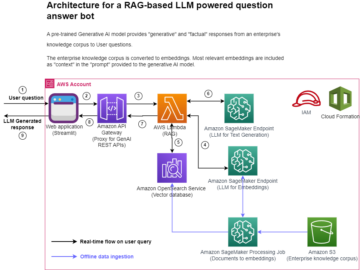
В компьютерном зрении семантическая сегментация — это задача классификации каждого пикселя изображения с классом из известного набора меток, так что пиксели с одной и той же меткой имеют определенные характеристики. Он генерирует маску сегментации входных изображений. Например, на следующих изображениях показана маска сегментации cat этикетка.
 |
 |
В ноябре 2018, Создатель мудреца Амазонки объявила о запуске алгоритма семантической сегментации SageMaker. С помощью этого алгоритма вы можете обучать свои модели с помощью общедоступного набора данных или собственного набора данных. Популярные наборы данных сегментации изображений включают набор данных Common Objects in Context (COCO) и классы визуальных объектов PASCAL (PASCAL VOC), но классы их меток ограничены, и вы можете захотеть обучить модель на целевых объектах, которые не включены в набор. публичные наборы данных. В этом случае вы можете использовать Amazon SageMaker - основа правды чтобы пометить свой собственный набор данных.
В этом посте я демонстрирую следующие решения:
- Использование Ground Truth для маркировки набора данных семантической сегментации
- Преобразование результатов Ground Truth в требуемый входной формат для встроенного алгоритма семантической сегментации SageMaker.
- Использование алгоритма семантической сегментации для обучения модели и выполнения логического вывода
Разметка данных семантической сегментации
Чтобы построить модель машинного обучения для семантической сегментации, нам нужно пометить набор данных на уровне пикселей. Ground Truth дает вам возможность использовать людей-аннотаторов через Amazon Mechanical Turk, сторонних поставщиков или ваших собственных сотрудников. Чтобы узнать больше о рабочей силе, см. Создание и управление персоналом. Если вы не хотите самостоятельно управлять персоналом, занимающимся этикетированием, Amazon SageMaker Ground Truth Plus — еще один отличный вариант в качестве нового готового сервиса маркировки данных, который позволяет быстро создавать высококачественные наборы обучающих данных и снижает затраты до 40 %. В этом посте я покажу вам, как вручную пометить набор данных с помощью функции автоматического сегментирования Ground Truth и пометить краудсорсинг с помощью рабочей силы Mechanical Turk.
Ручная маркировка с помощью Ground Truth
В декабре 2019 года Ground Truth добавила функцию автоматического сегментирования в пользовательский интерфейс маркировки семантической сегментации, чтобы увеличить пропускную способность маркировки и повысить точность. Для получения дополнительной информации см. Автоматическое сегментирование объектов при выполнении маркировки семантической сегментации с помощью Amazon SageMaker Ground Truth. С помощью этой новой функции вы можете ускорить процесс маркировки задач сегментации. Вместо того, чтобы рисовать плотно прилегающий многоугольник или использовать кисть для захвата объекта на изображении, вы рисуете только четыре точки: в самой верхней, самой нижней, самой левой и самой правой точках объекта. Ground Truth принимает эти четыре точки в качестве входных данных и использует алгоритм Deep Extreme Cut (DEXTR) для создания плотно прилегающей маски вокруг объекта. Учебное пособие по использованию Ground Truth для маркировки семантической сегментации изображения см. Семантическая сегментация изображений. Ниже приведен пример того, как инструмент автосегментации автоматически создает маску сегментации после выбора четырех крайних точек объекта.


Краудсорсинговая маркировка с помощью сотрудников Mechanical Turk
Если у вас большой набор данных и вы не хотите вручную маркировать сотни или тысячи изображений, вы можете использовать Mechanical Turk, который предоставляет масштабируемую человеческую рабочую силу по требованию для выполнения задач, которые люди могут выполнять лучше, чем компьютеры. Программное обеспечение Mechanical Turk формализует предложения о работе для тысяч работников, желающих выполнять частичную работу в удобное для них время. Программное обеспечение также извлекает выполненную работу и компилирует ее для вас, заказчика, который платит работникам за удовлетворительную работу (только). Чтобы начать работу с Mechanical Turk, см. Введение в Amazon Mechanical Turk.
Создать задание по маркировке
Ниже приведен пример задания маркировки Mechanical Turk для набора данных о морских черепахах. Набор данных морских черепах взят с конкурса Kaggle. Обнаружение лица морской черепахи, и я выбрал 300 изображений набора данных для демонстрационных целей. Морская черепаха не является распространенным классом в общедоступных наборах данных, поэтому она может представлять ситуацию, требующую маркировки массивного набора данных.
- На консоли SageMaker выберите Маркировка рабочих мест в навигационной панели.
- Выберите Создать работу по маркировке.
- Введите название для своей работы.
- Что касается Настройка входных данных, наведите на Автоматическая настройка данных.
Это генерирует манифест входных данных. - Что касается Расположение S3 для входных наборов данных, введите путь к набору данных.

