывает модели глубокого обучения. Он специализируется в области компьютерного зрения. В свободное время любит пешие прогулки.
Каран Синдвани — специалист по данным в лаборатории Amazon ML Solutions Lab, где он создает и развертывает модели глубокого обучения. Он специализируется в области компьютерного зрения. В свободное время любит пешие прогулки.
 Соджи Адешина является прикладным ученым в AWS, где он разрабатывает модели на основе графовых нейронных сетей для машинного обучения на графовых задачах с приложениями для мошенничества и злоупотреблений, графов знаний, рекомендательных систем и наук о жизни. В свободное время любит читать и готовить.
Соджи Адешина является прикладным ученым в AWS, где он разрабатывает модели на основе графовых нейронных сетей для машинного обучения на графовых задачах с приложениями для мошенничества и злоупотреблений, графов знаний, рекомендательных систем и наук о жизни. В свободное время любит читать и готовить.
 Видья Сагар Равипати является менеджером в лаборатории решений Amazon ML, где он использует свой обширный опыт работы с крупномасштабными распределенными системами и свою страсть к машинному обучению, чтобы помочь клиентам AWS из разных отраслевых вертикалей ускорить внедрение ИИ и облачных технологий.
Видья Сагар Равипати является менеджером в лаборатории решений Amazon ML, где он использует свой обширный опыт работы с крупномасштабными распределенными системами и свою страсть к машинному обучению, чтобы помочь клиентам AWS из разных отраслевых вертикалей ускорить внедрение ИИ и облачных технологий.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- Платоблокчейн. Интеллект метавселенной Web3. Расширение знаний. Доступ здесь.
- Источник: https://aws.amazon.com/blogs/machine-learning/part-2-power-recommendations-and-search-using-an-imdb-knowledge-graph/
- 1
- 10
- 100
- 11
- 116
- 7
- 9
- a
- О нас
- злоупотребление
- ускорять
- через
- дополнительный
- Дополнительная информация
- Принятие
- Реклама
- После
- AI
- Все
- в одиночестве
- Amazon
- Лаборатория решений Amazon ML
- анализ
- и
- Приложения
- прикладной
- Применить
- соответствующий
- ПЛОЩАДЬ
- искусственный
- искусственный интеллект
- AWS
- основанный
- между
- миллиард
- миллиарды
- Блог
- Коробка
- Театральная касса
- строить
- Строительство
- строит
- бизнес
- призывают
- случаев
- случаев
- каталог
- проблемы
- изменение
- расходы
- проверка
- Закрыть
- облако
- принятие облака
- облачные сервисы
- Кластер
- код
- когорта
- полный
- комплексный
- компьютер
- Компьютерное зрение
- вычисление
- понятия
- Проводить
- Конфигурация
- подключенный
- содержание
- соответствующий
- страны
- Создайте
- создали
- кредит
- кредиты
- клиент
- Взаимодействие с клиентами
- Клиенты
- данным
- обработка данных
- ученый данных
- Наборы данных
- глубоко
- глубокое обучение
- более глубокий
- развертывает
- подробнее
- Разработка
- развивается
- дгл
- различный
- открытие
- обсуждать
- обсуждается
- распределенный
- распределенные системы
- Dont
- скачать
- или
- появление
- Конечная точка
- обязательство
- Развлечения
- организация
- Окружающая среда
- Эфир (ETH)
- пример
- опыт
- экспорт
- извлечение
- Особенность
- несколько
- поле
- Файл
- Файлы
- Найдите
- обнаружение
- поток
- следовать
- после
- формат
- мошенничество
- от
- полный
- Функции
- Общие
- порождать
- поколение
- получить
- Глобальный
- Go
- график
- Графики
- практический
- Жесткий
- помощь
- полезный
- Скрытый
- на высшем уровне
- ЧАСЫ
- Как
- How To
- HTML
- HTTPS
- человек
- идентичный
- идентифицирующий
- осуществлять
- Осуществляющий
- улучшать
- in
- включает в себя
- В том числе
- Увеличение
- индекс
- промышленность
- info
- информация
- пример
- вместо
- Интеллекта
- включать в себя
- IT
- работа
- JSON
- Основные
- знания
- лаборатория
- язык
- большой
- крупномасштабный
- Фамилия
- вести
- изучение
- рычаги
- Библиотека
- Лицензия
- ЖИЗНЬЮ
- Медико-биологическая промышленность
- LINK
- связи
- расположение
- машина
- обучение с помощью машины
- Главная
- ДЕЛАЕТ
- менеджер
- многих
- карта
- отображение
- Медиа
- средний
- Участники
- Метаданные
- миллиона
- отсутствующий
- ML
- модель
- Модели
- БОЛЕЕ
- кино
- имя
- натуральный
- Обработка естественного языка
- Необходимость
- потребности
- Neptune
- сетевой
- сетей
- нейронные сети
- Новые
- узлы
- ноутбук
- Офис
- постоянный
- оригинал
- Другие контрактные услуги
- общий
- собственный
- пакет
- параметр
- параметры
- часть
- страсть
- трубопровод
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- возможное
- После
- мощностью
- Питание
- предсказывать
- прогнозирования
- Подготовить
- Печать / PDF
- проблемам
- процесс
- обработка
- Продукция
- Профиль
- обеспечивать
- приводит
- ассортимент
- рейтинги
- Сырье
- Reading
- рекомендовать
- Рекомендация
- рекомендаций
- рекомендуя
- Связанный
- Отношения
- оставаться
- помнить
- удаление
- Reporting
- обязательный
- Полезные ресурсы
- Итоги
- сохранение
- sagemaker
- то же
- НАУКА
- Ученый
- Поиск
- поиск
- Серии
- обслуживание
- Услуги
- набор
- установка
- должен
- показывать
- Решение
- Решения
- РЕШАТЬ
- Решает
- специализируется
- стек
- Начало
- Статус:
- Шаг
- Шаги
- магазин
- отправить
- такие
- Костюм
- Опрос
- системы
- целевое
- задачи
- снижения вреда
- Технологии
- Ассоциация
- Местоположение
- их
- Через
- время
- позиций
- в
- Train
- Обучение
- Transform
- правда
- учебник
- tv
- понимание
- использование
- прецедент
- Информация о пользователе
- ценный
- ценностное
- Огромная
- версия
- вертикалей
- видение
- способы
- Недели
- Что
- который
- широкий
- Широкий диапазон
- будете
- работает
- работает
- ВАШЕ
- зефирнет