- Что касается Категория задачи, выберите Фото товара.
- Что касается Выбор задачи, наведите на Семантическая сегментация.

- Что касается Типы работников, наведите на Amazon Mechanical Turk.
- Настройте параметры времени ожидания задачи, срока действия задачи и цены за задачу.

- Добавьте ярлык (для этого поста
sea turtle) и предоставить инструкции по маркировке. - Выберите Создавай.

После настройки задания маркировки вы можете проверить ход маркировки на консоли SageMaker. Когда оно будет отмечено как завершенное, вы можете выбрать задание, чтобы проверить результаты и использовать их для следующих шагов.

Преобразование набора данных
После получения результатов от Ground Truth вы можете использовать встроенные алгоритмы SageMaker для обучения модели на этом наборе данных. Во-первых, вам нужно подготовить помеченный набор данных в качестве запрошенного входного интерфейса для алгоритма семантической сегментации SageMaker.
Запрошенные входные каналы данных
Семантическая сегментация SageMaker предполагает, что ваш обучающий набор данных будет храниться на Простой сервис хранения Amazon (Амазон С3). Ожидается, что набор данных в Amazon S3 будет представлен в двух каналах, один для train и один для validation, используя четыре каталога, два для изображений и два для аннотаций. Предполагается, что аннотации представляют собой несжатые изображения PNG. Набор данных также может иметь карту меток, описывающую, как устанавливаются сопоставления аннотаций. Если нет, алгоритм использует значение по умолчанию. Для логического вывода конечная точка принимает изображения с image/jpeg Тип содержимого. Ниже приведена необходимая структура каналов данных:
Каждое изображение JPG в каталогах train и validation имеет соответствующее изображение метки PNG с тем же именем в каталоге. train_annotation и validation_annotation каталоги. Это соглашение об именах помогает алгоритму связать метку с соответствующим изображением во время обучения. Поезд, train_annotation, проверка и validation_annotation каналы обязательны. Аннотации представляют собой одноканальные изображения в формате PNG. Формат работает до тех пор, пока метаданные (режимы) в изображении помогают алгоритму считывать изображения аннотаций в одноканальное 8-битное целое число без знака.
Выходные данные задания маркировки Ground Truth
Выходные данные, созданные в результате задания маркировки Ground Truth, имеют следующую структуру папок:
Маски сегментации сохраняются в s3://turtle2022/labelturtles/annotations/consolidated-annotation/output. Каждое изображение аннотации представляет собой файл .png, названный в честь индекса исходного изображения и времени завершения маркировки этого изображения. Например, ниже приведены исходное изображение (Image_1.jpg) и его маска сегментации, созданная рабочей силой Mechanical Turk (0_2022-02-10T17:41:04.724225.png). Обратите внимание, что индекс маски отличается от числа в имени исходного изображения.
 |
 |
Выходной манифест задания маркировки находится в папке /manifests/output/output.manifest файл. Это файл JSON, и каждая строка записывает сопоставление между исходным изображением и его меткой, а также другими метаданными. Следующая строка JSON записывает сопоставление между показанным исходным изображением и его аннотацией:
Исходное изображение называется Image_1.jpg, а имя аннотации — 0_2022-02-10T17:41:04.724225.png. Чтобы подготовить данные в качестве необходимых форматов канала данных алгоритма семантической сегментации SageMaker, нам нужно изменить имя аннотации, чтобы оно имело то же имя, что и исходные изображения JPG. И нам также нужно разделить набор данных на train и validation каталоги для исходных изображений и аннотаций.
Преобразование выходных данных задания маркировки Ground Truth в запрошенный входной формат
Чтобы преобразовать вывод, выполните следующие шаги:
- Загрузите все файлы задания этикетирования с Amazon S3 в локальный каталог:
- Прочитайте файл манифеста и измените имена аннотации на те же имена, что и исходные изображения:
- Разделите наборы данных поезда и проверки:
- Создайте каталог в нужном формате для каналов данных алгоритма семантической сегментации:
- Переместите изображения поезда и проверки и их аннотации в созданные каталоги.
- Для изображений используйте следующий код:
- Для аннотаций используйте следующий код:
- Загрузите наборы данных обучения и проверки, а также их наборы данных аннотаций в Amazon S3:
Обучение модели семантической сегментации SageMaker
В этом разделе мы рассмотрим шаги по обучению вашей модели семантической сегментации.
Следуйте образцу записной книжки и настройте каналы данных
Вы можете следовать инструкциям в Алгоритм семантической сегментации теперь доступен в Amazon SageMaker для реализации алгоритма семантической сегментации в вашем наборе данных с метками. Этот образец ноутбук показывает сквозной пример, представляющий алгоритм. В записной книжке вы узнаете, как обучать и размещать модель семантической сегментации с использованием полностью сверточной сети (СКЛС) алгоритм с использованием Набор данных Pascal VOC для тренировки. Поскольку я не планирую обучать модель из набора данных Pascal VOC, я пропустил шаг 3 (подготовка данных) в этой записной книжке. Вместо этого я непосредственно создал train_channel, train_annotation_channe, validation_channelкачества validation_annotation_channel используя места S3, где я хранил свои изображения и аннотации:
Настройте гиперпараметры для собственного набора данных в оценщике SageMaker.
Я последовал за блокнотом и создал объект оценки SageMaker (ss_estimator) для обучения моего алгоритма сегментации. Одна вещь, которую нам нужно настроить для нового набора данных, находится в ss_estimator.set_hyperparameters: нам нужно изменить num_classes=21 в num_classes=2 (turtle и background), и я также изменил epochs=10 в epochs=30 потому что 10 только для демонстрационных целей. Затем я использовал экземпляр p3.2xlarge для обучения модели, установив instance_type="ml.p3.2xlarge". Обучение завершилось за 8 минут. Самый лучший ММОУ (Среднее пересечение по союзу) 0.846 достигается в эпоху 11 с pix_acc (процент пикселей в вашем изображении, которые классифицируются правильно) 0.925, что является довольно хорошим результатом для этого небольшого набора данных.
Результаты вывода модели
Я разместил модель на недорогом экземпляре ml.c5.xlarge:
Наконец, я подготовил тестовый набор из 10 изображений черепах, чтобы увидеть результат вывода обученной модели сегментации:
На следующих изображениях показаны результаты.

Маски сегментации морских черепах выглядят точными, и я доволен этим результатом, полученным на наборе данных из 300 изображений, помеченном работниками Mechanical Turk. Вы также можете изучить другие доступные сети, такие как сеть разбора пирамиды сцен (PSP) or ДипЛаб-В3 в образце записной книжки с вашим набором данных.
Убирать
Удалите конечную точку, когда вы закончите с ней, чтобы избежать дальнейших расходов:
Заключение
В этом посте я показал, как настроить маркировку данных семантической сегментации и обучение модели с помощью SageMaker. Во-первых, вы можете настроить задание по маркировке с помощью инструмента автоматической сегментации или использовать рабочую силу Mechanical Turk (а также другие варианты). Если у вас более 5,000 объектов, вы также можете использовать автоматическую маркировку данных. Затем вы преобразуете выходные данные задания маркировки Ground Truth в требуемые входные форматы для обучения встроенной семантической сегментации SageMaker. После этого вы можете использовать экземпляр ускоренных вычислений (например, p2 или p3) для обучения модели семантической сегментации со следующими ноутбук и разверните модель на более экономичном экземпляре (например, ml.c5.xlarge). Наконец, вы можете просмотреть результаты вывода в своем наборе тестовых данных с помощью нескольких строк кода.
Начало работы с семантической сегментацией SageMaker маркировка данных и модельное обучение с вашим любимым набором данных!
Об авторе
 Кара Янг является специалистом по данным в AWS Professional Services. Она увлечена тем, что помогает клиентам в достижении их бизнес-целей с помощью облачных сервисов AWS. Она помогала организациям создавать решения машинного обучения для различных отраслей, таких как производство, автомобилестроение, экологическая и аэрокосмическая отрасли.
Кара Янг является специалистом по данным в AWS Professional Services. Она увлечена тем, что помогает клиентам в достижении их бизнес-целей с помощью облачных сервисов AWS. Она помогала организациям создавать решения машинного обучения для различных отраслей, таких как производство, автомобилестроение, экологическая и аэрокосмическая отрасли.
- Коинсмарт. Лучшая в Европе биржа биткойнов и криптовалют.
- Платоблокчейн. Интеллект метавселенной Web3. Расширение знаний. БЕСПЛАТНЫЙ ДОСТУП.
- КриптоХок. Альткоин Радар. Бесплатная пробная версия.
- Источник: https://aws.amazon.com/blogs/machine-learning/semantic-segmentation-data-labeling-and-model-training-using-amazon-sagemaker/
- '
- "
- 000
- 10
- 100
- 11
- 2019
- a
- О нас
- ускорять
- ускоренный
- точный
- Достигать
- достигнутый
- через
- добавленный
- Аэрокосмическая индустрия
- алгоритм
- алгоритмы
- Все
- Amazon
- объявило
- Другой
- около
- Юрист
- Автоматизированный
- автоматически
- автомобильный
- доступен
- AWS
- фон
- , так как:
- ЛУЧШЕЕ
- Лучшая
- между
- строить
- встроенный
- бизнес
- захватить
- случаев
- определенный
- изменение
- каналы
- Выберите
- класс
- классов
- классифицированный
- облако
- облачные сервисы
- код
- Общий
- конкурс
- полный
- компьютер
- компьютеры
- вычисление
- доверие
- Консоли
- содержание
- удобство
- соответствующий
- рентабельным
- Расходы
- Создайте
- создали
- Клиенты
- настроить
- данным
- ученый данных
- глубоко
- демонстрировать
- развертывание
- различный
- непосредственно
- рисование
- в течение
- каждый
- позволяет
- впритык
- Конечная точка
- Enter
- окружающий
- установленный
- пример
- Кроме
- ожидаемый
- надеется
- Больше
- экстремальный
- Лицо
- Особенность
- First
- следовать
- после
- формат
- от
- генерируется
- Цели
- хорошо
- серый
- большой
- счастливый
- помог
- помощь
- помогает
- высококачественный
- состоялся
- Как
- How To
- HTTPS
- человек
- Людей
- Сотни
- изображение
- изображений
- осуществлять
- улучшать
- включают
- включены
- Увеличение
- индекс
- промышленности
- информация
- вход
- пример
- Интерфейс
- пересечение
- введение
- IT
- работа
- Джобс
- известный
- этикетка
- маркировка
- Этикетки
- большой
- запуск
- УЧИТЬСЯ
- изучение
- уровень
- Ограниченный
- линия
- линий
- Список
- локальным
- расположение
- места
- Длинное
- посмотреть
- машина
- обучение с помощью машины
- управлять
- обязательный
- вручную
- производство
- карта
- отображение
- маска
- Маски
- массивный
- механический
- может быть
- ML
- модель
- Модели
- БОЛЕЕ
- с разными
- имена
- именования
- Навигация
- сеть
- сетей
- следующий
- ноутбук
- номер
- Предложения
- Опция
- Опции
- организации
- Другие контрактные услуги
- собственный
- страстный
- процент
- выполнения
- пунктов
- Polygon
- Популярное
- Подготовить
- довольно
- цена
- частная
- процесс
- производит
- профессиональный
- обеспечивать
- приводит
- что такое варган?
- целей
- быстро
- RE
- учет
- представлять
- обязательный
- требуется
- Итоги
- обзоре
- то же
- масштабируемые
- Ученый
- МОРЕ
- сегментация
- выбранный
- обслуживание
- Услуги
- набор
- установка
- Поделиться
- показывать
- показанный
- просто
- ситуация
- небольшой
- So
- Software
- Решения
- раскол
- и политические лидеры
- диск
- Стабильность
- цель
- задачи
- команда
- тестXNUMX
- Ассоциация
- Источник
- задача
- сторонние
- тысячи
- Через
- пропускная способность
- время
- инструментом
- Train
- Обучение
- Transform
- союз
- использование
- Проверка
- поставщики
- видение
- КТО
- Работа
- рабочие
- Трудовые ресурсы
- работает
- ВАШЕ